
Jeder, der diesen Blog regelmäßig liest, weiß, dass wir bei GoDataDriven Open Source lieben. Damit meinen wir normalerweise die Technologie, aber was ist mit den Daten? Kürzlich entdeckte ich Kaggle als eine großartige Quelle für unterhaltsame, offene Datensätze. Als Liebhaber von Brettspielen war ich froh, einen Datensatz zu finden, der von BoardGameGeek.com, einer Website für Brettspielbewertungen, exportiert wurde. Der Satz enthält durchschnittliche Bewertungen von Brettspielen. Er enthält auch einige Metadaten zu Brettspielen wie die Kategorie und das Erscheinungsjahr.
In diesem Beitrag werde ich meine Erfahrungen bei der Untersuchung des Datensatzes und meinen Versuch, den geheimen Bewertungsalgorithmus von BoardGameGeek zu entschlüsseln, mit Ihnen teilen. Ich habe die Analyse in R durchgeführt und werde den Code auf diesem Weg zeigen.
Häufige Probleme mit durchschnittlichen Bewertungen
Lassen Sie uns zunächst unsere Daten laden und die Spiele ohne Bayes'sche Durchschnittswerte ausschließen.
Bibliothek(tidyverse) Bibliothek(modelr) brettspiele_tbl read_csv ('./games.csv') %>% mutate (sum_ratings = users_rated * average_rating , has_average_rating = average_rating !=0, has_bayes_average_rating = bayes_average_rating != 0) %>% filter (has_average_rating ) mit_bayes_durchschnitt boardgames_tbl %>% filter(bayes_average_rating != 0)
Ein häufiges Problem bei Durchschnittsbewertungen ist, dass Artikel mit wenigen Stimmen dazu neigen, extreme Werte anzunehmen. Wir sehen das auch bei den Brettspielen. Extreme Wertungen finden sich auf der linken Seite des Spektrums. Mit mehr Stimmen verringert sich die Varianz der Punktzahl erheblich.
ggplot(brettspiele_tbl, aes(benutzer_bewertet, Durchschnitt_Rating)) + geom_punkt(alpha = 0.1) + ggtitle('[1] Spiele mit wenigen Stimmen haben in der Regel extreme Bewertungen.')
Ist das eine schlechte Sache? Höchstwahrscheinlich nutzen Sie eine Website wie BoardGameGeek, um eines von zwei Dingen zu tun:
- den Spielstand eines Spiels nachschlagen
- neue Spiele zu entdecken, indem Sie die Top
Extreme Wertungen sind hier nicht gerade hilfreich. Sie könnten ein Spiel mit einer fantastischen Wertung kaufen, nur um dann festzustellen, dass es nicht so interessant ist. Oder im Falle einer niedrigen Wertung verpassen Sie vielleicht eine großartige Gelegenheit!
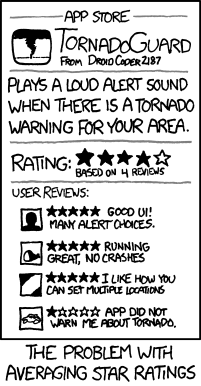
Vielleicht wollen Sie die besten Brettspiele entdecken, aber stattdessen finden Sie die Top 100 voller 10/10 Bewertungen. Wenn Sie viele solcher falsch-positiven Bewertungen erleben, werden Sie das Vertrauen in das Bewertungssystem verlieren. Um es klar zu sagen: Die meisten Spiele haben relativ wenige Stimmen und leiden unter diesem Phänomen.
Der Bayes'sche Durchschnitt
Glücklicherweise gibt es Möglichkeiten, damit umzugehen. Die Lösung von BoardGameGeek besteht darin, den Durchschnitt durch den Bayes'schen Durchschnitt zu ersetzen. In der Bayes'schen Statistik beginnen wir mit einem Prior, der unsere a priori Annahmen darstellt. Wenn wir Beweise erhalten, können wir diesen Prior aktualisieren und einen so genannten Posterior berechnen, der unsere aktualisierte Überzeugung widerspiegelt.
Übertragen auf Brettspiele bedeutet das: Wenn wir ein unbewertetes Spiel haben, können wir genauso gut annehmen, dass es durchschnittlich ist. Wenn nicht, müssen uns die Bewertungen vom Gegenteil überzeugen. Wie wir weiter unten sehen werden, werden dadurch sicherlich Ausreißer vermieden!
mit_bayes_durchschnittlich_lang with_bayes_average %>%
gather(metric, rating, average_rating, bayes_average_rating)
ggplot (with_bayes_average_long , aes (users_rated , rating )) +
geom_point ( alpha = 0.1) +
facet_grid (. ~ metric ) +
ggtitle ('[2] Der Bayes'sche Durchschnitt beseitigt Ausreißer.')
