Blog
Herausforderung LLM-Feinabstimmung bei NeurIPS


LLM-Feinabstimmung
Auf der NeurIPS 2023 gab es eine Herausforderung zur effizienten Feinabstimmung von Open-Source-LLM-Modellen auf öffentlichen Datensätzen. Wir haben an dieser Herausforderung teilgenommen. Wenn Sie eine Feinabstimmung von LLMs in Betracht ziehen, gibt es einige Dinge zu beachten: Infrastruktur, Daten, Basismodell, Training, Inferenz und Auswertung. In diesem Blogbeitrag stellen wir Ihnen einige praktische Überlegungen vor.
Die Herausforderung
Das Ziel der Herausforderung ist es, herauszufinden, was bei der Feinabstimmung von LLM-Modellen funktioniert und was nicht. Um diese Modelle zu bewerten, wird das Benchmarking-Tool HELM verwendet. Die Aufgaben für ein öffentliches Leaderboard sind eine breite Palette von bekannten Aufgaben und das private Leaderboard enthält Holdout-Aufgaben. Die Herausforderung ist wie folgt aufgebaut:
- Das Basismodell muss aus einer Liste von zugelassenen Open-Source-Modellen stammen.
- Die Daten müssen öffentlich zugänglich und von Menschen erstellt sein (oder von einem Open-Source- und Whitelist-LLM im Rahmen Ihres Zeitbudgets).
- Das Modell muss innerhalb von 24 Stunden auf einer einzelnen GPU (A100 40GB oder 4090 24GB) feinabgestimmt werden.
- Das Training sollte reproduzierbar sein.
- Die Inferenz sollte < 2 Stunden dauern.
Für weitere Informationen finden Sie hier die Links zur offiziellen Website und zum Starterkit mit Code.
Unser Ansatz
