
Die Multi-Label-Klassifizierung ist eine nützliche Funktion von tiefen neuronalen Netzen. Ich habe diese Funktion kürzlich in Keras ImageDataGenerator integriert, um auf Daten zu trainieren, die nicht in den Speicher passen. Dieser Blogbeitrag zeigt die Funktionalität und führt ein komplettes Beispiel mit dem VOC2012-Datensatz durch.
Seien Sie still und zeigen Sie mir den Code!

In freier Wildbahn aufgenommene Bilder sind äußerst komplex. Um ein Bild wirklich zu "verstehen", spielen viele Faktoren eine Rolle, z. B. die Anzahl der Objekte im Bild, ihre Dynamik, die Beziehung zwischen den Bildern, die Positionen der Objekte usw. Um KI in die Lage zu versetzen, Bilder in freier Wildbahn so zu verstehen wie wir, müssen wir KI mit all diesen Fähigkeiten ausstatten. Diese Befähigung kann auf unterschiedliche Weise erfolgen, z.B. durch Mehrklassen-Klassifizierung, Multi-Label-Klassifizierung, Objekterkennung (Bounding Boxes), Segmentierung, Posenschätzung, optischen Fluss usw.
Nach einer kleinen Diskussion mit den Mitarbeitern des Pakets keras-preprocessing haben wir beschlossen, den Benutzern von Keras einige dieser Anwendungsfälle über die bekannte Klasse ImageDataGenerator zu ermöglichen. Insbesondere dank der von @Vijayabhaskar hinzugefügten Flexibilität der Klasse DataFrameIterator sollte dies möglich sein.
Während unseres letzten GDD-Freitags bei Xebia beschloss ich dann, den Anwendungsfall der Mehrklassen-Klassifizierung hinzuzufügen.1 Das Endergebnis war dieser PR.
Aber zuerst... Was ist eine Multi-Label-Klassifizierung?
Nicht zu verwechseln mit der Mehrklassen-Klassifikation. Bei einem Multi-Label-Problem können einige Beobachtungen 2 oder mehr Klassen zugeordnet werden.
ANMERKUNG
Diese Funktionalität wurde erst gestern in der Version keras-preprocessing 1.0.6 in der PyPI veröffentlicht . Sie können keras aktualisieren, um die neueste Version zu erhalten, indem Sie:
pip install -U keras
Lernen Sie Spark oder Python in nur einem Tag
Entwickeln Sie Ihre Data Science-Fähigkeiten. **Online**, unter Anleitung am 23. oder 26. März 2020, 09:00 - 17:00 CET.
Mehrklassen-Klassifizierung in 3 Schritten
In diesem Teil wird die Verwendung von ImageDataGenerator für die Mehrklassen-Klassifizierung schnell demonstriert.
1. Bild-Metadaten in Pandas-Datenrahmen
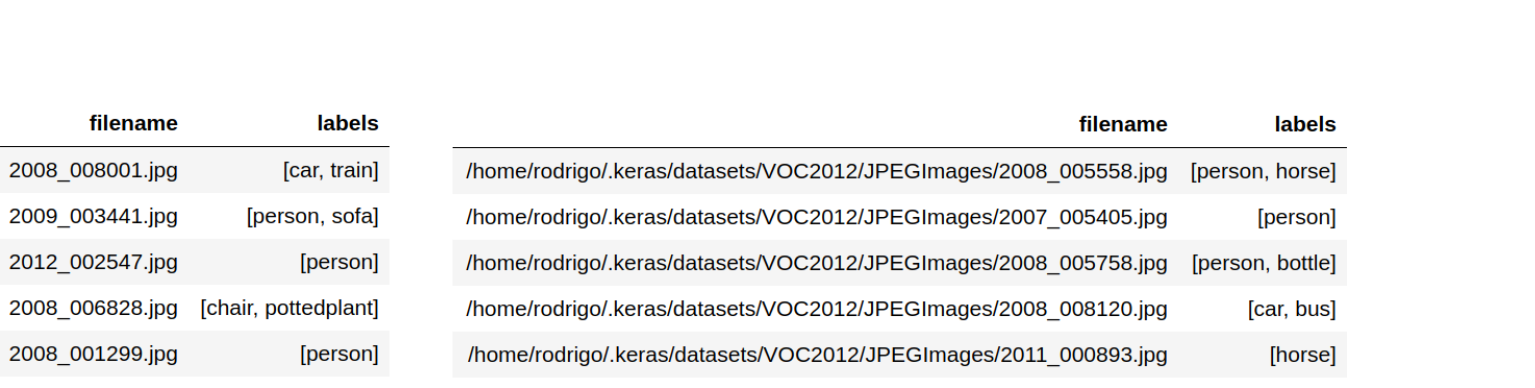
Nehmen Sie die Metadaten des Mehrklassenproblems in einen Pandas-Datenrahmen auf. Die Beschriftungen für jede Beobachtung sollten in einer Liste oder einem Tupel vorliegen. Die Dateinamen der Bilder können auf zwei Arten in den Datenrahmen aufgenommen werden, wie in der Abbildung unten gezeigt.
