
Vor nicht allzu langer Zeit habe ich an einem Graph Café teilgenommen, einer netten Art von Meetup, bei dem es keine formelle Tagesordnung gibt, sondern nur eine Reihe von Blitzvorträgen mit bierseligen Pausen dazwischen. Graph Cafés werden in regelmäßigen Abständen von der Graph Database - Amsterdam Meetup-Gruppe organisiert. Natürlich hatte mich mein Freund Rik van Bruggen freundlicherweise und ohne jeglichen Druck gebeten, ebenfalls einen Lightning Talk zu halten, also musste ich mir etwas einfallen lassen. Neo4j 2.0 wurde vor kurzem veröffentlicht und das Graph Café war eigentlich dazu gedacht, diesen Anlass zu feiern. Eine der neuen Funktionen in 2.0 ist eine umfassende Überarbeitung der Abfragesprache Cypher. Ich wollte herausfinden, wie viel man mit der Abfragesprache in Bezug auf die Erstellung von Funktionen tun kann. Meine Herausforderung: verschiedene Formen von Empfehlungen rein in Cypher zu implementieren. Und ich spreche hier nicht von der einfachen Art von Empfehlungen, die auf dem Zählen von Übereinstimmungen beruhen, sondern von etwas weniger Trivialem als dem. In meinem Blitzvortrag ging es schließlich darum, einen naiven Bayes-Klassifikator in Cypher zu erstellen, was auch einigermaßen funktionierte. Natürlich konnte ich es nicht dabei belassen, also habe ich den Klassifikator und die kollaborative Filterung (basierend auf der Kosinus-Ähnlichkeit zwischen den Artikeln) in Cypher implementiert. Dieser Beitrag zeigt, wie das geht.
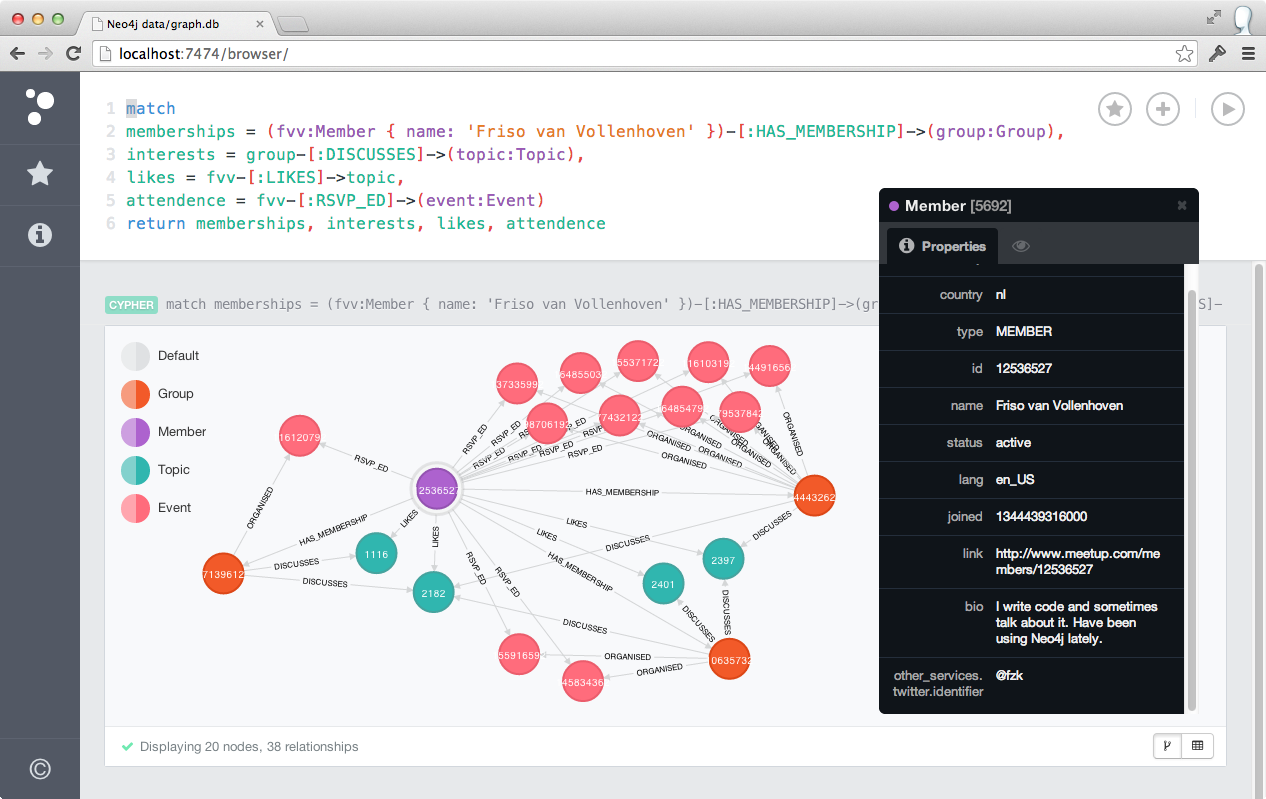
Ihre Meetup.com-Nachbarschaft in einer Grafik
Um Empfehlungen aussprechen zu können, benötigen wir einen Datensatz mit Dingen, die empfohlen werden können. Zu diesem Zweck habe ich mich entschieden, Daten für eine Reihe von Meetup.com-Gruppen über deren hervorragende API abzurufen. Damit können wir Gruppen, ihre Mitglieder, die RSVP's der Mitglieder, die Interessen der Mitglieder und vieles mehr abrufen. Unser Graph enthält mehrere Meetup-Gruppen mit allen Mitgliedern, Themen, die für die Mitglieder und die Gruppen von Interesse sind, sowie alle RSVP's der Mitglieder für jede Gruppe. Dies sind die möglichen Beziehungen und Knotenbeschriftungen (wenn Ihnen das zu umständlich vorkommt, sollten Sie zuerst etwas über Cypher lesen ):
