Blog
Lokal entwickeln, global skalieren: Dask auf Kubernetes mit Google Cloud

Wir glauben, dass die Nutzung der Cloud keine Kompromisse bei Ihrer Produktivität eingehen sollte. In diesem Blogbeitrag zeigen wir Ihnen, wie Sie lokal entwickeln können, während Sie Ihre Dask-Arbeitslast in der Cloud ausführen. Sie genießen den Komfort Ihrer eigenen IDE und der lokalen Versionskontrolle, während die Google Kubernetes Engine (GKE) die schwere Arbeit für Sie erledigt. Sie werden es nicht einmal bemerken.
Dask kombiniert eine umfangreiche Pandas-ähnliche API mit der Skalierbarkeit von Spark. Für Datenwissenschaftler bedeutet dies schnelles Prototyping und Data Crunching, ohne sich Sorgen machen zu müssen, dass die Daten nicht in den Speicher Ihres lokalen Rechners passen. Mit Dask können Sie auch Maschinenbibliotheken wie scikit-learn skalieren, um schwere Trainings- und Kreuzvalidierungsaufgaben zu verteilen.
Unser Setup unterscheidet sich von der offiziellen Variante, bei der Sie auf dem Cluster entwickeln müssen. Das bedeutet, dass Sie eine Online-IDE (wie Jupyter{Hub, Lab}) verwenden und Ihren Code auf dem Cluster klonen. Sie müssen Ihren Cluster immer am Leben erhalten, um den Status Ihres Projekts zu speichern. Unser Setup umgeht dieses Problem.
Die Einrichtung
Schritt 0: Vorbereitungen
Für den Blogbeitrag benötigen Sie sowohl gcloud als auch kubectl. Führen Sie gcloud auth list aus, um zu prüfen, ob Sie mit dem richtigen Konto authentifiziert sind, und verwenden Sie kubectl --version, um sicherzustellen, dass das Befehlszeilentool funktioniert. Für diesen Blog-Beitrag haben wir Kubernetes Version 1.19.4 verwendet.
Diese Anleitung funktioniert am besten, wenn Sie mit einem neuen Google Cloud-Projekt mit Standardnetzwerken beginnen. Sobald Sie Ihr Projekt erstellt haben, stellen Sie sicher, dass Sie Ihr Projekt als Standard in Ihrer gcloud config festlegen:
gcloud config set project <<YOUR PROJECT ID>>Stellen Sie außerdem sicher, dass die GKE-API aktiviert ist. Sie tun dies über die Konsole oder indem Sie:
gcloud services enable container.googleapis.comSchritt 1: Erstellen eines Kubernetes-Clusters
Erstellen Sie einen Kubernetes-Cluster wie folgt (vergessen Sie nicht, <<YOUR-IPV4-IP-HERE>> durch Ihre IP-Adresse zu ersetzen):
gcloud container clusters create dask-cluster
--create-subnetwork name=dask-cluster
--num-nodes 3
--region europe-west4
--machine-type n1-standard-2
--node-locations europe-west4-c
--enable-master-authorized-networks
--master-authorized-networks <<YOUR-IPV4-IP-HERE>>/32
--enable-ip-alias
--enable-private-nodes
--master-ipv4-cidr 172.16.0.0/28Dadurch wird ein privater Kubernetes-Cluster mit einem öffentlichen Master-Endpunkt erstellt. Damit können Sie sich mit dem Kubernetes-Master verbinden und kubectl verwenden, um mit dem Cluster zu interagieren.
Hinweis: Sie können Ihren Cluster noch sicherer machen, indem Sie den Client-Zugriff auf den öffentlichen Endpunkt deaktivieren. Für das Ziel dieses Blogbeitrags lassen wir diese Schritte jedoch aus.
