Einführung
Graphische neuronale Netze (GNNs) waren in den letzten Jahren eines der heißesten Themen in der Welt der KI, mit vielen potenziellen Geschäftsanwendungen. Sie sind Vertreter einer der leistungsstärksten Gruppen von Algorithmen des maschinellen Lernens, nämlich der Künstlichen Neuronalen Netze. Andere Mitglieder dieser Familie sind z.B. Sprachmodelle, die mit Textdaten arbeiten, oder Computer Vision Modelle, die wiederum mit visuellen Daten wie Fotos oder Videos arbeiten. Und genau das, was GNNs auszeichnet, ist die Art der Daten, mit denen sie arbeiten, nämlich Graphen. Graphen sind ausdrucksstarke und flexible Datenstrukturen, die aufgrund ihrer Effizienz bei der Modellierung und Darstellung verschiedener zusammengesetzter Interaktionen und Beziehungen häufig verwendet werden, was sie ideal für die Verarbeitung komplexer und vielfältiger Daten macht.
Aufgrund ihrer vielen wünschenswerten Eigenschaften haben GNNs an Popularität für die Anwendung bei der Lösung einer Vielzahl von Geschäftsproblemen gewonnen. Sie werden unter anderem bei der Erkennung von Betrug, bei der Entdeckung von Medikamenten oder bei der Analyse sozialer Netzwerke eingesetzt. GNNs machen sich die Tatsache zunutze, dass die Daten in vielen dieser Fälle sehr einfach als Graphen dargestellt werden können, wie z.B. die Beziehungen zwischen Gruppen von Menschen im Fall von sozialen Netzwerken.
Eine der vielversprechendsten Anwendungen von GNNs ist jedoch wohl die Verwendung in Empfehlungssystemen. Durch die Analyse der Beziehungen zwischen Produkten und Nutzern können GNNs personalisierte Empfehlungen aussprechen, die auf vergangenem Verhalten und Interaktionen basieren. Aufgrund der Effektivität und des geschäftlichen Nutzens solcher Empfehlungen beginnen immer mehr große Unternehmen damit, GNNs in ihren Empfehlungssystemen einzusetzen. Zum Beispiel:
- Bei Uber wurde der GraphSage-Algorithmus verwendet, um die Lebensmittel vorzuschlagen, die einem einzelnen Nutzer am ehesten zusagen,
- Pinterest nutzte seinen eigenen PinSage-Algorithmus, um visuelle Empfehlungen auf der Grundlage des Geschmacks seiner Nutzer zu geben,
- Bei Alibaba wurden GNNs zur Unterstützung einer Vielzahl von Geschäftsszenarien eingesetzt, darunter Produktempfehlungen und personalisierte Suche,
- Und für das letzte Beispiel hat Medium es für Artikel-Empfehlungen verwendet.
GNN sind ein mächtiges Werkzeug für Unternehmen, das eine Vielzahl neuer Möglichkeiten bietet. Da sich das Feld immer weiter entwickelt, sollten Unternehmen diesen schnell wachsenden Forschungsbereich und seine potenziellen Anwendungen im Auge behalten. Aus diesem Grund werden wir in diesem Blogbeitrag kurz beschreiben, was GNNs sind, wie sie funktionieren und wie wir beliebige Daten als Diagramme modellieren können. Außerdem werden wir einen genaueren Blick auf ihre Verwendung in einer ihrer vielversprechendsten Anwendungen werfen, nämlich in Empfehlungssystemen.
Was sind Graphische Neuronale Netze?
Um festzustellen, ob die Wahl von GNNs ein guter Ansatz für ein bestimmtes Geschäftsproblem ist oder nicht, ist es nützlich zu wissen, wie sie funktionieren und für welche Daten sie die besten Ergebnisse liefern können.
Wie kann man ein Problem mit einem Diagramm darstellen?
Beginnen wir mit einer Einführung in das, was Graphen eigentlich sind, denn dies ist eines der wichtigsten Konzepte, auf denen GNNs basieren. Es sind die als Graphenstrukturen modellierten Daten, die als Eingabe für diese Algorithmen dienen. Graphen sind also recht einfache Datenstrukturen, die extrem flexibel sind und Interaktionen innerhalb von Daten sehr gut modellieren können. Bei Empfehlungsdaten zum Beispiel analysieren wir in der Regel die Interaktionen zwischen Benutzern und Artikeln, die im folgenden Diagramm dargestellt sind. 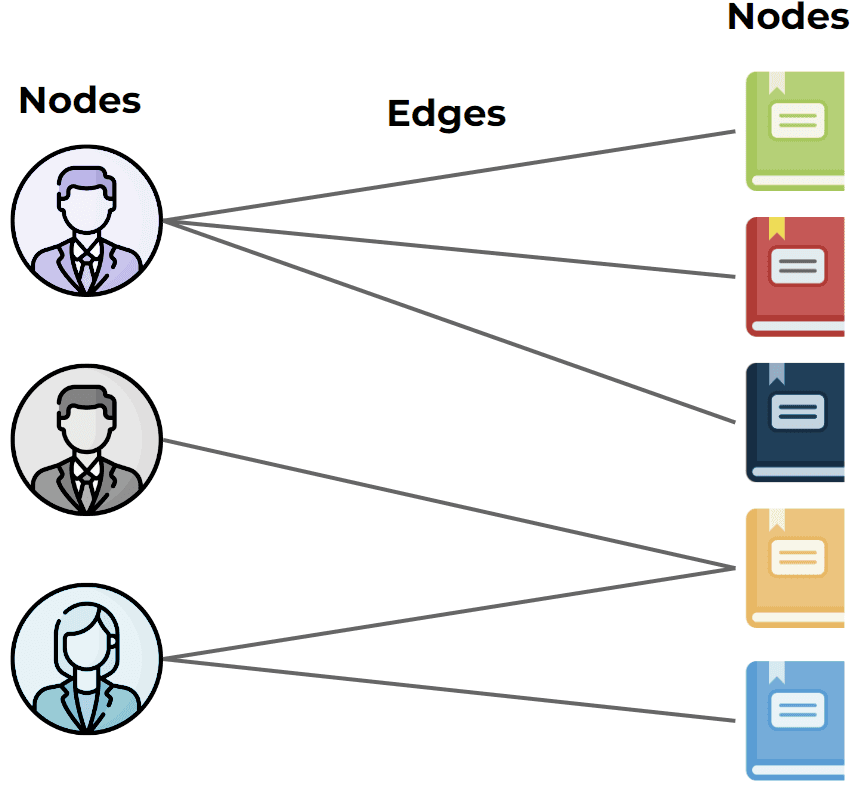
Graphen bestehen hauptsächlich aus zwei Elementen: Knoten, die bestimmte Arten von Entitäten darstellen - in diesem Fall Benutzer und Artikel - und Kanten, die hier die Interaktionen zwischen ihnen darstellen. Das können z.B. Informationen darüber sein, welche Artikel ein Benutzer gekauft oder in den Warenkorb gelegt hat.
