Intro
Maschinelles Lernen wird heute von Tausenden von Unternehmen genutzt. Seine Allgegenwart hat dazu beigetragen, Innovationen voranzutreiben, die immer schwieriger vorherzusagen sind, und intelligente Erfahrungen für die Produkte und Dienstleistungen eines Unternehmens zu schaffen. Machine Learning ist zwar überall zu finden, bringt aber auch viele Herausforderungen mit sich, wenn es darum geht, es tatsächlich zu implementieren. Eine dieser Herausforderungen besteht darin, schnell und zuverlässig von der Experimentierphase, in der die Modelle des maschinellen Lernens entwickelt werden, in die Produktionsphase überzugehen, in der die Modelle genutzt werden können, um einen Mehrwert für das Unternehmen zu schaffen.
Die Industrie bietet viele Tools, die sich dieser Herausforderung stellen. Öffentliche Cloud-Angebote haben ihre eigenen verwalteten Lösungen für die Bereitstellung von Machine Learning-Modellen und gleichzeitig gibt es eine Fülle von Open Source-Projekten, die sich ebenfalls darauf konzentrieren. In diesem Beitrag, dem ersten der Serie, vergleichen wir Open-Source-Tools, die auf Kubernetes laufen, um Ihnen die Entscheidung zu erleichtern, welches Tool Sie für das Machine Learning Model Serving in Ihrem Unternehmen verwenden sollten.
Vergleich einrichten
Wir haben unsere Forschung auf 9 Hauptbereiche von Modellierungswerkzeugen konzentriert:
- die Fähigkeit, Modelle aus Standard-Frameworks zu verwenden, einschließlich Scikit-Learn, PyTorch, Tensorflow und XGBoost
- Fähigkeit, benutzerdefinierte Modelle / Modelle aus Nischen-Frameworks zu bedienen
- Fähigkeit zur Vorverarbeitung/Nachbearbeitung von Daten
- Auswirkungen auf den Entwicklungsablauf und die bestehende Codebasis
- die Verfügbarkeit der Dokumentation
- DevOps-Betriebsfähigkeit
- Autoskalierungsfunktionen
- verfügbare Schnittstellen für die Erstellung von Prognosen
- Verwaltung der Infrastruktur
Die Tools, die wir in diesem Beitrag zum Vergleich ausgewählt haben, sind: KServe, Seldon Core und BentoML. Der nächste Beitrag wird sich mit Cloud-basierten, verwalteten Serving-Tools befassen.
Um die Tools zu vergleichen, haben wir ein ML-Projekt aufgesetzt, das eine Standard-Pipeline umfasste: Laden der Daten, Vorverarbeitung der Daten, Aufteilung des Datensatzes sowie Training und Testen des Regressionsmodells. Die Pipeline erforderte, dass die Modellinferenz einen Vorverarbeitungsschritt (Aufruf einer benutzerdefinierten Python-Funktion) enthielt, so dass verschiedene Aspekte der verwendeten Tools getestet werden konnten. Die Pipeline selbst ermöglichte es, das Modell einfach auszutauschen, so dass verschiedene Modellierungs-Frameworks verwendet werden konnten.
Hoher Überblick über die Tools für die Bereitstellung von Machine Learning-Modellen
KServe
KServe (vor der Version 0.7 hieß es KFServing) ist ein Open-Source-Tool auf Kubernetes-Basis, das eine benutzerdefinierte Abstraktion (Kubernetes Custom Resource Definition) zur Definition von Machine Learning Model Serving-Fähigkeiten bietet. Das Hauptaugenmerk liegt darauf, die zugrunde liegende Komplexität solcher Bereitstellungen zu verbergen, so dass sich die Benutzer nur auf die ML-bezogenen Teile konzentrieren müssen. Es unterstützt viele fortschrittliche Funktionen wie automatische Skalierung, Skalierung bis zum Nullpunkt, Canary-Bereitstellungen, automatische Stapelverarbeitung von Anfragen sowie viele gängige ML-Frameworks out-of-the-box. Es wird von Unternehmen wie Bloomberg, NVIDIA, Samsung SDS und Cisco verwendet.
