In diesem Beitrag behandeln wir die Nachverfolgung von Änderungen sowie den Vergleich und die Nachverfolgung der Bereitstellung von Machine Learning-Modellen mit der MLflow-Bibliothek. Später werden wir Ressourcen in der Azure Cloud einrichten, damit wir unser Modell bereitstellen können, und die Azure DevOps-Pipeline erstellen, um ein neues Modell bereitzustellen, indem wir es einfach in das Azure GIT-Repository pushen. Dies zeigt, wie einfach es ist, ML einzurichten - es ist nicht so langwierig oder schwierig, wie Sie denken, wenn Sie wissen, was Sie tun!
Wir werden uns nicht auf das Hypertuning der Modellparameter, die Feature-Exploration oder die Bereinigung der Daten konzentrieren. In unserem Beispiel verwenden wir den "Richter's Predictor: Modellierung von Erdbebenschäden", die von DrivenData veranstaltet wird.
Prozess der IT-Anwendungsentwicklung
Wenn wir eine Desktop-Anwendung, ein mobiles Produkt oder eine Website entwickeln, beginnen wir immer mit der Planung der Funktionen, die wir bereitstellen wollen (dies ist Teil des grundlegenden Produktdesigns). Dann programmieren wir sie und stellen sie kontinuierlich auf dem Server bereit.
Mit "kontinuierlich" meine ich, dass wir aus allen geplanten Funktionen eine kleine Teilmenge auswählen und daran arbeiten. Nachdem die Arbeit abgeschlossen und getestet ist, werden die Änderungen entweder von den Entwicklern oder dem Bereitstellungsteam auf dem Server bereitgestellt. Dies wird als Continuous Integration, Continuous Delivery (CI/CD) bezeichnet und ist Teil des DevOps-Ansatzes.
Da wir auf diese Weise arbeiten, kann der Kunde die Funktionen nutzen, die wir bereits fertiggestellt haben, während wir an einer anderen Teilmenge von Funktionen arbeiten. Um den Überblick über alle Änderungen in der Codebasis zu behalten, wollen wir immer eine Art Versionskontrollsystem verwenden, wie z.B. Git. Und warum? könnte jemand fragen. In komplexen Anwendungen können selbst kleinste Änderungen am bereits geschriebenen Code, die für die Fortsetzung der Arbeit an der aktuellen Funktion erforderlich sind, versehentlich eine andere Funktion zerstören. Ähnlich verhält es sich, wenn sich eine Anforderung geändert hat und daraufhin Anpassungen an der Codebasis vorgenommen wurden. Der andere Teil der Anwendung war möglicherweise streng davon abhängig, wie er vor der Änderung funktionierte. Dieser Teil des jetzt fehlerhaften Codes wird natürlich nach der Änderung nicht mehr funktionieren, aber das kann bei den Tests manchmal untergehen.
Solche Situationen kommen manchmal vor, und deshalb möchten wir in der Lage sein, alle Änderungen zu sehen, um alle früheren Arbeiten zu sehen und den Schuldigen zu finden, der den Funktionsbruch verursacht hat. Dies ermöglicht uns auch ein einfaches Rollback zu früheren Versionen, falls erforderlich. Nachdem alle Funktionen ausgeliefert wurden, gibt es nicht mehr viel zu tun, also wechseln wir zur Wartung und beheben nur noch Fehler, ohne neue Funktionen zu entwickeln.
Ist die Entwicklung von Machine Learning-Modellen so anders?
Während sich die Anwendungsimplementierung in der iterativen Phase befindet, können wir genau planen, was getan werden muss. Die Modellimplementierung hingegen ist ein eher explorativer Prozess, bei dem wir nicht wirklich wissen, was getan werden muss, um die besten Ergebnisse zu erzielen.
Natürlich können wir einige der wichtigsten Schritte planen, z. B. die Integration von Daten, die Datenanalyse, die Datenvalidierung, das Training oder die Erstellung des Modells und sogar die Bereitstellung. Aber wir können selten genau sagen, was zu tun ist, denn es gibt immer eine Möglichkeit, das Modell noch weiter zu verbessern.
Nachdem wir ein Modell erstellt haben, versuchen wir, das nächste Modell zu erstellen, um noch bessere Ergebnisse zu erzielen. Wir können andere Lerntechniken verwenden, die Hyperparameter des aktuellen Algorithmus ein wenig ändern (damit er die Realität besser widerspiegelt), versuchen, neue Daten zu integrieren, oder vielleicht einen radikal anderen Ansatz ausprobieren. Es gibt unendlich viele Möglichkeiten, die wir ausprobieren können, um festzustellen, ob sie die Genauigkeit unseres Modells verbessern.