(Mitglied:Mitglied)-[:HAS_MEMBERSHIP]->(Gruppe:Gruppe) (Mitglied:Mitglied)-[:LIKES]->(Thema:Thema) (Mitglied:Mitglied)-[:RSVP_ED]->(Veranstaltung:Veranstaltung) (Gruppe:Gruppe)-[:ORGANISIERT]->(Veranstaltung:Veranstaltung) (Gruppe:Gruppe)-[:DISKUSSIONEN]->(Thema:Thema)
Der Graph wird mit einem einfachen Python-Skript erstellt, das die erforderlichen API-Aufrufe tätigt und die Datenbank mit py2neo auffüllt. Bevor wir einen sinnvollen Abgleich mit der Datenbank vornehmen können, müssen wir einige Indizes erstellen, damit wir Dinge anhand ihres Namens finden können. Glücklicherweise ist das im neuen Cypher ganz einfach!
erstellen Index auf :Gruppe(Name) erstellen Index auf :Mitglied(Name) erstellen Index auf :Thema(Name)
Finden Sie mich (Friso van Vollenhoven) und zeigen Sie alle meine Gruppenmitgliedschaften, die Themen, die ich mag, die Themen, die in meinen Gruppen diskutiert werden, und die Veranstaltungen, für die ich zugesagt habe:
Sind Sie ein Experte für Graphdatenbanken?
In unserem Beispiel werden wir nach Personen suchen, denen wir die Graph Database - Amsterdam meetup Gruppe empfehlen können. Im Grunde können wir für jede Person in der Datenbank fragen: Sind Sie ein Graphdatenbank-Typ? Wir werden versuchen, vorherzusagen, wer diese Frage mit Ja beantworten wird. Diese Personen werden diejenigen sein, denen wir die Graphdatenbank-Gruppe empfehlen können.
Was also macht eine Person zu einem Graphdatenbank-Typ? Eine Möglichkeit, sich dieser Frage zu nähern, ist die Betrachtung der Themen, die typische Graphdatenbank-Menschen mögen, im Vergleich zu den Themen, die andere Menschen mögen. Wir verwenden die Themen als binäres Merkmal einer Person und erstellen auf der Grundlage dieser Merkmale einen naiven Bayes-Klassifikator. Für das Training gehen wir davon aus, dass Personen, die sich bereits in der Graphdatenbankgruppe befinden, Graphdatenbankpersonen sind und Personen, die sich in einer anderen, nicht verwandten Gruppe befinden, Nicht-Graphdatenbankpersonen sind.