Seldon Kern
Seldon Core ist ein Open Source-Tool, das von Seldon Technologies Ltd. als Baustein der größeren (kostenpflichtigen) Lösung Seldon Deploy entwickelt wurde. Vom Ansatz her ist es ähnlich wie KServe - es bietet Kubernetes CRD auf hohem Niveau und unterstützt Canary-Bereitstellungen, A/B-Tests sowie Multi-Armed-Bandit-Bereitstellungen.
BentoML
BentoML ist ein Python-Framework zum Verpacken von Modellen für maschinelles Lernen in einsatzfähige Dienste. Es bietet eine einfache objektorientierte Schnittstelle für die Verpackung von ML-Modellen und die Erstellung von HTTP(s)-Diensten für sie. BentoML bietet eine tiefgreifende Integration mit gängigen ML-Frameworks, so dass die gesamte Komplexität im Zusammenhang mit der Paketierung der Modelle und ihrer Abhängigkeiten ausgeblendet wird. Mit BentoML verpackte Modelle können in vielen Laufzeiten eingesetzt werden, darunter einfache Kubernetes-Cluster, Seldon Core, KServe, Knative sowie Cloud-verwaltete, serverlose Lösungen wie AWS Lambda, Azure Functions oder Google Cloud Run.
Der Vergleich umfasst die Beschreibung jedes Bereichs innerhalb jedes Tools sowie die Visualisierung, wie gut das Tool diesen Bereich abdeckt. Die Skala ist subjektiv und basiert auf dem Aufwand, der erforderlich ist, um das jeweilige Ziel zu erreichen. Je weiter rechts (grüner Bereich), desto besser wird der Aspekt durch das Tool abgedeckt.
Bedienung von Standardmodellen
Dieser Bereich des Vergleichs konzentrierte sich auf die Fähigkeiten der Tools, Modelle zu bedienen, die in einem der beliebten Frameworks trainiert wurden, darunter: Scikit-Learn, PyTorch, TensorFlow und XGBoost.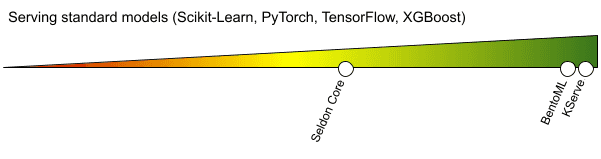
KServe
Alle getesteten Frameworks sind recht einfach zu bedienen. Standard-Frameworks sind in KServe ein Bürger erster Klasse, da es vorgefertigte Docker-Images für ihre Ausführung sowie eine direkte Definition im InferenceService (von KServe definierte benutzerdefinierte Ressource für Kubernetes) bietet.
Normalerweise muss eine Konfigurationsdatei vorbereitet werden, um die Modelle ordnungsgemäß zu starten.
Seldon Kern
Seldon Core kann problemlos Scikit-Learn, XGBoost und TensorFlow Modelle bedienen. Es gibt keine eingebaute Unterstützung für PyTorch, was über Triton Server erreicht werden könnte, aber viel zusätzlichen Aufwand erfordert und die Verwendung des v2-Protokolls von Seldon voraussetzt. Die Verwendung des v2-Protokolls wird auch bei der Verwendung von MLServer (der neuen empfohlenen Methode zur Bereitstellung von Modellen mit Seldon Core) erzwungen, was zu einigen Herausforderungen im nachgelagerten Bereich führt - siehe den Abschnitt über Preprocessing/Postprocessing unten.
BentoML
Die Verwendung von BentoML läuft darauf hinaus, eine benutzerdefinierte Python-Klasse zu implementieren, die von der Klasse des Frameworks erbt, so dass jedes Python-Framework verwendet werden kann. Es gibt eine eingebaute Unterstützung für alle Standard-Frameworks, die die Serialisierung und Deserialisierung von Modellen, Abhängigkeiten sowie die Verarbeitung von Ein- und Ausgaben übernimmt. Es ist wirklich einfach, die BentoService-Klassenschnittstelle von BentoML zu implementieren, was in der Regel mit wenigen Zeilen Code auskommt.