Aber genau wie bei der Anwendungsentwicklung wollen wir den Überblick über die bereits geleistete Arbeit behalten, damit wir die gleichen Dinge nicht zweimal tun - oder öfter! Wir müssen auch in der Lage sein, die Ergebnisse zu vergleichen, denn die Kombination verschiedener Lösungen kann oft zu einer noch besseren Lösung führen. Es wäre jedoch sehr mühsam, den gesamten Code für verschiedene Modelle sowie alle Parameter und Ergebnisse in mehreren Verzeichnissen und Excel-Tabellen zu speichern.
Es ist auch selten, dass wir in Ein-Mann-Teams arbeiten, also müssen wir auch in der Lage sein, unsere Experimente zu reproduzieren oder sie mit anderen Datenwissenschaftlern zu teilen. Die manuelle Erstellung von Docker-Images und die Bereitstellung auf dem Server sind nicht besonders schwierig, aber es kostet uns wertvolle Zeit, die wir mit dem Testen eines anderen Modells verbringen könnten. Wir hätten also gerne einen einfachen, mühelosen und automatischen Bereitstellungsprozess.
MLflow zur Rettung
MLflow konzentriert sich auf drei grundlegende Ziele:
- Verfolgung der Experimente, auch bekannt als Parameter
- Ergebnisse
- andere Artefakte
Gepackter ML-Code in wiederverwendbarer und reproduzierbarer Form ermöglicht den Austausch mit anderen Datenwissenschaftlern und die Überführung des Modells in die Produktion sowie die Unterstützung bei der Bereitstellung, da er eine Vielzahl von Bibliotheken und Cloud-Plattformen unterstützt. In diesem Artikel liegt der Schwerpunkt jedoch auf der Nachverfolgung des Modells und der Cloud-Bereitstellung.
Glücklicherweise deckt das die zuvor erwähnten Probleme in Bezug auf Verfolgung, gemeinsame Nutzung und Bereitstellung ab. MLflow ist recht einfach zu bedienen und erfordert nicht so viele Änderungen am Code, was ein großes Plus ist. Außerdem können die Artefakte der einzelnen Experimente, wie Parameter und Code, sowie die Modelle sowohl lokal als auch auf entfernten Servern/Maschinen gespeichert werden. Als ob das noch nicht genug wäre, gibt es eine sehr schöne Schnittstelle für den Vergleich der Experimente mit integrierten Diagrammen, so dass Sie diese nicht selbst erstellen müssen.
Schließlich unterstützt es auch viele Modelle aus Bibliotheken wie scikit-learn, Keras, PyTorch oder ONNX, neben Sprachen wie Python, R, Java und REST API sowie der Kommandozeile.
Fangen wir an
Anhand dieses einfachen Beispiels zeigen wir, wie Sie mit Python ein Modell trainieren und in der Azure Cloud bereitstellen können. Im folgenden Code trainieren wir ein sehr einfaches sequentielles Modell mit der Keras-Bibliothek. Während des Lernprozesses des neuronalen Netzwerks werden dem Algorithmus des neuronalen Netzwerks mehrfach Daten präsentiert. Ein Vorwärts- und ein Rückwärtsdurchlauf aller Trainingsbeispiele an das Modell wird als Epoche bezeichnet. Nach jedem einzelnen Durchlauf des neuronalen Netzwerks protokollieren wir die Genauigkeit und den Verlust jeder Epoche sowohl bei den Trainings- als auch bei den Testdatensätzen, die verwendeten Parameter und speichern das neuronale Netzwerkmodell.
Um das Skript auszuführen, müssen wir einige Bibliotheken installieren, also installieren wir diese zuerst:
Da wir nun die erforderlichen Bibliotheken haben, können wir uns das Skript ansehen.
Überspringen wir den langweiligen Schritt des Ladens der Daten und springen sofort zur Methode 'run_learning'.
Zunächst speichern wir alle Parameter, die an die Methode übergeben wurden, die wir in Kürze erforschen werden. Als nächstes legen wir run_learningtdas Hauptverzeichnis fest, so dass alle Artefakte im Basisverzeichnis gespeichert werden, nicht dort, wo jupyter notebook läuft. Wenn wir das Verzeichnis lokal festlegen wollen, müssen wir das Präfix 'file:' vor dem Pfad hinzufügen, für HTTP URI (Uniform Resource Identifier) fügen wir 'https:' hinzu und wenn wir einen databricks Arbeitsbereich verwenden wollen, fügen wir 'databricks://' hinzu. Anstelle einer 'with ... as ...'-Klausel können wir sie der Variablen zuweisen, aber wir müssen daran denken, das Experiment manuell zu schließen, indem wir die Methode 'end_run' verwenden. Die Notation 'with ... as ...' ist fehleranfällig, daher bleiben wir bei diesem Ansatz.
Das erste, was wir nach dem Start des Experiments tun, ist die Protokollierung von Parametern mit der Methode 'mlflow.log_param', aber die Reihenfolge der Protokollierung ist natürlich nicht wichtig - solange sie im Rahmen des Experiments bleibt. Danach erstellen wir ein temporäres Verzeichnis für Artefakte und erstellen, passen, trainieren und bewerten das Keras-Modell.
