
Je komplexer und umfangreicher die Datenprojekte und -teams werden, desto schwieriger wird es, die Datenintegrität aufrechtzuerhalten. Es wird immer wichtiger, sicherzustellen, dass Änderungen, die in einem Projekt vorgenommen werden, sich nicht auf abhängige Projekte - oder schlimmer noch, auf geschäftskritische Anwendungen - auswirken. An dieser Stelle kommen Datenverträge ins Spiel, die Werkzeuge zur Sicherstellung von Datenqualität und -konsistenz bieten.
In diesem Artikel werden wir uns mit den Konzepten von Datenverträgen befassen und wie sie mit dbt effektiv umgesetzt werden können. Zunächst werden wir uns kurz mit den Grundlagen von Datenverträgen beschäftigen, die als Vereinbarungen zwischen Datenproduzenten und -konsumenten dienen. Als Nächstes werden wir uns die Hände schmutzig machen und sie in dbt implementieren, wobei wir auch die Modellversionierung und Constraints ansprechen werden. Schließlich werden wir dbt Cloud verwenden, um sicherzustellen, dass wir mit Hilfe der CI/CD-Funktionen verhindern, dass Änderungen durchgeführt werden.Grundlagen von Datenverträgen
Stellen Sie sich ein Szenario vor, in dem ein Datenteam eine Pipeline entwickelt, um Kundendaten aus verschiedenen Quellen zu extrahieren, zu transformieren und in ein zentrales Data Warehouse zu laden. Nehmen wir nun an, das Marketingteam verlässt sich auf diese Kundendaten, um gezielte Kampagnen durchzuführen. Sie erwarten, dass die Daten Attribute wie "customer_name", "email_address" und "created_date" enthalten. Aufgrund eines Kommunikationsfehlers oder eines Versehens ändert das Datenteam jedoch die Datenpipeline, so dass das Feld "Kundenname" im endgültigen Datensatz in "customer_full_name" umbenannt wird.
Ohne einen Datenvertrag wird das Marketingteam die Änderung möglicherweise nicht sofort bemerken und seine bestehenden Prozesse und Codes, die auf das Feld "customer_name" angewiesen sind, weiter verwenden. Infolgedessen werden ihre Prozesse und Kampagnen fehlschlagen, was zu einer Verschwendung von Ressourcen führt und möglicherweise den Ruf des Unternehmens schädigt. Mit einem Datenvertrag hätte die Änderung in der Datenpipeline eine Warnung oder einen Validierungsfehler ausgelöst, der die Diskrepanz zwischen der erwarteten und der tatsächlichen Datenstruktur hervorhebt und das Problem verhindert.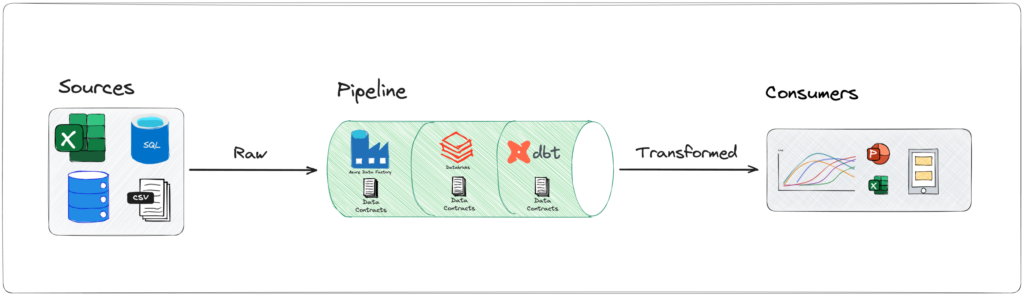
Datenverträge dienen, ähnlich wie eine API in der Softwareentwicklung, als Vereinbarungen zwischen Produzenten und Konsumenten. Genauso wie API-Verträge das erwartete Verhalten, die Eingaben und Ausgaben von API-Endpunkten definieren, umreißen Datenverträge die Struktur, das Format und die Qualitätserwartungen von Daten und Ausgabemodellen. Diese Verträge bilden eine Grundlage für den Aufbau robuster und skalierbarer Datenlösungen.