Aber das ist noch nicht alles. Wie bereits erwähnt, sind Graphen auch sehr flexible und ausdrucksstarke Datenstrukturen. Es ist kein Problem, zusätzlich Informationen über Interaktionen zwischen Nutzern einzubeziehen, z. B. Nutzer, die Features von Instagram oder Freunden von Facebook folgen. Solche Arten von Beziehungen werden in dem untenstehenden erweiterten Diagramm als blaue Kanten dargestellt. Wir können unserer graphischen Darstellung von Daten auch ganz einfach die zeitliche Dimension hinzufügen. Dies können wir erreichen, indem wir unseren Kanten Zeitstempel oder Ordnungsindizes zuweisen, die die Reihenfolge angeben, in der einige Artikel beispielsweise von einem bestimmten Nutzer gekauft wurden (rote Zahlen im Diagramm). Es ist auch möglich, verschiedene Arten von Kanten einzubeziehen, die z.B. anzeigen, ob ein bestimmter Benutzer einen Artikel zu seinen Favoriten hinzugefügt hat (grüne gestrichelte Linien). Oder wenn zwei bestimmte Artikel in einer Art Beziehung zueinander stehen - wie das gleiche Filmgenre (braune Linie). Am Ende kann jeder Knoten zusätzlich klassische tabellarische Daten speichern, die die Merkmale eines bestimmten Benutzers oder Artikels darstellen (lila und blaue Tabellen).
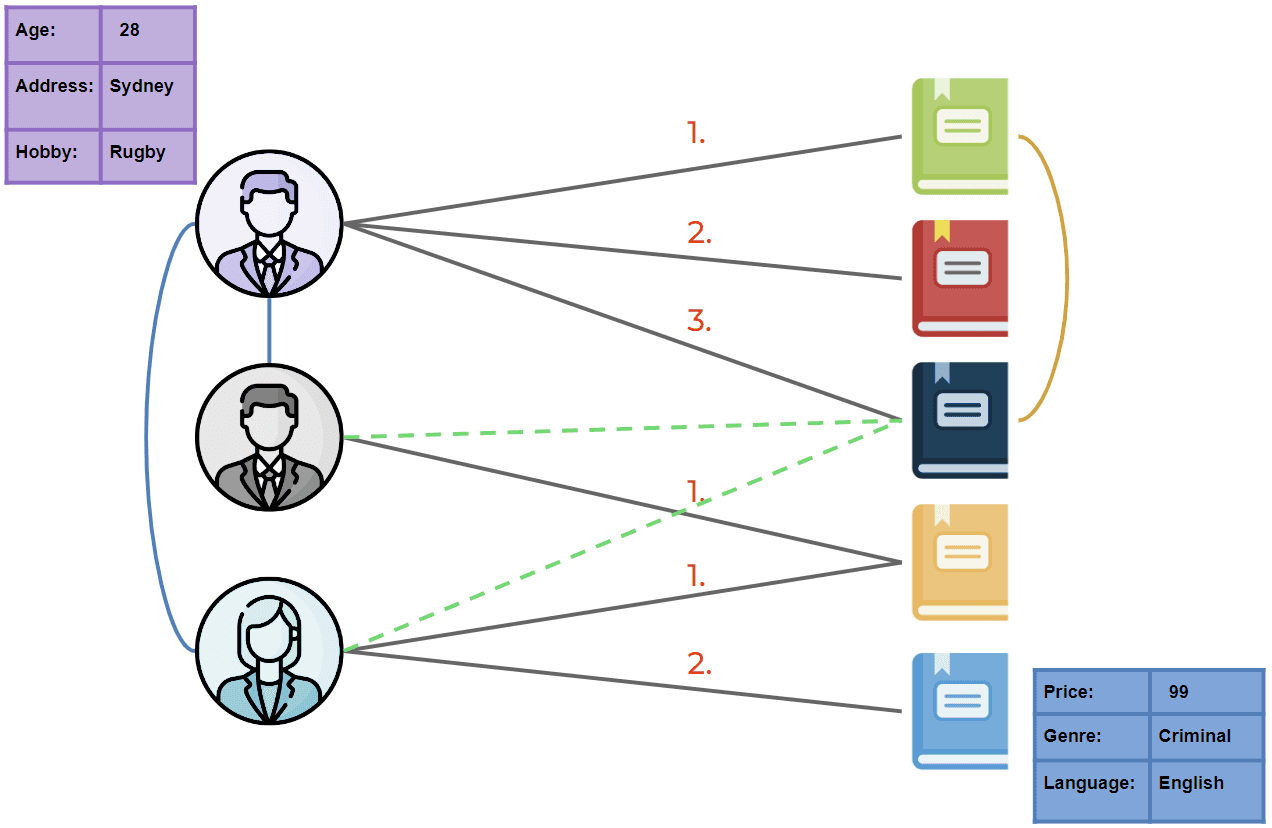
Wir wissen also, dass wir mit Graphen tatsächlich viele komplexe Interaktionen auf recht einfache Weise modellieren können. Was diese speziellen Datenstrukturen jedoch sehr nützlich macht, ist die Art und Weise, wie GNNs sie nutzen können.
