Blog
Wie man mehrere Databricks Workspaces mit einem dbt Cloud-Projekt verwendet

Einführung
In einem früheren Blogbeitrag habe ich beschrieben wie Sie mehrere BigQuery-Projekte mit einem dbt Cloud-Projekt verwalten können . Auch wenn sich die Anleitung auf BigQuery konzentriert, kann das gleiche Konzept auch für andere Cloud-Anbieter angewendet werden. Für jeden gibt es jedoch spezifische Details, die die Einrichtung erschweren oder erleichtern können.
In diesem Artikel gehen wir die Schritte zur Einrichtung für Databricks durch, indem wir mehrere Databricks Workspaces mit einem einzigen dbt Cloud-Projekt verwenden.
Zusammenfassend lässt sich sagen, dass es aus 3 Hauptschritten bestehen wird:
- Erstellen und Einrichten der Databricks Workspaces: Wir werden zwei Arbeitsbereiche verwenden, einen für die Entwicklung und den anderen für die Produktion.
- Einrichten des Azure Service Principal: Wir wollen vermeiden Persönliche Token die mit einem bestimmten Benutzer verknüpft sind, so weit wie möglich vermeiden. Daher werden wir einen SP verwenden, um dbt bei Databricks zu authentifizieren.
- Erstellen und Einrichten des dbt Cloud-Projekts: Wir werden nur ein dbt Cloud-Projekt mit mehreren Umgebungen verwenden. Verwendung von Umgebungsvariablen ermöglichen es uns, die Verbindung zwischen verschiedenen Databricks Workspaces umzuschalten.
Databricks Arbeitsbereiche erstellen und einrichten
Hinweis: Wenn Sie bereits einen Databricks-Arbeitsbereich konfiguriert haben, können Sie diesen Abschnitt überspringen.
Für dieses Projekt werden wir Azure als Cloud-Anbieter verwenden. Alle Schritte würden auch bei einem anderen Anbieter funktionieren, mit einigen Anpassungen.
Zunächst müssen wir zwei Databricks Workspaces erstellen. Wir nennen sie daten-plattform-udev und data-platform-uprod .
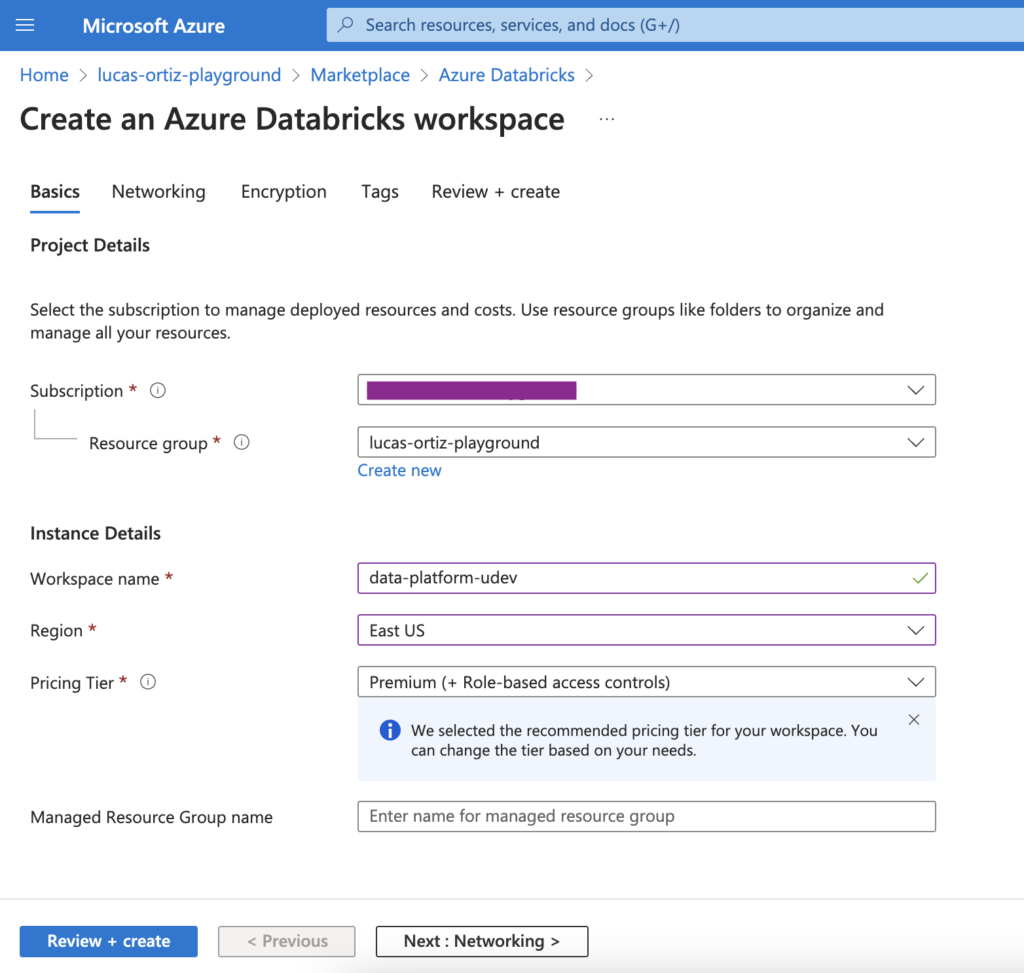
Sobald beide Arbeitsbereiche erstellt sind, öffnen wir beide. Dann müssen wir eine SQL-Warehouse Instanz, die Databricks verwenden wird, für jeden Arbeitsbereich.
Klicken Sie zunächst auf SQL-Warenhäuser in der linken Leiste, dann SQL-Warehouse erstellen Schaltfläche.

Daraufhin wird ein neues Fenster geöffnet. Hier können Sie die passenden Optionen für Ihren Anwendungsfall auswählen. Ich werde die Größen so klein wie möglich halten, da es nur für Demozwecke ist.
