Blog
Managed Apache Flink: How to Choose Between Confluent Cloud and Ververica Cloud

Kafka and Apache Flink have become a standard stack for low-latency stream processing. Together, they help data teams process events in real time, build streaming pipelines, and support operational use cases that cannot wait for batch processing.
How should teams choose between Confluent Cloud and Ververica Cloud for managed Apache Flink?
Teams should choose Confluent Cloud when they want an integrated Kafka + Flink platform with managed Kafka, Schema Registry, connectors, governance, and minimal setup. Ververica Cloud is a stronger fit when teams need broader Flink API flexibility, custom applications, multi-language pipelines, or advanced stateful stream processing.
Running Kafka and Flink in production requires expertise in tuning, observability, upgrades, incident response, scaling, and cost control. That is why many organizations consider managed platforms. The goal is not only to reduce infrastructure work, but also to give data teams more time to build reliable business pipelines.
In this article, we compare Confluent Cloud and Ververica Cloud as managed Apache Flink options. Both platforms support real-time stream processing, but they are built around different philosophies. Confluent Cloud is Kafka-first, with Flink as part of a broader data streaming platform. Ververica Cloud is Flink-first, focused on the full Flink development and runtime experience.
Why do teams choose managed Apache Flink platforms?
A self-managed Kafka and Flink stack gives engineering teams a high level of control, but that control comes with operational responsibility. Teams need to provision clusters, tune jobs, manage upgrades, monitor failures, configure security, and respond to incidents.