-
Relative Pfade: Wenn Sie nur die Dateinamen der Bilder angeben, müssen Sie später das Argument
directoryverwenden, wenn Sie die Methodeflow_from_dataframeaufrufen. -
Absolute Pfade: In diesem Fall können Sie das Argument
directoryweglassen. 2
2. Instanziieren Sie DataFrameIterator
Erstellen Sie den Generator für die Bildstapel. Dies geschieht durch die Instanziierung von DataFrameIterator über die Methode flow_from_dataframe von ImageDataGenerator. Angenommen, wir haben die Dateinamen als relative Pfade eingegeben, dann würde die einfachste Instanziierung wie folgt aussehen:3
von keras.preprocessing.image importieren ImageDataGenerator img_iter = ImageDataGenerator().flow_from_dataframe( img_metadata_df, Verzeichnis=/home/rodrigo/.keras/datasets'., x_col='Dateiname', y_col='Etiketten', Klasse_Modus='kategorisch' )
Die eigentliche Logik der Erstellung der Stapel und der Handhabung der Datenerweiterung wird von der Klasse DataFrameIterator verwaltet. Weitere verfügbare Argumente können Sie hier nachschlagen.
3. Trainieren Sie das Modell
Trainieren Sie das Modell mit der Methode fit_generator.4
Modell.fit_generator(img_iter)
So erhalten Sie Batches direkt von der Festplatte und können mit viel mehr Daten trainieren, als in Ihren Speicher passen.
Das war's!5
Rundown Beispiel mit VOC2012
In diesem Teil führe ich Sie Schritt für Schritt durch ein Mehrklassen-Klassifizierungsproblem. Das Beispiel verwendet den VOC2012-Datensatz, der aus ~17.000 Bildern und 20 Klassen besteht.
Wenn Sie sich die Bilder unten ansehen, können Sie schnell feststellen, dass es sich um einen recht vielfältigen und schwierigen Datensatz handelt. Perfekt! Je näher an einem realen Beispiel, desto besser.

Beginnen wir damit, die Daten von hier aus in ~/.keras/datasets herunterzuladen.
~/.keras/Datensätze/VOC2012 ├── Anmerkungen │ ├── 2010_000002.xml │ ├── 2010_000003.xml │ ├── 2011_000002.xml │ └── ... ├── ImageSets │ ├── Aktion │ ├── Layout │ ├── Haupt │ └── Segmentierung ├── JPEGImages │ ├── 2010_000002.jpg │ ├── 2010_000003.jpg │ ├── 2011_000002.jpg │ └── ... ├── SegmentierungKlasse │ ├── 2010_000002.png │ ├── 2010_000003.png │ └── 2011_000003.png └── SegmentierungObjekt ├── 2010_000002.png ├── 2010_000003.png └── ...
