Blog
How to Get the Most Out of Your Agents: Multi-Agent Systems

In the previous post we shared our experience with dealing with the context of an AI agent. We discussed several strategies for keeping control over the context of a single agent. In this post we will focus on creating a workflow with multiple agents: how does that work, and why would you want multiple agents anyway?
If you've followed the trend, you must have heard about multi-agent systems — sometimes presented as a multiplier for agents, as if their productivity scales linearly, or even exponentially, with their number. In practice, adding more agents also adds complexity, so it is worth asking: when do you actually need a multi-agent system?
When do you need multiple agents?
Imagine we want to design a system that can provide a balanced summary of a news story. Suppose we want to do this with a single agent, which we give access to tools that can retrieve news articles from several sources, as well as do web search. We could then give the agent instructions to follow a plan like this:
- Interpretation: Interpret the user’s query and create an outline.
- Fact search: Gather objective facts with broad, unbiased web searches.
- Viewpoints: Determine the different viewpoints on the story.
- Perspective search: Research these viewpoints with perspective-based deep web searches.
- Draft: Synthesize all research into a structured draft.
- Review: Review the draft for bias, balance, and accuracy, based on the unbiased web searches.
- Write: Write the final, polished summary.
A single agent can, in principle, perform tasks like these. However, as the task requires gathering a lot of information, it is likely that sometimes (or even often) it runs out of context, fails to follow instructions, or does something else entirely (like write a poem), due to attention issues as described in the previous post.
Of course, instructions like above are far too concise for a task like this. For example, for the fact search (step 2) we would have to elaborate on how to gather objective facts, what we consider reliable sources, and how to evaluate the reliability of an unknown source. And for the perspective search (step 4) we would give instructions for web searches that are quite the opposite of those for step 2; instead of looking for facts, the agent would be looking for opinions. It would be likely that the agent would (at least partially) be distracted by the contradicting instructions when conducting those steps.
A potential solution to this issue would be to use multiple agents. We could, for example, have an agent for each of the steps, each with their own instructions, and instructions on how to hand over to the next agent once they have completed their task.

