Blog
Architekturen für Modelle des maschinellen Lernens

Nach monatelangem Auswerten von Daten, Plotten von Verteilungen und Testen verschiedener Algorithmen für maschinelles Lernen haben Sie Ihren Stakeholdern endlich bewiesen, dass Ihr Modell einen geschäftlichen Nutzen bringen kann. Ihr Modell muss die Annehmlichkeiten Ihrer Entwicklungsumgebung verlassen und ist bereit, in die Produktion zu gehen, um vom Endbenutzer genutzt zu werden. Die Bereitstellung eines Modells kann doch nicht so schwer sein, oder? Das muss es auch nicht sein. Die Wahl des richtigen Architekturmusters für das Serving ist ausschlaggebend dafür, dass Sie den größtmöglichen geschäftlichen Nutzen aus Ihrem Modell ziehen können. In diesem Blog werden wir die gängigsten Serving-Architekturen1 erörtern: Batch-Predicting, synchrones Online-Serving und asynchrones Online-Serving. Der Argumentation halber gehen wir davon aus, dass das Modell für maschinelles Lernen in regelmäßigen Abständen auf einem endlichen Satz historischer Daten trainiert wird. Nach der Lektüre dieses Beitrags werden Sie verstehen, welche geschäftlichen Anforderungen, Qualitätsattribute und Einschränkungen die Entscheidung für die Serving-Architektur vorantreiben und Sie in die Lage versetzen, die Architektur zu wählen, die am besten zu Ihrem Anwendungsfall passt.
1. Andere Serving-Architekturen sind: Edge Serving, föderiertes Lernen und Online-Lernen. Dies sind fortgeschrittenere Serving-Architekturen, die einen eigenen Blog-Beitrag rechtfertigen.
In diesem Blogbeitrag verzichten wir darauf, bestimmte Tools und Technologien zu erwähnen, um das Kaninchenloch der Implementierungsdetails zu vermeiden. Stattdessen konzentrieren wir uns auf die Prinzipien, die die Diskussion vorantreiben. Es gibt viele Möglichkeiten, jede der genannten Architekturen zu implementieren, und einige von ihnen können sogar in hybriden Formen kombiniert werden. Viele verschiedene Faktoren beeinflussen die Architektur rund um ein maschinelles Lernmodell. Die dienende Architektur bietet einen soliden Bezugspunkt für weitere Diskussionen.
Glossar
In diesem Beitrag werden einige Definitionen immer wieder vorkommen. Diese Definitionen sind im Folgenden als Referenz aufgeführt und dienen dazu, die Diskussion über die Serving-Architekturen in den jeweiligen Abschnitten einzugrenzen.
- Vorhersage
Eine Vorhersage ist eine durch Anwendung einer Funktion (des Modells) auf Eingabedaten erzeugte Information. - Latenz
Die Latenz wird anhand der Zeit gemessen, die es dauert, bis eine Vorhersage den Benutzer in dem Moment erreicht, in dem sie angefordert wird. Es ist die Zeit, die für die Interaktion "Liest Vorhersagen" (siehe Abbildung 1) benötigt wird. - Durchsatz
Der Durchsatz ist die Anzahl der Vorhersagen, die pro Zeiteinheit gemacht werden können, z.B. 1000/Sekunde. - Vergänglichkeit
Die Vergänglichkeit einer Vorhersage ist die Zeit zwischen der Anforderung einer Vorhersage durch den Benutzer und dem Zeitpunkt, zu dem die Vorhersage berechnet wurde. Eine Vorhersage ist so veraltet wie die Eingabedaten und das Modell, das zu ihrer Berechnung verwendet wurde. - Zeitsensitivität
Die Zeitsensitivität ist definiert als der Wert Ihrer Vorhersagen in Abhängigkeit von der Veraltetheit. Wenn Vorhersagen sehr zeitempfindlich sind, haben veraltete Vorhersagen wenig Wert. Umgekehrt sind Vorhersagen mit geringer Zeitsensitivität über einen längeren Zeitraum hinweg wertvoll.
Wie wählen Sie Ihre Servierarchitektur?
Die folgenden Fragen bestimmen die Wahl der Architektur:
- Wie hoch ist die zeitliche Empfindlichkeit meiner Vorhersagen?
