Blog
Überwachungsstufen und Reifegrad der Überwachung

Überwachung und Alarmierung sind nach wie vor ein Teil unserer IT-Lösungen, der einen enormen Wert hat und an dem es in der Entwicklung immer mangelt. In diesem Blog finden Sie eine Zusammenfassung der Überwachungsebenen und des Überwachungsreifegrads, mit deren Hilfe Sie Ihre Situation einschätzen und bestimmen können, welche User Stories zur Verbesserung Ihrer Überwachungsfähigkeit erforderlich sind.
Die Verbesserung Ihrer Überwachungsfähigkeit wird Ihre Widerstandsfähigkeit, Zuverlässigkeit, Entwicklungsgeschwindigkeit, DORA-Reife, CI/CD-Reife und Ihren Reifegrad im Secure Software Development Lifecycle (SSDLC) verbessern.
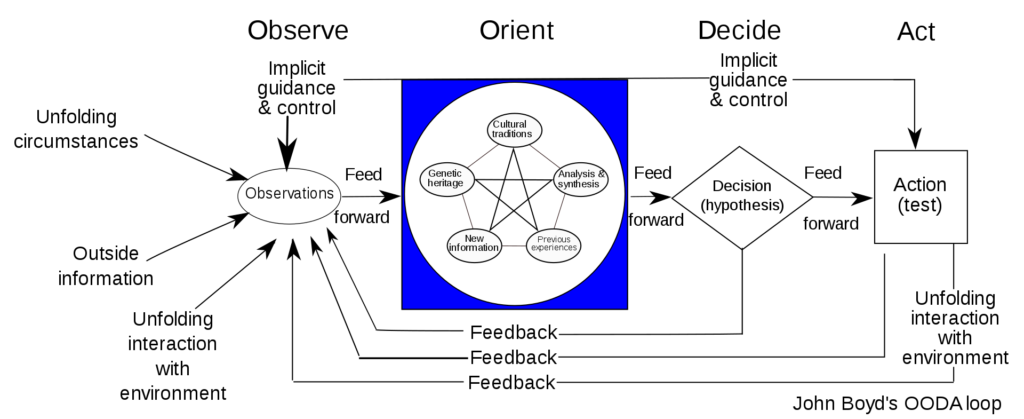 Diagramm der OODA-Schleife von wikipedia
Diagramm der OODA-Schleife von wikipedia