Managed Apache Flink platforms change the operating model. Instead of spending most of their time maintaining infrastructure, teams can focus on building streaming applications, improving data quality, and delivering real-time data products. Managed services may look more expensive at the unit-price level, but the total cost of ownership often changes once platform engineering time, incident response, and maintenance are included.
The key question is not whether managed Flink is useful. The more important question is which managed Flink platform fits your architecture, team skills, and workload patterns.
What does Confluent Cloud offer for managed Apache Flink?
Confluent Cloud is a managed data streaming platform built around Apache Kafka. It combines managed Kafka, Schema Registry, Kafka Connect, governance features, stream lineage, and managed Apache Flink in a single ecosystem.
This Kafka-first design is the main advantage. Kafka topics and schemas are treated as first-class platform objects, which makes Confluent Cloud attractive for teams that already use Kafka as the backbone of their event-driven architecture. Flink can work closely with Kafka topics, and the platform reduces the amount of manual integration required between streaming, schema management, governance, and connectors.
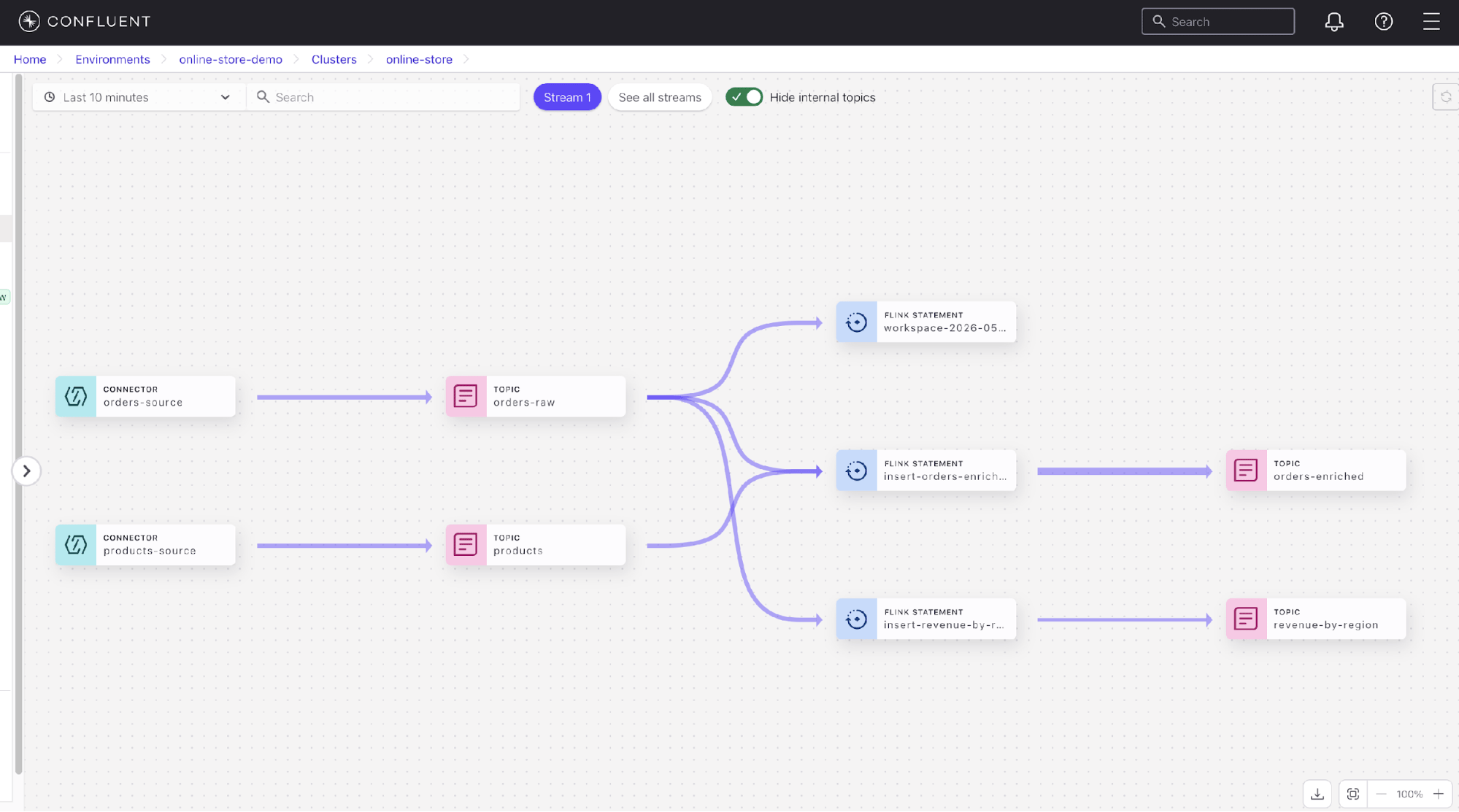
Figure 1. Confluent Cloud stream lineage view showing connectors, Kafka topics, and Flink statements.
Confluent Cloud is especially strong for teams that want to build Flink workloads without managing separate Kafka infrastructure. It provides a browser-based SQL workspace, REST API, Confluent CLI, and Terraform support for infrastructure-as-code workflows. Its compute pools scale automatically, so teams do not need to manually size and operate Flink clusters for typical workloads.
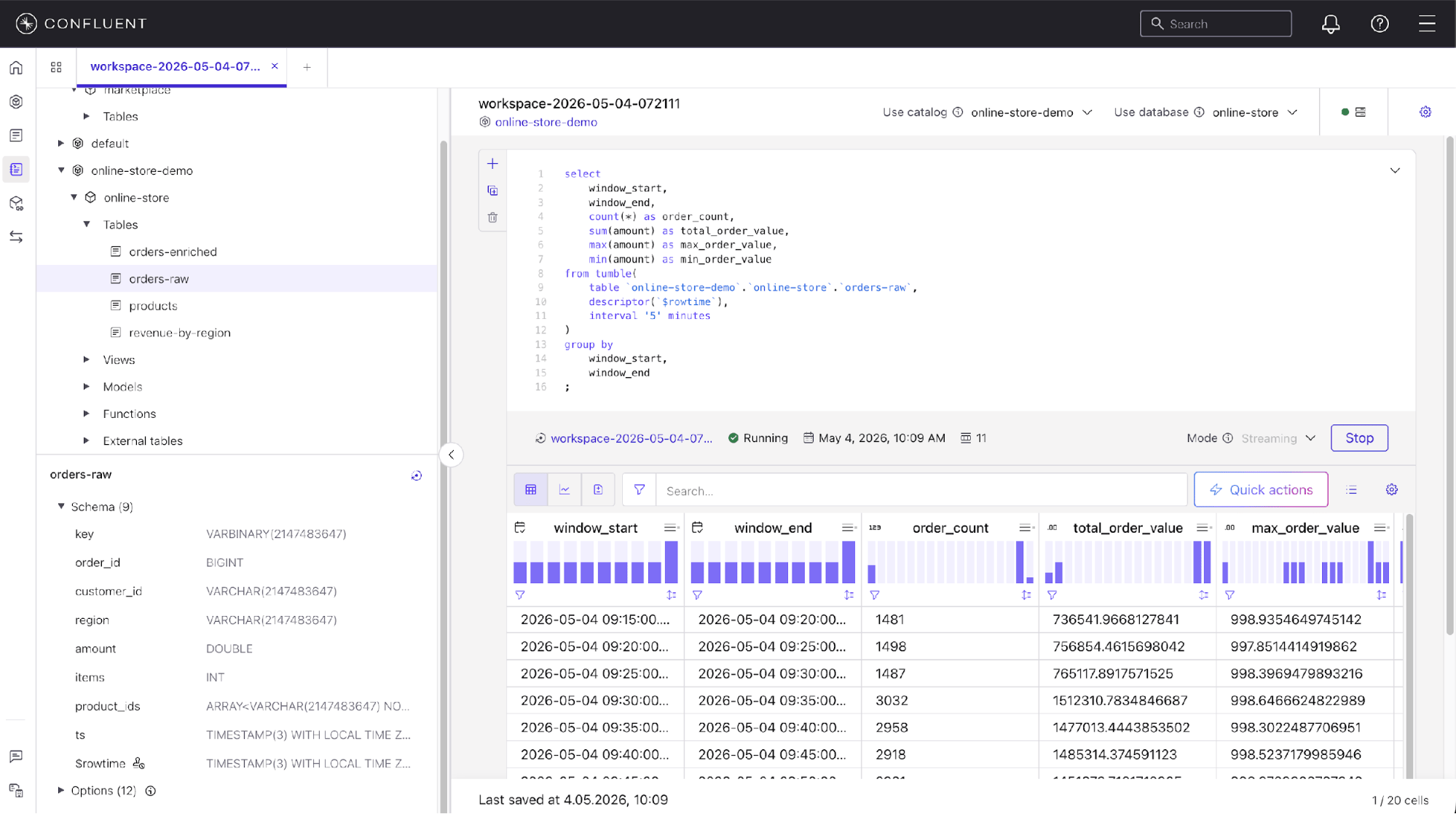
Figure 2. Confluent Cloud SQL workspace for Flink query development and result inspection.
Where does Confluent Cloud work best and what are its trade-offs?
