Diese KI-Suchassistenz befindet sich derzeit in einem Pilotprogramm und wird noch weiterentwickelt. Die Antworten, die auf Deutsch generiert werden, können einige Sekunden dauern. Wir streben nach Genauigkeit, aber gelegentlich können Fehler auftreten.
Bitte überprüfen Sie wichtige Informationen, bevor Sie Entscheidungen treffen oder kontaktieren Sie uns direkt.
Antwort
Verwandte Themen
Kontextdateien
Verwandte Themen
Blog
Die lineare Algebra hinter der linearen Regression
Aktualisiert April 20, 2026
6 Minuten
Teilen
Lineare Algebra ist ein Zweig der Mathematik, der sich mit Matrizen und Vektoren beschäftigt. Von der linearen Regression bis hin zu den neuesten und besten Methoden des Deep Learning: Sie alle basieren auf der linearen Algebra "unter der Haube". In diesem Blogbeitrag erkläre ich, wie die lineare Regression durch lineare Algebra geometrisch interpretiert werden kann.
Dieser Blog basiert auf dem Vortrag A Primer (or Refresher) on Linear Algebra for Data Science, den ich auf der PyData London 2019 gehalten habe.
Fibel für lineare Regression
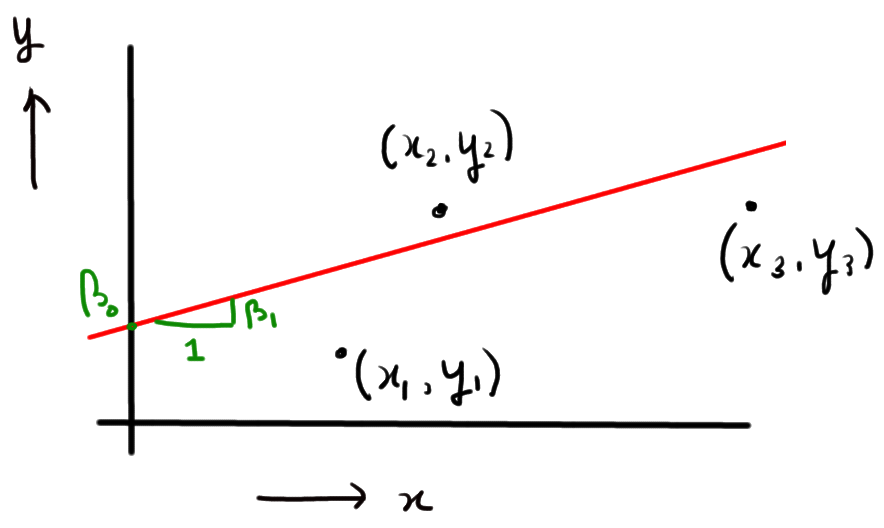
Bei der gewöhnlichen kleinsten Quadrate (d.h. der einfachen linearen Regression) besteht das Ziel darin, ein lineares Modell an die beobachteten Daten anzupassen. Das heißt, wenn wir die Ergebnisse y_i und die erklärenden Variablen x_i beobachten, passen wir die Funktion
y_i = beta_0 + beta_1 x_i + e_i,
die unten abgebildet ist
Dies läuft darauf hinaus, Schätzer zu finden hat{beta}_0 und hat{beta}_1, die den mittleren quadratischen Fehler des Modells minimieren:
wobei n die Anzahl der Beobachtungen ist.
Eine Möglichkeit, dieses Minimierungsproblem zu lösen, besteht darin, die Verlustfunktion numerisch zu minimieren (z.B. mit scipy.optimize.minimize). In diesem Blogbeitrag wählen wir einen alternativen Ansatz und stützen uns auf die lineare Algebra, um die besten Parameterschätzungen zu finden. Dieser Ansatz der linearen Algebra zur linearen Regression wird auch unter der Haube verwendet, wenn Sie sklearn.linear_model.LinearRegression.1
Lineare Regression in Matrixform
Nehmen wir der Einfachheit halber an, dass wir drei Beobachtungen haben (d.h., n=3), schreiben wir das lineare Regressionsmodell in Matrixform wie folgt:
was im Grunde nur eine kompakte Art ist, das Regressionsmodell zu schreiben.
