Blog
Entwicklung von AWS Glue-Aufträgen mit interaktiven Sitzungen

In diesem Blogbeitrag möchte ich Ihnen zeigen, wie Sie AWS Glue Interactive Sessions verwenden können, um Ihre Entwicklungserfahrung bei der Entwicklung von Glue-ETL-Jobs zu verbessern. Als Beispiel verwende ich den Delta Lake Connector für AWS Glue und beginne mit der Verarbeitung von CDC-Dateien (Change Data Capture), die von AWS Database Migration Service (DMS) generiert werden.
Die Entwicklung von Glue-Aufträgen war für mich schon immer etwas suboptimal. Zu Beginn könnten Sie Glue Studio verwenden, um Ihren ersten Auftrag zu erstellen und ein paar Testläufe durchzuführen, um zu sehen, ob er die richtigen Ergebnisse liefert. Das alles funktioniert bis zu einem gewissen Grad. Wenn die Datensätze jedoch größer werden oder die Transformationen komplexer werden, sollten Sie etwas mehr Debugging betreiben, um herauszufinden, warum Sie nicht das erwartete Ergebnis erhalten oder warum diese eine Spalte leer ist.
Warum dann nicht Glue Development Endpoints verwenden? Glue Development Endpoints, insbesondere in Kombination mit SageMaker Notebooks, bieten Ihnen bereits eine weitaus bessere Erfahrung. Dennoch müssen Sie den Endpunkt bereitstellen und SageMaker Notebooks einrichten. Nach einem anstrengenden Arbeitstag sollten Sie vor allem nicht vergessen, alles zu beenden, denn Entwickler-Endpunkte im Leerlauf sind ein guter Weg, die AWS-Rechnung in die Höhe zu treiben.
Glücklicherweise hat AWS Glue Interaktive Sitzungen (derzeit in der Vorschau), um die Entwicklungserfahrung mit Glue noch weiter zu verbessern. Die neue Funktion für interaktive Sitzungen wurde im Januar zusammen mit Job Notebooks als Vorschau veröffentlicht. Mit AWS Glue Job Notebooks können Sie schnell einen Notebook-Server mit interaktiven Glue-Sitzungen starten. In diesem Beitrag werde ich mich jedoch darauf konzentrieren, wie Sie Ihr eigenes Notebook lokal ausführen und dabei trotzdem eine Verbindung zu den interaktiven Sitzungen von Glue herstellen können. So können Sie Funktionen wie benutzerdefinierte Konnektoren und VPC-basierte Verbindungen von Ihrem lokalen Entwicklungsrechner aus nutzen.
Erste Schritte mit Glue Interactive Sessions
Zunächst müssen Sie sicherstellen, dass in Ihrer lokalen Umgebung die erforderlichen Pakete installiert sind. Eine Anleitung dazu finden Sie in der Dokumentation von AWS Kleber. Wenn alles installiert ist, können Sie Ihr lokales Notebook starten, indem Sie
jupyter notebook
Dies sollte einen lokalen Notebook-Server starten und einen Browser öffnen, um die Homepage anzuzeigen. Starten Sie ein neues Notebook und wählen Sie den Glue-Kernel Ihrer Wahl. In diesem Beispiel werde ich Glue PySpark verwenden.
Als ersten Schritt sollten Sie Ihre Glue-Einstellungen konfigurieren. Die verschiedenen Befehle können Sie anzeigen, indem Sie %help aufrufen und finden Sie in der Dokumentation. In der ersten Zelle konfigurieren wir die Glue-Umgebung und wie das Notebook mit AWS kommunizieren kann.
%glue_version 3.0 # Sie können 2.0 oder 3.0 wählen %profile <IHR_PROFIL> # Der Name des zu verwendenden AWS-Profils %region eu-west-1 # Die AWS-Region Ihrer Wahl %number_of_workers 2 # Die Anzahl der Arbeiter %iam_role <ROLE_ARN> # Die Rolle für Ihre AWS Glue-Sitzung %idle_timeout 30 # Nach 30 Minuten wird die Sitzung beendet
Bitte beachten Sie, dass Sie die Kommentare in diesen Magics entfernen sollten, da Sie sonst Fehler erhalten.
Nachdem Sie die obige Zelle ausgeführt haben, sollten Sie Glue bitten können, die aktuellen Sitzungen aufzulisten.