Confluent Cloud works best when teams want managed Kafka and managed Flink in one platform, and when stream processing requirements can be expressed mainly through Flink SQL or Table API-style development. This makes it a strong fit for data enrichment, filtering, joins, aggregations, materialized views, and real-time pipelines that do not require the full low-level flexibility of the DataStream API.
The main trade-off is API flexibility. Confluent Cloud is optimized around SQL and Table API workflows, with Table API support for Java and Python currently positioned as a preview capability in the documentation. For teams that need custom state handling, advanced event-time logic, highly specialized operators, or full DataStream API control, this can be limiting.
There are also workload boundaries to consider. Very large stateful jobs may run into state-size or compute limits, and they may become better suited to a dedicated platform team or a more Flink-native managed environment. Confluent Cloud can still be a strong choice, but teams should validate large stateful workloads before committing to the platform.
What does Ververica Cloud offer for managed Apache Flink?
Ververica Cloud takes a Flink-first approach. Ververica was founded by the original creators of Apache Flink, and its platform is designed around stream processing rather than around Kafka as the central product.
The biggest differentiator is API breadth. Ververica is a better fit for teams that want to work across Flink SQL, Java-based DataStream applications, and Python-based Flink development. This flexibility matters when teams are building custom streaming applications rather than only SQL-based transformations.
Ververica also provides VERA, its enterprise Flink runtime layer. VERA includes proprietary enhancements on top of Apache Flink, including Gemini for large stateful workloads, advanced CDC capabilities, Dynamic Complex Event Processing, and other runtime improvements designed for operationally demanding streaming applications.