While a setup like this is more likely to perform research according to the instructions, it is still likely to suffer from out-of-context or attention problems: each of the agents always has the entire history of inputs, messages, tool calls, and results in its context.
Multi-agent workflows with structured data
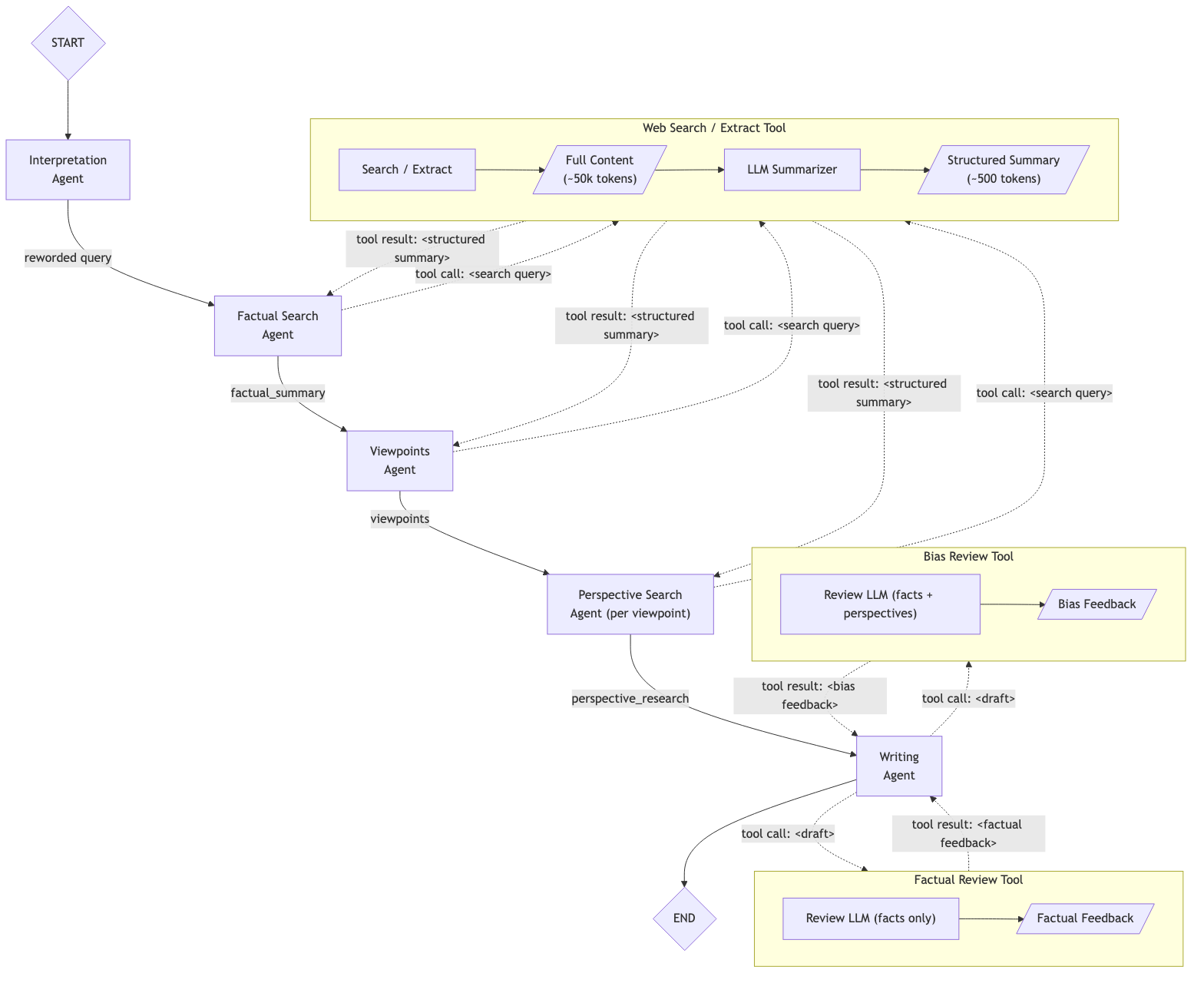
A far better solution would be to break up the workflow into a series of steps, each with its own instructions and goals, that communicate solely with structured information. This could look, for example, like the figure below, but a workflow containing a separate agent for each of the seven steps might work even better.

The structured information that would be passed between the agents could look something like this, where each of the fields would only be filled after the respective agent has finished work:
{
"outline": "...",
"factual_summary": "...",
"perspectives": {
"viewpoint_a": "...",
"viewpoint_b": "..."
},
"final_summary": "..."
}
This would ensure that the thought processes of the agents, as well as the raw search results, would not enter the context of the other agents: only the final result of each agent would make it into the context of the following agents. We can even take more control: we do not have to provide each agent with the full structured result, but can instead provide only the fields in the context that are relevant to the respective agent.
A workflow like this gives you a lot of control over the information flowing through, which can be beneficial, but it is not perfect yet. For example, it is likely that when doing the review (step 6), in which the summarizer is supposed to review the draft based on only neutral facts, it gets ‘distracted’ by the results of the perspective-based analysis (step 4). As long as those results are in the context, there is no guarantee that the review is based only on the neutral facts. However, since the last agent does require the perspective-based analysis in order to write the final summary, we cannot remove the perspective-based analysis from its context.
Agents-as-tools
We can fix this, as well as potential context overflows caused by large search results, by implementing agents-as-tools.
For example, we can create a tool that reviews a draft based on (only) the objective facts, and by making sure we do not provide any opinions as input, this agent is likely to be neutral. The summarizer agent can call this tool once it has prepared a draft, and repeat the call if necessary.
