Blog
Wie Sie Ihren ersten Bildklassifikator mit PyTorch erstellen

Neuronale Netzwerke sind heutzutage allgegenwärtig. Aber obwohl es scheint, dass heute buchstäblich jeder ein neuronales Netzwerk verwendet, kann es eine ziemliche Hürde sein, zum ersten Mal ein eigenes neuronales Netzwerk zu erstellen und zu trainieren. In diesem Blogbeitrag nehme ich Sie an die Hand und zeige Ihnen, wie Sie einen Bildklassifikator trainieren - mit PyTorch!
Warum nicht Keras?
Bevor wir beginnen, werden Sie sich vielleicht fragen, warum ich mich für PyTorch, und nicht für Keras entschieden habe. Natürlich gibt es für jede der Optionen Vor- und Nachteile, aber ich werde hier nicht versuchen, einen guten Überblick zu geben. Ich bin nicht die richtige Person, um nach einem Vergleich zu fragen, da ich keine Erfahrung mit Keras habe. Wenn Sie also einen Artikel über die Unterschiede zwischen diesen (und möglicherweise weiteren) Optionen suchen , können Sie hier nachschauen, hier oder hier.
Faltungsneuronale Netzwerke
Das Tool, das wir zur Erstellung eines Klassifizierers verwenden werden, nennt sich convolutional neural network, oder CNN. Unter finden Sie eine gute Erklärung, was das ist. hier auf wikipedia.
Aber wir werden nicht selbst ein vollständiges Training durchführen: Das würde viel mehr Zeit kosten, als ich bereit bin zu investieren. Stattdessen werden wir ein Transfer-Lernen durchführen, bei dem wir ein bereits trainiertes CNN nehmen und nur die letzte Schicht durch eine eigene Schicht ersetzen. Dann brauchen wir nur diese eine Schicht zu trainieren, da alle anderen Schichten bereits vernünftige Gewichte haben. Dabei machen wir uns die Tatsache zunutze, dass die Bilder, an denen wir interessiert sind, viele der gleichen Eigenschaften haben wie die Bilder, mit denen das ursprüngliche Netzwerk trainiert wurde. Unter finden Sie eine gute Erklärung des Transfer-Lernens hier.
Ein neuronales Netzwerk definieren
Bevor wir mit dem Transfer-Lernen beginnen, sehen wir uns an, wie wir unser eigenes CNN in PyTorch definieren können. Hier ist ein minimales Beispiel:
von fackel.nn importieren Conv2d, funktionell als F, Linear, MaxPool2d, Modul Klasse Netto(Modul): def __init__(selbst): super(Netto, selbst).__init__() selbst.konv = Conv2d(3, 18, kernel_size=3, schreiten=1, Polsterung=1) selbst.Pool = MaxPool2d(kernel_size=2, schreiten=2, Polsterung=0) selbst.fc1 = Linear(18 * 16 * 16, 64) selbst.fc2 = Linear(64, 10) def weiter(selbst, x): x = F.relu(selbst.konv(x)) x = selbst.Pool(x) x = x.ansehen(-1, 18 * 16 * 16) x = F.relu(selbst.fc1(x)) x = selbst.fc2(x) return x
Wir definieren ein neuronales Netzwerk, indem wir eine Klasse erstellen, die von Module erbt.
Wenn wir das Netzwerk initialisieren, definieren wir die Schichten des Netzwerks:
- eine 2D-Faltungsschicht,
- eine Max-Pooling-Schicht,
- zwei lineare Schichten.
In der Methode forward legen wir fest, was mit den Eingaben x passiert, die wir
in das Netzwerk einspeisen. Dieses Argument x ist ein PyTorch Tensor (ein mehrdimensionales
Array), der in unserem Fall ein Stapel von Bildern ist, die jeweils
3 Kanäle (RGB) haben und 32 mal 32 Pixel groß sind: die Form von x ist dann (b, 3, 32, 32)
wobei b die Chargengröße ist.
