Seien Sie nicht ein einsames Dokument": Das ist ein berühmtes Zitat von Emil Eifrem. Letzte Woche auf der Graphconnect hat er es noch einmal wiederholt, zusammen mit dem Auftrag, über die Konferenz zu twittern. Das hat mich dazu inspiriert, Twitter nach den Schlüsselwörtern "neo4j" und "graphconnect" zu durchsuchen und in Neo4j einzugeben. Verbinden sich die Menschen wirklich?
In meinem ersten Setup habe ich versucht, Tweets in Echtzeit mit Logstash abzurufen, den Stream in Kafka zu veröffentlichen und einen Spark Streaming Job laufen zu lassen, der jeden Tweet verarbeitet und in Neo4j einfügt.
Sie können die folgende Logstash-Konfiguration verwenden, um genau das zu tun.
Eingabe {
twitter {
consumer_key => "foo"
consumer_secret => "bar"
oauth_token => "baz"
oauth_token_secret => "qux"
Schlüsselwörter => ["graphconnect", "neo4j", "GraphConnect"]
}
}
Ausgabe {
kafka {
codec => einfach {
Format => "%{message}"
}
topic_id => "Tweets"
}
}
Der nächste Schritt ist der Spark Streaming-Auftrag. Ich hatte ein altes Testprojekt, das genau das tut. Einige Code-Beispiele finden Sie unter: https://github.com/rweverwijk/twitter-to-neo4j
Ein schwacher Laptop-Akku zwang mich, dieses kleine Experiment abzubrechen, aber es ging mir nicht aus dem Kopf.
Später zu Hause suchte ich nach einer neuen Lösung, um alle Tweets mit den ausgewählten Schlüsselwörtern zu sammeln. Ich habe das folgende einfache Python-Skript erstellt, um nach Tweets zu suchen und das JSON in einer Datei zu speichern:
importieren tweepy importieren Zeit importieren json ckey = 'foo' csecret = 'bar' atoken = 'baz' asecret = 'qux' OAUTH_KEYS = {'verbraucher_schlüssel': ckey, 'verbraucher_geheimnis':csecret, access_token_key':atoken, access_token_secret'.:asecret} auth = tweepy.OAuthHandler(OAUTH_KEYS['consumer_key'], OAUTH_KEYS['verbraucher_geheimnis']) api = tweepy.API(auth) def limit_handled(Cursor): während True: Versuchen Sie: Ertrag Cursor.nächste() außer tweepy.TweepError als e: drucken(e.fehler_msg) Zeit.schlafen(15 * 60) def Suche(Stichwort): # Extrahieren Sie die ersten "xxx" Tweets zum Thema "schnelles Auto". mit öffnen Sie('tweets_friday.json', 'a') als die_Datei: für tweet in limit_handled(tweepy.Cursor(api.Suche, q=Stichwort, seit='2017-05-09').Artikel()): die_Datei.Schreiben Sie(json.dumps(tweet._json) + 'n')
