Blog
Verwenden Sie Terraform zur Erstellung von ADF-Pipelines


Die meisten Online-Ressourcen empfehlen die Verwendung von Azure Data Factory (ADF) im Git-Modus anstelle des Live-Modus zu verwenden, da dieser einige Vorteile hat. Zum Beispiel die Möglichkeit, gemeinsam im Team an den Ressourcen zu arbeiten, oder die Möglichkeit, Änderungen rückgängig zu machen, die zu Fehlern geführt haben. Die Art und Weise, wie der Git-Modus implementiert ist, nutzt jedoch nicht die Vorteile des Infrastructure as Code (IaaC) Ansatzes. Einer der Aspekte von IaaC ist die Möglichkeit, den Zustand der bereitgestellten Ressourcen allein durch einen Blick auf den Code zu beurteilen. Wenn die Git-Integration aktiviert ist, ist sie leider nicht die main Zweig, der Ihnen die Ressourcen anzeigt, sondern einen automatisch generierten adf_publish Zweig. Diese Verzweigung ist mit ARM-Vorlagen implementiert, die recht ausführlich und nicht menschenfreundlich sind. Sie können einen Blick darauf werfen dieses Beispiel von Microsoft, die nur eine Aktivität enthält. Stellen Sie sich nun vor, dass Sie Dutzende von Pipelines mit komplexen Aktivitäten, mehreren Datensätzen und verknüpften Diensten haben. Eine Alternative dazu wäre die Verwendung von Terraform zur Bereitstellung von ADF-Pipelines.
Wir wollen zeigen, wie man die Unzulänglichkeiten der des ADF Git-Modus und profitieren trotzdem von den Vorteilen des in der Versionskontrolle gespeicherten Codes. Um dies zu erreichen, werden wir Terraform verwenden, um sowohl ADF (im Live-Modus) als auch seine Ressourcen bereitzustellen. Dies setzt voraus, dass der Terraform-Code im Git-Repository gespeichert ist. Außerdem werden wir zeigen, wie Sie einige der Einschränkungen die der Terraform-Anbieter von Azure hat, wenn es um komplexere Pipelines geht.
Mit unserer Methode kann man sich einfach den Code (oder eine bestimmte markierte Version davon) ansehen und mit Sicherheit sagen, was eingesetzt wird.
Allerdings gibt es eine Einschränkung bei der Verwendung von Terraform. Derzeit, azurerm Terraform Anbieter erlaubt nicht für die Erstellung von "komplexen" Pipelines. Mit "komplex" meinen wir die Pipeline, die andere Variablen als vom Typ string. Aber dafür haben wir eine Abhilfe.
Voraussetzungen für Terraform ADF-Pipelines
Wenn Sie, wie wir, eine CI/CD-Pipeline zur Bereitstellung der Ressourcen verwenden, nutzen Sie wahrscheinlich einen Service Principal auf Ihrem Build Agent. Um eine Lösung zu verwenden, die sowohl lokal beim Debuggen/Testen als auch auf dem Build-Agent funktioniert, benötigen Sie die Service Principal-Anmeldeinformationen.
Außerdem funktioniert dies nur mit der Bash, stellen Sie also sicher, dass Sie diese installiert haben.
Der fileset Ansatz
Wie bereits erwähnt, haben wir nicht bei Null angefangen, sondern verfügten bereits über bestehende Pipelines im JSON-Format und einen Prozess zu deren Erstellung. Mit diesem Gedanken im Hinterkopf haben wir beschlossen, dass diese Ressourcen so bleiben, wie sie sind. Diese Trennung ermöglicht es den Platform- und Data-Engineering-Teilen des Teams, so effizient wie möglich zu arbeiten und die Sprachen zu verwenden, mit denen sie am meisten vertraut sind. Die Plattformingenieure können Terraform verwenden, um Ressourcen bereitzustellen und das Beste daraus zu machen, während die Dateningenieure die Pipelines im gleichen Format bearbeiten können, wie sie in ADF dargestellt sind. . In der Abbildung unten sehen Sie, wie die Pipelines und Trigger (Ressourcen, die im json-Format bleiben) in unserem Fall gespeichert wurden.