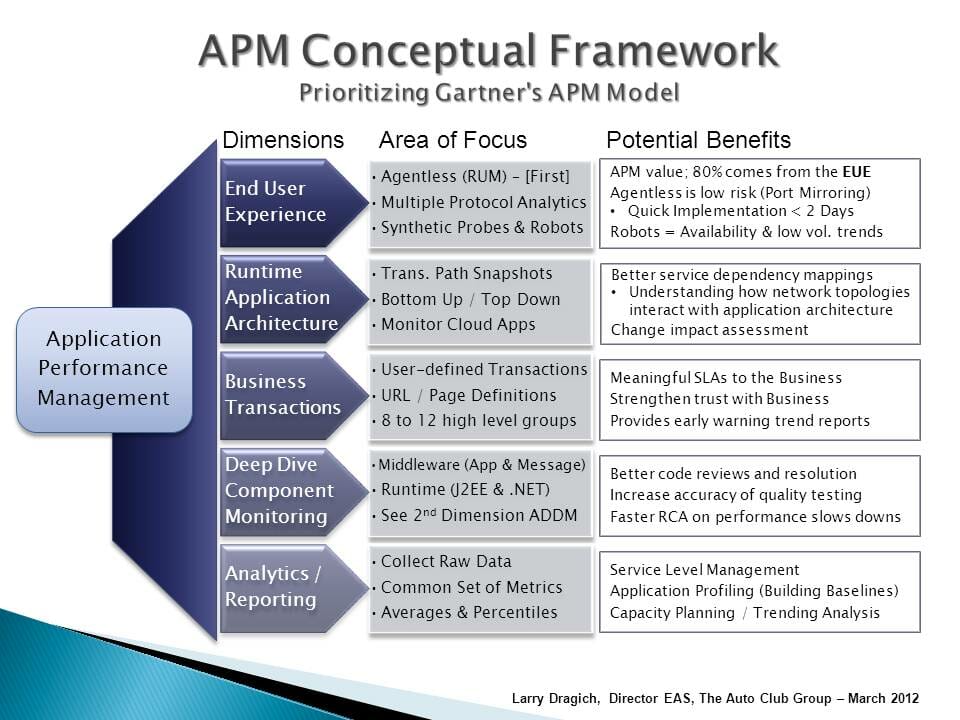 APM Conceptual Framework Bild aus Wikipedia
APM Conceptual Framework Bild aus Wikipedia
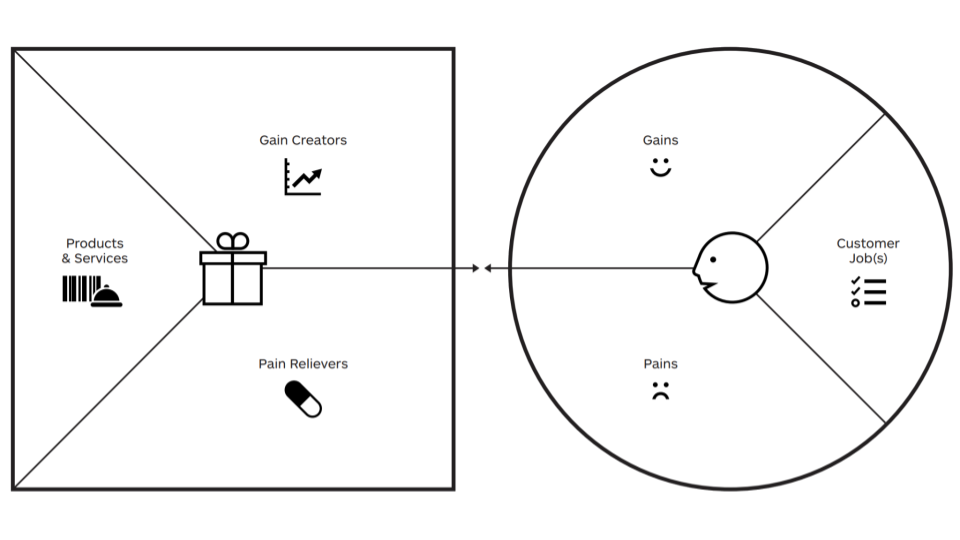 Das Wertversprechen-Canvas von Alexander Osterwaler und Strategyzer
Das Wertversprechen-Canvas von Alexander Osterwaler und Strategyzer
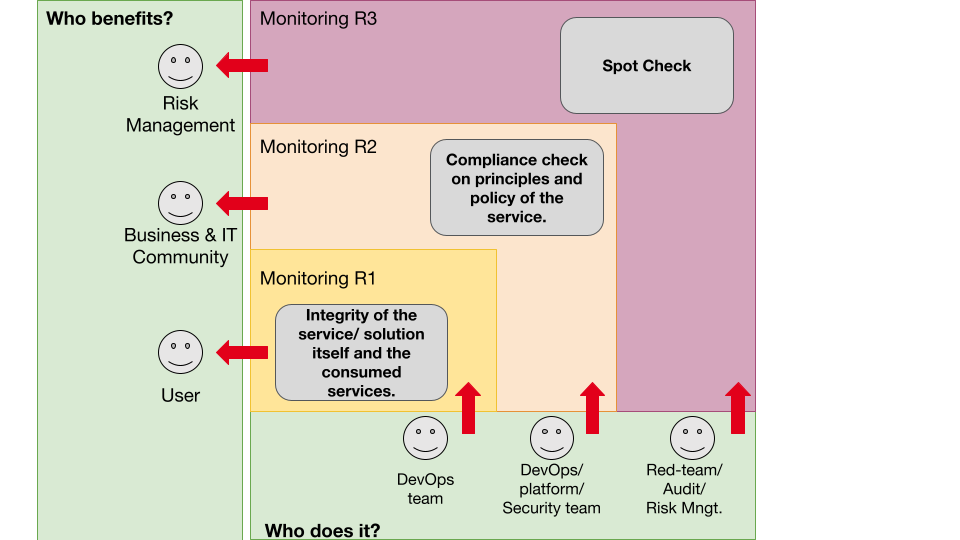
Überwachung im Kontext - Sensibilisierung
Die beiden berühmtesten Rahmenwerke zur Sinnfindung und Verbesserung sind der Deming-Kreis von Plan, Do, Check, Act und die OODA-Schleife von Observe, Orient, Decide und Act. Beide Rahmenwerke stützen sich auf Informationen, die durch die Beobachtung des Akteurs (Sie) gewonnen werden. Das ist es, was wir Überwachung nennen. Überwachung ist die Fähigkeit, Daten abzurufen (Protokollierung) und diese Daten in Informationen und Ereignisse umzuwandeln.