Wie funktionieren Graphische Neuronale Netze?
Jetzt, da wir wissen, was Graphen sind, können wir uns darauf konzentrieren, wie GNNs sie nutzen, um Probleme zu lösen. Beginnen wir mit einem sehr einfachen Beispiel und bleiben wir beim Thema Empfehlungssysteme. Nehmen wir an, wir möchten vorhersagen, welchen Artikel wir einem Benutzer empfehlen sollten, um die Wahrscheinlichkeit zu maximieren, dass dieser Benutzer ihn kauft. Gehen wir davon aus, dass wir die Merkmale der Benutzer und Artikel bereits in Vektoreinbettungen für jeden Knoten kodiert haben, die im Diagramm unten mit den bunten Balken dargestellt sind. Vektorielle Einbettungen von Merkmalen sind einfach ihre numerischen Darstellungen, die von vielen verschiedenen Algorithmen leichter verarbeitet werden können, da es sich um ein ziemlich universelles Format handelt. In dieser Form können wir unter anderem kategorische Variablen, Bilder oder ganze Texte darstellen, bei denen es sich zum Beispiel um Beschreibungen unserer Produkte handeln kann. 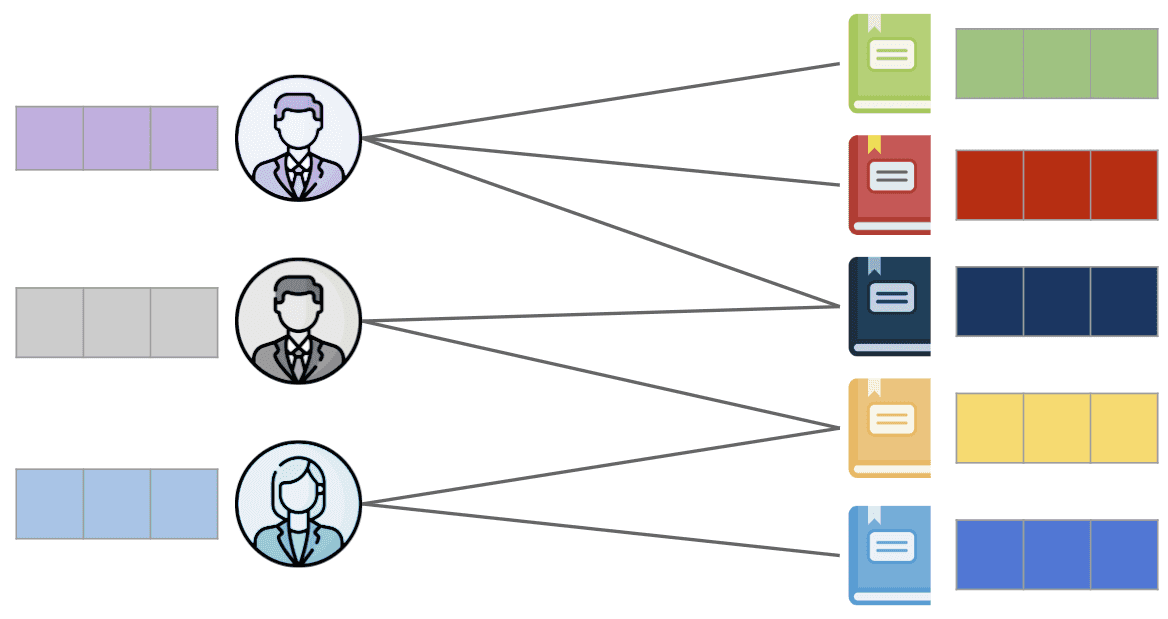
Wie bereits erwähnt, besteht unsere Aufgabe darin, vorherzusagen, welchen Artikel der betreffende Benutzer als nächstes kaufen wird - wir müssen also einfach eine neue Kante zwischen diesem Benutzer und einem Artikel finden. Eine solche Vorhersage wird uns helfen, eine nützliche Empfehlung zu erstellen. Die Idee dahinter ist, dass wir die Merkmalseinbettung der Knoten so aktualisieren, dass wir durch den Vergleich der Einbettung des Benutzers mit der Einbettung des Artikels auf der Grundlage ihrer Ähnlichkeit die Wahrscheinlichkeit berechnen können, dass dieser Benutzer diesen bestimmten Artikel kaufen wird. Wie wird dies nun gemacht? Lassen Sie uns zunächst definieren, was die Nachbarn eines Knotens im Graphen sind - das sind einfach Knoten, die mit einer Kante verbunden sind. Wie jedes andere tiefe neuronale Netzwerk haben auch neuronale Graphen-Netzwerke Schichten. In jeder dieser Schichten fassen wir für jeden Knoten Informationen von jedem seiner Nachbarn zusammen. Mit diesen aggregierten Informationen aktualisieren wir die Merkmalseinbettung des Zielknotens.