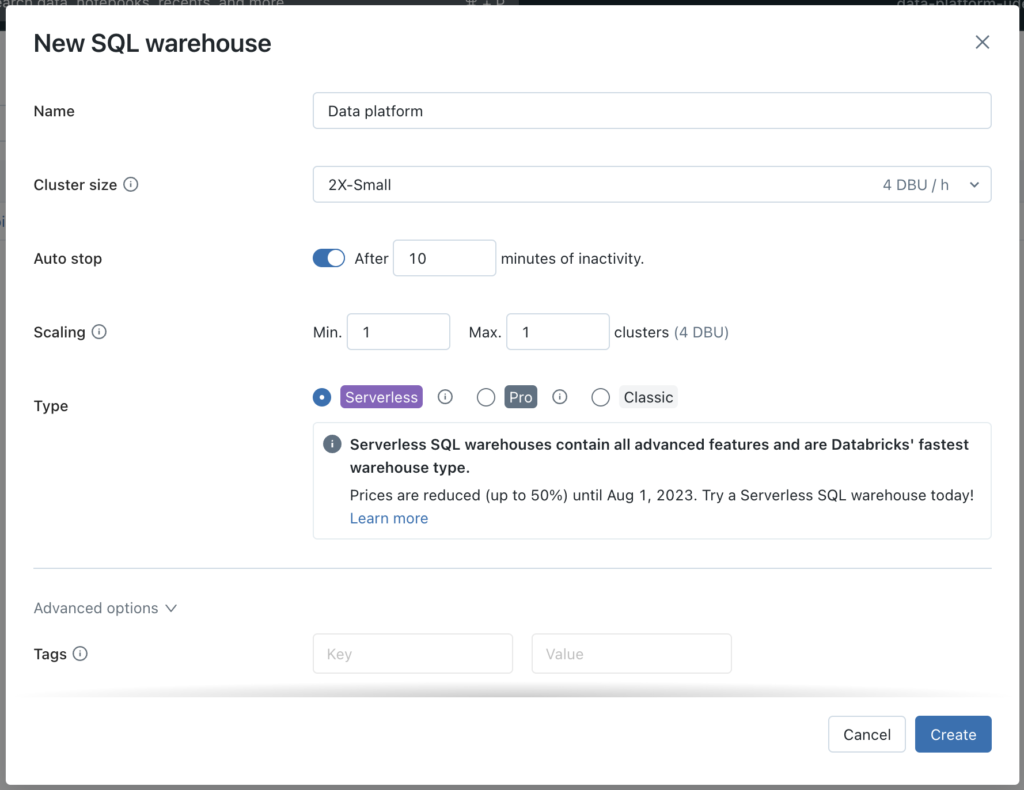
Nachdem wir nun unseren Databricks Workspace und die SQL Warehouse-Instanz konfiguriert haben, ist es an der Zeit, sich mit der Authentifizierung zu befassen.
Azure Service-Prinzipal einrichten
Wir möchten Zugriffstoken, die mit einem bestimmten Benutzer verknüpft sind, so weit wie möglich vermeiden. Auf diese Weise wird nichts kaputt gehen, wenn jemand das Unternehmen verlässt oder etwas anderes mit dem Konto passiert. Um dies zu ermöglichen, werden wir Folgendes verwenden Dienstprinzipien im Databricks Arbeitsbereich.
Um es einzurichten, navigieren Sie zunächst zum Azure Active Directory in Azure Portal und wählen Sie App-Registrierungen in der linken Leiste. Wir erstellen eine Neue Registrierung , indem Sie auf die Schaltfläche klicken.
Wir werden unsere Anwendung benennen als dbt-cloud nennen, damit wir wissen, wofür sie verwendet wird.
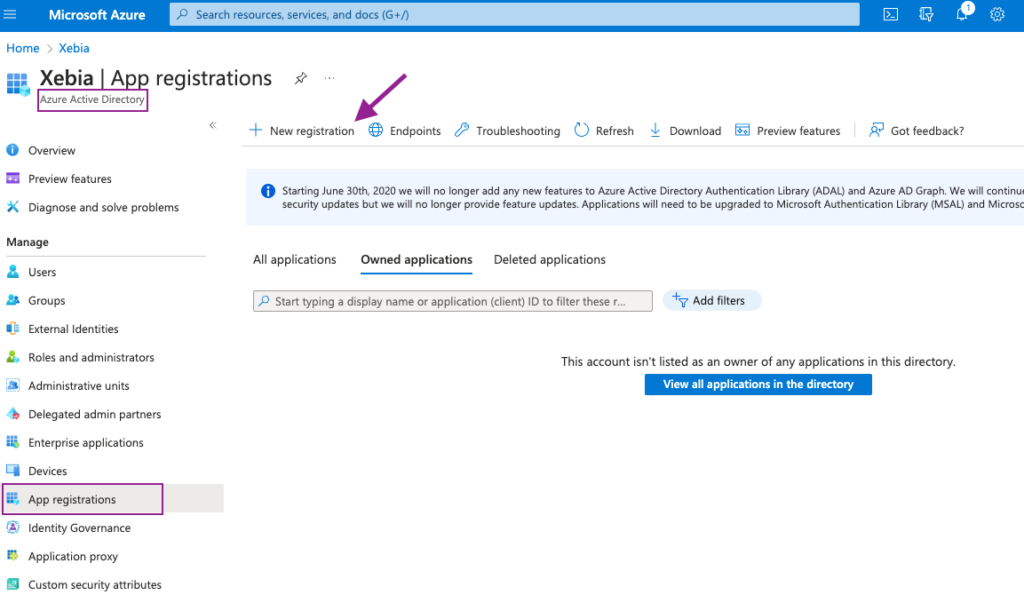
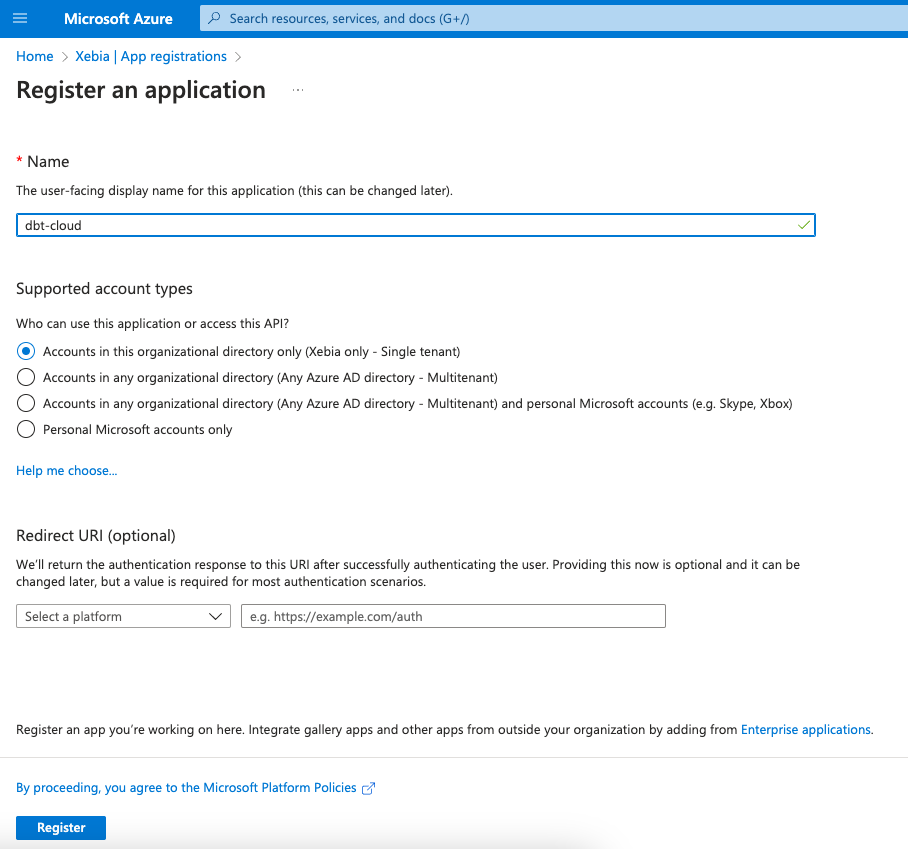
Sobald sie erstellt ist, werden wir zur Seite der neuen App weitergeleitet. Auf dieser Seite benötigen wir die Anwendungs-ID zu speichern (oder die Registerkarte geöffnet zu lassen).