Die Häufigkeit der Erfassung von Eingabedaten schränkt den Grad der Zeitempfindlichkeit ein, der erfüllt werden kann. Je häufiger die Daten aufgenommen werden, desto mehr zeitempfindliche Anwendungsfälle können bedient werden. Dies lässt sich auf die Datenaufnahme in Echtzeit übertragen, die es uns ermöglicht, die Anwendungsfälle mit der höchsten Zeitsensibilität zu bedienen. Dies zeigt, dass die (Daten-)Infrastruktur, die Sie unterstützt, die Serving-Architektur einschränken kann. - Wie interagieren die Benutzer mit den Vorhersagen, die wir anbieten?
Wenn Sie verstehen, wie Ihr Modell verwendet wird, können Sie die Einschränkungen der Umgebung, in der Ihr Modell läuft, besser verstehen. Ihre Benutzer müssen möglicherweise Eingaben machen, damit das Modell seine Vorhersage treffen kann. Das bedeutet oft, dass sich Ihre Anwendung im kritischen Pfad der User Journey befindet. Dies hat Auswirkungen auf Ihre Architektur.
Batch Vorhersage
Ein Batch-Vorhersageauftrag ist ein Prozess, der für eine begrenzte Zeit auf einer begrenzten Menge von Daten läuft. Der Prozess wird in regelmäßigen Abständen ausgelöst. Die Grenzen des Datensatzes sind spezifisch für den Anwendungsfall. Batch-Prognosen werden in der Regel in einer SQL-Tabelle oder einer In-Memory-Datenbank gespeichert, um eine geringe Latenzzeit zu gewährleisten. 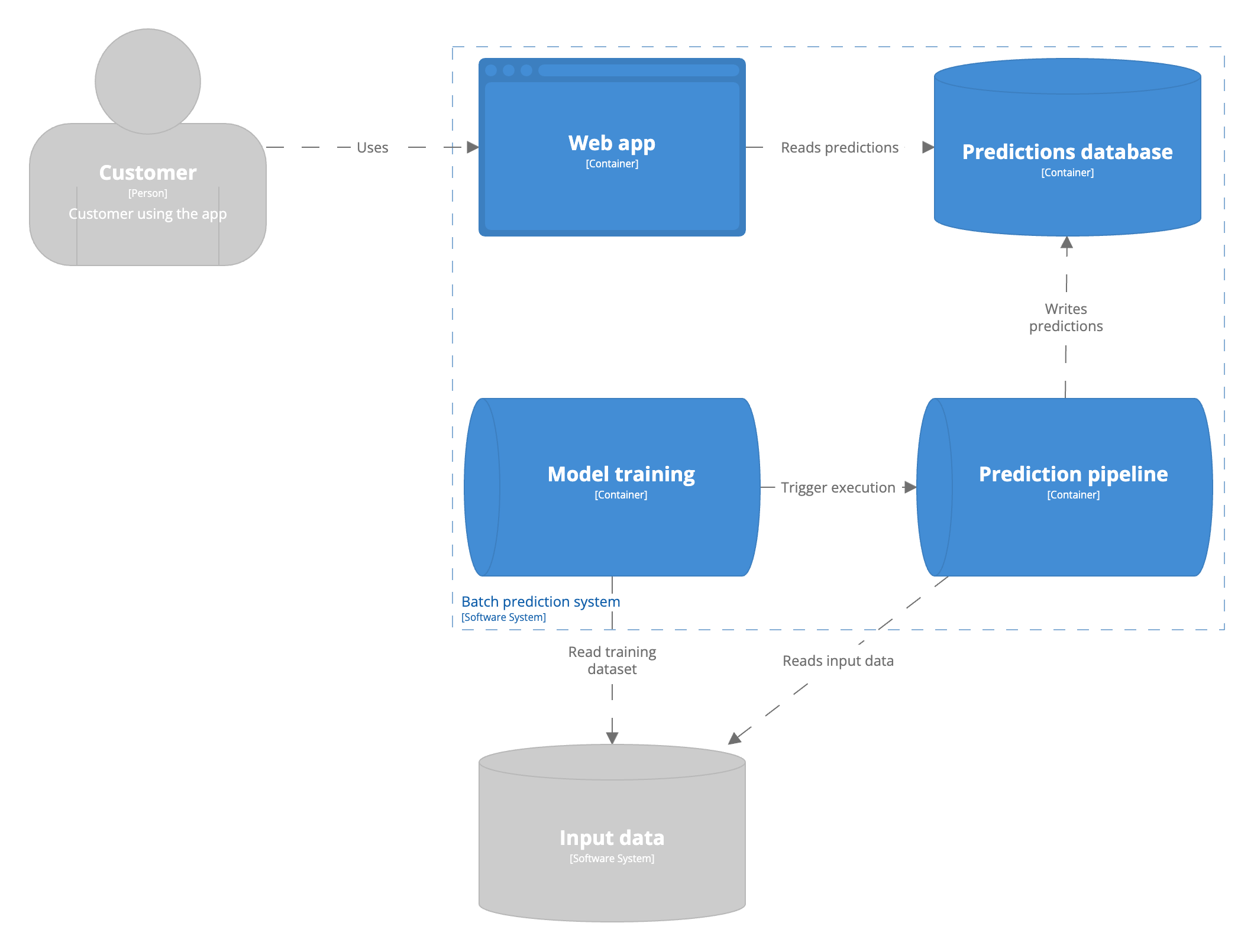 Die Bereitstellung von Batch-Vorhersagen wird manchmal auch als asynchrone Vorhersage bezeichnet. Das bedeutet, dass die Vorhersagen asynchron zur Benutzeranfrage berechnet werden. Dies führt dazu, dass die Vorhersagen, die dem Benutzer zur Verfügung gestellt werden, unbeständig sind. Alles, was zwischen der Berechnung und der Verwendung der Funktionen passiert ist, wird bei der Vorhersage für den Benutzer nicht berücksichtigt. Ein Beispiel: Ein E-Commerce-Unternehmen kann dem Benutzer auf seiner Website Produkte empfehlen. Die Empfehlungen werden alle paar Stunden berechnet und angezeigt, wenn sich ein Benutzer anmeldet. Alles, was innerhalb dieser wenigen Stunden bis zum nächsten Durchlauf geschieht, wird in den Empfehlungen nicht berücksichtigt. Das macht Batch-Modelle weniger anpassungsfähig an das veränderte Nutzerverhalten.
