
Airflow ist ein weit verbreiteter Orchestrator, mit dem Sie alle Arten von Workflows planen, ausführen und überwachen können. Dank Python bietet es eine große Ausdrucksfreiheit, um alle Arten von Aufgaben zu definieren und APIs in verschiedenen Bereichen zu verbinden. Es bietet auch viele Erweiterungen, um Arbeitslasten auf anderen Plattformen wie Kubernetes zu planen.
Dank dieser Eigenschaften wird Airflow häufig auch in Projekten zum maschinellen Lernen eingesetzt, um dort Aufgaben zu verwalten. Es gibt jedoch noch ein weiteres Tool, das zusätzlich die Abstraktion von Pipelines ermöglicht und sich bei der Organisation von ML-bezogenen Aufgaben auszeichnet - Kedro.
Können die beiden zusammen verwendet werden? Ja, das können sie! In diesem Artikel zeige ich Ihnen, wie Sie dies tun und wie Sie es effizient und nahtlos automatisieren können!
Erkundung der verfügbaren Tools - Kedro-Airflow Plugin
Für diese Aufgabe habe ich mich für das offizielle Kedro-Pluginzu verwenden, da es vor kurzem ein Update erhalten hat, das es Ihnen ermöglicht, seine Verwendung mit benutzerdefinierten Jinja-Vorlagen für die DAG-Generierung anzupassen.
Das Plugin ist sehr einfach strukturiert, denn es erfüllt nur eine Aufgabe - es ermöglicht Ihnen, einen DAG-Code für eine bestimmte Kedro-Pipeline zu generieren und ihr mithilfe einer Jinja-Vorlage Parameter zu übergeben.
Hier finden Sie alles, was es zu bieten hat:
kedro airflow create- Einen Airflow-DAG für ein Projekt erstellen-p, --pipeline TEXT- Name der registrierten Pipeline, die konvertiert werden soll. Wenn nicht festgelegt, wird die '__default__'-Pipeline verwendet.-e, --env TEXT- Name der Kedro-Konfigurationsumgebung. Der Standardwert ist lokal.-t, --target-dir DIRECTORY- Der Verzeichnispfad zum Speichern der generierten Airflow-Dags-j, --jinja-file FILE- Die Vorlagendatei für die generierten Airflow-Dags--params TEXT- Geben Sie zusätzliche Parameter an, die Sie an den Kontextinitialisierer übergeben möchten. Die Elemente müssen durch ein Komma getrennt werden, die Schlüssel durch einen Doppelpunkt oder ein Gleichheitszeichen, Beispiel:param1=value1,param2=value2. Jeder Parameter wird durch das erste Komma getrennt, so dass Parameterwerte Doppelpunkte enthalten dürfen, Parameterschlüssel jedoch nicht. Um ein verschachteltes Wörterbuch als Parameter zu übergeben, trennen Sie die Schlüssel durch '.', Beispiel:param_group.param1:value1.
Der schnelle Start von Kedro-Airflow und die Herausforderungen
Als erstes habe ich die Dokumentation gelesen und versucht, die Schnellstartschritte in einer lokal eingerichteten Airflow-Umgebung mit docker-compose durchzuführen. Die mitgelieferte Beispielvorlage erstellt KedroOperator, das lediglich eine weitere Variante von PythonOperator ist, die Kedro-Knoten in separaten Prozessen ausführt, die von session.run() gestartet werden. Ich habe mir schnell eine Meinung über die Schnellstart-Einrichtung gebildet - das dort angegebene Beispiel ist unpraktisch, da es in einigen Punkten fehlerhaft ist, die ich in meiner Lösung vermeiden möchte:
- Erstens setzt es voraus, dass Airflow und Kedro voneinander wissen. Ich würde es vorziehen, diese beiden Umgebungen zu isolieren, so dass ich weder Kedro in Airflow noch Airflow in Kedro importieren muss. Da die Verwaltung von Abhängigkeiten in Airflow eine Herausforderung ist, wäre es besser, dieses Problem ganz zu vermeiden.
- Aus den obigen Ausführungen geht hervor, dass beide ähnliche Anforderungen an die Spezifikationen des Rechners haben müssen, auf dem sie ausgeführt werden, da sie in der gleichen Umgebung ausgeführt werden.
- Drittens: Da der Code von denselben Prozessen ausgeführt würde, müsste er in Form von Paketen gemeinsam genutzt werden. In dieser Konfiguration läuft Airflow in einem Docker-Image. Ich müsste also entweder dieses Image jedes Mal neu erstellen und ausführen, wenn sich der Code des Airflow- oder Kedro-Projekts ändert, ODER zusätzlich viele virtuelle Python-Umgebungen irgendwo verwalten und die neuen Versionen der mikrogepackten Kedro-Pipelines dorthin liefern, wenn sich der Code ändert.
Arbeiten an der Lösung
Daher hatte ich zunächst die Lösung im Kopf, entweder DockerOperator oder KubernetesOperator zu verwenden, um diese Isolierung und Skalierbarkeit der Ausführung zu erreichen. Da mein Ziel die Google-Cloud war, werde ich mit verwaltetem Airflow (GCP Composer) arbeiten, das von einem GKE Autopilot-Cluster unterstützt wird, da diese beiden Systeme in GCP integriert sind. Das führte natürlich zur Wahl von GKEPodOperator von Google für die Arbeit mit GKE. GKEPodOperator erbt von KubernetesOperator und bietet die gleiche Funktionalität, nur mit dem zusätzlichen Bonus, dass es die Google-Authentifizierungsmechanismen für die Autorisierung beim GKE-Cluster für Sie handhabt und versteckt. Ich fand es witzig, dass dieses Plugin auch Operatoren zum Erstellen/Löschen von Clustern bereitstellt, als ob es eine gute Idee wäre, einen Berechnungscluster zu erstellen, um nur eine Aufgabe auszuführen... Ich vermute, dass dies der Fall sein könnte, wenn Sie eine große Aufgabe nicht so oft ausführen, da die Kosten für die Bereitstellung des Clusters in GCP 0 sind, während Sie für die Unterhaltszeit bezahlen. Das Tutorial ist sehr hilfreich, da es GKE-Cluster für Sie verwaltet.