Konzentrieren wir uns in diesem Beispiel auf den grauen Benutzer in der Grafik unten. Wir sehen, dass er zwei Nachbarn hat: ein dunkelblaues Objekt und ein gelbes Objekt. In der ersten Schicht unseres GNN nehmen wir die Einbettungen dieser beiden Elemente, fassen sie zusammen und aktualisieren damit die Merkmalseinbettung des grauen Benutzers. Dieser Prozess wird als Nachrichtenweitergabe in Graphen bezeichnet. Hätten wir unserem Netzwerk eine zweite Schicht hinzugefügt, hätten wir die oben genannten Aktionen zunächst für die Nachbarn des grauen Benutzers als Zielknoten durchgeführt und erst dann den Status des grauen Benutzers aktualisiert. Ein Beispielschema finden Sie in der folgenden Abbildung. Je mehr Schichten unser Netzwerk hat, desto größer ist die Nachbarschaft, die während einer einzelnen Passage durch das Netzwerk berücksichtigt wird. Jede dieser Passagen besteht aus Schritten von Aktualisierungen der Knotenrepräsentation und wird der Reihe nach entsprechend der Reihenfolge der Schichten durchgeführt - von der letzten zur ersten. Die Aggregations- und Aktualisierungsfunktionen können viele verschiedene Formate haben und je nach Netzwerkarchitektur variieren(so kann die Aggregationsfunktion beispielsweise einen Aufmerksamkeitsmechanismus verwenden (Graph Attention Networks) und die Aktualisierungsfunktion kann eine einfache Verkettung von Vektoren sein, gefolgt von einem Vorwärtsdurchlauf durch ein tiefes neuronales Netzwerk). 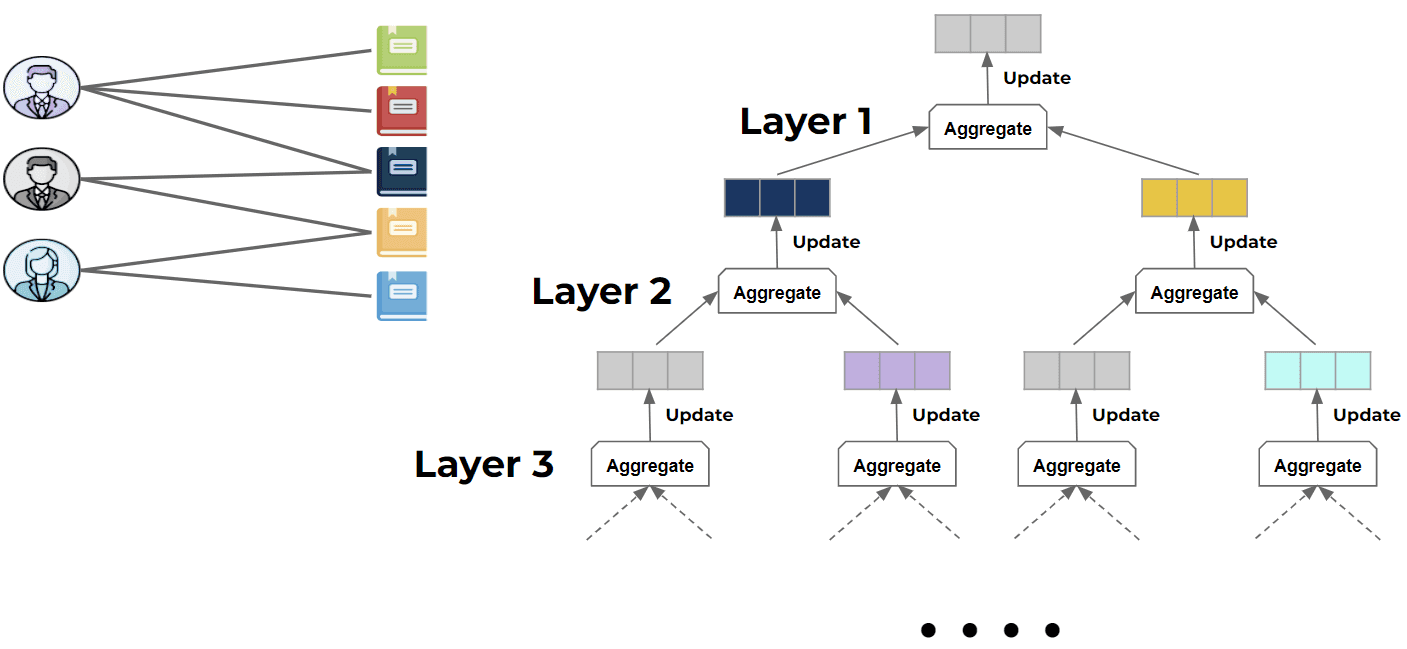
Am Ende eines solchen Prozesses können wir die Einbettung des Benutzers mit jedem der Artikel vergleichen und denjenigen empfehlen, der die größte Ähnlichkeit mit der Einbettung des Benutzers aufweist. Zum Beispiel der graue Benutzer und der rote Artikel, wie im folgenden Diagramm dargestellt. Dank des Prozesses der Nachrichtenweitergabe berücksichtigen die erstellten Benutzereinbettungen die Merkmale der Artikel, mit denen die Benutzer zuvor interagiert haben, und auch die Merkmale von Benutzern, die einen ähnlichen Geschmack wie unser Zielbenutzer haben. Dadurch wird sichergestellt, dass die endgültigen Einbettungen die Interaktionen zwischen Nutzern und Artikeln sowie deren Eigenschaften gut erfassen, was genaue und personalisierte Empfehlungen ermöglicht. 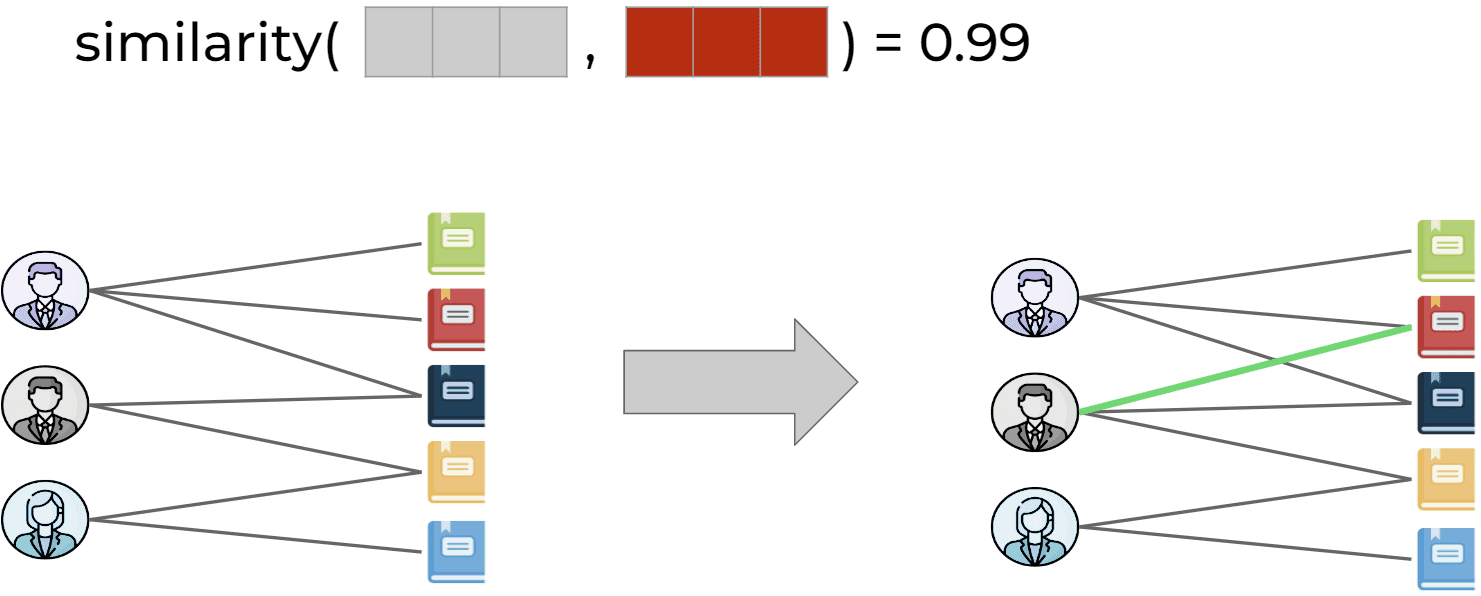
