
Erfolgsrezept für Finetuning LLMs
Auf der NeurIPS 2023 haben wir an der LLM Efficiency Challenge teilgenommen. Während der Konferenz traf ich mich mit den Gewinnern des Wettbewerbs und nahm an dem Workshop teil, in dem sie ihre Ansätze vorstellten. In diesem Blog teilen wir die wichtigsten Erkenntnisse über die Siegeransätze.
Die Herausforderung
Ziel des Wettbewerbs ist es, ein Large Language Model (LLM) so zu verfeinern, dass es bei einer Vielzahl von Aufgaben gut abschneidet. Die Regeln waren einfach:
- Verwenden Sie ein Open-Source-Basismodell.
- Verfeinern Sie es mit Open-Source-Daten, die von Menschen erstellt wurden.
- Auf einer einzigen GPU innerhalb von 24 Stunden.
Je nach GPU-Typ gab es im Wettbewerb zwei Spuren:
- 4090 Spur (24GB VRAM)
- A100 Spur (40GB VRAM)
Das Rezept
Was haben die beiden Gewinner getan? Im Allgemeinen war die Vorgehensweise der Gewinner bei beiden Titeln recht ähnlich.
- Beginnen Sie mit einem guten Basismodell, das bei relevanten Benchmarks gut abschneidet und bei der Inferenz effizient ist.
- Filtern Sie rigoros nach qualitativ hochwertigen Daten, indem Sie sie kuratieren und zwischen den Aufgaben abwägen.
- Effizientes Finetuning der Parameter kann mit LoRA oder QLoRA durchgeführt werden und wenn eine höhere Effizienz erforderlich ist, auch mit Flash Attention.
Machen Sie es zu Ihrem eigenen
Die Ansätze unterschieden sich darin, ob sie Quantisierung und Flash-Aufmerksamkeit verwendeten.
Ressourcen optimiert
Wenn Ihre Anwendung durch Speicherplatz, Zeit und/oder Kosten stärker eingeschränkt ist, sollten Sie die Verwendung von QLoRA und Flash Attention in Betracht ziehen. Seien Sie vorsichtig mit dem Quantisierungsverlust, messen Sie ihn während Ihrer Experimente. Flash Attention war zur Zeit des Wettbewerbs noch sehr innovativ, jetzt ist es in vielen Deep-Learning-Paketen integriert.
Weniger gezwungen
Wenn Sie etwas mehr Speicherplatz zur Verfügung haben, können Sie auch LoRA verwenden. Experimentieren Sie in beiden Fällen mit dem Rang. Wie Sie in diesem Blog gelesen haben, ist die Bandbreite, mit der Sie experimentieren können, recht groß. Der Rang der erfolgreichen Ansätze reicht von 8 bis 256.
Schauen wir uns die Besonderheiten der beiden unterschiedlichen Gewinnstrategien an.
4090 Track - Detaillierter Ansatz zum Gewinnen
Der Gewinner des 4090-Tracks war das Team Upaya. Ihr Ansatz war in mehrfacher Hinsicht einzigartig. Sie konzentrierten sich auf die Verallgemeinerung des Modells und verwendeten eine halbautomatische Datenkuration.
Auswahl und Vorbereitung der Daten
Das Team Upaya begann mit dem Super Natural Instructions-Datensatz. Sie wählten manuell relevante Aufgaben aus und gingen von 1600+ auf ~450 Aufgaben zurück. Die Aufgaben wurden dann in 2 Kategorien eingeteilt: Exact Match und Generierungsaufgaben. Das Basismodell wurde verwendet, um zu sehen, wo es bereits gut und wo es noch nicht gut ist. Zwischen den Aufgaben wurden mehr Generierungsaufgaben mit niedrigem Rouge-Score oder Exact Match-Aufgaben mit niedriger Genauigkeit ausgewählt. Sie haben ihre Stichproben auf ~50k aus jeder Kategorie abgeglichen. Das Ergebnis waren die ersten 100k Stichproben ihres Datensatzes.