Wir werden das Verzeichnis Annotations verwenden, um die Metadaten der Bilder zu extrahieren. Jedes Bild kann auch wiederholte zugehörige Beschriftungen haben. Das Argument unique_labels der Funktion unten regelt, ob wir wiederholte Beschriftungen behalten. Das werden wir nicht tun, glauben Sie mir, das Problem ist schwer genug.
importieren xml.etree.ElementTree als ET von pathlib importieren Pfad def xml_to_labels(xml_data, einzigartige_etiketten): Wurzel = ET.XML(xml_data) Etiketten = einstellen.() wenn einzigartige_etiketten sonst [] Etiketten_hinzufügen = Etiketten.hinzufügen wenn einzigartige_etiketten sonst Etiketten.anhängen. # Beschleunigt die Suche nach Methoden für i, Kind in aufzählen.(Wurzel): wenn Kind.Tag == 'Dateiname': img_filename = Kind.Text wenn Kind.Tag == 'Objekt': für Unterkind in Kind: wenn Unterkind.Tag == 'Name': Etiketten_hinzufügen(Unterkind.Text) return img_filename, Liste(Etiketten) def get_labels(annotations_dir, einzigartige_etiketten=True): für annotation_file in annotations_dir.iterdir(): mit öffnen Sie(annotation_file) als f: Ertrag xml_to_labels(f.lesen(), einzigartige_etiketten) annotations_dir = Pfad(~/.keras/datasets/VOC2012/Anmerkungen'.).expanduser() img_metadaten = pd.DataFrame(get_labels(annotations_dir), Spalten=['Dateiname', 'Etiketten'])
Nach der Extraktion erhalten wir einen Datenrahmen mit relativen Pfaden, wie unten gezeigt.
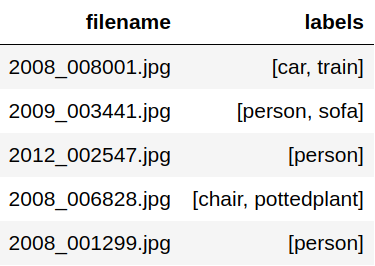
Die Dateinamen sind dann relativ zu
images_dir = Pfad(~/.keras/datasets/VOC2012/JPEGImages'.).expanduser()
Scannen Sie den Datensatz
Werfen wir nun einen kurzen Blick darauf, wie die Beschriftungen über den Datensatz verteilt sind. Diese Zählungen können leicht mit einem Counter Objekt berechnet werden.
von Sammlungen importieren Zähler Etiketten_Zahl = Zähler(Etikett für lbs in img_metadaten['Etiketten'] für Etikett in lbs)
Von hier aus können wir ganz einfach die class_weights zur späteren Verwendung berechnen.
gesamt_Zahl = Summe(Etiketten_Zahl.Werte()) Klasse_Gewichte = {cls: gesamt_Zahl / zählen für cls, zählen in Etiketten_Zahl.Artikel()}
Lassen Sie uns nun die Anzahl der Etiketten aufzeichnen.