Ein weiteres häufiges Problem ist, dass relativ neue Artikel tendenziell höhere Bewertungen haben. Wir können deutlich sehen, wie die durchschnittliche Bewertung von Brettspielen im Laufe der Zeit gestiegen ist.
agg with_bayes_average %>%
group_by (yearpublished ) %>%
summarise (mean_average = mean(average_rating ),
mean_nvotes = mean(users_rated ),
n = n ()) %>%
filter (n > 10, Jahrveröffentlicht != 0)
ggplot (agg , aes ( yearpublished , mean_average , size = mean_nvotes )) +
geom_point () +
geom_smooth () +
ggtitle ('[3] Kürzlich veröffentlichte Spiele haben im Durchschnitt höhere Bewertungen.')
Auch wenn es möglich ist, dass die Spielemacher endlich verstehen, wie man richtige Spiele macht, ist es wahrscheinlicher, dass etwas anderes im Spiel ist. Es könnte sein, dass Enthusiasten die ersten sind, die ein Spiel kaufen. Vielleicht vergeben frühe Anwender generell mehr Stimmen. Jedenfalls ist es schön zu sehen, dass der Bayes'sche Durchschnitt auch diesen Effekt etwas abmildert.
agg with_bayes_average %>%
group_by (yearpublished ) %>%
summarise (mean_average = mean(average_rating ),
mean_bayes_average = mean(bayes_average_rating ),
n = n ()) %>%
filter (n > 10, Erscheinungsjahr > 1960) %>%
gather (Typ , mittlerer_Durchschnitt , mittlerer_Durchschnitt , mittlerer_bayes_Durchschnitt)
ggplot (agg , aes (yearpublished , mean_average , weight =n , color = type )) +
geom_point (alpha = 0.3) +
geom_smooth () +
ggtitle ('[4] Der Bayes'sche Durchschnitt mildert den Rezenzeffekt.')
Aber wie kommen wir von der durchschnittlichen Bewertung zu ihrem Bayes'schen Gegenstück? Ein kurzer Blick auf das Diagramm zeigt, dass diese beiden Werte recht unterschiedlich sind.
mit_bayes_durchschnitt boardgames_tbl %>% filter(bayes_average_rating != 0)
ggplot (with_bayes_average , aes (bayes_average_rating , average_rating )) +
geom_point (alpha = 0.1) +
ggtitle ('[5] Der normale Durchschnitt und der Bayes'sche Durchschnitt sind sich nicht sehr ähnlich. )
Es stellt sich heraus, dass der Bayes'sche Durchschnitt berechnet werden kann, nachdem alle Stimmen gesammelt wurden. Es ist so, als ob man (C) Dummy-Wähler hinzufügt, die im Durchschnitt eine (m) Punktzahl wählen.
Aber was sind die Werte von (C) und (m)? In [2] haben wir gesehen, dass der Bayes'sche Durchschnitt von Spielen mit wenigen Stimmen im Bereich von 5-7 Punkten zu liegen scheint. Lassen Sie uns alle Durchschnittswerte in zwei Gruppen einteilen, je nachdem, ob ihr normaler Durchschnittswert größer als 5,5 ist. Es stellt sich heraus, dass die Spitzenwerte dieser beiden Gruppen leicht links und rechts von der 5,5 Bayes-Punktzahl liegen. Da die meisten Spiele nur wenige Stimmen haben, liegt der Prior wahrscheinlich nahe und zwischen diesen Spitzenwerten. Dies legt 5,5 als Ausgangspunkt nahe, was auch Sinn macht: a priori ist es am wahrscheinlichsten, dass ein Spiel durchschnittlich ist. Außerdem könnten wir die Skala zentrieren und durchschnittliche Spiele in der Mitte platzieren.