Durch die Definition klarer Datenverträge können Unternehmen Dateninkonsistenzen, Fehlinterpretationen und kostspielige Fehler vermeiden. Durch die Einführung von Datenverträgen und Versionskontrolle können Unternehmen Abwärtskompatibilität, Reproduzierbarkeit und nahtlose Datenintegration sicherstellen und dabei die Grundsätze der Best Practices der Softwareentwicklung einhalten und fehlerhafte Änderungen vermeiden. Jetzt, da das Konzept und(hoffentlich) seine Bedeutung klar sind, stellt sich die Frage, wie wir Datenverträge tatsächlich implementieren können, ohne unser Projekt, in dem wahrscheinlich schon viele verschiedene Akteure tätig sind, noch komplexer zu machen.dbt für die Rettung
In den letzten Jahren hat sich dbt zu einem unverzichtbaren Werkzeug für die Datentransformation im Modern Data Stack (und auch zu einem meiner Lieblingstools) entwickelt und ist führend im Bereich Analytics Engineer. Seit der Veröffentlichung von v1.5 und kürzlich v1.6 hat dbt begonnen, sich auf Multiprojektfunktionen zu konzentrieren, da die Projektgrößen und die Komplexität schnell wachsen.
Natürlich nicht nur, weil Sie können dass Sie sollten . In diesem Fall macht es jedoch Sinn: Die Modelle und die Geschäftslogik befinden sich in Ihrem dbt-Projekt, daher ist der logische Ort für Ihre Vertragsdefinitionen und deren Durchsetzung: Ihr dbt-Projekt. Auf diese Weise können Sie Ihre Datenmodellierung ganz einfach pflegen und weiterentwickeln und sich dabei auf automatisierte Prüfungen verlassen, statt nur auf sich selbst, um versehentliche Fehler zu vermeiden.Einrichten
Genug der Worte, machen wir uns die Hände schmutzig. Hier finden Sie das Repository, das wir verwenden, um unsere ersten Verträge in dbt zu erstellen.
Zuerst checken wir die Verzweigung aus start-here . Dort haben wir ein sehr einfaches Projekt mit einigen Staging-, Intermediate- und Marts-Modellen und einer grundlegenden Dokumentation.
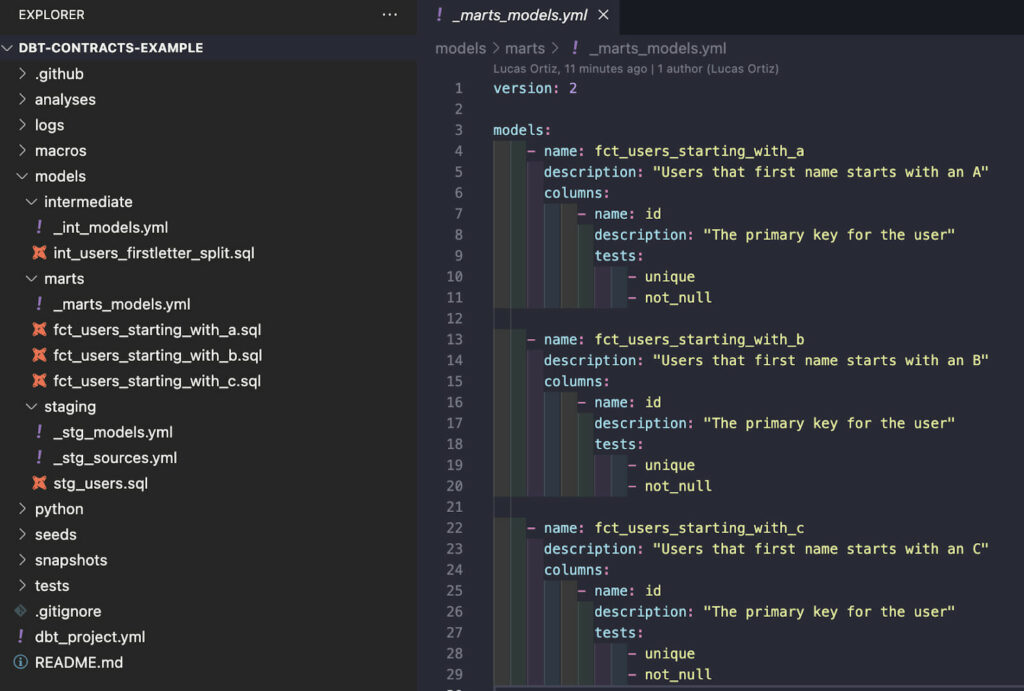
Damit wir die Durchsetzung von Datenverträgen in unserem dbt-Projekt verwenden können, müssen wir die Parameter name und data_type für jede Spalte definieren, da dies für "partielle" Verträge immer noch nicht zulässig ist.
