Blog
Mehrere BigQuery-Projekte mit einem dbt Cloud-Projekt verwalten

Die Verwaltung von Datenpipelines kann eine schwierige Aufgabe sein, insbesondere wenn Sie mit mehreren Umgebungen arbeiten. Wenn Sie neue Modelle und Transformationen entwickeln, müssen Sie sicherstellen, dass Ihre Änderungen nichts in Ihrer Produktionsumgebung kaputt machen, aber dennoch die Flexibilität für Tests und Entwicklung erhalten. Durch den Einsatz von dbt Cloud und BigQuery können Sie Ihre Transformations-Pipeline effizienter und effektiver verwalten, da Sie über mehrere Umgebungen und eine automatisierte Bereitstellung verfügen.
In diesem Artikel gehen wir die Schritte durch, mit denen Sie ein einziges dbt Cloud-Projekt verwenden, um separate GCP-Projekte für zwei verschiedene Umgebungen zu verwalten: preprod und prod.
GCP-Projekte erstellen
Zu Beginn müssen wir zwei verschiedene GCP-Projekte erstellen. Wir nennen sie xebia-data-preprod und xebia-data-prod .
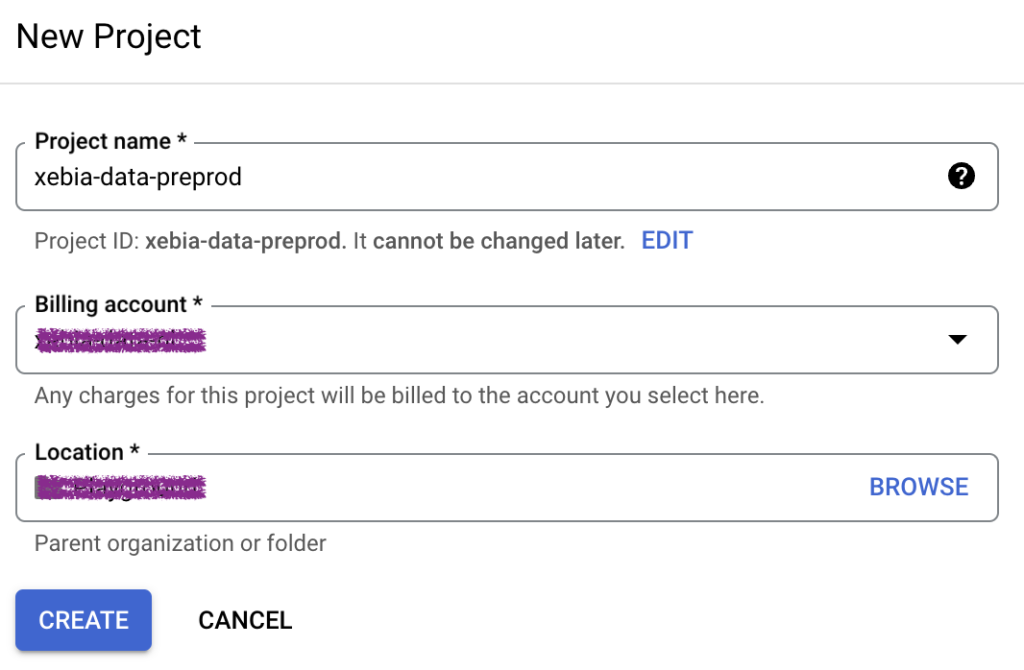
Unsere BigQuery-Konsole sollte in etwa so aussehen, für beide Projekte, wobei Plattform das Dataset mit den Daten ist, die wir umwandeln möchten.


Hinweis: In diesem Artikel befassen wir uns nicht mit dem Extrahieren und Laden von ELT. Daher gehen wir davon aus, dass beide Projekte über die Daten verfügen, die wir für die Modelle verwenden. Es gibt mehrere Möglichkeiten, dies zu tun, und es ist wirklich fallspezifisch.