Diagramm der OODA-Schleife von wikipedia
Die Kunst des Holzfällens
Die Protokollierung von Daten in IT-Systemen kann erfolgen über (1) die Aufnahme in Protokolldateien, (2) an einen Netzwerkdienst gesendete Protokolldaten. Üblich ist, dass ein IT-System Protokolle erzeugt. Ebenfalls üblich ist, dass die erstellten Protokolle die Umgebung, in der die Software läuft, nicht verlassen. Die Lokalisierung von Protokolldaten macht es schwierig, die Protokolldaten in einen Kontext zu stellen, und erschwert den Zugriff auf die Protokolldaten, wenn die Umgebung nicht mehr verfügbar ist. Ein Beispiel dafür sind die Protokolldateien des Webservers, die von den Datenbankprotokollen und den IP-Router-Protokollen isoliert sind. Dies verhindert, dass festgestellt werden kann, wie schnell der Inhalt der Website dem Endbenutzer präsentiert wird, und schränkt die Ermittlung des Engpasses bei der Antwortzeit ein. Und wenn der Webserver nach einem Neustart abstürzt, ist es "unmöglich", die Ursache des Absturzes zu ermitteln.- Tipp - Protokollieren Sie nicht nur für das Erwartete, sondern auch für das Unerwartete.
- Tipp - Protokollieren Sie Systemmetriken in einer anderen Datenbank als die Anwendungsprotokolldaten.
- Tipp - Halten Sie die Protokollumgebung in einem anderen Kontext als die Anwendung und die Infrastruktur, die die Protokolle erzeugen.
Überwachung der Log Levels
Für die Überwachung können Sie die folgenden Abstraktionsebenen definieren, auf denen die Überwachung stattfinden soll. Die folgende Liste geht von einer niedrigen bis zu einer höheren Abstraktionsebene. Je höher eine Ebene, desto mehr "Wert" wird überwacht. Diese Liste ist verwandt mit Application Performance Monitoring Wikipedia CIO-Wiki- Metrikdaten aus der Infrastrukturebene, z.B. CPU, Speicher, I/O, ...
- Metrische Daten auf der Ebene der Anwendungskomponenten,z.B. Transaktionen pro Sekunde, Start-/Stoppzeit, ...
- Funktionsprotokolldaten auf der Ebene der Anwendungskomponenten, z.B. Aufruf von Unterroutinen, Aufruf von Schnittstellen, Fehler- und Warninformationen, ...
- Metadaten auf der Ebene der Anwendungskomponenten, die Einblick in die Beziehungen geben.
- Ermöglicht einen Einblick in die Beziehung zwischen Infrastrukturkomponenten und Anwendungskomponenten.
- Ermöglichung von Einblicken in die Beziehung zwischen Anwendungskomponenten. Dies kann z.B. durch die Protokollierung einer UUID erfolgen, die von dem Elternprozess, der Sie aufgerufen hat, abgerufen wird, und durch die Protokollierung der Aufrufe, die nach außen zu Ihrem Kindprozess gehen. Auf diese Weise können Sie die Anwendungsprozesse über die Anwendungskomponenten hinweg miteinander verketten (korrelieren).
- Metadaten aus der benutzerdefinierten Geschäftsvorgangsebene,
- Ermöglicht die Bestimmung der geschäftlichen Auswirkungen von Änderungen/Fehlfunktionen in einer Anwendung oder Infrastrukturkomponente.
- Ermöglicht die Visualisierung und Analyse von Geschäftsprozessen auf der Grundlage von Data Mining, z.B. durch Hinzufügen eines Feldes "Name des übergeordneten Prozesses" zum Protokolleintrag, und bei Bedarf können Sie den Prozessnamen in einen Unterprozess ändern, wenn Sie Ihre eigenen untergeordneten Prozesse aufrufen. Dieser Textwert ist ein Zusatz zur UUID, da er dem Prozessfluss, den Sie durch die Korrelation der UUIDs gefunden haben, eine geschäftliche Bedeutung verleiht.