Die erste Anweisung unserer forward Methode wendet die Faltungsschicht
auf die Eingabe an, was zu einem 18-kanaligen, 32 x 32 Tensor für jedes Eingabebild führt.
Unmittelbar danach wenden wir
die ReLU-Funktion an.
Als nächstes wenden wir die Max-Pooling-Schicht an, die den Tensor auf die Größe (b, 18, 16, 16) reduziert.
Die view Methode von x formt den Tensor in die angegebene Form um, wobei der
Wert von -1 angibt, dass PyTorch diese Dimension herausfinden soll: dies
ermöglicht uns, mit unterschiedlichen Stapelgrößen zu arbeiten. Das Ergebnis ist ein 1D-Vektor der Größe 4608
für jedes Element unseres Stapels.
Schließlich wenden wir die beiden linearen (vollständig verknüpften) Schichten mit einer weiteren
relu dazwischen an. Dadurch wird unsere Form zunächst von (b, 4608) auf (b, 64) und dann von
auf (b, 10) reduziert. Unsere Ausgabe sind 10 Werte für jedes Bild.
Wir können diese Ergebnisse als eine Art Wahrscheinlichkeit für jede Klasse interpretieren, die richtige Klasse zu sein: Dieses Modell wäre ein Klassifikator für 10 Klassen.
Verwendung eines vortrainierten Modells
Wenn wir anstelle eines eigenen Modells ein bereits trainiertes Modell verwenden möchten, bietet PyTorch eine ganze Reihe von Modellen, die wir problemlos verwenden können. Alles, was wir tun müssen, um Squeezenet zu verwenden, ist zum Beispiel:
von torchvision.models importieren squeezenet1_0 Modell = squeezenet1_0(vorgebildet=True)
Wir können einen Blick auf die Struktur dieses Modells werfen, indem wir es einfach ausdrucken:
print(model) liefert uns:
SqueezeNet( (Funktionen): Sequentiell( (0): Conv2d(3, 96, kernel_size=(7, 7), schreiten=(2, 2)) (1): ReLU(inplace) (2): MaxPool2d(kernel_size=3, schreiten=2, Polsterung=0, Dilatation=1, Modus der Obergrenze=True) (3): Feuer( (quetschen): Conv2d(96, 16, kernel_size=(1, 1), schreiten=(1, 1)) (squeeze_activation): ReLU(inplace) (expand1x1): Conv2d(16, 64, kernel_size=(1, 1), schreiten=(1, 1)) (expand1x1_aktivierung): ReLU(inplace) (erweitern3x3): Conv2d(16, 64, kernel_size=(3, 3), schreiten=(1, 1), Polsterung=(1, 1)) (expand3x3_aktivierung): ReLU(inplace) ) ... ) (Klassifikator): Sequentiell( (0): Aussteiger(p=0.5) (1): Conv2d(512, 1000, kernel_size=(1, 1), schreiten=(1, 1)) (2): ReLU(inplace) (3): AvgPool2d(kernel_size=13, schreiten=1, Polsterung=0) ) )
Das Netzwerk besteht aus zwei Teilen: dem features und dem classifier.
Ich habe die Ausgabe des features Teils gekürzt, um die
Lesbarkeit zu erhalten: Es enthält 12 Schichten, von denen acht Fire Module sind.
Diese Module enthalten sechs Unterschichten und sind das entscheidende Merkmal von Squeezenet,
lesen Sie hier mehr darüber.
Für uns ist jedoch der classifier Teil viel interessanter: Hier
nimmt das Netzwerk die endgültige Klassifizierung auf der Grundlage der Merkmale vor, die
in den vorherigen Schichten erstellt wurden. Wenn wir Transfer-Lernen betreiben wollen, ist dies
die Schicht, die wir ersetzen wollen.