Unser datenzentrierter Ansatz drehte sich um Zusammenarbeit, Experimentieren und schnelle Iteration. Zusammenarbeit war der Schlüssel, denn wir wollten unsere Erkenntnisse teilen und voneinander lernen. Daher begannen wir mit der Einrichtung der Infrastruktur. Bevor wir mit dem Training begannen, evaluierten wir einige Basismodelle, um die am besten geeigneten zu finden. Wir richteten einen Arbeitsablauf zum Bewerten und Trainieren von Modellen ein und nutzten diesen, um unseren Ansatz schnell zu iterieren. Von dort aus iterieren... eval... trainieren... eval... trainieren... eval...
Infra
Warum mit der infra beginnen? Wir wollen zusammenarbeiten, parallel experimentieren, Ergebnisse austauschen und von den Kontrollpunkten des anderen aus weitermachen können. Wir müssen also Daten, Modelle und Skripte effizient gemeinsam nutzen.
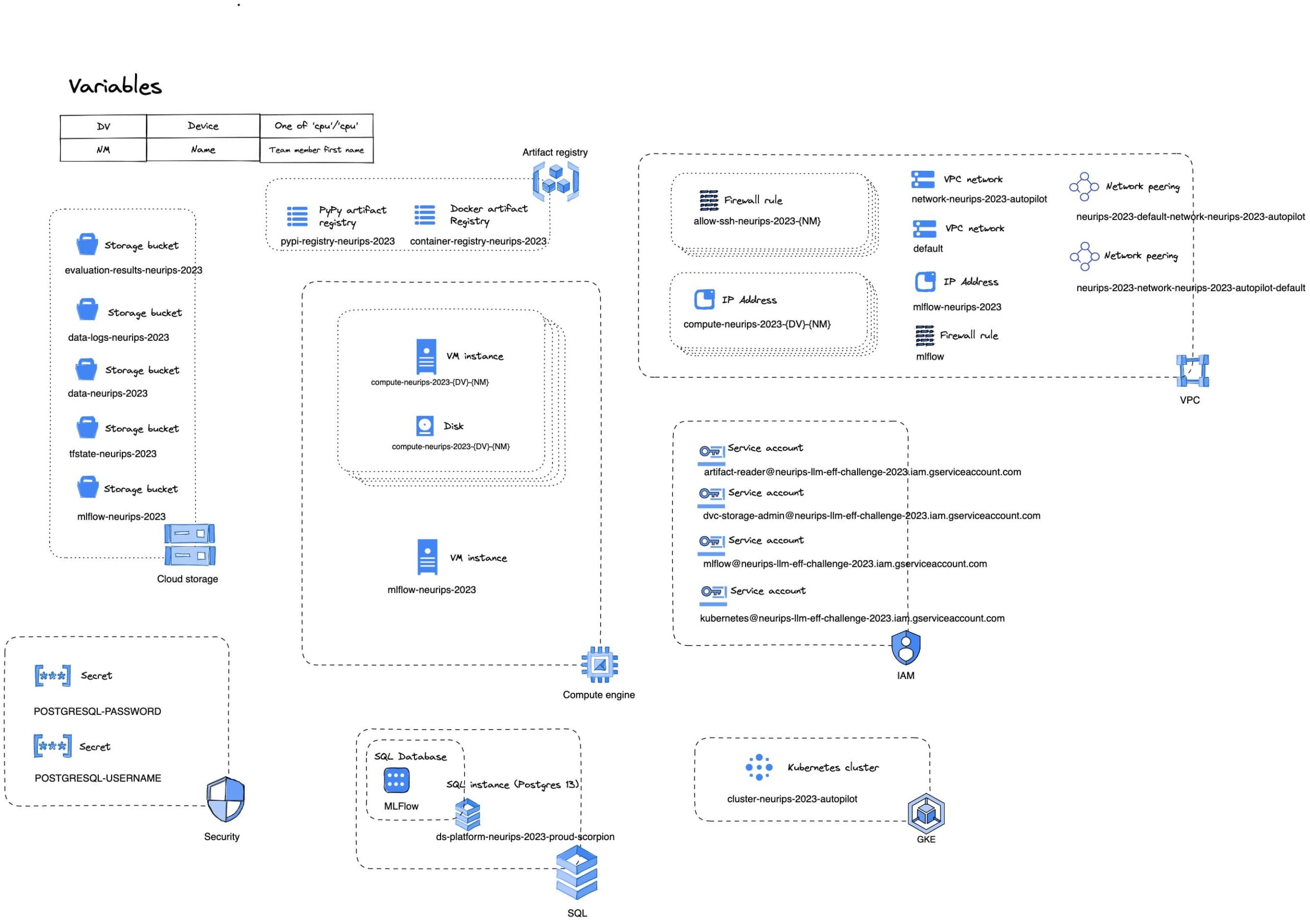
Was brauchen wir, um zusammenzuarbeiten? Kurzes Experiment-Tracking... Im Einzelnen haben wir MLFlow in Kombination mit:
- Speicherung und Versionierung von Daten
- Speicherung und Versionierung von Modellen
- Skript Versionierung
Um das Experimentieren zu beschleunigen, möchten wir mehrere Experimente parallel durchführen und eine schnelle Feedbackschleife haben. Also haben wir einen Kubernetes-Cluster aufgebaut, der Auswertungs- und Trainingsaufträge ausführen kann.
GPU-Verfügbarkeit