Um das Mögen von Themen als binäre Merkmale für unsere Klassifizierung zu verwenden, müssen wir die Wahrscheinlichkeiten bestimmen, dass eine Person ein bestimmtes Thema mag, sowohl allgemein als auch für die beiden Klassen, die wir klassifizieren möchten (Graphdatenbank-Person und Nicht-Graphdatenbank-Person). Wir können dies ganz einfach tun, indem wir zählen, wie viele Personen die einzelnen Themen mögen. Wir tun dies für die gesamte Trainingspopulation und für die beiden Klassen. Außerdem werden wir die Trainingsdaten in zwei Teile aufteilen, so dass wir einen Teil als Trainingsdaten und einen als Testdaten verwenden können, um die Genauigkeit unseres Klassifikators zu überprüfen.
Lassen Sie uns zunächst sehen, welche Gruppen wir im Datensatz haben.
Spiel (Gruppe:Gruppe) return Gruppe.Name
Das ergibt:
gruppe.name ----------------------------------------------------- Die Amsterdamer Meetup-Gruppe für angewandtes maschinelles Lernen Niederlande Cassandra Benutzer AmsterdamJS Graph Datenbank - Amsterdam Amsterdam Sprachcafé Open Web Meetup Amsterdam Photo Club 'Damm-Läufer Amsterdam Bier Meetup Gruppe Das Amsterdamer Indoor-Klettern (10 Zeilen)
Lassen Sie uns nun zwei Gruppen als Trainingsgruppen markieren, indem wir eine Beschriftung hinzufügen.
Spiel (graphdb:Gruppe { Name:'Grafik Datenbank - Amsterdam'}), (Foto:Gruppe { Name:'Amsterdam Foto Club' }) einstellen. graphdb :Ausbildung, Foto :Ausbildung
Wählen Sie in den Trainingsgruppen die Hälfte der Mitglieder als Trainingsdaten aus, indem Sie diesen Knoten ebenfalls eine Beschriftung hinzufügen (Hinweis: Führen Sie diese Abfrage nicht mehrmals aus).
Spiel (Gruppe:Gruppe :Ausbildung):HAS_MEMBERSHIP]-(Mitglied:Mitglied) wobei rand() >= 0.5 einstellen. Mitglied :Ausbildung return Gruppe.Name, zählen(distinct Mitglied)
Die Abfrage gibt die Anzahl der Mitglieder zurück, die als Trainingsdaten pro Gruppe ausgewählt wurden.
group.name | count(distinct member) ----------------------------+------------------------ Amsterdam Photo Club | 189 Graph Datenbank - Amsterdam | 106 (2 Zeilen)
Das Ergebnis zeigt uns, wie viele Personen in den Trainingsdatensatz für jede Gruppe aufgenommen wurden. Wir müssen uns diese Zahlen für spätere Zwecke merken, da sie die Nenner für einige der Berechnungen sind, die wir durchführen werden.
Lernen durch Zählen
Schauen wir uns an, wie das Mögen verschiedener Themen die Wahrscheinlichkeit erhöht, dass jemand ein Graph-Datenbanker ist. Dazu müssen wir auch die Gesamtzahl der Personen in den Trainingsdaten kennen. Natürlich können wir die obigen Zahlen zusammenzählen, aber wo bleibt da der Spaß? Lassen Sie uns das abfragen.
Spiel (Mitglied:Mitglied :Ausbildung)-[:HAS_MEMBERSHIP]->(grp:Gruppe :Ausbildung) return zählen(deutlich Mitglied) als total_mitglieder
Wir müssen diese Nummer für spätere Zwecke aufbewahren.
total_mitglieder --------------- 295 (1 Zeile)
Das Schöne an Naive Bayes ist, dass es sich bei binären Merkmalen meist nur um Zählen und Multiplizieren handelt. Das Problem ist, dass wir eine Möglichkeit brauchen, uns diese Zählungen zu merken. Cypher ist zustandslos und deklarativ, so dass wir keine Möglichkeit haben, die Daten zwischen den Abfragen im Speicher zu halten (AFAIK). Um dies zu umgehen, speichern wir die Anzahl einfach im Graphen selbst. Zuerst setzen wir die Likes aller Mitglieder für jedes Thema. Beachten Sie, dass wir 1 zur tatsächlichen Anzahl der Likes hinzufügen. Wir werden später sehen, warum das so ist.
