Blog
Überwachung von dbt-Modellen und Testausführungen mit Elementary Data

dbt ist ein großartiges Tool für Ihre Datentransformationen, das in modernen Datenstapeln auf der ganzen Welt weit verbreitet ist. Ich habe in den letzten zwei Jahren mit mehreren Kunden zusammengearbeitet, die bereits dbt verwenden oder ihre Transformationsaufgaben auf dbt umstellen. Die meisten Aspekte von dbt gefallen mir sehr gut, aber ein Problem, mit dem ich oft konfrontiert werde, ist das Fehlen von Überwachungsfunktionen in dbt. Ja, dbt liefert Protokolle an die stdout für jedes Modell und jede Testausführung, aber meiner Meinung nach reicht das nicht aus, um die gesamte Überwachung darauf aufzubauen. Diese Protokolle enthalten den Namen des Modells oder Tests, die Ausführungszeit und den Ausführungsstatus (bestanden, gewarnt oder fehlgeschlagen). Darüber hinaus zeigen die Protokolle auch die Anzahl der verarbeiteten Datensätze und Bytes pro Modellausführung und im Falle eines nicht bestandenen Tests die Anzahl der Datensätze, vor denen gewarnt wurde oder die fehlgeschlagen sind.
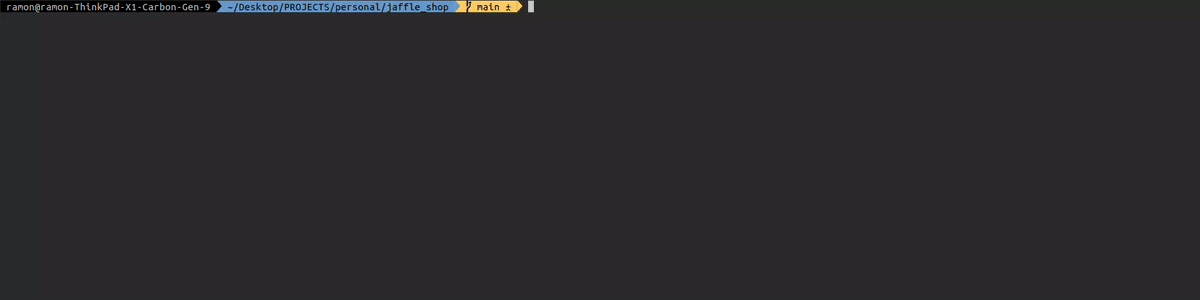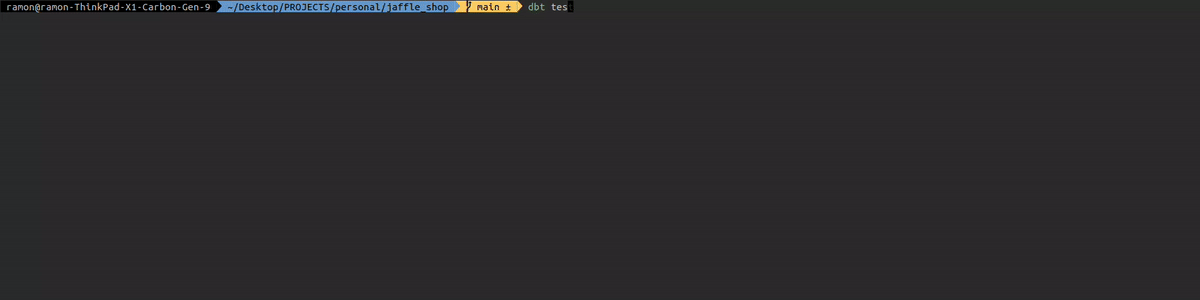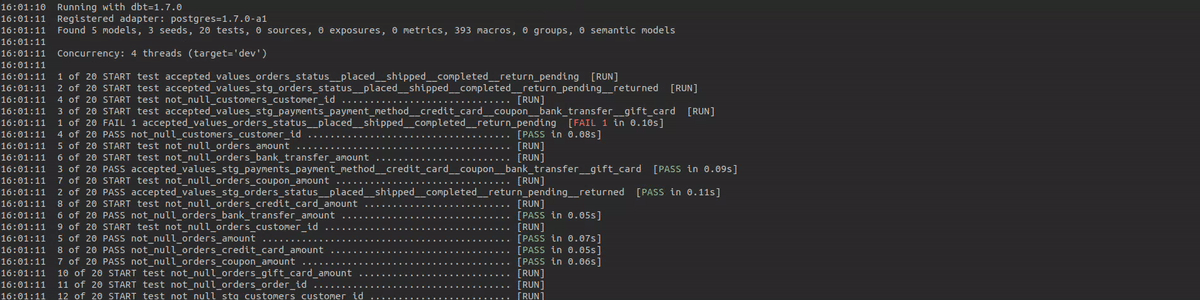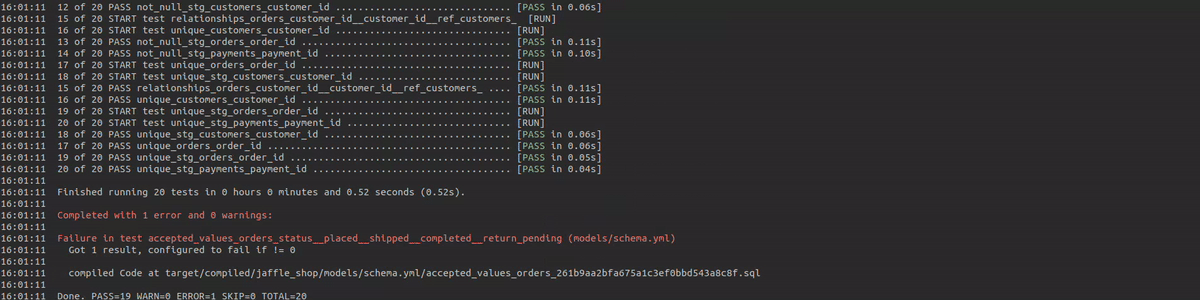
