
If you've worked in software development for any amount of time, you're probably used to working in a certain way, and have been in the situation where a new tool forces you to change your way of working. Some may also think that using tool X automatically means following process Y. For example, "We're using ArgoCD, therefore we're doing GitOps, right?" Don't get me wrong, adapting to a new(er) tool may introduce better practices, yet it becomes a problem when it obscures underlying issues. These are some common examples you're likely to run into:
The resurgence of branches
Back when Git became the standard (side note, yes, I'm old enough to have worked with Subversion) many branching strategies such as Git Flow, Github Flow and environment-based branching and workflows were thought up, to try to separate unstable, in-development code from releasable code. At some point most teams started to do Continuous Integration and Continuous Delivery, and it seemed like the consensus became that trunk-based development with short-lived branches was the best way to do CI/CD. This shortens feedback loops, improves collaboration, and is the quickest way to bring issues with software quality to light. But lately there's been a resurgence of increasing the amount of branches in order to accommodate different environments, often within the context of GitOps, infrastructure and containerized applications.
Consider the following branching strategy:
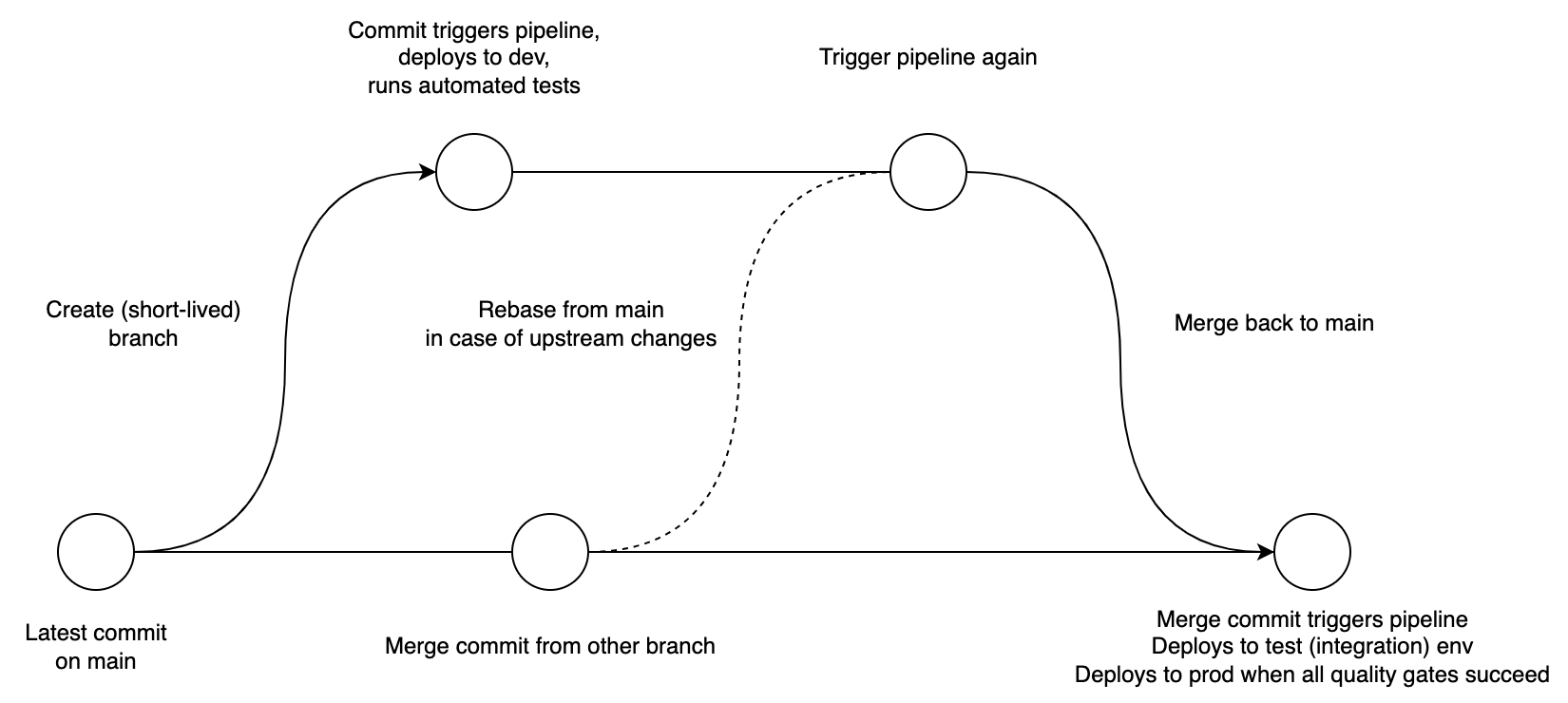
This workflow shows a developer creating a branch from main, deploying to a dev environment, and running all kinds of automated tests and checks there. When this all succeeds, the branch can be merged back into main, where the application is deployed to a test environment, and when ready (or automatically) followed by a deployment to production. Note that since you’re rebasing main into any branches whenever main changes, you can even omit the “deploy to test” step, as integration tests can run against branches as well.
