Blog
Aufbau eines stabilen öffentlichen Netzwerks auf AWS: Teil 4

Regionale Evakuierung mit statischem Anycast-IP-Ansatz
Willkommen zurück zu unserer umfassenden Blog-Serie "Building Resilient Public Networking on AWS", in der wir uns mit fortschrittlichen Netzwerkstrategien für regionale Evakuierung, Failover und robuste Disaster Recovery beschäftigen. Hier finden Sie eine Zusammenfassung unserer bisherigen Reise:
- Networking-Konzepte aus der Sicht des Kunden neu betrachten: Wenn Sie unsere grundlegenden Netzwerkkonzepte in der ersten Folge verpasst haben, können Sie sie hier nachholen hier . Wir haben die Grundlagen für unsere Gespräche festgelegt.
- Sichere öffentliche Web-Endpunkte bereitstellen: Wir haben uns mit der Bereitstellung eines Webservers und der Sicherung seines öffentlichen Endpunkts auf AWS beschäftigt, einschließlich DNS-Verwaltung mit Route 53 und Integration mit DNS-Hosting-Anbietern von Drittanbietern. Finden Sie den detaillierten Leitfaden hier.
- Evakuierung der Region mit DNS-Ansatz: In unserem dritten Beitrag haben wir die Bereitstellung von Webserver-Infrastrukturen über mehrere Regionen hinweg besprochen und den Ansatz der regionalen DNS-Evakuierung mit AWS Route 53 überprüft. Erforschen Sie die Details hier .
- Evakuierung von Regionen mit einem statischen Anycast-IP-Ansatz: In diesem vierten Blog-Beitrag werden wir die Webserver-Infrastruktur über mehrere Regionen hinweg bereitstellen und die Evakuierung von Regionen mithilfe von AWS Global Accelerator mit einem statischen Anycast-IP-Ansatz untersuchen. Wir werden die Vorteile und Überlegungen dazu untersuchen.
- Persistente TCP-Verbindungen des Clients und warum dies ein Problem sein könnte: Zum Abschluss unserer Serie befassen wir uns mit dem üblichen Verhalten von HTTP-Clients - persistenten TCP-Verbindungen. Verstehen Sie, warum die Vernachlässigung dieses Themas zu einem möglichen Scheitern der zuvor besprochenen Ansätze führen kann.
Außerdem haben wir für Sie ein GitHub-Repository zur Ergänzung dieser Blogserie . Es bietet Infrastructure as Code (IaC) unter Verwendung von AWS Cloud Development Kit (CDK), so dass Sie die erforderliche Infrastruktur mühelos bereitstellen und verwalten können.
Einführung
In diesem vierten Blog-Beitrag setzen wir unsere Reise fort, indem wir unsere Webserver-Infrastruktur über mehrere Regionen (us-east-1 und us-west-2) hinweg bereitstellen. Dabei konzentrieren wir uns auf die Evakuierung von Regionen mithilfe des statischen Anycast-IP-Ansatzes, der von AWS Global Accelerator bereitgestellt wird.
Wir werden Infrastructure as Code (IaC) verwenden, und den entsprechenden Code für diesen Blogbeitrag finden Sie hier . Für diejenigen, die neu bei AWS CDK sind oder eine Auffrischung benötigen, empfehlen wir, mit diesem Leitfaden zu beginnen "Erste Schritte mit dem AWS CDK" .
Wir werden die Vor- und Nachteile dieser Technik untersuchen und sie mit dem Ansatz zur Evakuierung von DNS-Regionen mithilfe von Route 53 vergleichen, den wir in unserem vorherigen Blog-Beitrag . Wir werden auch sehen, wie diese neue Methode die meisten der Nachteile überwinden kann, die wir bei dem bisherigen Ansatz festgestellt haben.
Kommen wir ohne Umschweife zur Sache!
Überblick über die Architektur
Das nebenstehende Diagramm stellt die Architektur unserer Infrastruktur visuell dar und hebt die Beziehungen zwischen den wichtigsten Komponenten hervor. Während die CDK-Stacks die Infrastruktur innerhalb der AWS Cloud bereitstellen, erfordern externe Komponenten wie der DNS-Anbieter (ClouDNS) manuelle Schritte. Diese Schritte sind in dem folgenden Diagramm deutlich markiert.
Einer der wichtigsten Unterschiede zwischen dem Ansatz in diesem Beitrag und dem vorherigen Beitrag ist, dass die Application Load Balancer (ALBs) hier privat sind, so dass das einzige Element, das direkt dem Internet ausgesetzt ist, der Global Accelerator und seine Edge-Standorte sind.
