Letzten Dienstag und Mittwoch haben Ivo Everts und ich an der Spark+AI Summit 2018 Konferenz in San Francisco teilgenommen. Ivo hielt einen Vortrag über Predictive Maintenance bei den niederländischen Eisenbahnen und ich präsentierte den KI-Fall GDD, der bei Royal FloraHolland Operation Tulip umgesetzt wurde : Einsatz von Deep Learning-Modellen zur Automatisierung von Auktionsprozessen.

Als Datenwissenschaftler habe ich es sehr geschätzt, dass es einen Data Science Track, einen Deep Learning Track und einen AI Track gab. Ursprünglich hatte ich erwartet, dass es hauptsächlich um Technik geht, aber wie Sie weiter unten sehen werden, gab es jede Menge gute Datenwissenschaft.
Hier sind die Highlights der Vorträge, die ich an jedem Tag besucht habe. 1
Hinweis: Für die nicht-technischen Leser liste ich einige nicht-technische Vorträge auf.
Tag 1
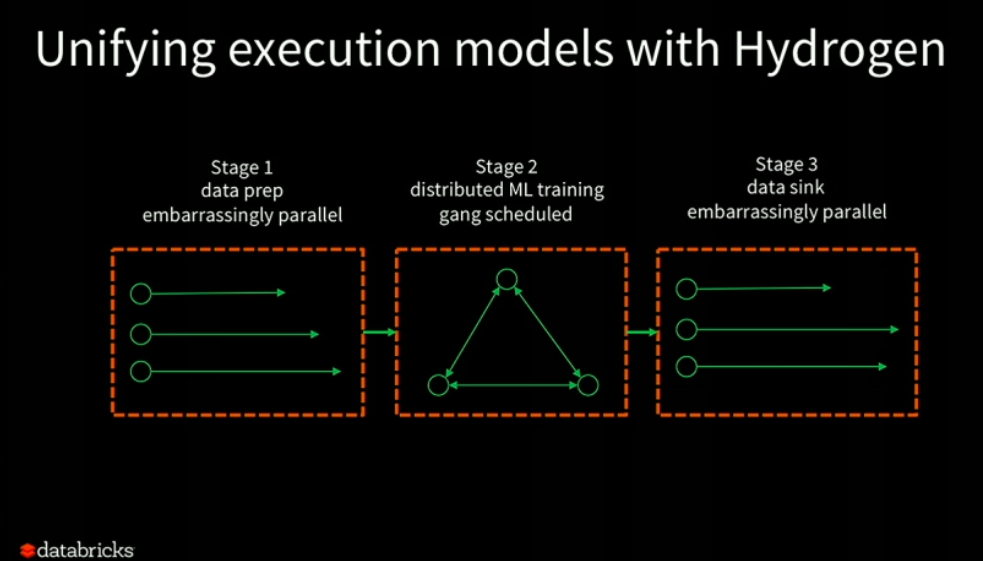
Projekt Hydrogen: KI und Big Data auf dem neuesten Stand der Technik in Apache Spark vereinen
Reynold Xin (Mitbegründer und Chefarchitekt @ Databricks)
Databricks hat das Projekt Hydrogen vorgestellt, mit dem das Problem gelöst werden soll, dass verteilte ETL-Spark-Jobs nicht gut mit Deep Learning-Frameworks zusammenspielen. Wie der Chefarchitekt von Databricks, Reynold Xin, sagt, gibt es eine grundlegende Inkompatibilität zwischen dem Spark-Scheduler und der Funktionsweise verteilter Machine Learning-Frameworks.