This is the simplest approach to branching one could take, and when you make sure all branches are short-lived (ideally merged within a day) and all tests are automated, should give you the shortest feedback loops and the least amount of risk.
Now, let’s look at the same workflow when all environments are tied to branches:
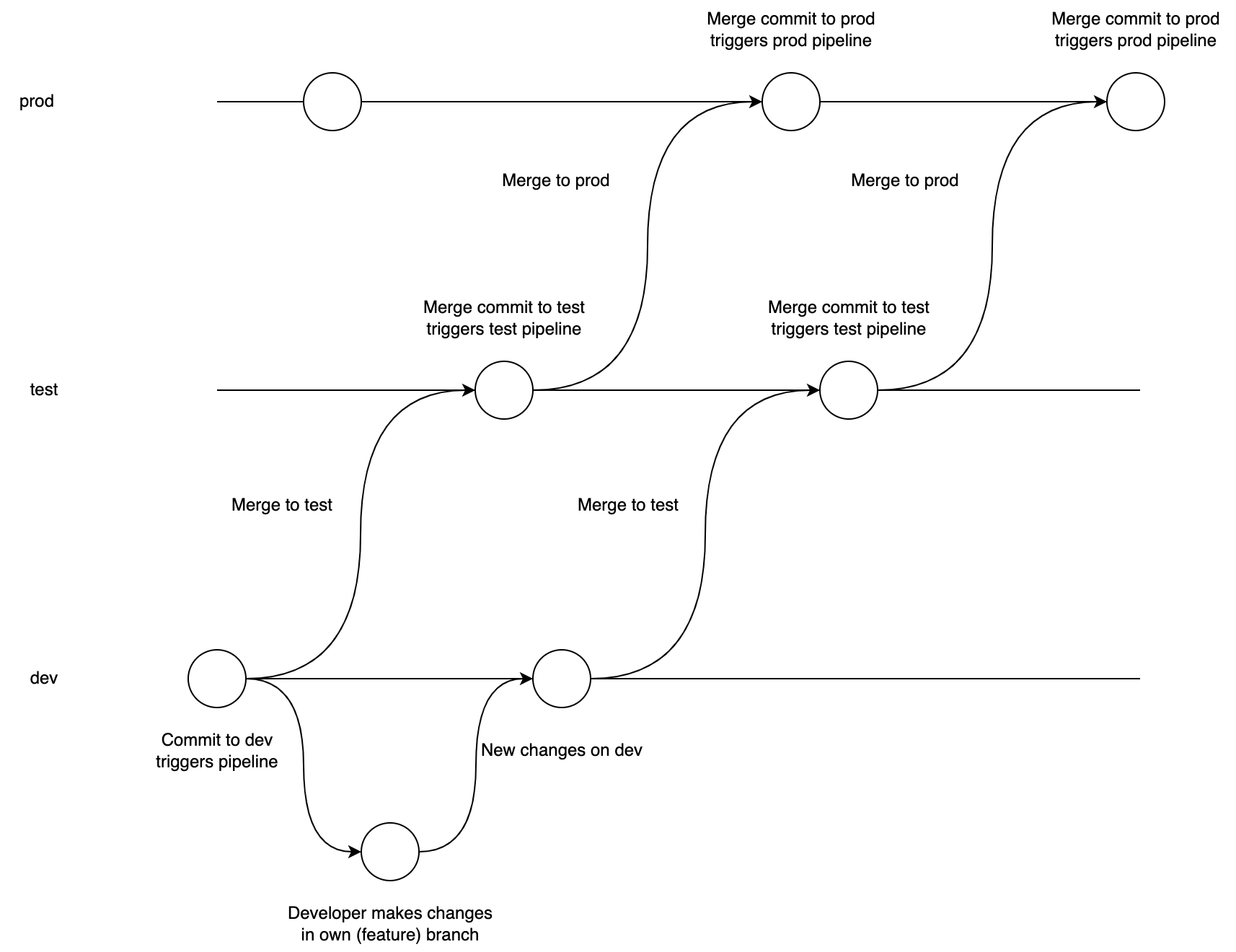
As you can see, this is much more complex than the previous approach, and it could get even more complex if developers create their own branches (short-lived or otherwise) for new features on top of the dev branch. Besides more complexity adding more ways for things to go wrong, this also delays feedback loops, as merging between environments is often done manually. In addition, it’s now easy to accumulate changes on the dev or test environments before daring to go to production, as there’s not a single, coherent pipeline that takes a change across all environments. To clarify, rather than each merge to main automatically and immediately going to production after it passes all quality gates, it’s now easier to postpone this by simply delaying merging (deliberately or not) from dev to test, or from test to prod. This leads to delayed feedback and ultimately higher risk per release.