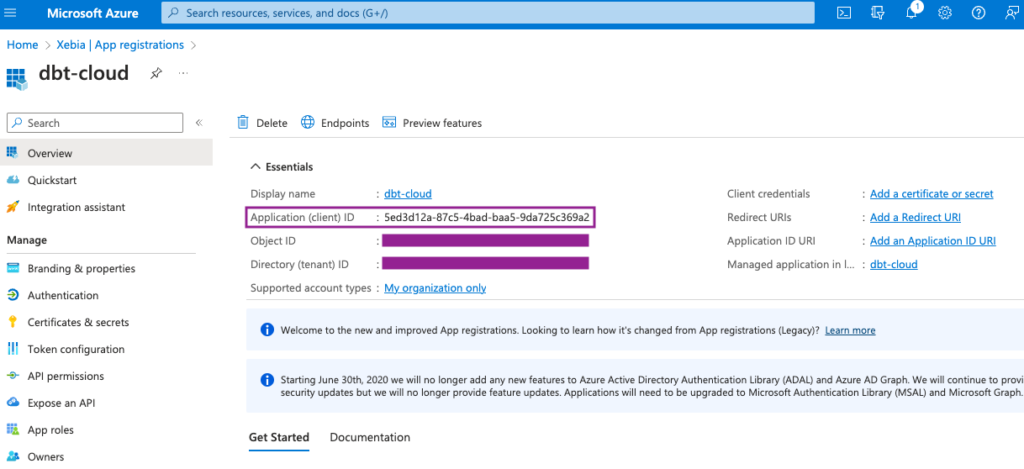
Der letzte Schritt bei der Einrichtung der Anwendung ist die Erstellung eines Client-Geheimnis . Es wird später verwendet, um unser Databricks Token für die Verbindung mit dbt zu generieren.
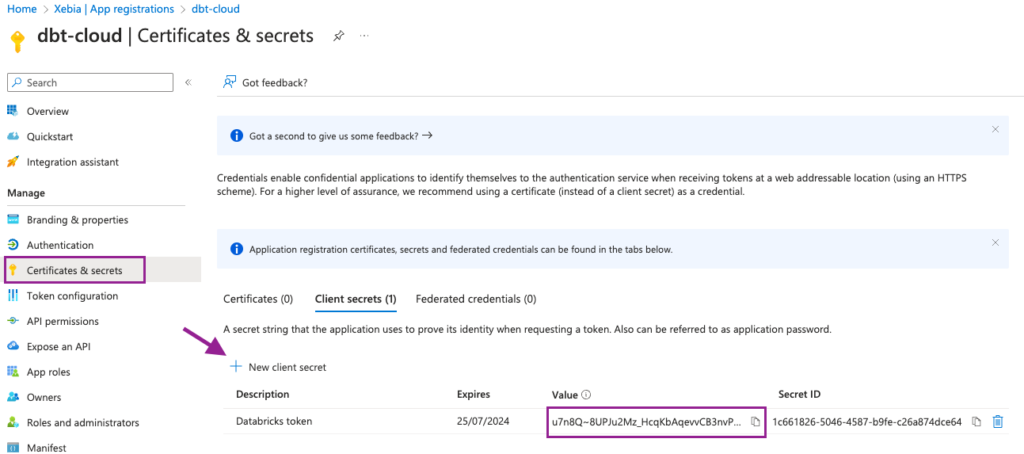
Um dies zu tun, navigieren wir zur Seite Zertifikate & Geheimnisse Seite und klicken auf Neues Kundengeheimnis . Fügen Sie eine passende Beschreibung und eine Verfallszeit hinzu.
Aus dem neuen Kundengeheimnis kopieren wir den Wert Feld und speichern es für einen späteren Schritt. Achtung: Das Wert wird Ihnen nur einmal angezeigt, speichern Sie ihn also unbedingt, sonst müssen Sie ein neues Kundengeheimnis .
Jetzt müssen wir nur noch den Dienstprinzipal zu unseren beiden Databricks Workspaces hinzuzufügen. Auf diese Weise können wir sie verwenden, um das Token für die Verbindung zu dbt zu generieren.
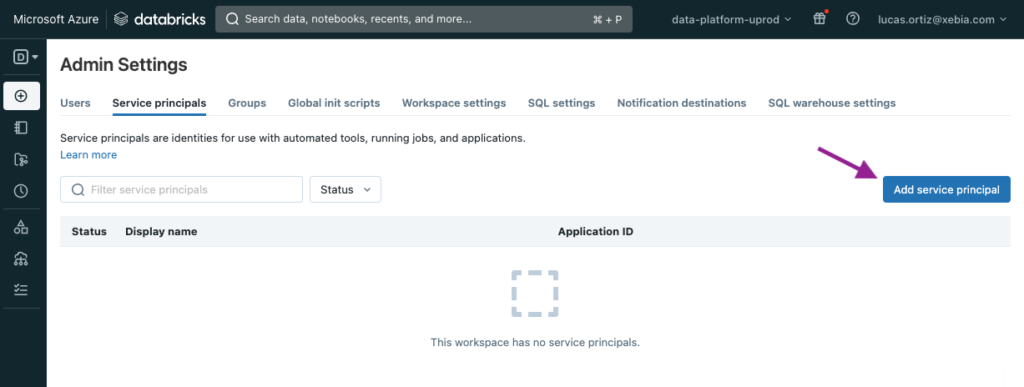
Navigieren Sie im Databricks-Arbeitsbereich zu Admin-Einstellungen > Dienstprinzipien .
Wir klicken auf Dienstprinzip hinzufügen um unsere kürzlich erstellte App zum Arbeitsbereich hinzuzufügen.
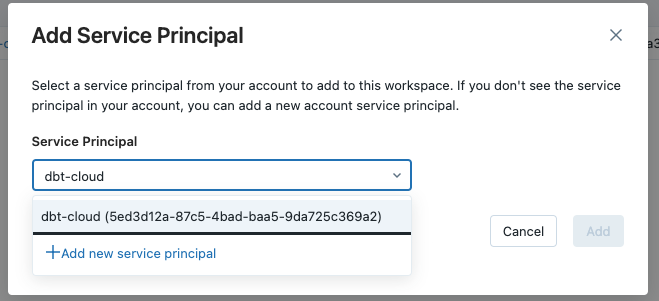
Ein neues Fenster wird geöffnet. Wir verwenden die Anwendung Id die wir in einem früheren Schritt kopiert haben. Wenn Sie die Datei nicht finden können Dienstvorgesetzter in der Dropdown-Liste, wählen Sie die Option Neuen Dienstprinzipal hinzufügen und fügen Sie die Option ApplicationId und einen geeigneten Namen anzeigen .