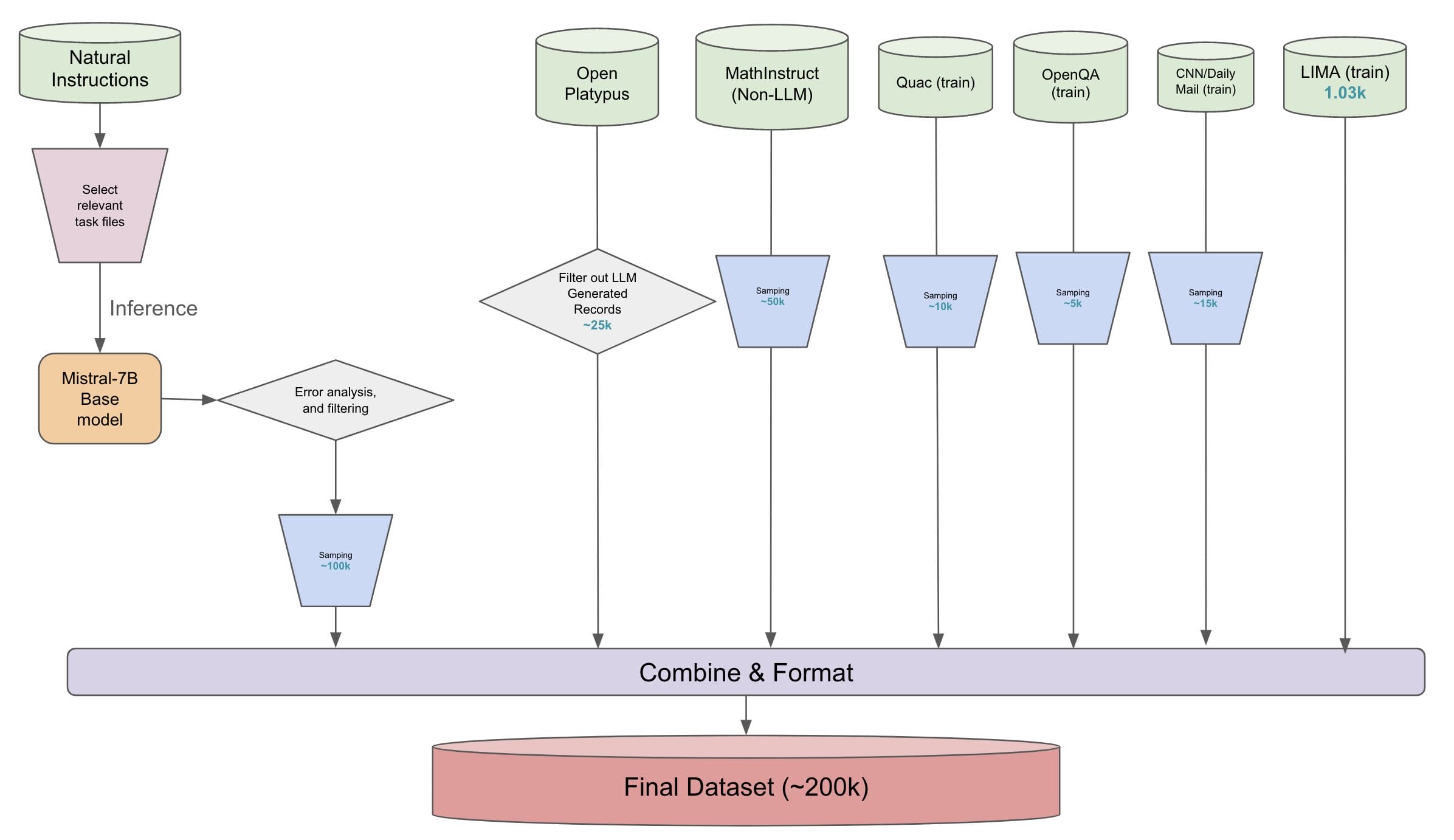
Andere Datensätze, die hinzugefügt wurden, sind:
- Open Platypus (Nicht-LLM generiert): 25k Proben
- MathInstruct (Nicht-LLM generiert): 50k Proben
- Quac (Zug): 10k Proben
- OpenQA (train): 5k Proben
- CNN/DailyMail (Zug): 15k Proben
- LIMA (Zug): 1k Proben
Diese Beispiele sind kombiniert und formatiert. MathInstruct benötigt ein wenig spezielle Vorbereitung. Der endgültige Datensatz besteht aus 200k Stichproben. Das Skript combine_datasets.py kombiniert alle Datensätze wie im obigen Diagramm gezeigt und bereitet die endgültige Aufteilung zwischen Training und Validierung vor. Der Validierungssatz beträgt 10% und der Test enthält 2000 Stichproben. Der endgültige Datensatz ist auf HuggingFace verfügbar.
Eingabeaufforderung im Format
Für das Format der Eingabeaufforderung wurde das folgende Format verwendet:
- special_tokens:
- bos_token: "<s>"
- eos_token: "</s>"
- unk_token: "<unk>"
Basismodell
Mistral-7B ist das Basismodell, das von Upaya verwendet wurde. Sie haben auch mit anderen Modellen experimentiert, wie z.B. QWEN-14B, aber Mistral-7B hat am besten abgeschnitten, auch wenn man die Inferenzzeit und den VRAM berücksichtigt.
Methoden zur Feinabstimmung
Ihre wichtigsten Methoden für effizientes Finetuning waren QLoRA, Flash Attention und der paged_adamw_32bit Optimizer. Sie trainierten 3 Epochen lang mit einer Stapelgröße von 2 und einer Akkumulation von 4. Im Nachhinein stellten sie fest, dass das Modell nach 2 Epochen die beste Leistung in ihrem Validierungsset zeigte. Das endgültige Modell von Upaya finden Sie auf Huggingface.