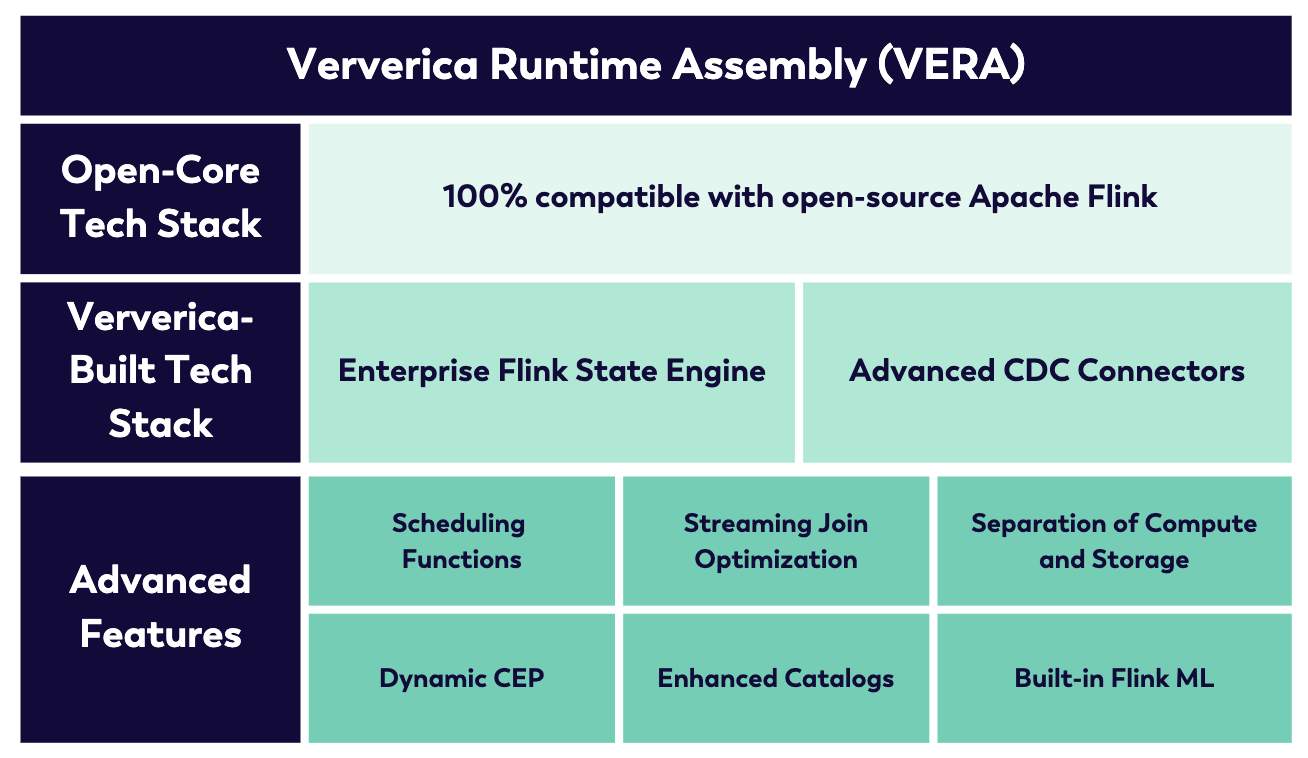
Figure 3. Ververica Runtime Assembly (VERA) overview.