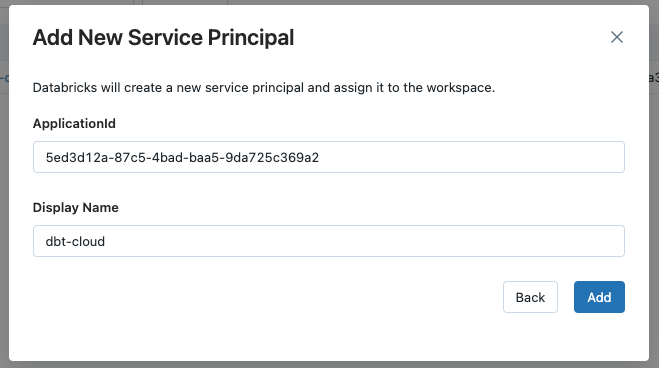
Jetzt, wo wir unseren Dienst-Prinzipal zum Arbeitsbereich hinzugefügt haben, müssen wir nur noch die richtigen Berechtigungen festlegen - zur Verwendung von Token und zur Änderung des Datenkatalogs.
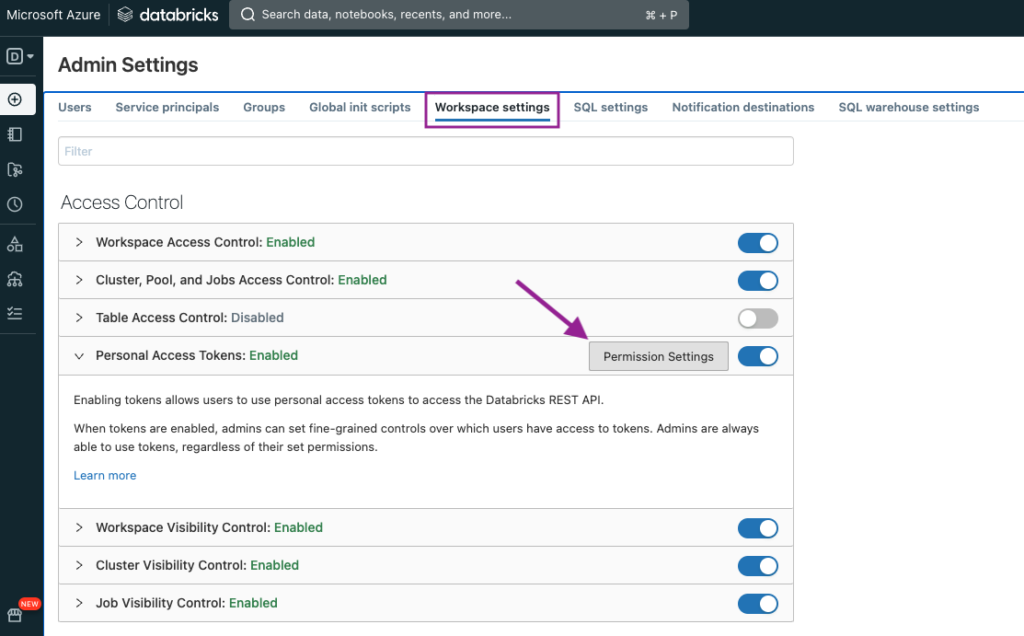
Standardmäßig, Dienstprinzipien dürfen keine Token verwenden. Um dies zu ändern, navigieren wir zu Arbeitsbereich-Einstellungen > Persönliche Zugriffstoken > Einstellungen für Berechtigungen .
Es wird ein neues Fenster geöffnet, in dem wir nach unserem Dienstprinzipal suchen und die Berechtigung Kann verwenden .
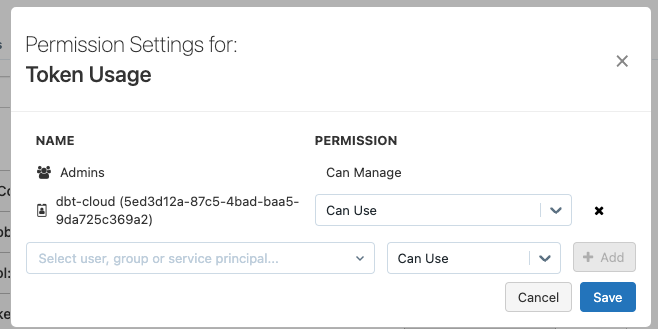
Schließlich geben wir den Service-Prinzipal Zugriff auf den Katalog, so dass er Schemata und Tabellen erstellen und ändern kann.
Wir navigieren zunächst zum Ordner Daten Seite, wählen den entsprechenden Katalog (Standard ist hive_metastore ), wählen Sie die Option Berechtigungen und klicken Sie auf Erteilen.
In dem sich öffnenden Fenster wählen wir den Namen des Dienstleiters aus und geben ihm Zugriff auf alle Berechtigungen.
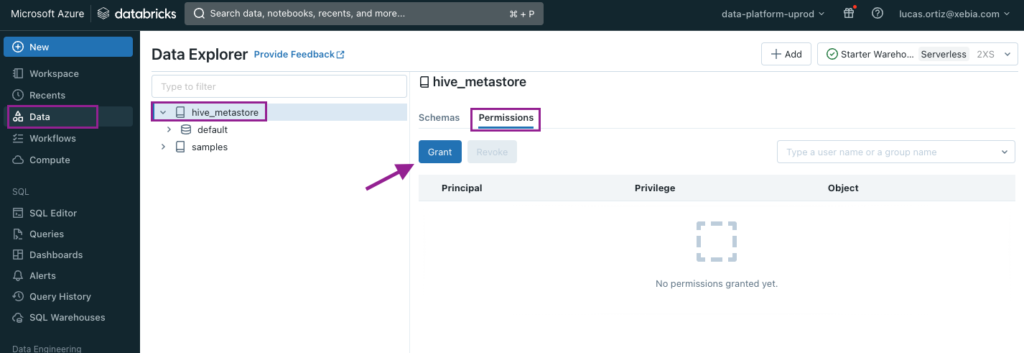
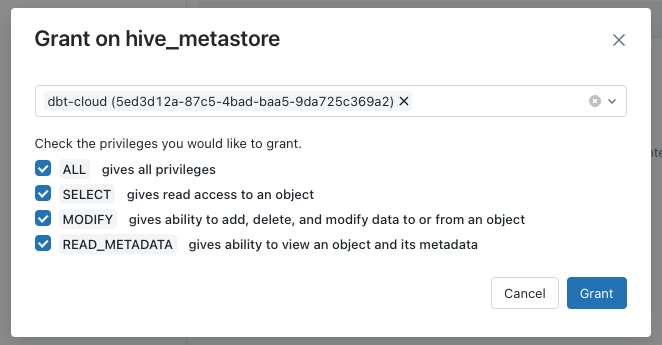
Stellen Sie sicher, dass Sie die letzten Databricks-Schritte auf beiden Workspaces ausführen - udev und uprod .