Spiel (Thema:Thema):LIKES]-(Mitglied:Mitglied :Ausbildung) mit Thema, zählen(distinct Mitglied) als mag einstellen. Thema.like_count = mag + 1 return zählen(Thema)
Die Abfrage gibt die Anzahl der aktualisierten Themen zurück.
count(Thema) ----------------------- 1111 (1 Zeile)
Dasselbe gilt für Likes von Mitgliedern der Graph-Datenbank.
Spiel (grp:Gruppe :Ausbildung { Name:'Grafik Datenbank - Amsterdam'} ):HAS_MEMBERSHIP]-(Mitglied:Mitglied :Ausbildung)-[:LIKES]->(Thema:Thema) mit Thema, zählen(distinct Mitglied) als mag einstellen. Thema.graphdb_like_count = mag + 1 return zählen(Thema)
Die 502 Themen aktualisiert.
count(Thema) -------------- 502 (1 Zeile)
Schließlich müssen wir das Gleiche für die Personen tun, die keine Graphen-Datenbank besitzen.
Spiel (graphdb:Gruppe :Ausbildung { Name:'Grafik Datenbank - Amsterdam' }), (andere:Gruppe :Ausbildung):HAS_MEMBERSHIP]-(Mitglied:Mitglied :Ausbildung)-[:LIKES]->(Thema:Thema) wobei nicht graphdb:HAS_MEMBERSHIP]-Mitglied mit Thema, zählen(distinct Mitglied) als mag einstellen. Thema.non_graphdb_like_count = mag + 1 return zählen(Thema)
Damit werden weitere 816 aktualisiert.
count(Thema) -------------- 816 (1 Zeile)
Prima. Jetzt haben wir alle Zutaten, um zu sehen, ob wir ein Mitglied als Graphdatenbank-Person klassifizieren können. Lassen Sie es uns mit meinem Freund Rik versuchen. Sie sehen in der Abfrage, dass wir coalesce verwenden, um Themen zu berücksichtigen, die wir in unseren Trainingsdaten nicht gesehen haben. Wir geben diesen Themen einen Standardwert von 1. Das wäre jedoch nicht fair gegenüber den Themen, die tatsächlich einmal vorhanden sind. Als Lösung könnten wir 1 zu diesen Themen hinzufügen, aber dann wäre es wiederum nicht fair gegenüber den Themen, die tatsächlich zweimal vorhanden waren, weshalb wir 1 zu allen Themenzahlen hinzufügen. Das ist die +1, die wir bei den früheren Abfragen gesehen haben, bei denen wir die Anzahl der Themen festgelegt haben. Dies ist eine Form der Glättung der Daten, die auf der Annahme beruht, dass wirklich seltene Eigenschaften weniger häufig vorkommen als die in den Trainingsdaten.
Schauen wir uns nun an, wie die verschiedenen Themen, die Rik mag, zu der Tatsache beitragen, dass er ein Graphdatenbank-Mensch sein könnte oder auch nicht. Wir schauen uns alle Themen an, die Rik mag, und geben die Wahrscheinlichkeiten dafür an, dass eine Person, die Graphdatenbanken mag, diese Themen mag, und die Wahrscheinlichkeit, dass eine Person, die keine Graphdatenbank mag, diese Themen mag. Damit können wir die bedingten Wahrscheinlichkeiten dafür, dass jemand ein Graphdatenbank-Mensch ist, anhand des Vorhandenseins eines Themas mit Hilfe des Satzes von Bayes bestimmen.
