Blog
Building Resilient Public Networking on AWS: Part 3

Region Evacuation DNS approach
Welcome to the continuation of our comprehensive "Building Resilient Public Networking on AWS" blog series sharing advanced networking strategies tailored for regional evacuation, failover, and robust disaster recovery. Here's a summary of this engaging journey:
- Revisiting networking concepts from the client's perspective: If you missed our exploration of fundamental networking concepts in the first installment, catch up here. We laid the groundwork for understanding the essentials that underpin the forthcoming discussions.
- Deploy Secure Public Web Endpoints: If you missed this blog post, you can find it here. We dove into the intricacies of deploying a web server and fortifying its public endpoint on AWS. Additionally, we demystified the management of a DNS hosted zone with Route 53, including its seamless integration with third-party DNS hosting providers.
- Region Evacuation with DNS approach: In the current blog post, we will deploy the previous web server infrastructure in several regions (us-east-1 and us-west-2), and then we will start reviewing the DNS-based approach to regional evacuation, leveraging the power of AWS Route 53. We'll study the advantages and limitations associated with this technique.
- Region Evacuation with static anycast IP approach: In the following blog post, we will deploy the web server infrastructure in several regions, and then we'll start exploring the concept of region evacuation using the robust Global Accelerator with a static anycast IP approach. Gain insights into its benefits and considerations for implementation.
- Client's TCP persistent connections and why this could be a problem: Concluding our series, we'll shed light on the critical role of addressing one of the most common HTTP client behaviors—TCP persistent connections. Uncover why overlooking this aspect can lead to the potential failure of previously discussed approaches.
Moreover, we've prepared a GitHub repository to complement this blog series. It provides Infrastructure as Code (IaC) using AWS Cloud Development Kit (CDK) and CloudFormation, allowing you to deploy and manage the necessary infrastructure effortlessly.
Introduction
In this third blog post, we aim to take our readers with an intermediate understanding of the topic to the next level.