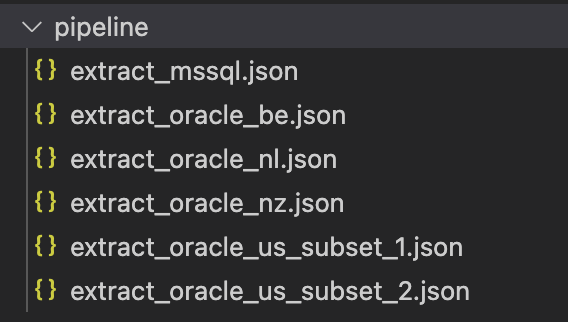
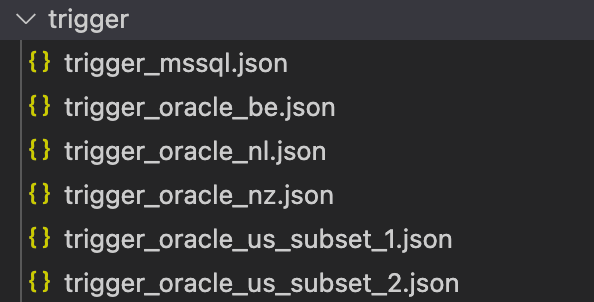
Da es uns gelungen ist, andere Ressourcen, wie verknüpfte Dienste und Datensätze, direkt in den Terraform-Code zu migrieren, konnten wir diese Dateien loswerden:
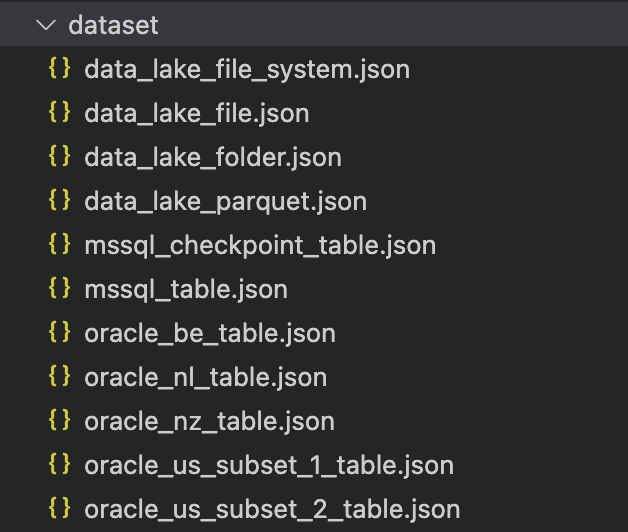
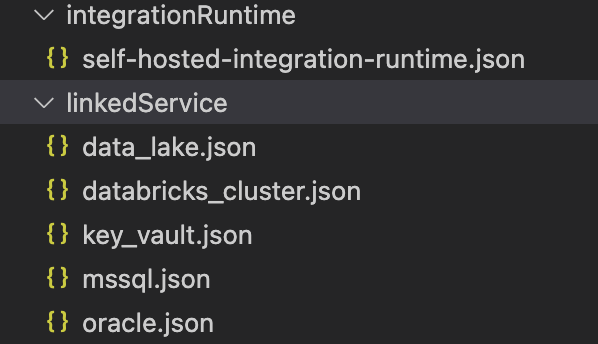
Unser Ansatz sorgt dafür, dass jedes Mal, wenn ein Dateningenieur neue Pipelines erstellt (oder bestehende modifiziert), der Terraform-Code diese automatisch aufnimmt und bereitstellt.
Um eine Reihe vorhandener Dateien zu lesen und zu verarbeiten, verwenden wir Terraforms Dateisatz Funktion. Lassen Sie uns das in Aktion sehen. Erstens, fügen wir eine lokale Variable mit fileset:
locals {
pipelines = { for value in fileset("./pipelines", "*.json") : value => jsondecode(file("./pipelines/${value}")) }
data_factory_id = "DATA_FACTORY_ID"
}Dieser Code iteriert über alle json-Dateien, die in der Datei pipelines Ordner und deserialisiert sie. Wenn Ihre Pipelines eine bestimmte Namenskonvention einhalten müssen oder sich in einem anderen Ordner befinden, können Sie die Maske und/oder den Speicherort ändern.
Idealerweise würden wir Folgendes verwenden azurerm_data_factory_pipeline Ressource, um die Pipelines zu verwalten. Leider konnten wir zum Zeitpunkt der Erstellung dieses Artikels nicht einfach die azurerm_data_factory_pipeline da sein Feld variables erlaubt nur die Abbildung von string. Unsere Pipelines hingegen verwendeten Variablen vom Typ array. Um das Problem der Fehler, haben wir null_resource. Bitte beachten Sie, dass dies nur ein vorübergehender Workaround ist und nur bei Bedarf verwendet werden sollte. Sobald der Fehler behoben ist, wird dieser Blog mit der richtigen Lösung aktualisiert.
