Blog
AWS Open Source Beobachtbarkeit - Amazon Neptune und Sicherheitsgraphen (Teil 2)

Im vorigen Artikel dieser Serie habe ich Observability als eine Reihe von Praktiken definiert , mit denen Daten aus einem System gesammelt, korreliert und analysiert werden können, um die Überwachung, Fehlerbehebung und allgemeine Sicherheit zu verbessern.
Mit CloudMapper haben wir zwei Anwendungsfälle abgedeckt, die in den meisten Cloud-Umgebungen üblich und nützlich sind (Sicherheitsaudit und Visualisierung). Dieser Artikel besteht aus einem Walkthrough, der die Einrichtung, Erstellung und Abfrage einer Graphdatenbank mit den genannten Tools beschreibt: ein eher nischenhafter, fortgeschrittener Anwendungsfall auf Amazon Neptune.
Was ist eine Graphdatenbank?
Da das Konzept der Graphdatenbanken einigen Lesern nicht geläufig sein könnte, beginnen wir mit seiner Definition. Eine Graphdatenbank ist eine Datenbankstruktur, die sich auf die Beziehungen zwischen ihren Elementen konzentriert und nicht auf den Inhalt der einzelnen Elemente selbst. Sie enthält:
- Knoten: Darstellungen der einzelnen Elemente und ihrer Eigenschaften. Sie symbolisieren reale Einheiten, die in der Lage sind, Beziehungen zu anderen herzustellen.
- Kanten: Darstellungen jeder Beziehung zwischen einem oder mehreren Elementen.
Optisch sehen sie folgendermaßen aus:
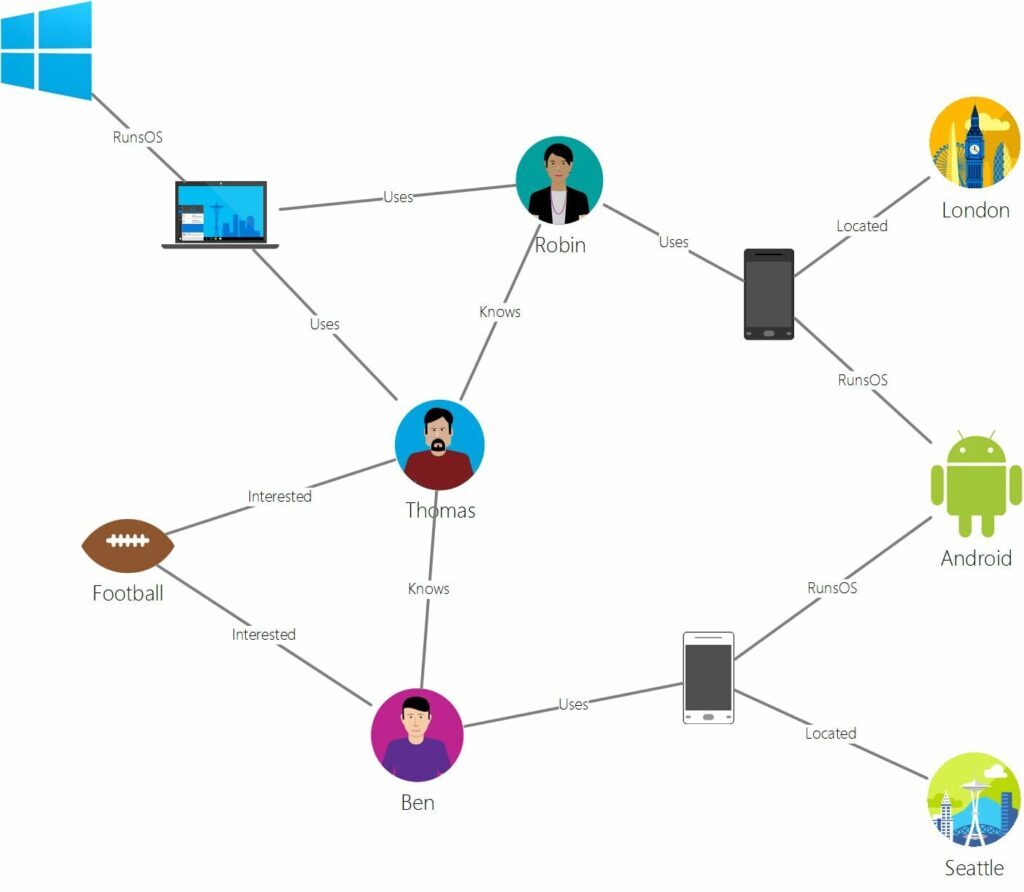
Robin, Android oder London sind Knoten mit verschiedenen Eigenschaften wie Alter, Version oder Koordinaten. Beziehungen wie "kennt", "interessiert" oder "befindet sich" werden durch die Kanten des Graphen dargestellt.