Nachdem der Cluster erstellt wurde, ziehen Sie die Anmeldedaten des Clusters, damit kubectl eine Verbindung zu ihm herstellen kann:
gcloud container clusters get-credentials dask-cluster
--zone europe-west4Wenn alles gut gegangen ist, können Sie die Knoten in Ihrem Kubernetes-Cluster auflisten:
kubectl get nodesDas ergibt in etwa folgendes Bild:
NAME STATUS ROLES AGE VERSION
gke-dask-cluster-... Ready <none> 2m12s v1.16.15-gke.4300
gke-dask-cluster-... Ready <none> 2m15s v1.16.15-gke.4300
gke-dask-cluster-... Ready <none> 28m v1.16.15-gke.4300 Schritt 2: Geben Sie Ihrem Cluster Zugang zum Internet
Da Sie einen privaten Kubernetes-Cluster betreiben, sind die Nodes nicht mit dem Internet verbunden. Glücklicherweise ist es in der Google Cloud extrem einfach, ein Cloud NAT einzurichten, um den Internetzugang in unserer privaten Cloud zu ermöglichen. Sie erstellen einen Cloud Router:
gcloud compute routers create nat-router
--network default
--region europe-west4und erstellen Sie dann eine Cloud NAT:
gcloud compute routers nats create nat-config
--router-region europe-west4
--router nat-router
--nat-all-subnet-ip-ranges
--auto-allocate-nat-external-ipsSchritt 3: Richten Sie Ihre lokale Umgebung ein
Erstellen Sie auf Ihrem lokalen Gerät eine virtuelle Umgebung mit Python 3.8.0 und installieren Sie die folgenden Abhängigkeiten
pip install dask'[complete]'==2020.12.0
dask-kubernetes==0.11.0
jupyter==1.0.0
numpy==1.18.1
s3fs==0.5.2Der Scheduler für Dask läuft per Fernzugriff auf GKE. Um seine Adresse einer lokalen IP-Adresse zuzuordnen, fügen Sie /etc/hosts hinzu, indem Sie den folgenden Befehl ausführen:
echo '127.0.0.1 dask-cluster.default' | sudo tee -a /etc/hostsDadurch wird sichergestellt, dass Sie die Adresse des Clusters zu localhost auflösen können (obwohl der Cluster eigentlich auf GKE läuft, werden wir die Verbindung über einen Tunnel verfügbar machen).
Sie sind nun bereit, Dask auf GKE von Ihrem lokalen Gerät aus auszuführen.
Dask ausführen
Nachdem Sie nun einen GKE-Cluster eingerichtet haben, sind Sie bereit für den schwierigeren Teil: die dynamische Bereitstellung eines Dask-Clusters in einer Jupyter Notebook-Umgebung.
Erstellen Sie zunächst eine Vorlage für die Worker-Spezifikation in einer YAML-Datei:
# worker-spec.yml
kind: Pod
spec:
restartPolicy: Never
containers:
- image: daskdev/dask:2020.12.0
imagePullPolicy: IfNotPresent
args: [dask-worker, --nthreads, 2, --no-dashboard, --memory-limit, 7GB, --death-timeout, 300]
name: dask
env:
- name: EXTRA_PIP_PACKAGES
value: s3fs
resources:
limits:
cpu: 1
memory: "7G"
requests:
cpu: 1
memory: "4G"Passen Sie die Worker an Ihre Bedürfnisse an: Nehmen Sie GPUs, TPUs oder Worker mit hohem Arbeitsspeicher, wie Sie es für richtig halten. Stellen Sie sicher, dass die Dask-Version (2020.12.0) mit Ihrer lokalen Dask-Version identisch ist.
Schritt 1: Ausführen des Schedulers
Öffnen Sie ein Jupyter-Notizbuch und führen Sie den folgenden Befehl in einer Zelle aus:
import dask
from dask_kubernetes import KubeCluster
cluster = KubeCluster.from_yaml('./worker-spec.yml', deploy_mode='remote', name='dask-cluster')Wenn er läuft, öffnen Sie ein neues Terminal und führen den folgenden Befehl aus:
kubectl port-forward service/dask-cluster 8786:8786 --pod-running-timeout=5m0sWenn Sie die Meldung "Fehler vom Server (NotFound): Dienste "dask-cluster" nicht gefunden" erhalten, waren Sie zu schnell. Führen Sie den Befehl einfach erneut aus, bis er erfolgreich ist.
Wenn Sie den Dask-Cluster neu erstellen möchten (weil etwas schief gelaufen ist), stellen Sie sicher, dass Sie zuerst den alten Cluster entfernen, indem Sie den Kubernetes-Dienst (kubectl delete service dask-cluster) und alle Pods (kubectl delete pods --all) entfernen.