Da wir nun in etwa wissen, wie GNNs funktionieren, wollen wir uns nun auf Empfehlungssysteme konzentrieren und darauf, wie ein graphenbasierter Ansatz uns helfen kann, präzise Empfehlungen für eine Vielzahl von Problemen zu generieren.
Graphneuronale Netze in Empfehlungssystemen
Was sind Empfehlungssysteme?
Kurz gesagt sind Empfehlungssysteme Algorithmen, die in der Regel auf Modellen des maschinellen Lernens basieren und Daten über die Benutzer, die Produkte und die Interaktionen zwischen ihnen verwenden, um genaue Empfehlungen zu geben. In der E-Commerce-Branche besteht das Ziel eines typischen Empfehlungssystems darin, das Interesse eines Benutzers an einer Reihe von Produkten zu bewerten. Auf der Grundlage dieser Bewertung können wir einem Kunden Artikel vorschlagen, die er mit hoher Wahrscheinlichkeit kaufen wird, was uns letztendlich helfen soll, mehr Produkte zu verkaufen und mehr Geld zu verdienen. Dies ist einer der Gründe, warum Empfehlungssysteme eine der wertvollsten Anwendungen des maschinellen Lernens für die Lösung von Geschäftsproblemen sind. Für einen ausführlicheren Leitfaden zum Thema Empfehlungssysteme möchten wir Sie auf unser White Paper " Leitfaden für Empfehlungssysteme. Implementierung von maschinellem Lernen in Unternehmen " zu diesem Thema.

Warum Graph Neural Networks in Empfehlungssystemen verwenden?
Eine der Herausforderungen bei der Erstellung präziser Empfehlungen besteht darin, aus Daten über vergangene Interaktionen und anderen verfügbaren Nebeninformationen effektiv etwas über die Benutzer und ihre Artikeldarstellungen zu lernen. Einer der Gründe, warum GNNs in letzter Zeit häufig in Empfehlungssystemen eingesetzt werden, ist die Tatsache, dass die meisten der im Empfehlungsbereich verwendeten Daten eine Graphenstruktur aufweisen undGNNs beim Lernen von Graphenrepräsentationen führend sind. Wir können sequentielle Daten leicht als Graphen oder sogar Wissensgraphen mit vielen Beziehungsebenen und vielen Arten von Knoten darstellen. Dank der Funktionsweise von GNNs und der Möglichkeit, mehrere Schichten in ihnen zu verwenden, ist es außerdem möglich, Informationen auch von sehr weit entfernten Nachbarn zu nutzen, was dazu beiträgt, nicht nur offensichtliche Beziehungen zu berücksichtigen. Außerdem hilft es bei dem Problem des Kaltstarts, das auftritt, wenn nur eine begrenzte Menge an Daten über frühere Benutzerinteraktionen vorhanden ist.