Dadurch erhalten Sie zwar einige Informationen auf hoher Ebene, aber es ist schwer festzustellen, welches SQL tatsächlich ausgeführt wurde und bei welchen Datensätzen genau ein Datenqualitätstest fehlgeschlagen ist oder eine Warnung ausgelöst hat. Die Protokolle enthalten lediglich Informationen über einen einzelnen Durchlauf, so dass Sie nicht ohne weiteres erkennen können, wie ein Test im Laufe der Zeit abschneidet. Meiner Meinung nach ist es sehr interessant zu sehen, wie sich die Datenqualität im Laufe der Zeit verbessert oder zurückentwickelt. Wenn Sie z.B. bestimmte Aktionen in den Quellsystemen durchführen (z.B. einen Datensatz mit Problemen reparieren), ist es schön zu sehen, welche Auswirkungen dies auf die gesamte Datenqualität hat.
Dies ist der Ort, an dem die dbt-Artefakte ins Spiel kommen. Immer, wenn dbt ausgeführt wird (z.B. wenn die Befehle dbt build | test | run | compile ausgeführt werden), generiert dbt einige so genannte Artefakte in Form von json-Dateien. Diese Artefaktdateien enthalten viele Metadaten und detailliertere Informationen über Ihr Modell und Ihre Testausführungen und können daher sehr nützlich sein. Diese Artefaktdateien werden im Verzeichnis ./target Ihres dbt-Projekts erzeugt.