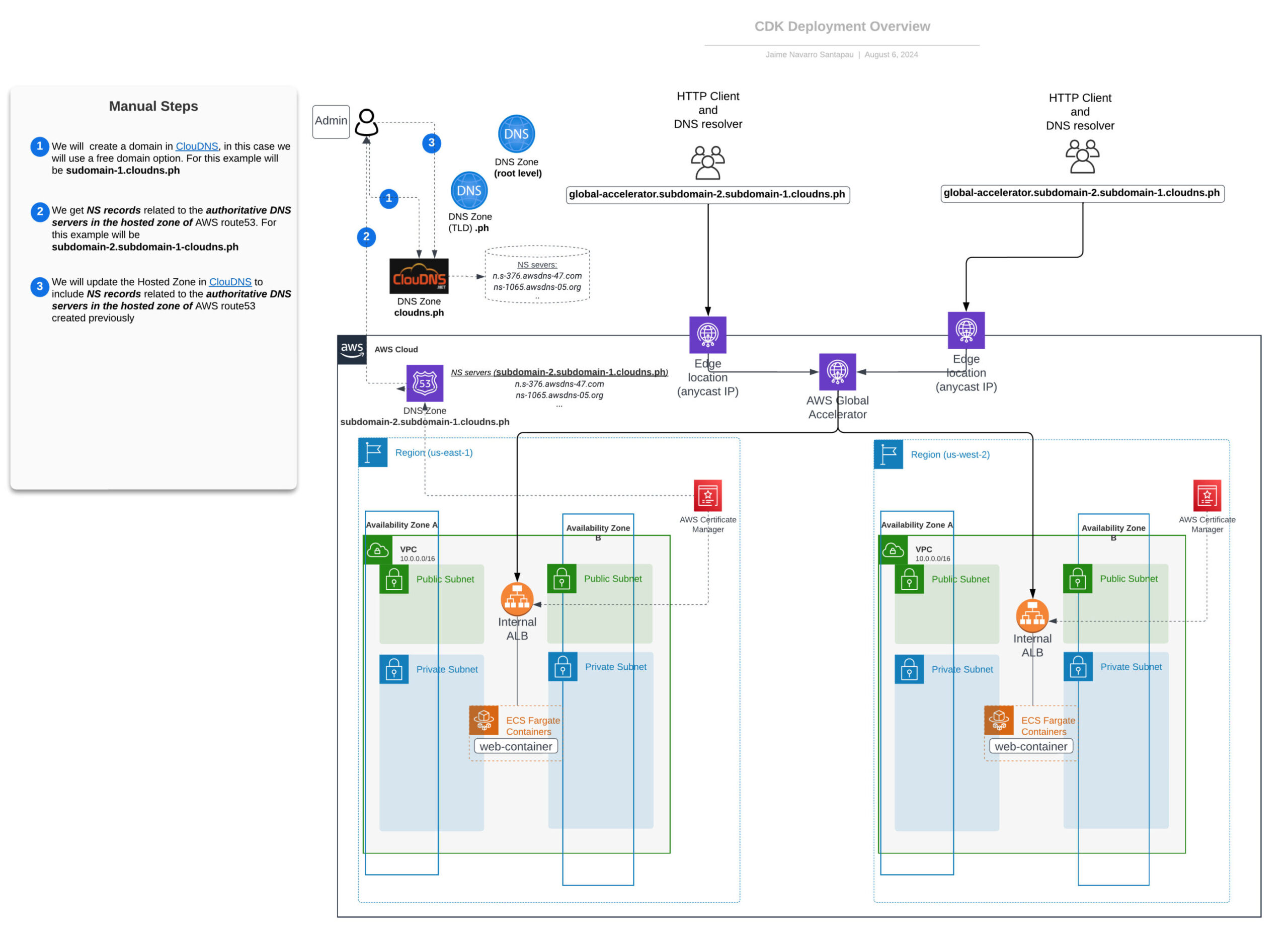
Netzwerkübersicht - Statische Anycast IP mit Global Accelerator
AWS Global Accelerator bietet zwei statische Anycast-IPs. Eine Anycast-IP ist eine Netzwerkadressierungs- und Routing-Methode, bei der eine einzige IP-Adresse von Servern an mehreren Standorten, den sogenannten Edge-Standorten, gemeinsam genutzt wird. Router leiten Pakete, die an diese IPs adressiert sind, unter Verwendung ihrer normalen Entscheidungsalgorithmen an den nächstgelegenen Standort weiter, in der Regel die niedrigste Anzahl von Netzwerksprüngen.
Diese Einrichtung stellt sicher, dass die Clients immer über den nächstgelegenen AWS Edge-Standort eine Verbindung zu unserer Anwendung herstellen. Vom Edge-Standort aus wird die TCP-Verbindung innerhalb des AWS-Netzwerks hergestellt, wodurch die Anzahl der Sprünge und folglich die Latenz für diese Verbindung verringert wird.
In diesem Abschnitt erläutern wir, wie AWS Global Accelerator statische Anycast-IPs verwendet, um den Benutzerverkehr je nach Zustand und Netzwerkbedingungen an den optimalen regionalen Endpunkt zu leiten. Das beigefügte Diagramm veranschaulicht den durch diese Einrichtung verbesserten Verkehrsfluss.