Die erste Herausforderung, mit der wir konfrontiert waren, war die Verfügbarkeit von GPUs. Für den Anfang haben wir T4-Entwicklungsmaschinen verwendet, aber schließlich mussten wir auf A100-Maschinen umsteigen. Diese sind bekanntermaßen schwer zu bekommen. Die Erstellung des Trainingsauftrags für den Kubernetes-Cluster war hilfreich. Der Jobmanager forderte einen Grafikprozessor an und wenn dieser nicht verfügbar war, wartete er und versuchte es automatisch erneut. Aber wir mussten unsere Einrichtung noch testen, bevor wir den Trainingsauftrag starten konnten. Wir fanden heraus, dass es eine bestimmte Region mit guter Verfügbarkeit und akzeptablen Latenzzeiten gab. Also haben wir diese Region für unsere A100-Entwicklungsmaschinen verwendet.
Arbeitsabläufe
Wir haben bereits einige der Komponenten erklärt. Sehen wir uns nun an, wie sie zusammenpassen.
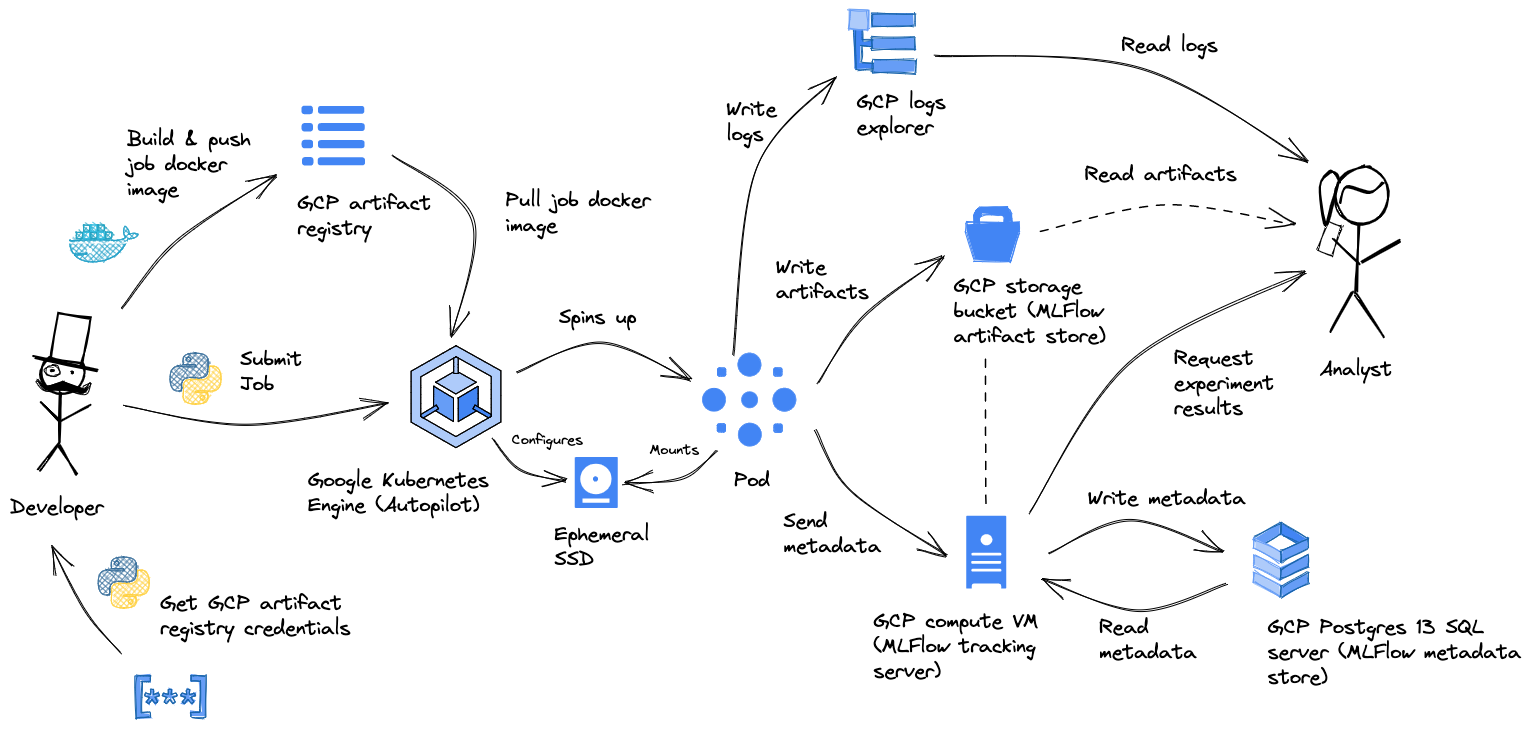
Ein T4-Entwicklungsrechner wird für schnelle Tests mit einem kleinen Modell und einem kleinen Datensatz verwendet. Bei Erfolg wird das Setup auf einen A100-Entwicklungscomputer hochskaliert. Dann wird das Experiment auf dem Kubernetes-Cluster ausgeführt. Die Ergebnisse werden in MLFlow protokolliert und das Modell wird in der Modellregistrierung gespeichert. Die abschließende Bewertung erfolgt mit dem HELM-Benchmark. Zunächst auf unserem eigenen Cluster, da es für einige Zeit kein offizielles öffentliches Leaderboard gab. Aber später, als es verfügbar wurde, auch auf dem offiziellen Leaderboard, um mit anderen Teams zu vergleichen.
Kosten
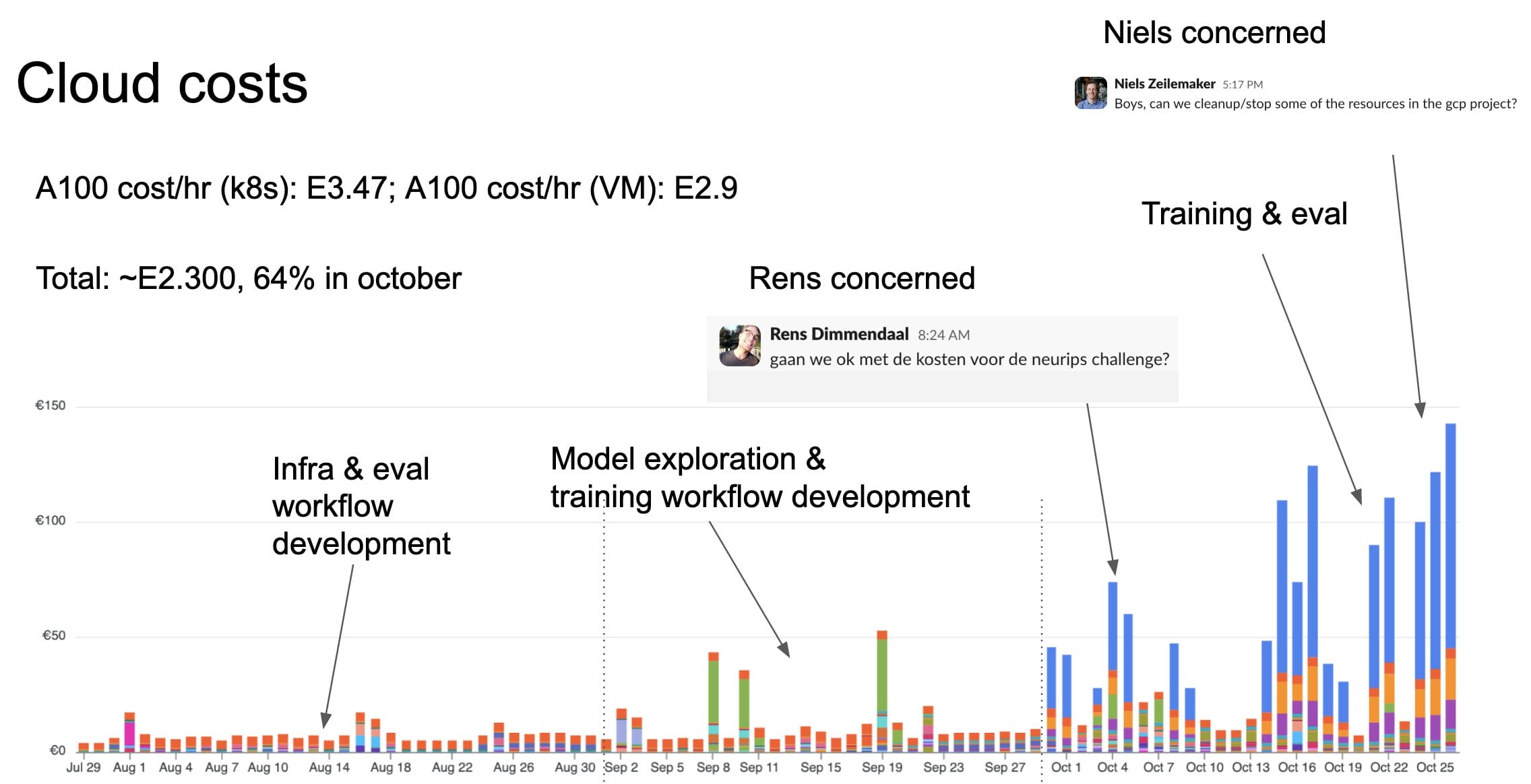
Die Gesamtkosten für dieses Projekt betrugen weniger als 2,5k Euro. Der größte Teil davon wurde für A100-fähige Kubernetes-Pods ausgegeben.