Infrastruktur für den gesamten ML-Lebenszyklus
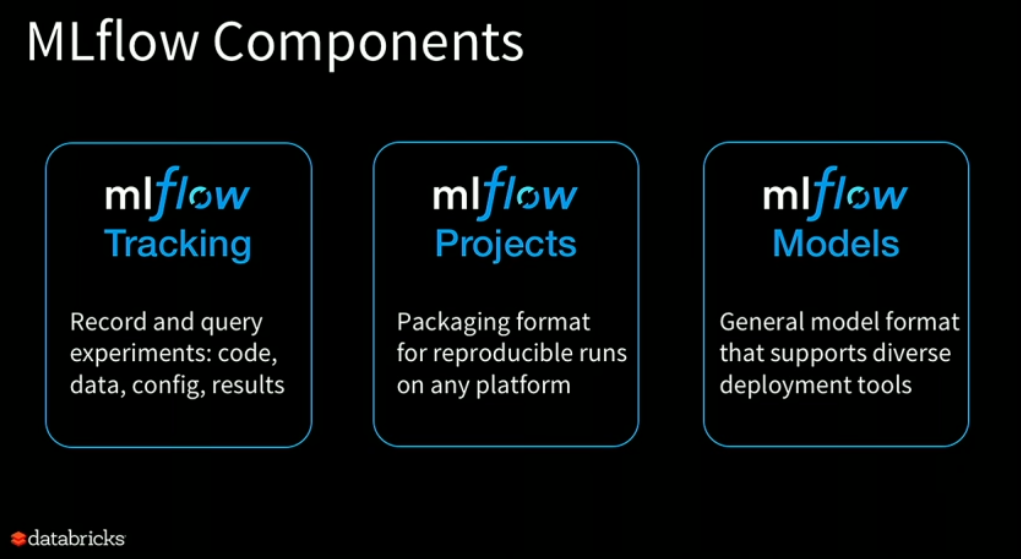
Matei Zaharia (Mitbegründer und CTO @ Databricks & Erfinder von Spark)
Dies war eine ziemlich aufregende Keynote. CTO Matei Zaharia stellte das neue Open-Source-Projekt mlflow vor und demonstrierte es. mlflow soll Datenwissenschaftlern helfen, Experimente zu verfolgen, Modelle einzusetzen und vor allem unterstützt es eine Vielzahl von Tools für maschinelles Lernen. Mehr dazu lesen Sie in dem Blogbeitrag von Matei diese Woche.
Die Zukunft von KI und Sicherheit
Dawn Song (Professorin @ UC Berkeley)
Professor Dawn Song sprach über drei Schwachstellen der KI:
- Angriffe auf KI-Modelle
- Missbrauch von KI
- Datenlecks
Sie gab schöne Beispiele für die drei und demonstrierte gegnerische Angriffe im wirklichen Leben, wie das Bild und das Video zeigen.

Dann sprach sie darüber, wie einige der offenen Fragen gelöst werden können und wie wir unter Berücksichtigung dieser 3 Aspekte vorankommen können.
Zeitreihenprognose mit Hilfe eines rekurrenten neuronalen Netzwerks und eines autoregressiven Vektormodells: Wann und wie
Jeffrey Yau (Chef-Datenwissenschaftler @ AllianceBernstein)
Jeffreys Vortrag war für viele Data Scientists, die sich mit Zeitreihen beschäftigen, von großem Wert. Er begann damit, den Unterschied zwischen univariater und multivariater Analyse bei der Dynamik von Zeitreihen zu erläutern, gefolgt von einer kurzen Erklärung, warum es besser ist, vektorautoregressive Modelle anstelle von ARIMA-Modellen zu verwenden. Anhand von zwei Beispielen zeigte er, wie man es tatsächlich macht.