Stellen wir uns vor, wir führen dbt als Container innerhalb eines Cloud-Ausführungsauftrag (eine Cloud-native Container-Laufzeitumgebung innerhalb von Google Cloud). Jeden Morgen, wenn alle Rohdaten eingelesen sind, starten wir über einen Trigger einen Container, um unsere tägliche Datenumwandlung mit dbt durchzuführen. Wenn jedoch die dbt-Arbeitslast beendet ist und der Container heruntergefahren wird, gehen diese Artefaktdateien, die viele aussagekräftige Informationen über die dbt-Aufrufe enthalten, verloren. Um dieses Problem zu lösen, ist es möglich, einen nachfolgenden Schritt in Form eines Skripts oder einer Anwendung zu entwickeln, um diese Artefaktdateien zu analysieren und sie irgendwo zu speichern. Dies erfordert jedoch eine Menge an kundenspezifischer Entwicklungsarbeit und ist keine leichte Aufgabe. Außerdem müssen Sie auf diesen Artefaktdaten ein Dashboard erstellen, um aussagekräftige Erkenntnisse daraus zu gewinnen.
Glücklicherweise gibt es dafür eine Open-Source-Lösung namens Elementare Daten .
Elementare Daten
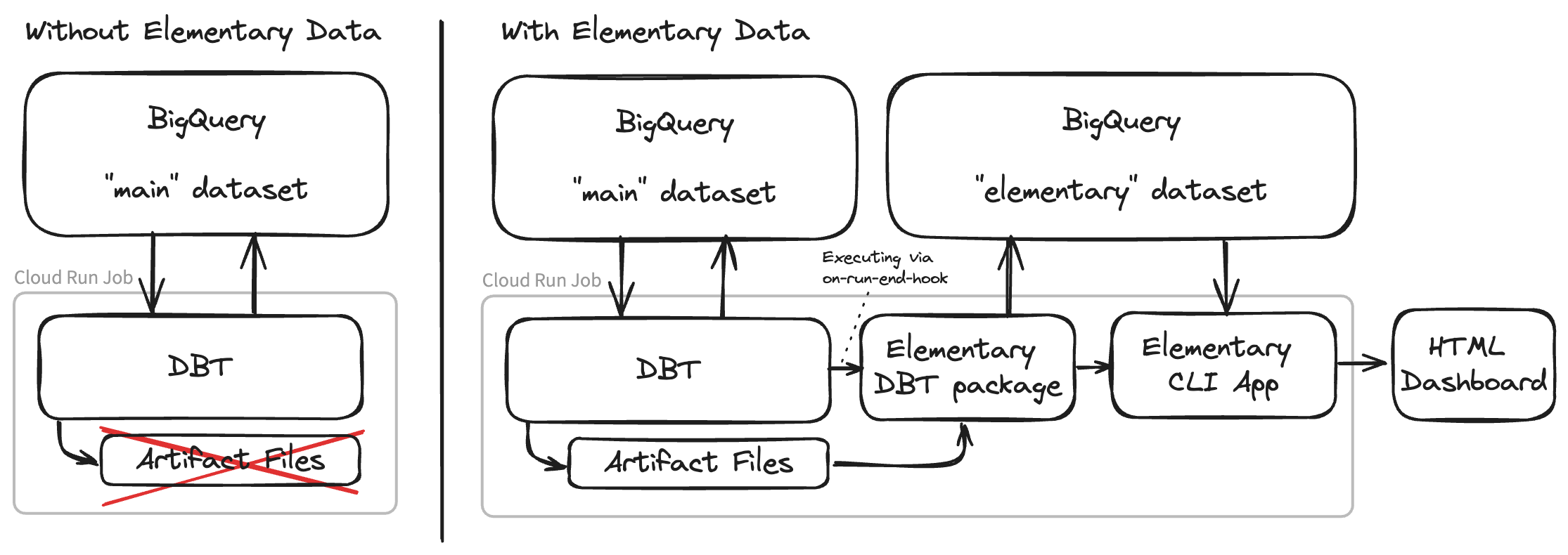
Elementary Data besteht aus zwei Komponenten, einem dbt-Paket und einer CLI-Anwendung. Das dbt-Paket nutzt den
Die CLI-Anwendung bietet eine Möglichkeit, ein vordefiniertes Dashboard aus den Daten Ihrer dbt-Artefakte zu erstellen. Das CLI-Tool fragt Ihre elementaren Tabellen im Warehouse ab und generiert ein aufschlussreiches Dashboard über die Zeit zu Ihrem dbt-Modell und Ihren Testausführungen. Dieses Dashboard liegt in Form einer einzigen HTML-Datei vor, die alle erforderlichen Daten in einem base64-kodierten json-String enthält. Sie können Elementary veranlassen, diese Dashboard-Datei automatisch in einen Objektspeicher wie GCS , S3 oder Azure Blob . Eine andere Möglichkeit ist, die Dashboard-Datei selbst auf einen Webserver hochzuladen. Dieses Dashboard bietet im Vergleich zu den Standard-Dbt-Protokollen sehr viel aufschlussreichere Informationen über Ihre dbt-Tests und Modellausführungen. Es bietet eine hervorragende Benutzeroberfläche und kann für Ihre tägliche Überwachung verwendet werden. So können Sie beispielsweise den Verlauf der Testausführung für einen einzelnen Test im Laufe der Zeit sehen und Anomalien erkennen. Es ist auch ein guter Ausgangspunkt für das Debugging von Datenqualitätsproblemen, da es eine einfache Möglichkeit bietet, das tatsächlich kompilierte SQL zu kopieren, das für einen bestimmten Test ausgeführt wurde.