Ein weiterer Punkt ist, dass Algorithmen wie XGBoost, Random Forest oder standardmäßige Deep Learning-Algorithmen einen konventionellen maschinellen Lernansatz verwenden, der auf einem tabellarischen Datenformat basiert. Diese Ansätze sind nicht für Graphdatenstrukturen optimiert. Hinzu kommt, dass Graphenlösungen derzeit in vielen Empfehlungsbenchmarks die besten Ergebnisse erzielen (Paperswithcode , BARS) und erfreuen sich deshalb großer Beliebtheit. Und nicht zuletzt sind Graphen, wie bereits erwähnt, sehr ausdrucksstarke und flexible Datenstrukturen, die es uns in Verbindung mit der Tatsache, dass GNNs vielseitige Algorithmen sind, ermöglichen, sie zur Lösung einer Vielzahl von Empfehlungsproblemen einzusetzen. Aus diesem Grund werden wir uns jetzt darauf konzentrieren zu erklären, wie und wo wir sie auf unterschiedliche Weise einsetzen können, je nachdem, welches Problem wir genau lösen wollen.
Kategorien von Graph Neural Network-basierten Empfehlungen
Empfehlungsaufgaben können sehr unterschiedliche Formen annehmen. Es hängt vor allem davon ab, was genau wir vorhersagen wollen, welche Faktoren die Handlungen unserer Zielnutzer beeinflussen und einfach davon, auf welche Daten wir Zugriff haben. Wir würden das Problem der Empfehlungen anders angehen, wenn wir keinen Zugang zu irgendwelchen Daten über unsere Kunden hätten, sondern nur zu Informationen über ihre anonymen Sitzungen, und anders, wenn wir z.B. Zugang zu Informationen über ihre Konten oder sozialen Gruppen hätten, denen sie angehören. Dank der vielen Eigenschaften von Graphen, die wir bereits erwähnt haben, können wir jedoch viele Arten von Empfehlungsproblemen mit GNNs leicht lösen. Wir werden nun kurz einige Arten von Ansätzen vorstellen, die GNNs für verschiedene Empfehlungsaufgaben nutzen.
Kollaboratives Filtern - z.B. einfache Geschmacksähnlichkeit 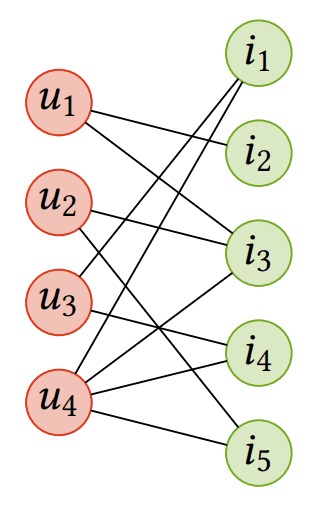 Wie im vorangegangenen Beispiel können wir die Historie aller Transaktionen unserer Benutzer mit Hilfe eines Graphen modellieren, dessen Knoten Benutzer (ui ) und Artikel (ii ) darstellen und dessen Kanten die Interaktionen zwischen ihnen repräsentieren. Quelle des Bildes: Graph Neural Networks in Recommender Systems: Ein Überblick
Wie im vorangegangenen Beispiel können wir die Historie aller Transaktionen unserer Benutzer mit Hilfe eines Graphen modellieren, dessen Knoten Benutzer (ui ) und Artikel (ii ) darstellen und dessen Kanten die Interaktionen zwischen ihnen repräsentieren. Quelle des Bildes: Graph Neural Networks in Recommender Systems: Ein Überblick
Die kollaborative Filterung basiert auf der Empfehlung von Artikeln durch die Identifizierung anderer Benutzer mit ähnlichem Geschmack; sie verwendet deren Meinungen, um dem Zielbenutzer Artikel zu empfehlen. Dieser Ansatz erfordert, dass wir die Transaktionshistorie jedes Nutzers speichern, aber er ist auch eine der einfachsten und beliebtesten Techniken, die oft zufriedenstellende Ergebnisse liefert. Wie man ein solches Problem mit Hilfe von Graphen modelliert, haben wir bereits in dem Abschnitt über die Einführung in GNNs vorgestellt.
Sequentielle Empfehlung - z.B. Vorhersage der nächsten Aktion in der Sitzung eines anonymen Benutzers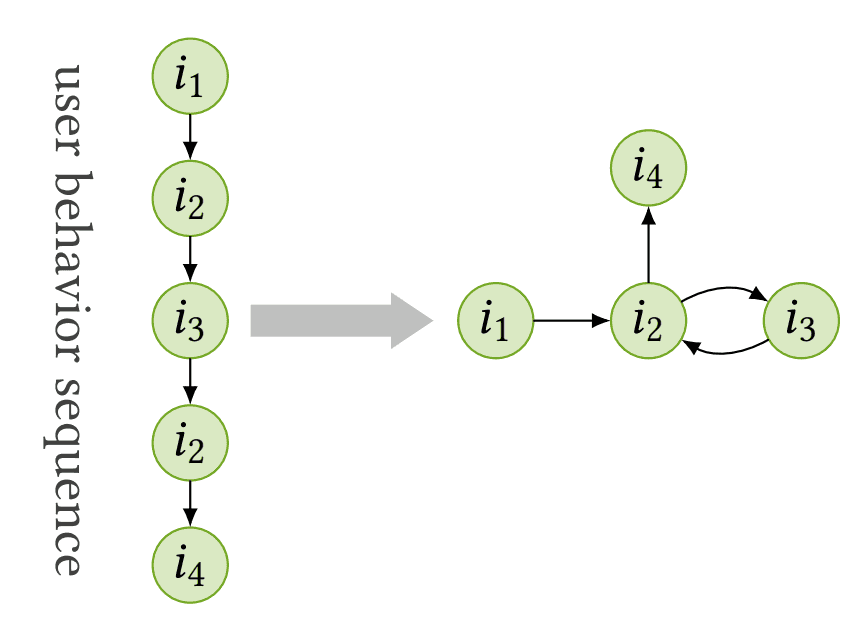 Das Nutzerverhalten auf einer bestimmten Website kann als eine Abfolge von Klicks auf verschiedene Elemente beschrieben werden. Wir sind in der Lage, eine solche Abfolge auf sehr einfache Weise als Diagramm darzustellen.