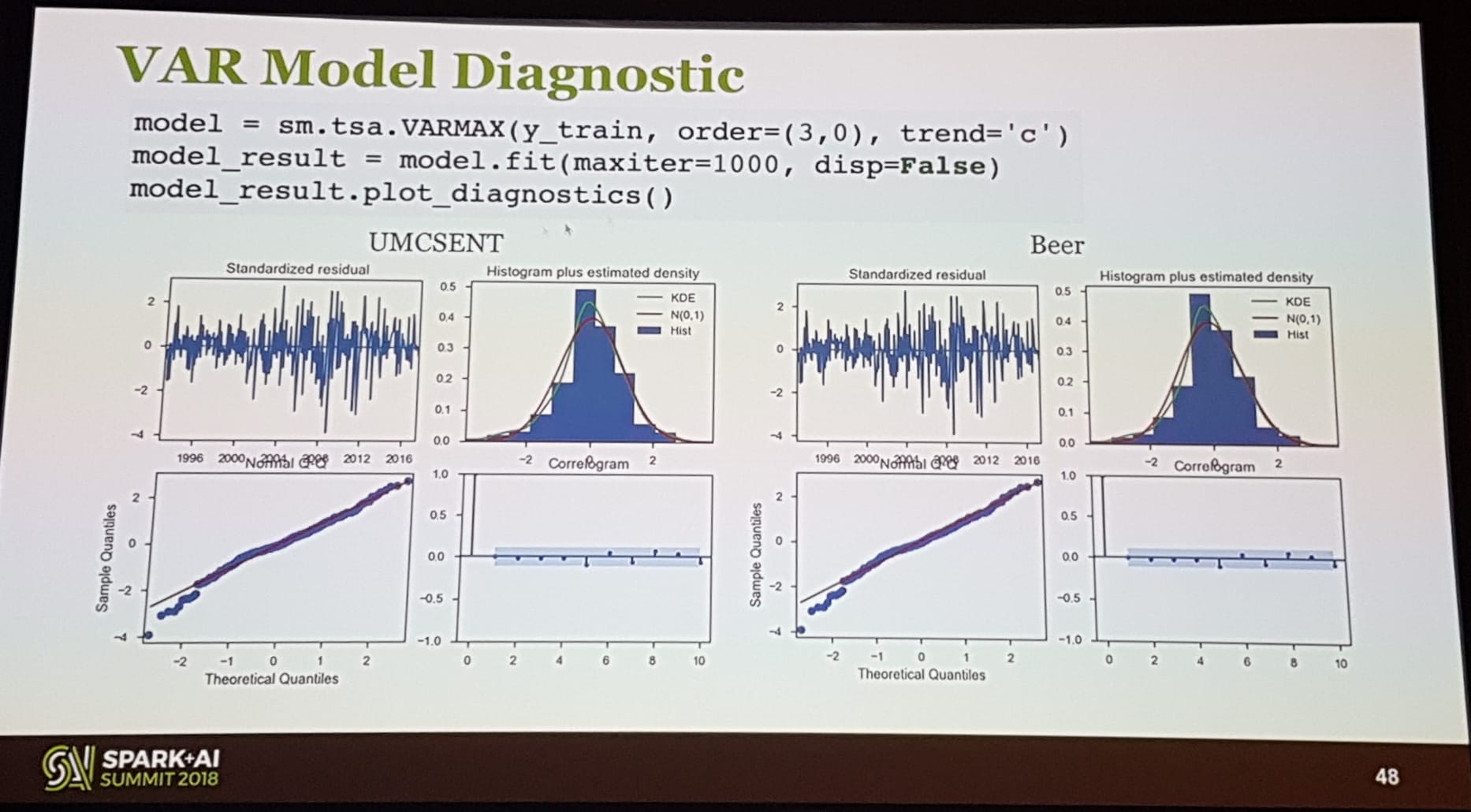
Dann zeigte er, wie Flint (eine Zeitreihenbibliothek für Spark) verwendet werden kann, um die natürliche Ordnung von Zeitreihendaten bei der Verwendung von Spark zu erhalten. Anschließend zeigte er, wie Sie Spark und das Zeitreihenmodul von StatsModel kombinieren können, um Hyperparameter zu tunneln.


Abschließend führte er LSTMS unter Verwendung von Keras ein und verglich ein Many-to-Many-Modell mit VARs-Modellen mit einer Vorhersage von 16 Schritten im Voraus.
