Inspiriert von Gene Kogans Keynote auf der PyData Warschau 2018 haben wir beschlossen, während unseres fast.ai Schnellkochtopfs im vergangenen Dezember selbst in die Stilübertragung einzutauchen. Dieser Blog erklärt, was das ist und beschreibt zwei Ansätze, wie Sie es selbst machen können.
Der Begriff "Stiltransfer" wird verwendet, um den Vorgang zu beschreiben, bei dem ein Bild im Stil eines anderen Bildes (oder einer anderen Gruppe von Bildern) neu zusammengesetzt wird. Im Allgemeinen werden dazu zwei Eingaben benötigt: ein Bild oder mehrere Bilder mit Inhalt und ein Bild oder mehrere Bilder mit Stil. Die angewandte Technik sollte dann eine Ausgabe erzeugen, deren "Inhalt" das Inhaltsbild widerspiegelt und deren "Stil" dem des Stilbildes ähnelt.
Nachfolgend ein Beispiel mit einem Original-Katzenfoto auf der linken Seite (das Inhaltsbild), das mit Hilfe der Stilbilder in der Mitte auf drei verschiedene Arten "gestylt" wird. Die verschiedenen Stile führen zu unterschiedlichen generierten Ausgabebildern, wie Sie rechts sehen können.

Als wir uns mit diesem Thema beschäftigten, fanden wir mehrere Möglichkeiten, den Stil zu übertragen. Wir stellen Ihnen hier zwei Ansätze vor, einschließlich des Codes, mit dem Sie Ihre eigenen gestylten Bilder erstellen können.
Ansatz 1: Neuronaler Stil
Die neuronale Stilübertragung wurde erstmals im August 2015 in einer von Gatys, Ecker und Bethge an der Universität Tübingen veröffentlichten Arbeit demonstriert. Der Algorithmus ist auf ml4a gut beschrieben, einer Website von Gene Kogan, die kostenlose Bildungsressourcen über maschinelles Lernen für Künstler bereitstellt.
Kurz gesagt besteht das Ziel des Stilübertragungsalgorithmus darin, ein Ausgabebild zu erzeugen, das eine Verlustfunktion minimiert, die sich aus der Summe zweier separater Terme zusammensetzt, einem "Inhaltsverlust" und einem "Stilverlust". Der Inhaltsverlust stellt die Unähnlichkeit zwischen dem Inhaltsbild und dem Ausgabebild dar, während der Stilverlust die Unähnlichkeit zwischen dem Stilbild und dem Ausgabebild darstellt.
Der Algorithmus trainiert ein einzelnes neuronales Faltungsnetzwerk, wobei bei jeder Iteration die Pixel des Ausgangsbildes leicht angepasst werden, um den Gesamtverlust zu verringern. Dies wird so lange wiederholt, bis der Verlust konvergiert oder bis wir mit unserem Ergebnis zufrieden sind.
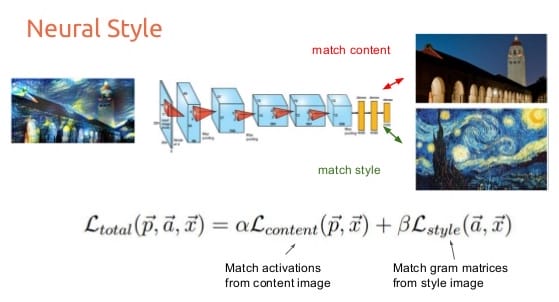
Der Inhalts- und der Stilverlust sind unterschiedlich definiert:
- Für den Inhaltsverlust werden das Ausgabebild und das Inhaltsbild durch das Convnet geleitet, wodurch wir eine Reihe von Merkmalskarten für beide erhalten. Der Verlust in einer einzelnen Schicht ist dann der euklidische (L2) Abstand zwischen den Aktivierungen des Inhaltsbildes und den Aktivierungen des Ausgabebildes.
- Für den Stilverlust verwenden wir ebenfalls die Aktivierungen des Convnets, aber anstatt die rohen Aktivierungen direkt zu vergleichen, nehmen wir die Gram-Matrix der Aktivierungen in jeder Schicht des Netzwerks. Auf diese Weise können wir Korrelationen zwischen Merkmalen in verschiedenen Teilen des Bildes erfassen, was sich als sehr gute Darstellung unserer Wahrnehmung des Stils in Bildern erweist. Der Stilverlust in einer einzelnen Schicht ist dann definiert als der euklidische (L2) Abstand zwischen den Gram-Matrizen der Stil- und Ausgabebilder.
Wenn wir dieses Modell für ein Bild von Amsterdam und ein Bild mit einem Winterthema verwenden, erhalten wir ein ziemlich gutes Ergebnis!

