Was ist Apache Iceberg?
Apache Iceberg ist ein offenes Tabellenformat für große Analysedatensätze, das mit gängigen Big-Data-Verarbeitungsmaschinen wie Apache Spark, Trino, PrestoDB, Flink und Hive verwendet werden kann. Mehr über Apache Iceberg und wie Sie damit in einer Batch-Job-Umgebung arbeiten können, erfahren Sie in unserem Blogbeitrag
Es ist erwähnenswert, dass Apache Iceberg mit jedem Cloud-Anbieter oder jeder Inhouse-Lösung verwendet werden kann, die Apache Hive Metastore und Blob-Storage unterstützt.
Kafka Connect Apache Iceberg Senke
Bei GetInData haben wir eine Apache Iceberg-Senke erstellt, die auf einer Kafka Connect-Instanz eingesetzt werden kann. Sie finden das Repository und das freigegebene Paket auf unserem GitHub.
Die Apache Iceberg-Senke wurde auf der Grundlage von memiiso/debezium-server-iceberg erstellt, das für die eigenständige Verwendung mit dem Debezium Server erstellt wurde.
Das Datenformat, das von Apache Iceberg verwendet wird, muss tabellenähnliche Daten und deren Schema darstellen. Daher haben wir ein von Debezium erstelltes Format für die Erfassung von Änderungsdaten verwendet. Mehr über dieses Format können Sie hier lesen.
Beispiel für die Erfassung von Änderungsdaten
Versuchen wir, unsere Senke zu verwenden, um die PostgreSQL-Datenbank mit Debezium zu replizieren, um alle Änderungen zu erfassen und in die Apache Iceberg-Tabelle zu streamen.
Wir werden eine Kafka Connect-Instanz betreiben, auf der wir die Debezium-Quelle und unsere Apache Iceberg-Senke bereitstellen werden. Ein Kafka-Thema wird für die Kommunikation zwischen den beiden verwendet und die Senke schreibt die Daten in einen S3-Bucket und die Metadaten in Amazon Glue. Später werden wir Amazon Athena verwenden, um die Daten zu lesen und anzuzeigen.
Erster Schritt: Kafka Connect ausführen
Authentifizieren Sie sich zunächst und speichern Sie die AWS-Anmeldeinformationen in einer Datei, zum Beispiel ~/.aws/config
[default]
region = eu-west-1
aws_access_key_id=\*\**
aws_secret_access_key=\*\**Download sink von der Seite Release, zum Beispiel Pfad~/Downloads/kafka-connect-iceberg-sink-0.1.3-shaded.jar
Für Kafka Connect verwenden wir ein Docker-Image von Debezium, das mit den Debezium-Quellpaketen geliefert wird. Wir mounten unsere Apache Iceberg-Senke in das Kafka Connect Plugin-Verzeichnis und fügen unsere AWS-Anmeldedatei hinzu.
docker run -it --name connect --net=host -p 8083:8083 \
-e GROUP_ID=1 \
-e CONFIG_STORAGE_TOPIC=my-connect-configs \
-e OFFSET_STORAGE_TOPIC=my-connect-offsets \
-e BOOTSTRAP_SERVERS=localhost:9092 \
-e CONNECT_TOPIC_CREATION_ENABLE=true \
-v ~/.aws/config:/kafka/.aws/config \
-v ~/Downloads/kafka-connect-iceberg-sink-0.1.3-shaded.jar:/kafka/connect/kafka-connect-iceberg-sink-0.1.3-shaded.jar \
debezium/connectZweiter Schritt: Daten aus der PostgreSQL-Quelle lesen
Eine der Möglichkeiten für Debezium, Daten aus PostgreSQL zu lesen, besteht darin, als Datenbankreplikat zu fungieren. Damit wal_level auf logical konfigurieren.
Für dieses Beispiel werden wir PostgreSQL auf Docker ausführen.
docker run -d --name postgres -e POSTGRES_PASSWORD=postgres \
-p 5432:5432 postgres -c wal_level=logicalWir benötigen außerdem eine Kafka-Instanz. Wie Sie diese auf Ihrem Rechner ausführen, erfahren Sie in: Grundlegende Einzelknoten-Bereitstellung auf Docker
Wenn wir die automatische Erstellung von Themen nicht aktiviert haben, müssen wir ein Thema erstellen, das für die Kommunikation zwischen der Debezium-Quelle und unserer Apache Iceberg-Senke verwendet wird. Der Themenname setzt sich aus einem logischen Namen, den wir der Debezium-Quelle zuweisen, dem Namen des Datenbankschemas und dem Tabellennamen zusammen.