QLoRA
Die Hyperparameter-Einstellungen für QLoRA waren ganz normal:
- Rang von 128
- Alpha des doppelten Ranges 256
- Quantisierung der vortrainierten Gewichte auf NF4
- Präzision der trainierbaren Gewichte in BF16
Es war interessant zu sehen, dass sie LoRA auf alle Aufmerksamkeitsebenen angewendet haben:
- lora_target_modules:
- q_proj
- v_proj
- k_proj
- o_proj
- gate_proj
- down_proj
- up_proj
Im Gegensatz zum A100-Track, bei dem nur zwei Aufmerksamkeitsebenen verwendet wurden.
Blitzlicht Aufmerksamkeit
Flash Attention beschleunigte das Training und die Inferenz. In Kombination mit der NF4-Quantisierung konnten sie das Modell auf einer 4090 GPU anpassen.
Ausgelagerte AdamW 32bit
Der paged AdamW-Optimierer wurde verwendet, um den Speicherbedarf des Optimierers zu reduzieren.
Alle Hyperparameter finden Sie in ihrem Repository.
Weitere Details finden Sie in ihrem Repo oder in ihrem Papier, das auf dem Workshop Data-centric Machine Learning Research(DMLR) auf der ICLR 2024 angenommen wurde.
A100 Track - Detaillierter Ansatz zum Gewinnen
Die Gewinner der A100 Strecke sind das Team Percent-BFD.
Auswahl und Vorbereitung der Daten
Ihr Datensatz basiert auf den folgenden Datensätzen:
| Datensatz | Teilmenge | Probenahme |
| MMLU | alle Highschool-Fächer & Philosophie, moralische Streitfragen & weitere Szenarien | 10% zufällig |
| BIG-bench | analytic_entailment, causal_judgement, empirical_judgements, known_unkowns, logical_deduction, emoji_movie, strange_stories, snarks, dark_humor_detection | |
| CNN_dailymail | 10% zufällig | |
| TruthfulQA | ||
| GSM8K | ||
| LIMA | 10 Kopien | |
| Databricks-Wagen-15k | ||
| Oasst1-de | ||
| zusammenfassen_aus_rückmeldungen_tldr_3_gefiltert |
Nach dem Filtern und Subsampling enthielt ihr endgültiger Datensatz immer noch insgesamt 247.000 Zeilen.
Eingabeaufforderung im Format
Die Prompts wurden im SFT-Format formatiert:
Human: {query}
Assistant: {answer}
Basismodell
Nach rigorosen Experimenten und einer erneuten Evaluierung, als neue Modelle auf den Markt kamen, entschied sich das Team für QWEN-14B.
Methoden zur Feinabstimmung
Die einzige effiziente Finetuning-Methode, die verwendet wurde, war LoRA. Es war interessant zu sehen, dass keine Quantisierung verwendet wurde. Die eingefrorenen und trainierbaren Parameter waren beide in BF16 Präzision.
Sie konnten das Modell immer noch in 40 GB VRAM unterbringen, indem sie einen sehr niedrigen Rang von 8 verwendeten und LoRA nur auf zwei der Aufmerksamkeitsebenen anwendeten:
c_attnc_proj
Außerdem betrug die Batchgröße nur 2 mit einer Akkumulation von 4. Aber das war bei anderen Teams häufiger der Fall. Um das 24-Stunden-Limit einzuhalten, haben sie nur 1 Epoche lang trainiert.
Fazit
Lassen Sie uns kurz das Erfolgsrezept für das Finetuning von LLMs rekapitulieren. Es war interessant zu sehen, dass beide Teams ein ähnliches Thema hatten. Jetzt können Sie diese Methoden in Ihrer Finetuning-Pipeline anwenden:
- Beginnen Sie mit einem guten Basismodell. Das Experimentieren beginnt mit der Auswahl des Basismodells.
- Filtern Sie rigoros nach hochwertigen Daten. Gehen Sie keine Kompromisse bei der Qualität der Daten ein.
- Wählen Sie die Finetuning-Methode je nach Ihrer Situation, ob Sie effizientes Finetuning wünschen oder ob Ihre Situation weniger eingeschränkt ist.
Danksagungen
Herzlichen Glückwunsch an die Gewinner des Wettbewerbs und vielen Dank an beide Teams, dass sie ihren Ansatz vorgestellt haben. Ein besonderer Dank geht an Ashvini Jindal (den Teamleiter von Upaya), den ich auf der NeurIPS kennenlernen durfte, und für sein Feedback zu diesem Blog. Schließlich möchte ich mich bei den Organisatoren für die Ausrichtung des Wettbewerbs und des Workshops bedanken. Hoffentlich sehe ich Sie alle bei der nächsten Ausgabe.
Referenzen
Verfasst von

Jetze Schuurmans
Machine Learning Engineer
Jetze is a well-rounded Machine Learning Engineer, who is as comfortable solving Data Science use cases as he is productionizing them in the cloud. His expertise includes: AI4Science, MLOps, and GenAI. As a researcher, he has published papers on: Computer Vision and Natural Language Processing and Machine Learning in general.




Contact