
Dieses Dokument enthält eine Anleitung für die Bereitstellung eines Spark-Clusters mit Rstudio. Sie benötigen einen Rechner, auf dem Bash-Skripte ausgeführt werden können, und ein funktionierendes Konto bei AWS. Beachten Sie, dass diese Anleitung für Spark 1.4.0 gedacht ist. Zukünftige Versionen werden höchstwahrscheinlich auf eine andere Weise bereitgestellt, aber dies sollte für den Anfang ausreichen. Am Ende dieses Tutorials verfügen Sie über einen vollständig eingerichteten Spark-Cluster, mit dem Sie einfache Dataframe-Operationen auf Gigabytes von Daten in RStudio durchführen können.
AWS-Vorbereitung
Stellen Sie sicher, dass Sie ein AWS-Konto mit Rechnungsstellung haben. Stellen Sie als Nächstes sicher, dass Sie Ihre .pem Dateien heruntergeladen haben und dass Sie Ihre Schlüssel bereithalten.
Spark Startup
Als nächstes holen Sie sich Spark von der Spark-Homepage lokal auf Ihren Rechner. Es ist ein ziemlich großer Blob. Entpacken Sie es, sobald es heruntergeladen ist, und gehen Sie in den Ordner ec2 im Ordner spark. Führen Sie den folgenden Befehl in der Befehlszeile aus.
./spark-ec2 --key-pair=spark-df --identity-datei=/Users/code/Downloads/spark-df.pem --region=eu-west-1 -s 1 --Instanz-Typ c3.2xgroß mysparkr starten
Dieses Skript verwendet Ihre Schlüssel, um sich mit amazon zu verbinden und einen Spark Standalone-Cluster für Sie einzurichten. Sie können angeben, welche Art von Maschinen Sie verwenden möchten sowie wie viele und wo auf amazon. Sie müssen nur warten, bis alles installiert ist, was bis zu 10 Minuten dauern kann. Weitere Informationen finden Sie unter https://spark.apache.org/docs/latest/ec2-scripts.html.
Wenn der Befehl signalisiert, dass er fertig ist, können Sie sich über die Kommandozeile in Ihren Rechner einwählen.
./spark-ec2 -k spark-df -i /Users/code/Downloads/spark-df.pem --region=eu-west-1 Anmeldung mysparkr
Sobald Sie sich auf Ihrem Amazon-Rechner befinden, können Sie SparkR sofort vom Terminal aus starten.
chmod u+w /root/spark/ ./spark/bin/sparkR
Dies ist nur ein kleines Beispiel. Sie sollten bestätigen können, dass der folgende Code bereits funktioniert.
ddf createDataFrame(sqlContext, faithful)
head(ddf)
printSchema(ddf)
Dieser ddf Datenrahmen ist kein gewöhnliches Datenrahmenobjekt. Es handelt sich um einen verteilten Datenrahmen, der über ein Netzwerk von Workern verteilt werden kann, so dass wir ihn über Spark nach paralisierten Befehlen abfragen können.
Spark UI
Dieser R-Befehl, den Sie gerade ausgeführt haben, startet einen Spark-Job. Spark verfügt über eine Web-ui, mit der Sie den Cluster im Auge behalten können. Um die Web-ui aufzurufen, müssen Sie zunächst mit diesem Befehl bestätigen, welche IP-Adresse der Master-Knoten hat:
locken icanhazip.com
Sie können das Webui jetzt über Ihren Browser aufrufen.
:4040
Von hier aus können Sie sich alles ansehen, was Sie über Ihre Spark-Cluster wissen möchten (z. B. Executor-Status, Job-Prozess und sogar eine DAG-Visualisierung).