Sobald dies geschehen ist, protokollieren wir alle Ergebnisse mit 'log_metric' auf ähnliche Weise wie bereits beschrieben. MLflow unterstützt von Haus aus keine Arrays, daher müssen wir die Drei-Parameter-Methode verwenden. Wir zählen das Array auf und protokollieren jede Epoche separat in der Schleife.
Zuletzt speichern wir das Modell und weisen MLflow an, das Artefakt in den zuvor angegebenen Pfad zu verschieben und den Prozess mit dem Löschen der temporären Dateien zu beenden.
Nachdem wir nun das Skript erklärt haben, lassen Sie es in einem Jupyter-Notebook laufen und sehen Sie sich die MLflow-Benutzeroberfläche an.
Hier sehen Sie ein Beispielergebnis, nachdem Sie das Lernskript ein paar Mal mit verschiedenen Parametern ausgeführt haben.
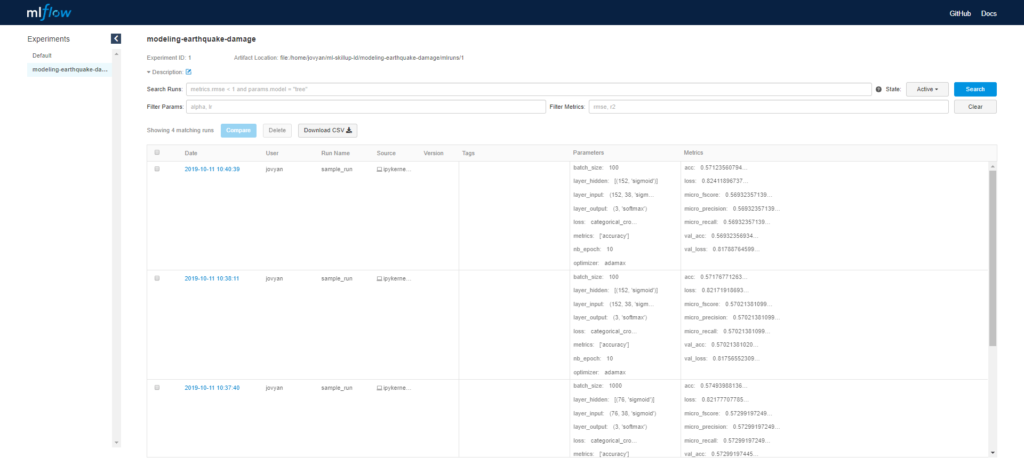
Wir können jeden Parameter/Messwert in separate Spalten aufteilen, indem wir auf den Parameternamen klicken
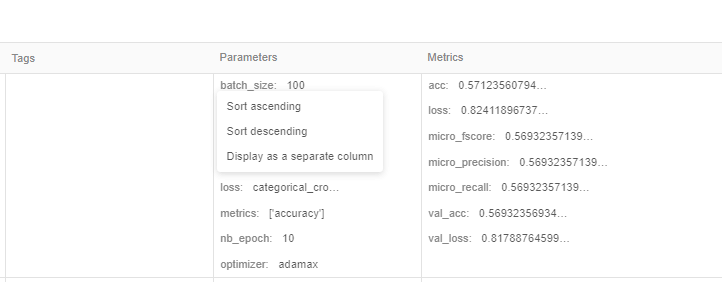
Zum Beispiel so:
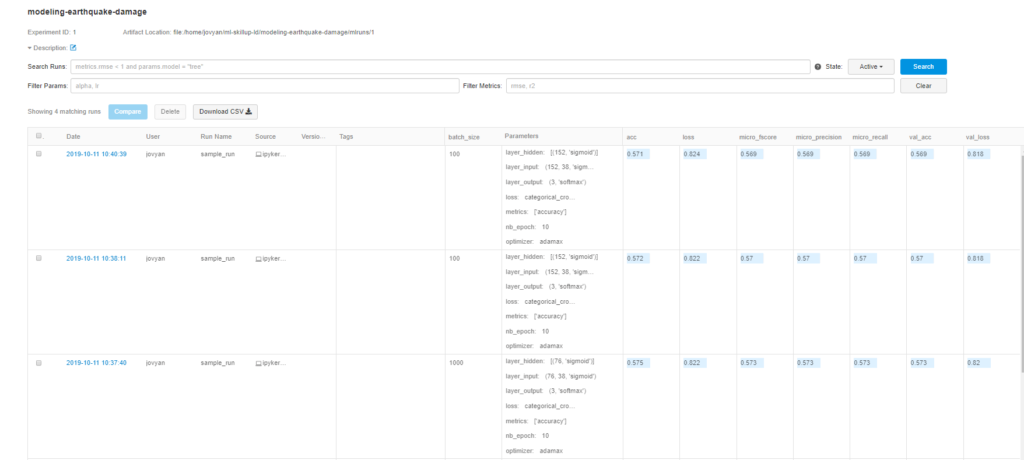
Wir können uns ein Experiment ansehen, indem wir auf den Hyperlink zum Datum klicken, wo wir alle protokollierten Parameter, Metriken und Artefakte sehen können. Das Artefakt kann auch heruntergeladen werden, nachdem es ausgewählt wurde.