Beachten Sie, dass es sich bei unserem Stilbild nicht wirklich um einen Stil handelt, sondern eher um ein Winterthemenbild. Die Texturen in den Stilbildern aus den Katzenbeispielen in der Einführung sind viel einfacher zu übertragen. In unserem Fall können Sie jedoch deutlich erkennen, dass das Modell die Aststruktur der Bäume aufgegriffen hat.
Lesen Sie den Anhang unten, um zu erfahren, wie Sie dies selbst tun können.
Ansatz 2: Zykluskonsistente kontradiktorische Netzwerke
Der zweite Ansatz, den wir verwendet haben, basiert auf diesem kürzlich erschienenen Artikel und seiner Implementierung. Er heißt Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. Anstatt von gepaarten Beispielen zu lernen (von Bild
Das Ziel ist es, die Transformation von X (Inhaltsbilder) nach Y' zu lernen, so dass Y' so aussieht, wie es von Y (Stilbilder) stammt. Wir können dies mit einem gegnerischen Modell überprüfen, das versucht, Y' von Y zu unterscheiden.
Ein Problem, das auftreten könnte, ist, dass unsere Transformation lernt, immer dasselbe Y' zu erzeugen, das das gegnerische Modell täuschen kann. Um dieses Problem zu überwinden, wollen wir, dass unser Modell "zykluskonsistent" ist, d.h. wir wollen auch ein Modell lernen, um Y' zurück nach X' zu übertragen, wobei X' wieder in der Nähe von X sein sollte.
Die folgende Abbildung gibt einen schematischen Überblick über diesen Ansatz. Links (a) sehen wir unsere Modelle F und G, die Bilder zwischen X und Y übertragen können. Außerdem haben wir DX und DY, die die gegnerischen Diskriminatoren sind. DX ermutigt F, Y in X' Ausgaben zu übersetzen, die von der Domäne X nicht zu unterscheiden sind.

In der Mitte (b) sehen wir den Zykluskonsistenzverlust, der verwendet wird, um sicherzustellen, dass die durch G transformierten Bilder durch F in etwas zurücktransformiert werden können, das dem Original X ähnelt. Rechts (c) sehen wir das Gleiche für Transformationen von Y nach X und zurück nach Y.
Wenn wir diesen Ansatz auf die gleichen Bilder mit demselben Inhalt (Amsterdam) und Stil (Winter) anwenden, erhalten wir wieder ein sehr schönes Ergebnis. Es ist interessant zu sehen, wie die verschiedenen Methoden ganz unterschiedliche Ausgabebilder erzeugen. Der Inhalt ist weder verzerrt noch schief, es wurde lediglich eine Menge Weiß hinzugefügt, was dem Bild einen winterlichen Stil verleiht. Was verrät, dass es sich um ein generiertes Bild handelt, ist der weiße Boden und die Vorderseite der Brücke, die ebenfalls weiß ist.

Wenn Sie es selbst ausprobieren möchten, lesen Sie im Anhang nach, wie Sie alles zum Laufen bringen.
Einpacken
Für unsere Stilübertragungsübung haben wir mit zwei Ansätzen herumgespielt. Während der erste Ansatz des neuronalen Stiltransfers eine Zuordnung zwischen zwei spezifischen Bildern lernt, können zykluskonsistente adversarische Netzwerke eine Zuordnung zwischen zwei Bildsammlungen lernen (obwohl in unserem Amsterdam-Winter-Beispiel jede Sammlung nur ein einziges Bild enthielt). Dieser zweite Ansatz ist reichhaltiger, da er versucht, den Stil einer ganzen Sammlung von Kunstwerken zu imitieren, anstatt den Stil eines einzelnen ausgewählten Kunstwerks zu übertragen. Zykluskonsistente kontradiktorische Netzwerke lernen also, Fotos im Stil von z.B. Van Gogh zu generieren und nicht nur im Stil von Sternennacht1.
Wir hoffen, dass dieser Blog Ihnen dabei hilft, Ihren eigenen Stil zu übertragen. Viel Spaß dabei!