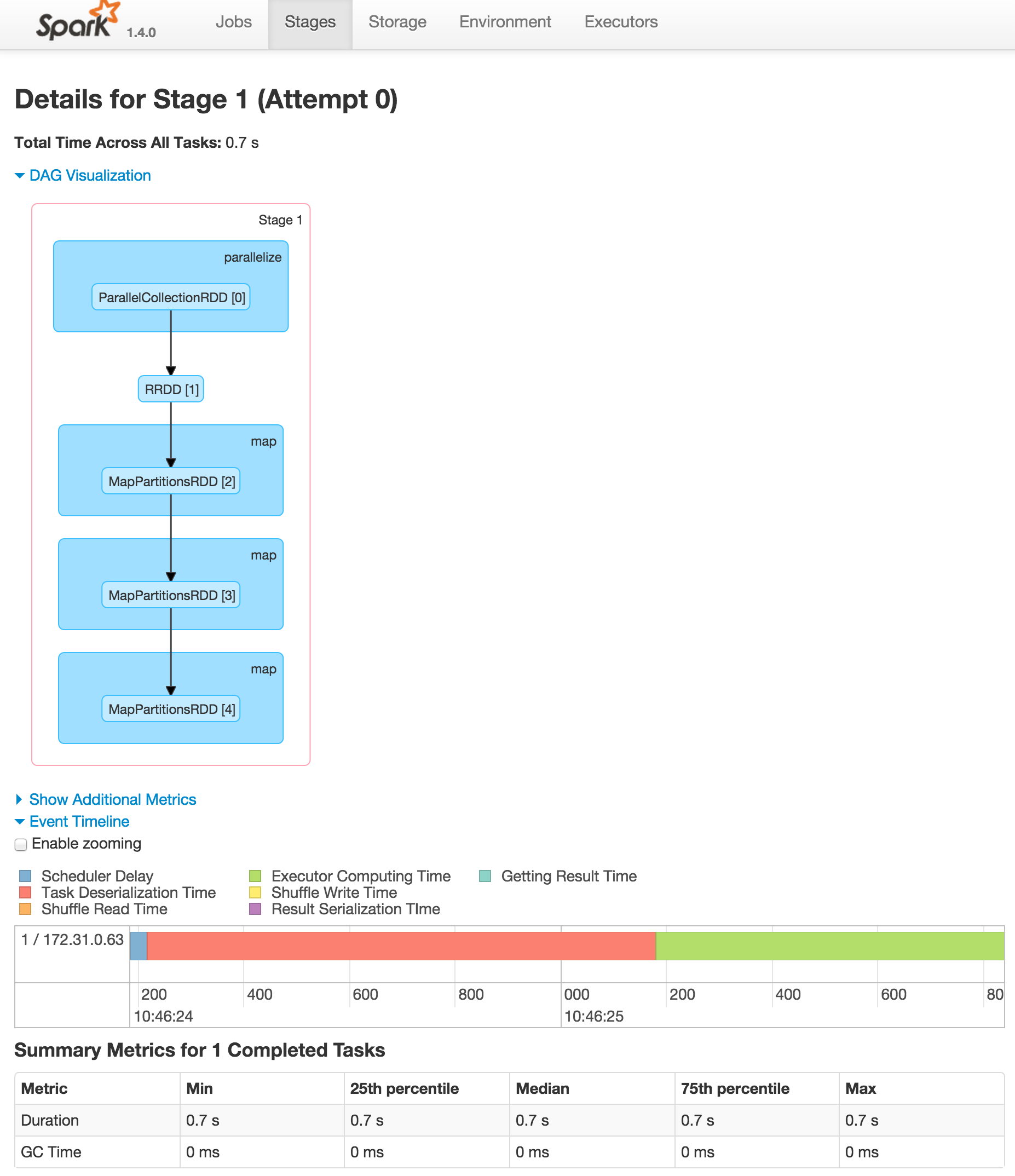
Dies ist ein guter Moment, um innezuhalten und zu erkennen, dass dies für sich genommen schon sehr cool ist. Wir können einen Spark-Cluster in 15 Minuten starten und ihn mit R steuern. Wir können angeben, wie viele Server wir benötigen, indem wir nur eine Zahl auf der Befehlszeile ändern, und ohne echten Entwickleraufwand erhalten wir Zugang zu all dieser parallisierenden Macht.
