Blog
AWS Elasticsearch Service mit Firehose Delivery Stream

Der AWS Elasticsearch Service ist eine Komplettlösung zum Aufnehmen, Verarbeiten und Visualisieren von Protokolldaten. Der Service hat mehrere Anwendungsfälle. Für Ad-hoc-Analysen ist der Service ideal, da er einfach einzurichten, kostengünstig und leicht zu bedienen ist. Wenn Sie fertig sind, können Sie den Service wieder entfernen. Der Dienst kann auch als operatives Dashboard verwendet werden, indem er die Daten kontinuierlich aufnimmt, aggregiert und visualisiert. Der Dienst kann als Such-Backend für Websites verwendet werden. Es gibt viele weitere Anwendungsfälle, für die der Dienst geeignet ist. In diesem Blog werden wir eine einfache Ingestion-Pipeline einrichten, die eine kleine JSON-Nutzlast aufnimmt und die Anzahl der "Hallo"- und "Tschüss"-Wörter in einem Dashboard zählt.
Die Architektur
Die Architektur besteht aus einer Python-Anwendung, die JSON-Nachrichten in einem Firehose Delivery Stream (FDS) veröffentlicht. Der FDS liefert die JSON-Nachrichten zur Indizierung an Elasticsearch (ES). Der ES-Dienst verfügt über einen Kibana-Endpunkt, der für das Dashboarding verwendet wird. 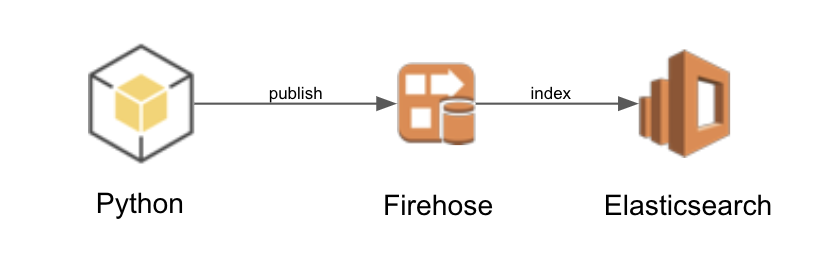
Definieren eines Elasticsearch-Dienstes
Fügen Sie in CloudFormation Folgendes hinzu, um einen ES-Cluster zu definieren. Der Cluster besteht aus einem einzelnen Knoten, t2.small.elasticsearch virtuelle Maschine, der kleinsten VM, die für den Dienst verfügbar ist.
ElasticsearchDomain:
Type: AWS::Elasticsearch::Domain
Properties:
ElasticsearchVersion: '6.3'
ElasticsearchClusterConfig:
InstanceCount: '1'
InstanceType: t2.small.elasticsearch
EBSOptions:
EBSEnabled: 'true'
Iops: 0
VolumeSize: 10
VolumeType: gp2
SnapshotOptions:
AutomatedSnapshotStartHour: '0'
AccessPolicies:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
AWS: '*'
Action: es:*
Resource: '*'
AdvancedOptions:
rest.action.multi.allow_explicit_index: 'true'
Definieren des Firehose Delivery Stream
Fügen Sie der CloudFormation-Vorlage Folgendes hinzu, um einen FDS zu definieren. Der ES-Cluster ist das Ziel für die Lieferung. Der FDS definiert, welche Protokolle erstellt werden müssen und wann auf einen neuen Index rotiert werden soll
Deliverystream:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamType: DirectPut
ElasticsearchDestinationConfiguration:
BufferingHints:
IntervalInSeconds: 60
SizeInMBs: 1
CloudWatchLoggingOptions:
Enabled: true
LogGroupName: example-firehose
LogStreamName: example-firehose
DomainARN: !GetAtt ElasticsearchDomain.DomainArn
IndexName: example
IndexRotationPeriod: OneHour # NoRotation, OneHour, OneDay, OneWeek, or OneMonth.
RetryOptions:
DurationInSeconds: 60
RoleARN: !GetAtt DeliverystreamRole.Arn
S3BackupMode: AllDocuments
S3Configuration:
BucketARN: !GetAtt DestinationBucket.Arn
BufferingHints:
IntervalInSeconds: 60
SizeInMBs: 1
CompressionFormat: UNCOMPRESSED
RoleARN: !GetAtt DeliverystreamRole.Arn
TypeName: example
ProcessingConfiguration:
Enabled: true
Processors:
- Type: Lambda
Parameters:
- ParameterName: LambdaArn
ParameterValue: !GetAtt ProcessorFunction.Arn
- ParameterName: RoleArn
ParameterValue: !GetAtt DeliverystreamRole.Arn
- ParameterName: NumberOfRetries
ParameterValue: '3'
- ParameterName: BufferSizeInMBs
ParameterValue: '1'
- ParameterName: BufferIntervalInSeconds
ParameterValue: '60'
ProcessorFunctionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Condition: {}
Path: /
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
- arn:aws:iam::aws:policy/AmazonKinesisFirehoseFullAccess
DeliverystreamRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: firehose.amazonaws.com
Action: sts:AssumeRole
Condition: {}
Path: /
Policies:
- PolicyName: Allow
PolicyDocument:
Statement:
- Effect: Allow
Action:
- s3:*
- kms:*
- kinesis:*
- logs:*
- lambda:*
- es:*
Resource:
- '*'
Der Prozessor Lambda
Es gibt zwei Lambdas zum Ausprobieren. Der map_message_processor ändert den Inhalt von hello world in bye world.