Die Bereitstellung von Batch-Vorhersagen wird manchmal auch als asynchrone Vorhersage bezeichnet. Das bedeutet, dass die Vorhersagen asynchron zur Benutzeranfrage berechnet werden. Dies führt dazu, dass die Vorhersagen, die dem Benutzer zur Verfügung gestellt werden, unbeständig sind. Alles, was zwischen der Berechnung und der Verwendung der Funktionen passiert ist, wird bei der Vorhersage für den Benutzer nicht berücksichtigt. Ein Beispiel: Ein E-Commerce-Unternehmen kann dem Benutzer auf seiner Website Produkte empfehlen. Die Empfehlungen werden alle paar Stunden berechnet und angezeigt, wenn sich ein Benutzer anmeldet. Alles, was innerhalb dieser wenigen Stunden bis zum nächsten Durchlauf geschieht, wird in den Empfehlungen nicht berücksichtigt. Das macht Batch-Modelle weniger anpassungsfähig an das veränderte Nutzerverhalten.
Das Servieren von Vorhersagen im Batch-Verfahren ist die einfachste Form des Modell-Serving. Die Serving-Architektur ist technisch gesehen ähnlich wie die Art und Weise, wie ein Modell trainiert wird. Die Berechnung von Vorhersagen im Batch-Verfahren ermöglicht es dem Team, die Vorhersagen zu überprüfen, bevor sie den Benutzern zugänglich gemacht werden. So können auch weniger erfahrene Teams Vertrauen in die von einem Modell erstellten Vorhersagen aufbauen. Verteilte Berechnungssysteme sind für viele Organisationen und Einzelpersonen allgemein zugänglich. Sie sind im Laufe der Jahre für die Verarbeitung großer Datenmengen optimiert worden. Batch-Prognosen sind ungeeignet, wenn die Domäne unbegrenzt ist. Die Domäne bezieht sich auf alle möglichen Eingabewerte. Stapelvorhersagen werden mit einem endlichen Datensatz durchgeführt und sind daher ungeeignet, wenn es keine Begrenzung für alle möglichen Eingabewerte gibt. Es ist zum Beispiel unmöglich, alle Eingabebilder für ein Bildklassifizierungsmodell zu kennen. Sie werden also niemals ein Bildklassifizierungsmodell im Batch-Modus bedienen. Schließlich können Batch-Berechnungen dazu dienen, die Latenzzeit zu verringern. Sie können alle Vorhersagen im Voraus berechnen und sie aus einer Datenbank bereitstellen, wenn der Benutzer sie anfordert, wenn die Berechnungszeit für die Vorhersage lang ist. Schließlich neigen Sie bei Batch-Vorhersagen dazu, mehr Vorhersagen zu berechnen, als Sie benötigen. Alle Vorhersagen werden berechnet, bevor sie ausgeliefert werden, aber Sie wissen nie, welche Vorhersagen Sie brauchen werden. Es gibt zwangsläufig Vorhersagen in der Datenbank, die nicht ausgeliefert werden, so dass ein Teil Ihrer Rechenleistung verschwendet wird.
