Blog
Echtzeit-Analytik: Architektur, Technologien und Beispielimplementierung im E-Commerce

Echtzeit-Analysen sind alle Prozesse des Sammelns, Umwandelns, Anreicherns, Bereinigens und Analysierens von Daten, um sofortige Einblicke und umsetzbare Informationen zu liefern. Sie ermöglicht es dem Benutzer, auf Daten zuzugreifen und Dashboards zu erstellen, die in Echtzeit aktualisiert werden. Das bedeutet, dass alle Änderungen sofort angezeigt werden, nicht täglich, nicht wöchentlich, sondern "jetzt", so dass der Benutzer datengesteuerte Entscheidungen treffen kann. In diesem Blogpost werden wir das Potenzial und die Anwendungsmöglichkeiten von Real-time Analytics und seine Vorteile gegenüber der Stapelverarbeitung diskutieren. Wir werden in die Architektur von Real-time Analytics eintauchen, damit Sie wissen, wie sie funktioniert und welche Mechanismen sie antreiben. Sie werden auch etwas über die Technologien und die Einschränkungen und Alternativen von Real-time Analytics erfahren, damit Sie entscheiden können, ob dies die beste Lösung für Ihr Unternehmen ist. Wir werden uns auch ein reales Beispiel aus der E-Commerce-Branche ansehen.
Einführung in die Echtzeit-Analyse
Traditionell wurden alle Analyseaufgaben als Batch-Jobs erledigt, die in der Regel stündlich oder sogar nur täglich ausgeführt wurden. Dieser Ansatz ist seit Jahren üblich und recht einfach zu implementieren und zu pflegen. Es ist viel einfacher, mit Batches Stabilität und Konsistenz zu erreichen. Doch in der heutigen schnelllebigen und datengesteuerten Welt ist ein traditioneller Ansatz ist oft nicht genug. Viele Branchen benötigen und verlassen sich auf schnelle, nahezu in Echtzeit erfolgende Berechnungen von Metriken, automatisierte Entscheidungsfindung oder andere Reaktionen auf Ereignisse. Dies ist besonders wichtig bei der kundenorientierten Analytik.
Kundenorientierte Analytik bringt BI-Funktionen direkt zu den Endbenutzern, oft innerhalb bereits bestehender oder benutzerdefinierter Anwendungen. Sie bietet Self-Service-Möglichkeiten, bei denen die Benutzer selbst Erkenntnisse gewinnen können, ohne komplexe Abfragen erstellen zu müssen. Eines der wichtigsten Merkmale der benutzerorientierten Analyse ist die Notwendigkeit, viele gleichzeitige Abfragen zu bearbeiten.
Das Hauptmerkmal der Echtzeitanalyse ist die Fähigkeit, Daten nahezu in Echtzeit zu analysieren. Dies ermöglicht es Unternehmen, zeitnahe Entscheidungen zu treffen, schnell auf veränderte Bedingungen zu reagieren und so einen Wettbewerbsvorteil zu erlangen. Dies kann für die folgenden Branchen sehr vorteilhaft oder sogar das A und O sein:
Finanzhandel - ermöglicht schnelle Entscheidungen zum Kauf oder Verkauf auf der Grundlage von Marktschwankungen,
E-Commerce - für das Anbieten von personalisierten Empfehlungen, die Anpassung von Preisstrategien und die effiziente Verwaltung von Beständen,
Internet der Dinge - für die Analyse riesiger Datenmengen, um sinnvolle Erkenntnisse zu gewinnen
Cybersicherheit - zur Identifizierung ungewöhnlicher Muster und zur Erkennung potenzieller Sicherheitsbedrohungen
Telekommunikation - zur Identifizierung von Problemen und zur Optimierung der Ressourcenzuweisung.
Diese Liste enthält nur ausgewählte Beispiele, aber in der Praxis gibt es noch viele weitere Anwendungsmöglichkeiten für diese Technologie.