Today, we embark on a journey to deploy the web server infrastructure discussed in our second post, but with a twist - we will deploy it across multiple regions (us-east-1 and us-west-2). Our primary focus will be on the DNS-based approach to regional evacuation.
A key part of this process is setting up the required infrastructure in the cloud. To accomplish this efficiently, we'll utilize Infrastructure as Code (IaC) with the assistance of AWS Cloud Development Kit (CDK), implemented using TypeScript. The corresponding code for this blog post can be found in the provided link.
For those new to AWS CDK or needing a refresher, we recommend starting with our guide on "Getting started with the AWS CDK." This resource will give you a sound understanding of the AWS CDK basics required to follow along with ease.
In the following sections, we will walk you through a step-by-step guide, exploring the essence of the region evacuation using a DNS-based approach and discussing the advantages and limitations of this technique. So, let's jump in!
Architecture Overview
The accompanying diagram visually represents our infrastructure's architecture, highlighting the relationships between key components. While the CDK stacks deploy infrastructure within the AWS Cloud, external components like the DNS provider (ClouDNS) require manual steps. These steps are clearly marked in the following diagram.
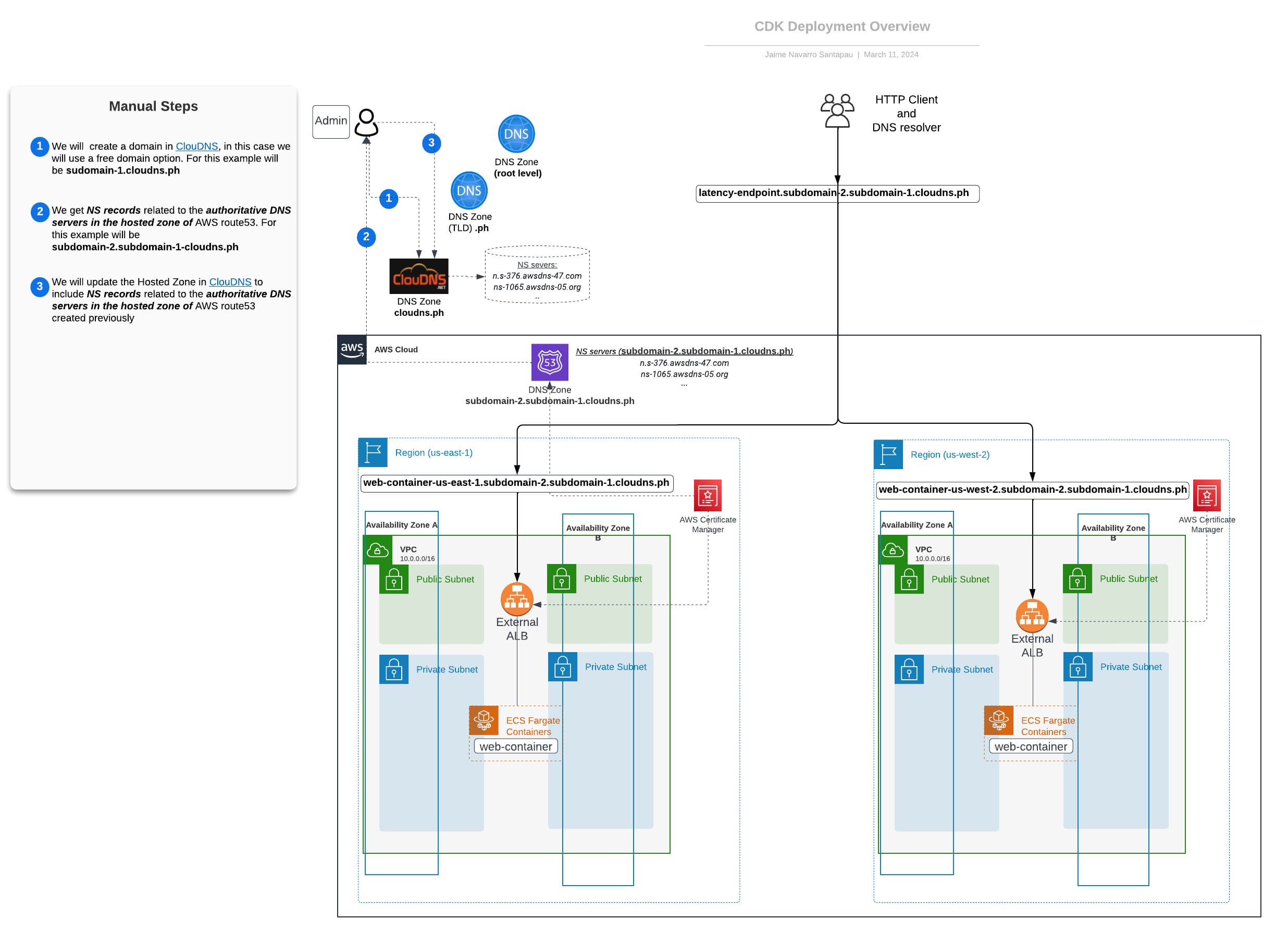 Networking Overview – DNS Latency approach using Route 53
Networking Overview – DNS Latency approach using Route 53
In this section, we will review the networking aspects to understand how AWS Route 53 can provide DNS records based on latency. This is particularly useful when you have resources spread across multiple AWS Regions and you want to route traffic to the region that offers the best latency for the client.
When a DNS resolver queries a DNS record based on latency, it returns the dynamic IPs of the Application Load Balancer (ALB) closest to your location. Consequently, the HTTP Client establishes a TCP connection to send HTTP requests to the nearest ALB. The following diagram illustrates the networking for this approach:
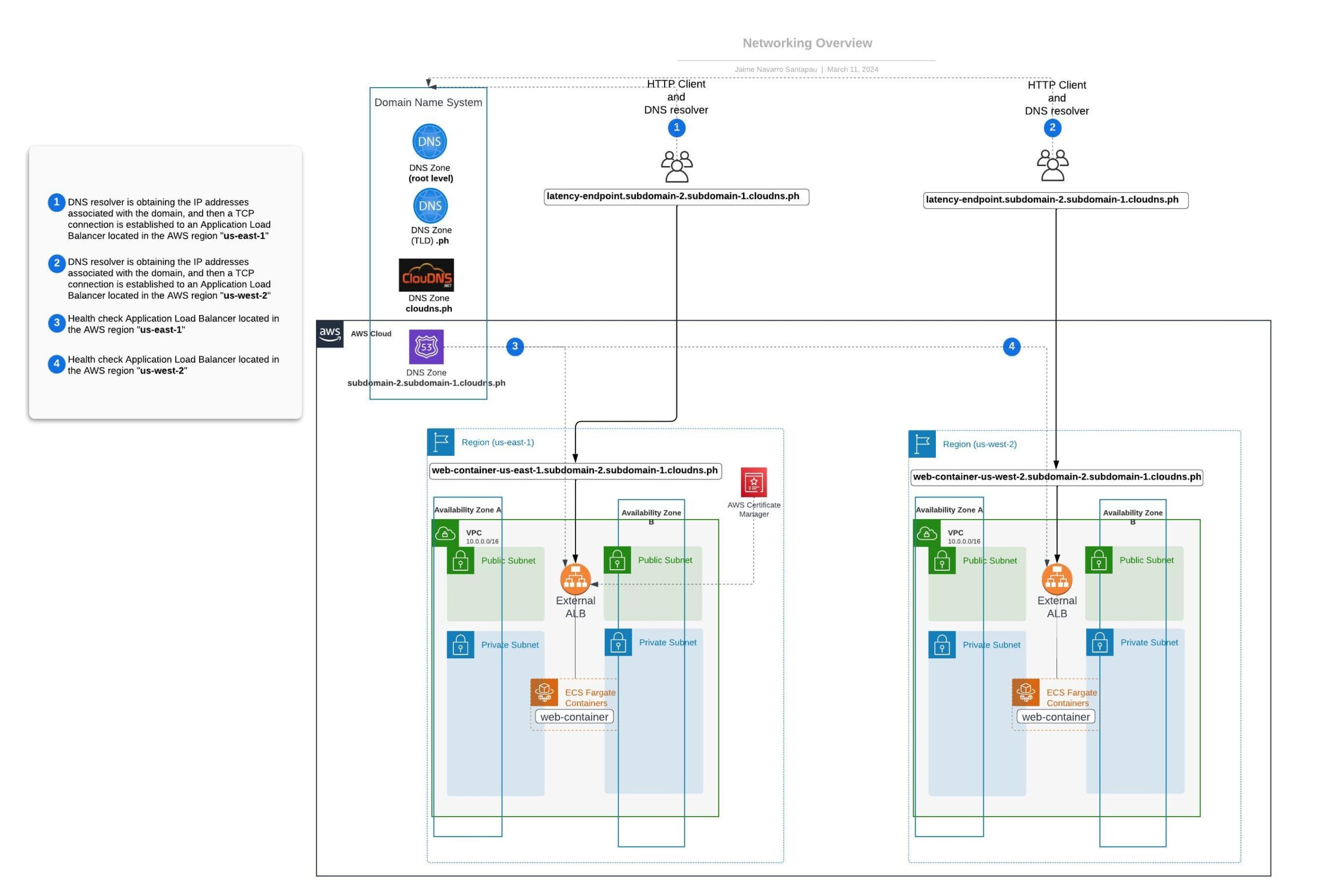
Deployment Steps and Validations
As we progress through this blog series, we will build upon the knowledge and insights gained from our previous blog posts. Therefore, we have omitted the step-by-step guide to deploy and validate this infrastructure for this blog post. However, you can access this guide by following the Deployment Steps and Validations Guide link in our GitHub repository.