Vorteile:
- Einfachheit
- Instandhaltbarkeit
- Hoher Durchsatz
- Geringe Latenz
Nachteile:
- Geringe Zeitempfindlichkeit
- Begrenzt auf begrenzte Domänen
- Kann Benutzereingaben nicht verarbeiten
- Es werden mehr Vorhersagen berechnet als bedient werden
Online-Synchrondienst
In dieser Model-Serving-Architektur wird ein Modell als zustandsloser Webserver gehostet und über einen HTTP- oder gRPC-Endpunkt bereitgestellt. Dies wird als synchrones Serving bezeichnet. Die Vorhersagen werden in dem Moment berechnet, in dem ein Benutzer sie anfordert. Die Vorhersagen werden aus Sicht des Benutzers synchron berechnet. Der Benutzer kann nicht mit der Anwendung fortfahren, bevor die Vorhersage zurückgegeben wird. Der Benutzer gibt in der Anfrage einen Teil oder alle Eingabemerkmale an. Das Modell kann zusätzliche Batch-Merkmale nutzen oder sowohl Batch- als auch Streaming-Merkmale verwenden. Es gibt einen Unterschied zwischen Modellen, die nur Batch-Funktionen und Streaming-Funktionen verwenden. Dies hat Auswirkungen auf die Serving-Architektur und die Anforderungen an die Infrastruktur. Bei beiden Modi kann es schwierig sein, die Latenzanforderungen zu erfüllen. Das Berechnen einer Modellvorhersage kann lange dauern. Dies kann gegen die Latenzanforderungen verstoßen, da die Vorhersage berechnet wird, wenn die Vorhersageanfrage gestellt wird. 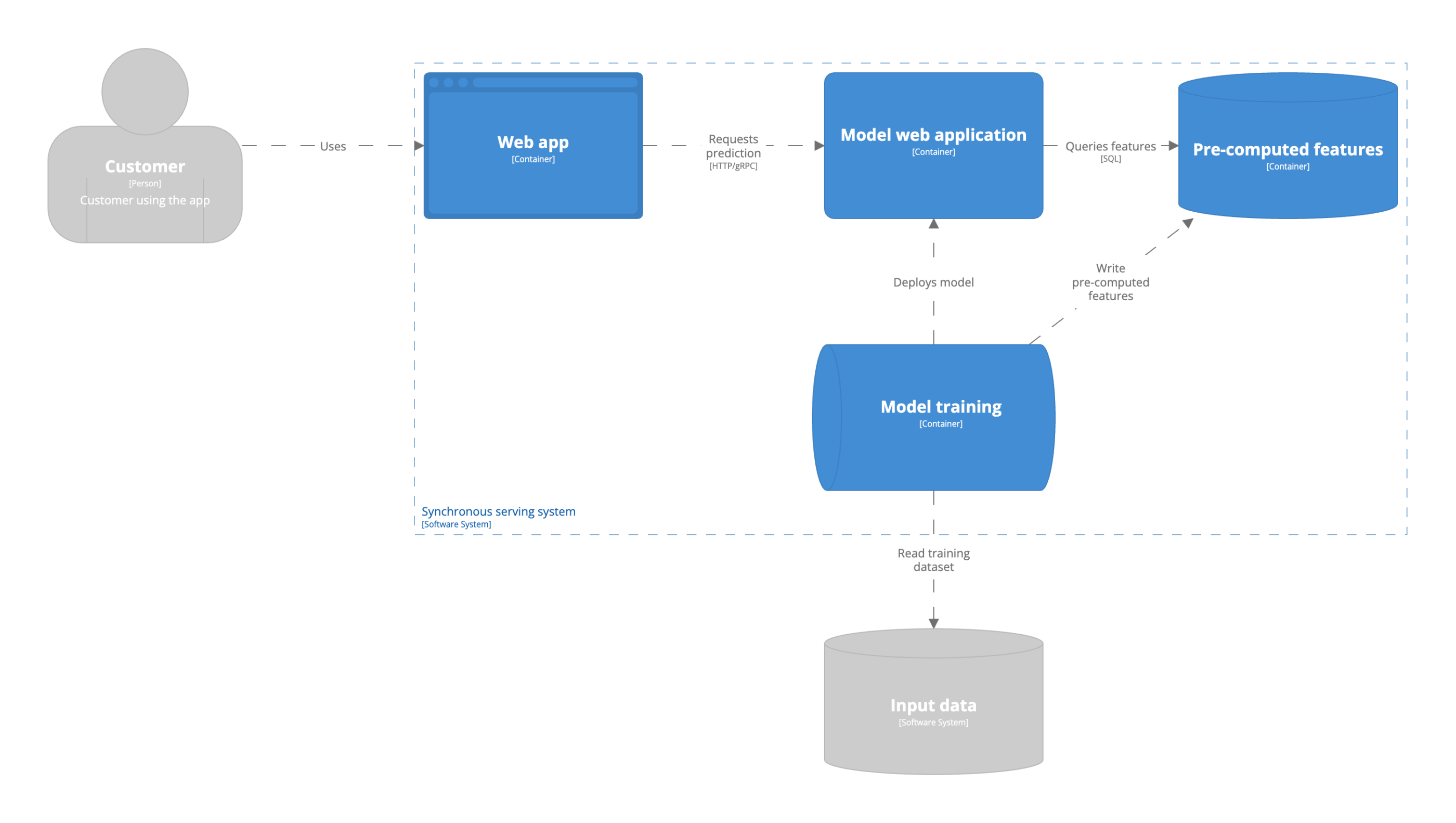