Ein Servicekonto in GCP erstellen
Um dbt Cloud mit beiden Projekten zu verbinden, müssen wir ein Servicekonto bereitstellen, das Zugriff auf beide Projekte hat.
Zunächst erstellen wir das Servicekonto in unserem xebia-data-preprod Projekt:
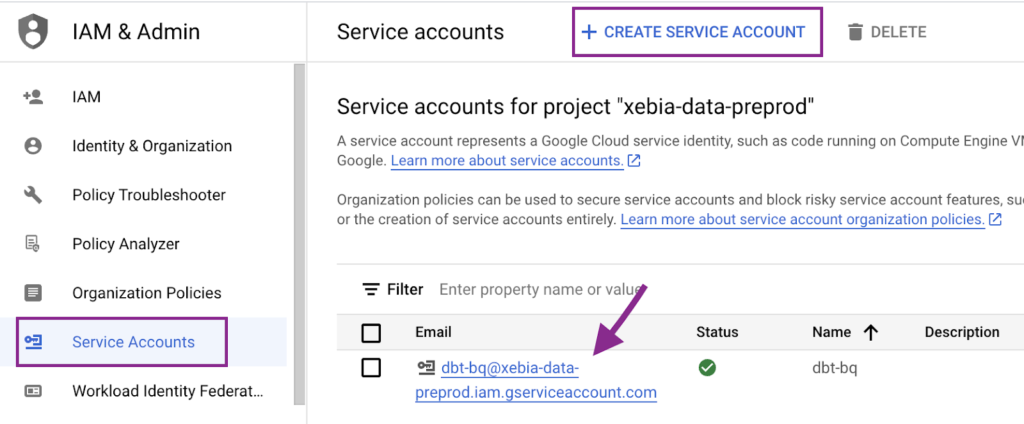
Als Nächstes erzeugen wir einen JSON-Schlüssel, der in der dbt Cloud verwendet werden soll. Dazu müssen wir in das erstellte Servicekonto klicken, zur Registerkarte Schlüssel navigieren und den JSON-Schlüssel erstellen. Es wird eine Datei erzeugt und auf Ihren Computer heruntergeladen.
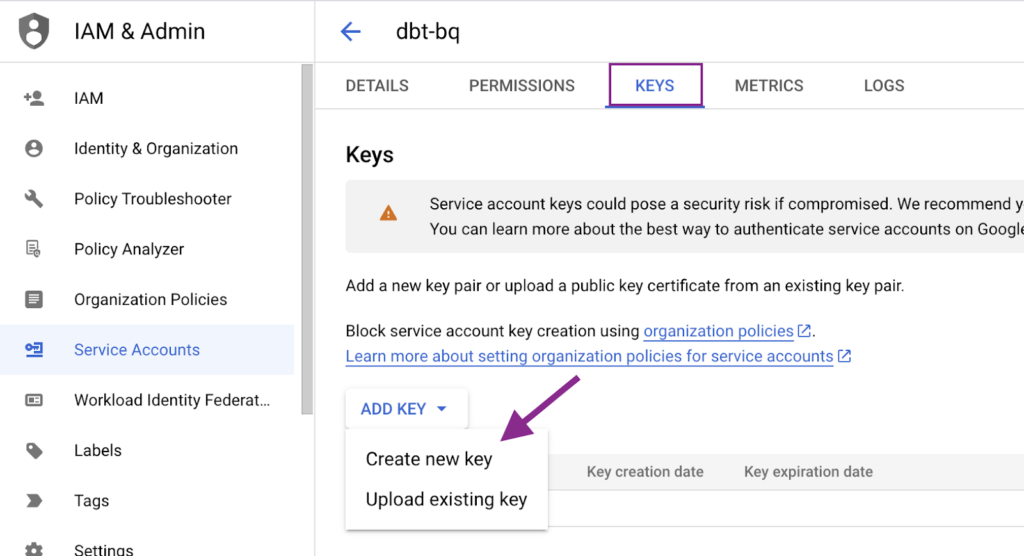
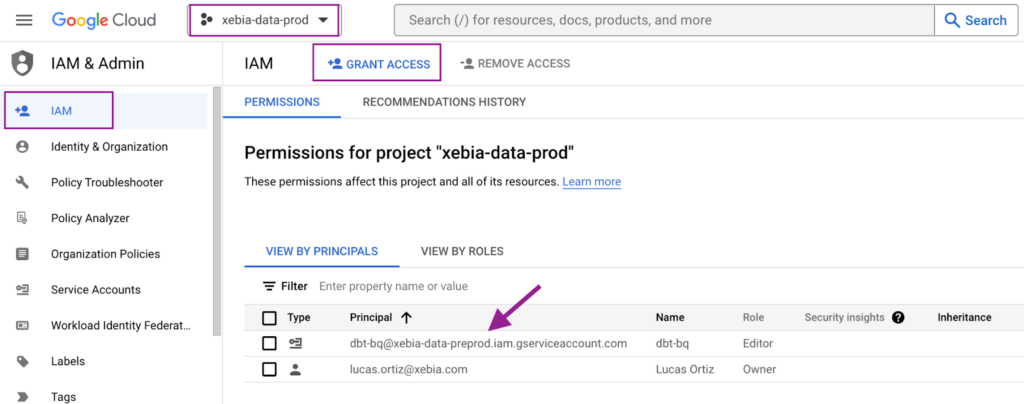
Zum Schluss kopieren wir die E-Mail aus dem erstellten Service-Konto und ermöglichen den Zugriff auf das andere Projekt (xebia-data-prod).