Erstellen Sie das dbt Cloud-Projekt
Auf der Seite der dbt Cloud beginnen wir mit der Erstellung unseres neuen Projekts.
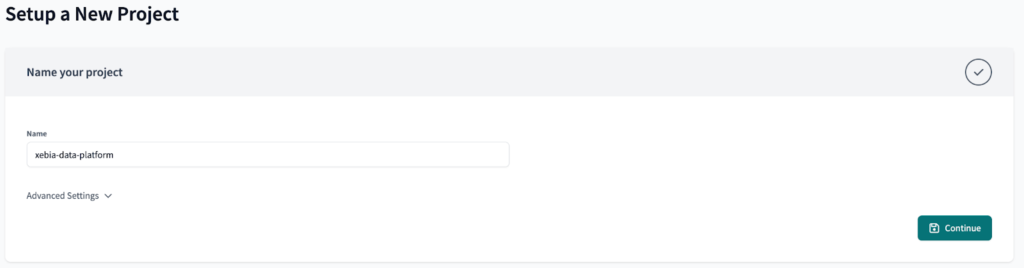
Zunächst werden wir die Verbindung zu Databricks nicht festlegen, da wir sie später aktualisieren müssten, um eine Umgebungsvariable und erzeugen Nacharbeit. Klicken Sie einfach auf die Überspringen Sie Schaltfläche für jetzt.
Sobald Sie dies getan haben, wird der nächste Schritt (Konfigurieren Sie Ihre Umgebung) automatisch übersprungen.
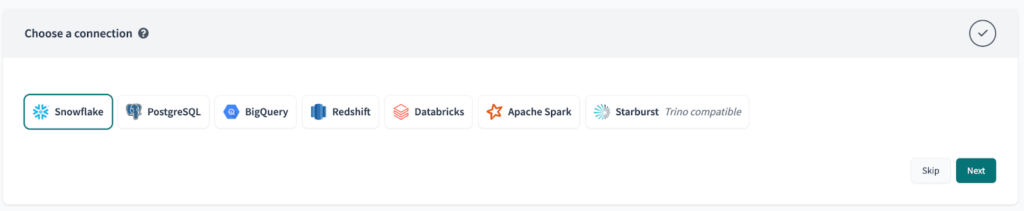
Zum Schluss richten Sie Ihr Repository mit Ihrer bevorzugten Git-Plattform ein.
Einrichten der Umgebungen und Umgebungsvariablen in dbt Cloud
Als nächstes werden wir drei Umgebungen erstellen: dev, preprod und prod. Dev ist eine Entwicklungsumgebung, während preprod und prod sind Einsatzumgebungen.
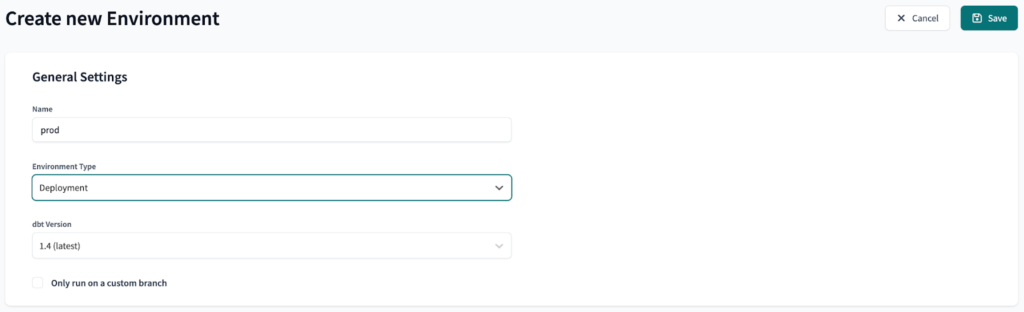
Das Endergebnis sollte wie folgt aussehen:
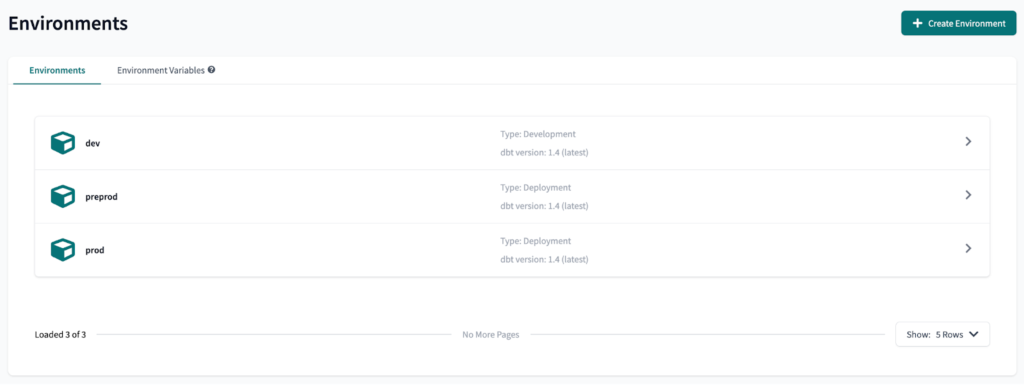
Der nächste Schritt ist die Erstellung von zwei Umgebungsvariablen . Dies ermöglicht uns die Verwendung der data-platform-udev Databricks Arbeitsbereich in der preprod dbt Cloud-Umgebung, und die data-platform-uprod Databricks-Arbeitsbereich in der prod dbt Cloud-Umgebung.
So erstellen Sie eine
Umgebungsvariable
zu erstellen, ist ziemlich einfach: auf der Seite
Umgebungen
Seite, wählen Sie
Umgebungsvariablen
und klicken Sie auf
Variable hinzufügen.
Wir werden die Variablen benennen DBT_DATABRICKS_HOST und DBT_DATABRICKS_HTTP_PATH.
Um die Werte der Variablen zu finden, müssen wir zum Databricks-Arbeitsbereich navigieren und dann das Fenster SQL-Warehouse die wir in den vorherigen Schritten erstellt haben. Unter Details zur Verbindungfinden wir beide Werte. Wir verwenden nicht den gesamten Wert, sondern nur den hervorgehobenen Teil.