Jetzt kann der eigentliche Spaß beginnen: Das Laden der Tweets in Neo4j. Die ausgewählte Struktur ist sehr einfach. Da ich mich besonders für Menschen interessiere, die sich verbinden, werde ich nach Twitter-Nutzern und den Erwähnungen in Tweets suchen. Darüber hinaus möchte ich zwischen dem ursprünglichen Verfasser eines Tweets und den Retweetern unterscheiden. Daraus ergibt sich die folgende Struktur:
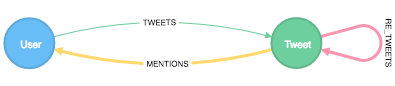
Die Eingabedaten liegen im JSON-Format vor. Ich verwende Python, um diese Daten zu lesen, die Felder zu extrahieren, die ich speichern möchte, und sie in Neo4j zu speichern. Der folgende Codeschnipsel tut genau das:
importieren json von neo4j.v1 importieren GraphDatabase importieren Zeit def speichern_tweet(tx, tweet): neo4j_params = {"user_id": tweet['Benutzer']['id'], "user_name": tweet['Benutzer']['Name'], "tweet_id": tweet['id'], "tweet_text": tweet['Text'], "tweet_time": Zeit.strftime('%Y-%m-%d %H:%M:%S', Zeit.strptime(tweet['erstellt_am'],'%a %b %d %H:%M:%S +0000 %Y')), "Erwähnungen": tweet['Entitäten']['user_mentions'] } tx.laufen(""" MERGE (u:Benutzer {uid: $user_id}) on create set u.name = $user_name MERGE (t:Tweet {uid: $tweet_id}) on create set t.text = $tweet_text, t.time = $tweet_time MERGE (u)-[:TWEETS]->(t) WITH t, $mentions als Erwähnungen unwind erwähnt als Erwähnung MERGE (u:User {uid: mention.id}) on create set u.name = mention.name MERGE (t)-[:MENTIONS]->(u) """, neo4j_params) def verarbeiten_datei(datei_name): mit GraphDatabase.Treiber("bolt://localhost:7687", auth=("neo4j", "Test")) als Treiber: mit öffnen Sie(datei_name, 'r') als die_Datei: mit Treiber.Sitzung() als Sitzung: mit Sitzung.begin_transaction() als tx: für Zeile in die_Datei: tweet = json.lädt(Zeile) speichern_tweet(tx, tweet) wenn 'retweeted_status' in tweet: speichern_tweet(tx, tweet['retweeted_status']) retweet_data = { 'tweet_id': tweet['id'], "retweet_id": tweet['retweeted_status']['id'] } tx.laufen(""" MATCH (t:Tweet {uid: $tweet_id}) MATCH (r:Tweet {uid: $retweet_id}) MERGE (t)-[:RE_TWEETS]->(r) """, retweet_data) verarbeiten_datei(tweets_friday2.json'.)
Schauen wir mal, was wir jetzt in Neo4j finden können.
Lassen Sie uns zunächst einen kurzen Blick auf die Beziehungen innerhalb von MENTIONS werfen:
MATCH p=()-[r:MENTIONS]->() RETURN p LIMIT 50
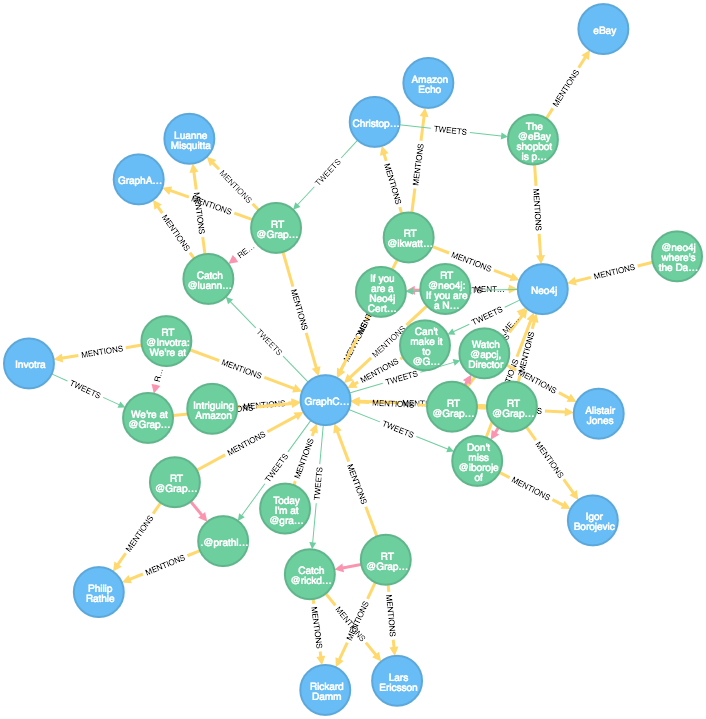
Das sieht schon ganz nett aus!