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic postgres.public.dbz_test --partitions 1 --replication-factor 1Jetzt müssen wir die Quelle auf Kafka Connect bereitstellen. Dies können wir mit einer POST-Anfrage tun, die die Konfiguration der Quelle enthält. Mehr über die Konfiguration können Sie hier lesen.
curl -X POST -H "Content-Type: application/json" \
-d '{
"name": "postgres-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname" : "postgres",
"database.server.name": "postgres",
"slot.name": "debezium",
"plugin.name": "pgoutput",
"table.include.list": "public.dbz_test"
}
}' \
<http://localhost:8083/connectors>Dritter Schritt: Apache Iceberg Sink
Für unsere Apache Iceberg Senke benötigen wir einen Bucket in S3, zum Beispiel gid-streaminglabs-eu-west-1 und eine Datenbank in Amazon Glue, zum Beispiel gid_streaminglabs_eu_west_1_dbz
Da wir die Kafka Connect-Instanz einschließlich unserer AWS-Anmeldeinformationen und des Pakets mit unserer Senke bereit haben, müssen wir sie nur noch bereitstellen. Ähnlich wie bei PostgreSQLsourcewerden wir dies mit einer POST-Anfrage tun. Mehr über die Konfiguration können Sie hier lesen.
curl -X POST -H "Content-Type: application/json" \
-d '{
"name": "iceberg-sink",
"config": {
"connector.class": "com.getindata.kafka.connect.iceberg.sink.IcebergSink",
"topics": "postgres.public.dbz_test",
"upsert": true,
"upsert.keep-deletes": true,
"table.auto-create": true,
"table.write-format": "parquet",
"table.namespace": "gid_streaminglabs_eu_west_1_dbz",
"table.prefix": "debeziumcdc_",
"iceberg.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.warehouse": "s3a://gid-streaminglabs-eu-west-1/dbz_iceberg/gl_test",
"iceberg.fs.defaultFS": "s3a://gid-streaminglabs-eu-west-1/dbz_iceberg/gl_test",
"iceberg.com.amazonaws.services.s3.enableV4": true,
"iceberg.com.amazonaws.services.s3a.enableV4": true,
"iceberg.fs.s3a.aws.credentials.provider": "com.amazonaws.auth.DefaultAWSCredentialsProviderChain",
"iceberg.fs.s3a.path.style.access": true,
"iceberg.fs.s3a.impl": "org.apache.hadoop.fs.s3a.S3AFileSystem"
}
}' \
<http://localhost:8083/connectors>Vierter Schritt: Überprüfen von
Jetzt können wir einen psql-Client öffnen und einige Tabellen und Daten erstellen
psql -U postgres -h localhost
create table dbz_test (timestamp bigint, id int PRIMARY KEY, value int);
insert into dbz_test values(1, 1, 1);
insert into dbz_test values(2, 2, 2);
alter table dbz_test add test varchar(30);
insert into dbz_test values(3, 3, 3, 'aaa');
delete from dbz_test where id = 1;
update dbz_test set value = 1 where id = 2;Gehen Sie dann zu Amazon Athena und führen Sie die Abfrage aus:
select * from debeziumcdc_postgres_public_dbz_test order by timestamp desc;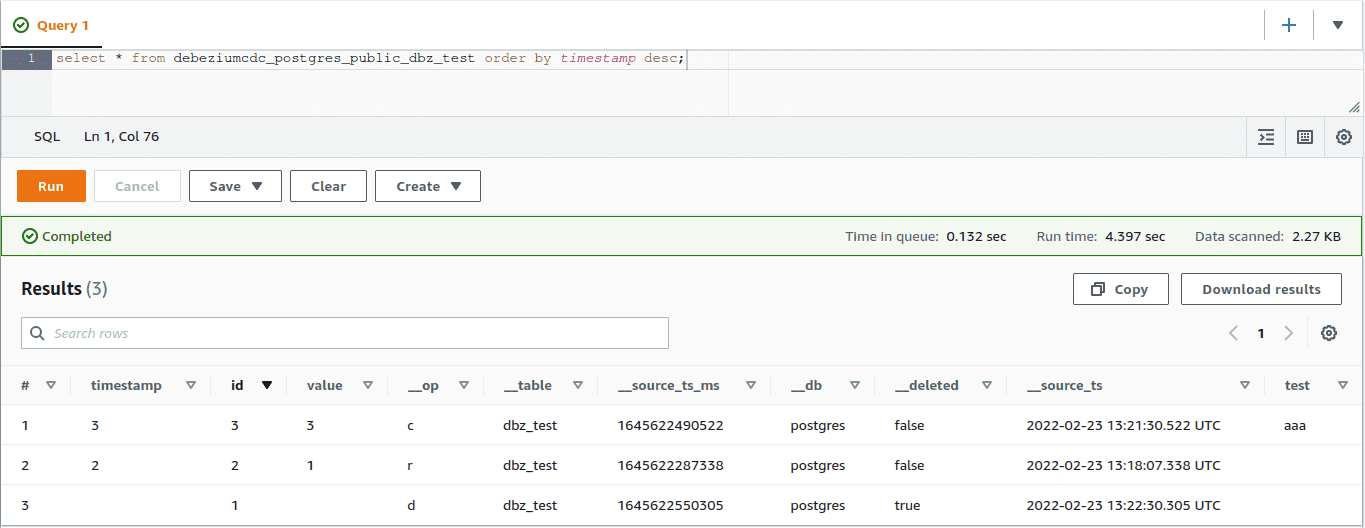
Apache Iceberg: Beispiel für Echtzeit-Ingestion mit Data Online Generator
In unserem Blogbeitrag: "Online-Datengenerierung für die Verarbeitung von Ereignisströmen" haben wir ein in GetInData entwickeltes Tool zur Datengenerierung auf der Grundlage von Zustandsautomaten vorgestellt. Heute werden wir es verwenden, um simulierte Echtzeitdaten zu erzeugen und sie in Apache Iceberg-Tabellen zu streamen.