This guide provides a detailed walkthrough of the deployment process, including the setup of key components, configuration settings, and validation checks. It's designed to be easy to follow, with clear instructions and helpful tips to guide you through each step.
Region Evacuation with DNS approach using Route 53
After deploying the necessary infrastructure using the guidelines provided earlier, we can now illustrate a practical example of how to effectively evacuate a region (in this case, us-east-1) when the existing infrastructure encounters issues. This example is designed to provide a basic understanding of the process.
- Step 1: To simulate a failure in the region, we modify our web-service in us-east-1 to return an HTTP 500 error code. This error code represents a server error, indicating a hypothetical failure in the region.
- Step 2: The HTTP 500 error code triggers failed health checks for our latency-based DNS records in us-east-1. These health checks serve as an early warning system, alerting Route 53 to potential issues and prompting it to reroute traffic.
- Step 3: In response to consistent health check failures, Route 53 ceases to propagate the associated IPs for the us-east-1 ALB. As a result, during the next scheduled update, the clients' DNS records will be updated to use the us-west-2 ALB IPs, effectively implementing the regional evacuation.
This tri-step process offers insights into handling service disruptions promptly, ensuring minimal impact on end-users during regional outages.
Step 1 - Web-service will return HTTP code 500 in us-east-1
In this first step, we modify our web-service container in us-east-1 to behave as if there's an error by having it return an HTTP 500 code, typically indicating server issues.
To make this change, we'll use a curl command to make an HTTP request to our web-service in us-east-1. Make sure to replace "subdomain-2.subdomain-1.cloudns.ph" with your own domain:
curl https://web-container-us-east-1.subdomain-2.subdomain-1.cloudns.ph/config/http/500
The response should be 'HTTP code response: 500', confirming our web-service in the us-east-1 region will now return an HTTP error code 500. This sets the stage for the region evacuation process.