Lassen Sie uns herausfinden, welcher Benutzer am häufigsten erwähnt wird:
MATCH (t:Tweet)-[r:MENTIONS]->(erwähnt:Benutzer) RETURN mentioned.name, count(r) as numberOfMentions order by anzahlderBemerkungen desc Grenze 10
führt zu:
| Benutzer | numberOfMentions |
|---|---|
| Neo4j | 1014 |
| GraphConnect | 613 |
| Emil Eifrem | 236 |
| Jim Webber | 150 |
| ICIJ | 149 |
| Rik Van Bruggen | 99 |
| GraphAware | 88 |
| LARUS | 86 |
| Philip Rathle | 86 |
| CluedIn | 69 |
Wenn wir die Konten der Organisationen ausschließen, sind die stärksten Einflussnehmer in der Grafik Emil, Jim und Rik. Sie waren ganz sicher keine einsamen Dokumente.
Lassen Sie uns weiterforschen und herausfinden, wer die Tweets mit den Erwähnungen schreibt:
MATCH (u:Benutzer)-[:TWEETS]->(t:Tweet) RETURN u.name as user, count(t) as numberOfTweets order by Anzahl der Tweets desc Grenze 10
| Benutzer | numberOfTweets |
|---|---|
| GraphConnect | 433 |
| Hakaishin Hokutosei | 379 |
| Neo4j | 244 |
| Yuxing Sun | 113 |
| Christophe Willemsen | 109 |
| Neo Fragen | 85 |
| Bence Arato | 42 |
| Cedric Fauvet | 41 |
| Nigel Klein | 38 |
| Mark Wood | 36 |
GraphConnect und Neo4j scheinen ziemlich offensichtlich zu sein, aber Hakaishin Hokutosei kenne ich nicht und 379 scheint eine Menge Tweets zu sein. Worüber tweetet dieser Benutzer?
MATCH (u:Benutzer)-[:TWEETS]->(t:Tweet) wo u.name = "Hakaishin Hokutosei" RETURN t.text Grenze 100
| t.text |
|---|
| RT @BenceArato: Wichtige @neo4j Meilensteine von Version 3.0 bis zu aktuellen und zukünftigen Plänen #GraphConnect https://t.co/J99pXpSzV5 |
| RT @GraphConnect: .@jimwebber: #Neo4j macht keine verrückten JOINs oder Sets - es jagt einfach Zeigern hinterher#GraphConnect |
| RT @GraphConnect: .@jimwebber: Weil #Neo4j eine native #Grafikdatenbank ist und wir den gesamten Stack besitzen, können wir jede Clustering-Anforderung... |
| RT @GraphConnect: .@jimwebber: #Neo4j 3.1 führte Sicherheit und Causal Clusteringn#GraphConnect |
| RT @GraphConnect: .@jimwebber: Causal Clustering, eingeführt in #Neo4j 3.1, kann jetzt mehrere Rechenzentren umfassen#GraphConnect |
| RT @GraphConnect: .@jimwebber: #Neo4j 3.2 Treiber sind sich auch der Causal Clustersn#GraphConnect |
| RT @GraphConnect: .@jimwebber: #Neo4j 3.2 kann jetzt #Kerberos verwenden, vor allem für diejenigen unter Ihnen in #FinServ, die es verwenden müssen#GraphC... |
| RT @matethurzo: Closing keynote of #graphconnect @jimwebber is always fun to watch #graph #graphdb #conferenceday #neo4j #devlife https://... |
| RT @mfalcier: Verfolgen Sie @neo4j #graphconnect Dr. @jimwebber 's Vortrag vom Sofa aus? Fantastisch! https://t.co/U0bCXGEd0D |
| RT @GraphConnect: .@jimwebber: Letztes Jahr in London wurde mit #Neo4j 3.0 die obere Speichergrenze ganz abgeschafft#GraphConnect |
Moment mal, jeder Tweet beginnt mit "RT". Retweetet er nur, oder haben wir auch selbst geschriebene Tweets?