Obwohl ich für das Kedro-Projekt keinen Bedarf an Airflow-Anforderungen hatte, war es nützlich, eine weitere Umgebung mitapache-airflow[google,kubernetes], kubernetes python-Pakete installiert, um die Gültigkeit der generierten DAGs zu überprüfen. Das Kubernetes-Paket wird hier verwendet, um Kubernetes-Objektbeschreibungen zu definieren und zu validieren, hauptsächlich Spezifikationen von Maschinenressourcen.
Einrichten der Umgebung
Der nächste Schritt nach der Auswahl der Tools für die Aufgabe war die Einrichtung der Umgebung für Composer und GKE. Zunächst tat ich dies in der GCP-Konsole, aber ich wollte leicht reproduzierbare Ergebnisse, also schrieb ich etwas terraform Code, um die Umgebung schnell bereitzustellen und zu zerstören. Außerdem wollte ich MLflow für die Nachverfolgung von Experimenten verwenden und einrichten, und Sie können in diesem anderen Blog-Beitrag nachlesen, wie man es auf Google Cloud Run einrichtet. Ich habe die offiziellen Google-Moduleverwendet, aber angesichts der Komplexität und der Warnungen würde ich mir ernsthaft überlegen, ob ich es außerhalb von Demo-Zwecken verwenden soll oder nicht.
Wir empfehlen Ihnen DRINGEND, die GCP-Anleitungen zu lesen, da die Ressource Umgebung einen langen Bereitstellungsprozess erfordert und mehrere Schichten der GCP-Infrastruktur umfasst, darunter einen Kubernetes-Engine-Cluster, Cloud-Speicher und Compute-Netzwerkressourcen. Aufgrund der Einschränkungen der API ist Terraform nicht in der Lage, viele dieser zugrunde liegenden Ressourcen automatisch zu finden oder zu verwalten. <br><br>Es kann bis zu einer Stunde dauern, eine Umgebungsressource zu erstellen oder zu aktualisieren. Außerdem erkennt GCP bestimmte Fehler in der Konfiguration möglicherweise erst dann, wenn sie verwendet werden (z.B. ~40-50 Minuten nach der Erstellung), und ist anfällig für begrenzte Fehlerberichte.
Um die Kommunikation zwischen MLflow und dem GKE-Cluster zu ermöglichen, waren einige zusätzliche Anstrengungen erforderlich, die den Rahmen dieses Artikels sprengen würden. Um es kurz zu machen: MLflow ist mit einem IAP-Proxy gesichert. Wir brauchten also einige Dienstkonten, die Zugriff darauf haben und Airflow-Executors (hier: GKE Pods) dazu bringen, diese Dienstkonten zu verwenden (Workload Identities ist hier der gängige Mechanismus). Weitere Einzelheiten dazu finden Sie in der Repository README dieser Demo.
Vertiefung in das Kedro-Airflow Plugin
Hier zeige ich Ihnen im Detail, wie Sie das Plugin verwenden und wie Sie es an Ihre Bedürfnisse anpassen können. Wir haben einige Eingaben, die das Plugin für uns erledigt. Hier sehen Sie, wie es unsere Jinja-Vorlage aufruft, um sie zu füllen:
emplate.stream(
dag_name=package_name,
dependencies=dependencies,
env=env,
pipeline_name=pipeline_name,
package_name=package_name,
pipeline=pipeline,
**dag_config,
).dump(str(target_path))tDabei ist env die Kedro-Umgebung, pipeline das Kedro-Pipeline-Objekt, dag_config das Wörterbuch der an die Vorlage übergebenen Parameter und dependencies ein Wörterbuch der Eltern-Kind-Beziehungen zwischen den von der Pipeline definierten Knoten. Die Parameter können entweder über die Befehlszeile beim Erstellungsaufruf oder über die Konfigurationsdatei airflow params übergeben werden. Die Konfigurationsdatei wird mit der Funktion _load_config in das Plugin geladen (und wir können hier sehen, wo es standardmäßig nach der Konfigurationsdatei als Dateimuster sucht):
def _load_config(context: KedroContext, pipeline_name: str) -> dict[str, Any]:
# Set the default pattern for `airflow` if not provided in `settings.py`
if "airflow" not in context.config_loader.config_patterns.keys():
context.config_loader.config_patterns.update( # pragma: no cover
{"airflow": ["airflow*", "airflow/**"]}
)
...
try:
config_airflow = context.config_loader["airflow"]
...Alle diese Parameter werden in jinja als Variablen sichtbar sein und können in unserer Vorlage verwendet werden. Machen wir uns an die Arbeit und konfigurieren wir sie!
Konfigurieren von Kedro-Airflow für einen realen Anwendungsfall
Hier ist meine conf/base/airflow.yml, die die Parameter definiert:
default:
grouping_prefix: "airflow:"
resources_tag_prefix: "machine:"
# When grouping is enabled, nodes tagged with grouping prefix get grouped together at the same node of Airflow DAG for shared execution
# Make sure the grouping_prefix is not a prefix for any node names and that every node has only one of tags with such prefix and that they are not disjoint
grouping: true
gcp_project_id: "gid-labs-mlops-sandbox"
gcp_region: "europe-west1"
gcp_gke_cluster_name: "europe-west1-test-environme-d1ea8bdc-gke"
k8s_namespace: "airflow-ml-jobs"
k8s_service_account: "composer-airflow"
docker_image: "europe-west1-docker.pkg.dev/gid-labs-mlops-sandbox/images/spaceflights-airflow"
start_date: [2023, 1, 1]
max_active_runs: 2
# https://airflow.apache.org/docs/stable/scheduler.html#dag-runs
schedule_interval: "@once" # null
catchup: false
# Default settings applied to all tasks
owner: "airflow"
depends_on_past: false
email_on_failure: false
email_on_retry: false
retries: 0
retry_delay: 5#
data_science:
owner: "airflow-ds"
In dieser Konfiguration können wir beliebige benutzerdefinierte Variablen definieren. Der Kontext ihrer Verwendung wird deutlich, wenn wir uns die Jinja-Vorlage ansehen. Die hier definierten Parameter konfigurieren das Verhalten von Airflow, verweisen auf den Standort des GKE-Clusters, definieren Parameter in der k8s-Pod-Vorlage und ergänzen Pipelines mit zusätzlichen informativen Tags.
