
Wie unterscheidet sich High-Performance Computing auf AWS vom normalen Computing?
Die heutige Serverhardware ist leistungsfähig genug, um die meisten Rechenaufgaben auszuführen. Mit gängigen Rechenressourcen können die meisten (seriellen) Rechenaufgaben gelöst werden. Einige Aufgaben sind jedoch sehr komplex und erfordern einen anderen Ansatz. Denken Sie an Fälle, die eine verbesserte Geschwindigkeit und Effizienz, die Fähigkeit zur Verarbeitung großer Datenmengen und Flexibilität usw. erfordern. Hierfür bringt HPC massiv paralleles Computing, Cluster- und Workload-Manager und Hochleistungskomponenten ins Spiel.
Warum HPC und Cloud gut zusammenpassen
- Die Einrichtung von HPC in der Cloud erfordert keine Vorabinvestitionen (CAPEX).
- Keine veraltete Infrastruktur. Mit einer öffentlichen Cloud haben Sie Zugriff auf die neuesten Komponenten, die nicht nur eine bessere Leistung, sondern auch ein besseres Preis-Leistungs-Verhältnis bieten.
- Geringere laufende Kosten. Umgebungen können beendet werden, sobald der Auftrag ausgeführt wurde. Dadurch werden die Betriebs- und Verwaltungskosten gesenkt.
- Ressourcen sind auf Abruf verfügbar, es gibt keine Bestell-/Wartezeit für die Bereitstellung von Ressourcen.
- Die Sicherheitsfunktionen der Cloud können genutzt werden, um Sicherheitskontrollen auf Auftragsebene (Richtlinien, Verschlüsselung usw.) zu ermöglichen.
HPC-Grundlagen
Modernes HPC besteht aus den folgenden Komponenten:
- Hauptknoten - zur Konfiguration von Aufträgen und zur Orchestrierung verteilter Aufträge
- Rechenknoten - um die schwere Arbeit zu erledigen
- GPUs - zur Beschleunigung von Berechnungen
- Optimierter Speicher - entweder lokaler/gemeinsamer Speicher mit niedriger Latenz oder Blob-Speicher (S3)
- Netzwerk - für konsistente Latenz und Durchsatz
- Container - zur Bündelung von Anwendungen und Abhängigkeiten
- Linux - wissenschaftliche Software basiert oft auf Linux-Distributionen
In den nächsten Kapiteln wird dies auf AWS-Ressourcen übertragen.
HPC-Dienste auf AWS
Berechnen Sie
Technisch gesehen könnten Sie Ihren eigenen HPC-Cluster auf AWS entwerfen und bauen. Es wird funktionieren, aber Sie werden viel Zeit mit Klempnerarbeiten und undifferenziertem Heavy Lifting verbringen. Der wahre Wert der Cloud liegt in der Nutzung von Abstraktionsdiensten auf höherer Ebene. AWS bietet zwei Services zur Unterstützung Ihrer HPC-Arbeitslast.
AWS Stapel
AWS Batch ist ein vollständig verwalteter Service, der die Ausführung von Batch-Computing-Arbeitslasten über AWS-Services hinweg vereinfacht. Er bietet eine leistungsstarke und skalierbare Plattform für die Ausführung umfangreicher Batch-Aufträge mit minimalem Einrichtungs- und Verwaltungsaufwand. Mit AWS Batch müssen Sie keine Batch-Computing-Software installieren oder verwalten, so dass Sie Ihre Zeit auf die Analyse von Ergebnissen und die Lösung von Problemen konzentrieren können.
Die wichtigsten Funktionen von AWS Batch
- Effizientes Ressourcenmanagement: AWS Batch stellt automatisch die erforderlichen Ressourcen wie Recheninstanzen und Speicherplatz auf der Grundlage der Auftragsanforderungen bereit. Es skaliert die Ressourcen dynamisch nach oben und unten und sorgt so für optimale Auslastung und Kosteneffizienz.
- Auftragsplanung und Prioritätensetzung: Mit AWS Batch können Sie Auftragswarteschlangen, Prioritäten und Abhängigkeiten definieren, was eine effiziente Planung und Ausführung von Aufträgen ermöglicht. Dadurch wird sichergestellt, dass wichtige Aufgaben priorisiert und auf die effektivste Weise ausgeführt werden.
- Integration mit AWS-Diensten: AWS Batch lässt sich nahtlos in andere AWS-Services wie Amazon S3, AWS Lambda und Amazon DynamoDB integrieren. So können Sie End-to-End-Workflows erstellen, die das gesamte Spektrum der AWS-Funktionen für Datenverarbeitung, Speicherung und Analyse nutzen.