Wenn alles gut gegangen ist, sollte die Zelle in Ihrem Jupyter-Notebook beendet werden (was bedeutet, dass [*] in [1] übergeht). Jetzt sehen Sie, dass der Scheduler-Pod in Ihrem Terminal läuft:
kubectl get pods -n defaultSie verbinden sich mit dem Dashboard des Dask-Schedulers, indem Sie ein weiteres Terminal öffnen und einen Tunnel erstellen:
kubectl port-forward service/dask-cluster 8787:8787 --pod-running-timeout=5m0sIn Ihrem Browser können Sie jetzt auf Ihr Dask-Dashboard unter http://localhost:8787 zugreifen :
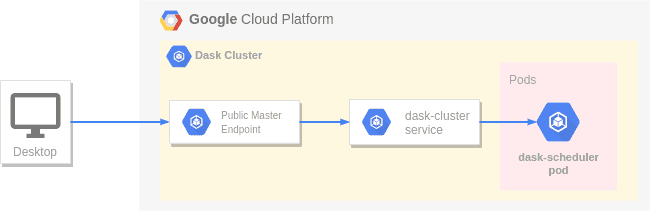
Was passiert nun eigentlich, wenn Sie den Dask-Cluster erstellen und den Befehl kubectl port-forward ausführen? Wenn Sie eine KubeCluster erstellen, erstellt Dask einen Pod, der den verteilten Dask Scheduler enthält. Außerdem wird ein Kubernetes-Dienst erstellt, der auf Port 8786 (Worker-Kommunikation) und 8787 (Dask-Dashboard) lauscht. Wenn Sie sich mit diesem Dienst verbinden, werden Sie zum Dask Scheduler-Pod weitergeleitet.
Kubernetes bietet die Möglichkeit, über den Master-Endpunkt über http(s) einen Tunnel direkt zu einem Pod oder Dienst aufzubauen. Wir nutzen diese Funktion, um uns von unserer lokalen Umgebung aus mit dem Dask-Scheduler zu verbinden. Dies ist in dem vereinfachten Diagramm unten dargestellt. Wenn Sie kubectl port-forward service/dask-cluster 8786:8786 aufrufen, verbindet sich kubectl mit dem GKE-Master-Endpunkt, der den Datenverkehr an den GKE Dask-Cluster-Dienst weiterleitet. Dieser Dienst wiederum leitet den Datenverkehr an den Dask-Scheduler-Pod weiter. So können Sie sich von Ihrem lokalen Notebook aus über eine sichere Verbindung mit dem Dask-Scheduler verbinden.
Im nächsten Schritt fügen Sie Ihrem Cluster Worker hinzu (unter "Workers" im Dask Dashboard sehen Sie, dass es noch keine gibt).
Schritt 2: Hinzufügen von Arbeitern
Sie können dem Cluster nun Arbeiter hinzufügen, indem Sie die Methode scale verwenden:
cluster.scale(2)Sie sehen nun zwei Arbeiter, die auf http://localhost:8787/workers laufen :
Schritt 3: Aufträge ausführen
Jetzt, wo wir einen Cluster mit Arbeitern haben, können wir mit der Ausführung von Aufgaben beginnen. Initiieren Sie einen Client:
from dask.distributed import Client
client = Client(cluster)Sie sind nun bereit, Ihr erstes Stück Dask-Code auszuführen:
import dask.array as da
# Create a large array and calculate the mean
array = da.ones((1000, 1000, 1000))
print(array.mean().compute()) # Should print 1.0Um den Cluster wirklich auf die Probe zu stellen, laden Sie den berüchtigten New Yorker Taxi-Datensatz für 2015 wie folgt auf Ihren Cluster:
import dask.dataframe as dd
import pandas as pd
taxi_data = dd.read_csv(
"s3://dask-data/nyc-taxi/2015/yellow_tripdata_2015-*.csv",
parse_dates=["tpep_pickup_datetime", "tpep_dropoff_datetime"],
storage_options={'anon': True, 'use_ssl': False}
)
print(f"row count: {taxi_data.shape[0].compute()}")
# 146,112,989 rows
print(f"average trip distance: {taxi_data['trip_distance'].mean().compute()}")
# 13.1 miles
distance_per_day = (
taxi_data
.assign(
day=ddf["tpep_pickup_datetime"].dt.day,
month=ddf["tpep_pickup_datetime"].dt.month,
year=ddf["tpep_pickup_datetime"].dt.year,
)
.groupby(["day", "month", "year"])["trip_distance"]
.sum().compute()
)
busiest_day = distance_per_day.idxmax()
distance = distance_per_day.max()