Batch-Funktionen
Genau wie die Batch-Vorhersagen werden auch die Batch-Features in regelmäßigen Abständen berechnet. Ein Beispiel für ein Batch-Feature ist die Anzahl der Besuche eines Benutzers auf einer Website im vergangenen Monat. Die Verwendung von Batch-Features in Modellen wird empfohlen, wenn sich die Features nur selten ändern. Die Datenverfügbarkeit der Eingabedaten, die zur Berechnung der Modellmerkmale verwendet werden, bestimmt, ob es sich bei Ihren Eingabedaten um Batch-Features handelt. Wenn Ihre Eingabedaten im Batch-Verfahren in das Data Warehouse eingespeist werden, handelt es sich bei Ihren Merkmalen um Batch-Merkmale. Ihre Architektur wird somit von den Einschränkungen der Umgebung, in der Sie arbeiten, bestimmt.
Vorteile:
- Einfachheit
- Unbegrenzter Bereich
- Kann Benutzereingaben verarbeiten
Nachteile:
- Zeitliche Sensibilität
- Durchsatz
- Latenzzeit
Batch- und Streaming-Funktionen
Streaming-Funktionen sind Funktionen, die in Echtzeit mit geringer Latenzzeit aktualisiert werden. Die Verwendung von Streaming-Funktionen erfordert, dass Ihr Unternehmen Architekturen zur Verarbeitung von Streaming-Daten unterstützt. Eine Streaming-Funktion könnte die Artikel sein, die ein Benutzer in der aktuellen Sitzung durchsucht hat. Wie bereits erwähnt, läuft das Modell immer noch als Teil eines zustandslosen Webservers. Die Merkmale, die das Modell als Eingabe für