Blog
AWS Disaster Recovery-Strategien - PoC mit Terraform

Intro
Ein regionaler Ausfall ist ein ungewöhnliches Ereignis bei AWS (und anderen Public Cloud-Anbietern), bei dem alle Availability Zones (AZs) innerhalb einer Region von einem Zustand betroffen sind, der das ordnungsgemäße Funktionieren der bereitgestellten Cloud-Infrastruktur behindert.
Regionale Ausfälle unterscheiden sich von Serviceunterbrechungen in bestimmten AZs, bei denen eine Reihe von Rechenzentren, die physisch nahe beieinander liegen, unerwartete Ausfälle aufgrund von technischen Problemen, menschlichen Handlungen oder Naturkatastrophen erleiden können. In diesem Fall sollten andere AZs immer noch verfügbar sein, und ein für hohe Verfügbarkeit zwischen AZs konfigurierter Workload sollte die Ereignisse abmildern, während die Infrastruktur in der ursprünglichen Region bereitgestellt wird.
Im Rahmen des AWS Shared Responsibility-Modells hat AWS die Verantwortlichkeiten von Kunden und AWS klar voneinander abgegrenzt. Während AWS für die zugrundeliegende Hardware und die Wartung der Infrastruktur verantwortlich ist, ist es die Aufgabe des Kunden, dafür zu sorgen, dass seine Cloud-Konfiguration Folgendes bietet Ausfallsicherheit gegen einen teilweisen oder vollständigen Ausfall bietet, bei dem die Leistung erheblich beeinträchtigt werden kann oder die Dienste vollständig nicht mehr verfügbar sind.
Dieser Beitrag untersucht ein in Terraform geschriebenes Proof-of-Concept (PoC), bei dem eine Region mit einem grundlegenden automatisch skalierten und lastausgeglichenen HTTP*-Basisdienst bereitgestellt wird und eine andere Wiederherstellungsregion so konfiguriert wird, dass sie als Plan B unter Verwendung verschiedener von AWS empfohlener Strategien dient.
*Zu Demonstrationszwecken verwenden wir HTTP anstelle von HTTPS. Dadurch können wir unseren Code vereinfachen, um uns auf das Thema DR zu konzentrieren und den damit verbundenen Konfigurationsaufwand für HTTPS zu vermeiden. In echten Produktionsszenarien sollten Sie die Verwendung von HTTP vermeiden, insbesondere wenn sensible Daten oder Anmeldeinformationen darüber übertragen werden. Sie können mit der Verwendung von HTTPS auf Ihrem Application Load Balancer (ALB) beginnen, indem Sie die offizielle Dokumentation .
Diagramm
Das Projekt wird eine Teilmenge des folgenden Diagramms erzeugen(Quelle : AWS Disaster Recovery Workloads ).
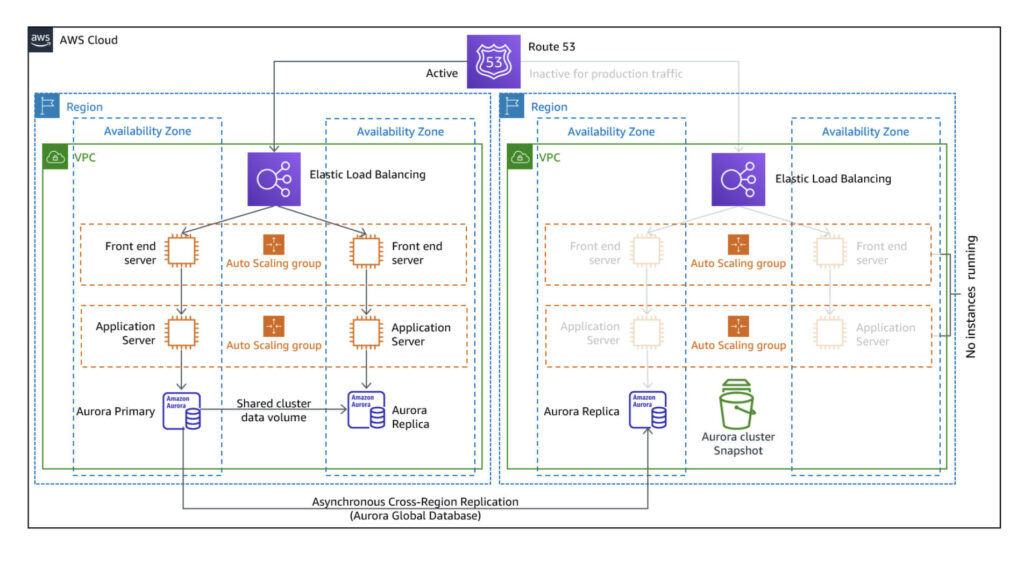
In diesem PoC werden wir die Front-End-Schicht einer dreistufigen Architektur erstellen. Der Einfachheit und Kosteneffizienz halber wurden die Backend-Instanzen und die Speicherschicht weggelassen. Außerdem wurde die DNS-Zuordnung