Erstellen Sie das dbt Cloud-Projekt
Auf der Seite der dbt Cloud beginnen wir mit der Erstellung unseres neuen Projekts. Wir werden es benennen xebia-data-platform .
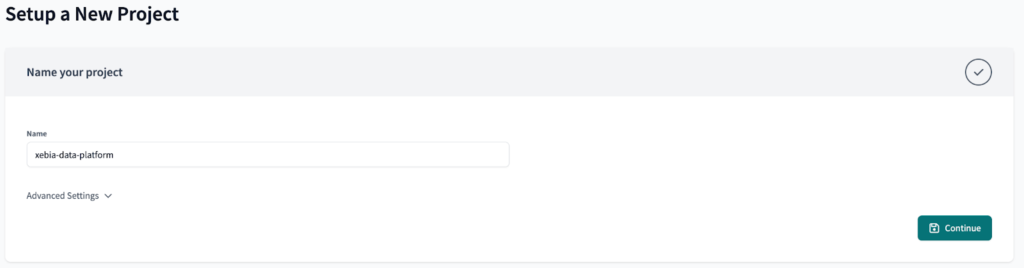
Zunächst werden wir die Verbindung zu BigQuery nicht festlegen, da wir sie später aktualisieren müssten, um eine Umgebungsvariable, um Nacharbeit zu erzeugen. Klicken Sie einfach auf die Schaltfläche ' Überspringen' Schaltfläche für jetzt.
Sobald Sie dies getan haben, wird der nächste Schritt (Konfigurieren Sie Ihre Umgebung) automatisch übersprungen.
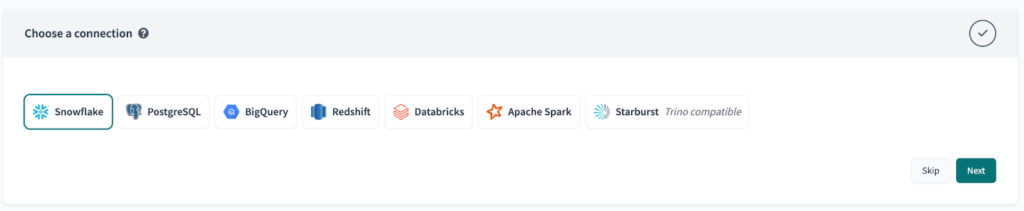
Zum Schluss richten Sie Ihr Repository mit Ihrer bevorzugten Git-Plattform ein.