die Berechnung einer Vorhersage verwendet, stammen jedoch aus einer Datenbank, die in Echtzeit durch Streaming Data Pipelines aktualisiert wird. In diesen Szenarien verwenden Unternehmen häufig einen Feature-Store. Das Konzept und die Anforderungen an einen Feature Store werden in diesem Blogbeitrag nicht erörtert. Der Einfachheit halber gehen wir davon aus, dass der Feature Store in der Architektur Batch- und Streaming-Features miteinander in Einklang bringt und der Anwendung eine einheitliche Schnittstelle zur Abfrage beider bietet. 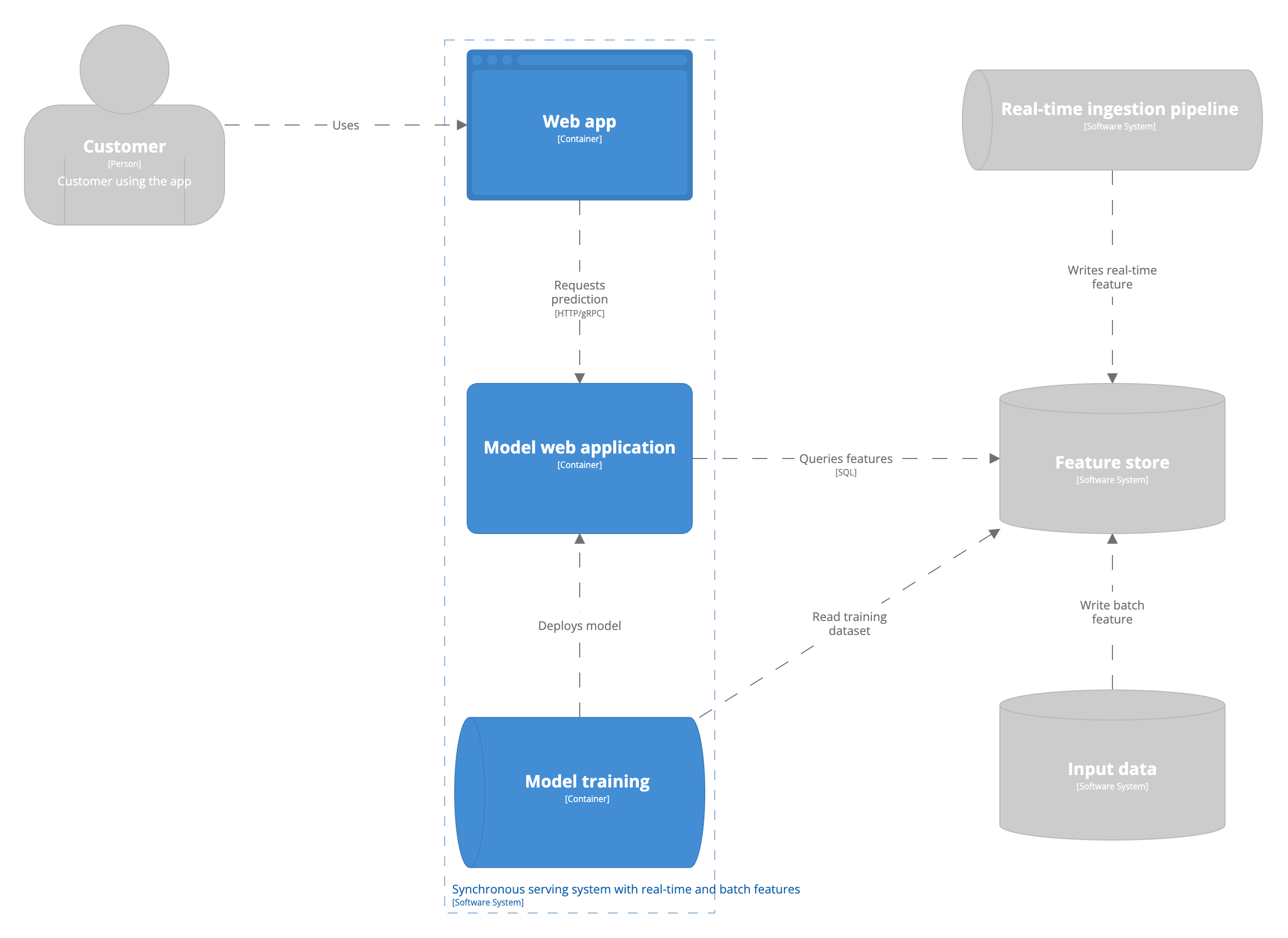 Der Hauptvorteil der Nutzung von Streaming-Funktionen ist die Fähigkeit, sich schnell an Änderungen der Benutzerpräferenzen anzupassen. Sie haben immer die aktuellste Sicht auf die Welt, die Ihrem maschinellen Lernmodell zur Verfügung steht, um Vorhersagen zu treffen. Kehren wir zu dem früheren Beispiel des E-Commerce-Unternehmens zurück. Im Beispiel der Batch-Vorhersage wird keine der Benutzeraktivitäten zwischen dem letzten Lauf und dem nächsten Lauf der Batch-Pipeline in der Vorhersage erfasst. Die Echtzeit-Datenpipeline verfolgt die Benutzerinteraktionen in Echtzeit und das Modell hat über einen Feature Store Zugriff auf diese Merkmale. Durch den Zugriff auf die Artikel, die ein Benutzer während seiner aktuellen Sitzung angesehen hat, kann unser Empfehlungsprogramm relevantere Produkte vorschlagen.