print(f"Busiest day of 2015: {'-'.join(map(str, busiest_day))} ({distance:.0f} taxi miles)")
# Busiest day of 2015: 25-11-2015 (200026475 taxi miles)Wenn Sie das obige Snippet ausführen, sehen Sie im Dashboard, dass die Last des Clusters steigt:
Schritt 4: Aktivieren Sie auto$caling
Wenn Sie auf mehr als zwei Worker skalieren, gehen Ihnen die Ressourcen aus, da der Cluster nur über drei Knoten verfügt (und einer davon für den Scheduler reserviert ist). Sie lösen dieses Problem, indem Sie die automatische Skalierung für Ihren GKE-Knotenpool aktivieren:
gcloud beta container clusters update dask-cluster
--region europe-west4
--min-nodes 0
--max-nodes 6
--autoscaling-profile optimize-utilizationJetzt können Sie auf mehr als zwei Mitarbeiter aufstocken:
cluster.scale(4)GKE wird feststellen, dass nicht genügend CPUs zur Verfügung stehen und zwei weitere VMs hinzufügen:
kubectl get nodesgke-dask-cluster-... Ready <none> 2m12s v1.16.15-gke.4300
gke-dask-cluster-... Ready <none> 2m15s v1.16.15-gke.4300
gke-dask-cluster-... Ready <none> 28m v1.16.15-gke.4300
gke-dask-cluster-... Ready <none> 28m v1.16.15-gke.4300
gke-dask-cluster-... Ready <none> 28m v1.16.15-gke.4300Zum Verkleinern skalieren Sie einfach auf Null (das Verkleinern dauert in der Regel ein paar Minuten):
cluster.scale(0)Dask unterstützt auch adaptive Cluster, die je nach Arbeitslast nach oben oder unten skalieren. Das bedeutet, dass Sie die Anzahl der Arbeiter nie manuell festlegen müssen. Um den Cluster adaptiv zu machen, legen Sie nur das Minimum und das Maximum der Arbeiter fest:
cluster.adapt(minimum=0, maximum=5) # scale between 0 and 5 workersLassen Sie uns das adaptive Clustering auf die Probe stellen und einen großen Auftrag ausführen:
# Create a large array and calculate the mean
array = da.ones((10000, 10000, 10000))
print(array.mean().compute()) # Should print 1.0Der Start des Auftrags dauert länger, da GKE zunächst den Node-Pool erhöht, bevor die Worker für Dask verfügbar sind. Dieser Prozess läuft jedoch vollautomatisch ab und nach ein paar Minuten sollte der Auftrag ausgeführt werden.
Nach Beendigung des Auftrags beendet Dask die Worker und GKE entfernt die VMs aus dem Pool.
Schritt 5: Herunterfahren Ihres Clusters
Sie löschen Ihren Dask-Cluster, indem Sie den Befehl shutdown() aufrufen:
client.shutdown()Dies löscht alle von Dask erstellten Pods und den Kubernetes-Dienst, der speziell für diesen Cluster erstellt wurde. Um zu überprüfen, ob alles beendet wurde, führen Sie gcloud container clusters delete dask-cluster --region europe-west4 aus.
Wenn Sie Ihren Cluster online halten möchten, aber nur minimale Kosten haben wollen, können Sie die Größe Ihres Nodepools auf 0 setzen. Normalerweise verursacht der Betrieb von GKE ohne Knoten immer noch Kosten durch die Verwaltungsgebühr von 0,10$ pro Stunde, allerdings entfallen die Verwaltungsgebühren für Ihren ersten Cluster. Wenn Sie also Ihren Cluster online halten möchten, aber nur minimale Kosten zahlen wollen, können Sie die Größe Ihres Nodepools auf 0 Maschinen reduzieren, indem Sie ihn ausführen:
gcloud container clusters resize dask-cluster
--region europe-west4
--num-nodes 0Wenn Sie einen Scheduler erneut ausführen möchten, stellen Sie sicher, dass Sie mindestens einen Knoten wieder hinzufügen.
Verfasst von
Diederik Greveling
Unsere Ideen
Weitere Blogs




Contact