Anhang
Ansatz 1: Einrichten des neuronalen Stils
Um den Code selbst auszuführen, klonen Sie dieses Torch-Projekt im neuronalen Stil (geschrieben in Lua) und folgen Sie den Anweisungen. Wenn Sie sich mit Python wohler fühlen, probieren Sie dieses Tutorial für neuronalen Transfer mit PyTorch aus. Torch ist ein separates Produkt von PyTorch; PyTorch hat keine Abhängigkeiten von Torch.
Die Anweisungen für das Torch-Tutorial sind für Ubuntu (ideal für die Ausführung in der Cloud), daher ist eine kleine Anpassung erforderlich, um Neural Style auf Ihrem Mac auszuführen. Wenn Sie keinen nVidia-Grafikprozessor auf Ihrem Rechner haben, können Sie den Code trotzdem mit der CPU Ihres lokalen Rechners mit dem Flag -gpu -1 ausführen:
th neural_style.lua -style_image beispiel/inputs/schiffswrack.jpg -content_image beispiele/inputs/golden_gate.jpg -output_image beispiel/outputs/mein_output_image.png -gpu -1
Ansatz 2: Aufbau von zykluskonsistenten kontradiktorischen Netzwerken
Um Ihren eigenen Code zum Laufen zu bringen, folgen Sie den nachstehenden Anweisungen. Erstellen Sie zunächst eine neue conda Umgebung und aktivieren Sie sie:
conda create -n style-transfer conda activate style-transfer # oder verwenden Sie source activate für ältere Versionen von conda
Klonen Sie dieses Repository und um sicherzustellen, dass Sie unsere Ergebnisse reproduzieren können, checken Sie einen bestimmten Commit vom Dezember 2018 aus:
git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix cd pytorch-CycleGAN-und-pix2pix git checkout c8323f9d0167161df1ad92e583f2a395fb59b5e8
Führen Sie ein Skript aus, um die erforderlichen Pakete zu installieren und alles zu aktualisieren:
bash ./scripts/conda_deps.sh conda update --all
Wenn Sie die Ergebnisse von Pferd zu Zebra reproduzieren möchten, können Sie ein vortrainiertes Modell und die entsprechenden Daten (um das Modell zu testen) mit den folgenden Skripten herunterladen:
bash ./scripts/download_cyclegan_model.sh horse2zebra bash ./datasets/download_cyclegan_dataset.sh horse2zebra
Um die Ergebnisse für die Daten von Pferd zu Zebra zu generieren, führen Sie Folgendes aus:
python Test.py --dataroot Datensätze/horse2zebra/testA --Name horse2zebra_pretrained--Modell Test --gpu_ids -1 --no_dropout
Und das sind die Argumente, die wir verwenden:
--dataroot: Pfad zum Datensatz.--name: Name des Experiments. Es entscheidet, wo die Proben und Modelle gespeichert werden. Versucht auch, ./checkpoints/{name}/latest_net_G.pth' zu laden.--model: Geben Sie das zu verwendende Modell an. Wir verwenden TesteModel, um CycleGAN-Ergebnisse für nur eine Richtung zu erzeugen. Dieses Modell stellt automatisch--dataset_mode singleein, das die Bilder nur aus einer Sammlung lädt.--display_id: Setzen Sie den Wert auf -1, um den zusätzlichen Overhead für die Kommunikation mit visdom zu vermeiden.--gpu_ids: Setzen Sie den Wert auf -1, um lokal ohne NVIDIA-GPU zu arbeiten.--no_dropout: Kein Abbruch.--resize_or_crop: Stellen Sie die Optionnoneein, um die ursprüngliche Bildgröße beizubehalten.
Führen Sie Ihren eigenen Datensatz aus
Um dasselbe für Ihren eigenen Datensatz zu tun, müssen Sie zunächst einen neuen Ordner im Verzeichnis datasets erstellen, der zwei Ordner trainA und trainB enthält, die Bilder aus zwei verschiedenen Gruppen enthalten (z. B. Pferde in A und Zebras in B).
Dann trainieren Sie ein neues Modell, das Sie zur Übertragung des Stils verwenden. Lernen Sie zunächst das Modell für die Stilübertragung, indem Sie es ausführen (ersetzen Sie matrix durch Ihren eigenen Datensatz):
python train.py --dataroot ./datasets/matrix --name matrix_cyclegan --model cycle_gan --gpu_ids -1 --display_id -1
Nach dem Training übertragen Sie den Stil von trainB auf alle Bilder von trainA wie folgt:
python test.py --dataroot datasets/matrix/trainA --name matrix_cyclegan --model test --model_suffix "_A" --gpu_ids -1 --no_dropout --resize_or_crop none
Um den Prozess zu beschleunigen, können Sie einen Grafikprozessor in der Cloud hochfahren und denselben Code ohne die Option --gpu_ids -1 ausführen. Bei uns führte dies zu einem Geschwindigkeitszuwachs um den Faktor 60; die Epochen dauerten 3 Sekunden statt 3 Minuten.
Möchten Sie selbst so etwas Cooles machen?
Unser dreitägiger Kurs über Deep Learning befasst sich mit allen Aspekten des Deep Learning, einschließlich Bilderkennung und Klassifizierung.
Verfasst von

Roel
Unsere Ideen
Weitere Blogs




Contact