Echtzeit-Analyse-Architektur
Das folgende Diagramm stellt die Architektur dar, die wir sehr oft sehen und unseren Kunden anbieten: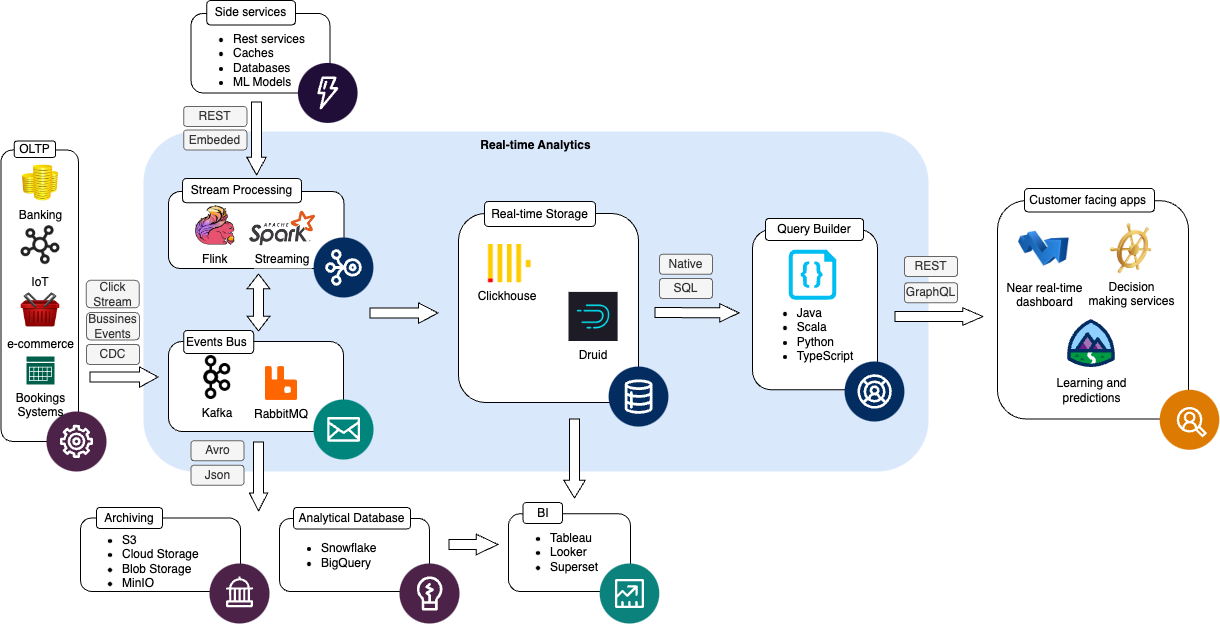
Durch die Beschreibung des Datenflusses im Kern des Systems können wir die drei Hauptteile unterscheiden , die an der Echtzeit-Analyse beteiligt sind:
Stream-Verarbeitung
Hier geht es darum, wie Daten aufbereitet werden, damit sie für Analyseabfragen bereit sind. Dazu gehören Ingestion, Bereinigung, Anreicherung und Transformation zur Erstellung leistungsorientierter Datenmodelle, die es ermöglichen, die erforderliche Leistung abzufragen. Diese Komponente arbeitet eng mit Messaging-Systemen zusammen, die für die Kommunikation zwischen anderen Komponenten verwendet werden, und ist auf diese angewiesen.
Speicherung in Echtzeit
Das Herzstück des Systems ist die analytische Datenbank. Sie ist für die Verarbeitung riesiger Datenmengen verantwortlich, um die notwendigen Metriken mit möglichst geringer Latenzzeit zu aggregieren und zu berechnen.
Query Builder
Eine leichtgewichtige Schicht, die ein Proxy für den Zugriff auf Daten ist. Sie wird normalerweise als Microservice oder Bibliothek erstellt, die für die Erstellung optimaler Abfragen in SQL oder einer anderen nativen Sprache zuständig ist. Meistens ist es notwendig, klare und konsistente APIs für externe benutzerdefinierte Anwendungen bereitzustellen, um die Daten optimal zu erreichen.
Datenquellen
In der Regel handelt es sich dabei um OLTP-Systeme, die für die Abwicklung von Kundengeschäften zuständig sind und in engem Zusammenhang mit der Branche stehen, für die die Echtzeit-Analyse vorbereitet wird. Die an das System gelieferten Daten können eine Vielzahl von Zwecken und Formaten haben und über verschiedene Protokolle geliefert werden. Die gängigsten Typen sind:
- Clickstream - kommt entweder direkt vom Browser des Benutzers durch die Darstellung von versteckten Pixeln oder JavaScript-Code oder indirekt durch die Erfassung von Ereignissen im Kundensystem.