Wir werden genau dasselbe Szenario verwenden, das in diesem Blogbeitrag beschrieben wird. Zur Erinnerung: Wir betrachten das simulierte Verhalten eines Benutzers, der mit einer Bankanwendung interagiert, Einkommen erhält, Geld ausgibt und einen Kredit aufnimmt. Als Ausgabe erhalten wir einen Strom von Benutzerklicks in der Anwendung, die durchgeführte Transaktion, den aktuellen Kontostand und Informationen über den Kredit, falls ein solcher aufgenommen wurde.
Erster Schritt: Datenformat
Wie bereits erwähnt, verbraucht Kafka Connect Apache Iceberg Sink Daten in dem von Debezium verwendeten Format, so dass wir unsere Daten in dieses Format umwandeln müssen. Das Format enthält sowohl den Vorher- als auch den Nachher-Zustand einer Änderung, aber unsere Senke ist nur am Nachher-Zustand interessiert, so dass wir den Vorher-Teil auslassen werden.
Eines der Ereignisse in unserem Beispiel ist ein aktueller Schnappschuss des Benutzersaldos, der einen user_id, der auch ein Primärschlüssel ist, die aktuelle balance und timestamp der letzten Änderung enthält.
Zunächst müssen wir das Ereignisformat in Debezium ändern. Wir müssen Struktur, Werte und Metadaten definieren, die die Datenbank, den Tabellennamen und die Art der Operation enthalten.
def balance_value_function(timestamp: int, subject: User, transition: Transition) -> str:
return json.dumps({
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int64",
"optional": True,
"field": "timestamp"
},
{
"type": "string",
"optional": False,
"field": "user_id"
},
{
"type": "int64",
"optional": True,
"field": "balance"
}
],
"optional": True,
"name": "doge.balance.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "int64",
"optional": False,
"field": "ts_ms"
},
{
"type": "string",
"optional": False,
"field": "db"
},
{
"type": "string",
"optional": False,
"field": "table"
}
],
"optional": False,
"name": "io.debezium.connector.postgresql.Source",
"field": "source"
},
{
"type": "string",
"optional": False,
"field": "op"
}
],
"optional": False,
"name": "doge.balance.Envelope"
},
"payload": {
"before": None,
"after": {
"timestamp": timestamp,
"user_id": str(subject.user_id),
"balance": subject.balance
},
"source": {
"ts_ms": timestamp,
"db": "doge",
"table": "balance"
},
"op": "c"
}
})Um den Primärschlüssel in der Apache Iceberg-Tabelle zu definieren, müssen wir ihn auch als Teil des Kafka-Ereignisschlüssels senden. Bitte beachten Sie, dass die Optionalität dieses Feldes auf False eingestellt ist und das Feld, das als Schlüssel verwendet wird, auch als Teil des Wertes vorhanden sein muss.
def user_id_key_function(subject: User, transition: Transition) -> str:
return json.dumps({
"schema": {
"type": "struct",
"fields": [
{
"type": "string",
"optional": False,
"field": "user_id"
}
],
"optional": False,
"name": "user_id.Key"
},
"payload": {
"user_id": str(subject.user_id)
}
})Andere Ereignisse werden auf ähnliche Weise behandelt, aber wir stellen keinen Primärschlüssel zur Verfügung. Sehen Sie sich das vollständige Beispiel hier an.