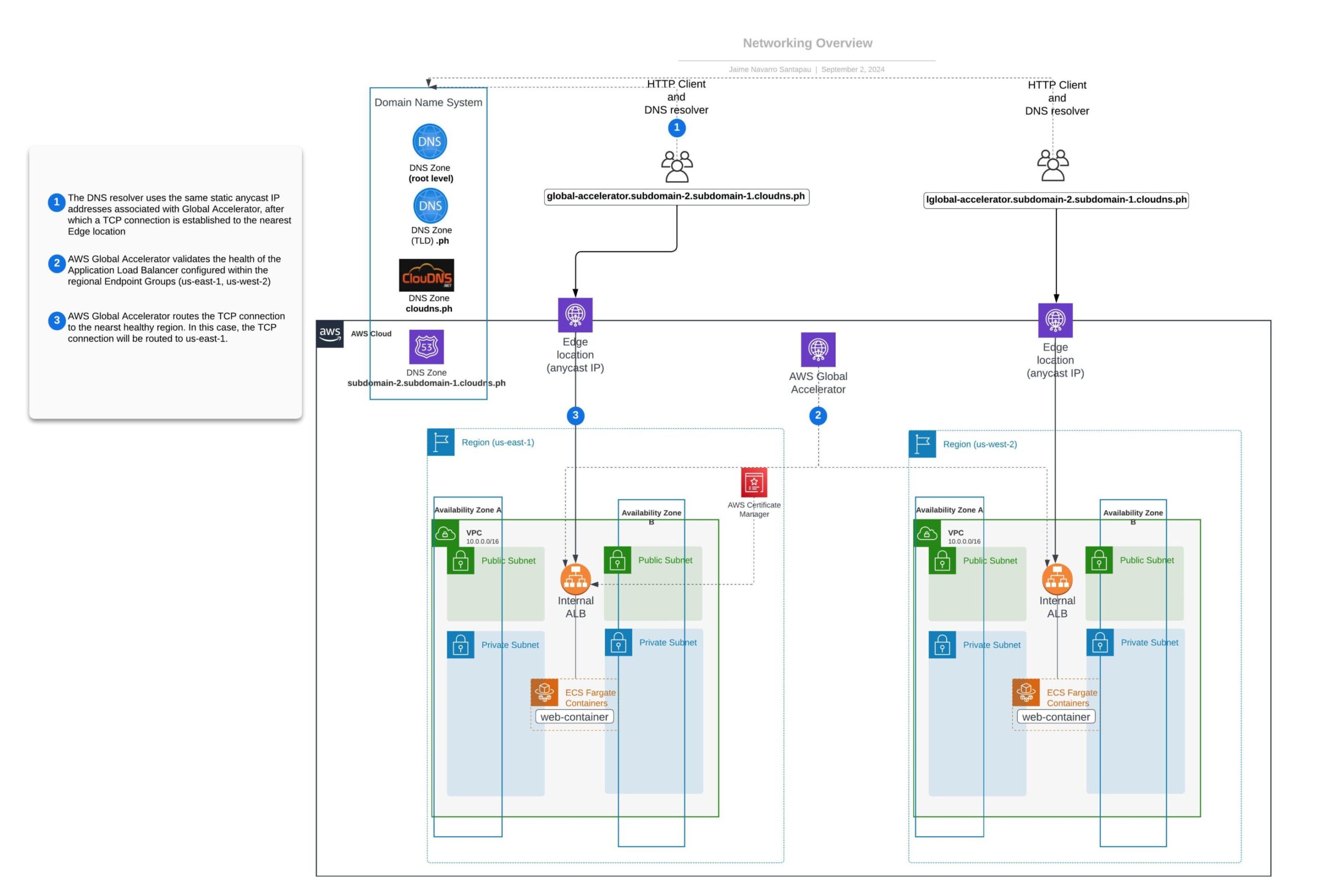
Implementierungsschritte und Validierungen
Im weiteren Verlauf dieser Blogpost-Serie bauen wir auf dem Wissen und den Erkenntnissen aus früheren Posts auf. Daher wird die schrittweise Anleitung zur Bereitstellung und Validierung hier weggelassen. Sie können jedoch auf diese Anleitung zugreifen, indem Sie dem Link Leitfaden für Implementierungsschritte und Validierungen Link in unserem GitHub-Repository.
Regionale Evakuierung mit statischem Anycast-IP-Ansatz unter Verwendung von Global Accelerator
Nach der Bereitstellung der erforderlichen Infrastruktur anhand der bereitgestellten Richtlinien zeigen wir ein grundlegendes Beispiel für die Evakuierung einer Region (in diesem Fall us-east-1) mit AWS Global Accelerator.
Es gibt verschiedene Ansätze, um eine Region mit AWS Global Accelerator zu evakuieren. Aber um dieses Beispiel so einfach wie möglich zu halten, verwenden wir eine integrierte Funktion von AWS Global Accelerator, der den Datenverkehr an die gesunden Endpunkte weiterleitet .
In den folgenden Abschnitten werden wir dieses Beispiel für die Evakuierung einer Region Schritt für Schritt durchgehen.
Schritt 1 - Prüfen Sie, welches Ihre nächstgelegene AWS-Region ist
Bevor Sie einen Ausfall simulieren, müssen Sie die nächstgelegene AWS-Region ermitteln. Dieser Schritt stellt sicher, dass Ihre TCP-Verbindungen zu einer gesunden Region umgeleitet werden. So können Sie überprüfen, ob der Prozess der Evakuierung der Region wie erwartet funktioniert.
Um Ihre nächstgelegene Region zu ermitteln, können Sie den folgenden curl-Befehl verwenden, der eine Anfrage an den AWS Global Accelerator sendet und die Region zurückgibt, an die Ihre Anfrage weitergeleitet wird:
curl https://global-accelerator.subdomain-2.subdomain-1.cloudns.ph
{
"MessageResponse": "Region: us-east-1. HTTP Response code: 200. Delay response: 0 seconds.",
"SocketRequest": "::ffff:10.0.182.85:18630",
"HeadersRequest": {
"x-forwarded-for": "188.26.219.81",
"x-forwarded-proto": "https",
"x-forwarded-port": "443",
"host": "global-accelerator.subdomain-2.subdomain-1.cloudns.ph",
"x-amzn-trace-id": "Root=1-66d47933-0264d457365086415ea1c500",
"user-agent": "curl/8.7.1",
"accept": "*/*"
},
"HeadersResponse": {
"x-powered-by": "Express"
}
}Da wir in Europa ansässig sind, wird in diesem Beispiel die nächstgelegene Region als us-east-1 identifiziert. Deshalb werden wir im nächsten Schritt einen Ausfall in dieser Region simulieren.