Step 2 - AWS Route 53 Health Checks will fail in us-east-1
By returning the HTTP 500 error code, our web-service's health check in us-east-1 detects an issue. After a few minutes, this triggers a health check fail, indicating that our service in this region is "unhealthy." You can monitor this by opening the following link in your AWS console:
AWS amazon.com/route53/healthchecks/home?region=us-east-1#/
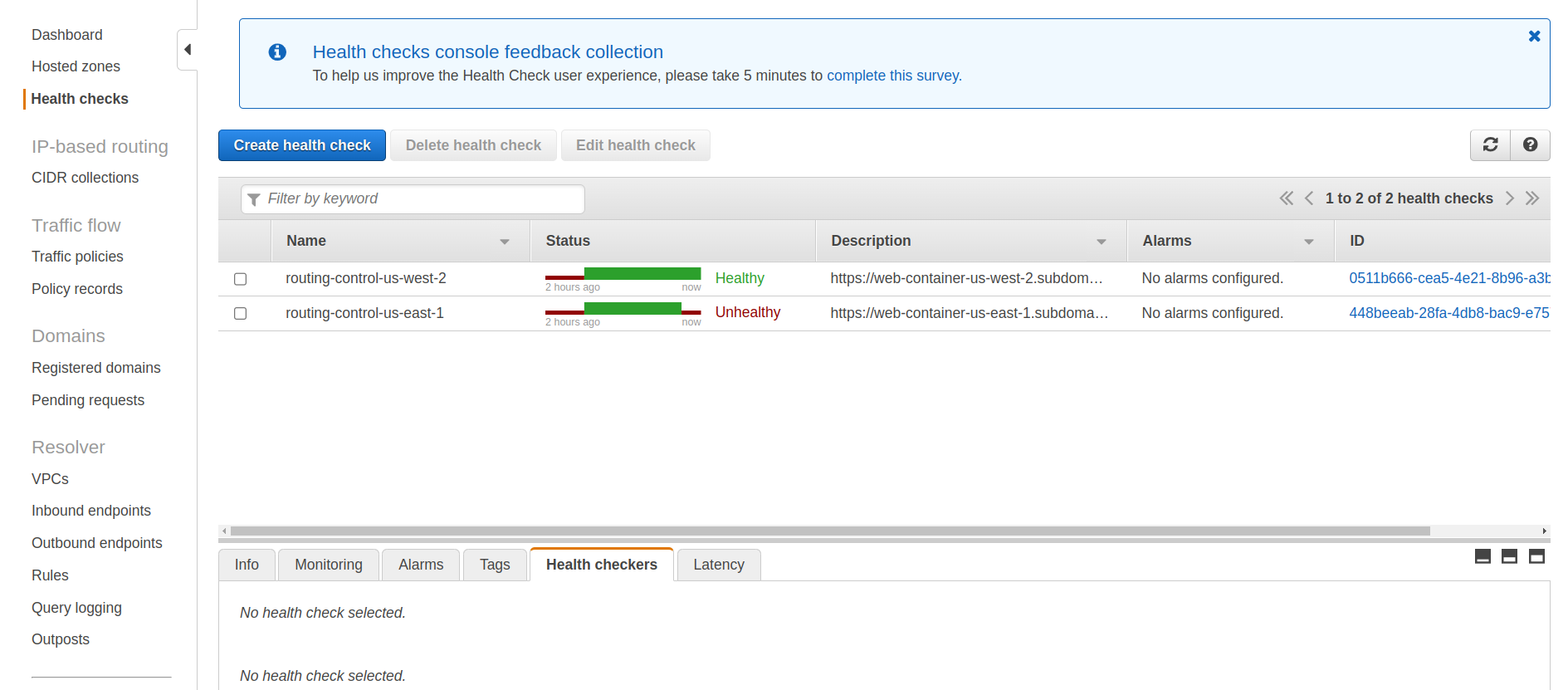
Remember, a failing health check is critical in our region evacuation process, as it initiates traffic rerouting to healthier regions.
Step 3 - AWS Route 53 will stop propagating the ALB IPs from us-east-1
Following the health check failure in us-east-1, AWS Route 53 stops broadcasting the region's dynamic ALB IPs to the internet. This means that after a few minutes, querying the DNS record for this domain (latency-endpoint. subdomain-xx.subdomain-xx.cloudns.ph) will return only the IPs for the ALB in us-west-2.
