
Ich habe über die Teams nachgedacht, denen ich in meinem Berufsleben helfe, und mir ist plötzlich aufgefallen, dass es verschiedene Phasen zu geben scheint, die jedes Team in dem Bemühen durchläuft, etwas in seiner täglichen Arbeit zu verbessern. Normalerweise beginne ich einen neuen Auftrag mit einer bestimmten Frage, und gemeinsam entwickeln wir meinen Auftrag von dort aus weiter.
Der Einstiegspunkt ist oft etwas Bestimmtes, wie z.B.:
- Migrieren Sie unsere On-Premise-Source-Control zu etwas in der Cloud (normalerweise viel neuer)
- Qualitätsbewertungen der Codebasis
- Arbeitsweise, um Änderungen in die Produktion zu bringen
Nachdem die anfängliche Frage geklärt ist (oder geklärt werden soll), helfe ich den Teams oft mit zusätzlichen Schritten, die sie einbeziehen können, um bestimmte Aspekte ihrer Arbeitsweise zu verbessern, und wir gehen von dort aus weiter.
Da mein Fachgebiet DevOps ist, drehen sich all diese Dinge um diese Themen. Ich habe viele Dinge rund um den DevOps-Zyklus getan, von der Erläuterung von Git als Methode zur Versionierung Ihres Codes bis hin zur Überwachung in der Produktion und der Bereitstellung in einer Cloud-Umgebung. Beachten Sie, dass diese Themen meist auf dem Einsatz von Technologie basieren, um Dinge zu verbessern. Die Welt der Menschen und der Kultur in einem Unternehmen ist ein anderes Mal dran.
DevOps - Zustände der Erleuchtung
Wenn ich auf meine Aufgaben zurückblicke, finde ich verschiedene Stadien, in denen sich die Teams in ihrer DevOps-Arbeitsweise befinden, und daraus können Sie die nächste Sache ableiten, die wahrscheinlich zur Verbesserung ihrer Umgebung beitragen würde. Mit Umgebung meine ich alles, was sie tun, damit die Anwendung in der Produktion läuft. Natürlich haben einige Teams diese Themen bereits (teilweise) im Griff, so dass Sie auch andere Zustände prüfen können, um mögliche Verbesserungen zu finden.
Ich habe versucht, diese in der untenstehenden Abbildung in eine logische Reihenfolge zu bringen und werde (versuchen), für jede Phase einen Blogbeitrag zu verfassen, in dem ich beschreibe, was dies bedeutet und wie Sie dies in Ihrer Einrichtung umsetzen können. Sie können jederzeit tiefer in ein bestimmtes Thema eintauchen, egal wo Ihr Team im Verbesserungsprozess steht, oder Dinge überspringen und später wiederkommen. Meiner Meinung nach ist diese Reihenfolge für mich sinnvoll:
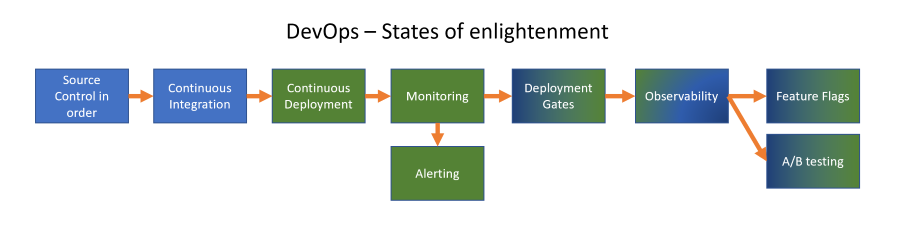
Ich habe die Staaten farblich gekennzeichnet, um zu verdeutlichen, was ihr Hauptanliegen ist und ob es sich dabei um eine entwicklungsorientierte (blau) oder eine operativ orientierte (grün) Sichtweise handelt, auch wenn dies natürlich nicht immer eindeutig ist.
Dev - Quellcodekontrolle in Ordnung
Aus der Sicht eines Entwicklers müssen Sie Ihre Versionskontrolle in Ordnung haben. Ich stoße immer noch auf Code, der überhaupt nicht versionskontrolliert ist. Manchmal liegt er einfach auf einem Benutzerrechner, einer Freigabe oder noch schlimmer: auf dem gemeinsamen Server, der für CI/CD (Continuous Integration and Deployment) verwendet wird! Link DevOps - Quellcodekontrolle in Ordnung.
Dev - CI (kontinuierliche Integration) Pipelines
Auf Wunsch des Entwicklers beginnen sie in der Regel mit der Implementierung einer kontinuierlichen Pipeline, die den Code zumindest auf einem anderen Rechner erstellt als der Entwickler, der den Code geschrieben hat. Dieser Zustand wird in verschiedene Reifegrade eingeteilt, da es viele verschiedene Verbesserungen zu erzielen gibt. Link DevOps - Kontinuierliche Integration.