Das Nutzerverhalten auf einer bestimmten Website kann als eine Abfolge von Klicks auf verschiedene Elemente beschrieben werden. Wir sind in der Lage, eine solche Abfolge auf sehr einfache Weise als Diagramm darzustellen.
Wenn wir jedoch nicht in der Lage sind, die Identität unserer Website-Besucher festzustellen, können wir auch nicht deren Transaktionsverlauf speichern. In diesem Fall können wir unsere Empfehlungen nur auf die Aktivitäten eines bestimmten Benutzers während einer laufenden Browsing-Sitzung stützen. Eine solche Aktivität kann aus Klicks auf verschiedene Artikel auf unserer Website, dem Hinzufügen von Artikeln in den Einkaufswagen oder aus Transaktionen bestehen. Wir können die Sequenzen solcher Aktionen als Graph darstellen, wie im obigen Diagramm zu sehen ist. Nach der Analyse vieler solcher Sequenzen von Interaktionen mit Artikeln ist das neuronale Graphennetzwerk in der Lage, die nächste Aktion vorherzusagen, die für den Benutzer von Interesse ist, und sie ihm zu empfehlen.
Soziale Empfehlungen - z.B. Geschmacksähnlichkeit unter Berücksichtigung der Vorlieben von Freunden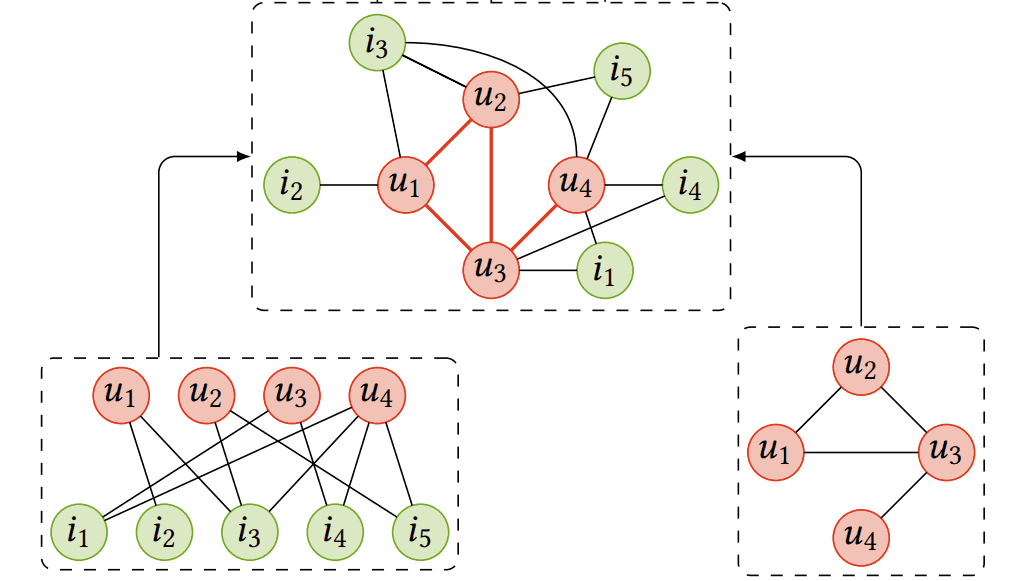 Um die sozialen Interaktionen der Benutzer zu berücksichtigen und sie für Empfehlungen zu nutzen, können wir den Graphen der sozialen Netzwerke der Benutzer in den Basisgraphen aus dem Ansatz der kollaborativen Filterung integrieren.
Um die sozialen Interaktionen der Benutzer zu berücksichtigen und sie für Empfehlungen zu nutzen, können wir den Graphen der sozialen Netzwerke der Benutzer in den Basisgraphen aus dem Ansatz der kollaborativen Filterung integrieren.
Ein wichtiger Faktor, der die Kaufentscheidungen der Nutzer oft beeinflusst, ist das Verhalten anderer Nutzer in ihren sozialen Netzwerken. Mit dem Aufkommen sozialer Online-Netzwerke wurden soziale Empfehlungssysteme vorgeschlagen, die die Präferenzen der Mitglieder der sozialen Gruppe jedes Nutzers nutzen, um die Empfehlungen zu verbessern. Wenn wir Zugang zu Informationen über die sozialen Interaktionen unserer Nutzer haben, besteht eine gute Chance, dass dies die Effektivität unseres Empfehlungssystems positiv beeinflussen kann.
Wissensgraphen-basierte Empfehlungen - z.B. verbesserte Darstellungen von Gegenständen/Objekten Nicht nur Benutzer können definierte Beziehungen zueinander haben. Oft kann jedes Objekt auf viele verschiedene Arten beschrieben werden, was die Grundlage für Beziehungen zwischen den Objekten bildet. Solche Beziehungen haben oft umfangreiche semantische Implikationen.
Nicht nur Benutzer können definierte Beziehungen zueinander haben. Oft kann jedes Objekt auf viele verschiedene Arten beschrieben werden, was die Grundlage für Beziehungen zwischen den Objekten bildet. Solche Beziehungen haben oft umfangreiche semantische Implikationen.