In effect, the DNS record listings for these domains should look similar:
- https://dnschecker.org/#A/latency-endpoint.subdomain-2.subdomain-1.cloudns.ph
- https://dnschecker.org/#A/web-container-us-west-2.subdomain-2.subdomain-1.cloudns.ph
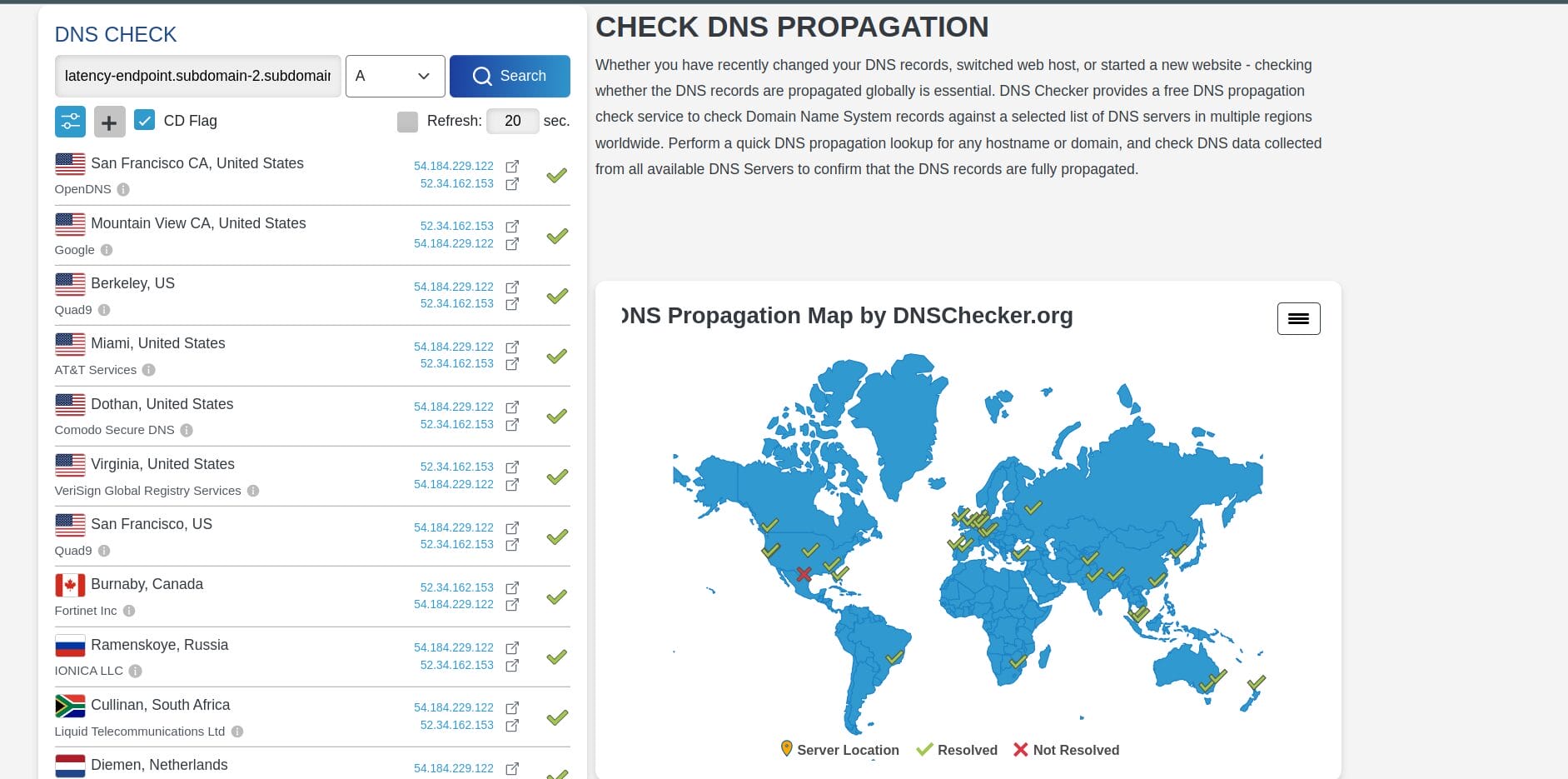
This confirms that the DNS-based regional evacuation process worked correctly.
Next, we present a diagram illustrating the final state of our networking setup after successfully evacuating the us-east-1 region.