Dennoch ist die Arbeit mit einem Terminal vielleicht nicht sehr produktiv. Wir würden es vorziehen, mit einer grafischen Benutzeroberfläche zu arbeiten, und wir hätten gerne einige grundlegende Plot-Funktionen, wenn wir mit Daten arbeiten. Lassen Sie uns also Rstudio installieren und ein paar Tools anschließen.
Rstudio-Einrichtung
Verlassen Sie die Shell SparkR, indem Sie q() eingeben. Als nächstes laden Sie Rstudio herunter und installieren es.
wget http://download2.rstudio.org/rstudio-server-rhel-0.99.446-x86_64.rpm sudo yum install --nogpgcheck -y rstudio-server-rhel-0.99.446-x86_64.rpm rstudio-server neu starten
Während dies installiert wird. Stellen Sie sicher, dass die TCP-Verbindung auf dem Port 8787 in der AWS-Sicherheitsgruppeneinstellung für den Master-Knoten offen ist. Es wird empfohlen, den Zugriff nur von Ihrer IP-Adresse aus zuzulassen.

Dann fügen Sie einen Benutzer hinzu, der auf rstudio zugreifen kann. Wir stellen sicher, dass dieser Benutzer auch auf alle rstudio-Dateien zugreifen kann.
adduser-Analyst passwd-Analyst
Sie müssen dies auch tun (die Details, warum, sind etwas kompliziert). Diese Änderungen müssen vorgenommen werden, weil der Benutzer analyst keine Root-Rechte hat.
chmod a+w /mnt/spark chmod a+w /mnt2/spark sed -e 's/^ulimit/#ulimit/g' /root/spark/conf/spark-env.sh > /root/spark/conf/spark-env2.sh mv /root/spark/conf/spark-env2.sh /root/spark/conf/spark-env.sh ulimit -n 1000000
Wenn dies bekannt ist, verweisen Sie den Browser auf
Rstudio - Spark-Link
Fantastisch. Rstudio ist eingerichtet. Starten Sie zunächst den Master Submit.
/root/spark/sbin/stop-all.sh /root/spark/sbin/start-all.sh
Dadurch wird Spark neu gestartet (sowohl der Master- als auch der Slave-Knoten). Sie können bestätigen, dass Spark nach diesem Befehl funktioniert, indem Sie den Browser auf
Als Nächstes lassen Sie uns Spark von RStudio aus starten. Starten Sie ein neues R-Skript und führen Sie den folgenden Code aus:
drucken('Ich schließe jetzt für Sie an Spark an.') funken_link system('cat /root/spark-ec2/cluster-url', intern=TRUE) .libPaths(c(.libPaths(), '/root/spark/R/lib')) Sys.setenv(SPARK_HOME = '/root/spark') Sys.setenv(PATH = paste(Sys.getenv(c('PATH')), '/root/spark/bin', sep =':')) Bibliothek(SparkR) sc sparkR.init(spark_link) sqlContext sparkRSQL.init(sc) drucken('Spark-Kontext verfügbar als "sc". n' ) drucken(Spark SQL-Kontext verfügbar als "sqlContext". n' )
Laden von Daten aus S3
Lassen Sie uns bestätigen, dass wir jetzt mit dem Rstudio-Stack spielen können, indem wir einige Bibliotheken herunterladen und sie gegen Daten auf S3 laufen lassen.
kleine_datei =dist_df read.df(sqlContext, small_file, "json") %> % cache "s3n://:@/data.json"
Dieses dist_df ist jetzt ein verteilter Datenrahmen, der eine andere API als der normale R-Datenrahmen hat, aber ähnlich wie dplyr ist.
head(zusammenfassen(groupBy(dist_df, df$Typ), Anzahl = n(df$auc)))
Außerdem können wir magnittr installieren, damit unser Code viel schöner aussieht.
lokal_df dist_df %> %
groupBy(df$type) %> %
summarize(count = n(df$id)) %> %
collect
Die Methode collect zieht den verteilten Datenrahmen zurück auf einen einzelnen Rechner, so dass Sie wieder Plot-Methoden darauf anwenden und R verwenden können. Ein üblicher Anwendungsfall ist die Verwendung von Spark, um eine Stichprobe zu nehmen oder einen großen Datensatz zu aggregieren, der dann in R weiter untersucht werden kann.
