
Dieser Artikel wurde ursprünglich auf 47deg.com am 8. Februar 2022 veröffentlicht.
Apache Spark ist ein äußerst beliebtes Data-Engineering-Tool, das einen großen Teil der Scala-Community ausmacht. Jede Spark-Version ist an eine bestimmte Scala-Version gebunden, so dass ein großer Teil der Scala-Benutzer kaum Kontrolle über die von ihnen verwendete Scala-Version hat, da Spark diese vorgibt.
Scala 2.13 wurde im Juni 2019 veröffentlicht, aber es dauerte mehr als zwei Jahre und eine große Anstrengung der Spark-Maintainer, bis die erste Scala 2.13-kompatible Spark-Version (Spark 3.2.0) erschien. Die Entwickler wussten zwar zu schätzen, wie viel Arbeit in die Aktualisierung von Spark auf Scala 2.13 geflossen ist, aber es war dennoch ein wenig frustrierend, so lange auf einer älteren Scala-Version festzusitzen.
Wenn es zwei Jahre gedauert hat, bis Spark von Scala 2.12 auf 2.13 aktualisiert wurde, fragen Sie sich vielleicht, wie lange es dauern wird, bis eine Scala 3-Version von Spark erscheint. Die Antwort lautet: Das spielt keine Rolle! Dank der Kompatibilität zwischen Scala 2.13 und Scala 3 können wir bereits Scala 3 für die Erstellung von Spark-Anwendungen verwenden.
Im weiteren Verlauf dieses Beitrags möchte ich Ihnen zeigen, wie Sie eine Scala 3-Anwendung erstellen, die auf einem Spark 3.2.0-Cluster läuft. Ich beginne mit einer kleinen Hallo-Welt-Anwendung und demonstriere dann eine realistischere Anwendung, die mehr Funktionen von Spark nutzt. Ich hoffe, dass ich damit mit einigen Mythen aufräumen kann und die Leute davon überzeugen kann, dass es sinnvoll ist, eine Scala 3 Spark-Anwendung in Produktion zu bringen.
Der gesamte Code und die Skripte für diesen Beitrag sind auf GitHub verfügbar.
Hallo, Welt!
Lassen Sie uns ohne Umschweife eine Spark-Anwendung in Scala 3 schreiben.
sbt-Konfiguration
Wir beginnen mit der sbt-Konfiguration. Die Datei build.sbt ist sehr kurz, erfordert aber eine kleine Erklärung:
scalaVersion := "3.1.1"
libraryDependencies ++= Seq(
("org.apache.spark" %% "spark-sql" % "3.2.0" % "provided").cross(CrossVersion.for3Use2_13)
)
// include the 'provided' Spark dependency on the classpath for sbt run Compile / run := Defaults.runTask(Compile / fullClasspath, Compile / run / mainClass, Compile / run / runner).evaluated - Wir setzen die Scala-Version auf 3.1.1, die neueste Scala-Version zum Zeitpunkt der Erstellung dieses Artikels. Woohoo, Scala 3! Das bedeutet, dass wir die neue Hipster-Syntax verwenden können und glänzende neue Funktionen wie Enums, Erweiterungsmethoden und undurchsichtige Typen in die Hände bekommen.
-
Wir fügen eine Abhängigkeit von spark-sql v3.2.0 hinzu, damit wir die Spark-API in unserem Code verwenden können
- Wir markieren es als
provided, weil wir unsere App als uber-jar für die Bereitstellung in einem Spark-Cluster verpacken werden. Wir möchten die Spark-API nicht in unser Bereitstellungspaket aufnehmen, da die Spark-Laufzeitumgebung sie bereitstellt. - Da es keine Scala 3-Version von
spark-sqlgibt, verwenden wirCrossVersion.for3Use2_13, um sbt mitzuteilen, dass wir die Scala 2.13-Version dieser Bibliothek benötigen
- Wir markieren es als
- Schließlich fügen wir eine einzeilige Beschwörungsformel hinzu, die sbt anweist, alle "bereitgestellten" Abhängigkeiten zum Klassenpfad hinzuzufügen, wenn wir die Aufgabe
runausführen. Wenn wir unseren Code mitsbt runtesten, können wir einen viel schnelleren Testzyklus durchführen, als wenn wir die Anwendung nach jeder Änderung neu verpacken und auf einem Spark-Cluster bereitstellen.
