Blog
Was ist Data Engineering? (Basierend auf einer Bohröl-Analogie)

Sie haben wahrscheinlich schon einmal gehört, dass "Daten das neue Öl" sind. Das ist eine wirklich coole Analogie - sagte jemand im Jahr 2006. Im Jahr 2021 ist diese Sichtweise zu einer Floskel geworden. Sie ist langweilig und wiederholend. Und doch... beschreibt es sehr gut, was Data Engineering ist. Deshalb werden wir Sie in diesem Blogbeitrag enttäuschen - und die Geschichte von Data Engineering noch einmal mit einigen Benzin-Analogien erzählen.
Es tut uns im Voraus sehr leid.
Aber wenn Sie das verkraften können, versprechen wir Ihnen einen umfassenden (und dennoch kurzen) Einblick in Data Engineering - einschließlich seiner Definition, Anwendungsfälle und Vorteile.
Eines der Schlüsselelemente des Data Engineering ist die Data Pipeline.
Was ist Data Engineering?
Lassen Sie uns mit einem allgemeinen Überblick beginnen. Data Engineering ist die zentrale Grundlage für jedes fortschrittliche Datenprojekt. Seine Aufgabe ist es, vollwertige datengesteuerte Operationen in Bereichen wie KI, Data Science oder Datenvisualisierung zu ermöglichen.
Laut QuantHub, ist der Schlüssel zum richtigen Verständnis von Data Engineering das Element "Engineering".. Ingenieure entwerfen und bauen Dinge. In ähnlicher Weise entwerfen und bauen Dateningenieure Datenlösungen. Diese Lösungen dienen der Umwandlung (und dem Transport) von Daten in ein Format, das für die weitere Verwendung geeignet ist - normalerweise durch Datenwissenschaftler.
Real Python fügt hinzu, dass Data Engineering zielt darauf ab, einen konsistenten und organisierten Datenfluss zu gewährleisten. Data Engineering kann verschiedene Wege einschlagen, um diesen Datenfluss zu erreichen, es gibt jedoch ein gemeinsames Muster: die Datenpipeline. Eine Datenpipeline ist ein System von Programmen, die Operationen mit den gesammelten Informationen durchführen und so in der Lage sind, relevante geschäftliche Vorteile in den oben genannten datengesteuerten Bereichen zu liefern.
Dennoch, Data Engineering ist eine weit gefasste Disziplin, die viele spezifische Namen haben kann. In manchen Unternehmen gibt es vielleicht sogar gar keine. Genau aus diesem Grund ist es am besten, die Besonderheiten von Data Engineering aus der Perspektive der endgültigen Ziele und gewünschten Ergebnisse zu definieren.
Um diese Perspektive zu erfassen und zu bestimmen, was Data Engineering ist (und was nicht), werden wir uns dem Thema wie ein Start-up nähern - Schritt für Schritt - ... und mit den benzinbezogenen Beispielen beginnen.
Sagen Sie nicht, wir hätten Sie nicht gewarnt.
Wie fängt man mit Data Engineering an?
Selbst wenn jemand nicht viel über datengesteuerte Entscheidungsfindung (DDDM), sollte es nicht schwer sein, einige seiner Komponenten intuitiv zu benennen. Die wichtigste davon sind natürlich die Daten. So trivial es auch klingen mag, das Sammeln der richtigen Informationen ist immer der erste (und oft schwierige) Schritt. Ohne Daten gibt es keinen Treibstoff für die Stärkung der Ihre Tätigkeiten in dieser Abteilung.
Aber bevor Sie mit dem Sammeln dieser Informationen beginnen, müssen Sie eine nützliche Quelle finden.
Beginnen wir mit dieser Analogie: Stellen Sie sich vor, Sie sind der Eigentümer eines neuen Erdölunternehmens wie BP oder Shell. Sie haben die Mittel, um mit der Förderung ölreicher Gebiete zu beginnen, aber... Sie wissen nicht, wo Sie sie finden können. Also müssen Sie mit der Suche beginnen.
Identifizierung von Daten(Öl?)quellen
Um Ihre Ölförderung in Gang zu bringen, benötigen Sie wahrscheinlich einige seismische Vibratoren. Diese erzeugen seismische Signale, um potenzielle Ölgebiete unter der Erde zu identifizieren. Auf diese Weise wissen Sie, wo Sie graben müssen.