Konzentrieren wir uns auf unser erstes Marts-Modell. Unten finden Sie die hinzugefügten Parameter, die noch fehlten.
Modelle:
- Name: fct_Benutzer_beginnen_mit_a
Beschreibung: "Benutzer, deren Vorname mit einem A beginnt"
Spalten:
- Name: id
data_type: int
Beschreibung: "Der Primärschlüssel für den Benutzer"
Tests:
- einzigartig
- nicht_null
- name: vorname
data_type: string
- name: vorname
data_type: string
- name: nachname
data_type: string
- name: email
data_type: string
Sobald wir alle unsere Spalten mit einem definierten Namen und data_type haben, besteht der nächste Schritt darin, die Vertragserzwingung tatsächlich einzubeziehen. Das geht ganz einfach, indem Sie die richtigen Parameter in der Datei models hinzufügen.
Modelle:
- Name: fct_Benutzer_beginnen_mit_a
config:
contract:
enforced: true
Beschreibung: "Benutzer, deren Vorname mit einem A beginnt"
Spalten:
- Name: id
data_type: int
Beschreibung: "Der Primärschlüssel für den Benutzer"
Tests:
- einzigartig
- nicht_null
- name: erster_buchstabe
data_type: string
- name: vorname
data_type: string
- Name: Nachname
data_type: string
- Name: E-Mail
data_type: string
Sie können den Code, den wir bisher haben, in der Verzweigung Vertragserzwingung .
Für eine einfache Implementierung ist das alles! Dbt vergleicht nun Ihre Datenvertragsdefinitionen und Ihr tatsächliches Modell, gibt einen Fehler aus und materialisiert das Modell nicht, wenn eine Abweichung vorliegt.
Aber wir sind nicht wegen der Grundlagen hier, oder?
Beschränkungen und Modellversionen
Zwei weitere großartige Funktionen, die in den neuesten Versionen von dbt hinzugefügt wurden, sind Constraints und die Modellversionierung.
Einschränkungen
Beschränkungen werden verwendet, um die Ausgabedaten des Modells zu überprüfen, bevor das Modell materialisiert wird. Wenn eine Einschränkung fehlschlägt, wird der Vorgang gestoppt und alle Änderungen werden rückgängig gemacht, so dass das Modell nicht mehr aktualisiert werden kann. Die Durchsetzung eines Vertrags durch Constraints stellt sicher, dass die Datenverträge eingehalten werden und die Genauigkeit und Aktualität der Daten erhalten bleibt.
Sie fragen sich vielleicht, was der Unterschied zwischen Beschränkungen und Tests ist:
- Constraints hängen von der plattformspezifischen Unterstützung ab, während Tests flexibler sind. Sie können alles testen, solange Sie eine Abfrage dafür erstellen können.
- Einschränkungen verhindern die Materialisierung der Tabelle, wenn die Tests fehlschlagen, nachdem das Modell bereits materialisiert wurde.
- Zwänge erfordern den Vertrag erzwungen werden, während Tests dies nicht tun.
Beschränkungen können sowohl auf Modellebene als auch auf Spaltenebene definiert werden. Wenn sich die Einschränkung nur auf eine Spalte bezieht, ist es am besten, sie auf Spaltenebene zu definieren.
Einrichten
Schauen wir uns einmal an, wie unser Code mit den angewendeten Einschränkungen aussehen wird.
Modelle:
- Name: fct_Benutzer_beginnen_mit_a
Konfiguration:
Vertrag:
erzwungen: true
Beschreibung: "Benutzer, deren Vorname mit einem A beginnt"
Beschränkungen:
- type: check
columns: [vor_name, nach_name]
expression: "vor_name != nach_name"
name: vor_und_nach_name_unterschied_check
Spalten:
- Name: id
data_type: int
Beschreibung: "Der Primärschlüssel für den Benutzer"
constraints:
- type: not_null
#- type: primary_key # Funktioniert auf Databricks nur bei Verwendung von Unity Catalog (funktioniert nicht für hive_metastore)
Tests:
- unique # validiert tatsächlich die Eindeutigkeit für diese Spalte
- name: erster_buchstabe
data_type: string
- name: vorname
data_type: string
- Name: Nachname
data_type: string
- Name: E-Mail
data_type: string
Sie können den Code, den wir bisher haben, in der Verzweigung sehen Beschränkungen .