Beachten Sie, dass Squeezenet für ein System entwickelt und trainiert wurde, das auf
ImageNet
Datensatz, der 1000 Klassen enthält. Wir können die Ebene Conv2d
durch unsere eigene Ebene mit der entsprechenden Anzahl von Klassen ersetzen. Zum Beispiel:
Modell.num_classes = n_classes Modell.Klassifikator[1] = nn.Conv2d(512, n_classes, kernel_size=(1, 1), schreiten=(1, 1))
Hier stellen wir auch das Attribut num_classes des Netzwerks ein, das intern
verwendet wird, um die endgültige Ausgabe des Netzwerks neu zu gestalten.
Ausbildung
Da wir nun ein Modell erstellt haben, müssen wir es im nächsten Schritt trainieren. Dafür benötigen wir die folgende Trainingsschleife:
von fackel.nn importieren CrossEntropyLoss von fackel.optim importieren SGD Modell.Zug() Kriterium = CrossEntropyLoss() Optimierer = SGD(Modell.Parameter(), lr=1E-3, Schwung=0.9) für Eingaben, Etiketten in Lader: Optimierer.null_grad() Ausgaben = Modell(Eingaben) Verlust = Kriterium(Ausgaben, Etiketten) Verlust.rückwärts() Optimierer.Schritt()
Zunächst versetzen wir das Modell in den Trainingsmodus - was das bedeutet, erkläre ich weiter unten. Als Nächstes definieren wir unseren Verlust, Cross-Entropie-Verlust, und unseren Optimierer: Stochastic Gradient Descent. Um die Parameter des Optimierers brauchen wir uns noch nicht zu kümmern.
Dann beginnen wir mit der Trainingsschleife. Wir durchlaufen eine Schleife über den Inhalt eines loader Objekts,
, das wir uns in einer Minute ansehen werden. Jede Iteration liefert zwei Elemente:
die inputs und die labels. Es handelt sich um PyTorch-Tensoren, deren
erste Dimension die Losgröße ist. Die inputs kann
direkt in das Modell eingespeist werden, während labels eine einzige Dimension hat, deren
Größe gleich der Stapelgröße ist: Sie repräsentiert die Klasse jedes Bildes.
Wir beginnen jede Iteration, indem wir den Optimierer zurücksetzen, indem wir zero_grad,
aufrufen und dann die Eingaben durch das Modell leiten. Als nächstes verwenden wir unsere Verlustfunktion
, um den Verlust für die Ergebnisse des Modells zu berechnen. Während wir diese Berechnungen durchführen
verfolgt PyTorch automatisch unsere Operationen und wenn wir backward() auf
aufrufen, berechnet es die Ableitung (Gradient) jedes der Schritte
in Bezug auf die Eingaben. Dieser Gradient ist es dann, den der Optimierer
zur Optimierung der Gewichte verwenden kann, wenn wir step() aufrufen.
Wir nennen die gesamte Trainingsschleife über alle Elemente im Lader eine Epoche.
Bewertung
Nachdem Sie eine oder mehrere Epochen lang trainiert haben, sind Sie wahrscheinlich an der Leistung Ihres Netzwerks interessiert. Wir können das beurteilen, indem wir den Gesamtverlust auf dem Evaluationsset wie folgt berechnen:
von Fackel importieren max, no_grad Modell.eval() Verlust = 0 mit no_grad(): für Eingaben, Etiketten in Lader: Ausgaben = Modell(Eingaben) Verlust += Kriterium(Ausgaben, Etiketten) _, Vorhersagen = max(Ausgaben.Daten, dimmen=1) ...
Zunächst müssen wir unser Modell in den Evaluierungsmodus versetzen (was dasselbe ist
wie das Deaktivieren des Trainingsmodus mit .train(False)). Dadurch werden Funktionen
deaktiviert, die bei der Verwendung der Trainingszeit praktisch sind, wie z. B.