Spiel (Mitglied:Mitglied { Name : 'Rik Van Bruggen' })-[:LIKES]->(Thema:Thema) return Thema.Name, hat(Thema.like_count) als in_training, ( (verschmelzen(Thema.graphdb_like_count, 1.0) / 106.0) * (106.0 / 295.0) ) / (verschmelzen(Thema.like_count, 1.0) / 295.0) als P_graphdb, ( (verschmelzen(Thema.non_graphdb_like_count, 1.0) / 189.0) * (189.0 / 295.0) ) / (verschmelzen(Thema.like_count, 1.0) / 295.0) als P_nicht_graphdb
Wenn man Neo4j und Graphdatenbanken mag, steigt die Wahrscheinlichkeit, dass man ein Graphdatenbanker ist. Welch eine Überraschung! Themen, die ausschließlich in der Graphdatenbank-Trainingsgruppe vorkommen, haben eine Wahrscheinlichkeit von 1,0, was aufgrund von Rundungsfehlern manchmal zu > 1,0 führt. Wir geben auch ein boolesches Flag zurück, das uns sagt, ob das Thema in den Trainingsdaten vorhanden war. Sie sehen, dass Themen, die in keiner der Klassen in den Trainingsdaten vorkommen, auf beiden Seiten eine Wahrscheinlichkeit von 1,0 ergeben, was zwar kontraintuitiv (und falsch) ist, aber für die Klassifizierung keine Rolle spielt.
topic.name | in_training | P_graphdb | P_non_graphdb --------------------------------------+-------------+--------------------+---------------------- Datenwissenschaft | Wahr | 1.0 | 0.03225806451612903 Data Mining | Wahr | 1.0 | 0.047619047619047616 Datenanalyse | Wahr | 0.9818181818181818 | 0.03636363636363636 Spielentwicklung | Falsch | 1.0 | 1.0 Videospiel-Design | Falsch | 1.0 | 1.0 Entwicklung von Handy- und Handheld-Spielen | Falsch | 1.0 | 1.0 Entwicklung mobiler Spiele | Falsch | 1.0 | 1.0 Videospielentwicklung | Falsch | 1.0 | 1.0 Indie-Spiele | Falsch | 1.0 | 1.0 Unabhängige Spielentwicklung | Falsch | 1.0 | 1.0 Spieldesign | Falsch | 1.0 | 1.0 Spieleprogrammierung | Falsch | 1.0 | 1.0 Datenvisualisierung | Wahr | 1.0 | 0.047619047619047616 Software-Entwickler | Wahr | 0.9090909090909091 | 0.10909090909090909 Open Source | Wahr | 0.8823529411764706 | 0.1323529411764706 Java | Wahr | 0.9600000000000002 | 0.08 Java Programmierung | Falsch | 1.0 | 1.0 mongoDB | True | 0.9615384615384616 | 0.07692307692307693 Big Data | Wahr | 1.0 | 0.013333333333333334 NoSQL | True | 0.9836065573770492 | 0.03278688524590164 Graph-Datenbanken | Wahr | 1.0 | 0.019230769230769232 Neo4j | True | 1.0000000000000002 | 0.020833333333333336 (22 Zeilen)
Unabhängigkeit für alle Funktionen!
Verwenden wir nun diese Wahrscheinlichkeiten und kombinieren sie zu einer Klassifizierung unter der naiven Annahme, dass das Mögen von Themen völlig unabhängig ist.
Spiel (Mitglied:Mitglied { Name : 'Rik Van Bruggen' })-[:LIKES]->(Thema:Thema) mit Mitglied, sammeln(verschmelzen(Thema.graphdb_like_count, 1.0)) als graphdb_likes, sammeln(verschmelzen(Thema.non_graphdb_like_count, 1.0)) als non_graphdb_likes mit Mitglied, (106.0 / 295.0) * reduzieren(prod = 1.0, ct in graphdb_likes | prod * (ct / 106.0)) als P_graphdb, (189.0 / 295.0) * reduzieren(prod = 1.0, ct in non_graphdb_likes | prod * (ct / 189.0)) als P_nicht_graphdb return Mitglied.Name, P_graphdb > P_nicht_graphdb
Und wieder einmal eine Überraschung. Rik ist wahrscheinlich ein Graph-Datenbank-Mensch! Beachten Sie, dass wir den Nenner nicht wie oben verwenden. Wir können dies tun, weil er für beide Klassen gleich ist und wir uns nur dafür interessieren, welches der beiden Ergebnisse größer ist.
member.name | P_graphdb > P_nicht_graphdb -----------------+--------------------------- Rik Van Bruggen | Wahr (1 Zeile)
Und nun die große Frage! Wie viele Graphdatenbank-Personen gibt es im gesamten Datensatz, die nicht bereits Mitglied der Graphdatenbank-Gruppe sind?