Kundenspezifische Modelle servieren
Die Arbeit eines DataScientists darf nicht durch die verwendeten Frameworks eingeschränkt werden. Es ist wichtig, dass die Serving-Lösung jedes benutzerdefinierte Framework und jeden Code unterstützt. 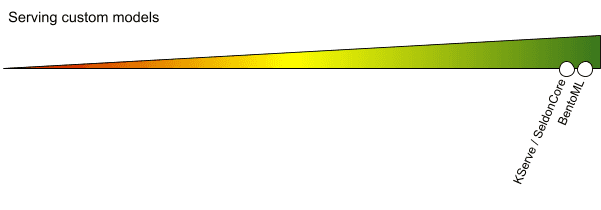
KServe
KServe erlaubt die Verwendung eines beliebigen Docker-Images als Teil des Deployments, so dass im Grunde jedes Framework/jeder Code/jede Sprache (bis zu einem gewissen Grad) verwendet werden kann. Das Tool stellt dem Python SDK eine abstrakte Klasse (KFModel) zur Verfügung, die vererbt werden kann, um die Integration des eigenen Codes zu erleichtern.
Seldon Kern
Ähnlich wie bei KServe kann jedes Docker-Image verwendet werden. Der Unterschied zwischen Seldon Core und KServe in diesem Bereich besteht darin, dass KServe das SDK mit Klassen bereitstellt, die implementiert werden müssen, während Seldon das SDK mit Klassen bereitstellt, die implementiert werden können (SeldonComponent), aber man kann sich auch für das Duck-Typing von Python entscheiden.
BentoML
Da die Verwendung von BentoML die Implementierung von Python-Code erfordert, kann jede Anpassung damit vorgenommen werden.
Fähigkeit zur Vorverarbeitung/Nachbearbeitung von Daten
Bei Machine Learning-Modellen in der realen Welt müssen die Eingabedaten in der Regel auf irgendeine Weise vorverarbeitet werden, entweder um Merkmale zu extrahieren, die Werte zu normalisieren oder die Daten zu transformieren. Es ist wichtig, dass die Tools, die für das Modell verwendet werden, eine Möglichkeit bieten, die Daten vor oder nach ihrer Verarbeitung in das Modell einzubinden. 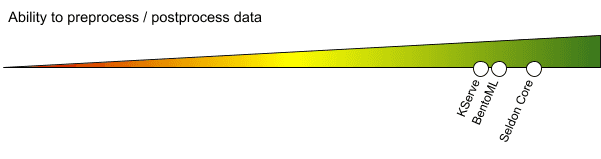
KServe
Die InferenceService-Abstraktion in KServe ermöglicht die Spezifikation eines Transformers, der sowohl die Vor- als auch die Nachverarbeitung der Daten übernehmen kann. Die Implementierung erfordert die Vorbereitung eines benutzerdefinierten Docker-Images mit einer aus dem SDK von KServe geerbten Klasse, ähnlich wie bei der Implementierung benutzerdefinierter Modelle.
Seldon Kern
Neben der standardmäßigen Vor- und Nachverarbeitung, die als TRANSFORMER definiert und als Python-Klasse implementiert werden kann (mit Vererbung oder Duck-Typing, siehe "Bedienung von benutzerdefinierten Modellen"), bietet Seldon Core die Abstraktion von Inferenzgraphen. Dazu gehören nicht nur Datentransformationen, sondern auch benutzerdefinierte ROUTER (z.B. die dynamische Entscheidung, an welches der vielen Modelle, die Teil desselben SeldonDeployments sind, die Daten gesendet werden sollen) sowie COMBINER, mit denen Sie ein Ensemble von Modellen direkt aus dem Deployment erstellen können. Dank dieser Funktionalität sind Multi-Armed-Bandit-Einsätze leicht zu realisieren. Beachten Sie bitte, dass bei der Verwendung von MLServer oder Triton Server keine Transformationen möglich sind - siehe ein entsprechendes GitHub-Problem https://github.com/SeldonIO/MLServer/issues/287.
BentoML
Wie in den vorangegangenen Bereichen kann jeder Code als Teil der BentoML-Bereitstellung ausgeführt werden.