 Klicken Sie
hier
um selbst mit dem Demo-Dashboard herumzuspielen
Klicken Sie
hier
um selbst mit dem Demo-Dashboard herumzuspielen
Eine der Funktionen, die ich an Elementarys Dashboard sehr schätze, ist die Möglichkeit, die kompilierte SQL-Abfrage für einen fehlgeschlagenen Datenqualitätstest mit nur einem Klick zu kopieren. Dies bietet großartige (und schnelle) Debugging-Möglichkeiten, da Sie diese Abfrage direkt in den Query Runner Ihres Data Warehouse einfügen können. Dies eröffnet Ihnen die Möglichkeit, sofort mit der Untersuchung der Ursache des Datenqualitätsproblems zu beginnen. Ohne Zugriff auf das kompilierte SQL müssen Sie allein anhand des Testnamens
Neben einem schönen Dashboard über Ihre dbt-Aufrufe bietet Elementary noch eine Menge weiterer Funktionen. Sie verfügen über eine Alarmierungslösung, die Warnungen an Slack
Einrichten von Elementary für Ihr dbt-Projekt
Das folgende Beispiel basiert auf dem Standard dbt jaffle_shop Projekt.
Der Jaffle-Shop ist ein fiktiver E-Commerce-Shop und wird in der dbt-Community häufig als Demoprojekt verwendet.
dbt-Plugin
Um das dbt-Paket zu installieren, fügen Sie das Folgende zu Ihrer packages.yml-Datei hinzu und führen Sie dbt deps aus, um die Abhängigkeiten zu installieren. Falls Sie noch keine packages.yml-Datei haben, können Sie eine im Stammverzeichnis Ihres dbt-Projekts erstellen.
packages:
- package: elementary-data/elementary
version: 0.13.1
Fügen Sie in Ihrer Datei dbtproject.yml die folgende Konfiguration hinzu, um das Paket zu aktivieren. Optional können Sie auch die Eigenschaft enabled angeben, um das Paket für eine bestimmte Umgebung zu aktivieren oder zu deaktivieren. Dem Schemanamen wird der Name des in Ihrer
models:
jaffle_shop:
materialized: table
staging:
materialized: view
elementary:
+schema: "elementary"
# enabled: "{{ target.name in ['prod', 'test'] }}"
Als nächstes müssen Sie die elementaren Modelle in Ihrem Lagerhaus erstellen. Dazu können Sie den folgenden Befehl ausführen.
dbt run --select elementary
Dadurch werden leere Tabellen und ein paar Ansichten erstellt. Diese Tabellen werden bei zukünftigen dbt-Ausführungen mit den Daten der Artefakte aktualisiert. Lassen Sie uns nun die Installation überprüfen, indem wir einige dbt-Tests durchführen und sehen, ob die Daten in die Tabellen eingefügt werden.
dbt test
Nachdem Sie einige Tests durchgeführt haben, werfen Sie einen Blick auf Ihre Tabelle elementary_test_results.