Geometrische Darstellung der Regression der kleinsten Quadrate
Das Ziel ist es, einen Schätzer zu erhalten hat{beta} derart, dass y approx Xhat{beta} (Beachten Sie, dass es in der Regel keine hat{beta} derart, dass y = Xhat{beta}; dies geschieht nur in Situationen, die in der Praxis eher unwahrscheinlich sind).
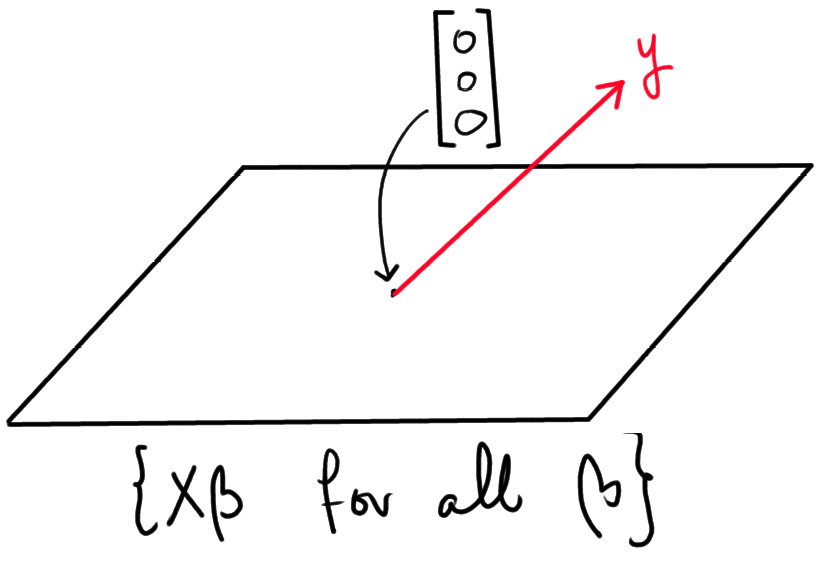
Um das Problem der Schätzung von hat{beta} geometrisch darzustellen, beachten Sie, dass die Menge
{ Xhat{beta} text{ for all possible } hat{beta} }
stellt alle möglichen Schätzer für hat{y} dar. Nun stellen Sie sich diese Menge als eine Ebene im 3D-Raum vor (stellen Sie sich ein Stück Papier vor, das Sie vor sich halten). Beachten Sie, dass y nicht in dieser Ebene "lebt", denn das würde bedeuten, dass es ein hat{beta} gibt, so dass Xhat{beta} = y. Alles in allem können wir die Situation wie folgt darstellen:
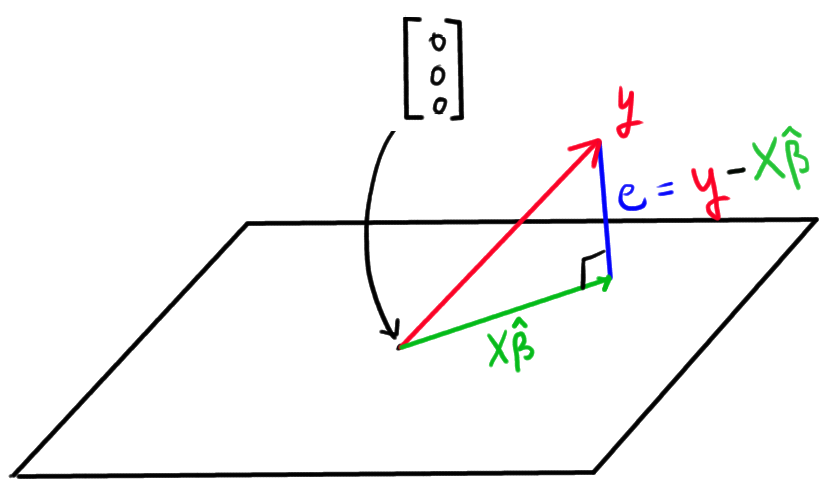
Die Suche nach dem besten Schätzer hat{beta}, läuft nun darauf hinaus, den Punkt in der Ebene zu finden, der y am nächsten liegt. Mathematisch gesehen entspricht dieser Punkt dem hat{beta}, so dass der Abstand zwischen Xhat{beta} und y minimiert wird. In der folgenden Abbildung wird dieser Punkt durch den grünen Bogen dargestellt:
Dies ist nämlich der Punkt in der Ebene, bei dem der Fehler (e) senkrecht zur Ebene liegt. Interessanterweise bedeutet die Minimierung des Abstands zwischen Xhat{beta} und y die Minimierung der Norm von e (Vektornormen werden in der linearen Algebra verwendet, um dem Begriff des Abstands in höheren Dimensionen als zwei eine Bedeutung zu geben):
text{"norm of $e$"} = | e | = | y - Xhat{beta} | = sum_{i=1}^n left(y_i - left( hat{beta}_0 + hat{beta}_1 x_i right)right)^2,
Wir minimieren also den mittleren quadratischen Fehler des Regressionsmodells!