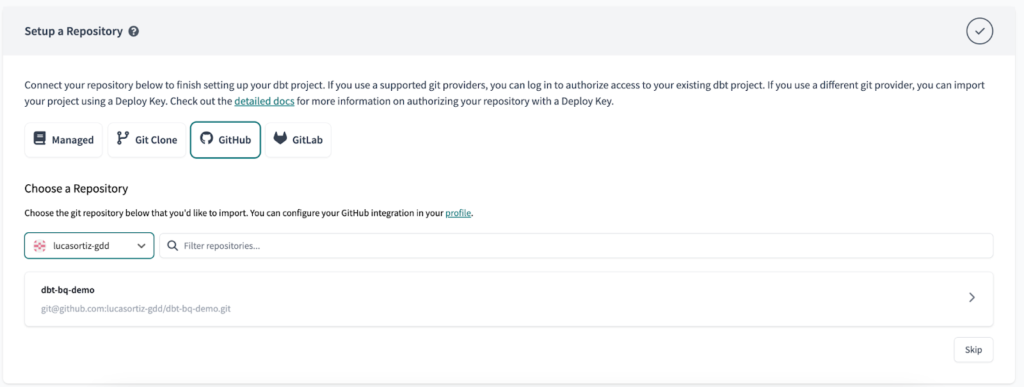
Einrichten der Umgebungen in der dbt Cloud
Als nächstes werden wir drei Umgebungen erstellen: dev , preprod und prod . Dev ist eine Entwicklungsumgebung, während preprod und prod Bereitstellungsumgebungen sind.
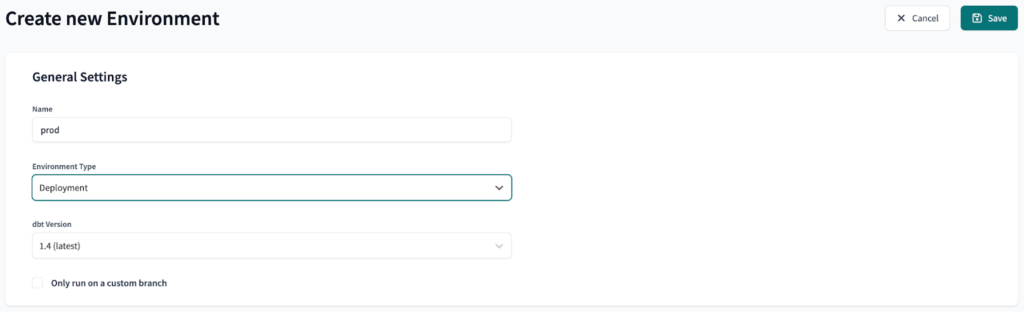
Das Endergebnis sollte wie folgt aussehen:
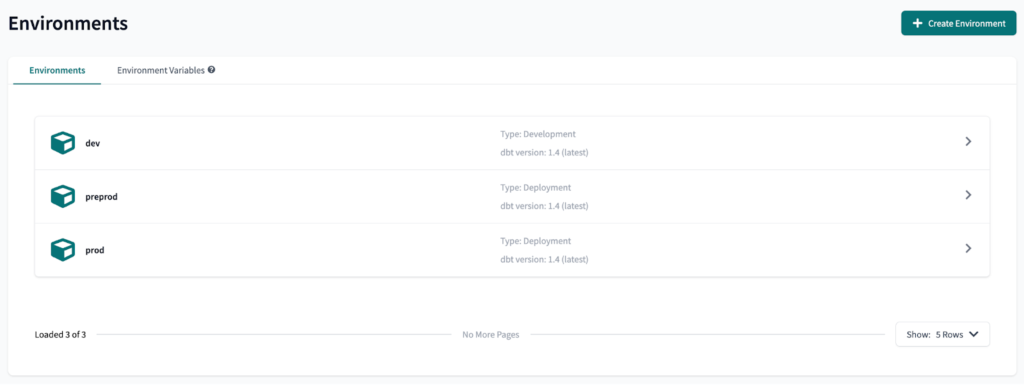
Einrichten der Umgebungsvariablen in dbt Cloud
Der nächste Schritt ist die Erstellung einer Umgebungsvariable zu jeder Umgebung. Dies ermöglicht uns die Verwendung der xebia-data-preprod GCP-Projekt im Verzeichnis preprod dbt Cloud-Umgebung, und das xebia-data-prod GCP-Projekt in der prod dbt Cloud-Umgebung.