Der Hauptvorteil der Nutzung von Streaming-Funktionen ist die Fähigkeit, sich schnell an Änderungen der Benutzerpräferenzen anzupassen. Sie haben immer die aktuellste Sicht auf die Welt, die Ihrem maschinellen Lernmodell zur Verfügung steht, um Vorhersagen zu treffen. Kehren wir zu dem früheren Beispiel des E-Commerce-Unternehmens zurück. Im Beispiel der Batch-Vorhersage wird keine der Benutzeraktivitäten zwischen dem letzten Lauf und dem nächsten Lauf der Batch-Pipeline in der Vorhersage erfasst. Die Echtzeit-Datenpipeline verfolgt die Benutzerinteraktionen in Echtzeit und das Modell hat über einen Feature Store Zugriff auf diese Merkmale. Durch den Zugriff auf die Artikel, die ein Benutzer während seiner aktuellen Sitzung angesehen hat, kann unser Empfehlungsprogramm relevantere Produkte vorschlagen.
Vorteile:
- Unbegrenzter Bereich
- Zeitliche Sensibilität
Nachteile:
- Durchsatz
- Komplexität
- Fehlersuchbarkeit / Rückverfolgbarkeit
- Latenzzeit
Asynchrone Online-Vorhersagen
Diese Serving-Architektur wird auch als Echtzeit- oder Streaming-Serving bezeichnet. Die Prognosen werden anhand eines unendlichen Stroms von Eingabedaten mit geringer Latenz berechnet. Das Modell ist immer verfügbar, um Prognosen für neue Eingabedaten zu erstellen. Daher die Online-Komponente in der Definition im Gegensatz zu Batch-Prognosen. Die Vorhersagen werden aus Sicht des Benutzers asynchron berechnet. Die Benutzer fordern die Vorhersagen nicht direkt an. Die Vorhersagen werden asynchron zur Interaktion mit der Anwendung bereitgestellt. 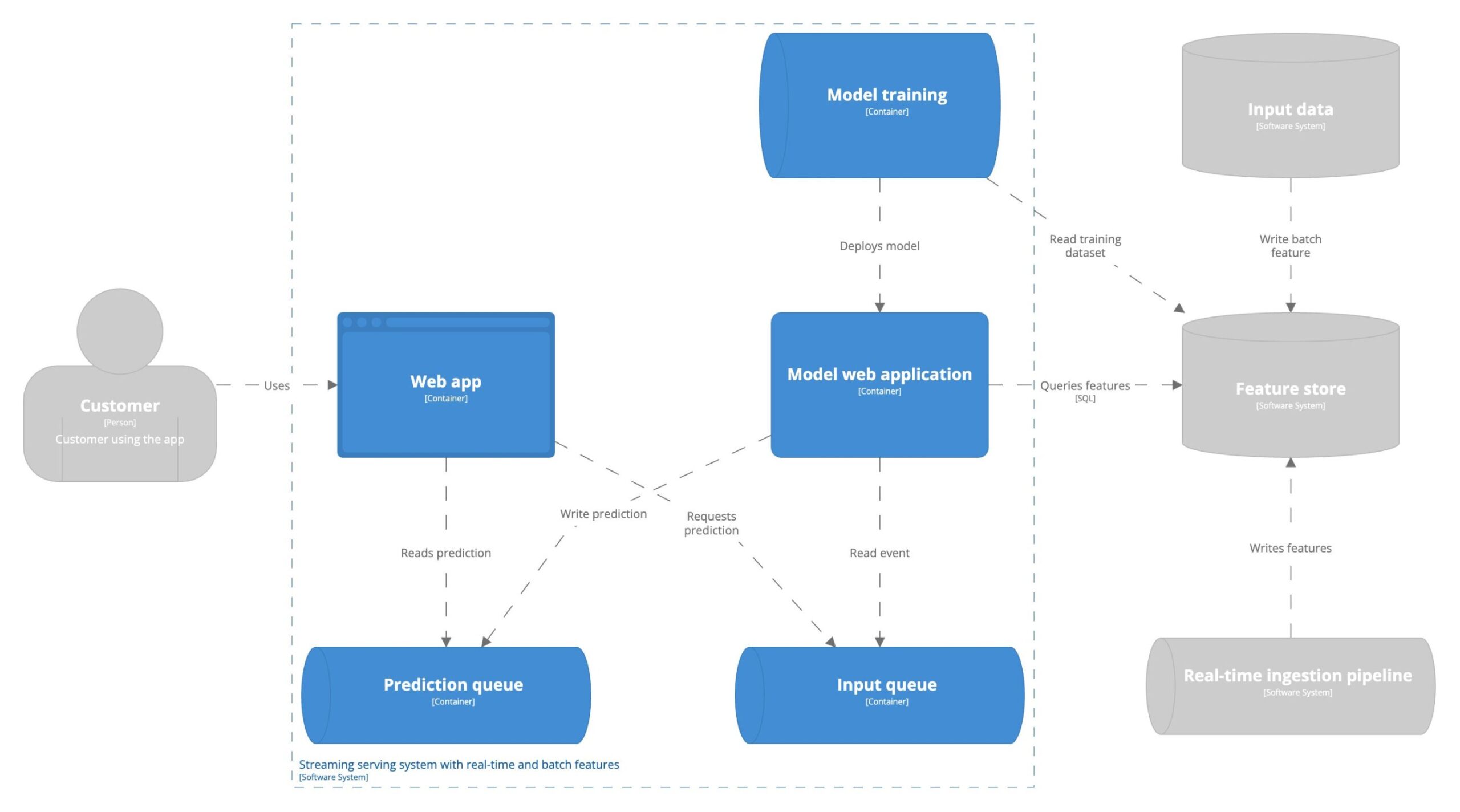 Es mag den Anschein erwecken, als sei die Umstellung auf Streaming-Vorhersagen das ultimative Ziel, um den größten geschäftlichen Nutzen zu erzielen. Aber wie bei allen architektonischen Entscheidungen kommt es auch hier darauf an. Stellen Sie sich vor, Sie arbeiten bei einer Bank und betreiben eine Vorhersage-Pipeline, um Geldwäsche zu erkennen. Dabei handelt es sich um mehrere aufeinanderfolgende Aktionen, die sich über Wochen, Monate oder sogar Jahre erstrecken. Wenn eine Person als Geldwäscher identifiziert wird, kann nicht sofort gehandelt werden. Es reicht also aus, diese Pipeline jede Woche oder jeden Monat im Batch-Verfahren laufen zu lassen.