Schätzung der ß's
Bleibt nur noch die Suche nach einem hat{beta} so dass der Vektor e=y-Xhat{beta} senkrecht zur Ebene ist. Oder in der Terminologie der linearen Algebra: Wir suchen nach hat{beta}, so dass eorthogonal zur Spannweite von X ist(Orthogonalität verallgemeinert den Begriff der Senkrechtigkeit auf höhere Dimensionen).
Im Allgemeinen gilt, dass zwei Vektoren u und v orthogonal sind, wenn u^top v = u_1v_1 + ... + u_n v_n = 0 (zum Beispiel: u=(1,2) und v=(2, -1) sind orthogonal). In diesem speziellen Fall ist e orthogonal zu X, wenn e orthogonal zu jeder der Spalten von X ist. Dies führt zu der folgenden Bedingung:
(y-Xhat{beta})^top X =0.
Wenn wir einige Tricks der linearen Algebra anwenden (Matrixmultiplikationen und -invertierungen), finden wir heraus, dass:
X^top left(y - Xhat{beta}right) = 0 Leftrightarrow\
X^top y - X^top Xhat{beta} = 0 Leftrightarrow \
X^top y = X^top Xhat{beta} Leftrightarrow \
left( X^top Xright)^{-1} X^top y = hat{beta}
Daher ist hat{beta} = left( X^top Xright)^{-1} X^top y der Schätzer, den wir suchen.
Numerisches Beispiel
Nehmen wir an, wir beobachten:
x = [1, 1.5, 6, 2, 3]
y = [4, 7, 12, 8, 7]
Um die Ergebnisse aus diesem Blogbeitrag anzuwenden, konstruieren wir zunächst die Matrix X:
die die Passgenauigkeit unseres Modells zeigt:
Obwohl dieser Blogbeitrag anhand eines einfachen Beispiels mit nur einem Merkmal geschrieben wurde, lassen sich alle Ergebnisse problemlos auf höhere Dimensionen (d.h. mehr Beobachtungen und mehr Merkmale) übertragen.
Wenn Ihnen dieser Beitrag gefallen hat, dann ist der fast.ai-Kurs über computergestützte lineare Algebra vielleicht etwas für Sie (er ist kostenlos).
Verbessern Sie Ihre Python-Kenntnisse, lernen Sie von den Experten!
Bei GoDataDriven bieten wir eine Vielzahl von Python-Kursen an, die von den besten Fachleuten auf diesem Gebiet unterrichtet werden. Machen Sie mit und verbessern Sie Ihr Python-Spiel:- Data Science with Python Foundation - Möchten Sie den Schritt von der Datenanalyse und -visualisierung zu echter Datenwissenschaft machen? Dies ist der richtige Kurs.
- Advanced Data Science with Python - Lernen Sie, Ihre Modelle wie ein Profi zu produzieren und Python für maschinelles Lernen zu verwenden.
Die Implementierung von sklearn.linear_model.LinearRegression ist ein wenig komplizierter als der hier beschriebene Ansatz. Insbesondere wird die Faktorisierung von Matrizen verwendet (z.B. die QR-Faktorisierung), um zu verhindern, dass Matrizen numerisch invertiert werden müssen (was numerisch instabil ist, siehe z.B. die Hilbert-Matrix). Für den Rest gilt genau derselbe Ansatz.
Hier möchten Sie die Matrixfaktorisierung verwenden, um zu vermeiden, dass Sie (X^top X)^{-1} direkt berechnen müssen; siehe auch Fußnote 1 .