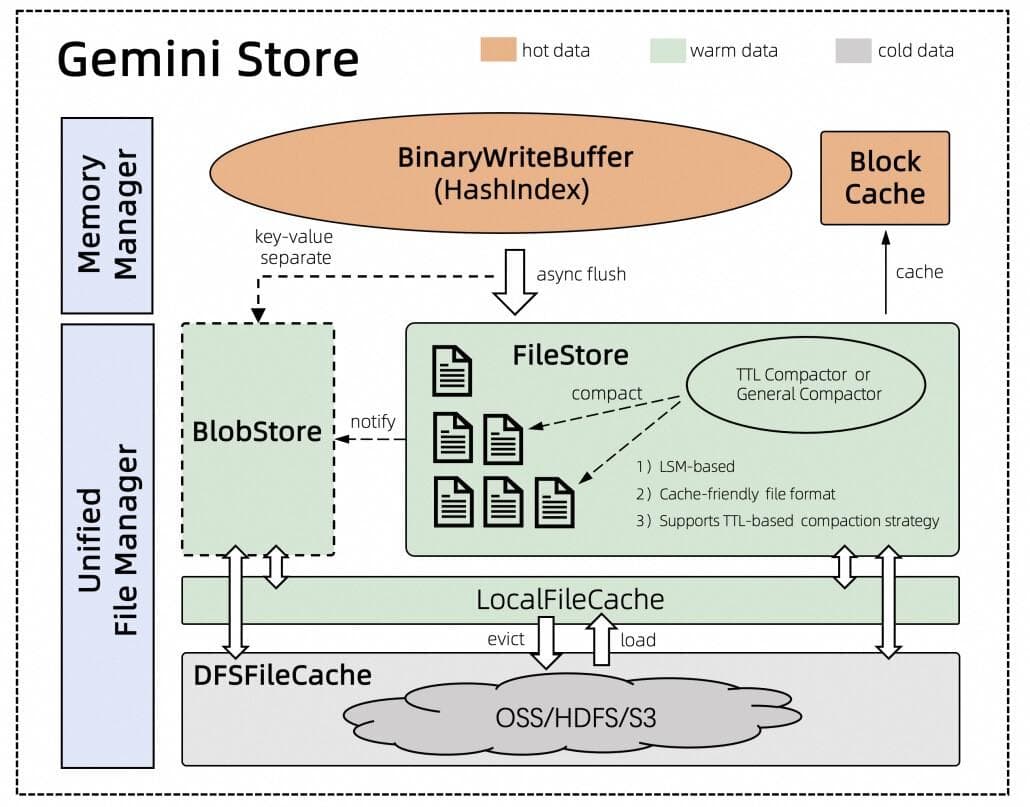
Figure 4. Gemini state backend architecture. Image source: Alibaba Cloud blog.
Because Ververica is Flink-first, it is particularly attractive for teams with strong Flink skills, complex stateful processing needs, or requirements that go beyond standard SQL stream processing.
Where does Ververica Cloud work best and what are its trade-offs?
Ververica Cloud works best when the Flink application itself is the center of the architecture. It is well suited for teams that need custom stream processing logic, complex event-time handling, multi-language development, large state management, or advanced stateful processing patterns.
The main trade-off is that Ververica does not provide the same integrated Kafka ecosystem as Confluent Cloud. Teams need to bring and operate their own messaging infrastructure or connect Ververica to an external Kafka service. They also need to integrate an external Schema Registry or governance layer if those capabilities are required.
This means Ververica can offer more flexibility for Flink-centric workloads, but it may require more architectural decisions around messaging, schemas, cataloging, and governance. For some teams, that is a benefit. For others, it creates additional integration work.