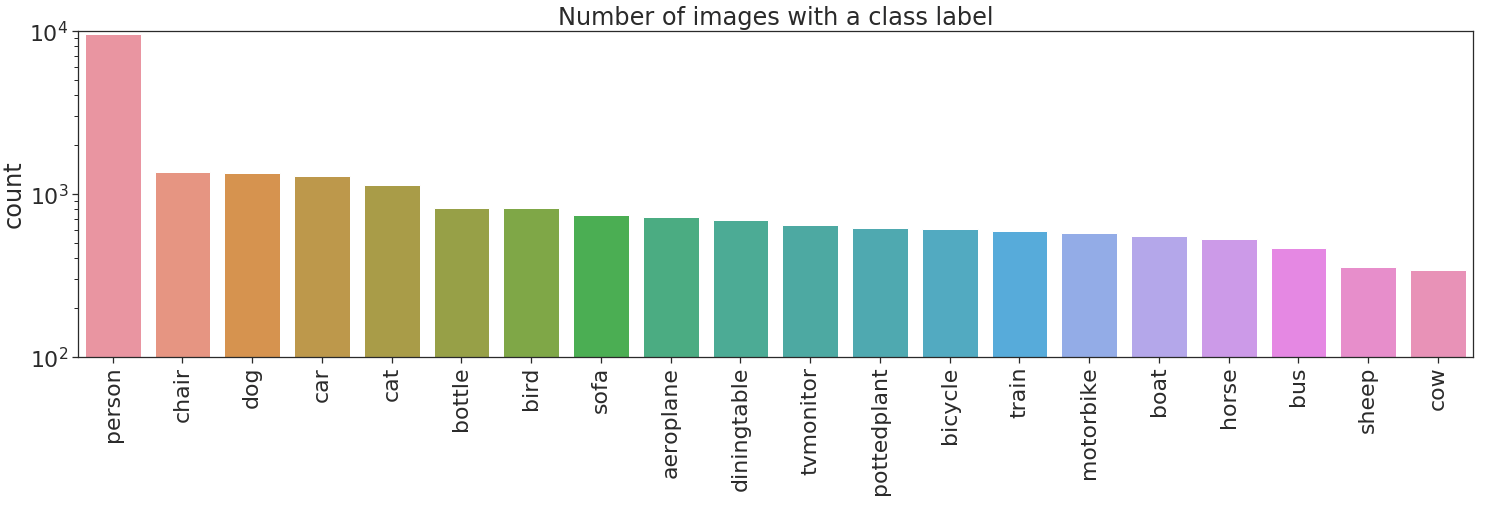
Nein bueno, überhaupt nicht bueno! Es gibt zwei Arten von Ungleichgewichten in dem Datensatz. Unausgewogenheit zwischen verschiedenen Klassen und Unausgewogenheit zwischen positiven und negativen Beispielen in einigen Klassen. Die erste Art des Ungleichgewichts kann zu einer Überanpassung an stark vertretene Klassen führen, in diesem Fall person. Das letztgenannte Ungleichgewicht kann dazu führen, dass eine Klasse immer als negativ gekennzeichnet wird, d.h. wenn cow immer als negativ gekennzeichnet wird, ergibt dies eine Genauigkeit von 97% für diese Klasse.
Was können wir also dagegen tun?... beten. Ich werde nicht ins Detail gehen, aber eine Möglichkeit, den Ungleichgewichten entgegenzuwirken, ist eine Kombination aus Klassengewichten und Probengewichten.6