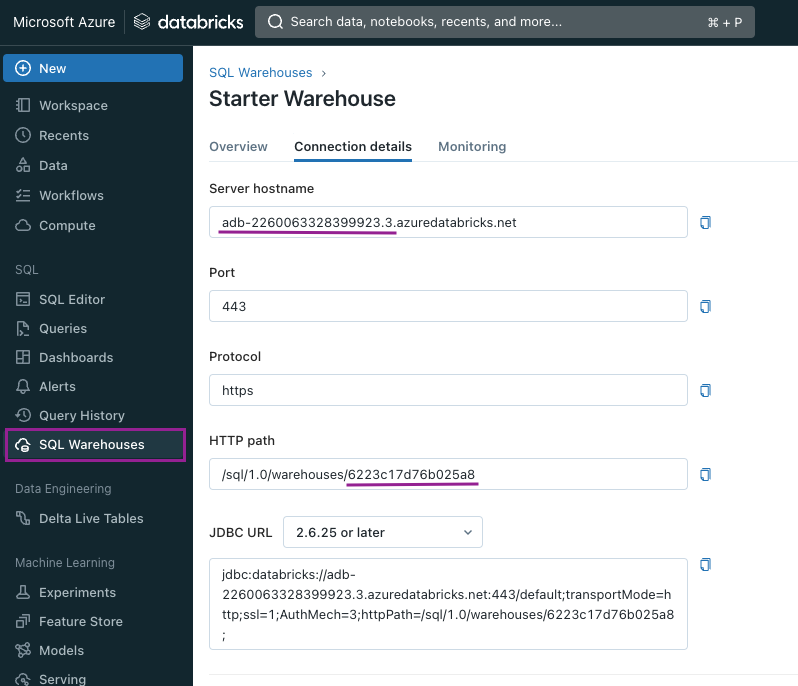
Zum Beispiel:
DBT_DATABRICKS_HOST = adb-2260063328399923.3
DBT_DATABRICKS_HTTP_PATH = 6223c17d76b025a8
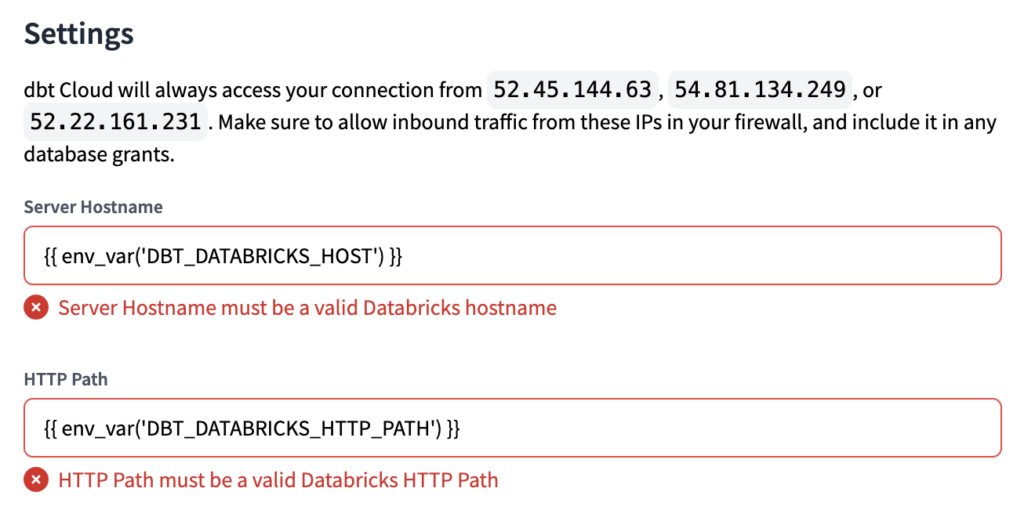
Wir müssen es so machen, dass wir nur einen Teil des Server-Hostname und HTTP-Pfad Werte, da dbt Cloud beim Einrichten der Verbindung eine Syntaxüberprüfung durchführt. Wenn wir die Variable als ganzen Wert festlegen und versuchen, beim Einrichten der Verbindung nur die Variable zu verwenden, erhalten wir einen Fehler.
Ein Beispiel für den Fehler, den Sie erhalten würden, sehen Sie in der Abbildung unten. Wenn es noch nicht klar ist, machen Sie sich keine Sorgen. Sobald wir die richtigen Werte eingestellt haben (in den nächsten Schritten), wird es klarer sein.
Das Endergebnis sollte wie folgt aussehen:
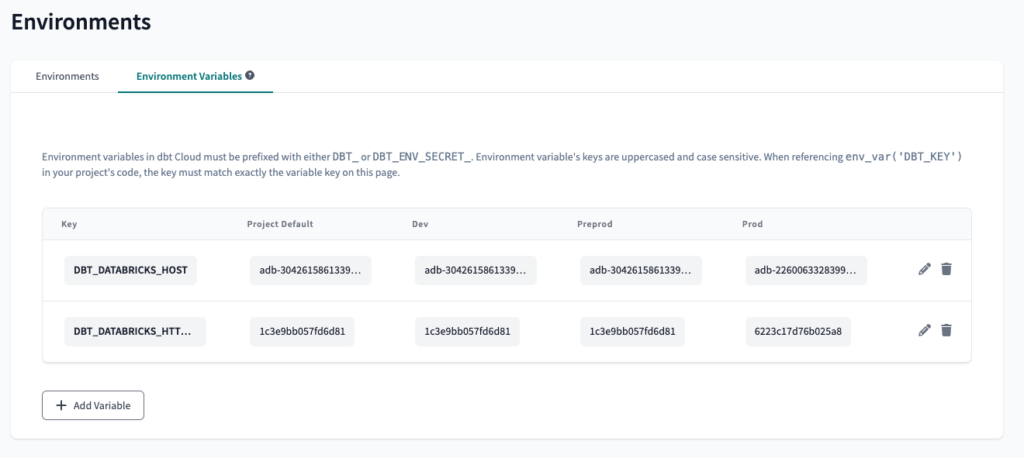
Da wir nur zwei Databricks Workspaces haben, verwenden wir die gleichen Werte für dev und preprod Es ist jedoch möglich, die gleiche Logik mit drei oder mehr Workspaces zu implementieren.
Sobald die Variablen gesetzt sind, können wir die Verbindung mit Databricks einrichten und die neu erstellten Variablen verwenden, um je nach verwendeter Umgebung zwischen den Workspaces zu wechseln.
Konfigurieren Sie die Verbindungsdetails in dbt Cloud
Um die Verbindung mit Databricks herzustellen, müssen wir zunächst zu den Kontoeinstellungen navigieren. Dort können wir alle unsere Projekte finden. Wir klicken auf das Projekt, das wir gerade erstellt haben, und dann auf Verbindung konfigurieren .