Gruppen von Parametern können als Standard definiert werden, der für alle Fälle und pipeline-spezifische Fälle verwendet wird, wobei der Name der Pipeline die Standardeinstellungen überschreibt. Wir verwenden Spaceflights starter als Ausgangspunkt, daher haben wir
Die
- verwenden wir Jinja-Schleifen, um Informationen über Kedro-Knotennamen, Tags und deren Abhängigkeiten als Wörterbücher mit "Rohdaten" zu übergeben,
- dann verwenden wir Konfigurationsparameter, um einen DAG zu konfigurieren, der die gegebene Pipeline repräsentiert,
- In diesem Prozess übersetzen wir Kedro-Knoten in Airflow-Knoten, indem wir
GKEPodOperatorfür jeden Knoten verwenden und den Docker-Befehl weitergeben, um nur ausgewählte Knoten in jedem Schritt auszuführen - wir verwenden das gleiche Docker-Image, das wir aus unserem Kedro-Projekt-Repository erstellt haben, - Während der Knotenübersetzung verwenden wir
slugify, um Strings zu bereinigen, die unabhängig von den Zeichenbeschränkungen der Kubernetes-API akzeptiert werden, - dann definieren wir die Sätze von Standard-Maschinenressourcen und wählen die richtige für jeden Knoten auf der Grundlage eines speziellen Tags
"machine:..."(als Konvention), - verknüpfen wir die DAG-Knoten auf der Grundlage der weitergegebenen Informationen über Abhängigkeiten miteinander,
- Schließlich fügen wir einen zusätzlichen Knoten vor den Startknoten hinzu, der eine spezielle Pipeline verwendet, um die MLflow-Sitzungserstellung zu handhaben und die MLflow-Lauf-ID über den Mechanismus
airflow_xcoman andere Knoten weiterzugeben.
Die DAGs durch Kedro-Knotengruppierung effizient machen
Standardmäßig wird jeder Kedro-Knoten in einen Knoten eines anderen Frameworks übersetzt, hier in einen Airflow DAG-Knoten. In der Version 0.18.13 unterstützt Kedro noch immer keine Kapselung von Knoten in Gruppen (ebenso wenig wie die meisten seiner Plugins). Für Kedro-Pipelines benötigen Sie eine hohe Granularität der Knoten, damit sie nur für eine Sache verantwortlich sind und leicht getestet und wiederverwendet werden können. Granularität bei der Aufgabenteilung in einem einzelnen Prozess hat fast keinen Overhead, da der Speicher von den Knoten gemeinsam genutzt werden kann. In Airflow (mit Docker-Images) möchten Sie jedoch so wenige Knoten wie möglich haben, um den Overhead bei der Erstellung und Zerstörung von Pods zu reduzieren. Mehr Knoten bedeuten auch, dass mehr Zeit für die Serialisierung von Daten und die Kommunikation zwischen ihnen verschwendet wird. Wie sollten Sie das also handhaben?
Was könnte uns mehr Kontrolle darüber geben, wie die Pipeline strukturiert ist?
Tags! Tags sind eine hervorragende Möglichkeit, Knoten zu gruppieren und ihre Eigenschaften zu definieren.
Wir haben alle Teile der Lösung zur Hand. In Kedro können wir mithilfe von Tag-Filtermechanismen nur ausgewählte Knoten ausführen, z.B.:
kedro run --tags data_processingWir werden eine Konvention mit speziellen Tags verwenden, die für diesen Zweck eingesetzt werden. Standardmäßig betrachten wir Tags, die mit “airflow:” beginnen, als Gruppierungs-Tags, wobei der Name der Gruppe der Text nach dem Präfix ist.
Da jeder Knoten in einem Docker-Container ausgeführt wird, muss nur noch festgestellt werden, ob die Knoten gruppiert sind oder nicht, und der richtige Befehl übergeben werden: entweder einen einzelnen Knoten oder eine Gruppe von Knoten mit einem Tag ausführen. Nun wäre es am besten, wenn Sie dies im Rahmen eines Hooks für das Plugin tun würden, um diese Verarbeitung bei der Tag-Generierung durchzuführen, aber wir haben solche Optionen in diesem Plugin noch nicht. Die nächstbeste Lösung wäre eine Programmierung in Jinja, aber das würde zu einer recht komplexen und nicht zu wartenden Vorlage führen. Die letzte Lösung besteht also darin, die Möglichkeiten von Python und Airflow zu nutzen und den Code, der diese Arbeit erledigt, in die DAG-Definition einzubetten. Ich habe also ein paar Funktionen implementiert, die neue Knotenzuordnungen erstellen und die Tags auf der Grundlage der Gruppierungs-Tags aktualisieren.
Der Code lautet wie folgt:
def group_nodes_with_tags(node_tags:dict, grouping_prefix:str = "airflow:") -> Tuple[dict, dict]:
# Helper dictionary that says to which group/node each node is part of
group_translator = { k:k for k in node_tags.keys() }
# Dict of groups and nodes they consist of
tag_groups = dict()
for node, tags in node_tags.items():
for tag in tags:
if tag.startswith(grouping_prefix):
if tag not in tag_groups:
tag_groups[tag] = set()
tag_groups[tag].add(node)
group_translator[node] = tag
return group_translator, tag_groupsdef get_tasks_from_dependencies(node_dependencies: dict, group_translator: dict) -> Tuple[set, dict]:
# Calculating graph structure after grouping nodes by grouping tags
group_dependencies = {}
task_names = set()
for parent, children in node_dependencies.items():
if group_translator[parent] not in group_dependencies:
group_dependencies[group_translator[parent]] = set()
this_group_deps = group_dependencies[group_translator[parent]]
task_names.add(group_translator[parent])
for child in children:
if group_translator[child] != group_translator[parent]:
this_group_deps.add(group_translator[child])
task_names.add(group_translator[child])
return task_names, group_dependencies
def update_node_tags(node_tags: dict, tag_groups: dict) -> dict:
# Grouping tags of new group nodes as sum of nodes' tags
node_tags.update({ group : set([tag for node in tag_groups[group] for tag in node_tags[node]]) for group in tag_groups})
return node_tags
...
group_translator, tag_groups = group_nodes_with_tags(node_tags)
task_names, group_dependencies = get_tasks_from_dependencies(node_dependencies, group_translator)
update_node_tags(node_tags, tag_groups)Aus Konvention habe ich beschlossen, diesen Mechanismus optional zu machen und der Einfachheit halber das in der Konfigurationsdatei definierte Präfix zu verwenden. Basierend auf den Ergebnissen der Gruppierung entscheiden die Dags dann, ob ein einzelner Knoten oder eine Gruppe von Knoten ausgeführt werden soll:
task_id=name.lstrip(GROUPING_PREFIX),
cmds=["python", "-m", "kedro", "run", "--pipeline", pipeline_name, "--tags", name, "--env", "{{ env | default(local) }}"] if name.startswith(GROUPING_PREFIX)
else ["python", "-m", "kedro", "run", "--pipeline", pipeline_name, "--nodes", name, "--env", "{{ env | default(local) }}"],
name=f"pod-{ slugify(pipeline_name) }-{ slugify(name.lstrip(GROUPING_PREFIX)) }",
Fehler bei der Knotengruppierung
Und das war's!