Der nächste Schritt ist die Betrachtung der Form- und Größenverteilung in den verschiedenen Bildern.
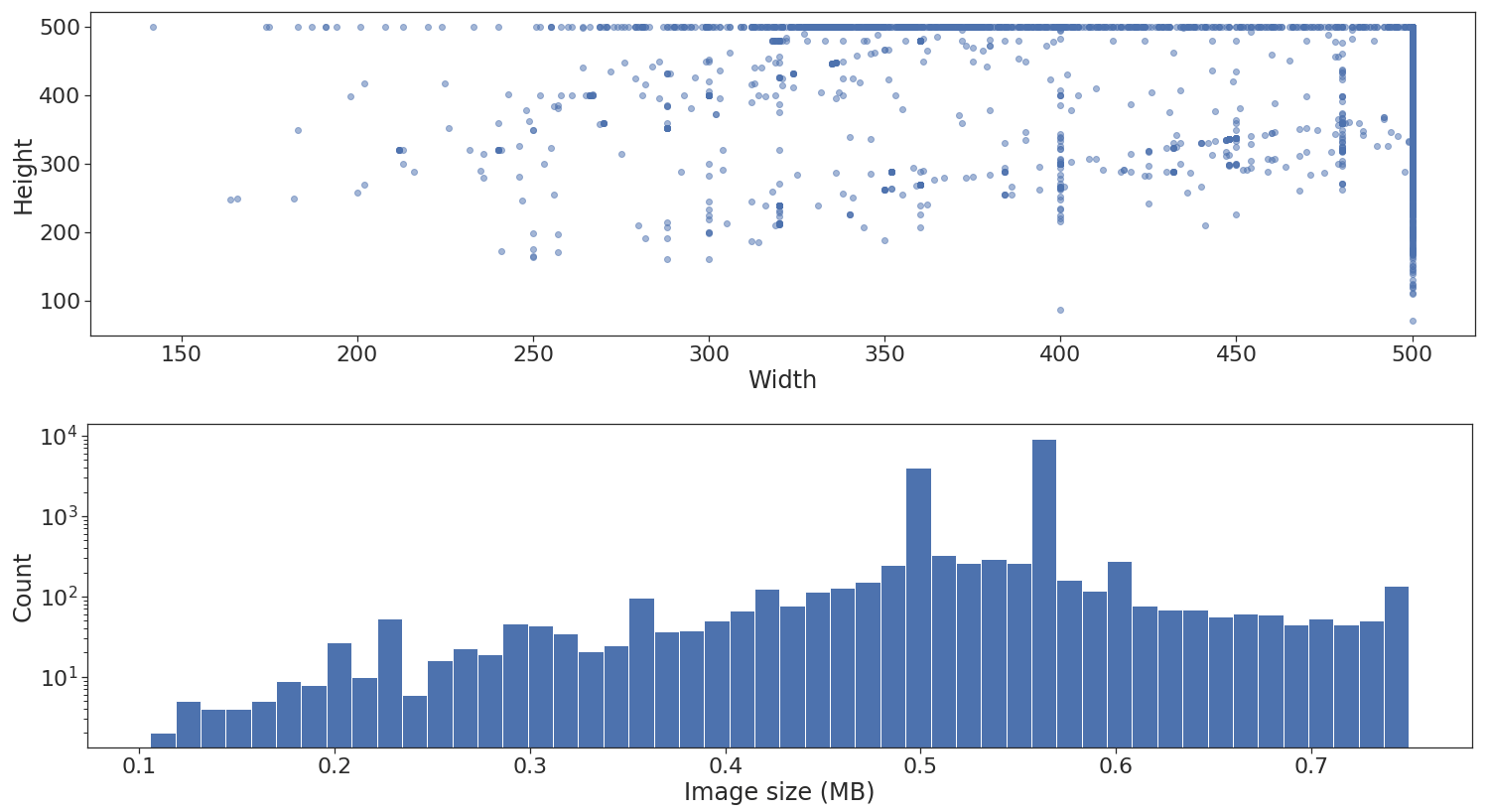
Wie oben dargestellt, enthält der Datensatz Bilder mit unterschiedlichen Höhen und Breiten. Ich werde hier nicht ins Detail gehen, aber das ist nicht wirklich ein Problem, wenn am Ende der Merkmalsextraktion über Faltungsschichten eine globale Pooling-Schicht angewendet wird. Leider gibt es noch ein weiteres Problem: Wenn Sie flow_from_dataframe verwenden, müssen alle Bilder auf dieselbe Breite und Höhe standardisiert werden.7 Dies wird über den Parameter target_size festgelegt.
Die untere Histogrammdarstellung ist gut, weil sie uns einen ungefähren Hinweis auf die maximale Stapel- und Warteschlangengröße geben kann, die unser Speicher bei Verwendung des Generators aufnehmen kann. In diesem Beispiel verwende ich das Diagramm jedoch nicht wirklich.