Dropout, in
, um die maximale Leistung aus unserem Netzwerk herauszuholen. Als nächstes geben wir die
no_grad Kontext, in dem die automatische Berechnung von Gradienten deaktiviert ist:
brauchen wir das während der Auswertung nicht.
Dann haben wir eine Schleife, die der im Trainingsfall ähnelt: wir machen eine Schleife über
die inputs und die labels aus dem Lader, übergeben die inputs an das Modell
und berechnen den Verlust. Außerdem können wir die Vorhersagen des Modells
einsehen (und möglicherweise verwenden), indem wir die Funktion torch.max verwenden, die
ein Tupel von (Maximalwerten, Positionen) zurückgibt. Diese Positionen entsprechen dem Ausgangsknoten
(und damit der Klasse), der nach unserem Modell die höchste Wahrscheinlichkeit hat,
was wir als Index der wahrscheinlichsten Klasse interpretieren können.
Der Lader
Natürlich sind Daten unerlässlich, um einen Klassifikator zu trainieren oder zu evaluieren.
In den beiden vorangegangenen Abschnitten haben wir den Inhalt dieses loader
Objekt, das wir vorher nicht definiert haben. Um es zu erstellen, müssen wir zunächst
einen Datensatz definieren.
Natürlich reicht ein einziger Datensatz nicht aus: Wir benötigen sowohl einen Trainings- als auch einen Testdatensatz . Darüber hinaus möchten Sie vielleicht auch einen Validierungsdatensatz haben. Angenommen, Sie haben Ihre Bilder in einer Ordnerstruktur wie dieser:
Bilder/ Zug/ Klasse_1/ Klasse_2/ ... Zug/ Klasse_1/ Klasse_2/ ...
können wir die Datensätze wie folgt definieren:
von torchvision importieren verwandelt von torchvision.datasets importieren ImageFolder train_transform = verwandelt.Komponieren Sie([ verwandelt.RandomResizedCrop(224), verwandelt.RandomHorizontalFlip(), verwandelt.ToTensor(), ]) test_transform = verwandelt.Komponieren Sie([ verwandelt.Größe ändern(256), verwandelt.CenterCrop(224), verwandelt.ToTensor() ]) train_set = ImageFolder(images/train', transformieren=train_transform) test_set = ImageFolder(Bilder/Test, transformieren=test_transform)
Für jeden Bildsatz stellen wir eine Transformation bereit, die PyTorch mitteilt, was mit den Bildern beim Lesen tun soll. Wir definieren zwei Transformationen, eine für jeden Datensatz.
Werfen wir zunächst einen Blick auf test_transform: Wenn wir ein Testbild lesen, werden wir
- die Größe des Bildes so ändern, dass die kleinste Dimension des Bildes 256 Pixel beträgt, dann können wir
- ein Quadrat von 224 x 224 Pixeln aus der Mitte des verkleinerten Bildes ausschneiden und schließlich
- konvertieren Sie das Ergebnis in einen Tensor, so dass PyTorch es durch ein Modell leiten kann.
In der train_transform machen wir etwas anders: wir
- Nehmen Sie einen zufälligen Ausschnitt einer zufälligen Größe (zwischen bestimmten Grenzen) und eines Seitenverhältnisses und ändern Sie die Größe auf 224x224,
- spiegeln Sie das Bild zufällig horizontal, und schließlich
- das Ergebnis in einen Tensor umwandeln.
Das bedeutet, dass das Modell zwar jedes Trainingsbild einmal während jeder Epoche sieht, aber die genauen Bilder, die es sieht, variieren von Epoche zu Epoche: Manchmal sieht es den größten Teil des Bildes und ein anderes Mal nur einen kleinen Ausschnitt. Da die meisten Objekte immer noch ungefähr gleich aussehen, wenn wir das Bild horizontal spiegeln, möchten wir, dass das Modell auch von den gespiegelten Bildern lernt. Vertikal gespiegelte (auf den Kopf gestellte) Bilder sehen in der Regel nicht mehr wie das gleiche Objekt aus, also spiegeln wir nur horizontal.