In der IT-Welt macht Data Engineering etwas Ähnliches - es hilft dabei, potenzielle Datenquellen zu identifizieren, die für das Erreichen bestimmter Geschäftsziele wichtig sind. Schließlich sind nicht alle Daten in einer bestimmten Situation nützlich. Im Gegenteil - die meisten werden so nützlich sein wie Wüstensand, wenn Sie Erdöl* brauchen. Relevante Daten können schwierig zu finden sein, genau wie Öl unter der Erde.
Aber sobald Sie wissen, wo die wichtigen Daten liegen, können Ihre Dateningenieure sie der Datenpipeline hinzufügen. Auf diese Weise wissen Sie, wo Sie nach nützlichen Informationen suchen müssen.
*Wussten Sie,dass Wüstensand so nutzlos ist, dass er sich nicht einmal für Bauzwecke eignet? Überraschenderweise ist er zu glatt. Daher müssen Länder wie die Vereinigten Arabischen Emirate, die scheinbar unbegrenzte Sandvorräte haben, diesen von anderswo importieren.
Erweiterung der Datenerfassung
Der nächste Schritt besteht nun darin, ohne Komplikationen auf diese neuen Datenquellen zuzugreifen. Eine benutzerdefinierte Pipeline ist unerlässlich, um dies auf effiziente Weise zu erreichen. Und durch mehr und mehr neue Daten wird Data Engineering in der Lage sein, noch mehr Leistung zu erbringen.
Mehr Daten können das Gesamtbild Ihrer Operationen offenbaren. Daher sind der 1. und 2. Schritt so etwas wie ein sich wiederholender Zyklus; mit neuen Daten entsteht ein neuer Bedarf, sie in die Pipeline aufzunehmen.
Aus der Perspektive unserer Treibstoff-Analogie haben Sie jetzt Ihr Öl unter der Erde gefunden und es ist an der Zeit, mit der Förderung zu beginnen; Data Engineering dient als Ihr Pumpenheber an einer Ölquelle. Und wenn Sie neue Ölquellen finden, müssen Sie an dem neuen Ort dasselbe tun.
Daten transformieren und formatieren
Wenn Sie bereits über Ihre Daten verfügen, wäre es eine gute Idee, sie zu nutzen. Leider ist es fast unmöglich, Rohdaten zu analysieren - vor allem, wenn sie aus mehreren verschiedenen Quellen stammen. Eine manuelle Bearbeitung dieser Daten kommt nicht in Frage, da sie in der Regel zu umfangreich sind, um von einer Person verarbeitet zu werden. Glücklicherweise kann Data Engineering helfen - durch die Konfiguration einer einzigartigen ELT- (Extrahieren, Laden und Transformieren) oder ETL-Pipeline (Extrahieren, Transformieren und Laden) ist es möglich, den gesamten Prozess zu automatisieren und eine verständliche, sinnvolle Ausgabe zu erzeugen. Auf diese Weise können die Daten den Nutzen erbringen, für den sie gedacht waren.
Sie werden einen ähnlichen Prozess in unserer Öl-Analogie beobachten können. Unmittelbar nach der Förderung ist das Öl nicht sehr brauchbar - es muss in einer Ölraffinerie verarbeitet werden, die dann brauchbare Produkte wie Benzin oder Dieselkraftstoff liefert.
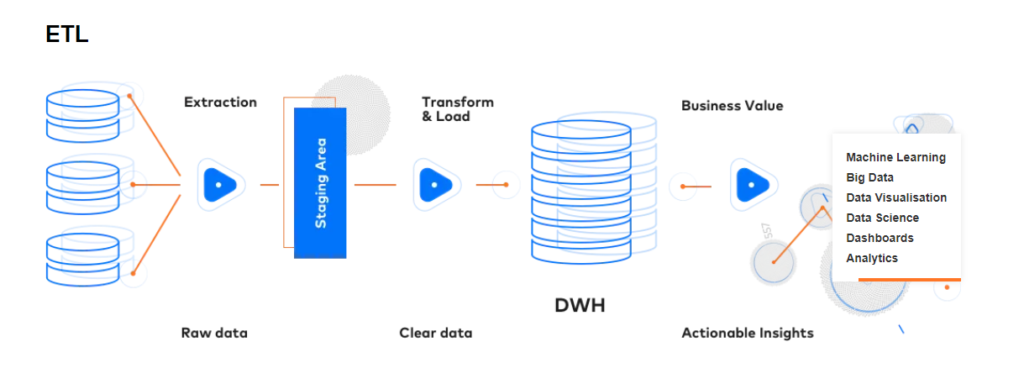
So sieht eine ETL-Datenpipeline aus.