Die null_resource Abhilfe
locals {
...
tmp_files_location = ".terraform/tmp"
data_factory_name = "DATA_FACTORY_NAME"
rg_name = "RESOURCE_GROUP_NAME"
tenant_id = "YOUR_TENANT_ID"
}resource "null_resource" "pipelines" {
for_each = local.pipelines
triggers = {
on_change = "${md5(jsonencode(each.value))}"
tenant_id = local.tenant_id
data_factory_name = local.data_factory_name
pipeline_name = each.value.name
data_factory_resource_group_name = local.rg_name
}
provisioner "local-exec" {
when = create
command = <<-EOC
az login --service-principal -u $ARM_CLIENT_ID -p $ARM_CLIENT_SECRET --tenant "${local.tenant_id}"
az account set --subscription $ARM_SUBSCRIPTION_ID
az datafactory pipeline create --factory-name "${local.data_factory_name}" --name "${each.value.name}" --resource-group "${local.rg_name}" --pipeline @${path.root}/pipeline/${each.value.name}.json
EOC
interpreter = [
"bash",
"-c"
]
}
provisioner "local-exec" {
when = destroy
command = <<-EOC
az login --service-principal -u $ARM_CLIENT_ID -p $ARM_CLIENT_SECRET --tenant "${self.triggers.tenant_id}"
az account set --subscription $ARM_SUBSCRIPTION_ID
az datafactory pipeline delete --factory-name "${self.triggers.data_factory_name}" --name "${self.triggers.pipeline_name}" --resource-group "${self.triggers.data_factory_resource_group_name}" -y
EOC
interpreter = [
"bash",
"-c"
]
}
}Wir haben beschlossen, nicht zu verwenden azurerm_data_factory_pipeline überhaupt nicht, auch nicht für die anfängliche Erstellung von Ressourcen. Die Kombination dieser beiden Ansätze würde noch mehr Probleme mit sich bringen. Das wichtigste ist - die Verwendung von timestamp() Auslöser an null_resource und erstellen Sie Pipelines bei jeder Anwendung neu.
Nur verwenden null_resource ermöglichte uns die Verwendung von md5 als Auslöser um die Pipelines neu zu erstellen, sobald sich ihr Dateiinhalt ändert. Dieser Ansatz bedeutet, dass wir auch eine 'on destroy'-Bedingung benötigen, um Pipelines zu löschen, wenn wir die terraform destroy. Infolgedessen mussten wir die Variablen in der trigger blockieren, da die Bereitsteller der Zerstörungszeit nicht auf externe Variablen zugreifen können.
Auch hier handelt es sich um eine Behelfslösung, die entfernt werden wird, sobald azurerm_data_factory_pipeline komplexe Variablen unterstützen wird.
Fazit
Diese Schnipsel sollten Ihnen einen guten Ausgangspunkt bieten, wenn Sie die Vorteile von Git und Infrastruktur Als Code. Natürlich ist dies nicht allgemeingültig und Ihr Anwendungsfall könnte einige Anpassungen erfordern, aber experimentieren Sie ruhig. Dennoch hat dieser Ansatz, wie bei allenhat auch dieser Ansatz seine Vor- und Nachteile:
Profis
- Es ist möglich, jede Version/Tag Ihrer Pipelines einzusetzen und zurückzusetzen.
- Dasselbe wie bei der Integration des Git-Modus:
- Alle wichtigen Arbeitsabläufe sind in der Versionsverwaltung gespeichert
- Es ermöglicht inkrementelle Änderungen von Datenfabrik-Ressourcen, unabhängig davon, in welchem Zustand sie sich befinden
Nachteile
- Es ist nicht möglich, mehrere Zweige auf derselben ADF-Instanz zu verwenden
- Ingenieure müssen auf ihrem lokalen Rechner dieselben Umgebungsvariablen exportiert haben wie der Build-Agent, wenn sie ihn lokal testen wollen
Wie bereits erwähnt, ist der Workaround nur eine vorübergehende Lösung, bis Azure eine Lösung für den Fehler. Wenn sie es tun, null_resource Teil sollte nicht mehr notwendig sein.
Verfasst von
Valerii Matveev
Unsere Ideen
Weitere Blogs




Contact