All diese zufällige Umwandlung der Trainingsbilder hilft zu verhindern, dass unser Modell zu sehr angepasst wird: kann es nicht auswendig lernen, dass ein kleiner Teil eines Bildes zu einem bestimmten Label gehört, da es in jeder Epoche eine andere Teilmenge des Bildes sieht.
Sobald wir die Datensätze definiert haben, können wir die Lader erstellen:
von torch.utils.data importieren DataLoader train_loader = DataLoader( Datensatz=train_set, chargen_größe=32, num_workers=4, Shuffle=True, ) test_loader = DataLoader( Datensatz=test_set, chargen_größe=32, num_workers=4, mischen=True, )
Zu jedem stellen wir den jeweiligen Datensatz zur Verfügung, und wir geben an, dass:
- die Stapelgröße ist 32 (Sie können auch andere Werte ausprobieren),
- wir wollen vier Prozesse zum Lesen und Umwandeln der Bilder und
- wir wollen die Bilder in zufälliger Reihenfolge lesen.
Jetzt haben wir alle Zutaten, um mit dem Training unseres Modells zu beginnen! Aber...
Lernrate
Damals, als wir den Optimierer definiert haben,
Optimierer = SGD(Modell.Parameter(), lr=1E-3, Schwung=0.9)
haben wir seine Parameter übersprungen. Und besonders der erste, lr, die Lernrate,
ist sehr wichtig. Dieser Parameter legt fest, wie stark die Gewichte
in jedem Optimierungsschritt geändert werden. Mit anderen Worten, er legt unsere Schrittgröße fest, wenn wir
nach dem optimalsten Satz von Gewichten suchen.
Schauen wir uns ein 1D-Beispiel an. Nehmen wir an, dass wir den Minimalwert in den unten abgebildeten Kurven finden wollen. Wenn unsere Lernrate zu groß ist, könnten wir tatsächlich vom Minimum weggehen, wie wir links sehen. Wenn andererseits unsere Lernrate zu niedrig ist, bewegen wir uns sehr langsam und laufen Gefahr, in einem lokalen Optimum stecken zu bleiben.
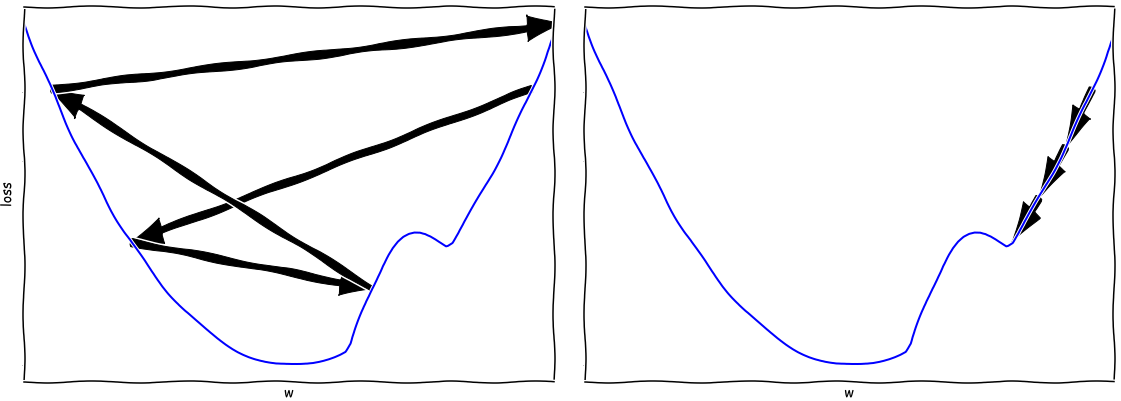
Nun könnten Sie geneigt sein, eine klassische Hyperparametersuche durchzuführen, indem Sie einfach viele Werte für die Lernrate ausprobieren und sehen, wie gut das Modell am Ende abschneidet. Aber das Trainieren eines einzigen Modells dauert auf einem anständigen Grafikprozessor mindestens ein paar Stunden, so dass das Trainieren von Dutzenden (oder Hunderten!) dieser Modelle zu einer kostspieligen Angelegenheit werden würde.