- Metadaten von (synthetischen) Endbenutzern
- Ermöglicht die Visualisierung und Analyse der Endbenutzererfahrung und setzt diese in Beziehung zu den geschäftlichen Auswirkungen und der Beziehung zu den Anwendungskomponenten. Sie können z.B. von einer bestimmten Endbenutzerschnittstelle aus einen Geschäftsprozess auslösen, den Sie in regelmäßigen Abständen (von einmal pro Tag bis mehrmals pro Minute) ausführen, um die Endbenutzerleistung Ihrer Lösung insgesamt zu überwachen.
- Tipp - Bestimmen Sie, warum Sie protokollieren, damit Sie entscheiden können, was Sie protokollieren möchten.
Überwachung von Log Levels & Application Performance Management (APM) Konzeptioneller Rahmen
Die sechs (6) Protokollebenen der Überwachung ähneln den Schritten im APM Conceptual Framework, sind aber etwas konkreter.
APM Conceptual Framework Bild aus Wikipedia
Reifegrad überwachen
Die Überwachung beruht auf der Protokollierung. Die folgenden Reifegrade definieren den Wert, den die Überwachung für die PDCA- oder OODA-Zyklen hat.- Sammeln Sie Daten.
- Extrahieren Sie Daten aus der Infrastruktur- oder Anwendungskomponente
- Senden Sie Daten zu Überwachungszwecken in eine andere Umgebung.
- Verwandeln Sie Daten in Informationen.
- Kombinieren Sie die Daten mit dem Kontext
- Visualisieren Sie die Daten für die verantwortlichen und rechenschaftspflichtigen Stakeholder (Nutzer).
- Verwandeln Sie Informationen in Ereignisse.
- Bestimmen Sie anhand der Informationen eine Bandbreite oder Schwellenwerte, bei deren Überschreitung ein Ereignis ausgelöst wird.
- Benachrichtigen Sie die Beteiligten, die von dem Ereignis betroffen sind, und stellen Sie ihnen die relevanten Daten zur Verfügung.
- Automatisieren Sie die Reaktion auf Ereignisse.
- Automatische Reaktion auf Ereignisse und Senden von Protokollen über die Erkennung von Ereignissen und die Reaktion an die zuständigen Personen.
Das Wertversprechen-Canvas von Alexander Osterwaler und Strategyzer
Parteien überwachen
Es ist eine gute Praxis, mehr als eine verantwortliche Partei für die Überwachung zu haben. Mehrere Verantwortungsebenen verringern die Anzahl der unerkannten Ereignisse und helfen, unerwünschte Nebeneffekte zu vermeiden. Modelle zur Inspiration sind das Viable Systems Model oder das Three lines of Defence Model. Im Zusammenhang mit einem IT-Team, das eine Lösung in der Cloud betreibt, würde dies bedeuten, dass das Team selbst für die Überwachung und Protokollierung verantwortlich ist. Dies ist der Ansatz von Secure Software Development Lifecycle und DevSecOps, wie er zum Beispiel vom Verteidigungsministerium in den USA definiert wurde. Ein zweites Team ist für die Sicherheit der Cloud-Umgebung verantwortlich und überwacht diese aus der Perspektive der Cloud-Plattform. Eine dritte Ebene könnte ein Chaos-Engineering-Team oder ein rotes Team sein, das die Überwachung und das Ereignismanagement überprüft, das vom IT-Team und dem Cloud-Plattform-Team eingerichtet wurde.Drei Verantwortungsbereiche bei der Überwachung
Um sicher zu sein, müssen Sie Ihre Erwartungen mit der Realität abgleichen, wie in unserem White Paper über BRACE und in diesem Vortrag beschrieben: "Die Sicherheitsfata Morgana" von Bruce Schneier https://www.youtube.com/watch?v=NB6rMkiNKtM Die Herausforderung dabei ist, dass die Beobachtung der Realität subjektiv ist. Wie in früheren Vorlesungen dargelegt:- (1) Embrace Chaos und Antifragilität auf dem Risk and Resilience 2022-11 Festival von Marinus J. Kuivenhoven und Edzo A. Botjes(Google Präsentation),
- (2) Umfassen Sie das Chaos und gewinnen Sie Wert durch kontinuierliches Lernen auf dem PROMIS 2022-11 Symposium(Google Präsentation),
- (3) Gastvortrag zu Situationsdesign an der Antwerp Management School 2022-10(Google Präsentation),
- (4) Einführung in die Sicherheit Gastvortrag an der Nyenrode Business University 2022-05(Präsentation) und
- (5) Optimierung der Widerstandsfähigkeit in Richtung Antifragilität eine sichere Cloud-Übersetzung bei OWASP Benelux 2022-04(Google Präsentation).