- Geschäftsereignisse, die in der Regel eine Reaktion des Systems auf Geschäftsaktionen sind, die von Benutzern ausgeführt werden, und direkte Quellen sind die Kundenanwendungen, die sie verarbeiten
- Die Änderungsdatenerfassung liest alle Änderungen an den in einer Datenbank gespeicherten Daten. Manchmal ist dies der einzig sinnvolle Weg in älteren und bestehenden Systemen, die auch nicht ereignisgesteuert konzipiert sind.
Archivierung und Analysedatenbanken
Da ein Echtzeit-Analysesystem-Server den Zweck hat, schnell Informationen über aktuelle Kennzahlen und die Unternehmensleistung zu liefern, können einige Bereiche von denselben gesammelten und aufbereiteten Daten profitieren. Ein Beispiel dafür ist das Training von Machine Learning-Modellen, die Erstellung von Offline-Berichten oder die Analyse von Rohdaten über die gesamte Historie. Diese Verarbeitung erfordert viele Ressourcen und sollte nicht die gleichen Ressourcen wie die Echtzeit-Analysen verwenden, die teurer sind und 24x7 zur Verfügung stehen. Außerdem kann eine starke Belastung des Echtzeitspeichers die normale Nutzung stören. Um dieses Problem zu lösen, empfehlen wir dringend die Integration mit einem anderen System, das für die Verarbeitung von Daten in Stapeln besser geeignet ist. Auf diese Weise können wir die Kosten des gesamten Systems senken und seine Stabilität erhöhen, während wir gleichzeitig viel mehr Funktionalität bieten.
Nebenleistungen
Die Datenaufbereitung erfordert in der Regel einen Anreicherungsprozess oder eine Transformation auf der Grundlage von externen Metadaten, die aus anderen Systemen stammen. Dabei kann es sich um Anwendungen, Caches, Datenbanken oder Modelle für maschinelles Lernen handeln. Mehr über das Training und die Bereitstellung von Modellen erfahren Sie in unseren anderen Blogbeiträgen.
Business Intelligence
BI-Tools können sich direkt mit dem Echtzeitspeicher verbinden und schnelle Berichtsberechnungen ohne Zwischencaches durchführen.
Technologien
Flink
Da wir die meisten der bekannten Streaming-Frameworks unterstützen können, empfehlen wir dringend die Verwendung von Apache Flink. Flink ist ein leistungsstarkes Framework für die verteilte Datenverarbeitung. Es verfügt über eine integrierte erweiterte Unterstützung für die Ereigniszeitverarbeitung, die für die Verarbeitung von Ereignissen in ungeordneter Reihenfolge in Streaming-Daten unerlässlich ist. Dadurch kann Flink mit realen Szenarien umgehen, in denen Ereignisse nicht in der Reihenfolge eintreffen, in der sie auftreten.
Flink wurde mit Blick auf eine Verarbeitung mit geringer Latenz entwickelt und eignet sich daher für Anwendungsfälle, die Echtzeit- oder echtzeitnahe Analysen erfordern. Dies steht im Gegensatz zu dem sehr beliebten Apache Spark, das Micro-Batching verwendet und eine gewisse Latenz aufweist.
Flink bietet native Unterstützung für zustandsabhängige Verarbeitung, so dass Sie den Zustand über Ereignisse und Zeit hinweg beibehalten und aktualisieren können. Dies ist besonders wichtig für Anwendungen, bei denen der Kontext über einen längeren Zeitraum aufrechterhalten werden muss , wie z.B. beim Session Windowing.
Flink bietet eine dynamische Skalierbarkeit, die für die Bewältigung unterschiedlicher Arbeitslasten und die Anpassung an Änderungen des Datenvolumens nützlich sein kann.
Flink ist sehr ausgereift und hat sich in vielen Produktionsumgebungen bestens bewährt. Auch wenn andere beliebte Frameworks ähnliche Funktionen unterstützen, wird die Implementierung von Flink oft als fortschrittlicher angesehen.