Auswirkungen auf den Entwicklungs-Workflow und die bestehende Code-Basis
Hier konzentrieren wir uns darauf, ob die Verwendung der Tools Änderungen im Entwicklungs-Workflow erfordert (z. B. die Anpassung an einen neuen Satz von APIs, einige Änderungen im bestehenden CI/CD-Setup, die Änderung des Trainingscodes und die Verwendung neuer Artefaktspeicher für Modelle usw.).
KServe
KServe lässt sich gut in bestehende DevOps-Pipelines für die Bereitstellung integrieren (ob direkt aus Kubernetes-Manifesten, Helm Charts oder anderen), da die Bereitstellung eine einfache Ressourcendefinition erfordert. Aus Sicht der Data Scientists/Machine Learning Engineers sind die Anpassungen eher minimal - Modelle können von jedem Cloud-Speicher wie S3 oder GCS bereitgestellt werden. Bestehende CI/CD-Pipelines, die Docker-Images erstellen, können intakt bleiben. Änderungen an den Docker-Images selbst sind optional und nur erforderlich, wenn ein benutzerdefinierter Code gestartet werden muss.
Seldon Kern
Ähnlich wie KServe hat Seldon Core keine Auswirkungen auf die bestehenden DevOps/Software Engineering Arbeitsabläufe. Die Bereitstellung erfolgt über Kubernetes-Manifeste. Solange eines der unterstützten Frameworks verwendet wird, ist nur ein minimaler Aufwand für die Data Scientists / Machine Learning Engineers erforderlich. Jegliche Anpassung oder die Verwendung von Nicht-Standard-Frameworks kann jedoch den Arbeitsablauf verkomplizieren und einige der Funktionen könnten nicht mehr verfügbar sein (da sie noch nicht implementiert sind, siehe "Fähigkeit zur Vor-/Nachbearbeitung von Daten").
BentoML
Obwohl die Implementierung von Python-Klassen keine schwierige Aufgabe ist, erfordert der Prozess der Bereitstellung von BentoML-basierten Diensten für die Ausführungsumgebung (z. B. einen Kubernetes-Cluster) Änderungen in der CI/CD-Pipeline. BentoML speichert die von BentoService geerbte Klasse mit einem serialisierten Modell, Python-Code und allen Abhängigkeiten in einem separaten Archiv/Verzeichnis. Das Archiv enthält eine Dockerdatei, mit der Sie ein eigenständiges Serving-Container-Image erstellen können. Da das BentoML-Archiv als Artefakt erstellt wird, muss die CI/CD-Pipeline es konsumieren und einen weiteren Build auslösen. Aus der Perspektive der Bereitstellung muss alles manuell gehandhabt werden, was im Falle von Kubernetes das Schreiben von Bereitstellungsdefinitionen bedeutet.
Verfügbarkeit der Dokumentation
Eine schnelle Anpassung der Serving-Tools ist nur möglich, wenn eine gute Dokumentation bereitgestellt wird. Die Unterstützung der Community über GitHub/Slack wurde ebenfalls in Betracht gezogen. 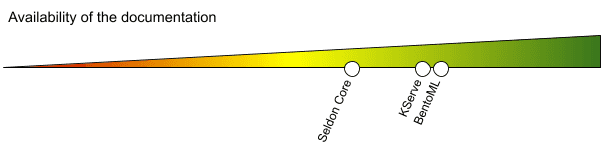
KServe
Die Dokumentation deckt die wichtigsten Aspekte ab. Bei nicht-trivialen Anwendungsfällen müssen Sie in den GitHub-Themen recherchieren oder andere in einem Slack-Kanal fragen, in dem die Community recht aktiv ist.
Seldon Kern
Die Dokumentation deckt meist triviale Anwendungsfälle ab, viele Links führen zu 404-Seiten. Fortgeschrittene Szenarien finden Sie auf GitHub, aber einige von ihnen sind veraltet.
BentoML
Ziemlich solide Dokumentation mit vielen aktuellen Beispielen. Sowohl der Code als auch die Konzepte sind gut beschrieben.