Wie Sie sehen, haben wir den not_null-Test entfernt und durch eine Einschränkung ersetzt, aber den unique-Test beibehalten.
In der offiziellen Dokumentation von dbt finden Sie weitere Informationen zu den Optionen für Einschränkungen und deren Erzwingung für jede Datenplattform.
Modellversionen i die Daten
Einrichten
Lassen Sie uns nun eine einfache Versionierung für unser Modell implementieren.
Zunächst erstellen wir eine doppelte Datei unseres Modells und fügen am Ende _v2 hinzu, in unserem Fall fct_users_starting_with_a_v2.sql - dies ist das von dbt verwendete Muster, um die Modellversionen zu identifizieren.
Wir werden eine der Spalten umbenennen, zum Beispiel E-Mail → email_address. Diese Änderung könnte einige der nachgelagerten Verbraucher, die auf diese Spalte angewiesen sind, beeinträchtigen, daher werden wir eine neue Version dieses Modells erstellen.
MIT
-- Zwischenstufe
users_firstletter_split AS (
SELECT * FROM {{ ref("int_users_firstletter_split")}}
),
-- Filter
filter_by_first_letter AS (
SELECT
id,
erster_Buchstabe,
vor_name,
letzter_name,
email AS email_address
FROM users_firstletter_split
WHERE LOWER(erster_Buchstabe) = 'a'
)
SELECT * FROM filter_by_first_letter
Zurück zu unserer .yml, fügen wir die notwendigen Parameter hinzu.
Modelle:
- Name: fct_Benutzer_beginnen_mit_a
neueste_version: 1
Konfiguration:
Vertrag:
erzwungen: true
Beschreibung: "Benutzer, deren Vorname mit einem A beginnt"
Zwänge:
- Typ: Scheck
Spalten: [vor_name, nach_name]
Ausdruck: "vor_name != nach_name"
name: vor_und_nach_name_diff_check
Spalten:
- Name: id
data_type: int
Beschreibung: "Der Primärschlüssel für den Benutzer"
Zwänge:
- Typ: not_null
#- Funktioniert auf Databricks nur bei Verwendung von Unity Catalog (funktioniert nicht für hive_metastore)
Tests:
- unique # validiert tatsächlich die Eindeutigkeit für diese Spalte
- name: erster_buchstabe
data_type: string
- name: vorname
data_type: string
- Name: Nachname
data_type: string
- Name: E-Mail
data_type: string
Versionen:
- v: 2
Spalten:
- include: all
exclude: [email]
- name: email_address
data_type: string
- v: 1
config:
alias: fct_users_starting_with_a
Sie können den Code, den wir bisher haben, in der Verzweigung model-versions .
Zusammenfassend lässt sich sagen, dass wir die erste Version als die neueste beibehalten, während wir unsere neue Version(v2) testen. Im Parameter versions müssen wir den Unterschied zwischen der Version und den Top-Level-Konfigurationen deklarieren. In diesem Fall schließen wir die Spalte email aus und fügen die Spalte email_address hinzu.
Das werden Sie haben, wenn Sie Ihre Modelle mit Modellversionen ausführen.

Es gibt noch einige weitere Optionen für die Definition von Modellversionen und das Verwerfen alter Modelle. Sie finden alle relevanten Informationen in der offiziellen Dokumentation von dbt.
Aufspüren von Änderungen mit dbt Cloud und CI/CD
Bisher haben wir unser Schema und die Vertragserzwingung konfiguriert, Beschränkungen und die Modellversion hinzugefügt. Wie können wir jedoch sicherstellen, dass eine Änderung des Schemas und die versehentliche Erstellung einer neuen Version nicht zu einem Bruch führt?
Hoffentlich helfen uns dbt Cloud und seine CI/CD-Funktionen dabei. Durch die Verwendung des Selektors state:modified und die Erzwingung unseres Vertrags verfolgt dbt Cloud die Änderungen im Schema und meldet einen Fehler, wenn eine mögliche Änderung entdeckt wird und keine neue Version erstellt wurde.
Die "bahnbrechenden Änderungen", die dbt Cloud verfolgt, sind:
- Entfernen einer vorhandenen Spalte.
- Ändern des data_type einer bestehenden Spalte.
- Entfernen oder Ändern einer der Beschränkungen einer bestehenden Spalte (dbt v1.6 oder höher).