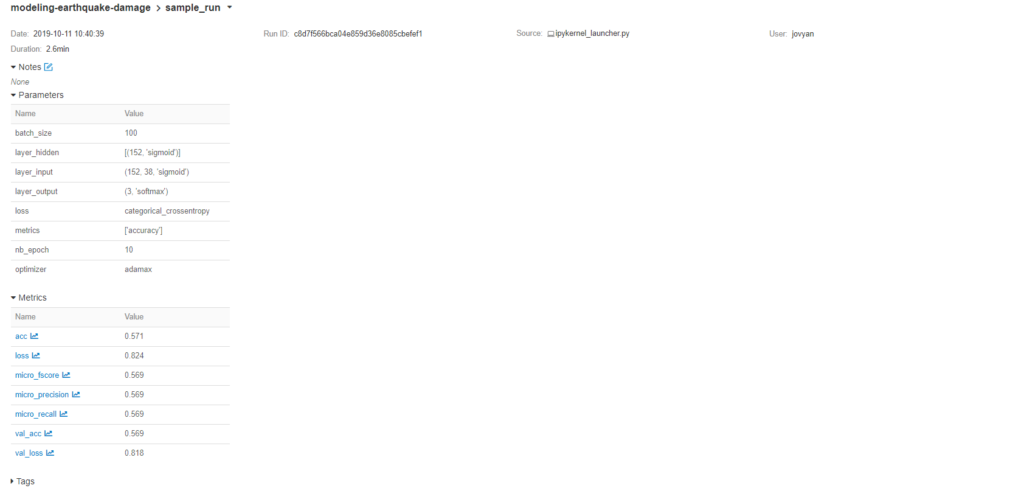
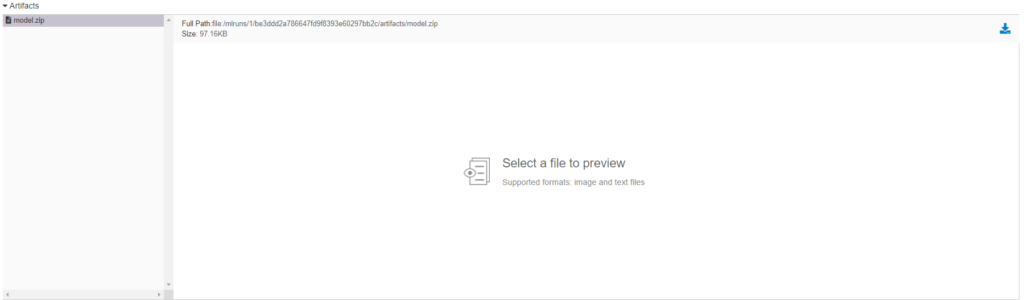
Wir können auch einen Blick auf die Verlustmetrik werfen, die in der Schleife protokolliert wurde, indem wir auf sie klicken.
Eine weitere großartige Sache ist der sofortige Vergleich zwischen verschiedenen Laufergebnissen. Dazu müssen wir nur die Kontrollkästchen aktivieren und auf die Schaltfläche "Vergleichen" klicken.
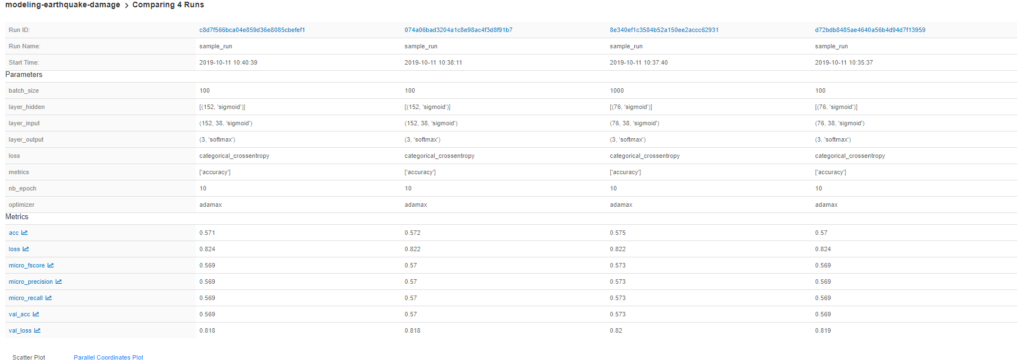

Wir können auch die Änderungen der Genauigkeit in jeder Epoche zwischen den ausgewählten Modellen vergleichen.