DevOps-Betriebsfähigkeit
Nach der Bereitstellung sind die DevOps-Teams in der Regel für die Überwachung und Wartung der Produktionsanwendungen verantwortlich. Die Model-Serving-Tools müssen für die DevOps zugänglich sein, um wiederholbare Implementierungen zu ermöglichen, die Überwachung zu gewährleisten und Möglichkeiten zur Diagnose von Problemen zu bieten, die zur Laufzeit unter hoher Last auftreten können. 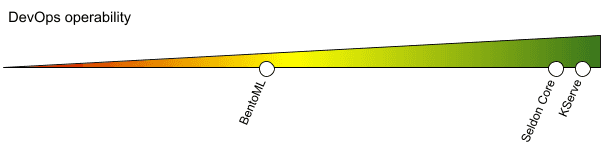
KServe
Der Stack des KServe basiert auf gut etablierten Open Source-Tools: KNative und Istio, die zuerst auf Dev-Ops und dann auf Kubernetes ausgerichtet sind. Die Überwachung basiert auf dem weit verbreiteten Prometheus. Einsätze können mit jeder Kubernetes-kompatiblen Lösung durchgeführt werden, sei es direkt von kubectl, Helm oder Helmsman. Die Protokollierung ist leicht konfigurierbar und die Meldungen sind in der Regel aussagekräftig. Canary-Bereitstellungen sind sofort verfügbar.
Seldon Kern
Seldon erfordert nur, dass Istio oder Ambassador verfügbar sind, um zu funktionieren. Die Überwachung erfolgt ebenfalls über Prometheus. Ähnlich wie bei KServe kann jede Kubernetes-Bereitstellungslösung verwendet werden. Die Protokollierung kann einfach konfiguriert werden, aber für einige Teile gibt es überhaupt keine Protokolle. Canary-Bereitstellungen sowie A/B-Test-Bereitstellungen sind sofort verfügbar.
BentoML
Da BentoML code-first ist, kann die Unterstützung für DevOps dank zahlreicher Integrationen mit Tracing-Tools (z.B. Jaeger) und Monitoring (Prometheus) konfiguriert werden. Sowohl die Konfiguration als auch die Bereitstellung in Kubernetes erfordert jedoch eine manuelle Implementierung. BentoML kann jedoch mit vielen bestehenden Serving-Lösungen oder sogar dienstlosen Diensten verwendet werden, da das Endergebnis am Ende ein einfaches Docker-Image ist.
Automatische Skalierungsfunktionen
Die eingesetzten Modelle sollten nicht nur in Bezug auf die Qualität ihrer Vorhersagen, sondern auch in Bezug auf ihren Durchsatz den geschäftlichen Anforderungen entsprechen. Serving-Lösungen sollten es den Modellen ermöglichen, sich zu vergrößern, wenn der Datenverkehr in die Höhe schießt, und sich zu verkleinern, wenn er sich wieder normalisiert. 
KServe
Dank der engen Integration mit KNative bietet KServe erstklassige Funktionen für die automatische Skalierung. Eingesetzte Modelle können nicht nur anhand der CPU-Auslastungsmetrik von Kubernetes hochskaliert werden, sondern auch anhand von Metriken auf hoher Ebene wie Anfragen pro Sekunde oder Gleichzeitigkeit (wie viele Anfragen gleichzeitig von einem einzelnen Container mit dem Modell verarbeitet werden können). KServe bietet auch eine Skalierung bis zum Nullpunkt mit schneller Aktivierung, was es einfacher macht, die Gesamtkosten des Clusters niedrig zu halten. Es gibt auch eine integrierte Unterstützung für die automatische Stapelverarbeitung von Anfragen, die dazu beiträgt, die Ressourcen der Pods besser zu nutzen.
Seldon Kern
Da Seldon Core Kubernetes-nativ ist, kann ein standardmäßiger Horizontal Pod Autoscaler mit Metriken wie CPU- und Speichernutzung verwendet werden. Wenn ereignisbasierte Metriken verwendet werden sollen, ist eine zusätzliche Installation von KEDA und die Integration mit KEDA erforderlich. Durch die Integration mit KEDA wird Scale-to-Zero über KEDA-native Ereignisquellen möglich. HTTP scale-to-zero erfordert weitere Add-ons für KEDA.