So erstellen Sie eine Umgebungsvariable zu erstellen, ist ziemlich einfach: auf der Seite Umgebungen Seite, wählen Sie Umgebungsvariablen und klicken Sie auf 'Variable hinzufügen'. .
Wir nennen unsere Variable DBT_GCP_PROJECT auf und setzen die Werte wie folgt:
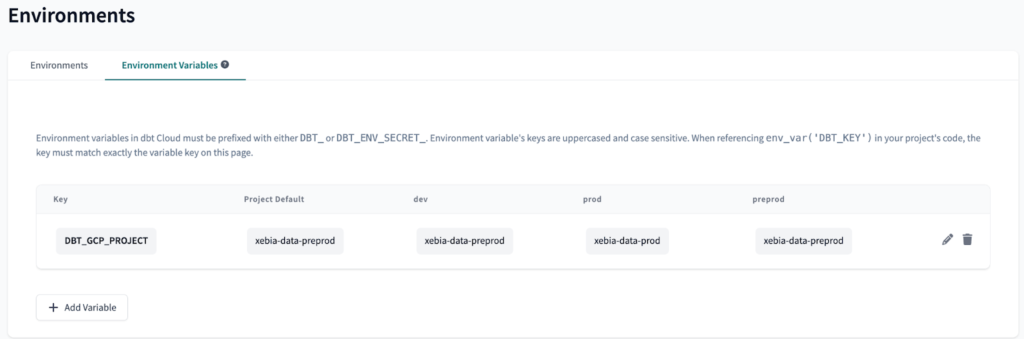
Da wir nur zwei GCP-Projekte haben, werden wir das gleiche Projekt für preprod und dev Es ist jedoch auch möglich, die gleiche Logik mit drei oder mehr Projekten zu implementieren.
Sobald die Variable gesetzt ist, können wir die Verbindung mit BigQuery herstellen und die neu erstellte Variable verwenden, um je nach verwendeter Umgebung zwischen den Projekten zu wechseln.
Einrichten der Verbindungsdetails in dbt Cloud
Um die Verbindung mit BigQuery herzustellen, müssen wir zunächst zu den Kontoeinstellungen navigieren. Dort können wir alle unsere Projekte finden. Wir klicken auf das Projekt, das wir gerade erstellt haben, und dann auf ' Verbindung konfigurieren'..
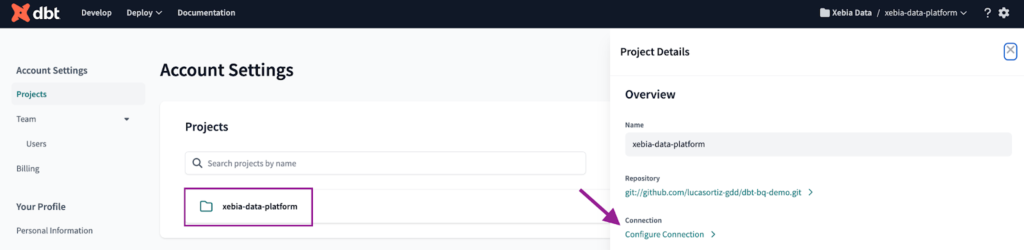
Der nächste Schritt besteht darin, den Verbindungstyp auf BigQuery einzustellen und die JSON-Datei zu importieren, die wir aus dem Servicekonto erstellt haben. Sobald dies geschehen ist, sollten alle anderen Informationen ausgefüllt sein.