Graph Representation Learning to Prevent Payment Collusion Fraud aud Prevention in Paypal
Venkatesh Ramanathan (Datenwissenschaftler @ PayPal)
Dieser Vortrag war eigentlich ziemlich cool. Der Anwendungsfall war das Aufspüren einer Art von Betrugstransaktion, an der mehrere Personen beteiligt sind, sowohl auf der Verkäufer- als auch auf der Käuferseite. Der Vortrag begann damit, dass er erklärte, wie man die Transaktionen auf eine graphbasierte Darstellung von Verkäufern und Käufern abbildet. Dann schlug er mehrere Lösungen vor, um den Betrug zu erkennen. Er erklärte zum Beispiel, wie man mit node2vec eine Vektordarstellung für die Knoten im Graphen findet und diese Darstellungen dann in verschiedenen ML-Modellen verwendet. Er ging auch auf fortgeschrittenere Algorithmen ein, bei denen eine zeitliche Komponente in den Graphen eingeführt wurde und ging auch auf Graphenfaltung ein.
Tag 2
ML trifft auf Wirtschaft: Neue Perspektiven und Herausforderungen
Michael I. Jordan (Professor @ UC Berkeley)
Ich mag diese Art von Vorträgen sehr, in denen KI und insbesondere Deep Learning in eine viel umfassendere und wirkungsvollere Perspektive gerückt werden. Professor Jordan gab sehr interessante Hinweise darauf, wie neue wirtschaftliche Märkte durch KI entstehen können, wenn wir unseren Ansatz für ihre Monetarisierung ändern. Er gab unter anderem ein anschauliches Beispiel aus der Musikindustrie und stellte eine Liste von Themen vor, die KI-Praktiker seiner Meinung nach bei der Entwicklung von KI-Systemen beachten sollten. Er übte auch heftige Kritik an der derzeitigen Art der KI-Entwicklung.

Ich war mit einigen seiner Standpunkte nicht wirklich einverstanden, aber es ist immer äußerst nützlich, beide Seiten zu hören und das Boot ein wenig zu schaukeln.
Kamingespräch mit Marc Andreessen und Ali Ghodsi
Marc Andreessen (Mitbegründer und Partner @ Andreessen Horowitz), Ali Ghodsi (CEO @ Databricks)
Dies war ein Gespräch, bei dem Ali eine Art Interview mit Marc (einem einflussreichen Risikokapitalgeber) führte. Es ist das perfekte Gespräch, um es morgens beim Aufstehen oder auf dem Weg zur Arbeit zu hören. Sie sprachen ein wenig über die Geschichte der Technologieunternehmen und wie sich die Pitches der Unternehmen mit dem Aufkommen der KI entwickelt haben. Außerdem gab Marc einige hilfreiche Hinweise für Startups, worauf ein Risikokapitalgeber achten sollte. Eine Diskussion, die besonders im Gedächtnis haften blieb, war die Frage, ob KI eine wirklich revolutionäre Technologie oder nur ein zusätzliches Feature ist?
Aufbau des Software 2.0 Stacks
Andrej Karpathy (Direktor für KI @ Tesla)
Dieser Vortrag hat mir sehr gut gefallen. Andrej hat in einem Konzept zusammengefasst, was wir alle erlebt haben, nachdem wir mehrere Modelle für maschinelles Lernen produziert haben. Er sprach über Software 2.0. Dieses Konzept besagt im Grunde, dass die Programmierung in der KI jetzt von Beschriftern übernommen wird. Was wir als Datenwissenschaftler tun, ist, einen großen Teil des Lösungsraums und der Daten auszuwählen und dann anhand der Daten das beste Programm für unseren Fall in diesem Raum zu finden.