Dieses Diagramm ist spezifisch für die DR-Strategie Pilot Light, die in den nächsten Abschnitten erläutert wird. Die Strategie
Der Code
Der Terraform-Code wurde in zwei Repositories aufgeteilt zwei Repositories : eines für die Bereitstellung der Hauptdienstinfrastruktur in einer bestimmten Region (standardmäßig, eu-central-1 ), und ein zweites Repository für die Bereitstellung des Backup-Dienstes in einer anderen angegebenen Region (standardmäßig, eu-west-1 ). Auf diese Weise haben Sie immer ein Repository, das als Hauptdienst verwendet wird, und ein weiteres, um mit verschiedenen Arten von DR-Konfigurationen zu experimentieren, ohne das erste zu verändern.
Der Code ist unter den nachstehenden Links öffentlich zugänglich, zusammen mit einer Dokumentation zur Verwendung.
Die Idee hinter diesen Repositories ist es, als Basis für verschiedene Anwendungsfälle zu dienen. Sie können sie zu einer Produktionslösung ausbauen, indem Sie die Codebasis an Ihre Anforderungen anpassen, oder sie können als lebendiges, vereinfachtes Beispiel verwendet werden, um AWS-Benutzern die verschiedenen DR-Optionen vorzustellen.
Strategien
Bevor wir eine Strategie festlegen, müssen wir klären, was unser Recovery Time Objective (RTO) und unser Recovery Point Objective (RPO) ist.
RTO ist die Zeitspanne, in der Ihr Dienst nicht verfügbar ist oder sich in einem nicht optimalen Zustand befindet. Diese Zeitspanne hängt von verschiedenen Faktoren wie den wirtschaftlichen Auswirkungen, den SLA-Anforderungen oder der Kritikalität des Dienstes ab. Ein Service, der stündlich Tausende von Geschäftstransaktionen verarbeitet, hat eine kürzere RTO als ein Service, der Operationen durchführt, die unterbrochen und zu einem späteren Zeitpunkt wieder aufgenommen werden können.
RPO ist der akzeptable Zeitrahmen ab dem letzten Datenwiederherstellungspunkt. Er definiert die Altersgrenze für die letzte Datensicherung vor dem Ausfallereignis. Ein Dienst, der auf die Integrität der Daten angewiesen ist, sollte einen kürzeren RPO haben als ein Dienst, bei dem die Daten leicht neu berechnet werden können.
Wenn Sie die gewünschten Werte für diese beiden Konzepte kennen, können Sie die Strategie bestimmen, die für Ihre Anforderungen besser geeignet ist. Der Einsatz einer umfassenderen, teureren Lösung ist aufgrund ihres Wartungsaufwands und ihrer Budgeteffizienz möglicherweise nicht machbar. Andererseits kann eine zu große Einsparung bei Ihrer Wiederherstellungslösung im Falle eines regionalen Ereignisses zu kritischen, vielleicht unbezahlbaren Auswirkungen führen.
AWS schlägt vier Strategien für Disaster Recovery vor: Backup und Wiederherstellung, Pilot Light, Warm Stand-by und Multi-Site aktiv/aktiv.