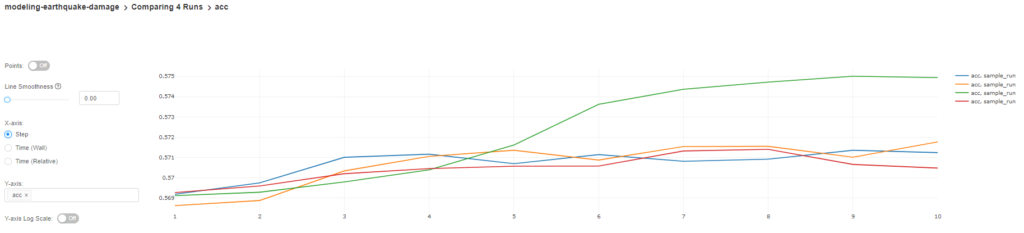
Nachdem wir alle Ergebnisse verglichen und das beste Modell ausgewählt haben, können wir die archivierte Version herunterladen, die wir als Artefakt gespeichert haben und die wir später verwenden werden.
Einsatz des Keras-Modells
Wir haben uns entschieden, unser Modell in der Azure-Cloud zu hosten. Daher müssen wir unsere Azure-Dienste so konfigurieren, dass sie das Modell, das wir im letzten Schritt erstellt haben, hosten können. Fangen wir gleich damit an!
Rufen Sie zunächst das Azure-Portal auf und melden Sie sich an. Wenn Sie noch kein Konto haben, können Sie es mit ein paar einfachen Schritten erstellen. Lassen Sie uns nun eine neue Ressourcengruppe erstellen. Darin werden alle Ressourcen gruppiert, z.B. unsere Anwendung, der Image-Container und so weiter. Klicken Sie auf 'Ressourcengruppen' und anschließend auf 'Hinzufügen', geben Sie der Ressourcengruppe einen Namen, wählen Sie die Region aus und klicken Sie auf 'Überprüfen + Erstellen', gefolgt von 'Erstellen'.
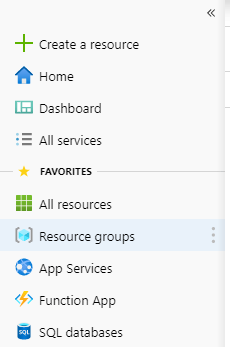
Klicken Sie nun im linken Bereich auf "Ressource erstellen", dann auf "AI + Machine Learning" und "Machine Learning Service Workspace". Geben Sie Ihrem Namensraum einen Namen, wählen Sie eine zuvor erstellte Ressourcengruppe und erstellen Sie sie. Warten Sie dann einfach, bis Azure die Erstellung dieser Ressourcen abgeschlossen hat.
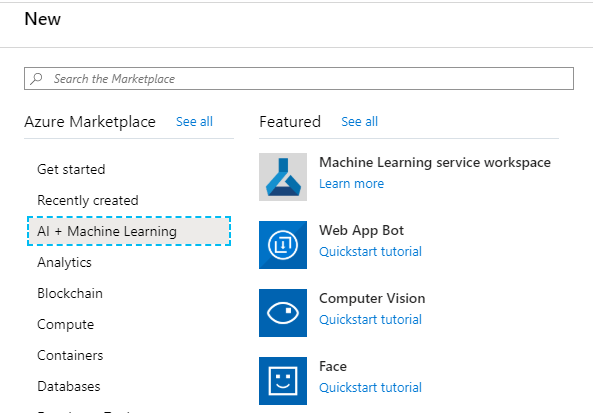
Fügen wir nun den Dienstprinzipal hinzu, der uns den Zugriff auf unsere Ressourcen von unserem Code aus ermöglicht. Klicken Sie zunächst im linken Bereich auf 'Azure Active Directory' und dann auf 'App-Registrierungen', bevor Sie auf die Schaltfläche 'Hinzufügen' klicken und die Anwendung erstellen.
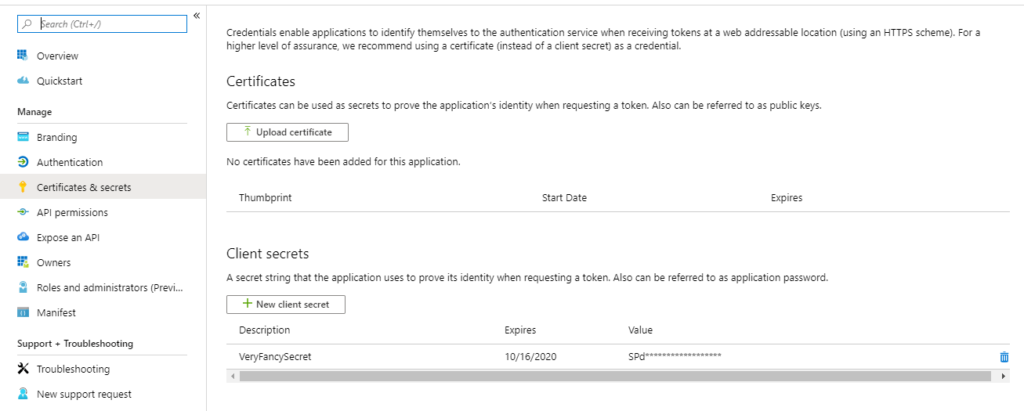
Wir werden zu den Details der App-Registrierung weitergeleitet, die wir gerade erstellt haben. Kopieren Sie die ID der Anwendung (Client) und die ID des Verzeichnisses (Tenant), da Sie diese später noch benötigen werden. Klicken Sie nun auf 'Zertifikate & Geheimnisse' und erstellen Sie ein Geheimnis, indem Sie auf 'Neues Client-Geheimnis' klicken. Kopieren Sie das Geheimnis irgendwo hin, da es später ebenfalls benötigt wird.