Sie sollten dort einige Daten sehen ️
CLI-Anwendung
Sie können die CLI-Anwendung installieren mit pip . Verwenden Sie zur Installation den folgenden Befehl:
pip install elementary-data
Als nächstes müssen Sie eine der zusätzlichen Abhängigkeiten für das von Ihnen verwendete Data Warehouse installieren. Die Optionen sind:
pip install 'elementary-data[snowflake]'
pip install 'elementary-data[bigquery]'
pip install 'elementary-data[redshift]'
pip install 'elementary-data[databricks]'
Nach diesem Schritt können Sie überprüfen, ob Ihre Installation erfolgreich war, indem Sie den folgenden Befehl ausführen. Falls edr nicht als Befehl erkannt wird, können Sie die Anleitung zur Fehlerbehebung von Elementary folgen.
edr --help
Fantastisch!
Sie haben das Paket Elementary dbt und die CLI-Anwendung erfolgreich installiert.
Jetzt können Sie Ihr erstes Elementary Dashboard erstellen. Dazu benötigen Sie eine profiles.yml-Datei, die eine Lesekonfiguration für Ihr Elementary-Schema enthält.
jaffle_shop:
target: dev
outputs:
dev:
type: postgres
host: 127.0.0.1
user: postgres
password: "1234"
port: 5432
dbname: jaffle_shop
schema: main
threads: 4
elementary:
target: elementary
outputs:
elementary:
type: postgres
host: 127.0.0.1
user: postgres
password: "1234"
port: 5432
dbname: jaffle_shop
schema: main_elementary
threads: 4
Sie können das Dashboard generieren, indem Sie den folgenden Befehl aus Ihrem dbt-Arbeitsverzeichnis ausführen. Weitere CLI-Optionen finden Sie in der CLI-Dokumentation .
edr report
--target-path <OUTPUT_PATH>
--profiles-dir <PROFILES_DIRECTORY>
Wenn Sie den Befehl ausführen, sehen Sie die folgende Ausgabe. Wenn Elementary beendet ist, wird das Dashboard automatisch in Ihrem Browser geöffnet.

Fazit
Elementary scheint eine großartige OSS-Lösung für die Beobachtung Ihrer dbt-Workloads zu sein. Es bietet eine Menge nützlicher Funktionen und ist einfach einzurichten. Es ist eine großartige Ergänzung für Ihr dbt-Projekt, und ich würde Ihnen auf jeden Fall empfehlen, es auszuprobieren. Es bietet eine hervorragende Schnittstelle zur Beobachtung Ihrer Datenqualität und zur sofortigen Behebung von Datenqualitätsproblemen. Darüber hinaus bietet es einige einzigartige Tests zur Erkennung von Anomalien und einen Datenkatalog. Leider hatte ich noch nicht die Gelegenheit, es in einer Produktionsumgebung auszuprobieren, aber ich habe definitiv vor, dies in Zukunft zu tun, um herauszufinden, ob es die meisten meiner Anforderungen an die Beobachtung von dbt erfüllt.
Bitte hinterlassen Sie mir eine Nachricht, wenn Sie Fragen oder Anmerkungen zu diesem Blogbeitrag haben.
Foto von Ibrahim Boran auf Unsplash
Verfasst von
Ramon Vermeulen
Cloud Engineer




Contact