%list_sessions
Sollte zurückkehren "Es gibt keine aktuelle Sitzung". Wenn Sie eine Fehlermeldung sehen, gehen Sie zurück und vergewissern Sie sich, dass Sie gültige Anmeldedaten haben und alle Einstellungen korrekt sind.
Um mit den eigentlichen Glue-Befehlen zu beginnen, müssen Sie den Glue-Kontext initialisieren. Dazu können Sie Folgendes ausführen:
sys importieren from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.transforms import * glueContext = GlueContext(SparkContext.getOrCreate())
Sie sollten einige Ausgaben sehen und nach etwa 30 Sekunden sollte etwas angezeigt werden wie "Sitzung <UUID> wurde erstellt".
Und jetzt können Sie tatsächlich mit der Entwicklung beginnen! Holen Sie sich einige Daten in einen DynamicFrame, indem Sie die üblichen Glue-Befehle verwenden, und beginnen Sie mit der Verarbeitung Ihrer Daten. Wenn Sie fertig sind, können Sie die Sitzungen beenden, indem Sie
%delete_session
Interaktive Glue-Sitzungen haben standardmäßig eine Leerlaufzeit von 60 Minuten, nach der Ihre Sitzung beendet wird. Sie können ein kürzeres Timeout konfigurieren oder einfach delete_session ausführen, um die Kosten sofort zu beenden.
Arbeiten mit Klebeverbindungen und benutzerdefinierten Anschlüssen
In diesem zweiten Teil möchte ich etwas tiefer eintauchen und zeigen, wie Sie Glue-Verbindungen und benutzerdefinierte Verbindungen aus der interaktiven Sitzung verwenden können.
Um Glue-Verbindungen zu verwenden, können Sie während der Konfigurationsphase der Glue-Sitzung eine Liste von Verbindungen angeben. Fügen Sie einfach hinzu:
%Verbindungen <VERBINDUNG_NAME>
Sie können mehrere Verbindungen durch ein Komma getrennt angeben. Glue sorgt dafür, dass die interaktiven Sitzungen über die richtige Konnektivität verfügen, falls eine Verbindung eine VPC-Konfiguration hat. So können Sie z.B. auch Redshift-Instanzen in privaten Subnetzen abfragen oder in diese schreiben! Benutzerdefinierte Konnektoren werden auch innerhalb interaktiver Sitzungen unterstützt. Abonnieren Sie einfach den Connector auf dem AWS Marketplace mit Glue Studio und erstellen Sie eine neue Verbindung.
Verarbeitung von CDC-Daten mit Glue und Delta Lake
Lassen Sie uns nun die Verbindung verwenden, die wir oben erstellt haben, und mit der Verarbeitung von Daten beginnen, die von AWS Database Migration Service aus einer MySQL-Datenbank in S3 repliziert wurden. Wir müssen die Initialisierung des SparkContext ein wenig ändern, damit wir das delta-Paket in PySpark verwenden können.
sys importieren from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.transforms import * sc = SparkContext.getOrCreate() sc.addPyFile("delta-core_2.12-1.0.0.jar") GlueContext = GlueContext(sc) from delta.tables import *
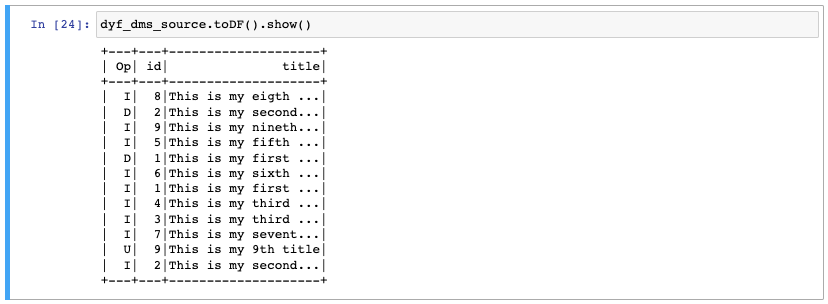
Als nächstes müssen wir die Daten abrufen, die von AWS DMS gespeichert wurden. Ich habe die Daten mit einem Glue Crawler gecrawlt, und das hat mir eine Tabelle mit dem Namen Demo. Wir erstellen einen DynamicFrame aus dem Glue-Katalog und drucken ein paar Zeilen aus, um die ersten 10 Zeilen der Daten zu sehen. Um die Demo einfach zu halten, habe ich nur drei Felder ausgewählt. Das Feld 'op', das die Operation aus dem DMS angibt ( Insert, Update, Delete), die Datensatz-ID und den Titel.