Schließlich werden wir die Projekt-ID die automatisch ausgefüllt wurde, durch die von uns erstellte Variable:
{{ env_var("DBT_GCP_PROJECT") }} 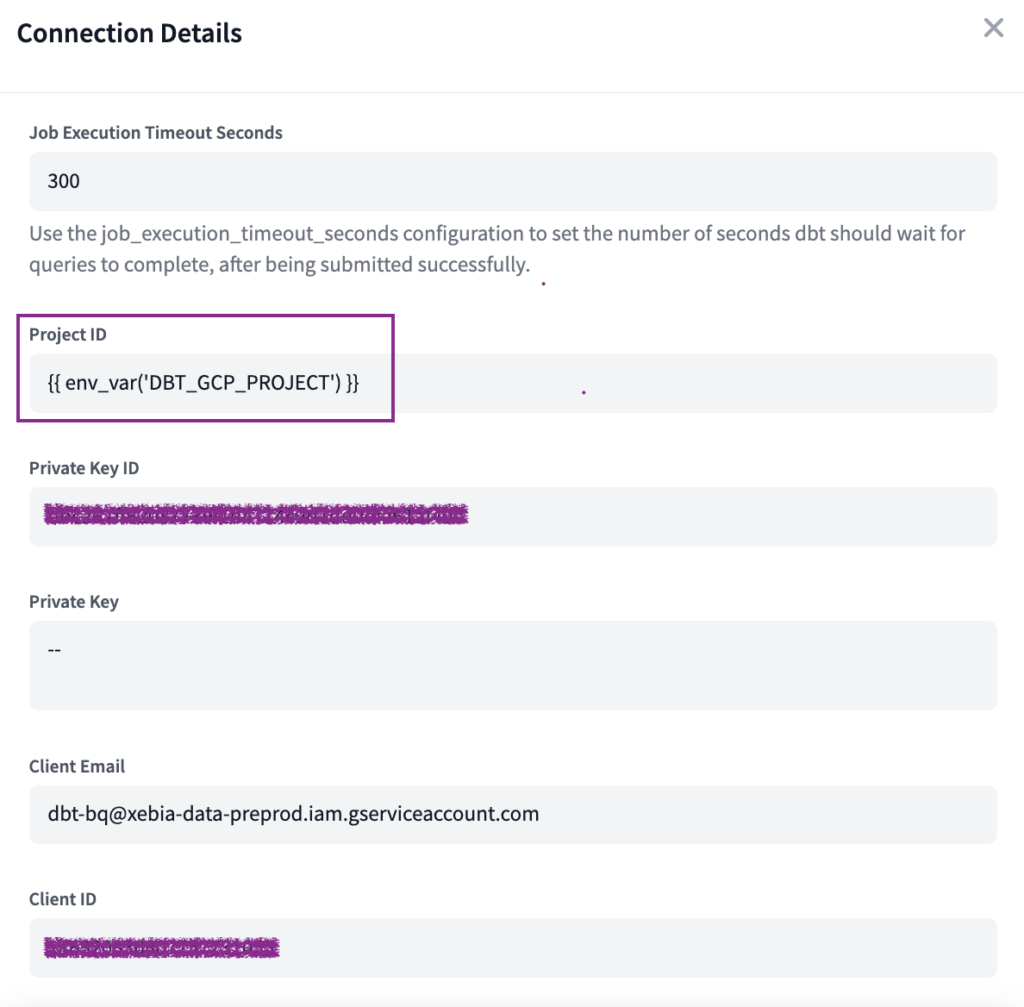
In einem weiteren Schritt werden wir die Anmeldeinformationen für die Entwicklung. Navigieren Sie dazu zur Seite 'Berechtigungsnachweise' Seite, wählen Sie das Projekt aus und wählen Sie einen 'Datensatz' einen für Sie eindeutigen Namen - dbt_lucas in meinem Fall.