BentoML
Da BentoML ein Code-first-Framework ist, bietet es keine automatischen Skalierungsfunktionen, da diese ausschließlich von der gewählten Laufzeitumgebung abhängen (BentoML kann auf KServe, Seldon Core, SageMaker Endpoints und vielen anderen Cloud-Lösungen eingesetzt werden). Das Framework unterstützt jedoch die automatische Stapelverarbeitung von Anfragen, wodurch sich die Serving-Leistung nach der Bereitstellung (bis zu einem gewissen Grad) anpassen lässt.
Verfügbare Schnittstellen für die Erstellung von Prognosen
Normalerweise werden Modelle als HTTP(s)-basierte Dienste mit JSON-Eingabe/Ausgabe bereitgestellt. Verschiedene Anwendungsfälle können andere Anfrage-/Antwortformate oder die Verwendung schnellerer, binärer Protokolle wie GRPC erfordern, so dass die Serving Tools auch diese unterstützen sollten. 
KServe
Obwohl KServe keine Beschränkung bei den verwendeten Protokollen vorsieht, ist die Standard-Serving-Methode HTTP-basiert. Nicht-Json-Eingaben/Ausgaben erfordern einen benutzerdefinierten Transformer. Die Konfiguration erlaubt die Verwendung von GRPC oder anderen Protokollen, aber die Handhabung solcher Protokolle erfordert eine manuelle, kundenspezifische Implementierung.
Seldon Kern
Ähnlich wie KServe schränkt auch Seldon Core die Verwendung von Protokollen nicht ein. Darüber hinaus bietet es Standardimplementierungen sowohl für HTTP- als auch für GRPC-Serving-Methoden, so dass jedes eingesetzte Modell automatisch sowohl auf HTTP- als auch auf GRPC-Anfragen reagieren kann. Anfrage- und Antwortformate können über eine benutzerdefinierte Implementierung in TRANSFORMER behandelt werden.
BentoML
Es wird nur HTTP unterstützt (GRPC scheint veraltet zu sein https://github.com/bentoml/BentoML/issues/703 ). Auch hier gilt: Da BentoML von Anfang an auf Code basiert, ist die Bearbeitung jeder Art von Anfrage möglich. Das Framework bietet einige vorimplementierte Bearbeitungsmethoden, so dass Anfragen von CSVs, JSON und anderen geparst werden können.
Verwaltung der Infrastruktur
Zu guter Letzt konzentriert sich dieser Bereich des Vergleichs von Model Serving Tools auf die Verwaltung der Infrastruktur - er berücksichtigt den Aufwand, der für den Betrieb des jeweiligen Tools in der Produktion und in großem Umfang erforderlich ist.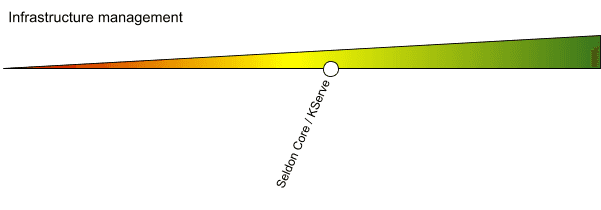
KServe / Seldon Kern
Beide Tools verlassen sich bei der Verwaltung der Infrastruktur vollständig auf den zugrunde liegenden Kubernetes-Cluster. Wenn Kubernetes in der Cloud verwaltet wird, könnte der Prozess den Infrastructure-as-a-Code-Ansatz beinhalten. Die Tools selbst haben keinen großen Druck auf die Ressourcenanforderungen, wenn sie in bestehenden Clustern eingesetzt werden.
BentoML
BentoML hängt von dem gewählten Einsatzziel ab und wird daher in diesem Bereich nicht berücksichtigt, da der Aufwand für den Betrieb zwischen gering und hoch variieren kann.