Diese Datenbanken werden häufig für die Datenanalyse verwendet und glänzen besonders bei der Betrugserkennung oder bei Empfehlungsmaschinen für soziale Medien. Sie können jedoch auch sehr nützlich sein, um die Beziehungen zwischen Elementen in einer Cloud-Umgebung darzustellen und deren Sicherheit zu verbessern.
Amazon Neptune ist ein verwalteter Graphdatenbank-Service, der von AWS angeboten wird.
Einrichten der Umgebung in AWS
In dieser Anleitung wird davon ausgegangen, dass Sie mit der Netzwerkarbeit in AWS vertraut sind und die entsprechenden ACLs, Routentabellen und Sicherheitsgruppen für die Erreichbarkeit von VPC/Regionen einrichten können.
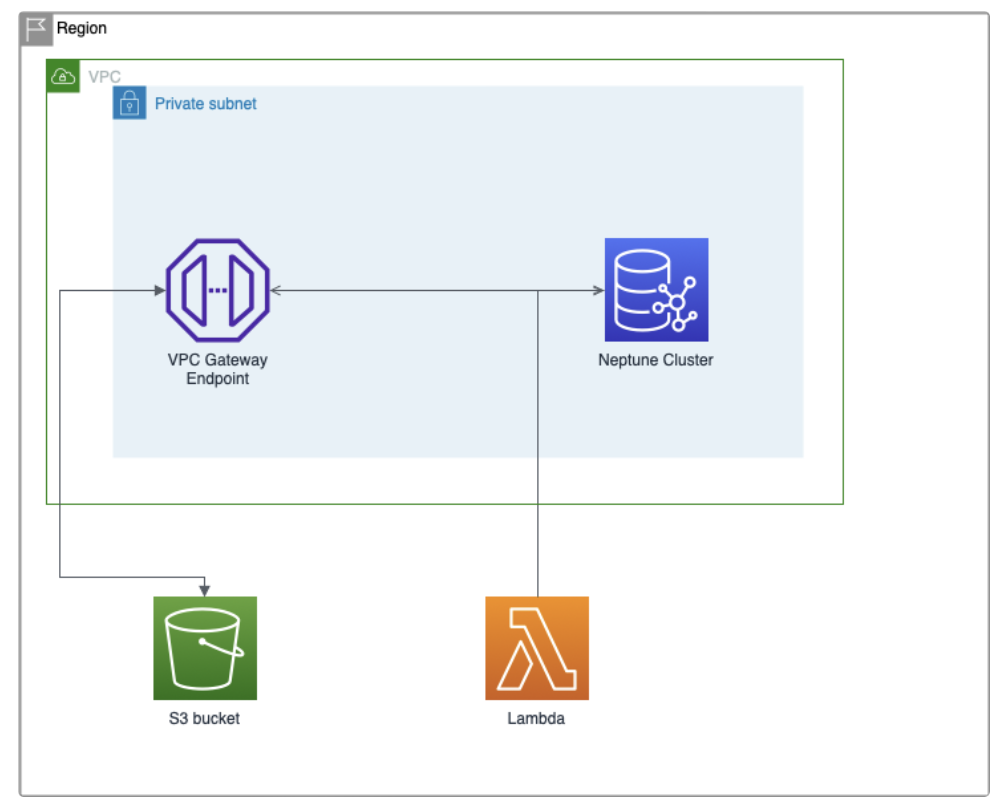
Für eine einzelne Region und VPC benötigen Sie:
- Ein nicht-öffentlicher S3-Bucket, um die Datenbankdaten im RDF-Format zu speichern
- Ein Teilnetz
- Ein Amazon Neptune-Cluster mit einer Instanz, die sich in dem Subnetz befindet. Sie können Nicht-Produktionsumgebungen und eine für Free-tier geeignete Instanz für das Staging auswählen. Sie können sie von der Konsole aus unter dem Neptune-Dienst erstellen oder eine CloudFormation-Vorlage verwenden.