Einrichten
Hinweis: Für diese Einrichtung gehen wir davon aus, dass Sie bereits ein dbt Cloud-Projekt mit mehreren Umgebungen und mindestens einem Job für jede Umgebung haben, der alle Modelle erstellt (dbt build). Wenn Sie dies nicht tun, können Sie die folgenden Blogbeiträge zur Einrichtung befolgen.
- Mehrere BigQuery-Projekte mit einem dbt Cloud-Projekt verwalten
- Wie man mehrere Databricks Workspaces mit einem dbt Cloud-Projekt verwendet
- CI/CD in der dbt Cloud mit GitHub-Aktionen: Automatisierung der Bereitstellung mehrerer Umgebungen
Lassen Sie uns nun unser Projekt in dbt Cloud öffnen.
Wir werden einen Job erstellen, der immer dann ausgelöst wird, wenn ein Pull Request geöffnet wird. Dieser Job sollte die notwendigen Tests und Validierungen durchführen, um sicherzustellen, dass die Codeänderungen für die Zusammenführung mit dem Hauptzweig bereit sind. Der Job erstellt nur die geänderten Modelle und die von ihnen abhängigen nachgelagerten Modelle.
In diesem Fall gehen wir davon aus, dass Sie GitHub als Code-Repository verwenden, aber andere Dienste wie GitLab und Azure DevOps werden ebenfalls unterstützt.
Wir nennen den Auftrag "CI preprod" und wählen die Preprod-Umgebung.
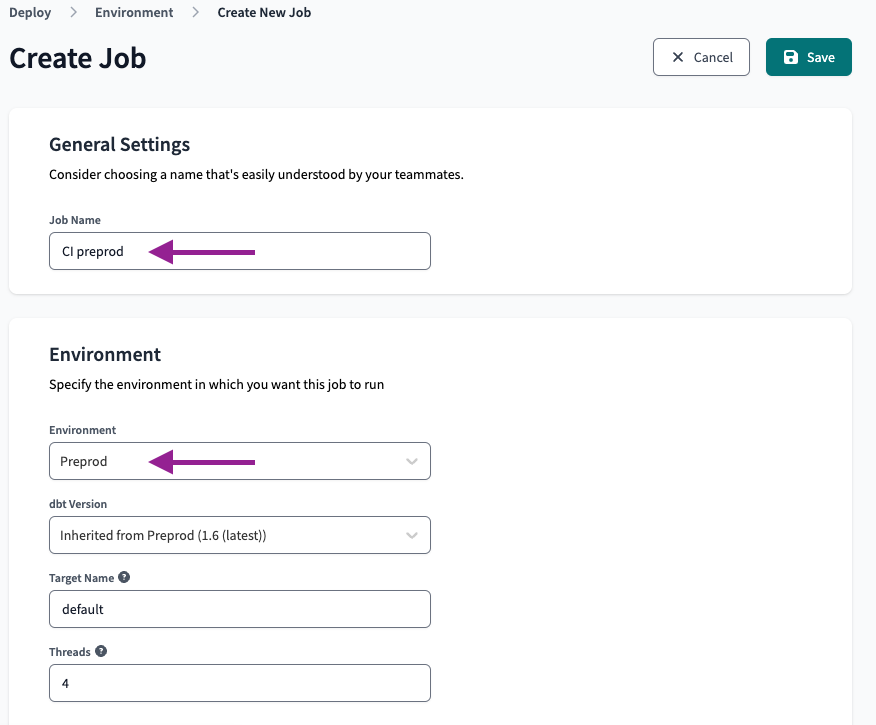
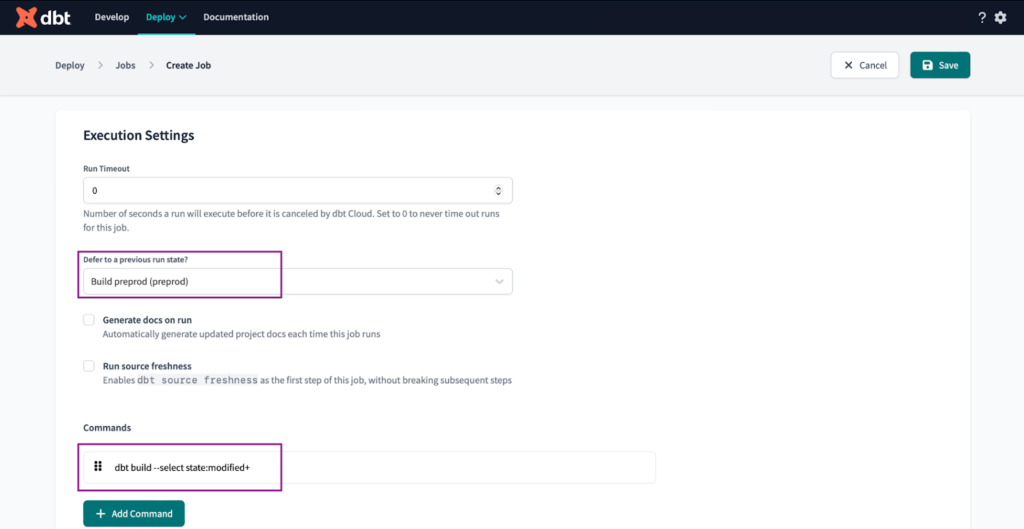
In den Ausführungseinstellungen stellen wir Folgendes ein:
- Setzen Sie "Auf vorherigen Ausführungsstatus zurücksetzen?" auf die Option " Vorläufigen Zustand erstellen ". Dadurch wird sichergestellt, dass unser CI-Job nicht ausgelöst wird, wenn es Probleme mit der Umgebung gibt.