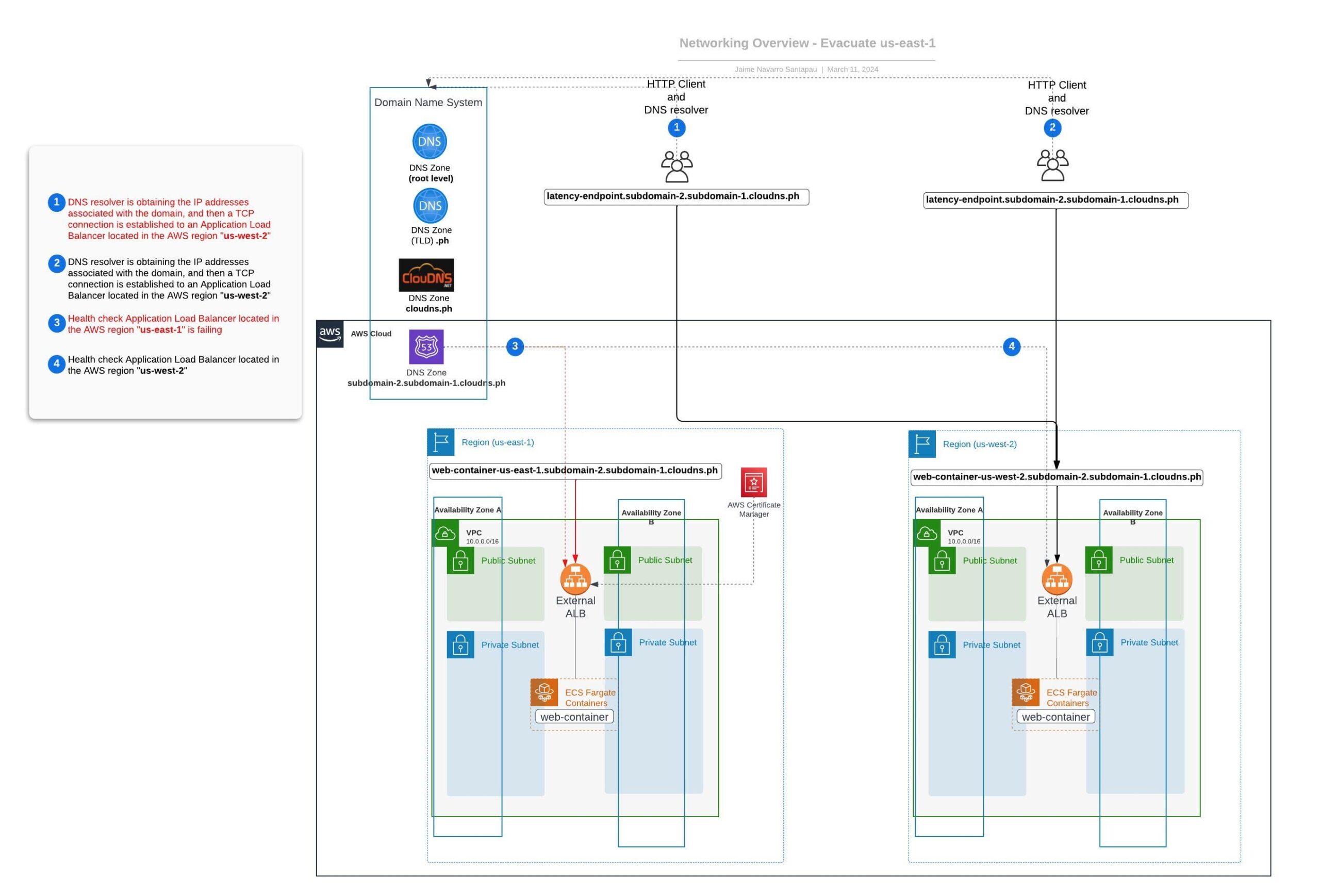 This exercise provides a fundamental basis for understanding how region evacuation operates using the DNS approach with Route 53. However, it's worth mentioning that this example is simplified for illustrative purposes. In real-world situations, you wouldn't want to automatically evacuate a region due to a single endpoint failure.
This exercise provides a fundamental basis for understanding how region evacuation operates using the DNS approach with Route 53. However, it's worth mentioning that this example is simplified for illustrative purposes. In real-world situations, you wouldn't want to automatically evacuate a region due to a single endpoint failure.
That's why it's crucial to delve into more advanced strategies and solutions. Our 'Enhancements' section delves into this, exploring other options using AWS Route 53 and AWS CloudWatch to improve our original approach.