- Eine Notebook-Instanz für die Abfrage der Datenbank. Sie können es unter dem Neptune-Dienst erstellen und konfigurieren.
- Ein VPC-Gateway-Endpunkt, der sich im Subnetz befindet, um mit dem S3-Bucket zu kommunizieren.
- Eine Lambda-Funktion oder EC2-Instanz, die mit dem VPC-Endpunkt und Neptune kommunizieren kann. Damit führen wir eine POST-Anfrage durch, um Daten aus dem S3-Bucket in den Neptune-Cluster zu laden. Wenn Sie eine Lambda-Funktion verwenden (und
das sollten Sie), können Sie jede Sprache verwenden, mit der Sie sich wohl fühlen. Ich werde die Bash mit dem Befehl curl verwenden.
Die Erstellung des Amazon Neptune-Clusters ist im offiziellen Benutzerhandbuch gut dokumentiert.
Erste Schritte mit Amazon Neptune
Vergessen Sie nicht, für Neptune eine dienstgebundene Rollenrichtlinie zu erstellen, wie hier beschrieben:
Erstellen eines IAM-Benutzers mit Berechtigungen für Neptune
Höhenmesser einrichten
Sie können Altimeter über pip installieren, wie in der Dokumentation beschrieben.
Im Repository wird eine Beispielkonfigurationsdatei bereitgestellt, die Sie als Grundlage für Ihre eigene .toml-Konfigurationsdatei verwenden können. Es wird empfohlen, den Abschnitt [regions] zu bearbeiten, um den Scan auf die Regionen zu beschränken, in denen Sie tatsächlich Einsätze haben. Lassen Sie die [preferred_account_scan_regions] als Standardeinstellung, da ich sonst auf einige Probleme gestoßen bin.
Außerdem müssen Sie AWS CLI-Anmeldeinformationen konfigurieren und über die richtige Berechtigungsstufe verfügen, um die Elemente zu lesen, die Sie überwachen möchten. Um z.B. Informationen über einen S3-Bucket zu lesen, benötigen Sie Lesezugriff für S3 auf diese Anmeldeinformationen.
Schließlich und um weitere dokumentierte Fehler zu vermeiden, müssen Sie die Umgebungsvariable AWS_DEFAULT_REGION definieren oder in Ihrem .aws-Konfigurationspfad konfigurieren (standardmäßig ~/.aws/config).
Sobald dies eingerichtet ist, rufen Sie den Befehl auf:
Höhenmesser <path_to_the_toml_config_file>
Altimeter füllt dann eine RDF-Datei mit allen relevanten Informationen über Ihre Umgebung und deren Beziehungen. Extrahieren Sie die Datei mit gzip -d path/to/file.gz. Vergewissern Sie sich, dass in der generierten .rdf-Datei keine Fehler enthalten sind (manchmal sehen Sie anstelle von gültigem RDF-Text in der Datei einen Python-Fehler, wenn etwas schief gelaufen ist).
Importieren von Daten in den Amazon Neptune-Cluster
Sobald unsere RDF-Datei erstellt ist, werden wir sie in unseren Neptune-Cluster importieren. Dazu müssen wir die Inhalte zunächst auf S3 hochladen. Am einfachsten ist es, sie über die Konsole hochzuladen, indem Sie zu S3 → Ihr Bucket navigieren und die Datei per Drag&Drop auf die Oberfläche ziehen.