Ein besserer Weg, um den optimalen Wert der Lernrate herauszufinden, ist ein Sweep der Lernrate : Wir trainieren unser Modell für eine Reihe von Batches für eine Reihe von Lernraten . In dem Beispiel hier habe ich einen kleinen Pseudocode eingefügt:
def set_learning_rate(Optimierer, lern_rate): für param_group in Optimierer.param_groups: param_group['lr'] = lern_rate lern_raten = np.logspace(min_lr, max_lr, num=n_Schritte) Ergebnisse = [] für lern_rate in lern_raten: set_learning_rate(Optimierer, lern_rate) train_batches(...) Ergebnisse.anhängen.(bewerten(...))
Das Ergebnis sollte in etwa so aussehen:
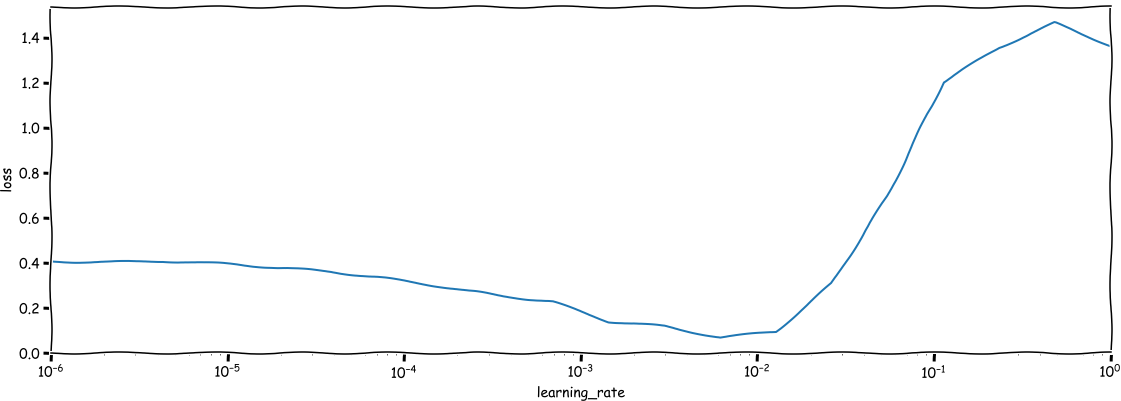
Wir sehen, dass wir anfangs nur sehr langsam lernen, aber nach einer Weile verbessert sich die Leistung. Dann, wenn die Lernrate einen Punkt um (10^{-2} ) überschreitet, sehen wir, dass die Leistung unseres Netzwerks abnimmt (der Verlust steigt), bis zu dem Punkt, an dem die Ergebnisse schrecklich sind. Ihre ideale Einstellung ist dort, wo die Verbesserung am schnellsten ist, d.h. wo die Linie am steilsten nach unten geht. Für das obige Beispiel wäre das irgendwo bei (10^{-3}).
Vergessen Sie nicht, das Netzwerk nach dem Sweep auf den Zustand vor dem Sweep zurückzusetzen, , da die Batches mit den höchsten Lernraten höchstwahrscheinlich die Leistung Ihres Netzwerks ruiniert haben .
Scheduler für Lernraten
Leider reicht es nicht aus, einmal einen Sweep zu machen, denn die beste Lernrate hängt von dem Zustand unseres Netzwerks ab. Je näher wir den idealen Gewichten kommen, desto niedriger sollten wir unsere Lernrate ansetzen. Wir können dieses Problem mit Hilfe eines Lernratenplaners lösen.