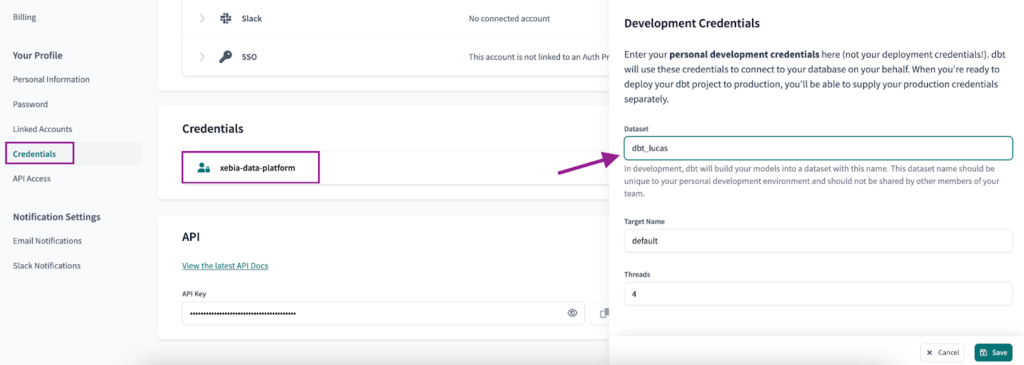
Von nun an sollte Ihr dbt-Projekt bereits mit zwei verschiedenen GCP-Projekten arbeiten. Jetzt müssen Sie nur noch Ihre Deployment-Pipeline für jede einzelne Umgebung einrichten.
Richten Sie Ihre Verteilungspipeline für jede Umgebung ein
Bearbeiten: Sie können die Schritte zur Einrichtung Ihrer Deployment-Pipeline in diesem neuen Artikel(CI/CD in dbt Cloud mit GitHub Actions: Automatisieren der Bereitstellung mehrerer Umgebungen).
Da es in diesem Artikel nicht um die besten Praktiken für die Einrichtung der Bereitstellung geht, werden wir nicht näher darauf eingehen. Einige allgemeine Tipps:
- Legen Sie einen Auftrag zur Ausführung der preprod Umgebung auszuführen, wenn ein Pull-Anfrage erstellt wird, in dbt Cloud.
- Folgen Sie diesem Link zur Einrichtung der prod Umgebung einzurichten, die ausgeführt wird, sobald der PR zusammengeführt wurde.
- Legen Sie einen Job zur Ausführung der prod Umgebung täglich in dbt Cloud auszuführen.
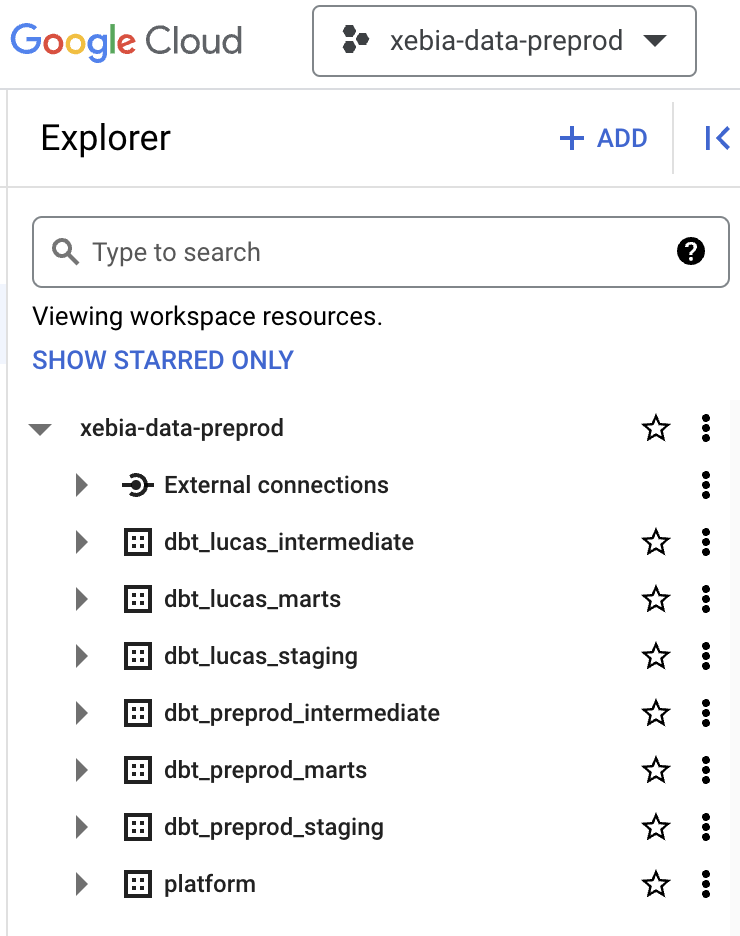
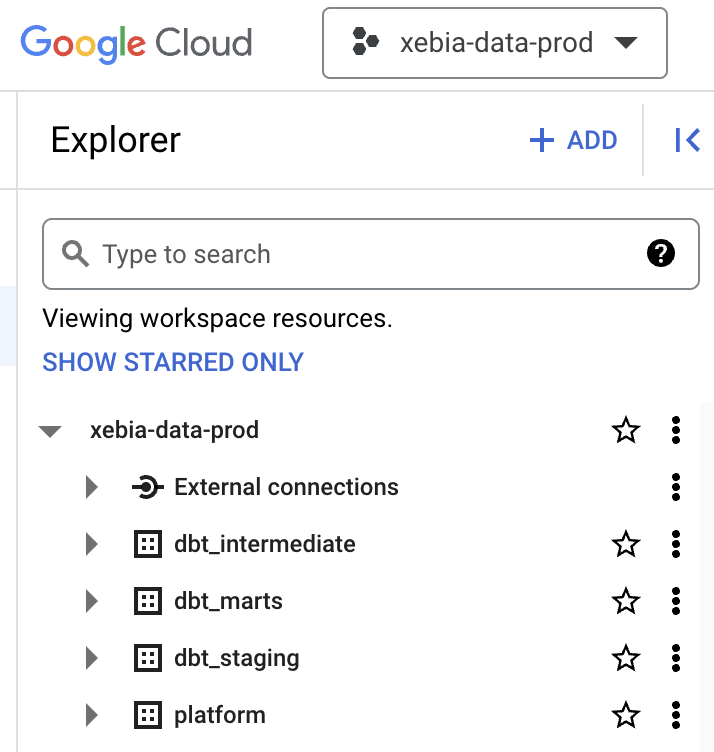