Speichern von Daten
Schließlich müssen alle Daten irgendwo gespeichert werden. Angesichts der wachsenden Menge historischer Daten sind Data Warehouses und Data Lakes für den einfachen Zugriff auf Daten aus Ihren Analyselösungen unerlässlich. In Verbindung mit der Cloud ist eine Speicherlösung, die sowohl zugänglich als auch kostenoptimiert ist, entscheidend. Ohne Data Engineering wäre das natürlich nicht möglich.
Und an dieser Stelle wollen wir Ihre Zeit nicht mit einem trivialen Erdöl-Beispiel verschwenden, sondern sagen nur: Auch Benzin muss irgendwo gelagert werden.
Software für Datentechnik
Es liegt auf der Hand, dass keine der Aufgaben, die wir in diesem Artikel erwähnt haben, ohne die richtigen Tools möglich wäre.
Das Internet ist voll von Hunderten (Tausenden?) von Data-Engineering-Technologien und -Tools. So sehr, dass jemand sogar eine Website eingerichtet hat - Ist es Pokémon oder Big Data? Aber Spaß beiseite, die Welt der Data Engineering Software ist in der Tat unglaublich vielfältig. Allein für den erwähnten Bereich Big Data gibt es eine überwältigende Anzahl spezieller Tools (und die beliebtesten werden von einem einzigen Unternehmen/einer einzigen Stiftung entwickelt).
Wenn Sie gerade erst mit dem Data Engineering beginnen, kann es daher schwierig sein, das optimale Tool zu finden. Um Ihnen zu helfen, sich in diesem technischen Labyrinth zurechtzufinden, hat unser Datenexperte eine Liste der nützlichsten (und beliebtesten) Data Engineering-Tools und -Technologien erstellt. Lesen Sie unbedingt unseren letzten Artikel darüber, um mehr zu erfahren.
Was ist der Wert von Data Engineering?
Wie Sie sehen können, besteht das allgemeine Ziel der Datentechnik darin, eine konsistente Datenpipeline aus verschiedenen Datenquellen zu erstellen. Die meisten Unternehmen produzieren riesige Mengen an Rohdaten, denen es jedoch oft an Konsistenz in Bezug auf Struktur und Formatierung mangelt; Data Engineering zielt darauf ab, diese Herausforderung zu überwinden.
Kurz und gut, das übergreifende Ziel des Data Engineering ist die Bereitstellung eines organisierten, konsistenten Datenflusses, der datengesteuerte Operationen ermöglicht. Diese Operationen umfassen zum Beispiel:
- Training von Machine Learning (ML) Modellen,
- die Durchführung einer explorativen Datenanalyse,
- das Auffüllen von Feldern in einer Anwendung mit externen Daten.
Diese Bereiche können in vielen Branchen vielfältige Vorteile bringen - und Data Engineering macht es möglich.
Aber warum sind Daten überhaupt wichtig?
Einen solchen Absatz hätten Sie wahrscheinlich gleich zu Beginn dieses Artikels erwartet. Aber wir wollten Sie nicht zu Tode langweilen, falls Sie schon hundertmal von diesem Thema gehört haben.
Aber falls Sie es nicht wussten: Zusammenfassend lässt sich sagen, dass Daten in der heutigen Landschaft eine Schlüsselrolle für fast alle Vorgänge in der digitalen Welt spielen. Daten helfen dabei, bessere Entscheidungen zu treffen und Probleme zu lösen. Sie müssen sich also nicht mehr (so sehr) auf Ihr Bauchgefühl verlassen.
Sicherlich ist geschäftliche Intuition hilfreich; selbst die besten Informationen werden nicht alle Ihre Probleme lösen. Aber sie kann zu einem wichtigen Wegbereiter und Wegweiser werden. So können Sie beispielsweise neue Kunden finden, deren Bindung erhöhen, das Marketing ankurbeln oder sogar Verkaufstrends vorhersagen. Darüber hinaus helfen gute Informationen auch, Prozesse zu verstehen und Key Performance Indicators (KPI) zu verfolgen, was ungemein nützlich ist, wenn Sie irgendeine Art von digitalem Service anbieten.
In Anlehnung an unsere Erdölwitze von vorhin ist es also keine Überraschung, dass Datenexperten (und alle anderen) sagen, dass Daten das neue Öl sind. In Wahrheit beschreibt diese Analogie, auch wenn sie sich wiederholt, perfekt den Mechanismus - Informationen sind der Treibstoff moderner Unternehmen.
Verfasst von
Xebia Author
Unsere Ideen
Weitere Blogs




Contact