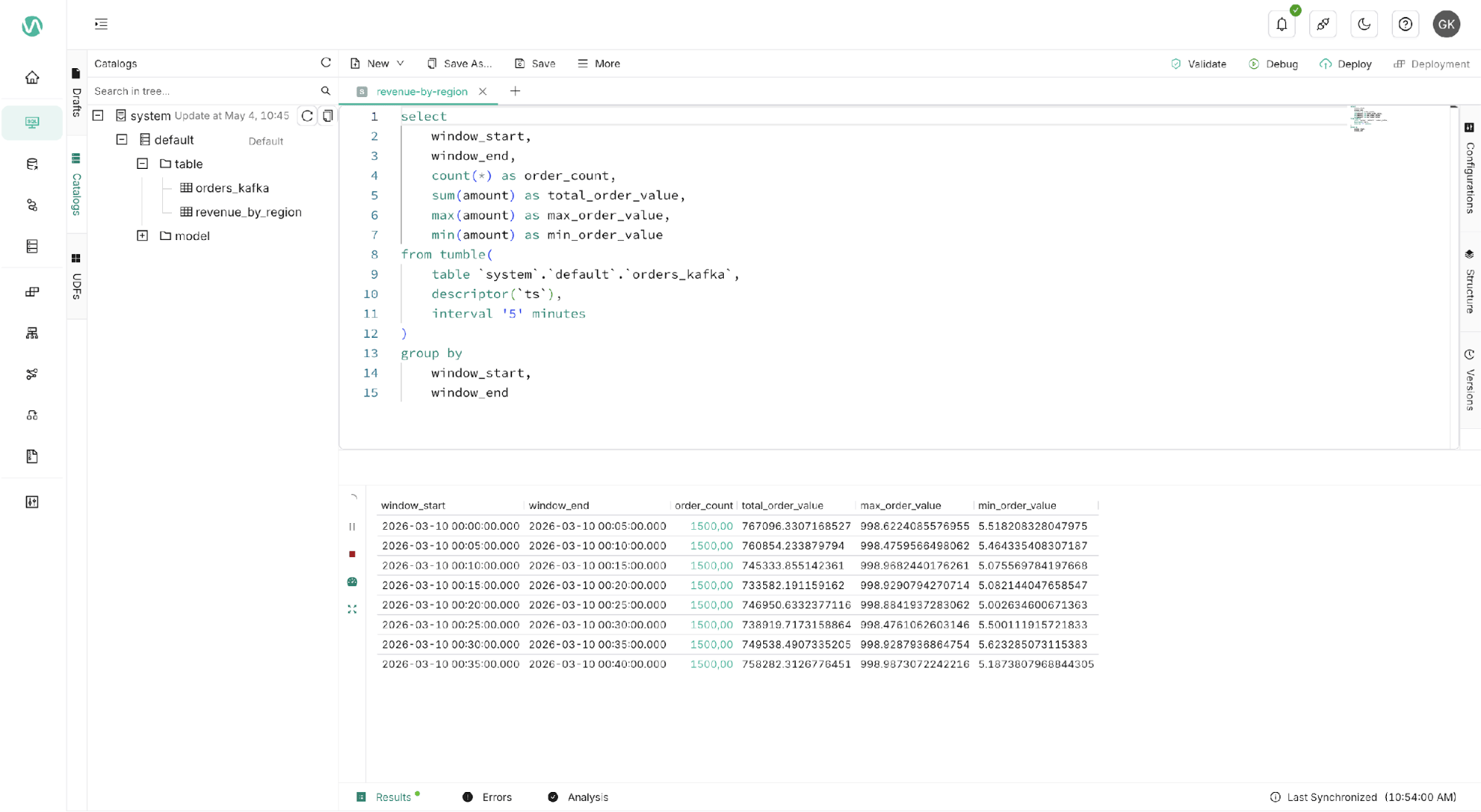
Figure 5. Ververica SQL editor with catalog view and query results.
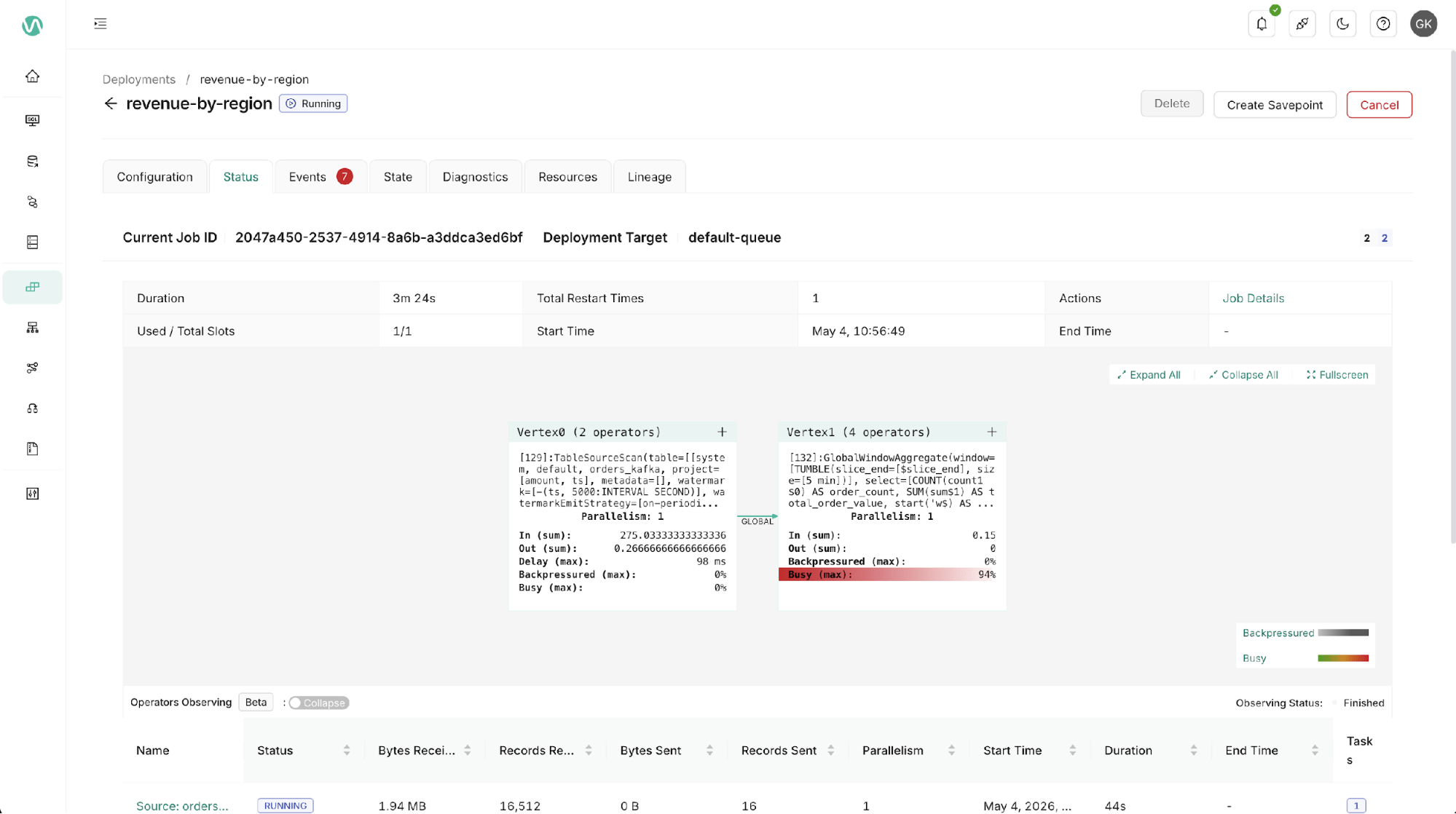
Figure 6. Ververica deployment status view with runtime operator metrics.
How do Confluent Cloud and Ververica Cloud compare?
The right platform depends on what your team needs to optimize for: integration, flexibility, operational simplicity, stateful processing, or existing Kafka investment. The table below summarizes the most important differences.
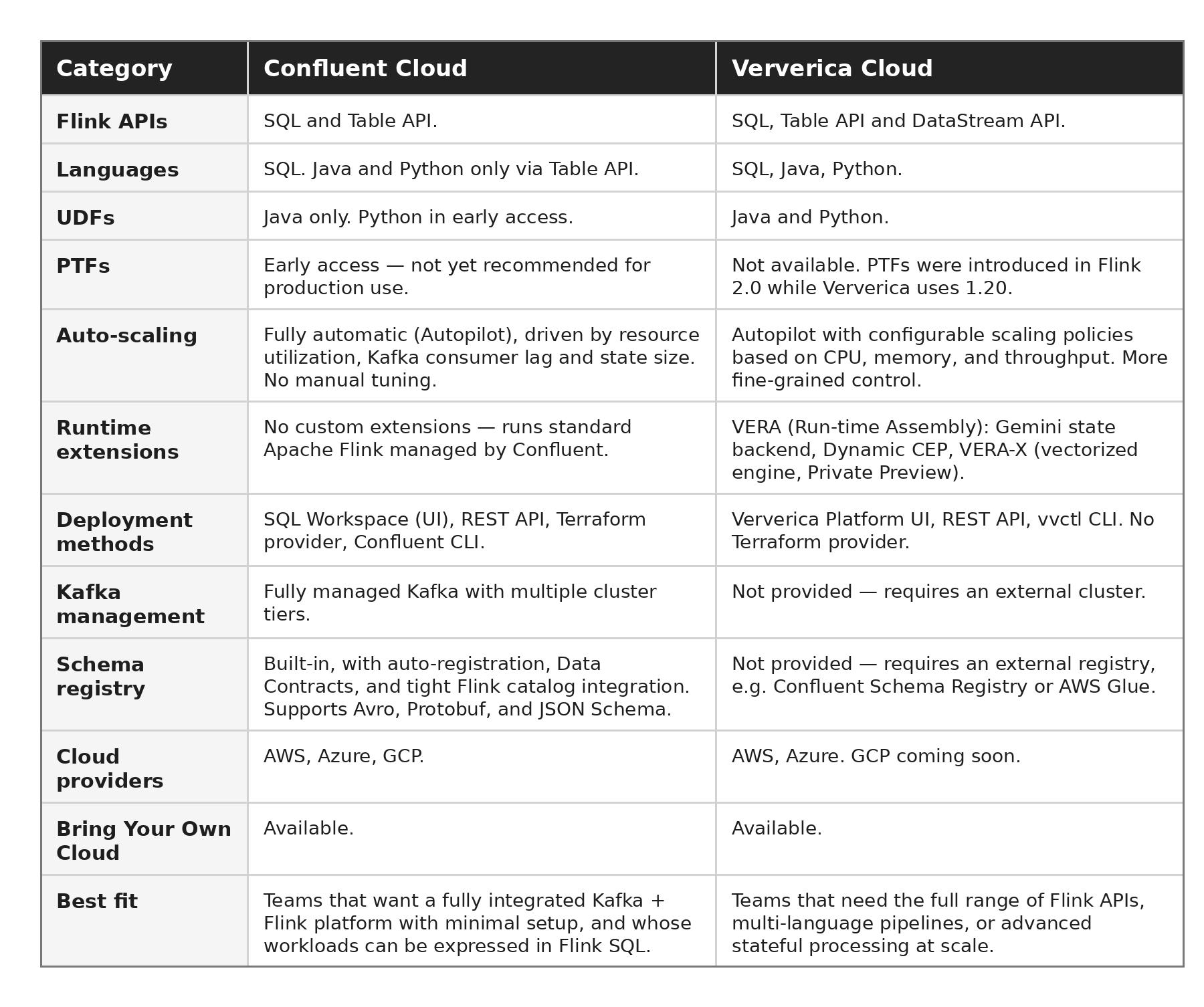
How should teams decide between Confluent Cloud and Ververica Cloud?
Choose Confluent Cloud if your team wants a fully managed Kafka + Flink platform with strong integration between topics, schemas, connectors, governance, and SQL-based stream