Bewertungen with_bayes_average %>% mutate(above_average = average_rating >= 5.5)
ggplot () +
geom_density (aes(bayes_average_rating, y = ..scaled..., fill =above_average ), alpha = 0.3, data = ratings ) +
ggtitle ('[6] Die vorherige Bewertung scheint bei 5,5 zu liegen.' )
Reverse Engineering des Algorithmus
Wenn Sie es immer noch nicht glauben (m = 5,5), können Sie immer noch in der BoardGameGeek FAQ nachsehen:
Um zu verhindern, dass Spiele mit relativ wenigen Stimmen an die Spitze der BGG-Rangliste klettern, werden künstliche "Dummy"-Stimmen zu den Benutzerbewertungen hinzugefügt. Man geht derzeit davon aus, dass diese 100 Stimmen dem mittleren Bereich der Bewertungsskala entsprechen: 5.5, aber der tatsächliche Algorithmus wird geheim gehalten, um Manipulationen zu vermeiden. Durch die Hinzufügung dieser Dummy-Stimmen werden die BGG-Bewertungen in Richtung des mittleren Bereichs gezogen. Bei Spielen mit einer großen Anzahl von Stimmen wird sich die BGG-Bewertung nur geringfügig von der Durchschnittsbewertung unterscheiden, aber bei Spielen mit relativ wenigen Nutzerbewertungen wird sich die BGG-Bewertung deutlich in Richtung 5,5 bewegen.
Sie besagt, dass (m = 5,5) und (C = 100). Seltsamerweise stimmt dies nicht mit den Daten überein.
m = 5.5 C = 100 faq_preds with_bayes_average %>% mutate (pred = (C*m + users_rated * average_rating ) / (C + users_rated ), resid = pred - bayes_durchschnitts_rating ) ggplot () + geom_point (aes( pred , bayes_average_rating ), data =faq_preds , alpha =0.1) + ggtitle("[7] Die FAQ-Formel stimmt nicht mit den Daten überein.")
Wenn Sie genau lesen, steht in den FAQ, dass die echte Sache etwas anders ist.
...aber der eigentliche Algorithmus wird geheim gehalten, um Manipulationen zu vermeiden.
Klingt nach einer Herausforderung! Wir können eine Kostenfunktion schreiben, die den Bayes'schen Durchschnitt für die Parameter (C) und (m) berechnet und den mittleren absoluten Fehler zurückgibt.
f = Funktion(C, m){ mit_bayes_durchschnitt %>% mutieren(vor = (C*m + benutzer_bewertet * Durchschnitt_Rating) / (C + benutzer_bewertet), Rückstand = vor - bayes_durchschnitts_rating) %>% zusammenfassen(mae = Rückstand %>% abs %>% Durchschnitt) %>% .[['mae']] }
Bei der Erkundung des Suchraums stellen wir fest, dass die beste Anpassung bei 750 Dummy-Stimmen zu liegen scheint - im Gegensatz zu den vorgeschlagenen (100) Dummy-Stimmen.
C_Intervall seq(1,2000, 10)
m_interval seq(4, 7, 0.1)
input_space = expand.grid ( C = C_interval , m = m_interval )
space = input_space %>% rowwise %>% mutate ( y = f ( C , m ))
ggplot ( space , aes (C , m , fill =y )) + Wir können den genauen Wert mit einer netten kleinen Funktion namens optimise finden. Bei einer Funktion, die eine Metrik und einen zu untersuchenden Parameterraum zurückgibt, gibt optimise die Parameter zurück, für die der Fehler am geringsten ist.
Optimieren Sie(f, Intervall= c(1, 2000), m=5.5)
$Minimum [1] 725.6158 $objektiv [1] 0.01206334
Vielleicht liegt die tatsächliche Zahl der Scheinstimmen eher in der Größenordnung von 725. Zumindest passt das viel besser zu unseren Daten!
m = 5.5 C = 725 optim_preds with_bayes_average %>% mutate (pred = (C *m + users_rated * average_rating) / ( C + users_rated ), resid = pred - bayes_durchschnitts_rating ) ggplot () + geom_point (aes (pred , bayes_average_rating ), data =optim_preds , alpha =0.1) + ggtitle('[9] Die Annahme von 725 Dummy-Stimmen führt zu einer besseren Anpassung.)
Fazit
Die vorhergesagten Werte sind keine exakte Rekonstruktion der Bayes-Werte, so dass ich davon ausgehe, dass BoardGameGeek noch einen anderen Faktor einbezieht. Nichtsdestotrotz scheint es, dass eine stärkere Glättung vorgenommen wird als angenommen. Zusammenfassend lässt sich sagen, dass der Bayes'sche Durchschnitt sicherlich eine elegante additive Glättung ist.
Verfasst von
Jelte Hoekstra
Unsere Ideen
Weitere Blogs




Contact