Advantages – Region Evacuation with DNS approach
These are some of the benefits that we could highlight from this solution:
- Simplified Traffic Management: The geography-based routing feature in AWS Route 53 allows for simplified management of traffic distribution across various geographical areas.
- Cost-effective: Compared to other cloud-based DNS services, AWS Route 53 provides a cost-effective solution for DNS management, charging users solely for the resources they actually use.
- High Availability: AWS Route 53 is a highly available and reliable service. Thus it offers minimal downtime and maximum data integrity during the region evacuation process.
- Scalability: AWS Route 53's scalability enables the DNS setup to effectively handle region evacuation, regardless of the organization's size or the amount of traffic it gets.
- Health Checks: AWS Route 53's health check system helps automate the region evacuation process, as the service redirects traffic when the health check fails for a particular region.
Disadvantages – Region Evacuation with DNS approach
Though effective, DNS-based region evacuation does come with certain drawbacks:
- Client-side dependency: We will need to rely on the HTTP clients to start using the new IPs for the domain to apply the region evacuation effectively. If there is a problem on the client side to update the DNS records, the whole process could fail.
- Failover Mechanism Dependency: The DNS propagation time can vary, and if it is long, it can result in traffic continuing to be routed to the unhealthy region in the meantime.
- DNS Cache Delays: Although rare, DNS propagation could take up to 48 hours. It's also important to remember that the timing for devices to start using new IPs depends on their respective DNS cache update intervals.
- Lack of Fine-grained Control: With this approach, you can't split traffic with precision. For instance, you can't route a percentage of the traffic to a specific region; this isn't an option.
- No Client Affinity Support: The latency-based DNS record may give different IPs to the same client over time, meaning that a client might be routed to various regions over time.
These limitations could be deal-breakers for specific projects or cloud-based software solutions. Therefore, we'll explore a different networking approach in our next blog post. We'll utilize static anycast IPs powered by the AWS Global Accelerator, which could potentially overcome most of these disadvantages.
Enhancements and Automation
In this section, we will focus on improving our solution to evacuate a region automatically. We will still use the DNS approach explained earlier with AWS Route 53 and the related health checks for our DNS records based on latency.
CloudWatch Alarm with Route 53 health checks
Integrating CloudWatch Alarms with Route 53 Health Checks presents a notable advancement to our setup - it allows us to detect a wide range of issues.
In our example, our CloudWatch Alarms are fed by metrics generated by our ALB, but we could use any other metric that we thought could be more relevant. The beauty of this solution is its flexible nature - our CloudWatch Alarm could use any relevant metric to decide whether a region evacuation is necessary, giving us more robust control over when and why to initiate the evacuation.