Das Modell trainieren
Zunächst müssen wir ImageDataGenerator instanziieren. Ich werde dies mit einem einfachen Setup tun, das lediglich die Pixelwerte normalisiert. Ich habe auch einen Validierungssplit eingefügt, um ihn für Validierungsstatistiken während des Trainings nach jeder Epoche zu verwenden.
img_gen = ImageDataGenerator(neu skalieren=1/255, validation_split=0.2)
Wir können nun die Trainings- und Validierungsdaten DataFrameIterator erstellen, indem wir subset als "training" bzw. "validation" angeben. Im Falle einer Multi-Label-Klassifizierung sollte class_mode "categorical" (der Standardwert) sein.
img_iter = img_gen.flow_from_dataframe( img_metadaten, Shuffle=True, Verzeichnis=images_dir, x_col='Dateiname', y_col='Etiketten', Klasse_Modus='kategorisch', ziel_größe=(128, 128), chargen_größe=20, Teilmenge='Ausbildung' ) img_iter_val = img_gen.flow_from_dataframe( img_metadaten, Shuffle=False, Verzeichnis=images_dir, x_col='Dateiname', y_col='Etiketten', Klasse_Modus='kategorisch', ziel_größe=(128, 128), chargen_größe=200, Teilmenge='Überprüfung' )
Ich verwende in diesem Beispiel das vortrainierte Modell ResNet50. Ich werde die letzten vollständig verbundenen Schichten des Netzwerks durch eine Ausgabeschicht mit 20 Neuronen ersetzen, eine für jede Klasse.8 Achten Sie außerdem auf die Aktivierungsfunktion der Ausgabe. Ich werde nicht ins Detail gehen, aber für die Klassifizierung in mehrere Klassen sollte die Wahrscheinlichkeit jeder Klasse unabhängig sein, daher die Verwendung der Funktion sigmoid und nicht der Funktion softmax, die für Mehrklassenprobleme verwendet wird.
Basis_Modell = ResNet50( einschließen_oben=False, Gewichte='imagenet', input_shape=Keine, Zusammenlegung='avg' ) für Ebene in Basis_Modell.Ebenen: Ebene.trainierbar = False Vorhersagen = Dichtes(20, Aktivierung='sigmoid')(Basis_Modell.Ausgabe) Modell = Modell(Eingaben=Basis_Modell.Eingabe, Ausgaben=Vorhersagen)
Als Nächstes kompilieren wir das Modell mit "binary_crossentropy" loss. Warum binäre Cross-Entropie und nicht kategorische Cross-Entropie, werden Sie sich fragen? Nun, auch hier werde ich nicht ins Detail gehen, aber wenn Sie categorical_crossentropy verwenden, bestrafen Sie im Grunde genommen nicht für falsch-positive Ergebnisse (wenn Sie eher ein Code-Mensch als ein Mathe-Mensch sind , hier ist es).
Modell.kompilieren( Verlust=binäre_Querentropie'., Optimierer='adam' )
HINWEIS: Auch wenn ich gerade gesagt habe, dass die Mathematik für multi-label Sigmoid und binäre Kreuzentropie vorschreibt, gibt es Fälle, in denen Softmax und kategorische Kreuzentropie besser funktionieren. Wie in diesem Fall.
Trainieren Sie das Modell bereits! Noch nicht... Geduld,"lento pero seguro". Lassen Sie uns über Metriken für ein Multi-Label-Problem wie dieses sprechen. Ich hoffe, es ist klar, dass Genauigkeit nicht der richtige Weg ist. Lassen Sie uns stattdessen f1_score, recall_score und precision_score verwenden. Es gibt allerdings ein kleines Problem - ja, das Leben ist ein Miststück - diese Metriken wurden aus gutem Grund aus den Keras-Metriken entfernt.