AWS Batch besteht aus den folgenden Komponenten:
Jobs
Ein Job ist eine Arbeitseinheit, die als containerisierte Anwendung auf AWS Fargate oder Amazon EC2 in Ihrer Datenverarbeitungsumgebung ausgeführt wird. Jobs können Artefakte wie Docker-Container-Images, Shell-Skripte oder reguläre ausführbare Linux-Dateien sein.
Job-Definitionen
AWS Batch-Auftragsdefinitionen legen fest, wie Aufträge ausgeführt werden sollen. Jeder Auftrag verweist auf eine Auftragsdefinition. Die Definition umfasst Konfigurationen wie CPU, Speicher, Orchestrierungstyp, parallele Ausführung mit mehreren Knoten, Ausführungszeitüberschreitungen, Prioritäten, Wiederholungsbedingungen, Zielknoten, Speichervolumen, (EKS-)Container-Konfiguration, Geheimnisse usw. Zu guter Letzt konfigurieren Sie IAM-Rollen und Richtlinien. Viele der Parameter können während der Laufzeit überschrieben werden.
Auftragswarteschlangen
Zunächst werden Aufträge an eine Auftragswarteschlange übermittelt. Jedes AWS-Konto kann mehrere Warteschlangen beherbergen, mit denen Sie zum Beispiel Warteschlangen mit hoher und niedriger Priorität konfigurieren können, die jeweils eigene Merkmale aufweisen. Die Aufträge verbleiben in der Warteschlange, bis sie für die Ausführung in der Rechenumgebung geplant werden können.
Compute-Umgebung
Compute-Umgebungen sind mit einer Job-Warteschlange verbunden (eine oder mehrere Umgebungen pro Warteschlange und/oder eine oder mehrere Warteschlangen pro Umgebung). Jede Umgebung kann unterschiedliche Spezifikationen/Konfigurationen haben. Vorzugsweise werden verwaltete Datenverarbeitungsumgebungen verwendet. Damit verwaltet AWS Batch Kapazität und Instanztypen. Es kann auch EC2 On-Demand-Instanzen und EC2 Spot-Instanzen in Ihrem Namen verwalten, wählt das richtige AMI aus, da es GPU-optimierte AMIs für Instanztypen mit GPU-Beschleunigung verwendet. Es ist auch möglich, Ihren eigenen ECS-Cluster zu verwenden, indem Sie nicht verwaltete Rechenumgebungen konfigurieren.
Richtlinien zur Terminplanung
Mithilfe von Planungsrichtlinien können Sie konfigurieren, wie Aufträge in der Warteschlange zugewiesen werden und wie die Ressourcen zwischen Aufträgen/Benutzern aufgeteilt werden.
AWS ParallelCluster
AWS ParallelCluster ist ein Open-Source-Cluster-Management-Tool, das die Erstellung und Verwaltung von HPC-Clustern (High Performance Computing) vereinfacht. Es ermöglicht Benutzern die Einrichtung von Clustern in wenigen einfachen Schritten und automatisiert den Prozess der Bereitstellung und Konfiguration der erforderlichen Ressourcen.
Hauptmerkmale von AWS ParallelCluster
- Flexibilität und Anpassbarkeit: AWS ParallelCluster unterstützt eine breite Palette von Anwendungen und Frameworks, darunter so beliebte wie MPI, TensorFlow und Apache Hadoop. Diese Flexibilität ermöglicht es Ihnen, maßgeschneiderte Umgebungen zu erstellen, die Ihren spezifischen Anforderungen entsprechen. Es unterstützt Slurm Workload Manager und AWS Batch als Scheduler.
- Skalierbarkeit: Mit AWS ParallelCluster können Sie Ihre Cluster je nach Arbeitslastanforderung problemlos vergrößern oder verkleinern. Der Service ist mit AWS Auto Scaling integriert, so dass Sie die Größe des Clusters dynamisch anpassen können, um unterschiedliche Rechenanforderungen effizient zu bewältigen.
- Kostenoptimierung: AWS ParallelCluster trägt zur Kostenoptimierung bei, da Sie aus verschiedenen Instance-Typen und Preisoptionen wählen können. So können Sie Spot-Instances für kostengünstiges Computing nutzen und gleichzeitig hohe Verfügbarkeit und Fehlertoleranz gewährleisten.