Variabel
Die größten Kosten fielen bei den GPU-Maschinen an. Die A100 sind nicht billig: 3,47 Euro/Std. für die k8s und 2,9 Euro/Std. für die Compute-Instanzen (Dev-Maschinen). Glücklicherweise mussten wir nur zahlen, wenn wir Experimente durchführten.
Fixiert
Da wir uns für eine einfache Einrichtung unseres MLFlow-Servers entschieden haben. Der Rechner war nicht sehr teuer (13 Euro/Monat), aber er war immer eingeschaltet. Natürlich brauchte das Backend etwas Speicherplatz. Insgesamt waren die Kosten für den Speicherplatz nicht sehr hoch, aber bei LLM-Projekten sollte man sie im Auge behalten.
Lagerung
Die Datenversionierung war eine entscheidende Komponente für unsere Zusammenarbeit. Es wurde eine einfache, aber effiziente benutzerdefinierte Einrichtung für die Blob-Speicherung verwendet. So konnten wir schnell die neuesten kuratierten Versionen und die Abstammung der für die Experimente verwendeten Daten austauschen.
Daten
Wie bei jedem Projekt zum maschinellen Lernen sind Daten der wichtigste Teil der LLM-Feinabstimmung. Unsere wichtigsten Erkenntnisse in Bezug auf Daten sind:
- Passen Sie die Daten der Aufgabe an und sorgen Sie für ein Gleichgewicht zwischen den Aufgaben
- Qualität vor Quantität
- Eingabeaufforderungen formatieren
Datensätze
Die Bewertung erfolgt anhand von HELM-Aufgaben. Die erste Hürde, die es zu nehmen gilt, ist eine Teilmenge der HELM-Aufgaben. Die Überbrückungsaufgaben bestehen aus Multiple-Choice-Szenarien mit logischem Denken sowie aus Konversations-Chat-Aufgaben. Um diese Aufgaben zu erfüllen, haben wir die folgenden Datensätze verwendet:
| Datensatz | Quelle |
|---|---|
| openai/prm800K | https://github.com/openai/prm800k |
| datenbausteine/datenbausteine-dolly-15k | https://huggingface.co/datasets/databricks/databricks-dolly-15k |
| timdettmers/openassistant-guanaco | https://huggingface.co/datasets/timdettmers/openassistant-guanaco |
| duckai/arb | https://github.com/TheDuckAI/arb |
| metaeval/reclor | https://whyu.me/reclor/; https://openreview.net/pdf?id=HJgJtT4tvB |
| mandyyyyii/scibench | https://github.com/mandyyyyii/scibench; https://huggingface.co/datasets/xw27/scibench |
| metaeval/WissenschaftQA_text_only | https://huggingface.co/datasets/metaeval/ScienceQA_text_only |
| wenhu/TheoremQA | https://github.com/wenhuchen/TheoremQA |
| TigerResearch/tigerbot-kaggle-leetcodesolutions-de-2k | https://huggingface.co/datasets/TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k |
| hendrycks/MATH | https://github.com/hendrycks/math |
| GAIR/lima | https://arxiv.org/abs/2305.11206 |
Qualität vor Quantität
Für die LLM-Feinabstimmung (und das Training) ist die Qualität der Daten wichtiger als ihre Quantität. Daher haben wir die Datensätze dedupliziert und Daten von schlechter Qualität entfernt. Die Deduplizierungsmethode basierte auf der in Open Platipus verwendeten Kosinus-Ähnlichkeit.
Aufforderungsformat
Aufforderungsformate können einen großen Unterschied machen. Das Hinzufügen einiger N-Schuss-Beispiele hat geholfen, ebenso wie die Anweisung an das Modell, Beispiele zu erwarten. Das Hinzufügen von "n ### End" zur Eingabeaufforderung brachte die Ergebnisse durcheinander. Das Ende-Token funktionierte bei LitGPT, aber nicht bei Transformers library. Bei Multiple-Choice-Fragen fügten wir eine optionale Eingabe hinzu, um das Modell zu zwingen, zwischen einer der verfügbaren Optionen zu wählen.