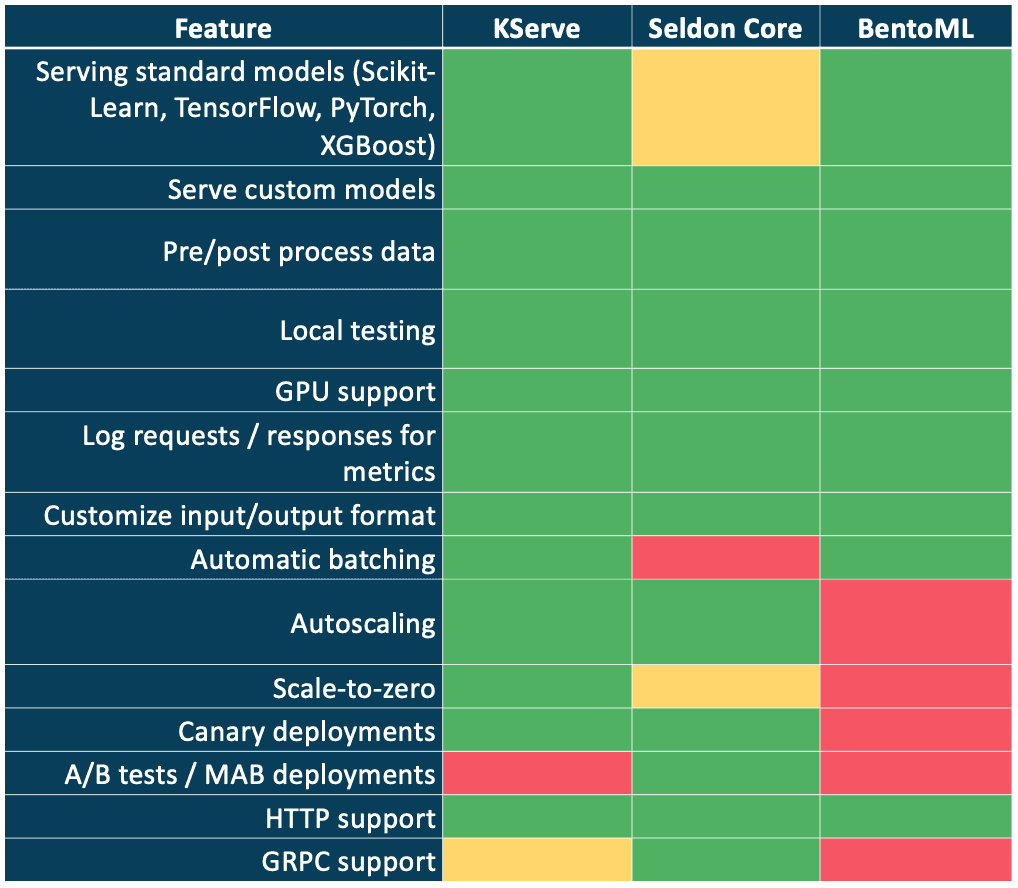
Feature-Matrix von Machine Learning-Modellen, die Tools dienen
Zusammenfassung
Die Übertragung von Machine Learning-Modellen aus der Experimentierphase in APIs, die in der Produktion laufen, ist ein komplexer Prozess. Alle verglichenen Tools versuchen, einige seiner Aspekte einfacher, schneller oder sogar mühelos zu gestalten. Gleichzeitig haben alle Tools auch ihre Schattenseiten. Deshalb ist es wichtig zu wissen, was die verschiedenen Fähigkeiten dieser Tools sind und was mit ihnen angesichts der wichtigsten Ziele und Einschränkungen des Projekts erreicht werden kann. Wir hoffen, dass dieser Vergleich Ihnen hilft, fundierte Entscheidungen zu treffen, wenn es um die Bereitstellung von Machine Learning-Modellen geht. Im nächsten Beitrag werden wir uns mit Cloud-nativen, verwalteten Machine Learning Serving Tools beschäftigen. Bleiben Sie dran!
Interessieren Sie sich für ML- und MLOps-Lösungen? Wie können Sie ML-Prozesse verbessern und die Lieferfähigkeit von Projekten steigern? Sehen Sie sich unsere MLOps-Demo an und melden Sie sich für eine kostenlose Beratung an.
Verfasst von
Marcin Zabłocki
Unsere Ideen
Weitere Blogs




Contact