indentity_processor.py:
from base64 import b64encode, b64decode
import json
def handler(event, context):
records = event['records']
for record in records:
record.pop('approximateArrivalTimestamp', None)
record.update({'result': 'Ok'}) # Ok, Dropped, ProcessingFailed
print(json.dumps(records))
return {'records': records}
map_message_processor:
from base64 import b64encode, b64decode
import json
import uuid
def handler(event, context):
records = event['records']
for record in records:
record.pop('approximateArrivalTimestamp', None)
msg = b64encode(bytes(json.dumps({'message': f'bye world! {uuid.uuid4()}'}), 'utf-8')).decode('ascii')
record.update({'data': msg})
record.update({'result': 'Ok'}) # Ok, Dropped, ProcessingFailed
print(json.dumps(records))
return {'records': records}
Der Herausgeber
Das folgende Python-Skript veröffentlicht Nachrichten an den FDS.
import boto3
import sys
import json
client = boto3.client('firehose')
stream_name = sys.argv[1]
number_of_messages = int(sys.argv[2])
print(f'Publishing {number_of_messages} to {stream_name}')
records = []
for x in range(1, number_of_messages, 1):
records.append({
'Data': bytes(json.dumps({'message': f'hello world {x}'}), 'utf-8')
})
try:
response = client.put_record_batch(
DeliveryStreamName=stream_name,
Records=records
)
if response['FailedPutCount'] > 0:
print('Error putting messages')
except Exception as e:
print(f'Error: {e}')
print('Done')
Beispiel
Das Beispielprojekt zeigt, wie Sie ein Projekt konfigurieren, um einen elasticsearch-Cluster für Ad-hoc-Analysen zu erstellen. Das Beispiel kann mit make publish ein.
Kibana
Melden Sie sich bei der 'AWS Console' an, dann beim 'Elasticsearch Service Dashboard' und klicken Sie auf die Kibana URL. Sobald Sie eingeloggt sind, klicken Sie auf "discover" und erstellen ein neues Indexmuster mit dem Namen example-*. Klicken Sie ein weiteres Mal auf 'entdecken' und Sie sollten Daten sehen. Falls nicht, geben Sie
Klicken Sie auf 'visualisieren' und klicken Sie auf 'Visualisierung erstellen' und wählen Sie 'Metrik', um einen Zähler zu erstellen. Wählen Sie den Index example-* und geben Sie im Filter message:bye ein und klicken Sie auf 'Speichern'. Nennen Sie sie 'tschüss'. Erstellen Sie eine weitere 'Metrik' mit dem Filter 'message:hello' und nennen Sie sie 'hello'.
Klicken Sie auf "Dashboard" und "Neues Dashboard erstellen". Klicken Sie auf 'Hinzufügen' und wählen Sie dann alle drei Metriken aus. Klicken Sie auf 'Speichern' und nennen Sie das Dashboard 'Summen'. Klicken Sie auf "Automatisch aktualisieren" und das Dashboard sollte aktualisiert werden.
Einnahme von Hallo
Standardmäßig nimmt das Beispiel aufgrund des Verarbeitungs-Lambdas 'bye world' auf. Ändern Sie das in 'hello world', indem Sie das Makefile bearbeiten und die Kommentare von make merge-lambda && make create ein und der Stack sollte aktualisiert werden. Geben Sie als nächstes make publish ein, um Nachrichten zu veröffentlichen. Nach ein paar Sekunden sollten Sie auf dem Dashboard sehen, wie sich die Gesamtzahlen ändern.
Fazit
In diesem Beispiel haben wir einen Elasticsearch-Dienst implementiert, Daten aufgenommen, einige Ad-hoc-Analysen durchgeführt und ein Dashboard erstellt. Elasticsearch eignet sich hervorragend für die Analyse von Protokolldaten wie Ereignisströmen, Klickströmen, Zugriffsprotokollen, CloudWatch- und Cloudtrail-Protokollen. Das nächste Mal werden wir uns die Verarbeitung von Zugriffsprotokollen von API Gateway ansehen, um Einblicke in die Leistung der API zu erhalten.
Verfasst von
Dennis Vriend
Unsere Ideen
Weitere Blogs




Contact