Eine Warnung über Abhängigkeiten
Scala 3 und 2.13 können zwar auf magische Weise zusammenarbeiten, aber es gibt eine Einschränkung, derer Sie sich bewusst sein sollten: Wenn Sie versehentlich sowohl die _2.13 als auch die _3 Version einer bestimmten Bibliothek in Ihrem Klassenpfad haben, landen Sie direkt in der Hölle der Abhängigkeiten. Tatsächlich erkennt sbt diesen Fall während der Auflösung der Abhängigkeiten und scheitert lautstark, um Sie vor sich selbst zu retten.
Für unsere Hallo-Welt-Anwendung spielt dies keine Rolle, da wir außer spark-sql keine weiteren Abhängigkeiten haben, aber ein echter Spark-Auftrag hat wahrscheinlich Abhängigkeiten von anderen Bibliotheken. Jedes Mal, wenn Sie eine Abhängigkeit hinzufügen, müssen Sie den Graphen der transitiven Abhängigkeiten überprüfen und CrossVersion.for3Use2_13 verwenden, wenn nötig.
Glücklicherweise gibt es bei Spark nur eine Handvoll Scala-Abhängigkeiten:
com.fasterxml.jackson.module::jackson-module-scalacom.twitter::chillorg.json4s::json4s-jacksonorg.scala-lang.modules::scala-parallel-collectionsorg.scala-lang.modules::scala-parser-combinatorsorg.scala-lang.modules::scala-xml
Code
Unsere Hallo-Welt besteht nur aus ein paar Zeilen Scala:
// src/main/scala/helloworld/HelloWorld.scala
package helloworld
import org.apache.spark.sql.SparkSession
object HelloWorld:
@main def run =
val spark = SparkSession.builder
.appName("HelloWorld")
.master(sys.env.getOrElse("SPARK_MASTER_URL", "local[*]"))
.getOrCreate() // 1
import spark.implicits._ // 2
val df = List("hello", "world").toDF // 3
df.show() // 4
spark.stop
Wenn Sie mit Spark vertraut sind, dürfte es hier keine Überraschungen geben:
- Erstellen Sie eine Spark-Sitzung, die Sie standardmäßig auf einem lokalen, eigenständigen Spark-Cluster ausführen.
- Importieren Sie einige Implikate, damit wir in Schritt 3
.toDFaufrufen können. - Erstellen Sie einen einspaltigen DataFrame mit zwei Zeilen.
- Gibt den Inhalt des DataFrame auf stdout aus.
Wenn wir diesen Code mit sbt run ausführen, sehen wir eine Ladung von Spark-Protokollen und unseren DataFrame:
+-----+
|value|
+-----+
|hello|
|world|
+-----+
Erfolgreich! Wir haben gerade unsere erste Scala 3 Spark-Anwendung ausgeführt.
Sie haben vielleicht bemerkt, dass der Name der Klasse name lautet helloworld.runauch wenn unser a>@main</code/a>code>@main</code</a-annotierte Ausführungsmethode befindet sich innerhalb des HelloWorld-Objekts. Dieses Verhalten ist in den Scala 3-Dokumenten dokumentiert, aber ich fand es ein wenig überraschend.
Ausführung auf einem echten Spark-Cluster
Die Ausführung innerhalb von sbt ist schön und gut, aber wir müssen sehen, ob dies bei der Bereitstellung in einem tatsächlichen Spark-Cluster funktionieren wird.