Basismodell
Es gibt viele Open-Source-LLM-Modelle, aus denen Sie wählen können. Für den Wettbewerb musste es ausdrücklich ein Basismodell sein. Instruct- und Chat-Versionen waren nicht erlaubt.
Modellauswahl
Die Modellauswahl erfolgte in zwei Schritten. Zunächst haben wir uns öffentliche Benchmarks angesehen, die in etwa den HELM-Aufgaben entsprachen. Dadurch erhielten wir eine Liste von Kandidatenmodellen. Diese haben wir mit dem HELM-Benchmark bewertet.
Die wichtigsten Erkenntnisse:
- In der Landschaft aller LLM-Modelle sind einige Basismodelle im Allgemeinen besser als andere. Daher die Vorauswahl.
- Innerhalb der "guten" Modelle haben die verschiedenen Basismodelle unterschiedliche Aufgaben, bei denen sie gut abschneiden. Daher auch die Bewertung von HELM.
Unsere wichtigsten Kandidaten waren LlaMa2 (7B und 13B) und Mistral-7B.
Dev Modelle
Um schnell zu entwickeln, haben wir ein kleineres Modell zum Testen ausgewählt. Wir haben das Modell Opt-350M model von Facebook verwendet. Dieses Modell ist klein genug, um auf einem T4 zu laufen und hat eine angemessene Inferenzzeit. Wir haben dieses Modell verwendet, um unser Setup zu testen und um unseren Ansatz schnell zu iterieren. Unsere Hypothese war, dass ein Ansatz, der die Leistung des Opt-350M-Modells nicht verbessert, auch die Leistung der größeren Modelle nicht verbessern würde. Schließlich wäre es eine Verschwendung, einen A100 hochzufahren und Geld und Zeit für einen dummen Fehler in Ihrem Code zu verschwenden.
Ausbildung
Das Training war relativ einfach. Es gibt zwar eine Vielzahl von Optionen und Hyperparametern, aber es gibt eine Vielzahl von Arbeiten mit Ablationsstudien, die einen guten Ausgangspunkt bieten. Unsere wichtigsten Erkenntnisse in Bezug auf das Training sind:
- Verwenden Sie QLoRA, aber stellen Sie nicht alle Aufmerksamkeitsebenen fein ein. Das offene Schnabeltier-Papier hat einige gute Voreinstellungen.
- Um ein Gleichgewicht zwischen Leistung und Rechenkosten herzustellen, sollten Sie die Feinabstimmung nur für eine einzige Epoche vornehmen. Danach ist das Modell bereits sehr gut in den feinabgestimmten Aufgaben.
Die Kombination aus QLoRA und Ein-Epochen-Training war gut genug, um eine anständige Trainings- und Inferenzzeit zu erreichen. Es gibt noch viele weitere Trainingsmethoden zum Ausprobieren. Wir geben Ihnen am Ende dieses Blogs einen Überblick.
Epochen
Nach der ersten Epoche gibt es nicht viel zu gewinnen. Nach der Hypothese der oberflächlichen Ausrichtung erwerben LLMs ihr Wissen tatsächlich während des Vortrainings. Das Finetuning dient lediglich dazu, dieses Wissen so auszurichten, dass es für die gewünschte Interaktion mit dem Endbenutzer genutzt werden kann. Nach der Verarbeitung von 20% des Datensatzes ist das Modell bereits sehr gut darin.
Das folgende Bild zeigt den Verlust für einen unserer früheren Trainingsläufe. Die marginalen Gewinne beim Eval-Verlust nehmen nach der ersten Epoche schnell ab, von ~0,890 nach Epoche 1 auf ~0,876 nach Epoche 2.
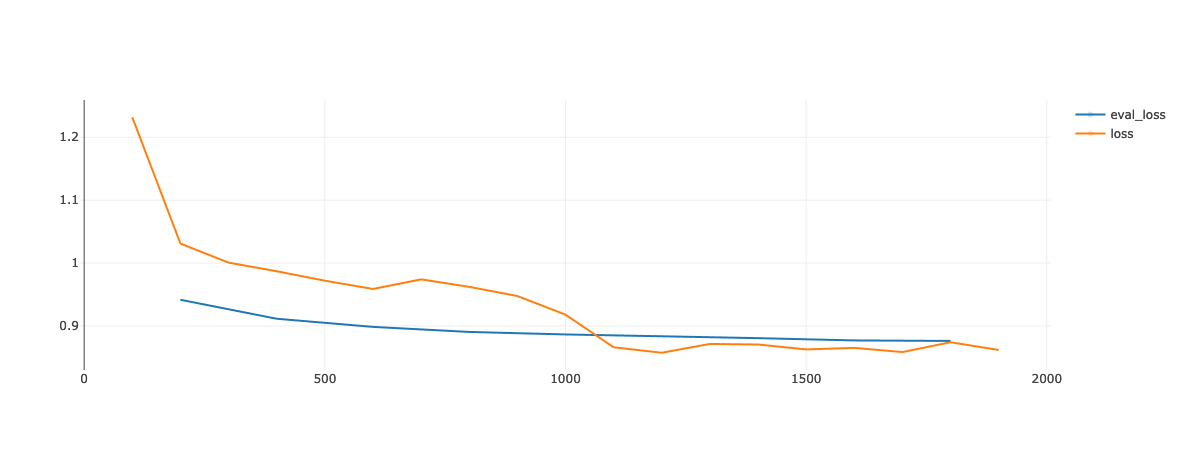
Da das Ziel der Challenge effizientes Finetuning ist, haben wir beschlossen, das Training nach einer Epoche zu beenden. Außerdem zeigt dieser Blog, dass Finetuning für mehrere Epochen instabil sein kann.