Nächster Schritt: Daten Online Generator ausführen
Wenn wir die automatische Erstellung von Themen nicht verwenden, müssen wir sie zuerst definieren und erstellen.
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic clickstream --partitions 1 --replication-factor 1
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic trx --partitions 1 --replication-factor 1
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic balance --partitions 1 --replication-factor 1
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic loan --partitions 1 --replication-factor 1
Als nächstes müssen wir unsere Senke mit einer POST-Anfrage konfigurieren
curl -X POST -H "Content-Type: application/json" \
-d '{
"name": "doge-iceberg-sink",
"config": {
"connector.class": "com.getindata.kafka.connect.iceberg.sink.IcebergSink",
"topics": "clickstream,trx,balance,loan",
"upsert": false,
"upsert.keep-deletes": true,
"table.auto-create": true,
"table.write-format": "parquet",
"table.namespace": "gid_streaminglabs_eu_west_1_dbz",
"table.prefix": "",
"iceberg.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.warehouse": "s3a://gid-streaminglabs-eu-west-1/dbz_iceberg/gl_test",
"iceberg.fs.defaultFS": "s3a://gid-streaminglabs-eu-west-1/dbz_iceberg/gl_test",
"iceberg.com.amazonaws.services.s3.enableV4": true,
"iceberg.com.amazonaws.services.s3a.enableV4": true,
"iceberg.fs.s3a.aws.credentials.provider": "com.amazonaws.auth.DefaultAWSCredentialsProviderChain",
"iceberg.fs.s3a.path.style.access": true,
"iceberg.fs.s3a.impl": "org.apache.hadoop.fs.s3a.S3AFileSystem"
}
}' \
<http://localhost:8083/connectors>Jetzt müssen Sie nur noch den Data Online Generator ausführen
python3 doge_demo_iceberg.pyLetzter Schritt: Verifizierung
Wie zuvor können wir Amazon Athena öffnen und den Inhalt der Apache Iceberg-Tabellen anzeigen.
select * from "balance" order by timestamp;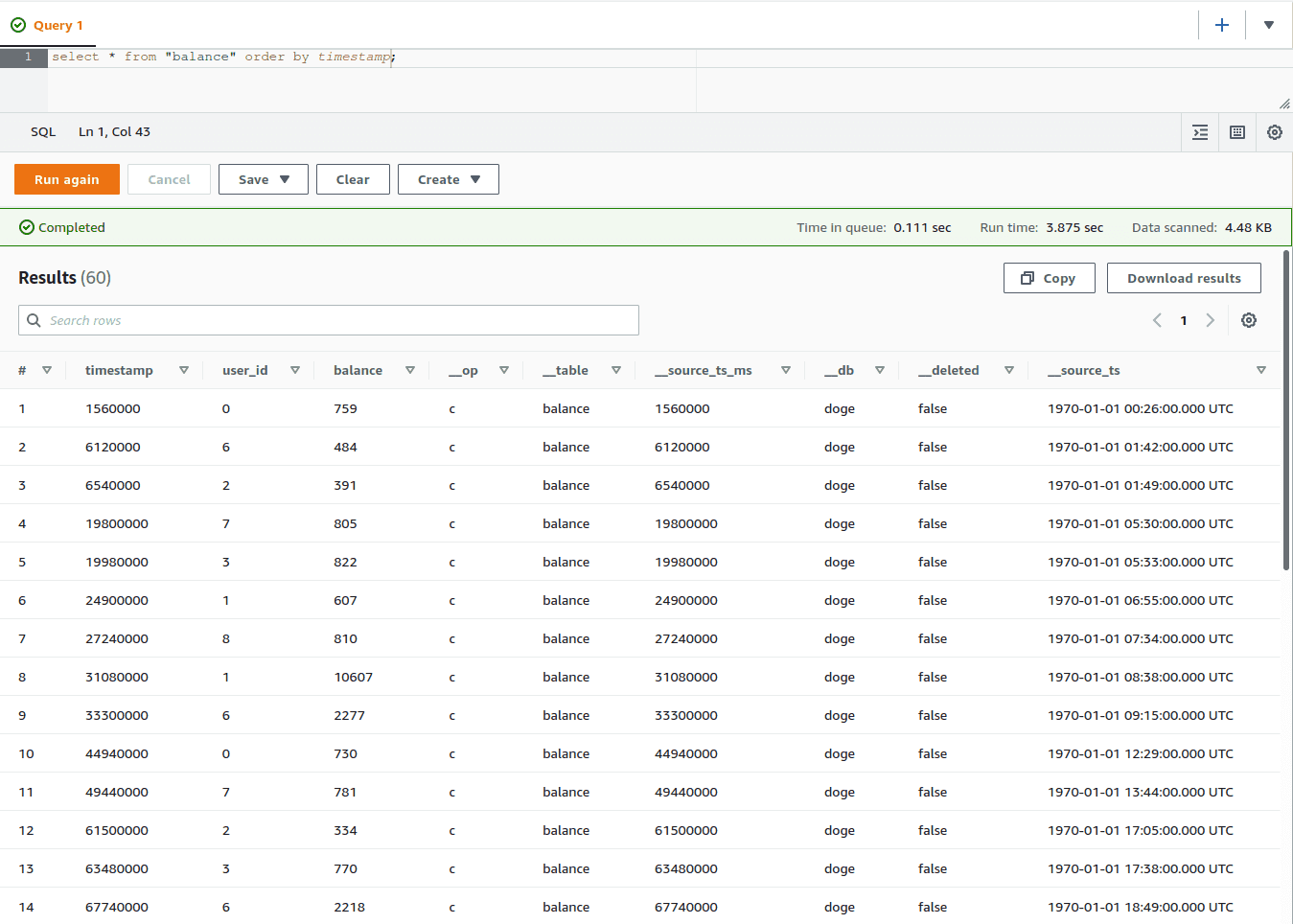
Sie haben vielleicht bemerkt, dass wir mehrere Einträge für dieselbe user_id haben, die als Schlüssel definiert wurde. Das liegt daran, dass wir in diesem Beispiel die Option upsert auf false gesetzt haben, wodurch unsere Senke neue Zeilen hinzufügt, anstatt wie im vorherigen Beispiel bestehende Zeilen zu ersetzen.