Schritt 2 - Simulieren des Ausfalls (us-east-1)
Um einen Ausfall in einer Region zu simulieren, halten wir die Container in dieser Region an (in unserem Fall ist es us-east-1). Infolgedessen wird unser ALB ungesund und gibt einen HTTP 503 Fehlercode zurück, wenn er versucht, unseren Webserver zu erreichen.
Verwenden Sie die AWS-Konsole, um unsere Fargate-Aufgabenkonfiguration zu aktualisieren:
- Öffnen Sie Einsatzkonfiguration für Ihre Fargate-Aufgabe
- Setzen Sie die Einsatzkonfiguration von "Gewünschte Aufgaben" auf 0
- Klicken Sie auf die Schaltfläche "Aktualisieren" unten auf der Seite.
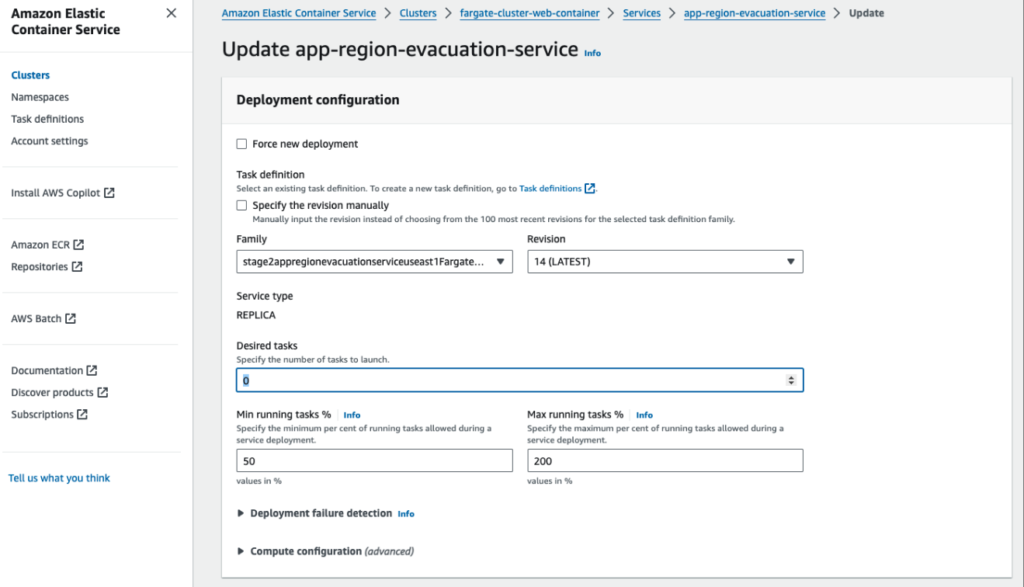
Nach ein paar Sekunden werden die Container in dieser Region angehalten.
Schritt 3 - AWS Global Accelerator erkennt einen ungesunden ALB-Status
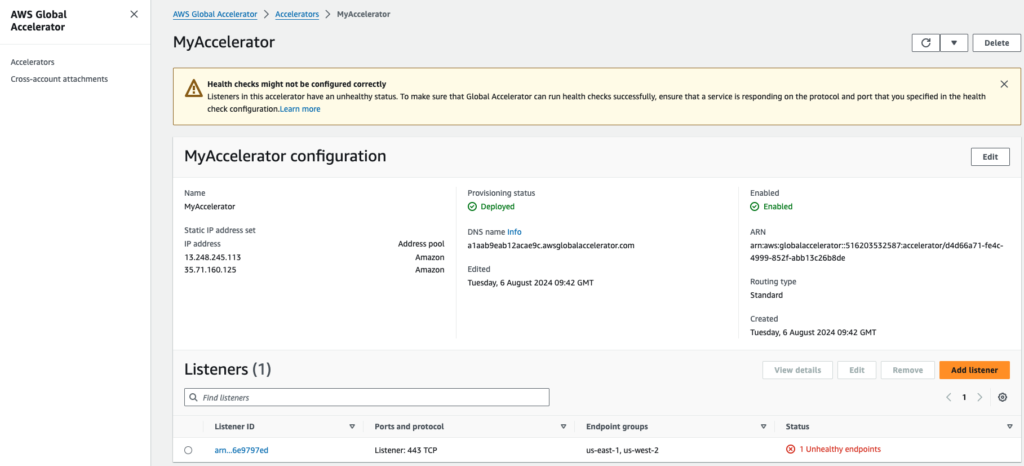
Sobald die Container gestoppt werden, beginnen die ALB-Zustandsprüfungen zu versagen, was dazu führt, dass unsere ALB in einen ungesunden Zustand gerät. Dadurch wird AWS Global Accelerator veranlasst, den Datenverkehr nicht mehr an die ungesunde Region zu senden und ihn an die verbleibenden gesunden Regionen umzuleiten.
Um den Stand von Global Accelerator zu überprüfen:
- Öffnen Sie das AWS Global Accelerator Dashboard
- Wählen Sie Ihren "Accelerator". In diesem Fall denjenigen mit dem Namen "MyAccelerator".
- Prüfen Sie die Registerkarte "Listener", um den Status Ihrer Endpunkte zu sehen. In diesem Fall ist es der Listener für Port 443 TCP.