Wenn die Datei hochgeladen ist, müssen wir eine POST-Anfrage an den Neptune-Cluster stellen, um die Daten zu importieren. Sie können dies von der Lambda-Funktion oder einer EC2-Instanz aus tun.
curl -X POST -H 'Content-Type: application/json' <NEPTUNE-ENDPOINT>:8182/loader -d '{"source":"s3://<S3-BUCKET-NAME>/master.rdf","format": "rdfxml","region":"<REGION>","failOnError":"FALSE","parallelism":"MEDIUM","iamRoleArn":"<NEPTUNE_ROLE_ACCESS_S3>","updateSingleCardinalityProperties":"FALSE","queueRequest":"TRUE"}'Wenn Sie eine 200: OK-Antwort sehen, werden die Daten in Neptune geladen. Warten Sie ein paar Minuten, bevor Sie fortfahren, um sicherzustellen, dass alle Daten geladen wurden.
Eine Alternative zu Amazon Neptun
Wenn Sie fortfahren möchten, ohne Amazon Neptune zu verwenden, können Sie eine lokale Instanz von Blazegraph starten und in Ihrer eigenen Umgebung damit arbeiten.
Abfrage der Datenbank
Jetzt müssen wir die Datenbank abfragen, um Informationen über unsere Umgebung zu erhalten. Über das Amazon Neptune Dashboard müssen Sie, falls Sie dies noch nicht getan haben, eine Notebook-Instanz erstellen. Dadurch wird eine Instanz mit Zugriff auf Jupyter erstellt, einen von Notebook verwalteten Dienst, der Abfragen an Ihre Graphdatenbank vornimmt. Sie können dies interaktiv über die Konsole tun, da der Vorgang selbsterklärend ist.
Sobald die Instanz erstellt ist, können Sie sie im Menü "Notizbücher" auswählen und im Dropdown-Menü "Aktionen" die Option "Jupyter öffnen" wählen.
Sie werden dann zum Jupyter-Front-End-Menü weitergeleitet. Standardmäßig ist ein Ordner namens Neptune mit verschiedenen Beispiel-Notizbüchern vorhanden, in denen Sie Beispieloperationen in der Gremlin-Sprache durchführen können. Dies ist zwar für den Einstieg interessant und um mehr über die Funktionsweise von Notizbüchern zu erfahren, aber wir werden unsere eigenen erstellen.
Klicken Sie auf die Dropdown-Schaltfläche "Neu" in der oberen rechten Ecke des Stammordners und fügen Sie einen Ordner namens AWS Altimeter Visualization hinzu. Klicken Sie dann auf dieselbe Schaltfläche "Neu" und erstellen Sie eine Python 3-Datei, z.B. SampleQueries.ipynb, die in dem soeben erstellten Ordner enthalten ist.
Wenn Sie das neue Notebook aufrufen, sehen Sie diesen Bildschirm:
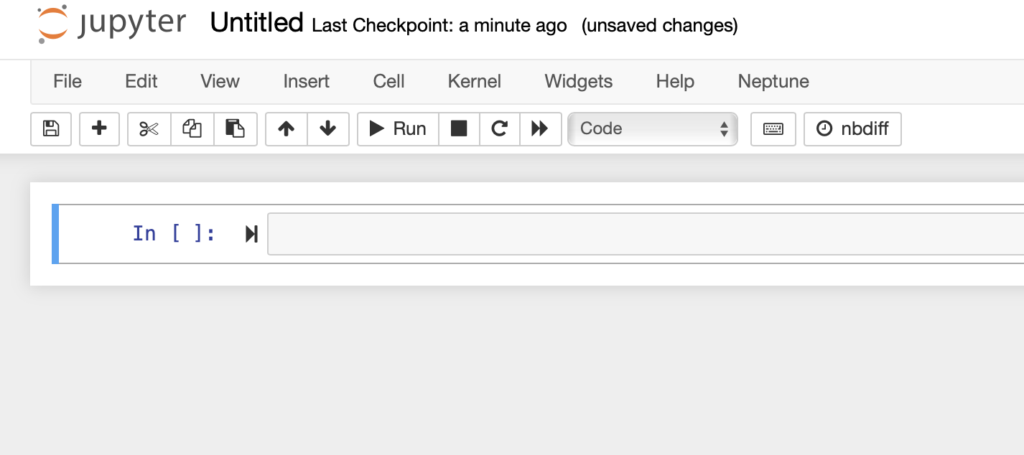
Notizbücher verwenden Zellen, die bearbeitbare Formatblöcke sind. Eine Zelle kann eine Codezelle, eine Markdown-Zelle oder eine rohe NBConvert-Zelle sein. Wählen Sie im oberen Menü 'Einfügen' und 'Zelle oben oder unten einfügen'. Im Bereich 'Zelle' können Sie zwischen den Zelltypen wechseln. Code-Zellen sind ausführbare Blöcke, während Markdown nützlich ist, um Notizen und Kommentare zu machen.