Wie im vorangegangenen Beispiel erwähnt, werden soziale Netzwerke, die die Beziehungen zwischen Menschen widerspiegeln, zur Anreicherung von Benutzerdarstellungen verwendet, während Wissensgraphen, die die Beziehungen zwischen Artikeln durch ihre verschiedenen Attribute ausdrücken, zur Verbesserung von Artikeldarstellungen verwendet werden. Die reichhaltigen semantischen Beziehungen zwischen den Artikeln im Wissensgraphen können auch dabei helfen, die Relevanz der Verbindungen zwischen ihnen zu erforschen und die Interpretierbarkeit der Ergebnisse zu erhöhen, indem die Verbindungen zwischen dem Wissensgraphen, den in der Vergangenheit von den Benutzern verwendeten Artikeln und den vom Benutzer empfohlenen Artikeln analysiert werden.
Wie Sie sehen können, können wir Empfehlungsprobleme auf viele verschiedene Arten angehen. Für GNNs ist das jedoch kein großes Problem, denn dank der Flexibilität von Graphen können sie jedes dieser Probleme so angehen, als ob sie dafür konzipiert wären. Wenn Sie neugierig sind, welche spezifischen Graph Neural Network-Modelle zur Lösung dieser Probleme verwendet werden können, empfehlen wir Ihnen den Artikel Graph Neural Networks in Recommender Systems: Ein Überblick. Und wenn Sie lernen möchten, wie man Graph-Lösungen anwendet und implementiert, können wir mit dem nächsten Abschnitt fortfahren.
Tools für die Implementierung von Graphenlösungen
Wie wir bereits erwähnt haben, sind Diagramme eine einzigartige Art von Daten und erfordern andere Modelle und Lösungen als ein standardmäßiger tabellarischer Ansatz. Glücklicherweise wurden dank des schnell wachsenden Interesses an GNNs eine Reihe von hochwertigen Tools entwickelt, die diese Arbeit erleichtern. Gute Beispiele dafür sind PyTorch Geometric und Deep Graph Library. Dabei handelt es sich um Python-Pakete, die u.a. in PyTorch integriert sind und mit denen Sie sehr einfach Deep Graph-Lösungen erstellen können. Im Bereich der Graphdatenbanken ist Neo4j einer der Marktführer und bietet vollständig verwaltete Cloud-Services mit vielen Graphlösungen an. Wir können damit Daten im Graphenformat speichern und verwalten, was manchmal natürlicher ist und die Pflege von Datenbeziehungen ermöglicht, die sehr schnelle Abfragen und tieferen Kontext für Analysen liefern. Außerdem hat Amazon vor kurzem einen neuen Service in AWS eingeführt, nämlich Amazon Neptune ML. Er verwendet GNNs, um Vorhersagen anhand von Graphdaten zu ermöglichen. GraphX, eine der Spark-Komponenten, ist ebenfalls ein bemerkenswertes Tool, das graph-parallele Berechnungen unterstützt.
Ein Beispiel für die Verwendung von Diagrammwerkzeugen finden Sie in dem Anwendungsfall Empfehlungen, der in den QuickStart ML Blueprints realisiert wurde. QuickStart ML Blueprints ist ein Framework, das wir bei GetInData entwickeln. Kurz gesagt handelt es sich dabei um eine Reihe von bewährten Praktiken aus den Bereichen Engineering und maschinelles Lernen für das schnelle Prototyping von Lösungen für maschinelles Lernen auf strukturierte Weise, unterstützt durch Dokumentation und reale Beispiele. Es ermöglicht ein schnelles, strukturiertes und effizientes Prototyping, macht das Testen neuer vielversprechender Trends in der Datenwissenschaft sehr einfach und ist ein guter Rahmen für die Evaluierung neuer hochmoderner Lösungen in realen Szenarien und Datensätzen.
Ein Beispiel für eine solche hochmoderne Lösung ist ein GNN, das für den Zweck sequentieller Empfehlungen für den Datensatz des E-Commerce-Onlineshops Otto implementiert wurde. Das spezifische Netzwerk, das für diese Aufgabe verwendet wurde, war das Dynamic Graph Neural Networks for Sequential Recommendation (DGSR). Dieses Modell nutzt Ideen aus dynamischen neuronalen Graphennetzwerken, um die dynamischen kollaborativen Signale zwischen allen Interaktionen in den Daten zu modellieren, was bei der Erforschung des interaktiven Verhaltens von Benutzern und Artikeln mit Zeit- und Bestellinformationen hilft. QuickStart ML Blueprints ist ein Open-Source-Projekt. Wenn Sie also mehr darüber erfahren möchten, können Sie das Projekt-Repository durchsuchen .
Zusammenfassung
Graphische neuronale Netze sind Teil eines äußerst aktiven und schnell wachsenden Forschungsgebiets. Auch wenn man bedenkt, wie effektiv und vielseitig diese Algorithmen sind, lohnt es sich, ihre Entwicklung genau zu beobachten. Empfehlungsdaten, die in der Regel aus Interaktionen zwischen Nutzern und Artikeln bestehen, können je nach Aufgabenstellung auf viele verschiedene Arten als Graph modelliert werden. Dieser Aspekt trägt weiter zur Attraktivität von GNNs bei, da Empfehlungssysteme zu den Anwendungen des maschinellen Lernens gehören, die den größten geschäftlichen Nutzen bringen.
Wenn Sie sich nach der Lektüre dieses Artikels für das Thema Graphische Neuronale Netze interessieren, bleiben Sie dran für die nächsten Blogs in dieser Serie. Wenn Sie möchten, dass wir Ihnen zeigen, wie Sie den QuickStart ML Blueprints Ansatz in Ihrem Unternehmen anwenden können, melden Sie sich für eine Demo an.
Verfasst von
Michał Stawikowski
Unsere Ideen
Weitere Blogs




Contact