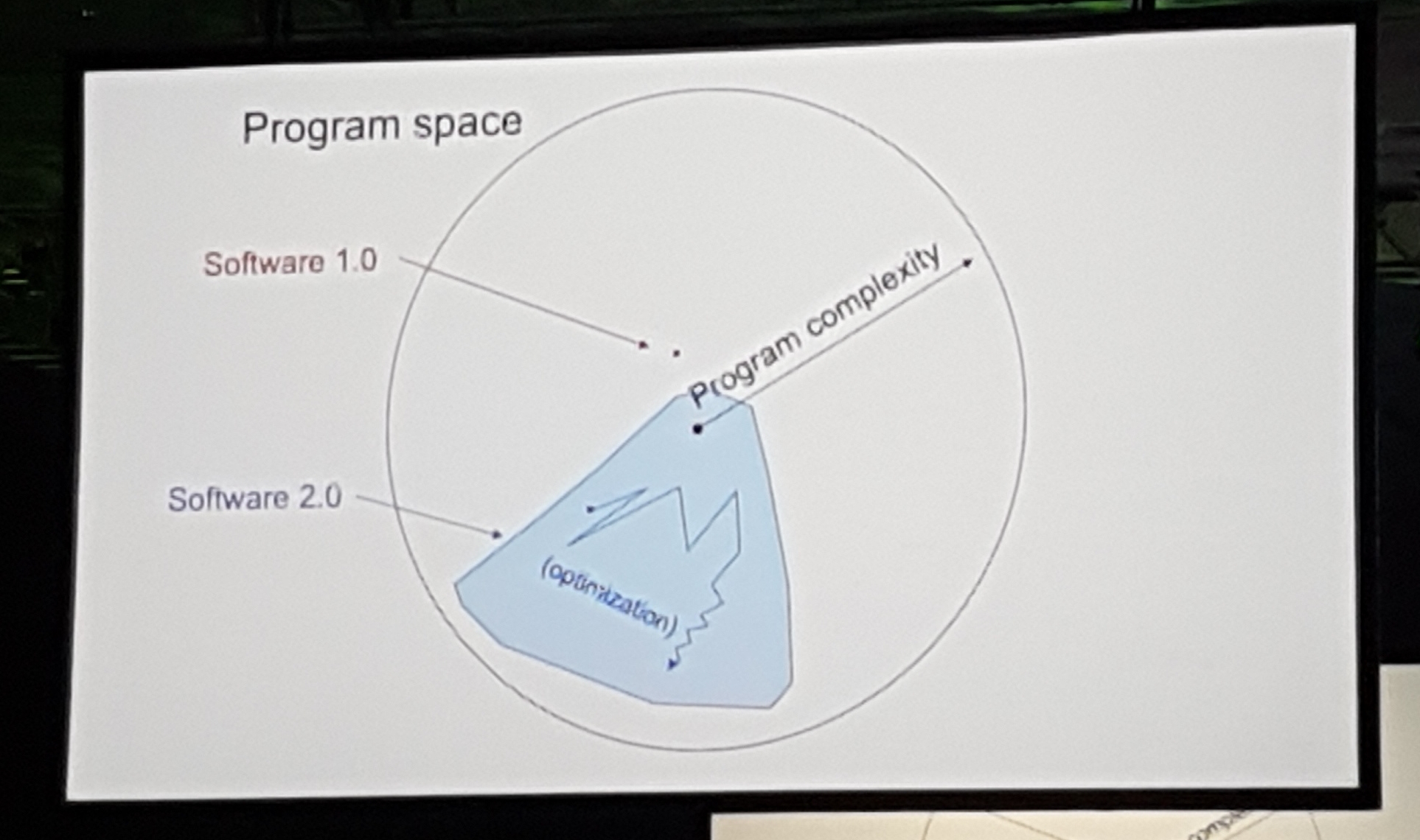
In Anbetracht dieser Überzeugung erwähnte er, wie er in Tesla die meiste Zeit damit verbracht hat, sicherzustellen, dass die Beschriftungen der Datensätze von sehr hoher Qualität sind. Er nannte einige lustige Beispiele für extrem seltene Daten, auf die er gestoßen ist, und betonte erneut, wie wichtig es ist, ein robustes und hochwertiges Kennzeichnungssystem zu haben.

Mir hat es sehr gefallen, wie authentisch seine Kommentare waren und zu sehen, dass selbst Tesla diese Art von "tödlichen" Problemen hat, mit denen auch ich zu kämpfen habe.