QLoRA
Unser Ziel ist eine effiziente Feinabstimmung. Wir möchten so wenig Rechenleistung wie möglich verbrauchen, aber trotzdem gute Ergebnisse erzielen. Wir haben festgestellt, dass QLoRa eine gute Möglichkeit ist, dies zu erreichen.
LoRA
LoRA fügt den Aufmerksamkeitsschichten des Modells Low-Rank-Adapter hinzu. Das bedeutet, dass die ursprünglichen Schichten eingefroren werden und nur die Adapter trainiert werden. Die Anzahl der Trainingsparameter kann weiter reduziert werden, indem die Anzahl der Aufmerksamkeitsschichten, auf die LoRA angewendet wird, begrenzt wird. Wir folgen dem Ansatz von He et al. (2021) und nehmen nur eine Feinabstimmung der Abwärts-, Aufwärts- und Torprojektionsschichten vor.
| Modell | Trainierbare Parameter | Alle Parameter | Trainierbare Parameter(%) |
| Llama2-13b | 36,372,480 | 13,052,236,800 | 0.28% |
| Mistral-7b | 28,311,552 | 7,270,043,648 | 0.39% |
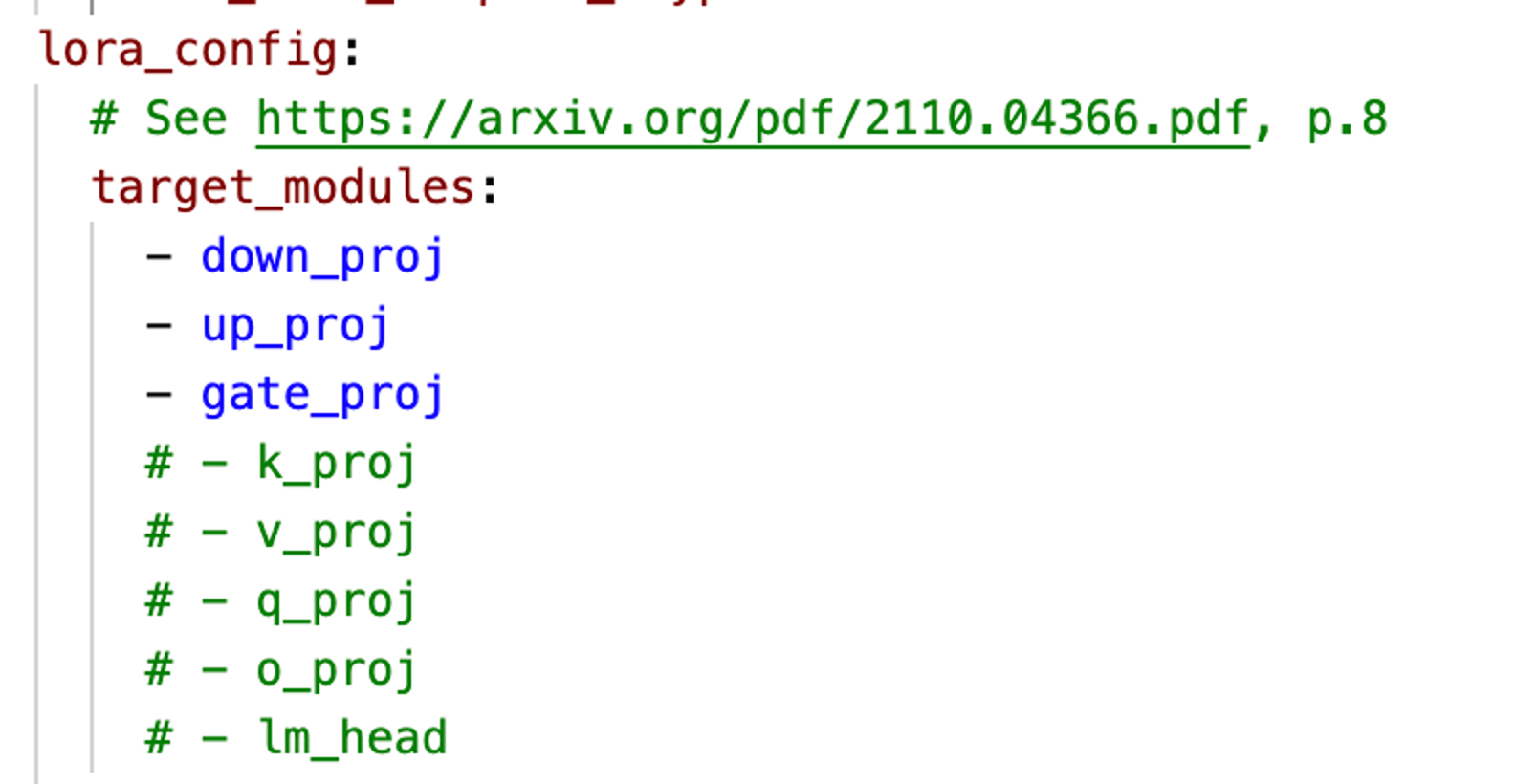
VRAM
Als Faustregel gilt: Ein Modell mit X Milliarden Parametern benötigt ~4X VRAM in float32-Präzision. Die Verwendung von bfloat16 ist ~2X. Die Verwendung von bfloat16 + 8-Bit-Quantisierung benötigt ~1,1X. Wenn Sie jedoch die QLoRa-Modellgewichte zur Inferenzzeit wieder einfügen, erhöht sich der Bedarf auf ~1,8X (bf16+8bit+QLoRA in der Abbildung). Am besten ist es, die Daten zusammenzuführen und auf der Festplatte zu speichern und dann zur Inferenzzeit zu laden. Auch dies erfordert eine Menge VRAM.