Jetzt, da wir den Dienstprinzipal haben, mit dem wir uns vom Code aus anmelden können, müssen wir ihm Zugriff auf alle zuvor erstellten Ressourcen gewähren. Gehen Sie zurück zu den Ressourcengruppen und wählen Sie die Ressource, die wir zuvor erstellt haben, gefolgt von 'Zugriffskontrolle (IAM)'.
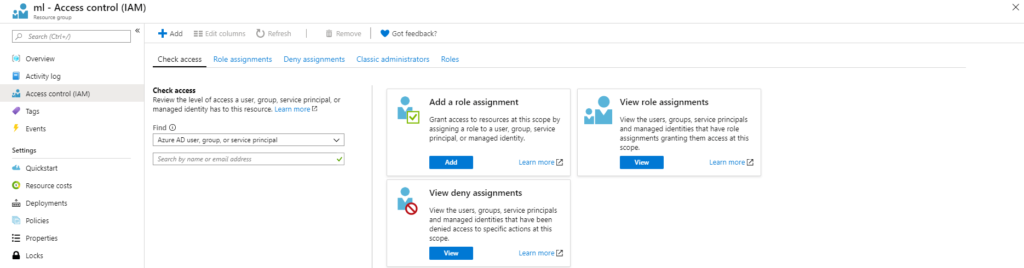
Wir können überprüfen, wer auf unsere Ressourcen zugreifen kann, indem wir uns die Rollenzuweisungen ansehen, also klicken wir auf 'Anzeigen'. Jetzt sollten wir alle Anwendungen, Benutzer und Gruppen sehen, die Zugriff auf diese Ressourcengruppe haben. Der Zugriff auf alle Ressourcen in dieser Ressourcengruppe wird vererbt. Um also auf früher erstellte Dienste für maschinelles Lernen zuzugreifen, müssen wir hier nur unseren Dienstprinzipal hinzufügen.
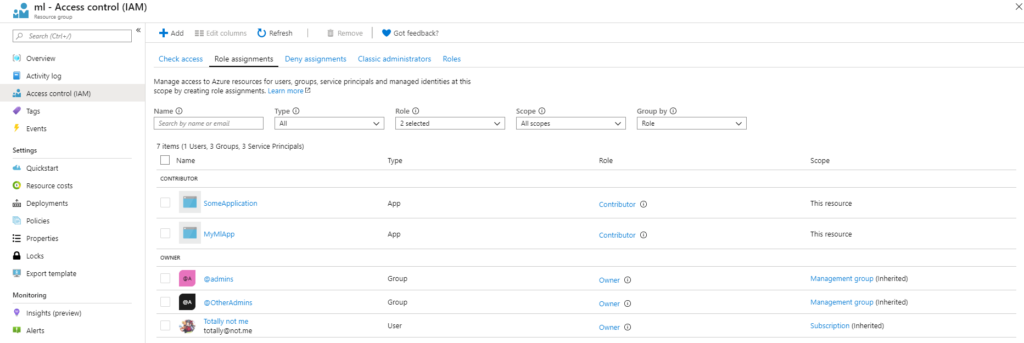
Klicken Sie auf die Schaltfläche 'Hinzufügen', gefolgt von 'Rollenzuweisung hinzufügen'. Es sollte ein neues Fenster erscheinen, in dem wir die Rolle auswählen und festlegen, wer diese Rolle erhalten soll. Es empfiehlt sich, die Rolle als Mitwirkenden festzulegen, damit sie alles verwalten kann, aber die Zugriffsrechte auf die Ressource nicht ändern kann. Dann wählen wir die App aus, die wir erstellt haben, und klicken auf Speichern. Jetzt richten wir alles ein, einschließlich einiger weiterer Konfigurationseinstellungen, die vorgenommen werden müssen:
- Speicherort - dies ist nur der Speicherort für unsere Ressourcen, also stellen wir sicher, dass er mit dem Speicherort der Gruppe übereinstimmt.