Kafka
Die Streaming-Verarbeitung ist ohne einen schnellen und zuverlässigen Ereignisbus kaum vorstellbar. Unsere Architektur und Komponenten können mit den meisten gängigen Messaging-Systemen zusammenarbeiten, aber ähnlich wie bei Flink empfehlen wir unseren Kunden ein System vor anderen. Unsere Wahl fällt auf Apache Kafka, ein verteiltes System mit starken Haltbarkeitsgarantien. Es hat keine Konkurrenten, was den Durchsatz und die einfache Skalierbarkeit in Kombination mit der Reife und Produktionsreife angeht.
Klickhaus oder Druide
Als wir diesen Artikel schrieben, kannten wir zwei Echtzeit-Speicher und hatten Erfahrung mit ihnen: Clickhouse und Druid. Beides sind leistungsstarke Echtzeit-Analysedatenbanken. Beide verwenden ein spaltenförmiges Format, wodurch sie viel leistungsfähiger sind als andere Datenbanken, Datenpartitionierung und Voraggregation sowie Rollups unterstützen. Beide Systeme bieten niedrige Latenzzeiten und schnelle Aggregation selbst für Milliarden von Zeilen. Beide Systeme dienen ähnlichen Zwecken, doch Druid scheint besser zu sein, wenn es um die Verwendung von Daten geht, die gerade eingefügt wurden (was Cickhouse nicht garantiert), und ist tendenziell eher ereignisbasiert, während Clickhouse es vorzieht, Daten in Mikrobatches zu verarbeiten (Einfügungen, materialisierte Ansicht usw.). Leider ist das nicht ganz unproblematisch. Druid ist teurer im Support und in der Wartung, da es mehr Maschinen und granulare Komponenten erfordert.
Beschränkungen
Die vorgeschlagene Lösung hat auch ihre Grenzen. In der Online-Welt gibt es immer viel mehr Regeln, Einschränkungen und Probleme zu lösen. Für einen leistungsorientierten Ansatz müssen wir einige bewährte Verfahren oder saubere, lesbare Datenstrukturen opfern, um die Latenzzeit und den Ressourcenverbrauch zu senken. Ein Beispiel dafür ist die Denormalisierung von Datenmodellen, die für Menschen weniger lesbar ist, aber eine weitaus bessere Leistung als ein Sternschema bietet.
Alternativen
Reine Echtzeitverarbeitung
Man könnte sich fragen: "Warum nicht den reinen (Beinahe-)Echtzeit-Ansatz verwenden"? Durch den Einsatz geeigneter Frameworks und Programmiersprachen können wir jede erdenkliche Transformation erstellen. Das stimmt tatsächlich, und die Stream-Verarbeitung ist ein integraler Bestandteil der vorgeschlagenen Lösung, dennoch ist sie oft nicht ausreichend. Das größte Problem dabei ist die Datenaggregation. In der Regel sind wir nicht in der Lage, Dimensionen, Datumsbereiche oder sogar Metriken vorherzusagen, die online berechnet werden sollen. So wie Data Lakes die Flexibilität bieten, Berechnungen von Erkenntnissen zu einem späteren Zeitpunkt zu definieren, gibt uns die Echtzeitanalyse die Möglichkeit, die Dimensionen zu einem späteren Zeitpunkt zu erreichen.
Vor-Aggregationen
Eine andere bekannte Technik zur Bereitstellung von Echtzeit-Analysefunktionen besteht darin, die möglichen Berechnungen im Voraus auszuarbeiten und dann nur die Ergebnisse abzufragen. Dies ist ein guter Ansatz, wenn wir Dimensionen und Metriken vorhersagen können. Er wird in der Regel verwendet, wenn wir genau wissen, an welchem Zeitrahmen unsere Benutzer interessiert sind, z.B. an monatlichen Berichten. Auf diese Weise können wir die erforderlichen Ressourcen und Kosten des Systems erheblich senken. Leider ist in den meisten Fällen die Anzahl der Kombinationen aller möglichen Dimensionen so groß, dass die Implementierung und Pflege keinen Sinn macht.
Hybrid
In den meisten anspruchsvollen Umgebungen lassen sich die besten Ergebnisse mit einer Kombination der verschiedenen in diesem Artikel beschriebenen Techniken erzielen.
Beispiel
In diesem Abschnitt beschreibe ich ein Beispielsystem, das wir vor kurzem für ein Startup-Unternehmen aus der E-Commerce-Branche entwickelt haben.