- Öffnen Sie die "Endpunktgruppe" für die Region us-east-1

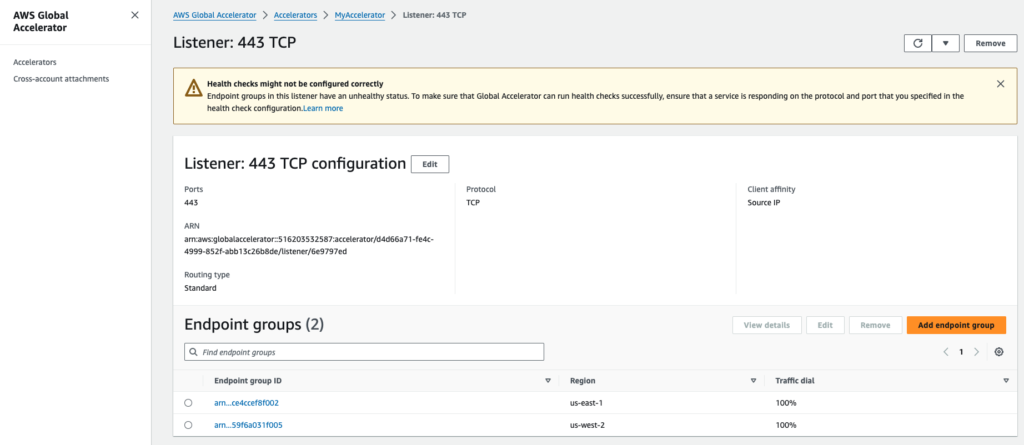
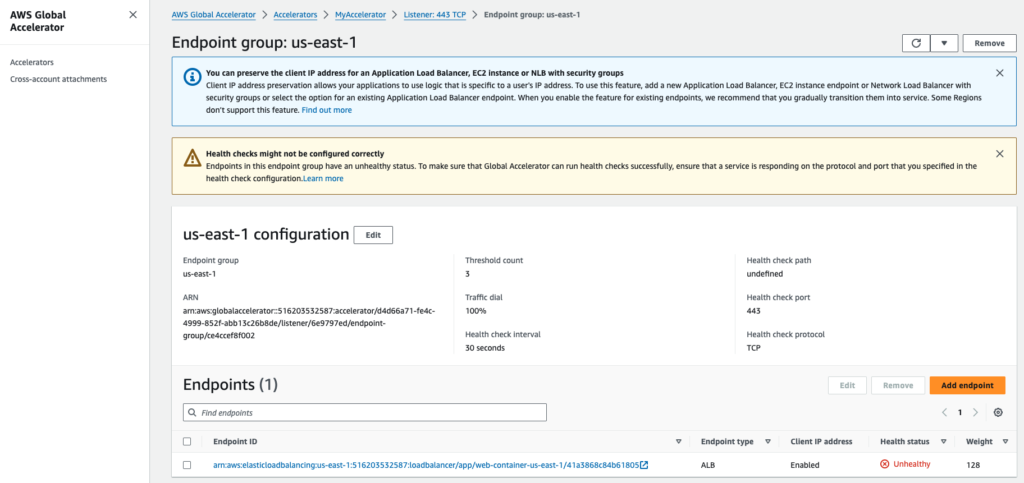
Schritt 4 - AWS Global Accelerator leitet den Verkehr um (nach us-west-2)
Um zu bestätigen, dass AWS Global Accelerator aufgehört hat, Datenverkehr an die ungesunde Region (us-east-1) zu senden und begonnen hat, Datenverkehr an die gesunden Regionen umzuleiten, können wir einen einfachen curl-Befehl verwenden:
curl https://global-accelerator.subdomain-2.subdomain-1.cloudns.ph
{
"MessageResponse": "Region: us-west-2. HTTP Response code: 200. Delay response: 0 seconds.",
"SocketRequest": "::ffff:10.0.241.224:63706",
"HeadersRequest": {
"x-forwarded-for": "188.26.219.148",
"x-forwarded-proto": "https",
"x-forwarded-port": "443",
"host": "global-accelerator.subdomain-2.subdomain-1.cloudns.ph",
"x-amzn-trace-id": "Root=1-66b1f8b0-296801ec6a94b4cb6a49145a",
"user-agent": "curl/8.6.0",
"accept": "*/*"
},
"HeadersResponse": {
"x-powered-by": "Express"
}
} Das folgende Diagramm veranschaulicht den endgültigen Zustand unseres Netzwerks nach der erfolgreichen Evakuierung der Region us-east-1.