Spiel (Mitglied:Mitglied)-[:LIKES]->(Thema:Thema), (graphdb:Gruppe { Name:'Grafik Datenbank - Amsterdam'}) wobei nicht Mitglied-[:HAS_MEMBERSHIP]->graphdb mit Mitglied, sammeln(verschmelzen(Thema.graphdb_like_count, 1.0)) als graphdb_likes, sammeln(verschmelzen(Thema.non_graphdb_like_count, 1.0)) als non_graphdb_likes mit Mitglied, (106.0 / 295.0) * reduzieren(prod = 1.0, ct in graphdb_likes | prod * (ct / 106.0)) als P_graphdb, (189.0 / 295.0) * reduzieren(prod = 1.0, ct in non_graphdb_likes | prod * (ct / 189.0)) als P_nicht_graphdb mit P_graphdb > P_nicht_graphdb als graphdb_person return graphdb_person, zählen(*)
Nun, es stellt sich heraus, dass unser Klassifikator glaubt, dass es 863 Personen gibt, die potenziell süchtig nach Graphdatenbanken sind, ohne dass sie der Gruppe bereits beigetreten sind.
graphdb_person | count(*) ----------------+---------- Falsch | 1724 Wahr | 863 (2 Zeilen)
Die nächste offensichtliche Frage ist nun: Wie genau sind diese Ergebnisse? Da wir die Hälfte der Daten in unserem beschrifteten Datensatz als Testsatz beiseite gelegt haben, können wir diese nun verwenden, um herauszufinden, wie genau unser Klassifikator ist, indem wir eine Konfusionsmatrix erstellen (obwohl sie in unserer Ausgabe nicht wie eine Matrix aussieht, aber Sie verstehen schon). Schauen wir uns das mal an.
Spiel (Gruppe:Gruppe :Ausbildung):HAS_MEMBERSHIP]-(Mitglied:Mitglied)-[:LIKES]->(Thema:Thema) wobei nicht (Mitglied:Ausbildung) mit Gruppe, Mitglied, sammeln(zusammenführen(Thema.graphdb_like_count, 1.0)) als graphdb_likes, sammeln(zusammenführen(Thema.non_graphdb_like_count, 1.0)) als non_graphdb_likes mit Gruppe, Mitglied, (106.0 / 295.0) * reduzieren(prod = 1.0, ct in graphdb_likes | prod * (cnt / 106.0)) als P_graphdb, (189.0 / 295.0) * reduzieren(prod = 1.0, ct in non_graphdb_likes | prod * (cnt / 189.0)) als P_nicht_graphdb mit Gruppe, P_graphdb > P_nicht_graphdb als graphdb_person return Gruppe.Name, graphdb_person, zählen(*)
Die Ergebnisse:
group.name | graphdb_person | count(*) ----------------------------+----------------+---------- Graph Datenbank - Amsterdam | Falsch | 3 Graph Datenbank - Amsterdam | Wahr | 117 Amsterdam Photo Club | Falsch | 157 Amsterdam Photo Club | Wahr | 10 (4 Zeilen)
Wie sich herausstellt, haben wir 10 falsch-positive Ergebnisse, d.h. wir klassifizieren fälschlicherweise etwa 7 % der Personen, die keine Graphdatenbank nutzen, als Graphdatenbanknutzer. Wenn wir dies verbessern möchten, gibt es mehrere Möglichkeiten. Eine davon ist, die Details der falsch-positiven Ergebnisse zu untersuchen, indem wir eine manuelle explorative Analyse durchführen und als Ergebnis möglicherweise bessere Merkmale finden. Die andere, offensichtliche Möglichkeit ist: MEHR DATEN! Entscheiden Sie sich für Letzteres, wenn Sie können. Es ist billiger, als zahlreiche Stunden mit der Verbesserung Ihres Modells zu verbringen.
Produktionsbereit?
Die obige Lösung funktioniert. Allerdings gibt es einen Haken: Wir müssen die Anzahl der Likes für die Themen im Graphen selbst speichern, damit alles funktioniert. Das Gute daran ist, dass dadurch eine denormalisierte (gibt es das in einer Diagrammdatenbank?), voraggregierte Ansicht einiger für die Klassifizierung benötigter Daten entsteht. Dadurch wird der Klassifizierungsprozess beschleunigt. Die Kehrseite der Medaille ist, dass das Festlegen und Aktualisieren der Zählungen eine globale Operation des Graphen ist, die auch in den Graphen zurückschreibt.