dyf_dms_source_raw = glueContext.create_dynamic_frame.from_catalog( database="dms", table_name="demo", transformation_ctx="dyf_dms_source") dyf_dms_source = SelectFields.apply( frame = dyf_dms_source_raw, paths=['Op', 'id', 'title']) dyf_dms_source.toDF().show()
Als nächstes teilen wir die eingehenden Daten wie folgt in Einfügungen und Aktualisierungen+Löschungen auf:
df_inserts = Filter.apply( frame=dyf_dms_source, f=lambda x: x["Op"] == 'I' oder x["Op"] == Keine, transformation_ctx='dyf_inserts').toDF() df_updates = Filter.apply( frame=dyf_dms_source, f=lambda x: x["Op"] == 'U' oder x["Op"] == 'D', transformation_ctx='dyf_updates').toDF()
Um Abkürzungen zu vermeiden, habe ich weggelassen, dass Sie wahrscheinlich nach dem Zeitpunkt der Operation sortieren und nur die letzte Aktion eines Datensatzes auf der Grundlage des eindeutigen Schlüssels eines Datensatzes verarbeiten möchten.
Der erste Schritt besteht darin, alle neu eingefügten Daten in eine Delta-Tabelle zu schreiben. Sie können dies tun, indem Sie ausführen:
df_inserts.write.format("delta").mode("append").save("s3a://demobucket/my_delta_table/")
Nachdem dies abgeschlossen ist, sollte der Bucket Parkettdateien mit den Daten enthalten. Bevor ich die Aktualisierungen und Löschungen verarbeite, möchte ich sicherstellen, dass die Daten tatsächlich in S3 geschrieben werden, indem ich die Daten mit Amazon Athena abfrage. Damit Athena oder eine andere Presto-basierte Abfrage-Engine Delta-Tabellen abfragen kann, müssen wir eine Manifestdatei erstellen. Dazu initialisieren wir ein Delta-Tabellenobjekt und rufen die Funktion generate auf.
deltaTable = DeltaTable.forPath(spark, "s3a://demobucket/mein_delta_tisch/") deltaTable.generate("symlink_format_manifest")
Gehen Sie nun zu Athena und erstellen Sie eine externe Tabelle,