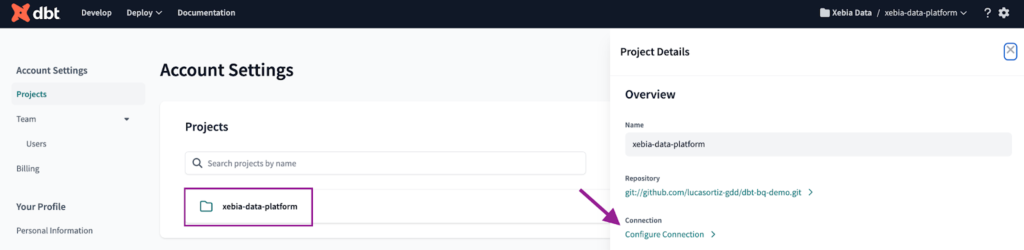
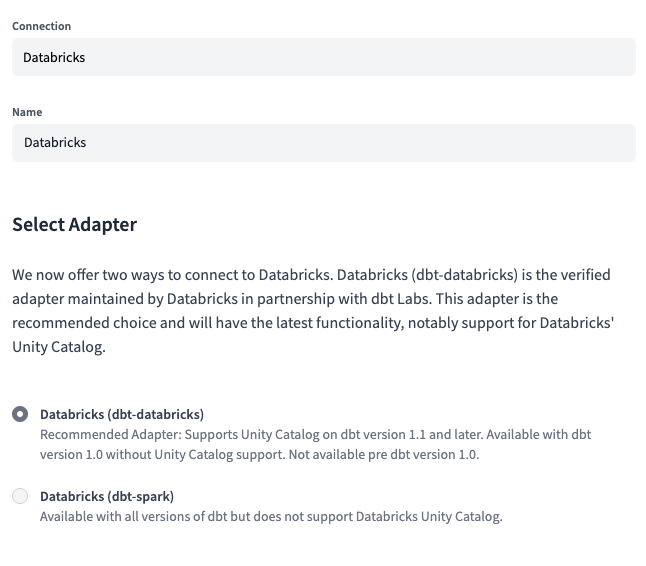
Der nächste Schritt ist die Einstellung des Verbindungstyps auf Databricks und wählen Sie dbt-databricks als Adapter.
Schließlich legen wir fest Server-Hostname und HTTP-Pfad Werte wie folgt fest:
Server Hostname = {{ env_var('DBT_DATABRICKS_HOST') }}.azuredatabricks.net
HTTP Path = /sql/1.0/warehouses/{{ env_var('DBT_DATABRICKS_HTTP_PATH') }}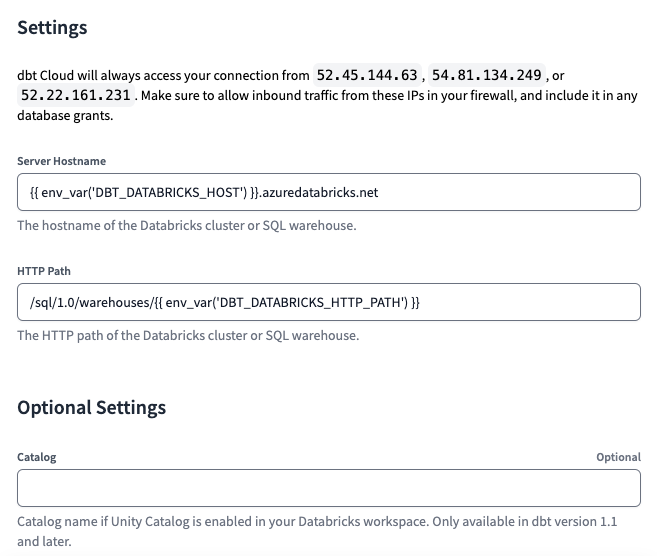
Hinweis: Wenn Sie den Unity-Katalog verwenden, ist es auch möglich, den Wert als Variable festzulegen. Um dies zu konfigurieren, müssen Sie im vorherigen Schritt eine dritte Variable erstellen und die entsprechenden Werte für jede Umgebung festlegen.
In einem weiteren Schritt werden wir die Entwickler-Berechtigungsnachweise . Navigieren Sie dazu zur Seite Berechtigungsnachweise Seite und wählen Sie das Projekt aus. Wir müssen eine Token und Schema . Für das Schema wählen Sie einfach einen eindeutigen Wert - in meinem Fall dbt_lucas.
Bei dem Token handelt es sich um ein persönliches Zugriffstoken (PAT), das für jeden Benutzer einzigartig ist. Wir können ein solches Token direkt im Databricks Workspace generieren ( udev ), indem Sie Benutzereinstellungen > Zugangs-Token > Neuen Token generieren
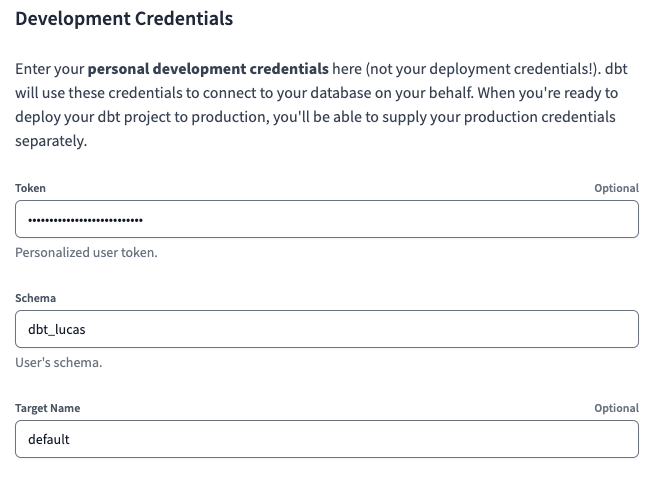
Einrichten von Deployment Credentials für jede Umgebung in der dbt Cloud
Ab jetzt haben wir den richtigen Server-Hostname und HTTP-Pfad für jede Umgebung festgelegt, indem wir Umgebungsvariablen . Wir setzen auch unsere Entwicklung Berechtigungsnachweiseso dass jeder Entwickler seine eigene Umgebung für die Entwicklung nutzen kann. Das einzige, was noch fehlt, ist die Authentifizierung für die Bereitstellungsumgebungen.
Um sie einzurichten, navigieren wir zunächst zur Seite Environments in dbt Cloud, wählen preprod und klicken auf bearbeiten. . Wenn Sie bis zum Ende der Seite scrollen, finden Sie die Berechtigungsnachweise für den Einsatz Abschnitt. Dort können wir eine Token und Schema . Für Letzteres verwenden wir dbt .