Unser Kunde bietet Echtzeit-Analysefunktionen für Online-Shops. Er verfolgt alle Aktivitäten der Kundenbenutzer und liefert nützliche Metriken und Berichte darüber, wie das Geschäft läuft und wie man die KPIs verwalten und verbessern kann. 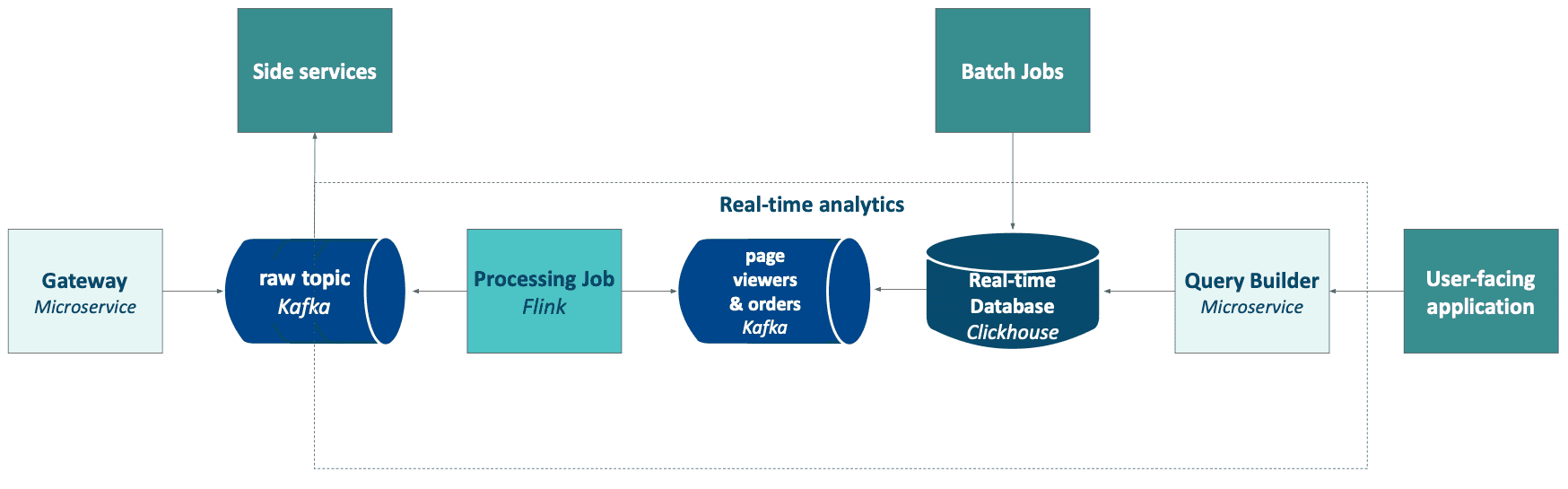
Der Hauptstrom der Daten kommt direkt von den Browsern der Benutzer als Clickstream. Sie werden über einen einfachen Proxy im Originalformat an das Kafka-Thema weitergeleitet. Der nächste Schritt ist die Verarbeitung dieser Daten durch einen Flink-Job, der für die Anreicherung (z.B. mit vorhergesagten Werten aus maschinellen Lernmodellen), die Transformation (z.B. durch die Berechnung von Benutzersitzungen durch Windowing) oder die Zusammenführung mit anderen Streams zuständig ist, um eine halbdenormalisierte Struktur zu erhalten. Die aufbereiteten Daten werden dann zurück an Kafka gesendet und von Clickhouse aufgenommen. Clickhouse verwendet seine Konnektoren und materialisierten Ansichten für die weitere Datenanreicherung, Transformation und Voraggregationen. Der Grund dafür, dass ein Teil der Verarbeitungslogik in Clickhouse verbleibt, liegt darin, dass einige der Daten, die von Batch-Jobs eingefügt werden, bereits im Speicher selbst verfügbar und leicht zugänglich sind, und nicht durch externe Jobs. Die letzte Komponente ist der Query Builder, der für die Erstellung optimaler SQL-Anfragen an die Datenbank unter Verwendung geeigneter Schlüssel, Partitionen und Datenverteilungen zuständig ist.
Verfasst von
Piotr Pękala
Unsere Ideen
Weitere Blogs




Contact