Wenn wir diese Klassifizierung nur einmal durchführen und dann vergessen würden, wäre es schöner, die Zählungen im Speicher und nicht im Diagramm zu behalten. Wir könnten eine Anfrage für eine Cypher-basierte Skriptsprache stellen, die es ermöglicht, während der Skriptausführung Variablen zu setzen, die im gesamten Skript wiederverwendet werden können.
Wenn Sie andererseits den Klassifikator ständig laufen lassen müssen, wäre es schöner, die Zählungen im Diagramm zu speichern, sie aber zu aktualisieren, wenn sich etwas ändert. Ein weiterer Funktionswunsch: Auslöser.
Ganze Gruppen ins Visier nehmen
Jede Person einzeln zu klassifizieren ist eine Menge Arbeit. Es kann problematisch sein, einen solchen Ansatz zu skalieren. Können wir nicht einfach ganze Meetup-Gruppen anvisieren, die unserer Graphdatenbank-Meetup-Gruppe irgendwie ähneln? Natürlich können wir das. Wir können kollaboratives Filtern verwenden, um herauszufinden, welche Gruppen den unseren am ähnlichsten sind.
Das absolut Einfachste (Dümmste), was Sie tun können, ist einfach anzunehmen, dass die Gruppen, die die meisten Mitglieder mit unserer Gruppe gemeinsam haben, sich am ähnlichsten sind und daher auch Graphdatenbanken (als Gruppe) mögen werden. Das Problem dabei ist, dass dadurch größere Gruppen gegenüber kleineren bevorzugt werden (weil sie mehr Mitglieder gemeinsam haben). Aus diesem Grund werden wir die Anzahl der gemeinsamen Mitglieder auf die Größe der Zielgruppen normalisieren.
Spiel (us:Gruppe { Name: 'Grafik Datenbank - Amsterdam'}):HAS_MEMBERSHIP]-(Mitglied:Mitglied)-[:HAS_MEMBERSHIP]-(andere:Gruppe) mit andere, zählen(distinct Mitglied) als gurren Spiel andere:HAS_MEMBERSHIP]-(Person:Mitglied) return andere.Name als Name, gurren, (coo * 1.0) / zählen(distinct Person) als Rang Bestellung von Rang absteigen.
Dieses Ergebnis impliziert, dass wir uns an die Mitglieder der niederländischen Cassandra Users Meetup-Gruppe wenden sollten, wenn wir nach neuen Mitgliedern für die Graphdatenbankgruppe suchen. Das scheint gut zu sein, aber es gibt immer noch Probleme. Zunächst einmal sehen wir, dass das Open Web Meetup relativ gut abschneidet (Platz 3), aber es ist eine sehr kleine Gruppe, so dass nur wenige gemeinsame Mitglieder nötig sind, um einen großen gemeinsamen Anteil zu erreichen, so dass das Ergebnis möglicherweise nicht sehr aussagekräftig ist. Wir könnten versuchen, die Anzahl der Mitglieder in der Zielgruppe zu berücksichtigen, um ein Konfidenzintervall zu erstellen, dessen untere Grenze wir als tatsächliche Punktzahl verwenden könnten(hier ist eine schöne Erklärung des Konzepts), aber das heben wir uns vielleicht für später auf.