Ops - CD (kontinuierliche Bereitstellung / Lieferung) Pipelines
Oft haben die Mitarbeiter, die die Anwendung in einer Umgebung bereitstellen, das Bedürfnis, diese Aktionen in einem wiederholbaren Prozess zu automatisieren, der ohne manuelle Eingriffe ausgeführt werden kann. Ich habe immer noch Teams gesehen, in denen dieser Prozess von sechs designierten Teammitgliedern orchestriert wurde, von denen jeder warten musste, bis ein anderer fertig war, um den nächsten Schritt in der Bereitstellung zu starten, indem er seine eigene Batch-Datei (natürlich nicht versioniert!) mit benutzerdefinierten Einstellungen für diese Umgebung ausführt. Dieser Zustand kann auch in mehrere Reifegrade aufgeteilt werden. Link DevOps - Kontinuierliche Bereitstellung
DevOps - Gates vor und nach der Bereitstellung mit aktuellen Prüfungen
Dies ist das erste häufige Szenario, bei dem sowohl die Entwicklungsabteilung als auch der Betrieb ein Interesse daran haben, dass die Dinge erledigt werden: Der Betrieb hat in der Regel ein Interesse daran, zu überprüfen, ob die Dinge nach einer Bereitstellung noch funktionieren, und dies ist oft der letzte Schritt für die Entwickler, wenn sie denken, dass ihre Arbeit abgeschlossen ist.
Ops - Beginnend mit der Überwachung
Natürlich ist dies in erster Linie eine Frage des Betriebs, auch wenn die Entwickler (endlich) mehr und mehr einen Blick auf die tatsächlich laufende Anwendung werfen, um zu sehen, wie die Dinge laufen. Um mehr Einblicke zu erhalten, ist die Überwachung ein wichtiges Thema, das behandelt werden muss. Wenn Entwickler sich mit diesem Thema befassen, gehen sie oft von einem anderen Ausgangspunkt aus als jemand mit einem operativen Hintergrund.
Ops - Alarmierung
Wenn die Überwachung eingerichtet ist, wäre es sehr hilfreich, wenn Sie auch Warnmeldungen von Ihrer Überwachungseinrichtung erhalten. Oft beginnen Sie hier und erhalten zu viele Warnungen. Dies richtig zu machen ist schwierig, aber sehr wichtig. Ausgehend von der Alarmierung können Sie auch mit einem guten Wiederherstellungsmechanismus beginnen, z.B. mit dem Hinzufügen von Playbooks/Runbooks, um einen Wiederherstellungsvorgang zu starten (dies könnte sogar eine Skalierung nach oben/unten sein).
Ops - Beobachtbarkeit
Oftmals wird dies durch etwas aus der Überwachung (daher Ops) ausgelöst und es entsteht der Bedarf, tatsächliche Einblicke in das zu erhalten, was die Anwendung tatsächlich tut. Die Entwickler haben in der Regel den Einblick, wo Sie zusätzliche Protokollierung in die Anwendung einfügen können, um diese Informationen herauszubekommen. Daher der Farbverlauf im Bild: Es beginnt mit Ops (oft) und wird dann zu einer gemeinsamen Anstrengung, um die Informationen herauszubekommen.
DevOps - Funktionskennzeichen
Nachdem Sie durch grundlegende Protokollierung und Beobachtung mehr Informationen über die Anwendung erhalten haben, können Sie sich auf den Weg machen, geeignete Funktionsflags zu setzen: ein Flag zu setzen, um etwas in der Anwendung/Umgebung zu aktivieren/deaktivieren, um z.B. neue Funktionen zu aktivieren oder eine Empfehlungsmaschine am schwarzen Freitag zu deaktivieren, um eine zuverlässigere Anwendung zu haben. Dies ist oft eine gemeinsame Anstrengung von Entwicklern und Technikern.
DevOps - Schnelle A/B-Tests mit Benutzerkohorten
Wenn Sie Feature-Flags in Ihrem System haben, geht Ihnen oft ein Licht auf: Sie können diese zum Testen in der Produktion verwenden! Warum geben Sie nicht bestimmten Benutzern eine Kennzeichnung wie 'intern', 'Beta-Tester', 'Kunde' und lassen nur diese Gruppen neue Funktionen testen? Dies ermöglicht Canary-Releases (eine Untergruppe von Benutzern erhält die neue Funktion) oder sogar echte A/B-Tests, um zu sehen, welcher Anwendungsablauf mehr Kunden zum Kauf eines Produkts bewegt.
Verfasst von
Rob Bos
Rob has a strong focus on ALM and DevOps, automating manual tasks and helping teams deliver value to the end-user faster, using DevOps techniques. This is applied on anything Rob comes across, whether it’s an application, infrastructure, serverless or training environments. Additionally, Rob focuses on the management of production environments, including dashboarding, usage statistics for product owners and stakeholders, but also as part of the feedback loop to the developers. A lot of focus goes to GitHub and GitHub Actions, improving the security of applications and DevOps pipelines. Rob is a Trainer (Azure + GitHub), a Microsoft MVP and a LinkedIn Learning Instructor.
Unsere Ideen
Weitere Blogs




Contact