Der richtige Weg, diese Metriken zu implementieren, besteht darin, eine Callback-Funktion zu schreiben, die sie am Ende jeder Epoche anhand der Validierungsdaten berechnet. Etwa so:
von itertools importieren Abschlag # endlich! Ich habe etwas Nützliches für sie gefunden von sklearn importieren Metriken Klasse Metriken(Rückruf): def __init__(selbst, validierung_generator, validierung_schritte, Schwellenwert=0.5): selbst.validierung_generator = validierung_generator selbst.validierung_schritte = validierung_schritte oder len(validierung_generator) selbst.Schwellenwert = Schwellenwert def on_train_begin(selbst, Protokolle={}): selbst.val_f1_scores = [] selbst.val_recalls = [] selbst.val_präzisionen = [] def on_epoch_end(selbst, Epoche, Protokolle={}): # Generator duplizieren, um sicherzustellen, dass y_true und y_pred aus denselben Beobachtungen berechnet werden gen_1, gen_2 = Abschlag(selbst.validierung_generator) y_true = np.vstack(nächste(gen_1)[1] für _ in Reichweite(selbst.validierung_schritte)).astype('int') y_pred = (selbst.Modell.predict_generator(gen_2, Schritte=selbst.validierung_schritte) > selbst.Schwellenwert).astype('int') f1 = Metriken.f1_score(y_true, y_pred, Durchschnitt='gewichtet') Präzision = Metriken.präzision_score(y_true, y_pred, Durchschnitt='gewichtet') Rückruf = Metriken.recall_score(y_true, y_pred, Durchschnitt='gewichtet') selbst.val_f1_scores.anhängen.(f1) selbst.val_recalls.anhängen.(Rückruf) selbst.val_präzisionen.anhängen.(Präzision) drucken(f" - val_f1_score: {f1:.5f} - val_precision: {Genauigkeit:.5f} - val_recall: {Rückruf:.5f}") return
Endlich! Wir sind bereit, das Modell zu trainieren. Zu Ihrer Information: Ich habe mich wenig bis gar nicht um die Optimierung des Modells bemüht.
Metriken = Metriken(img_iter_val, validierung_schritte=50) Geschichte = Modell.fit_generator( img_iter, Epochen=5, Schritte_pro_Epoche=250, Klasse_Gewicht=Klasse_Gewichte, Rückrufe=[Metriken] )
Während der Trainingszeit sollten Sie am Ende jeder Epoche Validierungsmetriken sehen, etwa so:
Epoche 1/5 250/250 [==============================] - 261s 1s/Schritt - Verlust: 4.2584 - val_f1_score: 0.28155 - val_precision: 0.21952 - val_recall: 0.40316
Wenn Ihr Gedächtnis während des Trainings schmilzt, reduzieren Sie die batch_size, die target_size oder die max_queue_size Parameter.
Post-mortem Untersuchung
Bei einem Mehrklassenproblem ist es bereits eine große Hilfe, die Konfusionsmatrix zu zeichnen. Auf diese Weise können wir sehr deutlich erkennen, wo das Modell eine Klasse mit einer anderen "verwechselt" und die Probleme direkt angehen. Da es sich um ein Multi-Label-Problem handelt, macht es keinen Sinn, das Gleiche zu tun. Stattdessen kann eine Verwechslungsmatrix pro Klasse überprüft werden. 9