If this has convinced you to reconsider, going back to the trunk-based approach may seem easier said than done, as tools promoting the environment-based approach are usually tightly coupled to it. However, there are often ways to work around this while still using your preferred tools. You could look at using tags instead of branches and automatically tagging a specific commit on main whenever the pipeline passes a certain stage. For example, when the pipeline passes the “test” stage, you could tag that commit with “test”. Another approach would be to use environment-specific configuration files and templating to differentiate across environments, all within the same branch.
Drift detection and automated reconciliation
Often cited as the main advantage of GitOps, and the tools that market themselves as GitOps tools, is some way to detect drift between a live environment and the source of truth in Git, and then automatically reconcile that drift. Here’s my concern: if Git is the source of truth, this means all changes should come from a Git commit and go through CI/CD. This also means your environments should be immutable by anything besides whatever you're using for deployments. Basically engineers should not be able to change your environments manually, especially production. The fact that there is drift in the first place shows you have a problem which won't be solved by using a GitOps tool - such a tool will only hide the problem by automatic reconciliation.
For example, it could be that a manual change occurred to quickly fix an issue, while it wasn’t documented “as code” afterwards. Or you may even find that there’s some background agent running which modifies resources at runtime.
Instead of automatic reconciliation, I propose merely alerting on drift instead. This way you can investigate not just what resource has drifted, but also its cause. After investigating, resolve the drift by fixing the source of the problem. This could be as simple as disallowing manual changes, or if that isn't an option, implementing (or forcing) a process where those manual changes are always added as code to Git afterwards.
Low-code and the loss of engineering practices
Low-code and no-code platforms are gaining traction, and it has become easier than ever for anyone to build applications. What is often forgotten, is the fact that even though it's easy to build and deliver these software applications, it's still software. There is still code underneath the process diagrams and UIs. Therefore, in order to create a high-quality application, especially if it’s not just a one-off app, you will still need to apply engineering best practices. You still have to think about architecture, implement automated tests and other quality gates in a CI/CD pipeline, you will have to monitor it and think about observability, and you will have to make sure it’s maintainable and extendable (as software systems have a tendency to change). Some of these platforms may claim that they take care of these things for you, but in the end they’re “just” platforms. They don’t build the actual application for you, nor maintain its functionality. As a result, it’s often too easy to forget that it requires an engineering mindset to prevent running into quality issues down the line.
Conclusion
The common denominator among these issues is this: when a tool is too opinionated on a certain way of working, and makes this process easy, it also becomes easy for issues with your application to become hidden. Fortunately, the solution is also simple: don’t just use a tool or a certain feature of a tool because you can, but also think about why you are using it. Ask questions like:
- Why am I letting this tool automatically reconcile drift, and don’t I want to know why the drift occurred?
- Why am I using this low-code platform; is it because I quickly want to create a one-off app, or because I think I won’t have to do any engineering?
- And do I really need so many branches?
Asking these questions will at least make you understand why certain decisions are made and hopefully also put you on track to considering better-suited alternatives.
This blog is part of our series "Holistic Horizons". Check out the previous entry - "The Shift Beyond the Hype: Transitioning from Vanity Metrics to Authentic Business Objectives” by Kateryna Zhuzha. Or read further to the next article - "The three forms of CI / CD" by Dave van Stein.
Written by
Tariq Ettaji
Software Delivery Consultant
Our Ideas
Explore More Blogs


From Spec to Code: Building Software with Spec Kit
This article walks through the full workflow, from installation to a working implementation, covering both greenfield projects and extending an...
Hidde de Smet, Emanuele Bartolesi


Contact