CREATE EXTERNAL TABLEmy_delta_table(opString,idbigint,titleString) ZEILENFORMAT SERDE org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'. GESPEICHERT ALS EINGABEFORMAT org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'. OUTPUTFORMAT org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'. LOCATION s3://demobucket/my_delta_table/_symlink_format_manifest'.
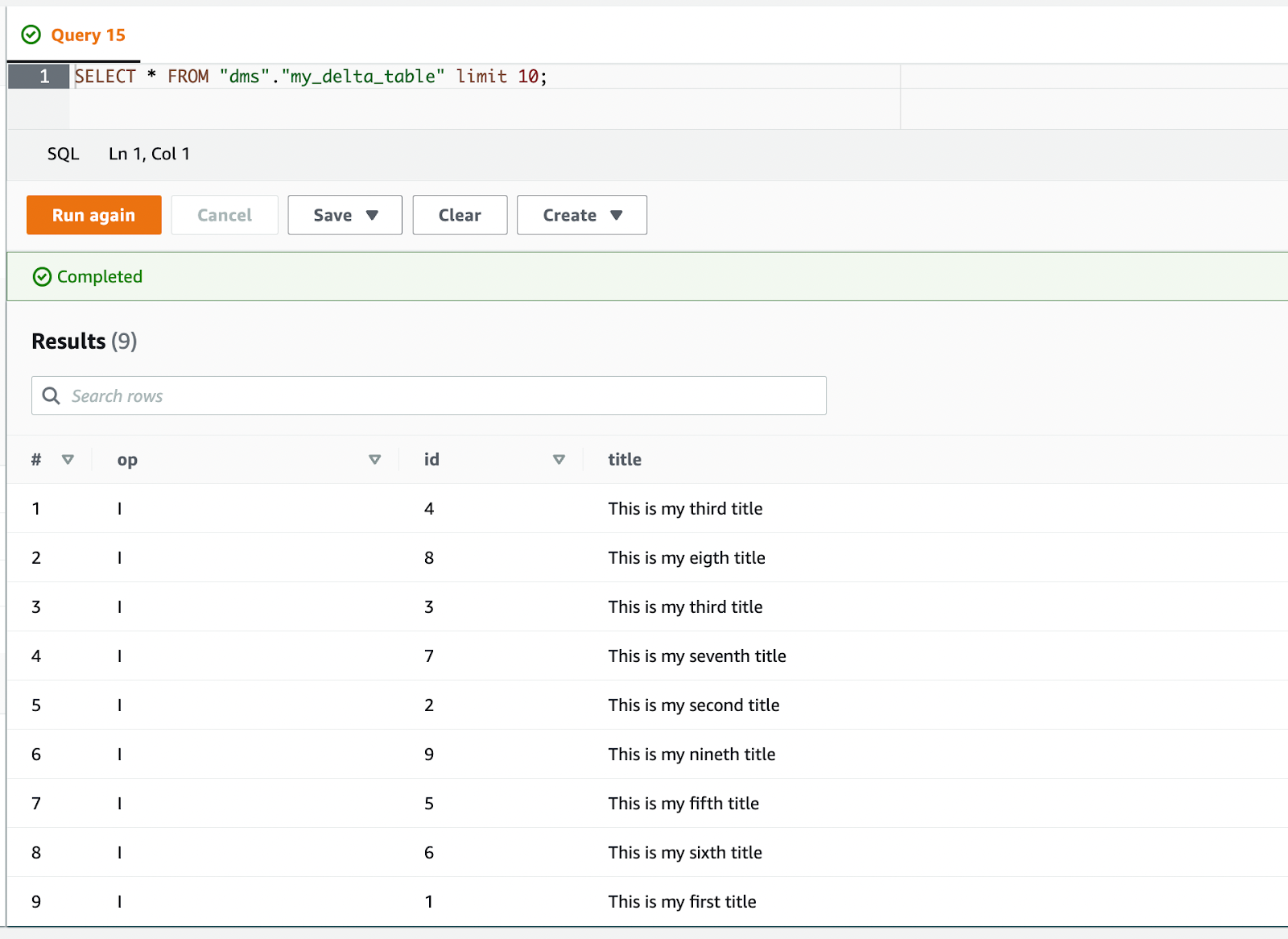
Athena zeigt uns nun alle Daten an, die von DMS als eingefügt markiert wurden.
Um die Aktualisierungen und Löschungen zu verarbeiten, werden wir Upserts verwenden, indem wir eine Tabellenzusammenführung durchführen. Mit der Delta-Tabelle aus dem vorherigen Schritt führen wir aus:
deltaTable.alias("currentData").merge( df_updates.alias("newData"), "aktuelleDaten.id = neueDaten.id") .whenMatchedDelete(condition = "newData.Op = 'D'") .whenMatchedUpdateAll(condition = "neueDaten.Op != 'D'") .whenNotMatchedInsertAll(condition = "neueDaten.Op != 'D'") .execute() deltaTable.generate("symlink_format_manifest")
Hier führen wir zwei Datensätze zusammen, den aktuellen und den neuen, und verbinden sie anhand der id Feld. Je nach Ergebnis des Zusammenführens führen wir eine Aktion aus. Wenn die Zusammenführungsaktion übereinstimmende Daten finden konnte und die Operation 'D' war, dann sollte sie die Daten aus der Originaltabelle löschen. Wenn die Operation mit einer anderen Operation übereinstimmt, aktualisieren wir die Felder des ursprünglichen Datensatzes. Der letzte Schritt besteht darin, alle nicht übereinstimmenden Daten als neuen Datensatz einzufügen.
Der letzte Schritt in der Zelle besteht darin, sicherzustellen, dass die Änderungen in Athena angezeigt werden, indem Sie die Manifestdatei erneut aktualisieren.