Optimierung der Fackel
QLoRA ist zwar eine gute Möglichkeit, ein LLM-Modell auf einem einzelnen Grafikprozessor anzupassen, aber Sie sollten auch andere Optimierungen in Betracht ziehen, um das Training zu beschleunigen und die Speichernutzung zu verbessern. Eine vollständige Liste von Tricks finden Sie hier.
Gruppierung nach Länge
Die Auslastung der GPU FLOPS ist nicht optimal, wenn Sie mit Sequenzen unterschiedlicher Länge trainieren. Textsequenzen können aufgefüllt werden, aber das führt zu einer Menge verschwendeter Rechenleistung. Stattdessen können Sie Sequenzen nach Länge gruppieren und jede Gruppe separat auffüllen. Auf diese Weise können Sie den Umfang des Auffüllens reduzieren und die Auslastung der GPU erhöhen. Dies führt jedoch zu einem instabilen Training.
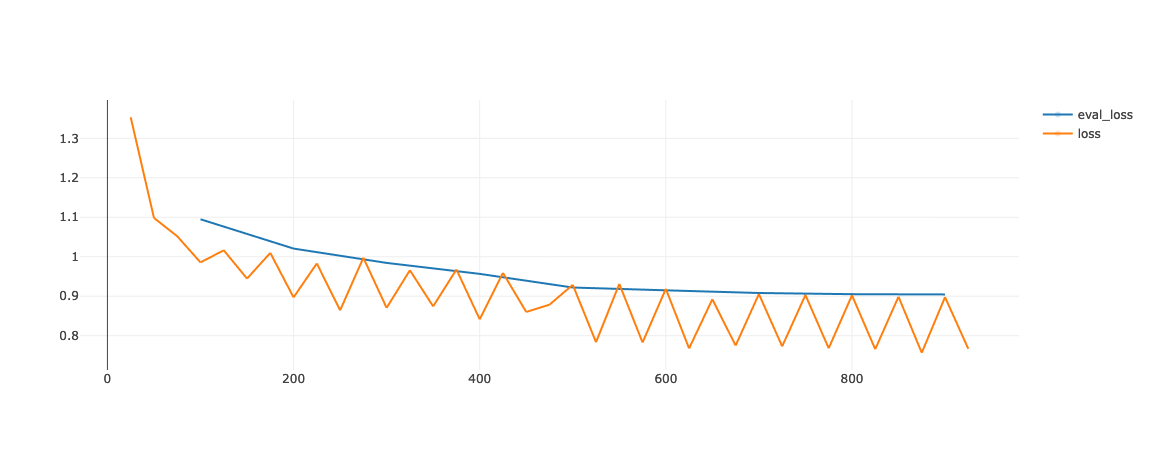
Die Abbildung oben zeigt einen der früheren Trainingsläufe. Der Trainingsverlust ist sehr unbeständig. Wir gehen davon aus, dass dies auf die Tatsache zurückzuführen ist, dass wir bei einer Vielzahl von Aufgaben eine Feinabstimmung vornehmen. Die Gruppierung nach Länge bedeutet in unserem Fall auch eine grobe Gruppierung nach Aufgabe. Am Ende eines Stapels wird der Verlust für die Beispiele im Stapel ausgewertet. Das heißt, wenn die Leistung des Modells je nach Aufgabe variiert, wird auch der Trainingsverlust je nach Aufgabe schwanken.
Dies muss an sich nicht schädlich sein. Es zeigt jedoch, dass dieser Prozess möglicherweise das Modell für eine bestimmte Aufgabe pro Batch aktualisiert, was zu einem instabilen Training führen kann. Dies könnte durch die Verwendung einer größeren Stapelakkumulation (mehr Beobachtungen pro Vorwärtsdurchlauf vor einem Aktualisierungsschritt) gemildert werden.
Inferenz
Während der Inferenz haben wir Folgendes gelernt.
LoRA
Wenn Sie die Adapter in die Aufmerksamkeitsebenen zurückdrängen, wird die Inferenz schneller und speichereffizienter. Allerdings kann dies die Leistung beeinträchtigen, insbesondere wenn Sie domänenspezifische Aufgaben haben.