Das GitHub Repo für diesen Beitrag enthält eine Dockerdatei, docker-compose.yml und Skripte zum Aufbau und Betrieb eines 3-Knoten-Spark-Clusters in Docker. Ich werde nicht auf alle Details des Docker-Images eingehen, aber es gibt einen wichtigen Punkt zu erwähnen: Es stehen mehrere Spark 3.2.0-Binärdateien zum Download bereit und Sie müssen die richtige auswählen, wenn Sie Spark installieren. Obwohl Spark 3.2.0 Scala 2.13 unterstützt, ist die Standard-Scalaversion immer noch 2.12. Sie müssen also die Version mit dem Suffix _scala2.13 wählen.
(Wenn Sie eine verwaltete Spark-Plattform wie Databricks oder AWS EMR verwenden, müssen Sie eine Spark 3.2.0 + Scala 2.13-Laufzeit wählen. Weder Databricks noch EMR bieten derzeit eine solche Laufzeitumgebung an).
Wenn Sie ./start-spark-cluster.sh ausführen, wird das Docker-Image erstellt und ein Spark-Cluster mit einem Master-Knoten und zwei Worker-Knoten gestartet.
Wenn Sie ./open-spark-UIs.sh ausführen, sollten Sie die Spark-Benutzeroberfläche in Ihrem Browser sehen können:
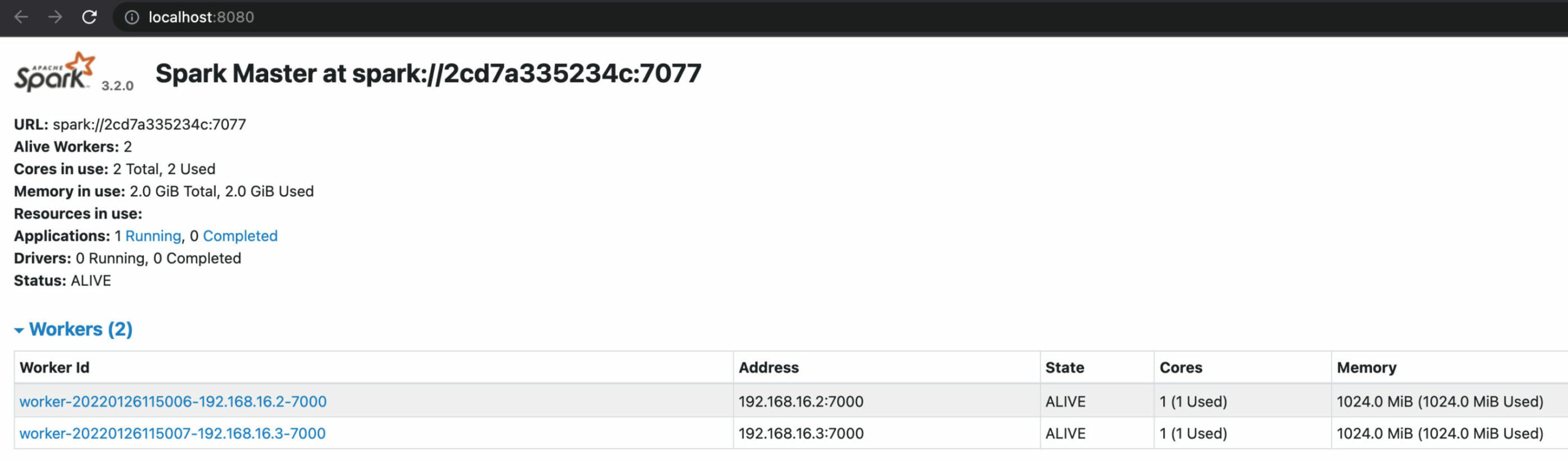
Wir sind nun bereit, unsere Spark-Anwendung zu verpacken und sie zur Ausführung an den Cluster zu senden.
Wenn Sie sbt assembly ausführen, wird ein Uber-Jar erstellt, das unseren Anwendungscode und die Scala-Standardbibliothek enthält. (Eigentlich enthält es zwei Scala-Standardbibliotheken: eine für Scala 2.13.6 und eine für 3.1.1. Ich verstehe das zwar nicht ganz, aber es scheint zu funktionieren!) Denken Sie daran, dass wir die Spark-Abhängigkeit als "bereitgestellt" markiert haben, so dass sie nicht im uber-jar enthalten ist.