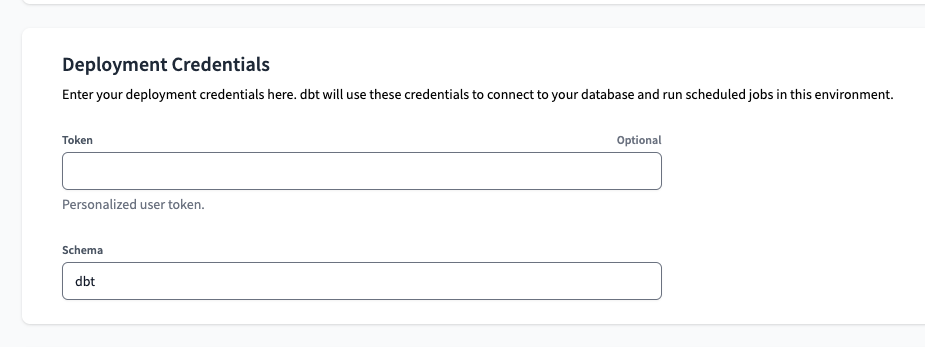
Um das Token ist ein bisschen komplizierter. Auch wenn die Schnittstelle sagt Personalisiertes Benutzer-Token , wollen wir vermeiden Persönliche Token die mit einem bestimmten Benutzer verbunden sind, so weit wie möglich vermeiden - das ist der Grund, warum wir ein Dienst-Prinzipal in den ersten Schritten dieses Beitrags. Zum Glück haben wir das schon von Anfang an bedacht, so dass es jetzt viel einfacher sein wird.
Leider gibt es bei Databricks keine Möglichkeit, ein Token für einen Dienst-Prinzipal direkt über die Benutzeroberfläche. Die einzige Möglichkeit, die uns bleibt, ist die Verwendung der APIs von Azure und Databricks, um das Token zu generieren. Wir werden ein Python-Skript verwenden. Stellen Sie also sicher, dass Sie es installiert haben und Python-Skripte ausführen können.
Um dieses Skript ordnungsgemäß auszuführen, benötigen wir die Tenant ID (Sie finden sie in Ihrem Azure-Portal), die Anwendungs-ID, den Client Secret Value und die Databricks URL. Ersetzen Sie die Werte entsprechend und führen Sie das Skript aus.
Der Token wird in Ihrer Konsole ausgegeben, wenn alles richtig eingestellt wurde.
# This script creates a Service Principal token for Databricks, with the duration of 1 year.
# First, it uses the Azure API to create a bearer token based on a Client secret from a Azure
# Active Directory App. This token has a maximum lifetime of 1 day. To make it live longer, we
# then use this token to create a token in Databricks, with a lifetime of 1 year.
import requests
import json
# Variables
tenant_id = '9e9c4a1a-0a3d-4d4e-8f2e-7f4f6d5e6d7c'
application_id = '3c5b6a9b-1a2b-4c3d-5e6f-7g8h9i0j1k2l'
client_secret_value = 'qQt8Q~FQEptp1kv5-RUJNagwumzSPLfriPigqa41'
databricks_url= 'https://adb-123456789.0.azuredatabricks.net'
# Create an Azure Active Directory token. To do so, we use the Azure API, with the Tenant Id,
# Application Id and Client secret value. The last two can be obtained by creating an App under Azure
# Active Directory.
def get_aad_token(tenant_id, application_id, client_secret_value):
url = f'https://login.microsoftonline.com/{tenant_id}/oauth2/v2.0/token'
payload = f'client_id={application_id}&client_secret={client_secret_value}&grant_type=client_credentials&scope=2ff814a6-3304-4ab8-85cb-cd0e6f879c1d/.default'
response = requests.post(url, data=payload)
aad_token = json.loads(response.text)['access_token']
return aad_token
# Create a Databricks token. We use the Databricks API, with our Databricks URL and the AAD
# token obtained from the get_aad_token() function.
def create_databricks_token(databricks_url, aad_token):
expiration_years = 1
url = f'{databricks_url}/api/2.0/token/create'
payload = json.dumps({
'lifetime_seconds': 60 * 60 * 24 * 365 * expiration_years,
'comment': 'blog post'
})
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {aad_token}'
}
response = requests.post(url, headers=headers, data=payload)
response_json = json.loads(response.text)
token_value = response_json['token_value']
return token_value
# Call the functions
aad_token = get_aad_token(tenant_id, application_id, client_secret_value)
token_value = create_databricks_token(databricks_url, aad_token)
# Print the token
print(token_value)
Der Token wird in etwa so aussehen dapi0fafa34d3b9g012962d34e7ba5dd62c44-3. Sobald Sie ihn haben, setzen Sie diesen Wert einfach als Token in Ihren Deployment Credentials-Wert.
Wiederholen Sie die gleichen Schritte in diesem Abschnitt für die Prod Umgebung, und vergessen Sie nicht, die Option databricks_url in das Python-Skript ein und führen Sie es erneut aus. Das Token ist für jede Umgebung unterschiedlich.
Richten Sie Ihre Deployment Pipeline für jede Umgebung ein
Von nun an sollte Ihr dbt-Projekt bereits mit zwei verschiedenen Databricks Workspaces arbeiten. Jetzt müssen Sie nur noch Ihre Deployment-Pipeline für jede einzelne Umgebung einrichten.
Sie können die Schritte zum Einrichten Ihrer Deployment-Pipeline in diesem Artikel nachlesen ( CI/CD in der dbt Cloud mit GitHub-Aktionen: Automatisieren der Bereitstellung mehrerer Umgebungen ).
Nachdem Sie die Modelle für jede Umgebung erstellt haben, sollten Sie auch in der Develop IDE zwei Arbeitsbereiche haben, die wie die folgenden Bilder aussehen:
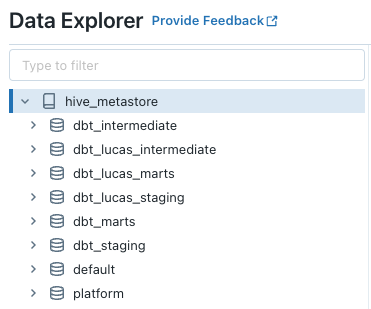
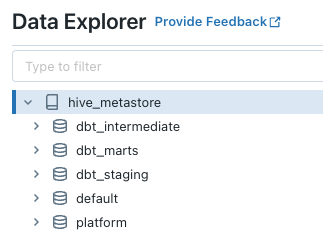
Fazit
Databricks ist ein großartiges Tool, das eine einheitliche Analyseplattform bietet, die Data Engineering, Data Science und Business Analytics kombiniert. Es bietet eine kollaborative Umgebung für die Zusammenarbeit von Teams und beschleunigt die Entwicklung und den Einsatz von datengesteuerten Lösungen. Mit seinen leistungsstarken Verarbeitungsfunktionen und seiner Skalierbarkeit ermöglicht es Databricks Unternehmen, schneller und effizienter wertvolle Erkenntnisse aus ihren Daten zu gewinnen.
Durch die Implementierung dieses Setups mit mehreren Databricks Workspaces und einem dbt-Cloud-Projekt können Sie eine größere Wartungsfreundlichkeit, Skalierbarkeit und Sicherheit für Ihre Datenplattform erreichen und sie für das Wachstum des Datenteams bereit machen.
Verfasst von
Lucas Ortiz
I've always been fascinated by technology and problem-solving. Great challenges are what keep me motivated, I rarely accept that a task can’t be done, it’s only a matter of finding new paths to solve the puzzle.
Unsere Ideen
Weitere Blogs




Contact