- resource_group - der Name der Ressourcengruppe, die erstellt wurde
- workspace_name - der Name des erstellten Arbeitsbereichs
- subscription_id - Abonnement-ID (suchen Sie einfach nach Abonnement in der oberen Leiste)
- account_name - der Name des Speicherkontos, das in der Ressourcengruppe erstellt wurde (gehen Sie zu Ressourcengruppen -> wählen Sie Ressource -> und suchen Sie nach Speicherkonto und kopieren Sie den Namen)
- account_key - Zugriffsschlüssel für das Speicherkonto (zu finden auf der Registerkarte Zugriffsschlüssel im Speicherkonto)
- service_principal_id, service_principal_password und tenant_id können über App-Registrierungen im Active Directory von Azure abgerufen werden.
- tenant_id ist die "Verzeichnis (Mieter) ID".
- service_principal_id ist "Anwendungs-(Client-)ID".
- service_principal_password ist das "Client-Geheimnis", das wir auf der Registerkarte "Zertifikate & Geheimnisse" erstellt haben
Werfen wir nun einen Blick auf das Deployment-Skript.
Zu Beginn importieren wir sichere Variablen wie den Kontonamen, die Haupt-ID und das Passwort aus der Umgebung. Als nächstes entpacken wir das Modell, gefolgt vom Lademodell, um zu prüfen, ob es gültig ist. Später erstellen wir ein Authentifizierungsobjekt mit der ID und dem Kennwort des Dienstherrn (der Anwendung, die wir zuvor erstellt haben).
Danach erstellen oder erhalten wir einen Arbeitsbereich, wobei die Eigenschaft 'exist_ok' auf True gesetzt ist. Damit können wir fortfahren, ohne einen Arbeitsbereich zu erstellen, wenn dieser bereits existiert; andernfalls erhalten wir eine Ausnahme. Im nächsten Schritt wird das Image erstellt, gefolgt von seiner Bereitstellung.
Bevor Sie das Skript ausführen, fügen Sie einen Pfad zu Ihrem Modell ein!
Jetzt wissen wir, wie wir das Modell bereitstellen können, also lassen wir es automatisch geschehen!
Azure DevOps Pipeline einrichten
Wir möchten eine Pipeline einrichten, die unser Modell in der Azure Cloud bereitstellt, nachdem es in das Repository übertragen wurde.
Gehen Sie auf die Azure DevOps-Seite und melden Sie sich an. Zunächst müssen wir ein Projekt erstellen, falls noch nicht geschehen. Danach müssen wir das Repository importieren. Gehen Sie zu Repos, klicken Sie auf Importieren und fügen Sie die URL des Vorlagen-Repositorys ein.
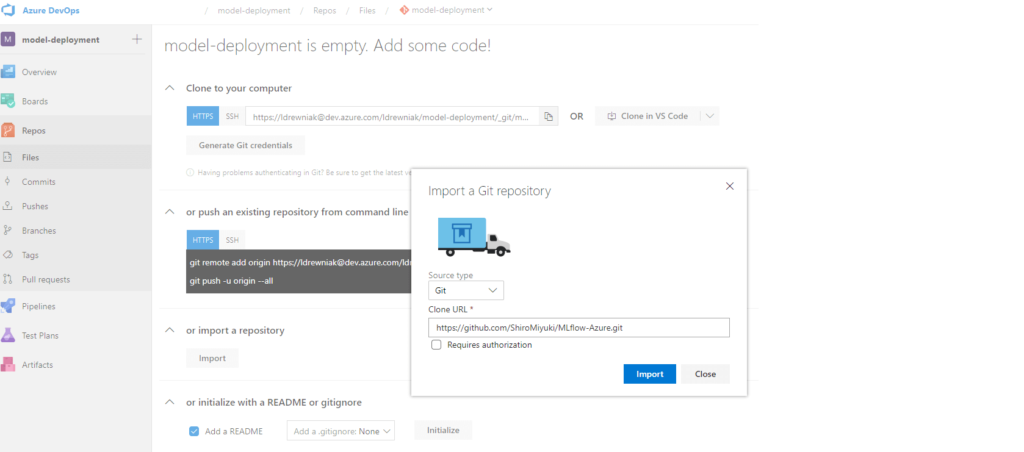
Lassen Sie uns nun die Pipeline erstellen. Gehen Sie zu Pipelines, Neue Pipeline, Azure Repos Git und wählen Sie Repository. Sie sollten nun den YAML-Code sehen. Klicken Sie oben rechts auf Variablen und fügen Sie die zuvor aufgelisteten Variablen hinzu - denken Sie daran, die sensiblen Variablen als geheim zu markieren!