name | coo | rang -----------------------------------------------------+-----+----------------------- Niederlande Cassandra Benutzer | 31 | 0.2246376811594203 The Amsterdam Applied Machine Learning Meetup Group | 55 | 0.2029520295202952 Open Web Meetup | 4 | 0.10256410256410256 AmsterdamJS | 36 | 0.06557377049180328 'Dammer Läufer | 5 | 0.009433962264150943 Amsterdam Bier Meetup Gruppe | 4 | 0.005934718100890208 Amsterdam Photo Club | 2 | 0.005154639175257732 Amsterdam Language Cafe | 2 | 0.0027397260273972603 (8 Zeilen)
Ein weiteres Problem bei diesem Ergebnis ist, dass es nur die Gruppenzugehörigkeit als Input berücksichtigt. Es ist fraglich, ob die Mitgliedschaft in einer Gruppe wirklich ein starker Hinweis auf das Interesse eines Mitglieds ist. Jeder kann Mitglied in vielen Meetup-Gruppen werden, da der Beitritt einfach und kostenlos ist. Vielleicht treten viele Leute einer Gruppe nur bei, um sie einmal auszuprobieren und interagieren dann nicht mehr mit der Gruppe, sind aber trotzdem als Mitglied aufgeführt. Um dies zu umgehen, werden wir die RSVP's der Personen verwenden, um zu sehen, wie oft sie tatsächlich mit der Gruppe interagieren. Mehr RSVP's bedeuten mehr Interesse an der Gruppe. Auch hier müssen wir natürlich die Anzahl der Treffen, die eine Gruppe tatsächlich organisiert, normalisieren. Wir werden die Anzahl der besuchten Treffen als Bruchteil der von einer Gruppe organisierten Treffen als Wert für das Interesse der einzelnen Mitglieder an einer Gruppe verwenden. Anhand dieser Punktzahl können wir eine Ähnlichkeit zwischen zwei Gruppen berechnen, die auf der Ähnlichkeit der Art und Weise beruht, wie die Mitglieder mit der Gruppe interagieren. Eine Möglichkeit, dies zu tun, ist die kollaborative Filterung unter Verwendung der Kosinusähnlichkeit als Ähnlichkeitsmaß (im Gegensatz zur reinen Koinzidenz im obigen Beispiel). So, das ist es:
Spiel (us:Gruppe { Name:'Grafik Datenbank - Amsterdam'})-[:ORGANISIERT]->(graph_meetup:Veranstaltung) :RSVP_ED]-(Mitglied:Mitglied)-[:RSVP_ED]->(anderes_meetup:Ereignis) :ORGANISIERT]-(andere:Gruppe) wobei us andere mit us, andere, Mitglied, zählen(distinct graph_meetup) als graph_rsvp, zählen(distinct anderes_meetup) als andere_rsvp Spiel us-[:ORGANISIERT]->(graph_meetup:Ereignis), andere-[:ORGANISIERT]->(anderes_meetup:Veranstaltung) mit us, andere, Mitglied, (graph_rsvp * 1.0) / zählen(distinct graph_meetup) als graph_score, (andere_rsvp * 1.0) / zählen(distinct anderes_meetup) als andere_Punktzahl mit us, andere, sammeln(graph_score * andere_Punktzahl) als score_product, sammeln(graph_score * graph_score) als graph_score_squared, sammeln(andere_punktzahl * andere_Punktzahl) als andere_punktzahl_quadrat, zählen(distinct Mitglied) als gurren wobei gurren > 1 return us.Name, andere.Name, gurren, reduzieren( Summe = 0, prd in score_product | Summe + prd) / ( sqrt( reduzieren(Summe = 0, x in graph_score_squared | Summe + x) ) * sqrt( reduzieren(Summe = 0, y in andere_punktzahl_quadrat | Summe + y) ) ) als Cosinus_Ähnlichkeit Bestellung von Cosinus_Ähnlichkeit absteigen.
Und in den Ergebnissen können Sie sehen, dass: a) wenn Sie nicht nur die Mitgliedschaft, sondern auch die Teilnahme an den Meetings betrachten, es nur drei andere Gruppen gibt, die tatsächlich mit der Graphdatenbankgruppe übereinstimmen und b) die Amsterdam Applied Machine Learning Meetup Group jetzt besser abschneidet als die Cassandra-Gruppe.
us.name | other.name | coo | cosine_similarity ----------------------------+-----------------------------------------------------+-----+-------------------- Graph Database - Amsterdam | The Amsterdam Applied Machine Learning Meetup Group | 38 | 0.7815846503441577 Graph Datenbank - Amsterdam | Niederlande Cassandra Benutzer | 18 | 0.6727954587015834 Graph Datenbank - Amsterdam | AmsterdamJS | 18 | 0.4432132175425046 (3 Zeilen)
Fazit
Ja, Sie können einen kompletten Empfehlungsdienst nur in Cypher erstellen. Es wäre allerdings schön, wenn Sie Trigger und eine Skriptumgebung hätten.
Unsere Ideen
Weitere Blogs




Contact