Nachdem Sie die Modelle für jede Umgebung und auch in der Develop IDE erstellt haben, sollten Sie zwei Projekte haben, die wie die folgenden Bilder aussehen:
Fazit
Durch die Implementierung dieser Einrichtung, mit einem einzigen dbt Cloud-Projekt und zwei separaten GCP-Projektenkönnen Sie eine bessere Wartbarkeit, Skalierbarkeit und Sicherheit für Ihre Datenplattform erreichen, und machen sie bereit für das Wachstum des Datenteams.
Mit mehreren Umgebungen und automatisierter Bereitstellung können Sie die verschiedenen Entwicklungs- und Produktionsphasen problemlos verwalten, das Fehlerrisiko verringern und den Zeitaufwand für manuelle Aufgaben minimieren. Auf diese Weise können Sie und Ihr Team sich mehr auf die Gewinnung wertvoller Erkenntnisse und Ergebnisse aus Ihren Daten konzentrieren und gleichzeitig den Zeit- und Arbeitsaufwand für Wartungs- und Verwaltungsaufgaben reduzieren.
Verfasst von
Lucas Ortiz
I've always been fascinated by technology and problem-solving. Great challenges are what keep me motivated, I rarely accept that a task can’t be done, it’s only a matter of finding new paths to solve the puzzle.
Unsere Ideen
Weitere Blogs




Contact