Diese Funktion ist nur in der Entwicklungsversion von scikit-learn enthalten, die Sie über
pip install git+https://www.github.com/scikit-learn/scikit-learn.git --upgrade
Danach sollten Sie in der Lage sein
von sklearn.metrics importieren multilabel_confusion_matrix
Ich habe eine Wrapper-Plot-Funktion plot_multiclass_confusion_matrix um multilabel_confusion_matrix herum geschrieben, die Sie im Code finden können. Die Ausgabe der Funktion sieht folgendermaßen aus:
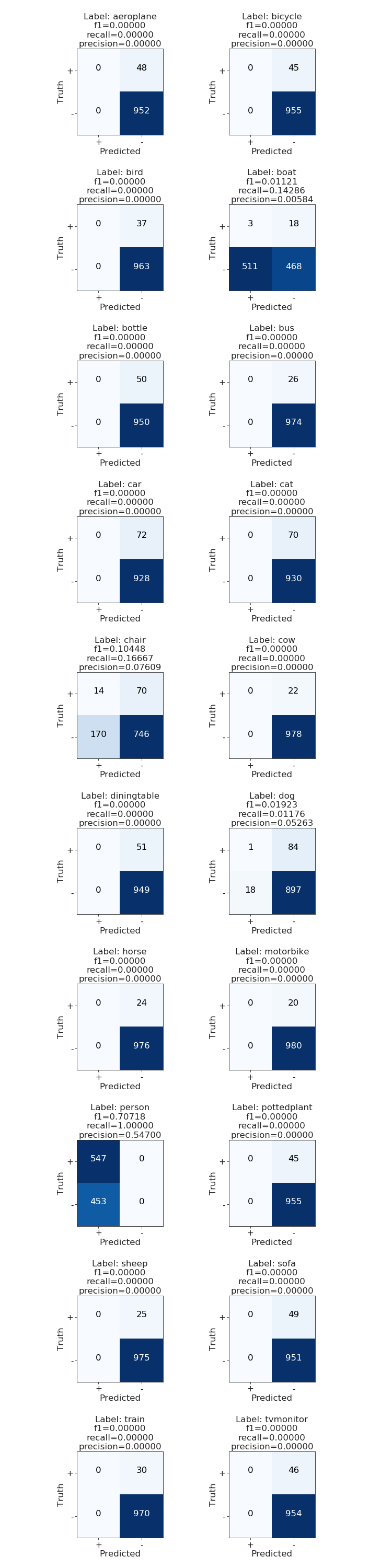
Das war's, Leute! Wie Sie sehen können, ist das Modell schlecht. Ihr Auftrag, falls Sie ihn annehmen wollen...

Adios

Ich hoffe, Sie fanden diesen Blogbeitrag nützlich. Ich habe viele Konzepte recht schnell abgehandelt, aber ich denke, es sind einige wertvolle Tipps dabei.
Sie können den Code hier finden.
Wenn Sie weitere Fragen haben, pingen Sie mich einfach auf Twitter an @rragundez.
Möchten Sie Keras selbst ausprobieren?
Nehmen Sie an einem dreitägigen Kurs über Deep Learning teil. Sie lernen nicht nur die Theorie hinter Deep Learning und die für Deep Learning verwendeten Algorithmen kennen, sondern erhalten auch umfangreiche praktische Erfahrungen mit Keras.
- Das war schon vorher möglich, aber auf eine nicht sehr API-freundliche Weise. Sie können hier darüber lesen.
- Das absolute Pfadformat bietet Ihnen mehr Flexibilität, da Sie einen Datensatz aus mehreren Verzeichnissen erstellen können.
-
Im Falle einer Mehrklassen-Klassifizierung sollten Sie
class_mode='categorical'verwenden . -
Für die Mehrklassen-Klassifizierung stellen Sie sicher, dass die Ausgabeschicht des Modells eine
sigmoidAktivierungsfunktion hat und dass die Verlustfunktionbinary_crossentropyist . - Ich hoffe, Sie wissen die Einfachheit zu schätzen :)
-
Beispielgewichte sind noch nicht in
flow_from_dataframeimplementiert. Ich warte auf diese Person, aber wenn Sie dazu beitragen möchten, tun Sie es bitte! - Dies ist eine Voraussetzung, da jeder Stapel von Bildern in ein Numpy-Array geladen wird. Daher sollte jedes geladene Bild die gleichen Array-Abmessungen haben. Außerdem wäre dies eine großartige Funktion. Eine PR wäre zwar ziemlich umständlich, aber machen Sie es!
-
Die Ausgabeschicht von
ResNet50, wenninclude_top=Falseeine Größe von 2048 hat, würde ich normalerweise nicht mit einer voll verknüpften Schicht von 20 Neuronen folgen, aber für dieses Beispiel ist es ausreichend, um die Funktionalität zu zeigen. Normalerweise versuche ich, die Ausgabeeinheiten auf jeder Schicht um 1/3 oder 1/10 zu verringern, wenn 1/3 nicht ausreicht. - Es gibt einige Dinge, die eine Verwirrungsmatrix pro Klasse nicht berücksichtigt, aber es ist ein guter erster Ansatz.
Unsere Ideen
Weitere Blogs




Contact