Deep Learning für Empfehlungssysteme
Nick Pentreath (Leitender Ingenieur @ IBM)
Zusammen mit dem Vortrag über Zeitserien der nützlichste für einen Datenwissenschaftler. Der Vortrag von Nick war sehr gut strukturiert und erklärt. Er begann mit den grundlegenden Methoden wie Item-Item und Matrixfaktorisierung, die auf Merkmalen und expliziten Interaktionen oder Ereignissen beruhen. Dann stellte er die Landschaft der derzeit am häufigsten vorkommenden Fälle dar, die explizite, implizite, soziale und beabsichtigte Ereignisse umfassen. Anschließend ging er auf das Problem des Kaltstarts ein und erklärte, warum die Standard- bzw. alten Modelle der kollaborativen Filterung mit den aktuellen Anforderungen der Anwendungen nicht mehr zurechtkommen.


Dann wurden Deep Learning-Ansätze behandelt und erklärt, wie implizite Ereignisse in der Verlustfunktion eines neuronalen Netzwerks verwendet werden können. Anschließend zeigte er die modernsten Deep Learning-Implementierungen wie DeepFM.3

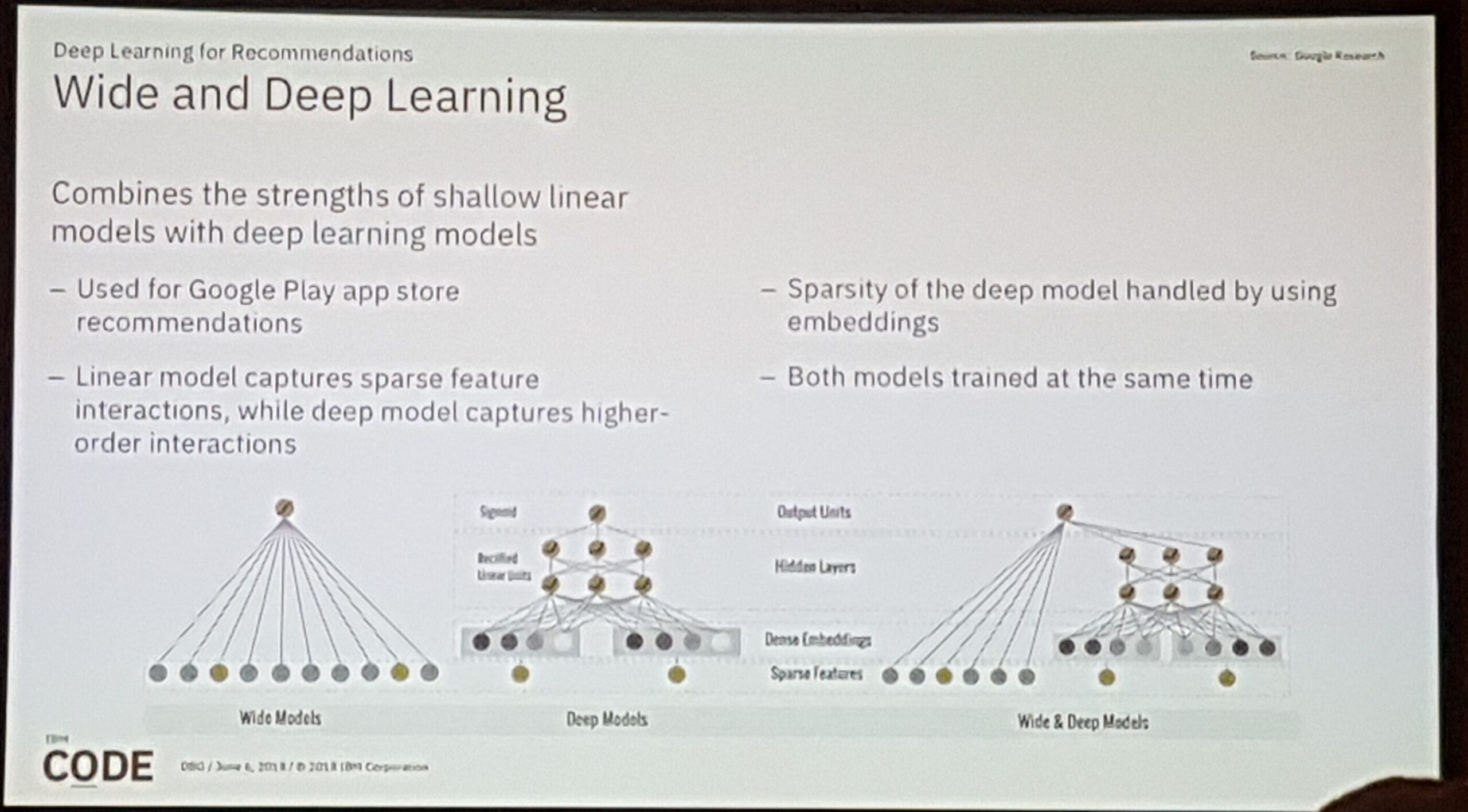
Der nächste Teil war sogar irgendwie neu für mich. Er fügte sitzungsbasierte Empfehlungen und die zuvor besprochenen Inhalte hinzu, indem er rekurrente neuronale Netze zusätzlich zu den bereits vorhandenen Netzwerken verwendete.