... oder doch nicht? Was ist, wenn wir bei der Markierung einen Fehler machen und die DAG aufhört, eine DAG zu sein (ein Zyklus wird eingeführt)? Nun, dann würde uns die Airflow DAG-Validierung anschreien, weil wir die falsche DAG definiert haben. Aber der Fehler kann hier auch verschleiert werden, da die Abhängigkeiten von Kedro in gruppierten Knoten versteckt sind und aus der Perspektive von Airflow nach der Übersetzung nicht sichtbar sind. Um den Aufwand für die Fehlersuche zu verringern, wäre es also schön, wenn Sie den Tag-Validierungscode in den DAG-Erstellungsprozess aufzunehmen. Wie ich bereits erwähnt habe, haben wir keine Hooks für dieses Plugin zur Verfügung (Stand: Kedro 0.18.13). Der nächstbeste Ort dafür ist also die Funktion Pipelines registrieren.
Jetzt wird der Befehl kedro airflow create einen Fehler oder eine Warnung mit der folgenden Meldung ausgeben, wenn wir einen Fehler beim Markieren machen:
[09/29/23 18:48:00] INFO Validating pipelines tagging...
WARNING Group airflow:split has multiple machine tags, this may cause unexpected behavior in which machine is used for the group, please use only one machine tag per group
ERROR Pipeline __default__ has invalid grouping that creates a cycle in its grouping tags regarding nodes: {'train_model_node', '__start__', 'airflow:split'}("__start__" ist hier der virtuelle Knoten, der auf alle anderen Knoten verweist, die zur Vereinfachung des Algorithmus hinzugefügt wurden)
Verwenden Sie das Plugin und erhalten Sie die Ergebnisse
Wenn Sie es bis hierher geschafft haben, vielen Dank fürs Lesen. Jetzt können Sie die Bilder dieser Lösung in Aktion sehen. Ausführlichere Anweisungen finden Sie in der Projekt README-Datei. Hier ist die Pipeline-Definition als Referenz:
Kedro Spaceflights Pipelines:
[ # data processing pipeline
node(
func=preprocess_companies,
inputs="companies",
outputs="preprocessed_companies",
name="preprocess_companies_node",
tags=["airflow:companies"]
),
node(
func=preprocess_shuttles,
inputs="shuttles",
outputs="preprocessed_shuttles",
name="preprocess_shuttles_node",
tags=["airflow:shuttles", "machine:medium"]
),
node(
func=create_model_input_table,
inputs=["preprocessed_shuttles", "preprocessed_companies", "reviews"],
outputs="model_input_table",
name="create_model_input_table_node",
tags=["airflow:split", "machine:medium"]
),
]
...
[ # data science pipeline
node(
func=split_data,
inputs=["model_input_table", "params:model_options"],
outputs=["X_train", "X_test", "y_train", "y_test"],
name="split_data_node",
tags=["airflow:split", "machine:medium"]
),
node(
func=train_model,
inputs=["X_train", "y_train"],
outputs="regressor",
name="train_model_node",
tags=["machine:medium"]
),
node(
func=evaluate_model,
inputs=["regressor", "X_test", "y_test"],
outputs=None,
name="evaluate_model_node",
tags=["machine:medium"]
),
]
Achten Sie besonders auf die Tags. Es handelt sich um die folgende Kedro-Pipeline: 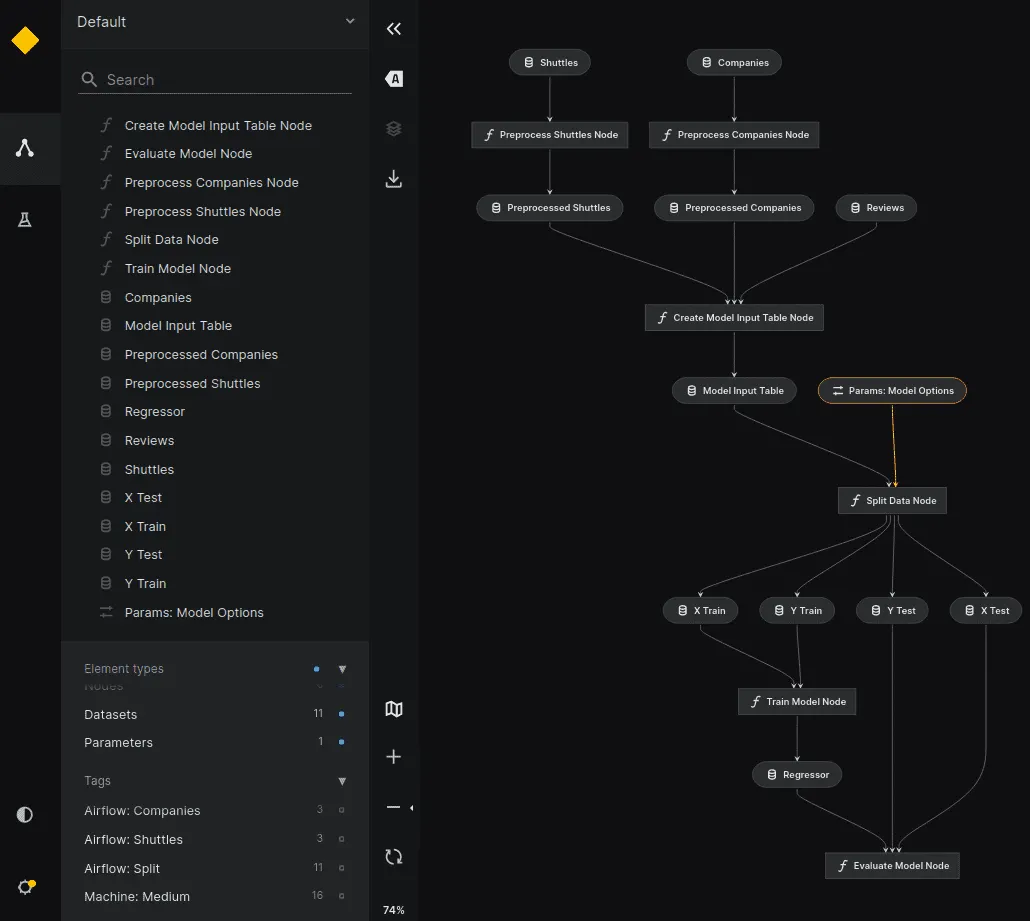
Wir brauchen das Docker-Image, also bauen wir es und liefern es in einem Rutsch an die Docker-Registry in gcp: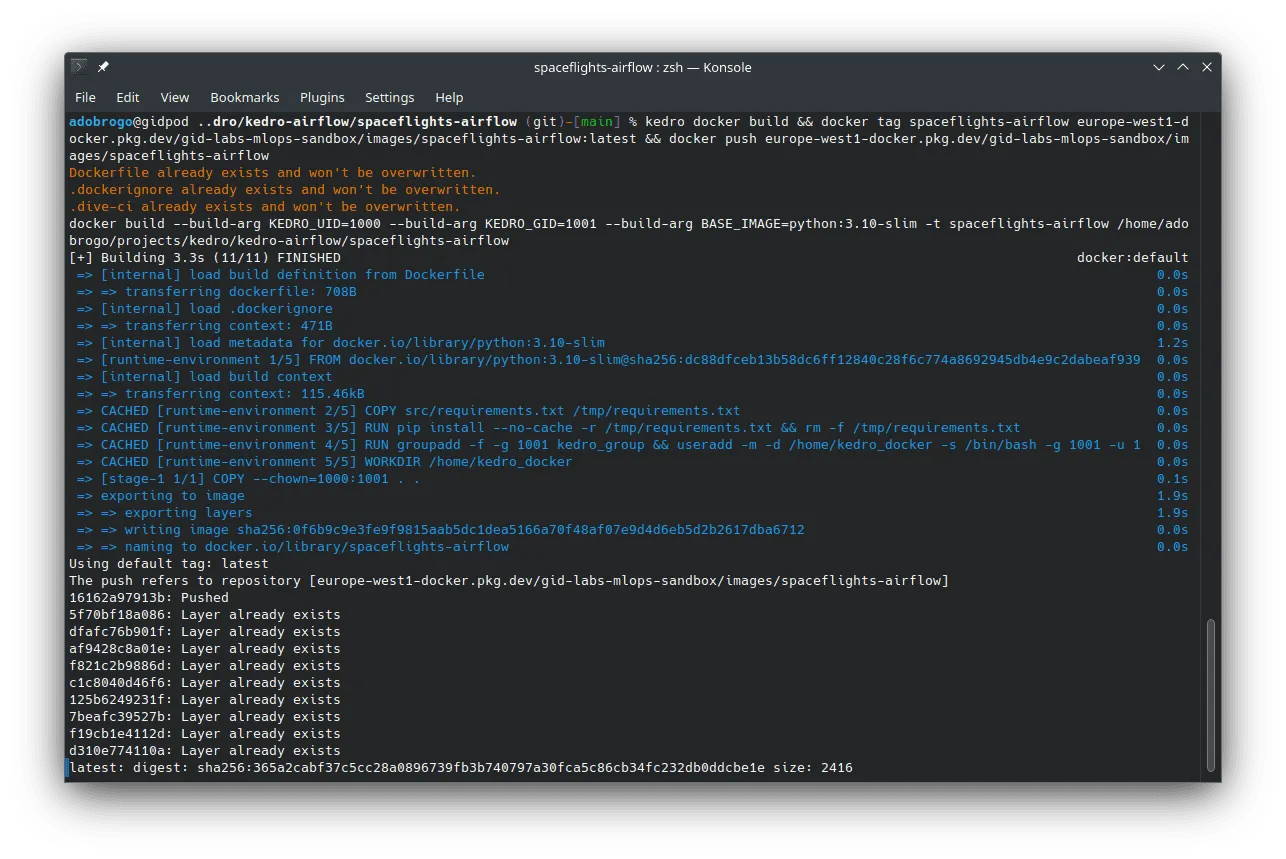
Dann erstellen wir die DAG mit dem Plugin und kopieren sie in den DAGs-Bucket des Composers: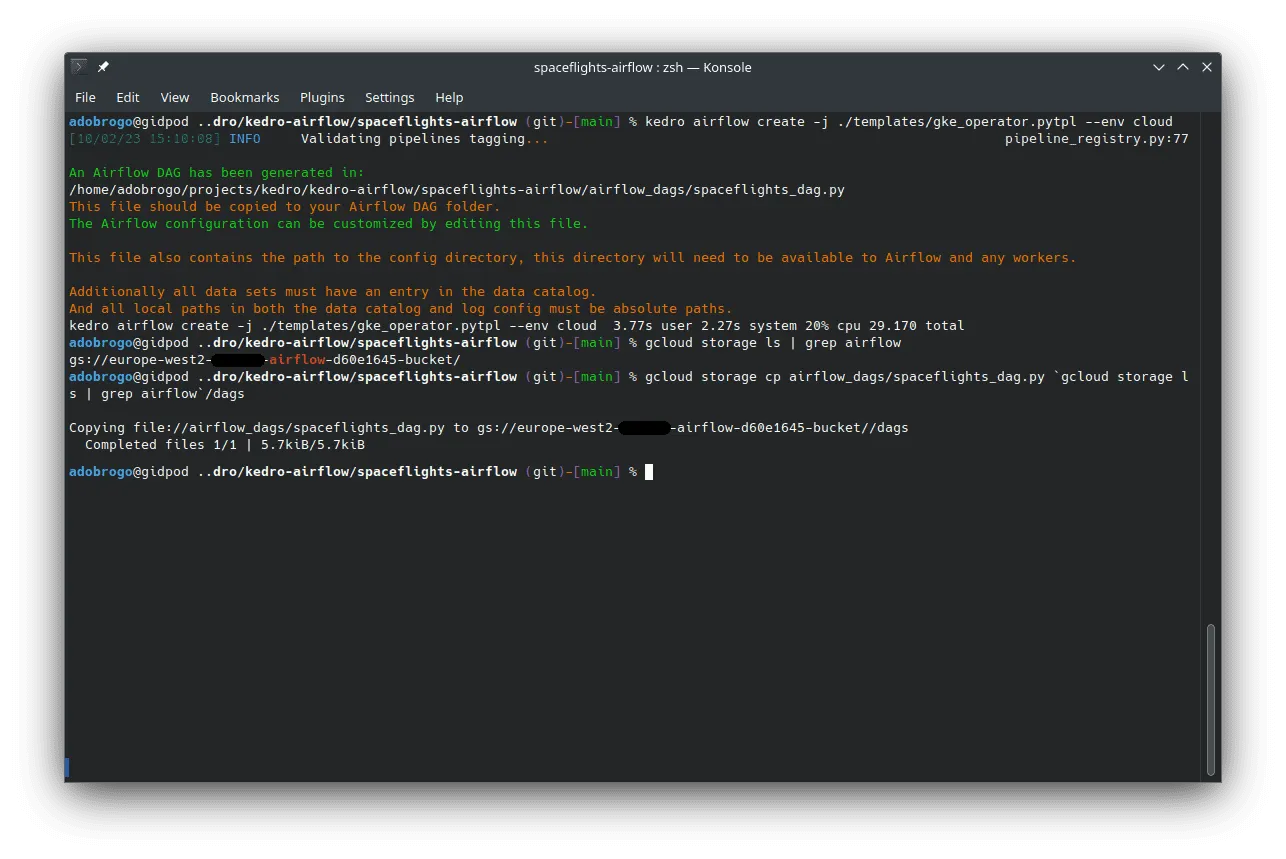
Nach ein paar Minuten sollten wir unseren DAG in der Composer-Benutzeroberfläche sehen. Wir können sie manuell auslösen und sehen die folgenden Ergebnisse: 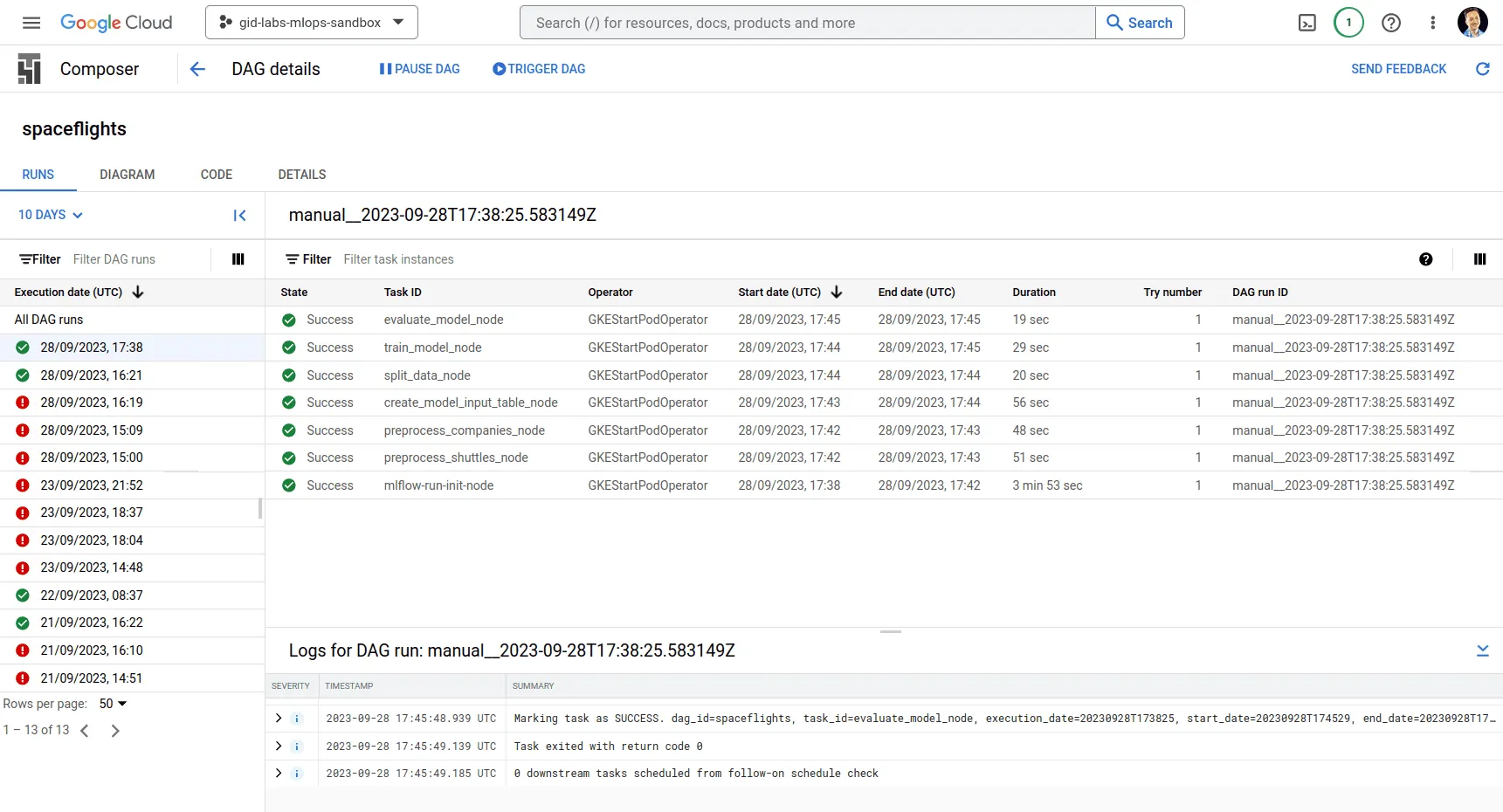
Dies wurde mit deaktivierter Gruppierung durchgeführt. Lassen Sie uns nun die Gruppierung aktivieren und den Unterschied sehen: 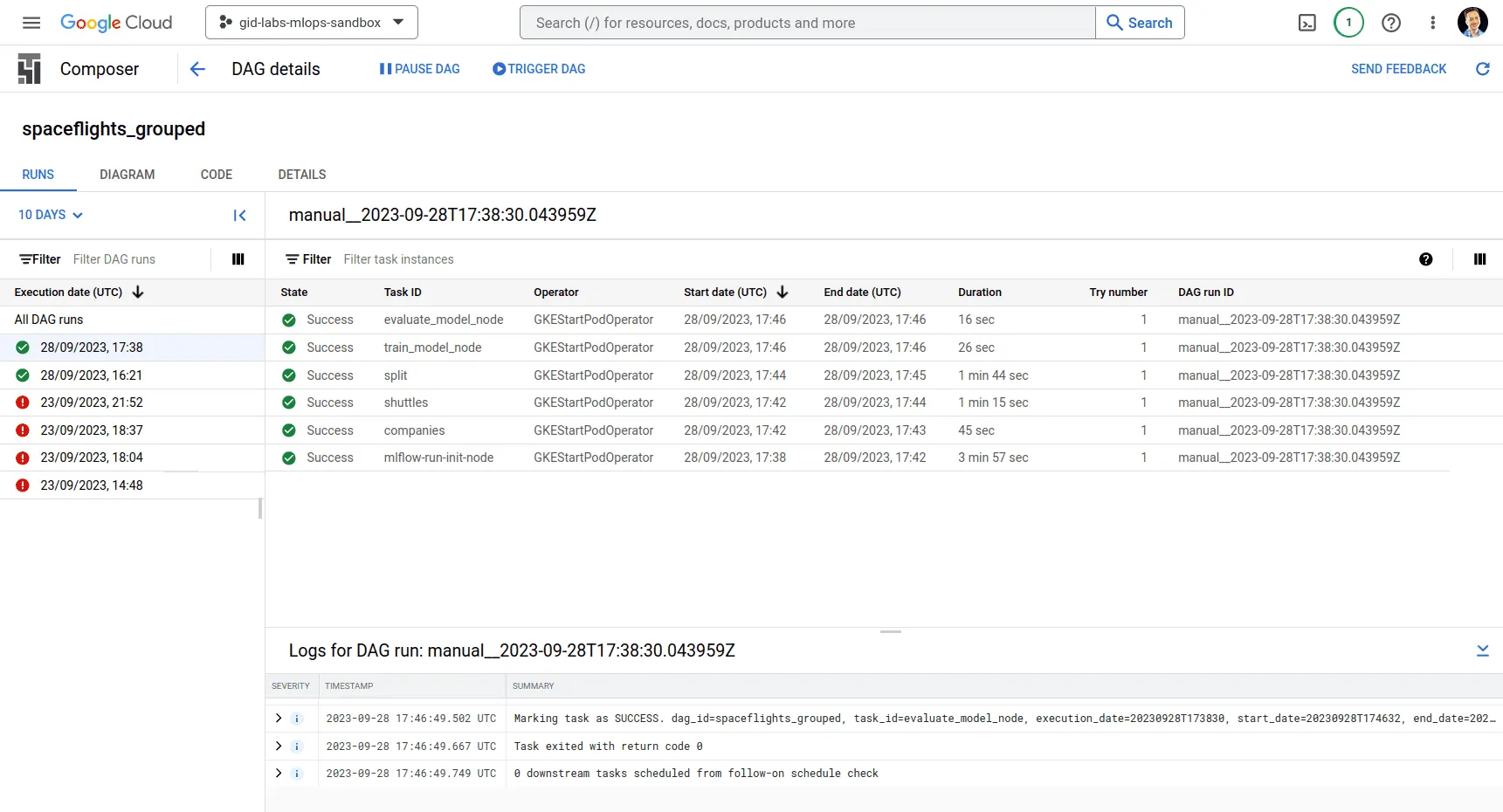