Sie können nun das Skript ./run-hello-world.sh ausführen, um unsere App auf dem Spark-Cluster zu starten. Sie sollten eine ähnliche Terminalausgabe sehen wie bei der Ausführung der App in sbt.
Wenn Sie die Spark Master UI aktualisieren, sollten Sie sehen, dass die App erfolgreich abgeschlossen wurde:

Schön!
Eine realistischere Anwendung
Jetzt, wo wir eine "Hallo-Welt" im Kopf haben, können wir eine komplexere Anwendung erstellen, die mehr Funktionen von Spark nutzt und ein bisschen mehr wie ein Spark-Job aussieht, den Sie in der realen Welt schreiben könnten.
Spark-Funktionen von Interesse
Eine Spark-Funktion, die es wert ist, überprüft zu werden, sind typisierte Datasets. Oft ist es besser, mit einem Dataset[MyCaseClass] zu arbeiten als mit einem rohen DataFrame, so dass das Typsystem von Scala uns helfen kann, Fehler zu vermeiden. Aber Sparks Mechanismus für die Konvertierung zwischen Fallklassen und seiner internen Datendarstellung beruht auf der Reflexion zur Laufzeit - wird das in Scala 3 funktionieren? Das werden wir bald herausfinden.
Eine weitere wichtige Spark-Funktion, die wir üben sollten, sind benutzerdefinierte Funktionen (UDFs), da Spark unseren Scala-Code serialisieren und auf den Worker-Knoten ausführen muss. Intuitiv scheint das etwas zu sein, das bei der Verwendung von Scala 3 kaputt gehen könnte.
Anwendungsübersicht
Wir werden Spark verwenden, um das klassische Traveling Salesman Problem (TSP) zu lösen. Wir wollen die kürzeste Route finden, die bei einer beliebigen Menge von N Städten beginnt, alle anderen Städte genau einmal besucht und schließlich zum Ausgangspunkt zurückkehrt.
Das effiziente Lösen des TSP übersteigt bei weitem den Rahmen dieses Beitrags, daher werden wir einen sehr naiven Brute-Force-Ansatz verwenden. Allerdings können wir zumindest die Berechnung über den Spark-Cluster verteilen, was die Sache etwas beschleunigen sollte.
(Nebenbei: einen unterhaltsamen Einblick in die Geschichte der TSP-Forschung und einen Überblick über den aktuellen Stand der Technik bietet dieser Vortrag von Prof. William Cook von der University of Waterloo).
Unsere Anwendung funktioniert folgendermaßen:
- Laden Sie eine Liste von Städten (Namen und Orte) aus einer Konfigurationsdatei.
- Erstellen Sie eine Liste mit allen möglichen Reisen durch diese Städte.
- Teilen Sie die Fahrten in Etappen auf, von einer Stadt zur nächsten.
- Berechnen Sie die Entfernung der einzelnen Beine.
- Addieren Sie diese Entfernungen, um die Gesamtentfernung jeder Reise zu ermitteln.
- Drucken Sie die Route und die Entfernung der kürzesten Strecke aus.
Dies gibt uns die Möglichkeit, einige Spark-Funktionen zu überprüfen, darunter die beiden oben genannten.
Datenmodell
Hier sind die Fallklassen, die wir verwenden werden, um unsere Daten zu modellieren, während sie einige Transformationen durchlaufen:
// A city with a name and a lat/long coordinate
case class City(name: String, lat: Double, lon: Double)
// A stop at a given city as part of a given journey
case class JourneyStop(journeyID: String, index: Int, city: City)
// A leg of a journey, from one city to the next
case class JourneyLeg(journeyID: String, index: Int, city: City, previousCity: City)
// The distance in km of a given journey leg
case class JourneyLegDistance(journeyID: String, index: Int, distance: Double)
Wir werden nach Möglichkeit typisierte Datensätze verwenden, damit wir mit diesen Fallklassen in Spark arbeiten können, anstatt mit rohen Rows zu arbeiten.