Es mag den Anschein erwecken, als sei die Umstellung auf Streaming-Vorhersagen das ultimative Ziel, um den größten geschäftlichen Nutzen zu erzielen. Aber wie bei allen architektonischen Entscheidungen kommt es auch hier darauf an. Stellen Sie sich vor, Sie arbeiten bei einer Bank und betreiben eine Vorhersage-Pipeline, um Geldwäsche zu erkennen. Dabei handelt es sich um mehrere aufeinanderfolgende Aktionen, die sich über Wochen, Monate oder sogar Jahre erstrecken. Wenn eine Person als Geldwäscher identifiziert wird, kann nicht sofort gehandelt werden. Es reicht also aus, diese Pipeline jede Woche oder jeden Monat im Batch-Verfahren laufen zu lassen.
Vorteile:
- Durchsatz
- Zeitliche Sensibilität
- Robustheit
- Lang laufende Berechnungen
Nachteile:
- Komplexität
Beispiel
Lassen Sie uns das anhand eines Beispiels erläutern. Stellen Sie sich vor, Sie arbeiten für eine Bank. Sie müssen Transaktionen in Kategorien einordnen, um den Benutzern Einblicke in ihre Ausgaben zu geben. Wir möchten, dass die Benutzer eine Transaktion auch dann abschließen können, wenn die Klassifizierung fehlschlägt. Die Klassifizierung der Transaktion liegt nicht im kritischen Pfad der Transaktion, so dass die Klassifizierung asynchron berechnet werden kann.
Streaming-Vorhersagen haben zwei wesentliche Vorteile gegenüber der synchronen Zustellung: Durchsatz und Robustheit. Der Kompromiss ist die Systemkomplexität. Streaming-Vorhersagen nutzen Message Broker, um den Dienst, der die Vorhersage anfordert, und den Dienst, der die Vorhersage liefert, zu entkoppeln. Die Einführung des Message Brokers erhöht die Fehlertoleranz des Systems und macht das System robuster gegenüber Widrigkeiten. Der Message Broker macht das System komplexer, was die Überwachung und die Wartbarkeit angeht.
Fazit
In diesem Blog-Beitrag haben Sie erfahren, was die Entscheidung für eine Model-Serving-Architektur beeinflusst. Sie haben progressiv komplexere Architekturen kennengelernt. Sie haben verschiedene konkrete Anwendungsfälle gesehen, bei denen die jeweilige Architektur einen Mehrwert bietet. Die High-Level-Architekturdiagramme veranschaulichen die Komponenten, die in einem maschinellen Lernsystem eine Rolle spielen. Sie sind nun in der Lage, die Anforderungen für Ihr Projekt zu analysieren und die richtige Model-Serving-Architektur auszuwählen.
Verfasst von
Roy van Santen
Unsere Ideen
Weitere Blogs




Contact