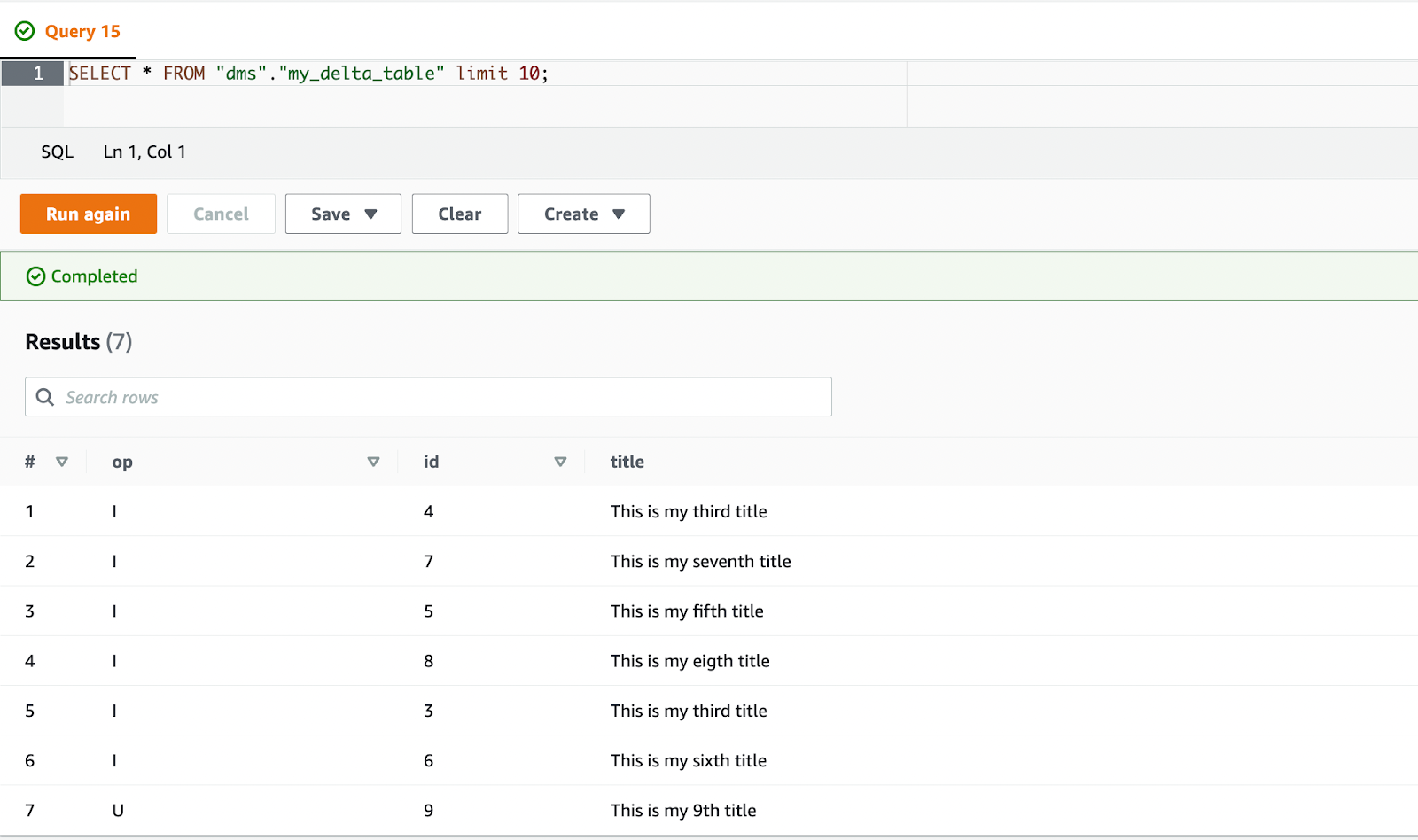
Eine neue Abfrage in Athena zeigt uns die neuen Ergebnisse. Die Datensätze mit der ID 1 und 2 wurden gelöscht und der Datensatz mit der ID 9 wurde aktualisiert, um den neuen Titel anzuzeigen. Wenn Sie dies mit den Rohdaten vergleichen, die von AWS DMS generiert wurden, können Sie sehen, dass dies das erwartete Ergebnis ist.
Letzte Worte
In diesem Blogbeitrag habe ich zunächst gezeigt, wie Sie Glue Interactive Sessions verwenden können, um die Entwicklungserfahrung mit Glue-Jobs erheblich zu verbessern. Zweitens habe ich einen Überblick darüber gegeben, wie Sie Verbindungen und benutzerdefinierte Konnektoren verwenden können, um CDC-Daten zu verarbeiten und sie mit Delta Lake in Glue in S3 zu speichern.
Weitere Informationen zur Verwendung von AWS Glue Interactive Sessions finden Sie in der Dokumentation. Schauen Sie sich auch einige meiner anderen Blogs an!
Verfasst von
Andrès Koetsier
Andrès is our cloud native development hero, who likes to play basketball and crash MTBs and (virtual) racing cars.
Unsere Ideen
Weitere Blogs




Contact