Laden der Daten in Spark
Überspringen wir die Teile, in denen wir die Städte aus der Konfiguration laden und alle möglichen Fahrten aufzählen, nehmen wir einfach an, wir hätten eine Liste von JourneyStop.
Wir möchten sie in eine Dataset laden, damit wir mit ihr in Spark arbeiten können:
val journeyStops: List[JourneyStop] = ???
val journeyStopsDs: Dataset[JourneyStop] = spark.createDataset(journeyStops)
Leider lässt sich das nicht kompilieren. Wir sind auf unseren ersten Scala 3-Stolperstein gestoßen!
[error] -- Error: /Users/chris/code/spark-scala3-example/src/main/scala/tsp/TravellingSalesman.scala:61:80
[error] 61 | val journeyStopsDs: Dataset[JourneyStop] = spark.createDataset(journeyStops)
[error] | ^
[error] |Unable to find encoder for type tsp.TravellingSalesman.JourneyStop. An implicit Encoder[tsp.TravellingSalesman.JourneyStop] is needed to store tsp.TravellingSalesman.JourneyStop instances in a Dataset. Primitive types (Int, String, etc) and Product types (case classes) are supported by importing spark.implicits._ Support for serializing other types will be added in future releases..
[error] |I found:
[error] |
[error] | spark.implicits.newProductEncoder[tsp.TravellingSalesman.JourneyStop](
[error] | /* missing */
[error] | summon[reflect.runtime.universe.TypeTag[tsp.TravellingSalesman.JourneyStop]]
[error] | )
[error] |
[error] |But no implicit values were found that match type reflect.runtime.universe.TypeTag[tsp.TravellingSalesman.JourneyStop].
Die Compiler-Meldung ist recht hilfreich: implizite Auflösungsfehler sind in Scala 3 viel informativer als in Scala 2. Spark versucht, einen Encoder abzuleiten, um unsere Case-Klasse in seine interne Datendarstellung zu konvertieren, aber das schlägt fehl, weil es kein scala.reflect.runtime.universe.TypeTag finden kann. Scala 3 unterstützt keine Runtime Reflection, daher ist es nicht überraschend, dass dies fehlgeschlagen ist.
Glücklicherweise hat Vincenzo Bazzucchi vom Scala Center eine praktische Bibliothek geschrieben, die sich um dieses Problem kümmert. Sie heißt spark-scala3 und bietet eine generische Ableitung von Encoder-Instanzen für Case-Klassen unter Verwendung der neuen Metaprogrammierfunktionen von Scala 3 anstelle von Runtime Reflection. Nachdem wir diese Bibliothek als Abhängigkeit hinzugefügt und den notwendigen Import hinzugefügt haben, lässt sich unser Code kompilieren.
Damit ist die erste der beiden Spark-Funktionen, die Sie interessieren, erledigt: typisierte Datensätze.
Wir können nun unsere erste Umwandlung vornehmen, indem wir Fahrtunterbrechungen in Fahrtabschnitte umwandeln:
val journeyLegs: Dataset[JourneyLeg] = journeyStopsDs
.withColumn(
"previousCity",
lag("city", 1).over(Window.partitionBy("journeyID").orderBy("index"))
)
.as[JourneyLeg]
Dazu gibt es nicht viel zu sagen, außer dass wir ohne Probleme von einem getippten Dataset zu einem Dataframe und dann wieder zu einem getippten Dataset wechseln können.
Benutzerdefinierte Funktionen
Der nächste Schritt besteht darin, die Entfernung der einzelnen Streckenabschnitte zu berechnen. Wir tun dies, indem wir unsere eigene Implementierung der Haversine-Formel entwickeln. Ich werde die Details der Implementierung auslassen.