- Setzen Sie die Befehle auf " dbt build --select state:modified+ "
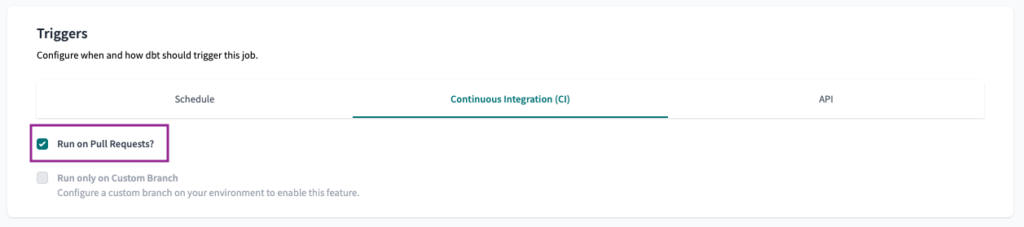
Um schließlich den Auslöser für die kontinuierliche Integration (CI) festzulegen, müssen wir nur das Kontrollkästchen Bei Pull Request ausführen? aktivieren.
Hinweis: Um den CI-Trigger zu aktivieren, müssen Sie Ihr dbt Cloud-Projekt entweder mit GitHub, GitLab oder Azure DevOps verbinden.
Wir sind bereit! Um es zu testen, müssen wir zuerst den Job ausführen, der alle Modelle erstellt( in unserem FallBuild preprod ), damit dbt Cloud ein Manifest erstellt, um die letzten Änderungen zu vergleichen.
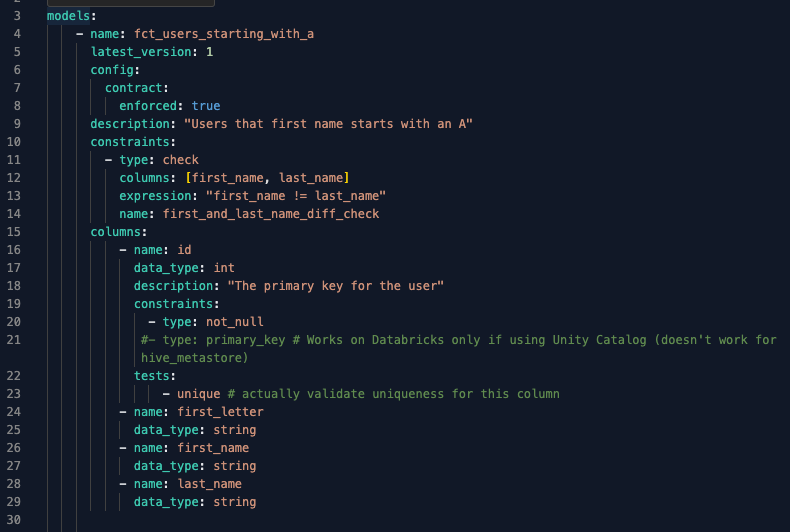
Sobald dies geschehen ist, erstellen wir einen neuen Zweig und fügen eine Änderung ein, ohne absichtlich eine neue Version zu erstellen. In diesem Fall entfernen wir die E-Mail-Spalte, sowohl aus der letzten Version des Modells(fct_users_starting_with_a.sql) als auch aus der .yml-Datei des Modells.