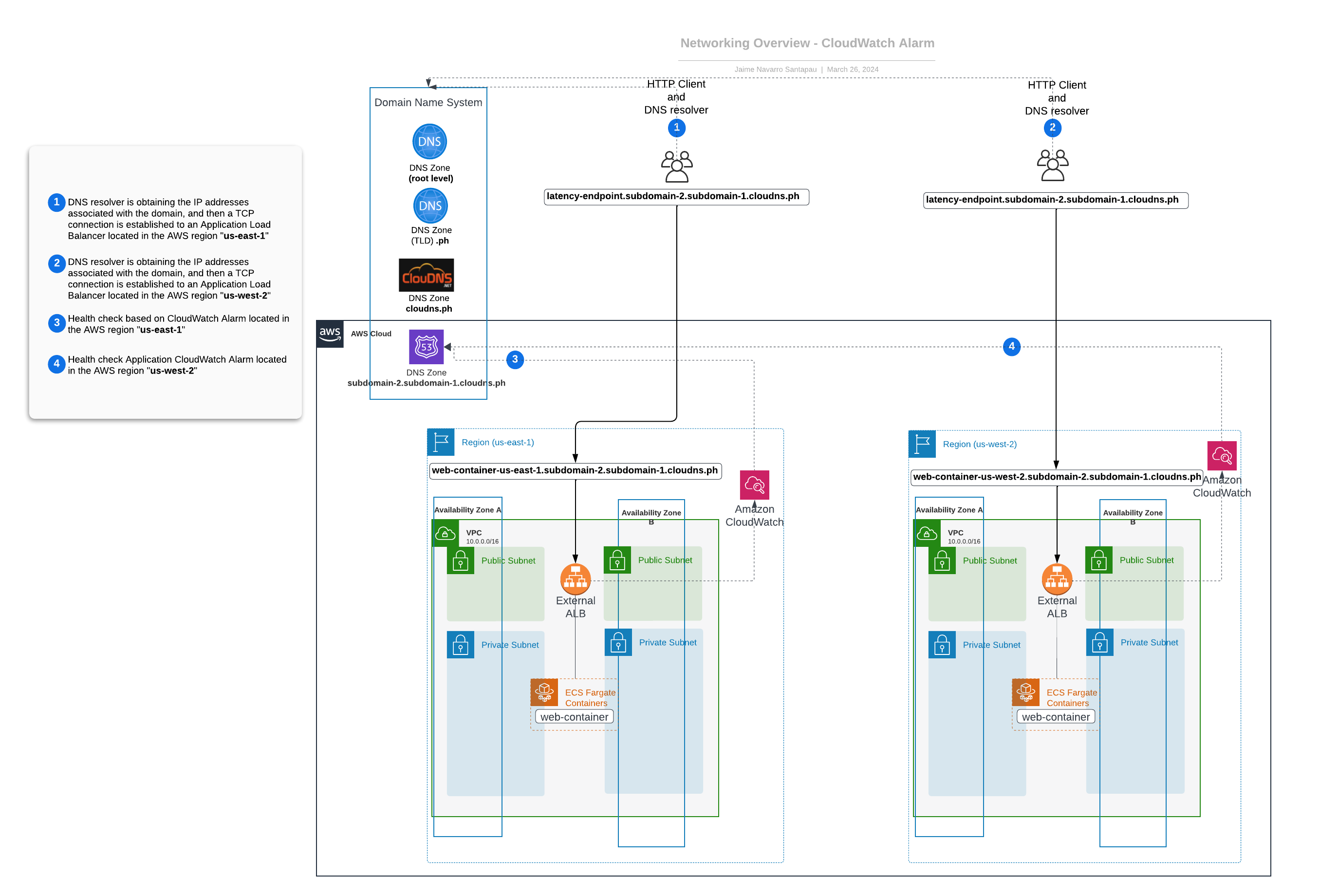 As demonstrated in the diagram:
As demonstrated in the diagram:
- Route 53 manages our latency-based DNS records and constantly monitors the CloudWatch Alarms associated with these records as health checks.
- When these CloudWatch Alarms are triggered, a consequent failure of the associated health check is registered, indicating an issue in that region.
This enhanced integration of CloudWatch Alarms with Route 53 health checks significantly bolsters our region's evacuation strategy, promising more precise detection and better decision-making control.
Conclusion and What's Next
Congratulations! You've successfully navigated the complexities of regional evacuation using the DNS approach with Route 53. We've explored the process of setting up the necessary infrastructure, delved into the DNS latency approach, and demonstrated a practical example of regional evacuation.
But our journey is not complete yet. Here is a quick summary of our upcoming posts:
- We will explore region evacuation using the anycast IP approach with Global Accelerator. We'll weigh the pros and cons of the approaches mentioned earlier, providing a balanced perspective to help you choose the best strategy for your needs.
- Finally, we will conclude our blog post series by discussing one of the most common HTTP client behaviors (TCP persistent connections) and why ignoring this can lead to the complete failure of the previous approaches.
So, stay tuned as we continue our journey into building resilient and highly available applications in the cloud. We look forward to sharing more insights and practical examples to help you master these advanced networking strategies. Until then, happy experimenting!
Additional Resources
- AWS CDK Getting Started: This guide introduces essential AWS CDK concepts and outlines the installation and configuration process.
- AWS ACM Documentation (ACM) Documentation: Access the official AWS documentation for AWS Certificate Manager to explore features, use cases, and best practices.
- AWS Route 53 Documentation: Delve into the intricacies of AWS Route 53 with the official documentation, covering DNS management and domain registration.
- ClouDNS Documentation: Refer to the official ClouDNS documentation for detailed insights into their DNS hosting services and configurations.
- GitHub Repository for Practical Examples: Explore the GitHub repository used in this blog post series to access practical examples and infrastructure as code (IaC) configurations.
Written by
Jaime Navarro Santapau
I'm a Senior DevOps Engineer with over 18 years of experience starting as a Software Engineer followed by Backend Software Development Lead. Currently, I manage complex infrastructure and deliver scalable solutions. Proficient in cloud platforms like AWS and Azure, containerization technologies (Docker, Kubernetes), and automation tools. Proven track record in driving successful DevOps implementations, streamlining workflows, and improving team collaboration. Strong expertise in CI/CD pipelines, monitoring, and scripting languages.




Contact