Da wir eine benutzerdefinierte Funktion haben, die wir auf die Daten anwenden müssen, ist dies eine gute Gelegenheit, UDFs zu testen. Im Allgemeinen empfiehlt es sich, die Verwendung von UDFs zu minimieren und nur die in Spark integrierten Transformationsoperatoren zu verwenden, da UDFs für den Catalyst-Optimierer eine Blackbox sind. Aber diese Abstandsberechnung wäre mit den eingebauten Operatoren ziemlich mühsam zu schreiben.
Um eine UDF mit Scala zu erstellen, schreiben Sie normalerweise eine einfache Scala-Funktion und verpacken sie dann in Sparks udf(...) Hilfsfunktion, um sie in eine UDF zu verwandeln:
def addAndDouble(x: Int, y: Int): Int = (x + y) * 2
val addAndDoubleUDF = udf(addAndDouble)
Leider funktioniert das mit Scala 3 nicht, da es auf TypeTag beruht, genau wie die automatische Ableitung von Encoder Instanzen für Fallklassen.
Ich konnte die Java-API verwenden, um eine UDF zu erstellen, aber das ist ziemlich unangenehm:
val haversineJavaUDF: UDF4[JDouble, JDouble, JDouble, JDouble, JDouble] =
new UDF4[JDouble, JDouble, JDouble, JDouble, JDouble] {
def call(lat1: JDouble, lon1: JDouble, lat2: JDouble, lon2: JDouble): JDouble =
JDouble.valueOf(Haversine.distance(lat1, lon1, lat2, lon2))
}
val haversineUDF: UserDefinedFunction = udf(haversineJavaUDF, DataTypes.DoubleType)
Sobald das erledigt ist, können wir die UDF verwenden, um eine distance Spalte zu unserem Dataset hinzuzufügen:
val journeyLegDistances: Dataset[JourneyLegDistance] = journeyLegs
.withColumn(
"distance",
when(isnull($"previousCity"), 0.0)
.otherwise(haversineUDF($"city.lat", $"city.lon", $"previousCity.lat", $"previousCity.lon"))
)
.drop("city", "previousCity")
.as[JourneyLegDistance]
In unserem Fall brauchen wir jedoch eigentlich keine UDF zu verwenden. Wir können das Gleiche einfacher und sicherer mit map erreichen:
val journeyLegDistancesWithoutUDF: Dataset[JourneyLegDistance] = journeyLegs.map { leg =>
val distance = Option(leg.previousCity) match {