Ich war froh, dass ich bei den meisten modernen Deep Learning-Anwendungen für Empfehlungssysteme auf dem neuesten Stand war, aber ich lernte auch etwas Neues, nachdem ich mich mit Nick und einem Datenwissenschaftler von Nike unterhalten hatte, der sich mit denselben Problemen beschäftigte.
Nandeska? Say What? Lernen, Visualisieren und Verstehen mehrsprachiger Worteinbettungen
Ali Zaidi (Datenwissenschaftler @ Microsoft)
In diesem Vortrag ging es darum, wie man ähnliche Einbettungsräume für Wörter mit derselben Bedeutung unabhängig von der Sprache finden kann - ziemlich cooles Zeug. Ali stellte zu Beginn fest, dass große Datensätze für bereichsspezifisches NLP ziemlich rar sind, also stellte er einige davon vor.
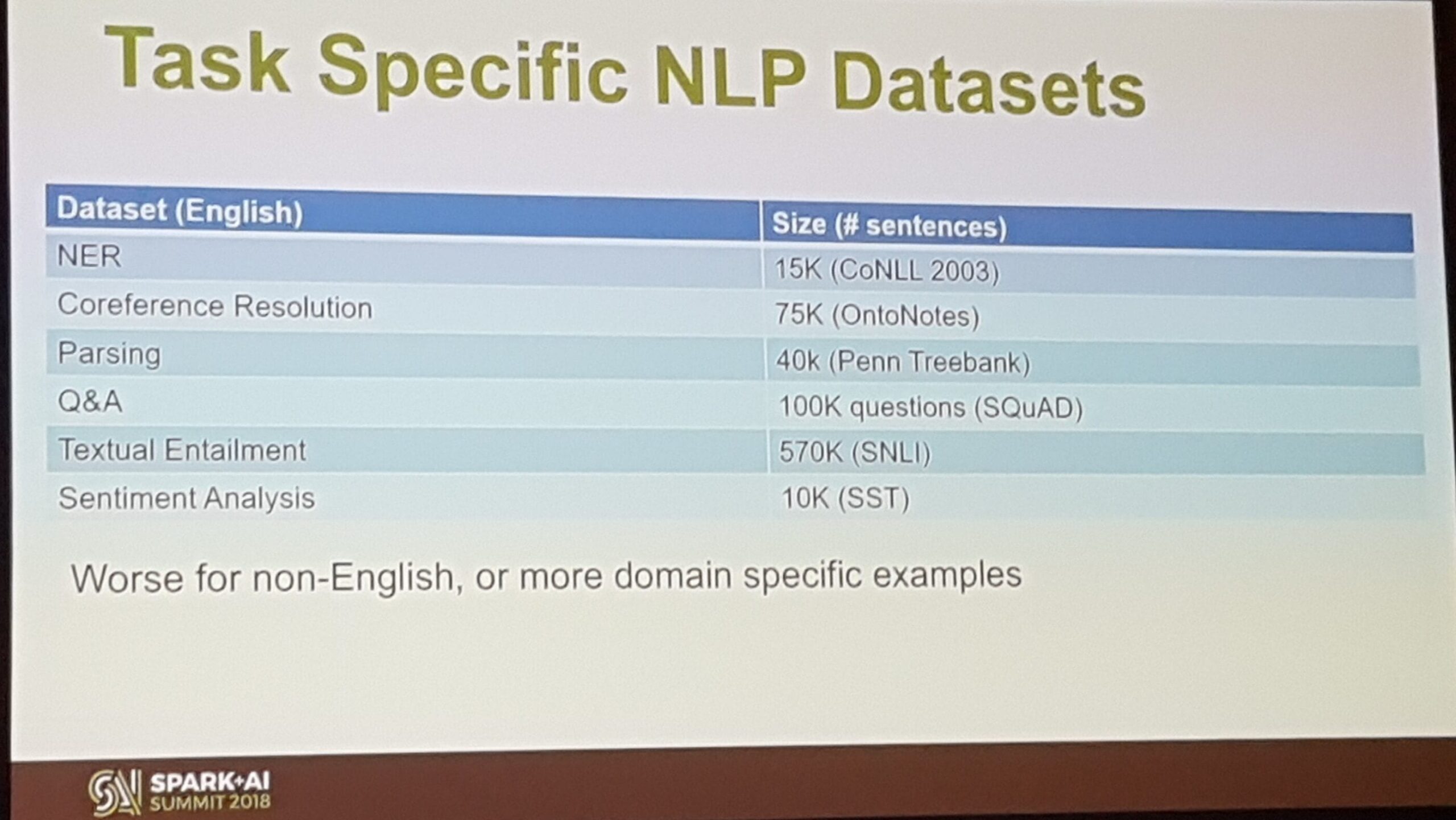
Ali zeigte dann, wie man Word2Vec-Einbettungen in großem Maßstab mit Spark über das Azure-Textanalysepaket (tatk) lernen kann. Anschließend erläuterte er, wie Sie das gewünschte Ziel erreichen können, indem Sie die Einbettungen für jede Sprache einzeln berechnen und sie dann in eine Domänenanpassung mit einem kontradiktorischen Ziel einfließen lassen. Er zeigte dies für Spanisch und Russisch.


Ich weiß nicht, wie gut der Algorithmus für die meisten Wörter im Allgemeinen funktioniert hat, aber der Ansatz und das gezeigte kleine Beispielergebnis waren ganz nett.
Adiós