Sichern und Wiederherstellen
Wie der Name schon sagt, besteht die Sicherung und Wiederherstellung darin, Replikate für unsere Speicherebene (DBs, EBS...) in einer anderen Region zu implementieren und sie nach einem Katastrophenereignis auf den letzten Sicherungspunkt wiederherzustellen.
Diese Strategie ist am einfachsten zu implementieren (insbesondere bei Verwendung von AWS-verwalteten Lösungen) und minimiert die Kosten. Sie führt jedoch zu der höchsten RTO, da die Wiederherstellung des Dienstes von dem zu behebenden Ereignis abhängt. Dies kann zu mehrstündigen Ausfallzeiten führen, die nur in bestimmten Anwendungsfällen akzeptabel sind, z. B. bei nicht kritischen Arbeitslasten wie Batch-Computing-Aktivitäten, bei denen die Verfügbarkeit nicht entscheidend ist.
Unser Terraform PoC enthält keinen Anwendungsfall für Backup und Restore, da dies der Konfiguration einer regionsübergreifenden Replikation für jeden spezifischen Service entspricht und daher zum Anwendungsbereich der von Ihnen gewählten Lösung gehört.
Kontrollleuchte
Diese Strategie erweitert Backup und Restore, und während die Speicherebene ebenfalls in einer anderen Region repliziert wird, wird auch das Rückgrat Ihrer Workload-Infrastruktur bereitgestellt. Beispiele sind VPCs, Subnetze, Gateways, Load Balancer, Auto-Scaling-Gruppen und EC2-Vorlagen.
Aber während alles Vorherige verfügbar ist, sind in Pilot Light Computing-Elemente wie EC2-Anwendungsinstanzen abgeschaltet und nur während eines Failovers oder Tests verfügbar.
Diese Strategie verbessert die RTO- und RPO-Zeiten im Vergleich zu einer einfachen Sicherung und Wiederherstellung erheblich, da sie die Zeit, bis ein aktiver Dienst zur Verfügung steht, von Stunden auf Minuten verkürzt (die Zeit, die benötigt wird, um in den Failover-Modus zu wechseln und die Datenverarbeitungsebenen bereitzustellen). Da keine Datenverarbeitungselemente aktiv sind, ist diese Strategie äußerst kosteneffizient, da nur minimale oder in einigen Fällen gar keine Kosten für die Netzwerk- und Infrastrukturkonfiguration anfallen.
Pilot Light wird in unserem Terraform-Code eingesetzt, indem wir die Option gewünschte_Kapazität Variable der auto-scaling Gruppe auf 0 und die Änderungen anwenden. Während des Failover-Modus sollte unser Service-Routing auf die Failover-Region verweisen und deren Kapazität so hoch skalieren, dass sie die ursprüngliche Konfiguration widerspiegelt ( desired_capacity sollte geändert werden in 2 ändern).
Warmes Standby
Warm Stand-by ist eine Erweiterung von Pilot Light, die dieselbe Workload-Infrastruktur verwendet, aber eine Version der Rechenschicht mit reduzierter Kapazität beinhaltet. Dadurch wird sichergestellt, dass der Service im Falle einer Notfallwiederherstellung sofort für die Kunden verfügbar ist, obwohl die Leistung reduziert wird, während der Service horizontal skaliert.
Die RPO- und RTO-Werte werden sich im Vergleich zu Pilot Light verbessern, aber diese Strategie ist mit festen Kosten verbunden, da sie eine voll funktionsfähige, verkleinerte Version jeder Schicht (einschließlich EC2, Lambda-Funktionen und anderer Computing-Dienste) erfordert.
Warm Stand-by wird in unserem Terraform-Code eingesetzt, indem wir die Option gewünschte_Kapazität Variable auf 1 und die Änderungen anwenden. Wie bei Pilot Light sollte unser Service-Routing im Failover-Modus auf die Failover-Region verweisen und deren Kapazität so hoch skalieren, dass sie die ursprüngliche Konfiguration widerspiegelt ( desired_capacity sollte geändert werden auf 2 ändern).