Fähigkeiten und Grenzen
DDL - Datendefinitionssprache
Die Erstellung neuer Tabellen und deren Erweiterung um neue Spalten wird unterstützt. Apache Iceberg Sink führt keine Operationen durch, die sich auf mehrere Zeilen auswirken würden, so dass beim Löschen von Tabellen oder Spalten keine Daten tatsächlich entfernt werden. Dies kann ein Problem darstellen, wenn eine Spalte gelöscht und dann mit einem anderen Typ neu angelegt wird. Dieser Vorgang kann die Senke zum Absturz bringen, da sie versucht, neue Daten in eine vorhandene Spalte mit einem anderen Datentyp zu schreiben.
Ein ähnliches Problem besteht bei der Änderung der Optionalität einer Spalte. Wenn sie nicht als erforderlich definiert wurde, als die Tabelle zum ersten Mal erstellt wurde, prüft sink nicht, ob solche Beschränkungen eingeführt werden können und ignoriert sie.
DML - Sprache zur Datenmanipulation
Zeilen können nur dann aktualisiert oder entfernt werden, wenn der Primärschlüssel definiert ist. Im Falle einer Löschung ist das Verhalten von sink auch von der Option upsert.keep-deletes abhängig. Wenn diese Option auf true gesetzt ist, hinterlässt Apache Iceberg sink einen Grabstein in Form einer Zeile, die nur einen Primärschlüsselwert enthält und __deleted flach auf true gesetzt ist. Wenn die Option auf false gesetzt ist, wird die Zeile vollständig entfernt.
Unterstützung der Apache Iceberg Partitionierung
Derzeit erfolgt die Partitionierung automatisch auf der Grundlage der Ereigniszeit. Die Partitionierung funktioniert nur, wenn die Senke im Modus "Nur Anhängen" konfiguriert ist:
"upsert": false,Die Partitionen werden nach Tagen aufgeteilt und mit einem Zeitstempel aus dem Feld payload.source.ts_ms versehen.
Fazit
Wir wissen, wie zeitaufwändig es sein kann, spezielle Lösungen für die Datenübertragung in die Iceberg-Tabelle zu schreiben. Es gibt eine ganze Reihe verschiedener Tools, die diese Aktion in
Verfasst von
Grzegorz Liter
Unsere Ideen
Weitere Blogs




Contact