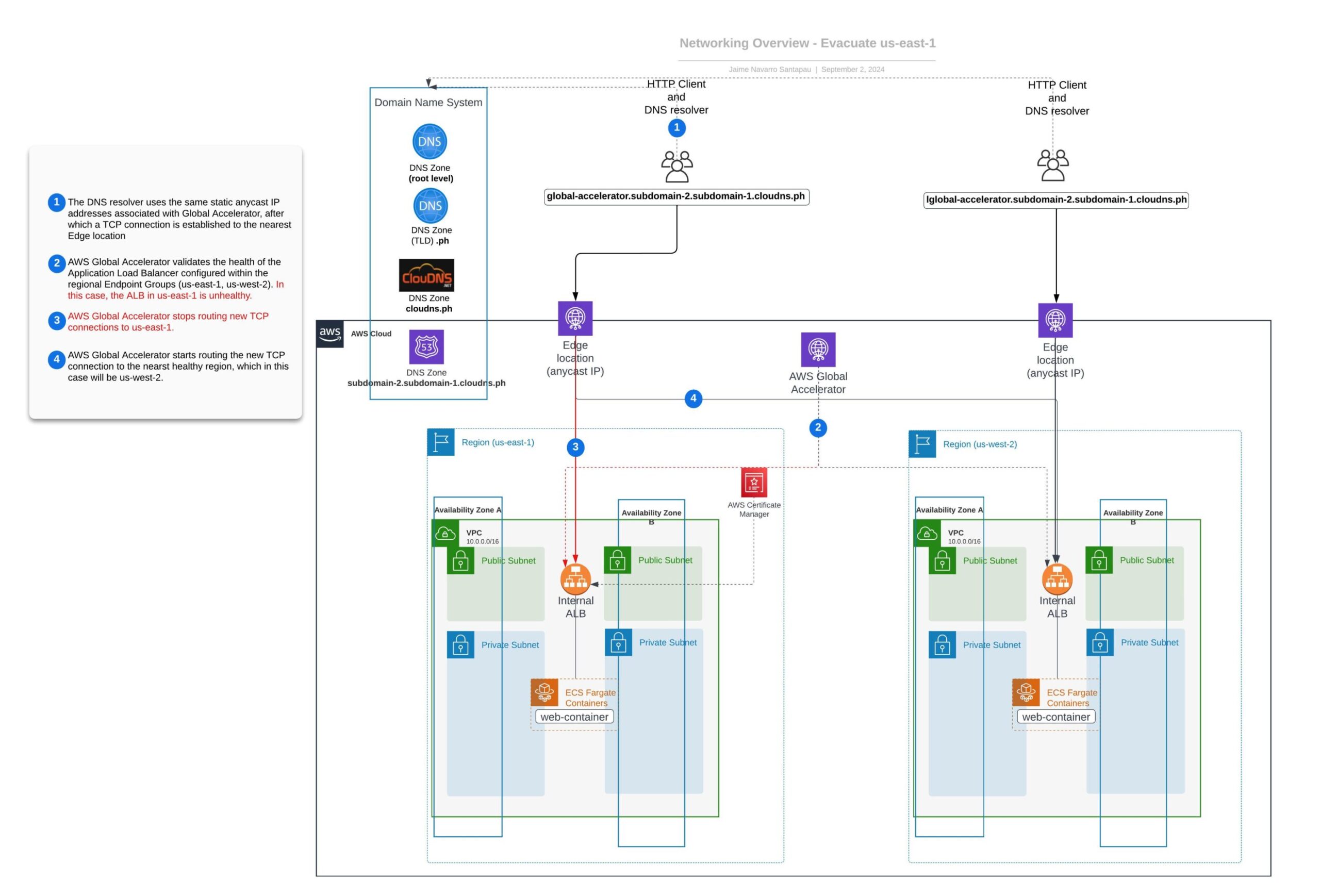
Es ist erwähnenswert, dass dieses Beispiel zu Anschauungszwecken vereinfacht ist. In realen Situationen würden Sie keine Container in einer Region anhalten wollen, um die Evakuierung der Region zu starten.
Deshalb werden wir uns mit fortschrittlicheren Strategien und Lösungen befassen. Unsere Weiterentwicklungen Abschnitt werden weitere Optionen zur Verbesserung unseres ursprünglichen Ansatzes untersucht.
Vorteile - Regionale Evakuierung mit statischem Anycast-IP-Ansatz
Die Verwendung von Global Accelerator und seinem statischen Anycast-IP-Ansatz bietet mehrere Vorteile gegenüber der DNS-basierten Methode zur Evakuierung von Regionen mit Route 53, die wir in unserem vorigen Beitrag besprochen wurde, Sie überwindet die meisten der Probleme, die bei dieser Methode festgestellt wurden.
- Verbesserte Latenzzeit: Bei allen HTTP-Anfragen ist die Latenzzeit geringer, da der Datenverkehr durch das private AWS-Netzwerk geleitet wird, sobald er den Edge-Standort erreicht. Weniger Sprünge im Internet führen zu besseren und konsistenteren Antwortzeiten.
- Feinkörnige Verkehrskontrolle: AWS Global Accelerator ermöglicht eine genaue Kontrolle über das Routing des Datenverkehrs. Sie können zum Beispiel 80 % des Datenverkehrs in eine Region leiten. Traffic-Einstellungen können Sie den Prozentsatz des Datenverkehrs anpassen, der an jede AWS Region oder Endpunktgruppe geleitet wird.
- Kundenaffinität : Kundenaffinität sorgt dafür, dass ein und derselbe Client immer in dieselbe Region geleitet wird. Wenn Sie die Client-Affinität aktivieren, werden TCP-Verbindungen von einem bestimmten Gerät immer in dieselbe Region geleitet.
- Schnelleres Failover: Der Failover-Mechanismus mit Global Accelerator ist schneller als der Ansatz mit DNS-Latenzeinträgen. Er verlässt sich nicht darauf, dass HTTP-Clients neue IPs für die Domäne verwenden, um die Evakuierung der Region effektiv durchzuführen. Stattdessen werden die neuen TCP-Verbindungen von der Backend-Seite an die gesunde Region weitergeleitet. Unter Beispiele aus der Praxis Eine regionale Evakuierung mit Global Accelerator kann in etwa 4 Minuten abgeschlossen werden.