Schauen wir mal:
MATCH (u:Benutzer)-[:TWEETS]->(t:Tweet) wo u.name = "Hakaishin Hokutosei" und nicht (t)-[:RE_TWEETS]->() RETURN count(t)
| zählen(t) |
|---|
| 0 |
Wir müssen also Tweets von Retweets trennen, um zwischen Originalautoren und Retweetern unterscheiden zu können:
MATCH (u)-[r1:TWEETS]->(t) wo nicht (t)-[:RE_TWEETS]->() optionale Übereinstimmung (u)-[:TWEETS]->(rt)-[r2:RE_TWEETS]->() RETURN u.name, count(distinct r2) as numberOfReTweets, count(distinct r1) as numberOfTweets order by Anzahl der Tweets desc
| u.Name | numberOfReTweets | numberOfTweets |
|---|---|---|
| GraphConnect | 238 | 195 |
| Neo4j | 65 | 179 |
| Yuxing Sun | 0 | 113 |
| Neo Fragen | 0 | 85 |
| Mark Wood | 4 | 32 |
| Bence Arato | 18 | 24 |
| Carina Birt | 3 | 23 |
| Marlon Samuels | 0 | 20 |
| Tägliche technische Fragen | 0 | 16 |
| Andres L. Martinez | 1 | 15 |
| Neo4j Frankreich | 11 | 15 |
| Louis Dubruel | 0 | 15 |
| Nigel Klein | 23 | 15 |
| Adam Hill | 5 | 15 |
| Rik Van Bruggen | 1 | 15 |
Was sind die beliebtesten Tweets?
MATCH (rt)-[r2:RE_TWEETS]->(t)[:TWEETS]-(u) RETURN u.name AS user, t.text, count(rt) AS numberOfRetweets ORDER BY numberOfRetweets DESC
| Benutzer | t.text | numberOfRetweets |
|---|---|---|
| Mar Cabra | Arbeiten Sie 6 Monate lang von DC, Paris oder Madrid aus mit @ICIJorg zusammen und machen Sie komplexe Daten und Diagramme dank @neo4js... https://t.co/Z0rR3Rt7zV | 20 |
| ICIJ | Sind Sie daran interessiert, mit Daten Geschichten zu finden? Möchten Sie am nächsten Projekt von ICIJ mitarbeiten? Bewerben Sie sich für das Connected Data Fellowship https://t.co/LUdsjWKwRJ | 18 |
| William Lyon | Demokratisierung von Daten bei @AirbnbEng mit Dataportal, einem neuen Tool zur Skalierung der Datensuche und -entdeckung, angetrieben von @neo4j nnhttps://t.co/e12fHuA26M | 18 |
| Pat Patterson | Visualisierung & Analyse von Salesforce-Daten mit #StreamSets Data Collector & @Neo4j https://t.co/DunEFtAPyO Vielen Dank für gr... https://t.co/pXwBISQtme | 18 |
| ICIJ | Aufregende Ankündigung: Wir stellen jetzt einen Neo4j Connected Data Fellow ein! Mehr Informationen und wie Sie sich bewerben können hier: https://t.co/knjHKgyQiz #GraphConnect | 17 |
| Dr. GP Pulipaka | Ankündigung von Neo4j im Microsoft Azure Marketplace (Teil I). #BigData #DataScience #Neo4J #Azure #Analytics... https://t.co/1XEqQHgedu | 16 |
| Kursion | #GraphConnect Neo4j 3.2 steht heute zum Download bereit https://t.co/QZu3XvAjts | 15 |
Die beliebtesten Tweets drehen sich also um ICIJ und dessen Connected Data Fellowship oder die neue Neo4j-Version.
Und nicht zuletzt: Welches sind die Tweets, die die meisten Retweets erhalten haben und zu Gewinnern des Preises für das am wenigsten "einsame Dokument" erklärt werden können (wenn das eine echte Auszeichnung wäre):
MATCH (rt)-[r2:RE_TWEETS]->(t)[:TWEETS]-(u) RETURN u.name as user, count(rt) as numberOfRetweets order by numberOfRetweets desc
Rik van Bruggen
Oder wie mein lieber Freund Rik sagen würde. "Vielleicht bin ich das einsamste Dokument und das ist der Grund, warum ich so viel über Neo4j twittere, denn ich habe keine Hobbys. ;) "
Unsere Ideen
Weitere Blogs




Contact