Aufruf zum Handeln
Wo soll man also anfangen?
Ich würde Ihnen raten, mit den vier Tipps zu beginnen, sich dann Ihre Überwachungsprotokolle und den Reifegrad der Überwachung anzusehen und damit zu beginnen, einen ausgewogenen Stapel von Anwendergeschichten zu erstellen. Ich persönlich würde dazu raten, sich eine Open Source-Lösung für die Überwachung von Metriken anzusehen, die über eine integrierte Datenbank und ein Dashboard verfügt, und diese nach der Implementierung schnell um eine Graphdatenbank einschließlich Dashboard zu ergänzen. Je eher Sie Ihren Stakeholdern den Geschäftsprozess zeigen können, desto einfacher ist es, den Wert Ihrer Überwachungslösung zu bestimmen. Die Erstellung eines Kontextdiagramms oder eines Bedrohungsmodells hilft bei der Identifizierung Ihrer Lösungskomponenten, externen Systeme, Beteiligten und deren Beziehungen. Wenn Sie dann das Gefühl haben, dass Sie auf dem richtigen Weg sind, können Sie (kontrolliertes) Chaos einführen, um Ihr System zu trainieren und anzupassen.Zusammenfassung
TL;DRTipps zur Überwachung
- Tipp - loggen Sie nicht nur für das Erwartete, sondern auch für das Unerwartete.
- Tipp - Protokollieren Sie Systemmetriken in einer anderen Datenbank als die Anwendungsprotokolldaten.
- Tipp: Die Protokollumgebung sollte sich in einem anderen Kontext befinden als die Anwendung und die Infrastruktur, die die Protokolle erzeugen.
- Tipp - Bestimmen Sie, warum Sie protokollieren, damit Sie entscheiden können, was Sie protokollieren möchten.
Überwachungsebenen
- Metrische Daten auf der Ebene der Infrastruktur.
- Metrische Daten auf der Ebene der Anwendungskomponenten.
- Funktionsprotokolldaten auf der Ebene der Anwendungskomponenten.
- Metadaten auf der Ebene der Anwendungskomponenten.
- Metadaten aus der benutzerdefinierten Geschäftsvorgangsebene.
- Metadaten von (synthetischen) Endbenutzern.
Reifegrad überwachen
- Sammeln Sie Daten.
- Verwandeln Sie Daten in Informationen.
- Verwandeln Sie Informationen in Ereignisse.
- Automatisieren Sie die Reaktion auf Ereignisse.
Weißbuch über Widerstandsfähigkeit und IT-Sicherheit
In anderen Blogs werden wir ausführlicher auf die Überwachung und ihre Beziehung zur Widerstandsfähigkeit und zur (IT-)Sicherheit eingehen. Mehr darüber können Sie in unserem White Paper lesen: "Einführung in das BRACE-Modell - Metamodell zur sicheren Produktentwicklung", für den Download ist keine Anmeldung erforderlich.Sharing Knowledge
Die Kernwerte von Xebia sind: Menschen zuerst, Wissen teilen, Qualität ohne Kompromisse und Kundennähe. Aus diesem Grund wird dieser Blogeintrag unter der Lizenz Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA) veröffentlicht. Mit freundlichen Grüßen Edzo BotjesVerfasst von

Edzo Botjes
Antifragility Architect & Variety Engineer at Xebia. A Shrek look a like. Loves Coffee, Food, Roadtripping & Zen. ENFP-T. Phd candidate for resilient information security and governance. edzob @ Signal, Linkedin, WWW, Medium, Riot/Matrix, Wire, Telegram




{kind=link}
{kind=link}
Contact
Let’s discuss how we can support your journey.