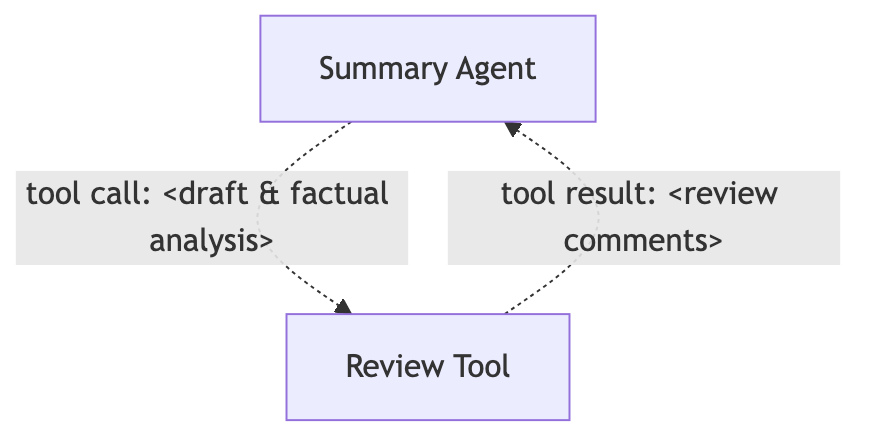
Web search as an agent
Similarly, we can implement a search tool that pre-summarizes the search results, preventing context overflow. The resulting workflow becomes a little more complex, but it will be much less likely to run out of context, lose attention, write you a poem, or create a biased summary. So instead of a tool that expects a URL or search query and extracts the content of that page(s), the agent will get access to a tool that expects a URL or search query and a description of the information it wants to extract. This tool will return a summary of the requested information. This allows the agent to do multiple searches and page lookups sequentially, without filling its context with irrelevant information, as that irrelevant information will be filtered out by the tool.
To understand why this matters, consider what happens without it. A standard web search tool returns raw page content directly into the calling agent's context. A single page can contain tens of thousands of tokens, most of which are irrelevant to the task at hand. After just a few searches, the noise dominates the agent's context.
With a web-search agent-as-tool, the sub-agent fetches the raw content and proceeds to extract only the information relevant to the query before returning a compact, structured summary. The calling agent never sees the raw page content. Instead, it sees only the information it requested.
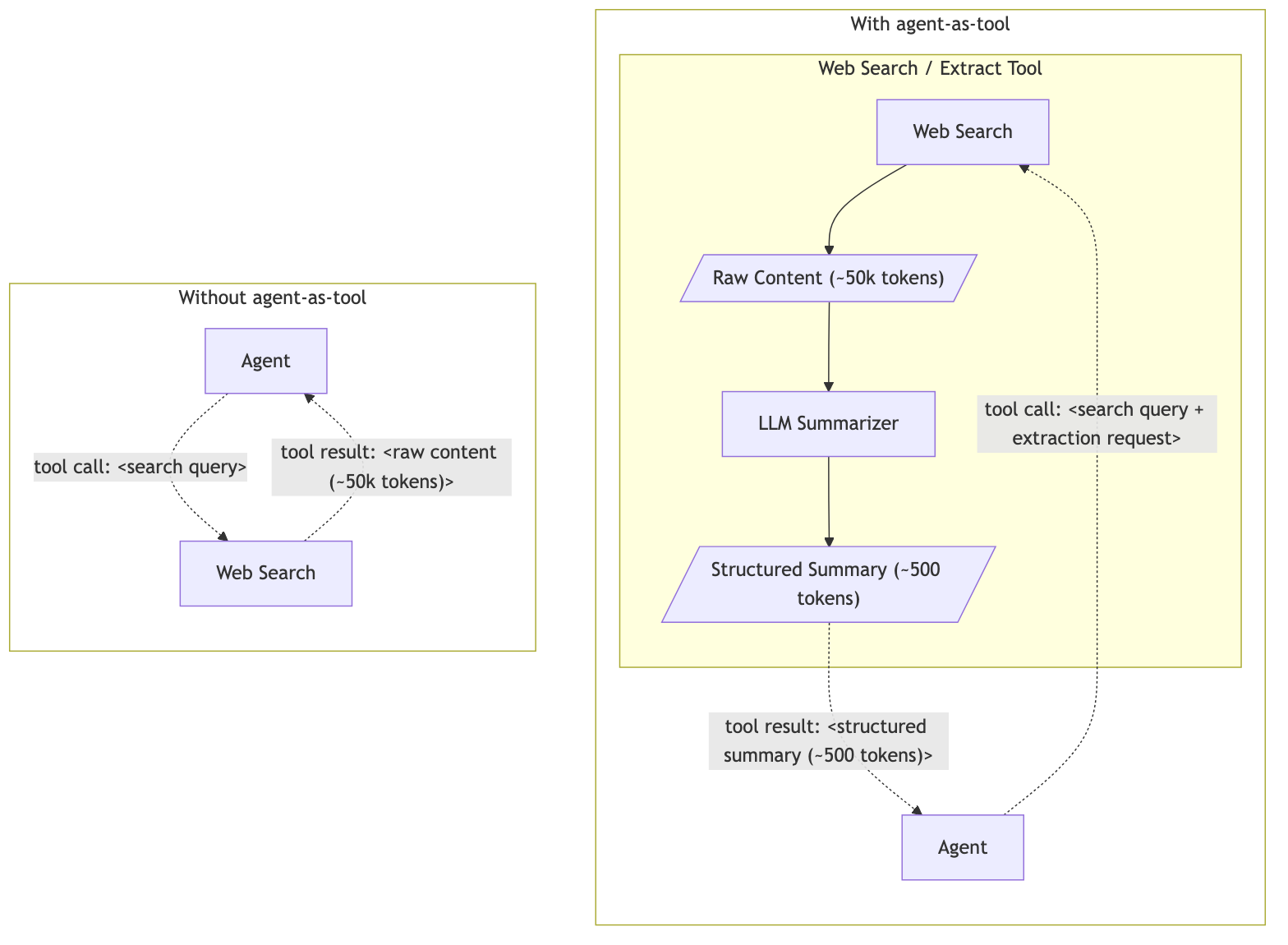
In our experience, this reduces the data returned per search call by 90–98% compared to raw content. The main agent can make many more searches before hitting context limits, and its attention stays focused on the task rather than sifting through noise. The trade-off is an extra LLM call per search, which adds some latency — but we found this a worthwhile cost given the reliability gains.
The complexity does, unfortunately, bring a set of new problems. Debugging becomes a lot more complicated, for example. Debugging issues in a complex agentic workflow requires a good tracing and visibility setup, and that is something we’ll dive into in one of the following posts in this blog series. In addition, creating effective tools, especially those that incorporate agents, requires a lot of attention (of you, not of the agent), which we will also leave for a later post.
Conclusion
In short, multi-agent systems are not the exponential multiplier for productivity they are sometimes said to be. They are, however, the right tool when a single agent struggles with attention or context limits.
A structured chain of agents, where the agents communicate solely with well-defined data fields, goes a long way. It keeps each agent focused on a single task and prevents earlier reasoning or irrelevant information from entering the context of later agents. Furthermore, implementing agents-as-tools gives you an even finer level of control: a review tool that only sees neutral facts cannot be biased by opinions it has never seen, and a search tool that pre-summarizes the search results can be used to reduce the amount of context by an order of magnitude.
However, each layer of structure adds complexity, extra LLM calls, and harder-to-debug issues. In our experience, the reliability gains are worth the cost, especially for tasks where accuracy is essential.
Written by
Rogier van der Geer
Our Ideas
Explore More Blogs




Contact