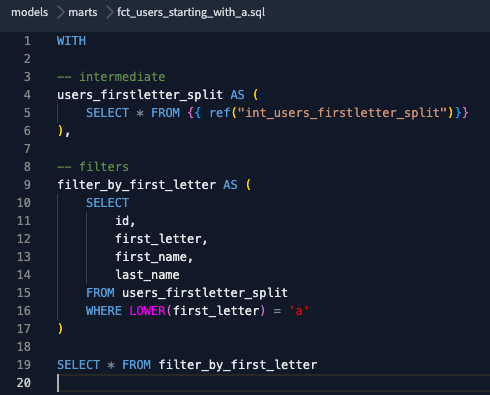
E-Mail-Spalte aus der Schemadefinition der letzten Version des Modells in der .yml-Datei entfernt.
Schließlich erstellen wir einen Pull Request, der unseren CI Preprod Job auslöst und aufgrund einer Vertragsänderung fehlschlägt.
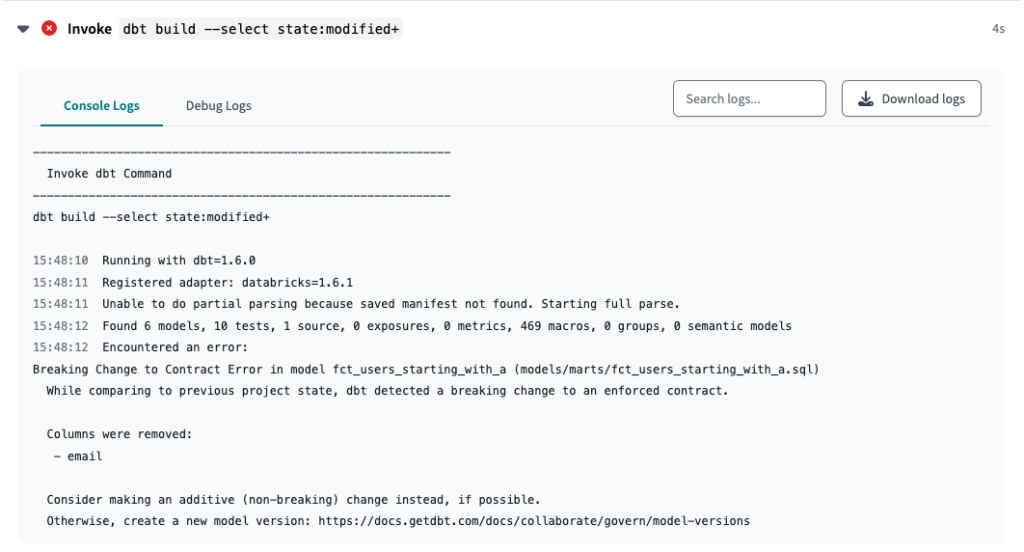
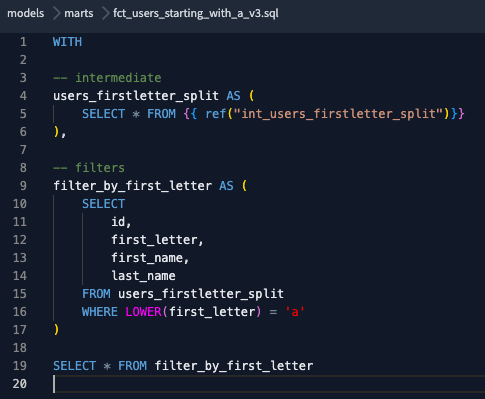
Wie erwartet, haben wir unseren Fehler! Um ihn zu beheben, erstellen wir zunächst eine neue Version des Modells mit der von uns vorgenommenen Änderung und fügen diese Version dann der .yml-Datei hinzu. Sobald wir sie übertragen haben, wird der Job erneut ausgeführt und (hoffentlich) erfolgreich sein.