Lassen Sie uns nun ein Beispiel für SPARQL-Abfragen erstellen. Fügen Sie in einer Codezelle Folgendes ein:
%%sparql
select ?launch_time ?ec2_instance_id ?sg_id ?public_ip_address ?from_port ?to_port
where {
?ec2_instance a <alti:aws:ec2:instance> ;
<alti:id> ?ec2_instance_id ;
<alti:account> ?account ;
<alti:public_ip_address> ?public_ip_address ;
<alti:state> 'running' ;
<alti:launch_time> ?launch_time ;
<alti:security-group> ?sg .
?sg <alti:id> ?sg_id ;
<alti:ingress_rule> ?ingress_rule .
?ingress_rule <alti:ip_protocol> 'tcp' ;
<alti:from_port> ?from_port ;
<alti:to_port> ?to_port
FILTER (?from_port <= 22 && ?to_port >= 22)
} order by desc(?launch_time)Dadurch werden die EC2-Instanzen aufgelistet, die eine öffentliche IP haben und Port 22 geöffnet ist. Wenn Sie auf 'Ausführen' klicken, werden die Ergebnisse mit Informationen über jede Instanz angezeigt, sofern mindestens eine davon zutrifft.

Weitere Beispielabfragen finden Sie in der offiziellen Altimeter-Dokumentation.
Schlussfolgerungen:
Was sind die Einschränkungen?
Wie bereits in der Einleitung erwähnt, ist für viele geschäftliche Anwendungsfälle eine proprietäre Software die richtige Wahl. Altimeter hat eine begrenzte Dokumentation und liefert zwar viele Informationen, aber es ist nicht einfach, die Ausgabe zu kategorisieren und einzuschränken, ohne auszuprobieren.
Da es sich um ein Gemeinschaftsprojekt handelt, können Sie außerdem auf Inkompatibilitäten oder fehlende Unterstützung für neuere Versionen von Abhängigkeiten stoßen. Ich bin in meiner MacOS-Umgebung auf einen Fehler gestoßen, bei dem eine der Abhängigkeiten von Altimeter einen veralteten Verweis auf collections.MutableMapping hatte, der durch collections.abc.MutableMapping ersetzt werden musste.
Was kann ich also damit anfangen?
Altimeter bietet eine Open-Source-Alternative, mit der Sie innerhalb weniger Minuten eine komplexe Graph-Datenbank mit Ihren Cloud-Informationen füllen können. Aufgrund der Komplexität sind in den meisten Fällen andere Überwachungsalternativen die richtige Wahl, aber für Fälle, in denen die Informationen mit künstlicher Intelligenz und/oder maschinellem Lernen verarbeitet werden müssen, sind die in Amazon SageMaker integrierten AWS Notebooks ein möglicher Weg, den es zu erkunden gilt. Es ist auch nützlich, um Netzwerkanalysen durchzuführen.
Da die Datenbank mit Daten aus einem S3-Bucket gefüttert wird, können Sie die Versionierung aktivieren, um eine Momentaufnahme des Zustands einer Cloud-Umgebung zu erstellen und historische Analysen zu bestimmten Zeitpunkten durchzuführen.
Und schließlich bedeutet Open Source, dass Sie Altimeter auch erweitern können, um es in Ihren internen Projekten zu verwenden. Vielleicht ein Front-End, um damit zu arbeiten, API-Integrationen mit der Graph-Datenbank oder eine Dashboard-Lösung für interne AWS-Konten auf der Grundlage von Analysedaten. Dies könnte ein großartiges experimentelles Tool für Forschungsteams sein, die ein ähnliches Ziel vor Augen haben und die Anforderung haben, erweiterbar, offen und kostenlos zu sein.
Verfasst von
Martin Perez Rodriguez
DevSecOps and Cloud specialist at Xebia Security
Unsere Ideen
Weitere Blogs




Contact