case Some(City(_, prevLat, prevLon)) =>
Haversine.distance(prevLat, prevLon, leg.city.lat, leg.city.lon)
case None =>
0.0
}
JourneyLegDistance(leg.journeyID, leg.index, distance)
}
Aggregation
Jetzt müssen wir nur noch die Gesamtentfernung der einzelnen Fahrten durch einfache Aggregation ermitteln. Wir sortieren nach der Gesamtentfernung und wählen die erste Zeile, d.h. die kürzeste Strecke:
val journeyDistances: Dataset[(String, Double)] = journeyLegDistancesWithoutUDF
.groupByKey(_.journeyID)
.agg(typed.sum[JourneyLegDistance](_.distance).name("totalDistance"))
.orderBy($"totalDistance")
val (shortestJourney, shortestDistance) = journeyDistances.take(1).head
Ergebnis
Wenn Sie den TSP-Auftrag entweder über sbt run oder auf dem Spark-Cluster mit ./run-travelling-salesman.sh ausführen, sollten Sie das folgende Ergebnis erhalten:
The shortest journey is
New York
->Chicago
->San Jose
->Los Angeles
->San Diego
->Phoenix
->San Antonio
->Houston
->Dallas
->Philadelphia
->New York
with a total distance of 9477.70 km
Und hier ist es auf einer Karte:
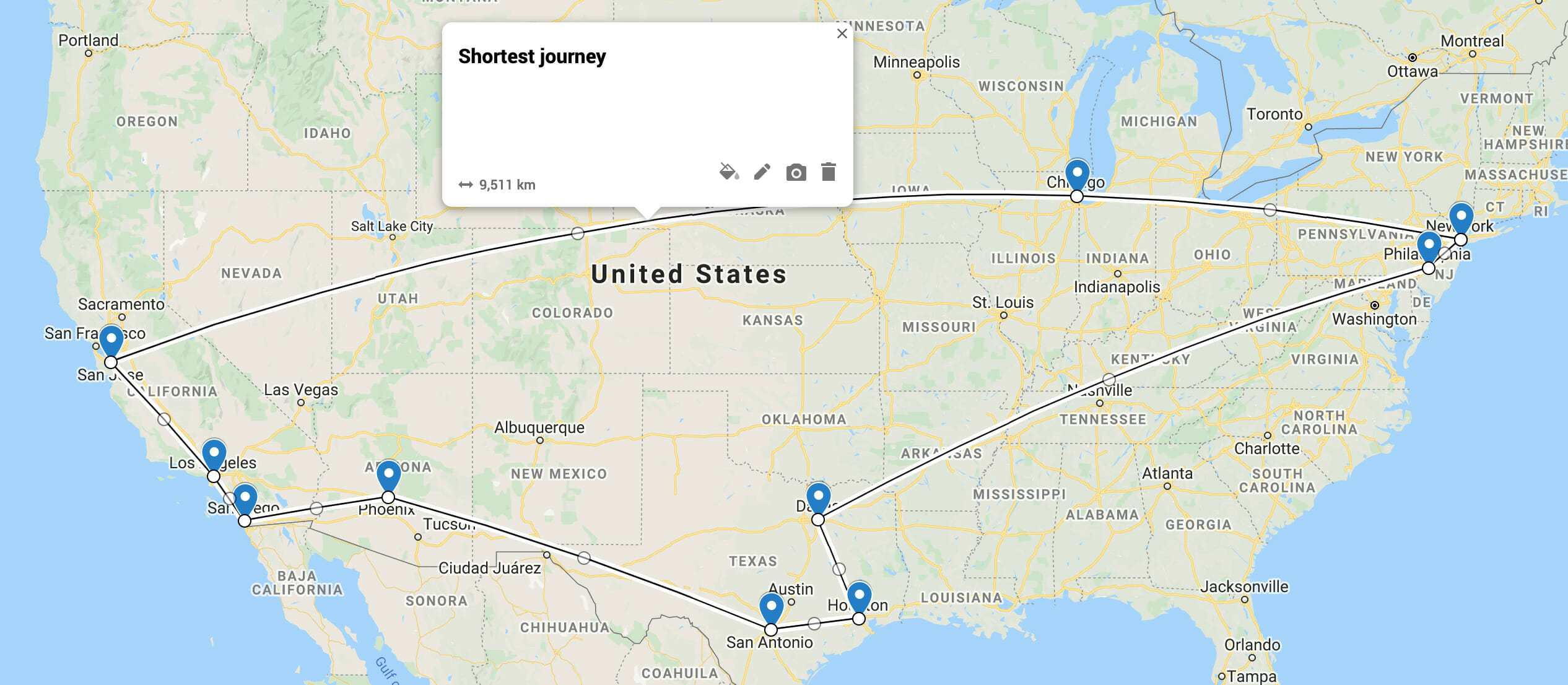
Google Maps stimmt sogar mit unserer Entfernungsberechnung bis auf etwa 50 km überein, was eine gute Kontrolle ist.
Fazit
Wir haben die Leistungsfähigkeit von Spark und Scala 3 genutzt, um einen epischen (und optimalen) Roadtrip durch Amerika zu planen und dabei einige Spark-Funktionen zu validieren.
Spark funktioniert meist problemlos mit Scala 3. Denken Sie nur daran, dass Sie immer dann, wenn Sie eine Methode in der Spark-API sehen, die eine TypeTag erfordert, darauf vorbereitet sein müssen, eine Umgehung zu finden.
Eine letzte Erinnerung: Der gesamte Code und die Skripte für diesen Beitrag sind auf GitHub verfügbar.
Verfasst von
Chris Birchall
Chris is a Principal Software Developer at Xebia Functional. His technical interests include distributed systems, functional domain modelling, metaprogramming and property-based testing.




Contact