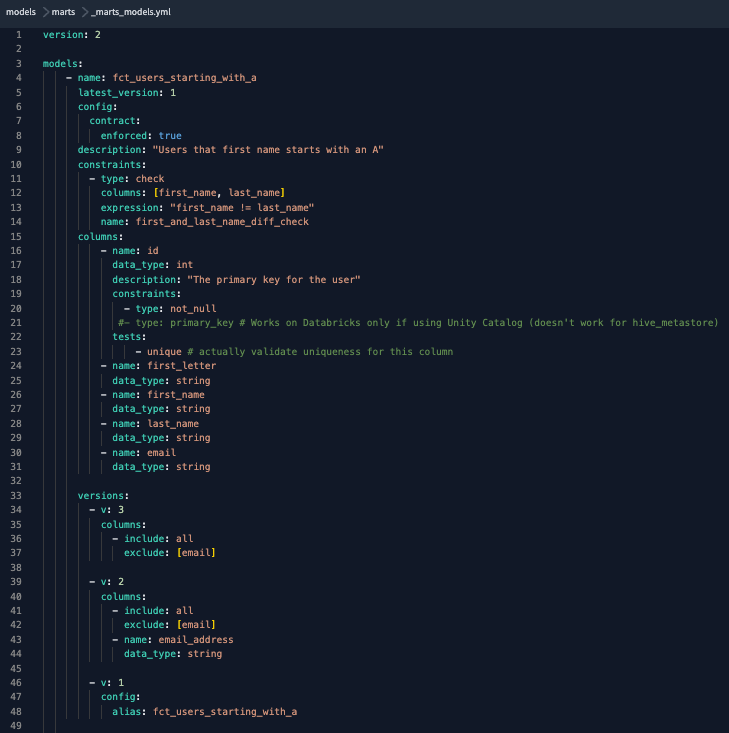
Neue Modellversion(_v3), bei der die E-Mail-Spalte entfernt wurde.
Neue Version zur .yml-Datei hinzugefügt und E-Mail-Spalte wieder in die Schemadefinition der neuesten Version des Modells eingefügt.
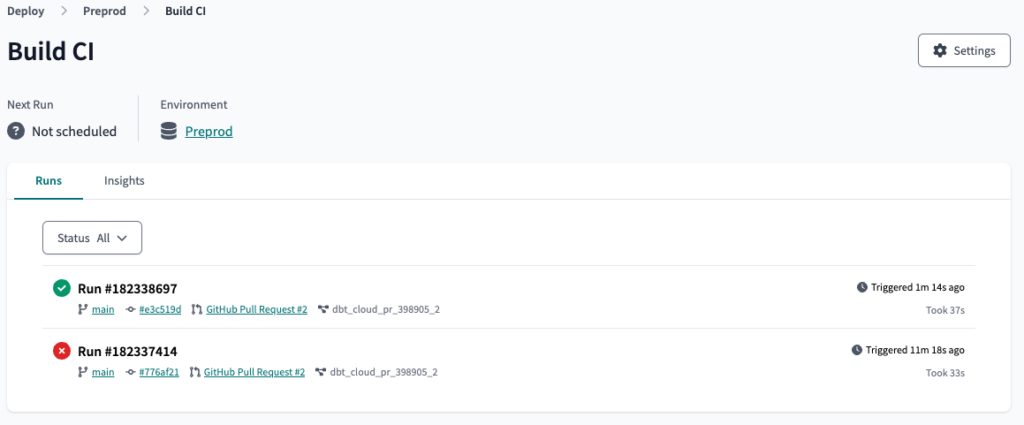
Nach dem Commit wird der Job erneut ausgeführt und ist dieses Mal erfolgreich.
Fazit
In der Welt der Datenprojekte und -teams ist die Wahrung der Datenintegrität von entscheidender Bedeutung, um die Qualität und Konsistenz der Daten sicherzustellen. Durch die Implementierung von Datenverträgen mit dbt können Unternehmen Dateninkonsistenzen, Fehlinterpretationen und kostspielige Fehler verhindern. Mit den Funktionen von dbt zur Durchsetzung von Verträgen können Abweichungen zwischen den erwarteten und den tatsächlichen Datenstrukturen aufgezeigt werden, so dass Probleme gar nicht erst entstehen. Durch die Einführung von Datenverträgen und Versionierung können Unternehmen Abwärtskompatibilität, Reproduzierbarkeit und nahtlose Datenintegration sicherstellen. Die Funktionen von dbt machen es zu einem leistungsstarken Werkzeug für die Implementierung und Durchsetzung von Datenverträgen und bilden die Grundlage für den Aufbau robuster und skalierbarer Datenlösungen.
Verfasst von
Lucas Ortiz
I've always been fascinated by technology and problem-solving. Great challenges are what keep me motivated, I rarely accept that a task can’t be done, it’s only a matter of finding new paths to solve the puzzle.
Unsere Ideen
Weitere Blogs




Contact