- Erhöhte Sicherheit : Bei dieser Bereitstellung ist nur der Global Accelerator dem Internet ausgesetzt, während die ALBs privat bleiben.
- Konsistente IP-Adressen : Clients verbinden sich immer über dieselbe IP-Adresse, da AWS Global Accelerator statische Anycast-IPs bereitstellt und so die DNS-Verwaltung vereinfacht.
Nachteile - Regionale Evakuierung mit statischem Anycast-IP-Ansatz
Der statische Anycast-IP-Ansatz mit AWS Global Accelerator bietet zwar erhebliche Vorteile, ist aber auch nicht ohne Nachteile
- Wenn die AWS-Kontrollebene ausfällt, haben Sie weder über die AWS-Konsole noch über die Befehlszeilenschnittstelle (CLI) die Möglichkeit, die Verkehrskennzahlen zu aktualisieren, was bedeutet, dass Sie AWS Global Accelerator nicht anweisen können, eine Region zu evakuieren.
- Hier einige weitere Details über
AWS Global Accelerator SLA
damit Sie die Auswirkungen des vorherigen Nachteils verstehen können
- Die Verfügbarkeit der Steuerebene ist auf 99,9% ausgelegt. Das bedeutet, dass die Kontrollebene für 8 Stunden und 45 Minuten pro Jahr oder 43 Minuten pro Monat ausfallen kann.
- Die Verfügbarkeit der Datenebene ist auf 99,995% ausgelegt. Das bedeutet, dass die Datenebene für 26 Minuten pro Jahr oder 2 Minuten pro Monat ausfallen kann.
- Hier einige weitere Details über
AWS Global Accelerator SLA
damit Sie die Auswirkungen des vorherigen Nachteils verstehen können
- Auswirkungen auf die Kosten: Global Accelerator könnte zu höheren Kosten führen, da seiner Preisstruktur Preisstruktur, die einen festen Stundensatz plus zusätzliche Gebühren für die über den Dienst übertragene Datenmenge vorsieht.
Erweiterungen und Automatisierung
In diesem Abschnitt werden wir uns darauf konzentrieren, wie wir unsere Lösung zur automatischen Evakuierung einer Region verbessern können, um den Anforderungen in einer Produktionsumgebung gerecht zu werden.
CloudWatch Alarm Integration mit Global Accelerator Endpunkten
Die Integration von CloudWatch Alarms mit Global Accelerator ist ein bemerkenswerter Fortschritt für unser Setup - es ermöglicht uns, eine Vielzahl von Problemen zu erkennen.
In unserem Beispiel werden unsere CloudWatch Alarme von Metriken gespeist, die von unserer ALB generiert werden, aber wir könnten auch jede andere Metrik verwenden, die wir für relevanter halten. Das Schöne an dieser Lösung ist ihre Flexibilität - unser CloudWatch-Alarm könnte jede relevante Metrik verwenden, um zu entscheiden, ob eine Evakuierung der Region notwendig ist, was uns eine bessere Kontrolle darüber gibt, wann und warum die Evakuierung eingeleitet wird.
Zum besseren Verständnis dieser Einrichtung und der benötigten AWS-Services finden Sie im Folgenden ein detailliertes Diagramm, das die erforderliche Interaktion zwischen CloudWatch Alarms, Event Bridge, Lambda-Funktion und AWS Global Accelerator während eines automatisierten Evakuierungsprozesses einer Region veranschaulicht.
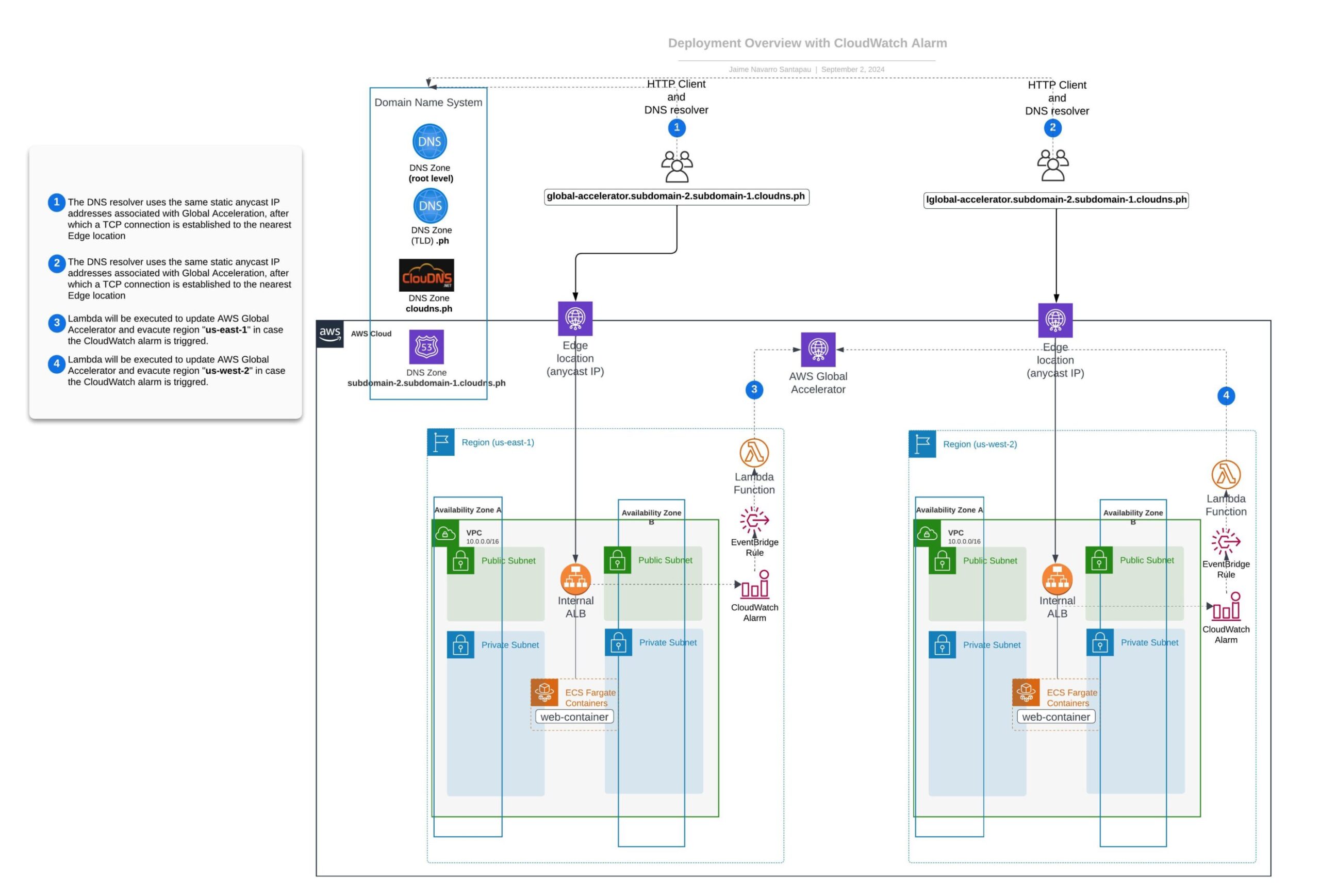
Wenn CloudWatch Alarms eine Schwellenwertverletzung feststellt (die auf eine ungesunde Region hinweist), wird die folgende Sequenz ausgelöst:
- Alarm-Aktivierung: Der spezifische CloudWatch-Alarm ändert seinen Status auf 'ALARM'.
- EventBridge-Regel: Diese Regel fängt die Änderung des Alarmzustands ab und löst eine bestimmte AWS Lambda-Funktion aus.
- Lambda-Funktionsaufruf: Die ausgeführte Funktion passt die Verkehrskennzahlen von AWS Global Accelerator an, indem sie die Weiterleitung des Verkehrs in die betroffene Region beendet und ihn auf eine gesündere Alternative umleitet.
Durch den Einsatz dieser automatisierten Verbesserungen können Unternehmen eine präzisere, effizientere und zeitnahe Reaktion auf regionale Störungen gewährleisten und so eine hohe Verfügbarkeit und Leistung in verteilten Umgebungen aufrechterhalten.
Schlussfolgerung und nächste Schritte
Wir haben nun zwei leistungsstarke Ansätze zur regionalen Evakuierung auf AWS besprochen. Unser nächster Beitrag wird diese Serie abschließen, indem wir die Auswirkungen von persistenten TCP-Verbindungen untersuchen und zeigen, wie das Übersehen dieses üblichen Client-Verhaltens selbst die robustesten Netzwerkstrategien untergraben kann.
Bleiben Sie dran für weitere aufschlussreiche Diskussionen und praktische Beispiele in der letzten Folge unserer Serie. Bis dahin möchten wir Sie ermutigen, mit den behandelten Techniken zu experimentieren und die unten aufgeführten Ressourcen für ein tieferes Verständnis zu nutzen.
Zusätzliche Ressourcen
- AWS CDK Erste Schritte : Dieser Leitfaden führt Sie in die wesentlichen Konzepte von AWS CDK ein und beschreibt den Installations- und Konfigurationsprozess.
- AWS Global Accelerator Dokumentation : Erkunden Sie die Feinheiten von AWS Global Accelerator mit der offiziellen Dokumentation, die die Funktionen und Konfigurationen abdeckt.
- AWS ACM-Dokumentation (ACM) Dokumentation: Greifen Sie auf die offizielle AWS-Dokumentation für AWS Certificate Manager zu, um Funktionen, Anwendungsfälle und bewährte Verfahren zu erkunden.
- AWS Route 53 Dokumentation : Tauchen Sie ein in die Feinheiten von AWS Route 53 mit der offiziellen Dokumentation, die DNS-Verwaltung und Domainregistrierung abdeckt.
- ClouDNS Dokumentation : In der offiziellen ClouDNS-Dokumentation finden Sie detaillierte Informationen zu den DNS-Hosting-Diensten und -Konfigurationen von ClouDNS.
- GitHub Repository für praktische Beispiele: Erkunden Sie das GitHub-Repository, das in dieser Blogpost-Reihe verwendet wird, um auf praktische Beispiele und Infrastruktur-als-Code-Konfigurationen (IaC) zuzugreifen.
Verfasst von
Jaime Navarro Santapau
I'm a Senior DevOps Engineer with over 18 years of experience starting as a Software Engineer followed by Backend Software Development Lead. Currently, I manage complex infrastructure and deliver scalable solutions. Proficient in cloud platforms like AWS and Azure, containerization technologies (Docker, Kubernetes), and automation tools. Proven track record in driving successful DevOps implementations, streamlining workflows, and improving team collaboration. Strong expertise in CI/CD pipelines, monitoring, and scripting languages.




Contact