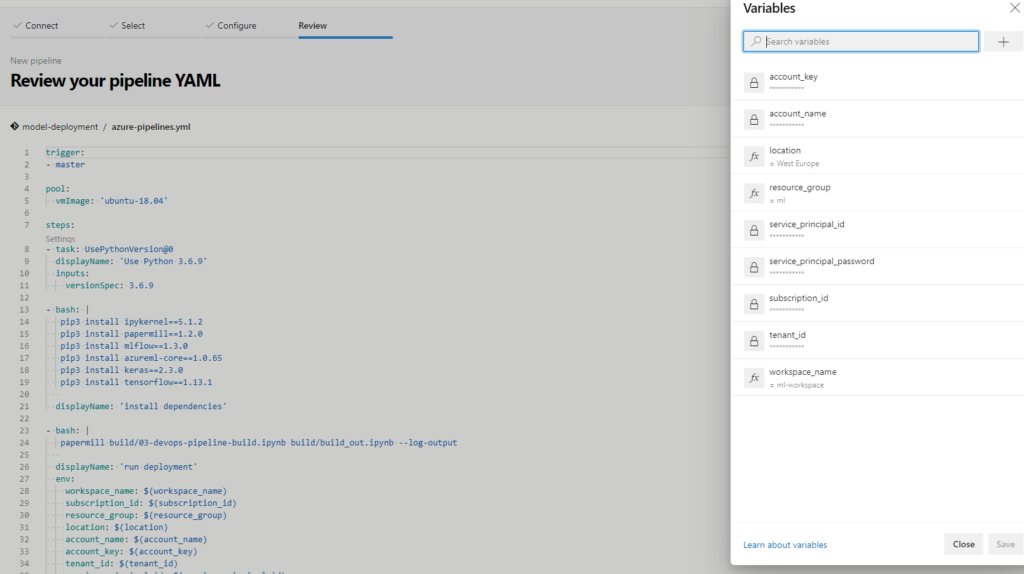
Speichern Sie die Variablen und klicken Sie auf 'Ausführen'. Während die Bereitstellung läuft, werfen wir einen Blick auf YAML.
Die Pipeline umfasst nur wenige Schritte. Zunächst wählt sie die Version der virtuellen Maschine aus, dann die Python-Version und installiert alle erforderlichen Abhängigkeiten. Anschließend wird das Deployment-Notebook mit allen Variablen, die der Umgebung hinzugefügt wurden, ausgeführt. Am Ende wird die URL für die Bewertung ausgedruckt.
Das Deployment-Skript ähnelt dem Skript, das wir bereits behandelt haben, da es nur wenige Änderungen gibt. Nachdem wir die Geheimnisse importiert haben, durchsuchen wir das Verzeichnis und wählen das Modell mit der höchsten Version aus. Die Modellnamen sollten wie folgt lauten: v.zip.
Im letzten Schritt der Pipeline können wir die URL sehen, unter der das Modell bereitgestellt wird.
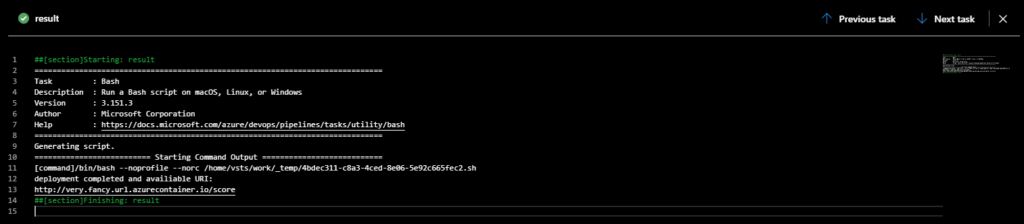
Zusammenfassung
Also, was haben wir gelernt? Wir haben gezeigt, wie man ML-Modelländerungen verfolgt und die Modelle mithilfe der MLflow-Bibliothek miteinander vergleicht. Wir haben auch gelernt, wie man Azure-Ressourcen einrichtet, damit wir das Modell vom Code aus bereitstellen können. Danach haben wir die Einrichtung der Azure DevOps-Pipeline behandelt.
Wenn wir nun ein neues Modell bereitstellen möchten, müssen wir es nur in unser GIT-Repository verschieben und es wird ein Image erstellt, in einer Container-Registry gespeichert und in der Azure Cloud bereitgestellt.
Ich hoffe, dies zeigt, wie einfach es ist, eine Reihe von ML-Anwendungen und -Lösungen einzurichten. Gepaart mit der Cloud - nicht nur Azure, sondern auch AWS und Google Cloud Platform - ist es sehr gut möglich, vielseitige und außergewöhnliche ML-Anwendungen für jedes Unternehmen zu entwickeln.
Geschäftsperspektive
Dank Cloud-Plattformen wie Azure haben wir jetzt einen einfachen Zugang zum Testen und Verfolgen unserer Machine Learning-Modelle. Neben der kosteneffizienten Verwaltung von Ressourcen ermöglicht dies Unternehmen einen einfachen Einstieg in ML und die schnellstmögliche Nutzung der Vorteile.
Quellen
Verfasst von
Xebia Author
Unsere Ideen
Weitere Blogs




Contact