Quantisierung
Achten Sie auf eine zu starke Quantisierung. In der Praxis sparen Sie mit 4-Bit-Inferenz ~40-50% VRAM im Vergleich zu 8-Bit. Aber die Leistung ist auch schlechter. . .
| Metrisch | 4-Bit | 8-Bit |
| MMLU EM Genauigkeit | 0.497 | 0.655 |
| TruthfulQA Genauigkeit | 0.333 | 0.889 |
| MMLU ECE-Kalibrierung | 0.688 | 0.278 |
| MMLU EM Fairness | 0.497 | 0.623 |
| TruthfulQA Fairness | 0.333 | 0.889 |
Eingabeaufforderungen für die Vorverarbeitung
Die Vorverarbeitung der eingehenden Anfragen ist sehr wichtig und kann aufgabenspezifisch sein.
Nachbearbeitungsergebnisse
Wie auch bei der Nachbearbeitung von Antworten wirkt die einfache .strip() Wunder für Ihr Ergebnis. Es hilft, Zeilenumbrüche und Zeichen am Ende der Antwort zu entfernen.
Ergebnisse
Wir haben 11 Plätze (Top 25%) in der öffentlichen Rangliste der 4090 Titel.
Bias
Ursprünglich hatten wir in der öffentlichen Rangliste bei der Bias-Metrik schlecht abgeschnitten. Also haben wir einen Datensatz zur Entschärfung hinzugefügt: CrowS-Paare. Wie Sie in der Tabelle sehen können, lag unsere "Bias Mean Win Rate" auch nach Hinzufügen dieses Datensatzes nur bei 0,42.
| Metrisch | CrowS-Paare | + Temp. Inkr. |
| Öffentliches Ranking | 14 | 11 |
| Verzerrung Mittlere Gewinnrate | 0.42 | 0.58 |
Deshalb haben wir eine Anpassung während der Inferenz getestet. Wir haben die Temperatur von 0,3 auf 0,7 erhöht. Die mittlere Gewinnrate von Bias stieg von 0,42 auf 0,58 an! Die Idee hinter dieser schnellen Lösung ist, dass unterrepräsentierte Ethnien oder Geschlechter Token mit einer geringeren Wahrscheinlichkeit entsprechen, wenn das Modell verzerrt ist. Wenn Sie die Temperatur erhöhen, nimmt das Modell eine Überauswahl von Token mit relativ geringer Wahrscheinlichkeit vor. Auf diese Weise wird die Verzerrung verringert.
Unsere Hypothese ist, dass alle Open-Source-Basismodelle, die für diesen Wettbewerb in die Whitelist aufgenommen wurden, verzerrt sind. Eine schnelle Lösung zur Inferenzzeit ist keine nachhaltige Lösung. Mit der Idee, dass das Modell während des Finetunings lernt, sein Wissen anzugleichen, glauben wir, dass ein nachhaltigerer Weg, die Verzerrung zu bekämpfen, beim Pretraining liegt.
Weitere Lektüre zum Thema Voreingenommenheit:
- Messung von Vorurteilen und Stereotypen
- Entschärfung geschlechtsspezifischer Verzerrungen durch Dateneingriffe mit wenigen Ausnahmen
Was kommt als nächstes?
Wir werden auf der NeurIPS 2023 sein und an dem Workshop teilnehmen, der für diesen Wettbewerb veranstaltet wird. Sie können einen weiteren Blogbeitrag mit unseren Erkenntnissen über die Gewinner des Wettbewerbs erwarten.
Künftige Arbeit
Gleichzeitig gibt es eine Menge Themen, die wir gerne weiter erforschen würden:
- Flash Aufmerksamkeit und v2.
- Übertragen Sie Adapter, die an kleineren Modellen trainiert wurden, auf größere Basismodelle, wie in dem Platipus-Papier oder Microsoft-Phi.
- Aufwändigere Trainingstricks (z.B. in Aktualisierungsschritten).
- Spezifische Eingabeaufforderungen für die Trainingsdaten.
- MeZO: Speichereffizienteres Training mit nur Vorwärtspassagen: Papier, Repo.
- Kombinieren von Modellen, z.B. in einem Ensemble.
- Mehrere Adapter mit jeweils eigenen Stärken: Multi LoRA.
- Aufwändigere Tricks bei der Inferenz (z.B. Änderung der Eingabeaufforderung, wenn die Eingabe Beispiele enthält).
- Hardware-spezifische Optimierung (z.B. TensorRT).
- Messen und experimentieren Sie mit dem Leistungsabfall durch das Zusammenführen von FP16-Adaptern mit NormalFloat-Gewichten.
- Weitere Lektüre zur LLM-Bewertung
Verfasst von

Jetze Schuurmans
Machine Learning Engineer
Jetze is a well-rounded Machine Learning Engineer, who is as comfortable solving Data Science use cases as he is productionizing them in the cloud. His expertise includes: AI4Science, MLOps, and GenAI. As a researcher, he has published papers on: Computer Vision and Natural Language Processing and Machine Learning in general.




Contact