Slurm Workload-Manager
Bestehende HPC-Anwender kennen vielleicht Slurm, einen hochgradig konfigurierbaren Open-Source-Workload-Manager. Slurm wird für die Verwaltung und Übermittlung von Batch-Aufträgen an den Cluster verwendet. Er verwendet CLI-Befehle wie sbatch (Aufträge übermitteln), salloc (eine Auftragszuweisung erhalten) und srun (einen parallelen Auftrag auf dem Cluster ausführen). Slurm verwaltet auch die Rechenressourcen für Ihren Cluster. Die genaue Konfiguration ist in der Clusterkonfiguration beschrieben.
AWS ParallelCluster-Benutzeroberfläche
AWS ParallelCluster UI ist eine webbasierte Benutzeroberfläche zur Verwaltung von Clustern. Sie basiert auf serverlosen Services (API Gateway / Lambda) und bietet die gleiche Funktionalität wie das CLI-Tool pcluster.
HPC-spezifische Ressourcen
Obwohl die meisten gängigen AWS-Services in einem HPC-System verwendet werden können, bietet AWS einige ergänzende Funktionen
Amazon FSx für Lustre
Lustre ist ein paralleles, verteiltes Open-Source-Dateisystem, das für große Cluster entwickelt wurde. Es verwendet verschiedene Schichten: Verwaltungsserver, Metadatenserver, Objektspeicher-Server und Objektspeicher-Ziele. Durch die Entkopplung von Aufgaben und die Bereitstellung einer Reihe von Servern (bis zu hundert Hosts) kann die Architektur eine Skala von Terabyte pro Sekunde bieten, die von Tausenden von Hosts genutzt wird. Sie bietet mehr Skalierbarkeit als herkömmliche Netzwerk-Dateisysteme. Lustre ist POSIX-kompatibel. AWS bietet Lustre als verwalteten Service an (Amazon FSx für Lustre). Das Einrichten eines neuen Clusters und dessen Wartung erfordern nur minimalen Aufwand. Die Daten werden mit AWS KMS, Verschlüsselung während der Übertragung, IAM und täglichen Backups in S3 geschützt und verfügen über AWS Backup Support. Lustre unterstützt nur Linux-Clients.
Elastic Fabric Adapter
Elastic Fabric Adapter (EFA) ist eine Art Netzwerkschnittstelle für Amazon EC2-Instanzen. Er nutzt OS-Bypass-Funktionen und verbessert die Leistung der Kommunikation zwischen den Instanzen, die für die Skalierung von HPC- und Machine Learning-Anwendungen entscheidend ist. Sie ist für den Einsatz in der bestehenden AWS-Netzwerkinfrastruktur optimiert und kann je nach Anwendungsanforderungen skaliert werden. Mit einer EFA verwenden HPC-Anwendungen MPI oder NCCL als Schnittstelle zur Libfabric-API. Die Libfabric-API umgeht den Betriebssystemkern und kommuniziert direkt mit dem EFA-Gerät, um Pakete über das Netzwerk zu übertragen. Dadurch wird der Overhead reduziert und die HPC-Anwendung kann effizienter ausgeführt werden. EFA ist kein Ersatz für normale Schnittstellen, da es Einschränkungen hat, z.B. kann es nicht zum Senden außerhalb des Subnetzes verwendet werden.
Ausführen Ihrer ersten HPC-Anwendung
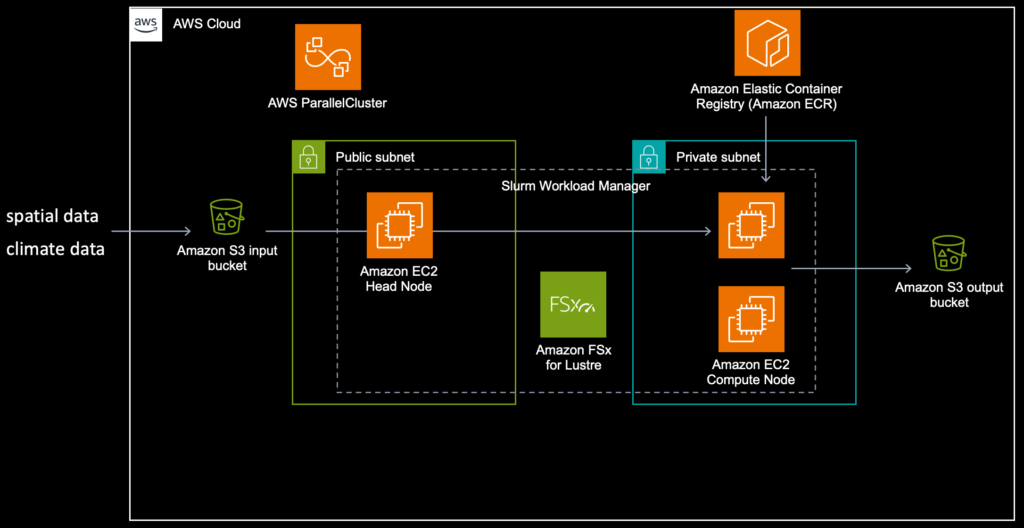
In diesem Blogbeitrag verwenden wir AWS ParallelCluster, um die Arbeitslast zu verwalten. Das Lösungsdiagramm unten bietet einen Überblick über die Lösung.