Multi-Site aktiv/aktiv
Multi-Site aktiv/aktiv ist die umfassendste Strategie für Disaster Recovery. Sie repliziert die ursprüngliche Umgebung mit voller Kapazität in einer anderen Region und fungiert als gespiegelte Version, die jederzeit sofort verfügbar ist.
Daher sinken die RPO- und RTO-Werte auf Sekunden, da nur eine Umleitung erforderlich ist, um den Betrieb wie gewohnt fortzusetzen. Es ist auch die teuerste Option, da sie Ihre Ressourcen zu jedem Zeitpunkt im Verhältnis 1:1 dupliziert. Aus diesem Grund eignet sich diese Strategie besser für Anwendungsfälle, bei denen Minuten der Ausfallzeit zu Verstößen gegen die Compliance oder zu großen wirtschaftlichen Auswirkungen führen. Ein Beispiel: Ein E-Commerce-Anbieter, der Tausende von Transaktionen pro Minute abwickelt, würde diese Strategie bevorzugen, da jeder Moment der Ausfallzeit einen Gewinnverlust bedeutet.
Multi-site active/active wird in unserem Terraform-Code eingesetzt, indem wir die Option gewünschte_Kapazität Variable auf 2 und Änderungen vornehmen. Im Failover-Modus müssen Sie nur das Routing des Dienstes ändern, ohne dass damit ein Skalierungsaufwand verbunden ist.
Schlussfolgerungen
Sie haben nun erfahren, wie Disaster Recovery-Strategien im Wesentlichen funktionieren und nach welchen Kriterien man sich für die eine oder andere entscheidet. Bitte beachten Sie, dass dieser PoC zwar einen vereinfachten Service behandelt hat, dass aber reale Szenarien einen zusätzlichen Aufwand erfordern, um aufzuzählen und zu ermitteln, welche Elemente in eine Failover-Region übertragen werden müssen, und um sich darüber klar zu werden, wann und wie dies geschehen soll.
Infrastructure as Code (IaC) ist ein Muss, wenn wir sicherstellen wollen, dass unsere Bereitstellung automatisch, schnell und zuverlässig erfolgt. Auf diese Weise werden manuelle Eingaben zur Konfiguration minimiert oder sind im besten Fall gar nicht erforderlich. Während wir in diesem Beispiel Terraform von Hashicorp verwendet haben, bietet AWS CloudFormation als native IaC-Lösung an.
Weitere Lektüre und zusätzliche Informationen:
- AWS bietet einen DR-Service namens AWS Elastic Disaster Recovery an, der bei der Implementierung verschiedener Strategien und der regionsübergreifenden Replikation hilft.
- AWS führt eine Liste der dokumentierten regionalen Ereignisse der letzten Jahre als Teil ihrer Post-Event Summaries. Sie hilft Ihnen zu verstehen, welche Faktoren einen regionalen Ausfall verursachen können und wie sie vorgehen, um diese zu lösen.
- Disaster Recovery ist keine Hochverfügbarkeit. Ein Service, der in einer einzigen AZ über eine einzige EC2-Instanz bereitgestellt wird, ist nicht hochverfügbar, selbst wenn er ein DR-Gegenstück in einer anderen Region hat. Während dieser Service einen regionalen Ausfall überstehen könnte, wird er bei einer hohen Anzahl von Anfragen oder einem ungesunden Instanzstatus Schwierigkeiten haben, einen Service bereitzustellen. Robuste Architekturen bereiten sowohl auf DR als auch auf Hochverfügbarkeit vor, und sie ergänzen sich bei der Vorbereitung auf das Unerwartete.
- Wenn Sie sich nicht sicher sind, wie Sie Ihre RTO- und RPO-Werte ermitteln sollen, können Sie mit einigen Fragen aus diesem Leitfaden beginnen.
Verfasst von
Martin Perez Rodriguez
DevSecOps and Cloud specialist at Xebia Security
Unsere Ideen
Weitere Blogs




Contact