Wenn Sie sich die Spark-Oberfläche für diese Aufträge ansehen möchten, gehen Sie einfach zu:
:4040
Ein vollständigerer Stapel
Leider enthält dieser Stack eine alte Version von R (wir benötigen Version 3.2, um die neueste Version von ggplot2/dplyr zu erhalten). Außerdem gibt es im Moment noch keine Unterstützung für die Bibliotheken für maschinelles Lernen. Diese Probleme sind derzeit bekannt und sollten in Version 1.5 behoben werden. Version 1.5 wird auch die Installation von rstudio als Teil des ec2-Stacks enthalten.
Ein weiteres Problem ist, dass der Namespace von dplyr derzeit mit sparkr kollidiert. Das Gleiche gilt für andere Datenfunktionen wie die Fensterfunktion und komplexere Datentypen.
Das Töten des Clusters
Wenn Sie mit dem Cluster fertig sind. Sie müssen nur die ssh-Verbindung beenden und den folgenden Befehl ausführen:
./spark-ec2 -k spark-df -i /Users/code/Downloads/spark-df.pem --region=eu-west-1 zerstören mysparkr
Fazit
Die Wirtschaftlichkeit von Spark ist sehr interessant. Wir zahlen Amazon nur für die Zeit, in der wir Spark als Compute Engine nutzen. Alle anderen Zeiten bezahlen wir nur für S3. Das heißt, wenn wir 8 Stunden lang analysieren, zahlen wir auch nur für 8 Stunden. Spark ist auch insofern sehr flexibel, als wir weiterhin in R (oder Python oder Scala) programmieren können, ohne mehrere domänenspezifische Sprachen oder Frameworks wie bei Hadoop lernen zu müssen. Spark macht Big Data wieder ganz einfach.
Dieses Dokument soll Ihnen den Einstieg in Spark und Rstudio erleichtern. In einer Produktionsumgebung gibt es jedoch noch einige Dinge zu beachten:
- Sicherheit, unsere Webverbindung erfolgt nicht über https, auch wenn wir amazon mitteilen, dass nur unsere IP-Adresse verwendet werden soll, können wir einem Sicherheitsrisiko ausgesetzt sein, wenn ein Mann in der Mitte zuhört.
- Wenn mehrere Benutzer an einem solchen Cluster arbeiten, müssen Sie möglicherweise einige Schritte in Bezug auf Benutzergruppen, Dateizugriff und Ressourcenverwaltung überdenken.
- Wenn Sie jedoch sensible, private Benutzerdaten haben, müssen Sie dies möglicherweise vor Ort tun, da die Daten Ihr eigenes Rechenzentrum nicht verlassen dürfen. Die meisten Installationsschritte sind die gleichen, aber die Erstinstallation von Spark erfordert den meisten Aufwand. Weitere Informationen finden Sie in der Dokumentation.
Spark ist ein erstaunliches Tool, erwarten Sie in Zukunft mehr Funktionen.
Möglicherweise Gotya
Hängend
Es kann vorkommen, dass das Skript ec2 im Teil Waiting for cluster to enter 'ssh-ready' state hängen bleibt. Das kann passieren, wenn Sie amazon häufig verwenden. Um dies zu verhindern, können Sie einige Zeilen in ~/.ssh/known_hosts entfernen. Weitere Informationen finden Sie hier. Eine andere Möglichkeit besteht darin, die folgenden Zeilen zu Ihrer ~/.ssh/config Datei hinzuzufügen.
# AWS EC2 öffentliche Hostnamen (IPs ändern) Host *.compute.amazonaws.com StrictHostKeyChecking nein UserKnownHostsFile /dev/null
Unsere Ideen
Weitere Blogs




Contact