Wie bei den meisten anderen Systemen, die für den Betrieb auf AWS konzipiert sind, müssen Sie zunächst einige Grundlagen schaffen. Sowohl AWS Batch als auch AWS ParallelCluster basieren auf EC2 und Netzwerken. Dies erfordert eine VPC mit öffentlichen und privaten Subnetzen, Zugang zum Internet (Routen/NAT-Gateway). Wichtig ist, dass AWS ParallelCluster die VPC-Optionen benötigt DNS-Auflösung = ja und DNS-Hostnamen = ja aktiviert werden.
Cluster-Konfigurationsdatei generieren
Es wird empfohlen, die folgenden Befehle in einer Virtualenv auszuführen. Sie können die Befehle auf Ihrem lokalen Rechner oder auf EC2 in AWS ausführen. Bevor Sie beginnen, stellen Sie sicher, dass Sie Ihre VPC-Konfiguration und Ihr SSH-Schlüsselpaar konfiguriert haben. Die pcluster configure führt Sie durch eine Reihe von Fragen, wie z. B. die VPC-Subnetz-ID für Ihren Hauptknoten, die maximale Größe Ihres Clusters, Instance-Typen usw. Es ist selbsterklärend, wenn Sie die AWS-Grundlagen kennen. Für weitere Informationen zur Installation der Tools klicken Sie auf hier.
$ pip install -U aws-parallelcluster setuptools-rust
$ export AWS_PROFILE=myprofile
$ pcluster configure --config cluster-config.yamlDadurch wird eine Konfigurationsdatei erzeugt:
Region: eu-west-1
Image:
Os: alinux2
HeadNode:
InstanceType: t2.micro
Networking:
SubnetId: subnet-08c245b78a82c3924
Ssh:
KeyName: steyn-mbp
Scheduling:
Scheduler: slurm
SlurmQueues:
- Name: queue1
ComputeResources:
- Name: t2micro
Instances:
- InstanceType: t2.micro
MinCount: 0
MaxCount: 10
Networking:
SubnetIds:
- subnet-0b864625631add41e
- subnet-0053337e5ceeea8f3
- subnet-035761b17a12851ac
SharedStoragein Betracht ziehen.
Erstellen des Clusters
Erstellen Sie nun den Cluster$ export AWS_PROFILE=myprofile
$ pcluster create-cluster --cluster-name steyn --cluster-configuration cluster-config.yamllist-clusterskönnen Sie den Fortschritt sehen:
$ export AWS_PROFILE=myprofile
$ pcluster list-clusters
{
"clusters": [
{
"clusterName": "steyn",
"cloudformationStackStatus": "CREATE_IN_PROGRESS",
"cloudformationStackArn": "arn:aws:cloudformation:eu-west-1:123456789012:stack/steyn/173732e0-16b1-11ee-a432-0ab77f79d7f7",
"region": "eu-west-1",
"version": "3.6.0",
"clusterStatus": "CREATE_IN_PROGRESS",
"scheduler": {
"type": "slurm"
}
}
]
}Warten Sie nun darauf, dass der clusterStatus sich in CREATE_COMPLETED. Dies kann eine Weile dauern. Prüfen Sie nach Abschluss, ob Sie sich bei Ihrem Hauptknoten anmelden können:
$ export AWS_PROFILE=myprofile
$ pcluster ssh --cluster-name steyn
[ec2-user@ip-10-0-0-149 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
queue1* up infinite 10 idle~ queue1-dy-t2micro-[1-10]Ihr Cluster ist nun in Betrieb und wartet darauf, dass Aufträge an die Warteschlange übermittelt werden. In Ihrer EC2-Konsole sehen Sie jetzt einen aktiven Knoten, den Head Node.