Wir können zum Beispiel den ReduceLROnPlateau Scheduler verwenden, der die Lernrate
verringert, wenn der Verlust eine Zeit lang stabil war:
von torch.optim.lr_scheduler importieren ReduceLROnPlateau Planer = ReduceLROnPlateau(Optimierer, Faktor=0.5, Geduld=10)
Dieser Scheduler ist so konfiguriert, dass er die Lernrate um den Faktor 2 reduziert, wenn die Leistung von
10 Epochen lang stabil war.
Als nächstes müssen wir nur noch scheduler.step(test_loss) nach jeder Epoche aufrufen,
und der Scheduler wird die Lernrate automatisch an die Situation anpassen.
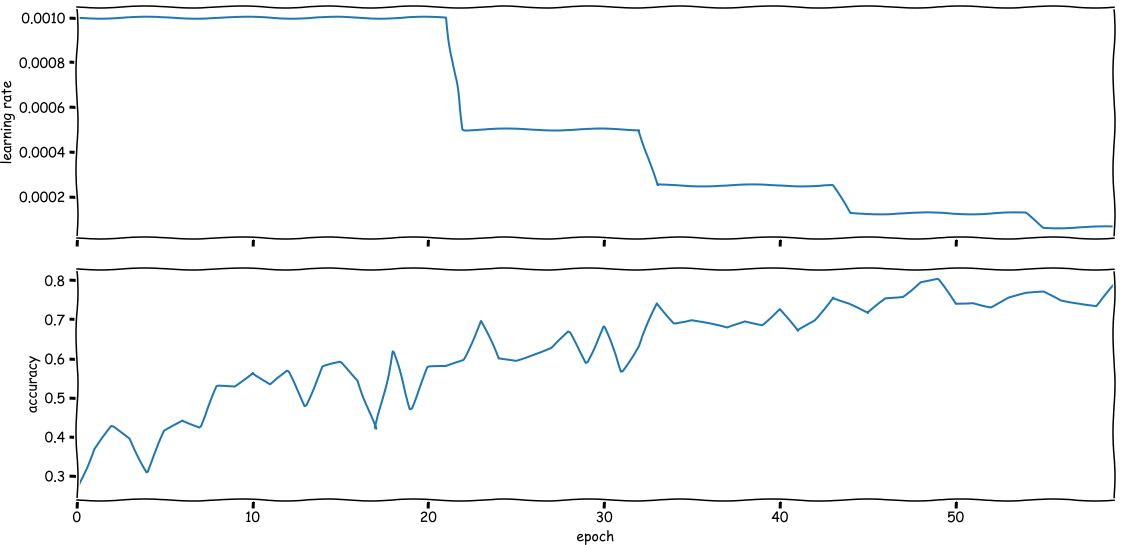
Das Ergebnis sieht in etwa so aus wie in der Abbildung unten: Von Zeit zu Zeit wird der Scheduler beschließen, die Lernrate zu verringern, wenn er der Meinung ist, dass sich der Verlust nicht ausreichend verbessert .
Alles, was Sie jetzt noch brauchen, um Ihren eigenen Bildklassifikator zu erstellen, ist ein Datensatz!
Wohin als nächstes?
Wenn Sie mehr Beispielcode suchen, schauen Sie sich dieses Projekt an, mit dem ich einen Bildklassifikator erstellt habe, der die Skylines einiger großer Städte erkennen kann. Ich habe auf der EuroPython 2019 einen Vortrag über das Projekt gehalten, dessen Folien Sie hier finden. Und natürlich sind die PyTorch-Dokumente Ihr Freund, wenn Sie so etwas bauen!
Erfahren Sie mehr über Deep Learning!
Möchten Sie sich mit Deep Learning vertraut machen? Unser dreitägiger Deep Learning-Kurs vermittelt Ihnen die Theorie, die Sie wissen müssen, und bietet Ihnen jede Menge praktische Erfahrung.
Verfasst von
Rogier van der Geer
Unsere Ideen
Weitere Blogs




Contact