Abschließend kann ich sagen, dass ich mit dem Inhalt der Konferenz zufrieden war und Datenwissenschaftlern empfehlen werde, nächstes Jahr daran teilzunehmen. Auch das Netzwerk, das ich während der Diskussionen geknüpft habe, ist unbezahlbar.4
Es hat auch Spaß gemacht, auf der Konferenz zu sprechen. Ich bin mit einem guten Gefühl gegangen und konnte einige gute Witze erzählen.


Aber um ehrlich zu sein, das Beste von allem war der Ort, an dem wir authentisches mexikanisches Essen fanden! Ich habe vor Aufregung fast geweint... sie hatten sogar Agua de Horchata

Wie immer bin ich gerne bereit, weitere Fragen zur Konferenz oder zu anderen Themen zu diskutieren und zu beantworten. Schreiben Sie mir einfach auf Twitter @rragundez oder LinkedIn.
- Die Folien und Präsentationen sind noch nicht hochgeladen worden. Ich werde die Links aktualisieren, sobald sie veröffentlicht sind.
- Spark unterteilt Aufträge in unabhängige Aufgaben (peinlich parallel). Dies unterscheidet sich von der Arbeitsweise verteilter Frameworks für maschinelles Lernen, die manchmal MPI oder benutzerdefinierte RPCs für die Kommunikation verwenden.
- Ich würde Ihnen empfehlen, zunächst mit der hier beschriebenen LightFM-Implementierung zu beginnen.
- Nebenbei bemerkt, habe ich in den Vorträgen der großen Unternehmen sehr viel Tensorflow in Spark gesehen. Ich wünschte mir, dass die Unternehmen der NL über ein so großes Datenvolumen verfügen würden.
Unsere Ideen
Weitere Blogs




Contact