Ihren ersten Auftrag einreichen
Lassen Sie uns mit einem einfachen Auftrag beginnen, um zu überprüfen, ob alles funktioniert. Erstellen Sie ein einfaches Skript namens hellojob.sh.
$ cat > hellojob.sh
#!/bin/bash
sleep 30
echo "Hello World from $(hostname)"
Senden Sie dieses Skript nun an die Warteschlange:
$ sbatch hellojob.sh
$ sinfoAWS ParallelCluster wird nun einen Rechenknoten für diesen Auftrag erstellen. Es kann einen Moment dauern, bis der Rechenknoten Aufträge aus der Warteschlange abruft.
Sie können die Warteschlange anzeigen, indem Sie squeue ausführen:
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
1 queue1 hellojob ec2-user R 0:08 1 queue1-dy-t2micro-2Dieser Auftrag mit der Auftragsnummer 1 befindet sich seit 0:08 Sekunden in der Ausführung. Die Spalte ST zeigt den Status an. Nach Abschluss des Auftrags wird die Ausgabe in das aktuelle Arbeitsverzeichnis in eine Datei geschrieben, die nach der Auftragsnummer benannt ist: slurm-1.out.
Planen von parallelen Aufträgen
Es gibt mehrere Strategien, um parallele Aufträge zu planen. Der bequemste Weg ist die Verwendung von Auftrags-Arrays in sbatch. Im nächsten Beispiel werden wir 64 Aufträge in einem Array planen.
$ sbatch --array=0-64 hellojob.sh
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
20_[40-64] queue1 hellojob ec2-user PD 0:00 1 (Resources)
20_30 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-1
20_31 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-7
20_32 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-2
20_33 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-8
20_34 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-6
20_35 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-9
20_36 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-3
20_37 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-4
20_38 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-5
20_39 queue1 hellojob ec2-user R 0:03 1 queue1-dy-t2micro-10Die Ergebnisse werden erneut in Ihr lokales Arbeitsverzeichnis geschrieben, allerdings mit einem anderen Namen. Die Jobid wird nun an den Array-Index angehängt.
ls | tail
slurm-20_5.out
slurm-20_60.out
slurm-20_61.out
slurm-20_62.out
slurm-20_63.out
slurm-20_64.out
slurm-20_6.out
slurm-20_7.out
slurm-20_8.out
slurm-20_9.outAufräumen
Compute Nodes werden standardmäßig nach 10 Minuten Leerlaufzeit beendet. Beobachten Sie die EC2-Konsole, um den Status zu überprüfen. Nach 10 Minuten sollte nur noch der Hauptknoten in Betrieb sein.
Beenden Sie nun den Cluster. Diese Befehle müssen in Ihrer pcluster-Umgebung ausgeführt werden.
$ export AWS_PROFILE=myprofile
$ pcluster delete-cluster --cluster-name steyn
$ pcluster list-clusters
{
"clusters": [
{
"clusterName": "steyn",
"cloudformationStackStatus": "DELETE_IN_PROGRESS",
"cloudformationStackArn": "arn:aws:cloudformation:eu-west-1:123456789012:stack/steyn/173732e0-16b1-11ee-a432-0ab77f79d7f7",
"region": "eu-west-1",
"version": "3.6.0",
"clusterStatus": "DELETE_IN_PROGRESS",
"scheduler": {
"type": "slurm"
}
}
]
}
Wiederholen Sie den letzten Befehl, bis sich der Status ändert. Die Ausgabe sieht dann etwa so aus
$ export AWS_PROFILE=myprofile
$ pcluster list-clusters
{
"clusters": []
}Verwaltung des Clusters
Für einen bequemeren Zugriff auf den Cluster, die Aufträge und die Warteschlangen empfiehlt sich die Installation von AWS ParallelCluster UI. Dies ist eine serverlose Web-Benutzeroberfläche, die die pcluster-Funktionalität widerspiegelt.
Andere Ressourcen
Das Well-Architected Framework ist eine solide Grundlage für die Entwicklung und den Aufbau von Systemen auf AWS. Dieses Framework bietet Anleitungen und die Möglichkeit zur Selbsteinschätzung. Es gibt eine spezielle Linse (Fokus) für HPC-Workloads, siehe hier.
Verfasst von
Steyn Huizinga
As a cloud evangelist at Oblivion, my passion is to share knowledge and enable, embrace and accelerate the adoption of public cloud. In my personal life I’m a dad and a horrible sim racer.
Unsere Ideen
Weitere Blogs




Contact