processing. It is the more natural choice when operational simplicity and ecosystem integration matter more than low-level Flink control.
Choose Ververica Cloud if your team needs Flink as a first-class engineering platform. It is the stronger option when workloads require custom Flink applications, broader API flexibility, advanced stateful processing, or Flink-specific runtime features.
For many teams, the decision comes down to one question: are you buying a Kafka-centered streaming platform with Flink included, or are you buying a Flink-centered platform for advanced stream processing?
To sum up:
Confluent Cloud and Ververica Cloud both make Apache Flink easier to operate, but they solve different problems. Confluent Cloud is strongest when teams want an integrated Kafka + Flink experience with managed Kafka, Schema Registry, connectors, governance, and SQL-driven streaming workloads.
Ververica Cloud is strongest when teams need deeper Flink flexibility, multi-language development, custom stream processing applications, and advanced stateful processing. It gives Flink teams more room to build complex applications, but it also requires more decisions around Kafka, schema management, and surrounding architecture.
The best choice depends on your workload, team skills, and platform strategy. If your priority is integrated Kafka operations, Confluent Cloud is often the better fit. If your priority is full Flink capability and advanced stateful processing, Ververica Cloud is likely the stronger option.
Frequently Asked Questions
Written by

Grzegorz Kołakowski




Contact