In diesem Beispiel verwenden wir die Gruppierungsfunktion, um die Namen der einzelnen Knoten (sie definieren eine Knotengruppe) mit "airflow:companies" und "airflow:shuttles" zu ändern. Dann gruppieren wir die Erstellung der Modelleingabetabelle und die Datenaufteilung in einem Knoten mit einem "airflow:split" Tag.
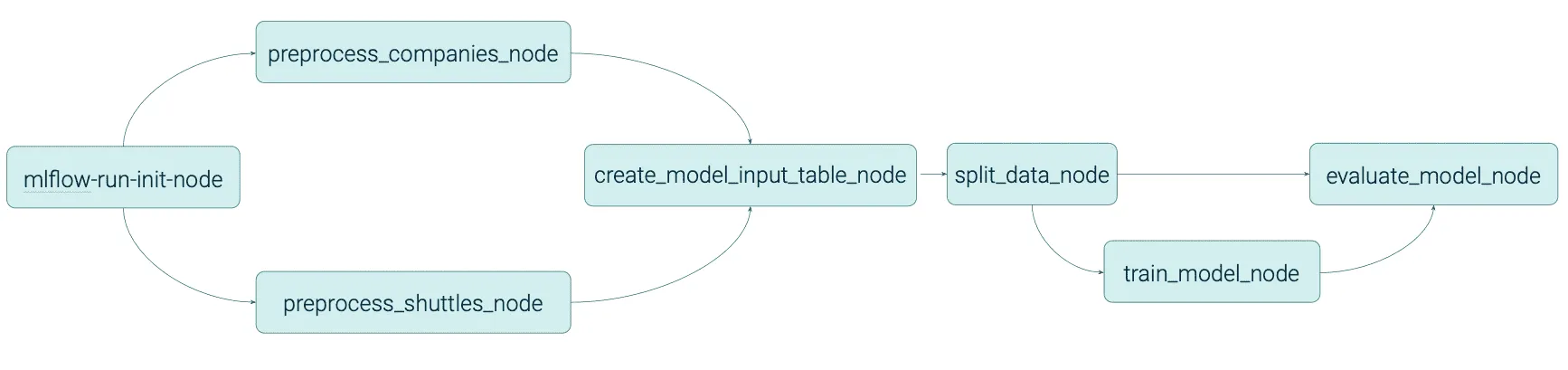
Hier sehen Sie einen direkten Vergleich der generierten Tags mit und ohne Gruppierung: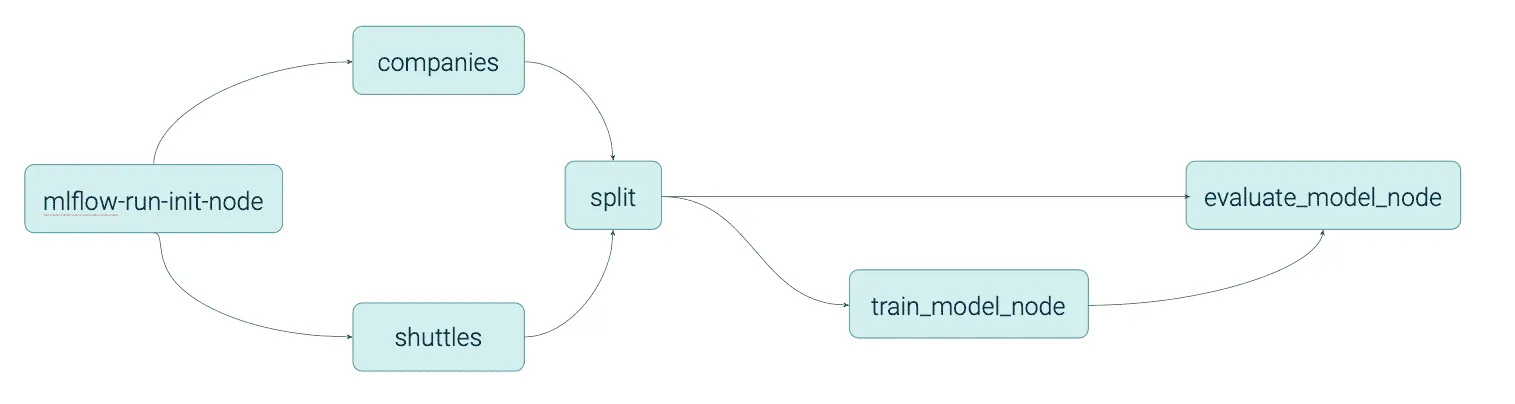
Zoomen Sie einen Knoten heran und sehen Sie sich an, wie die Tags, der Name und das Maschinen-Tag des Knotens in die Parameter des Pods übersetzt werden.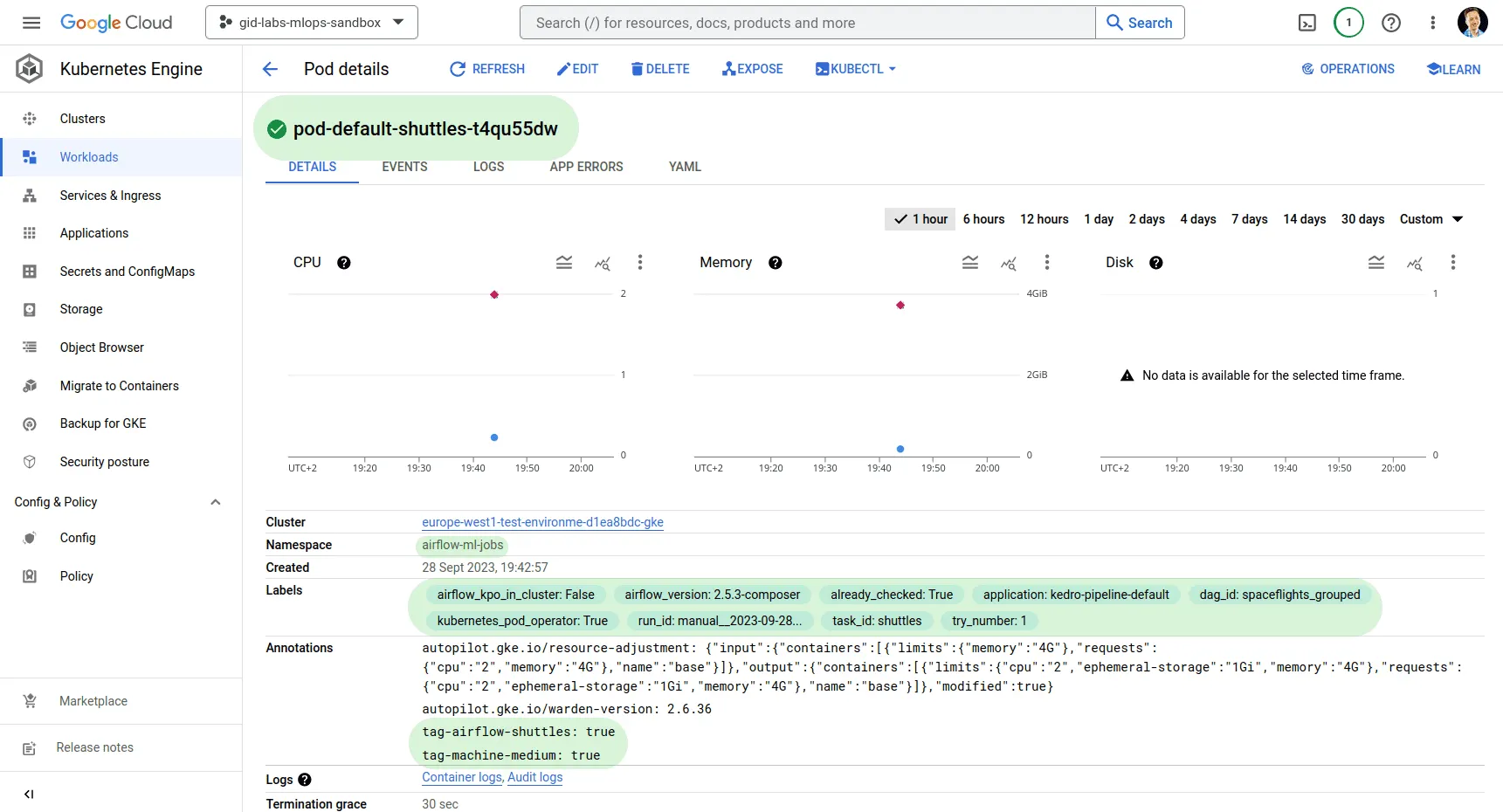
Ein kleines Problem mit Airflow KubernetesOperator XCom
Lassen Sie uns einen Blick auf GKE werfen, um zu sehen, wie Knoten in Pods übersetzt werden: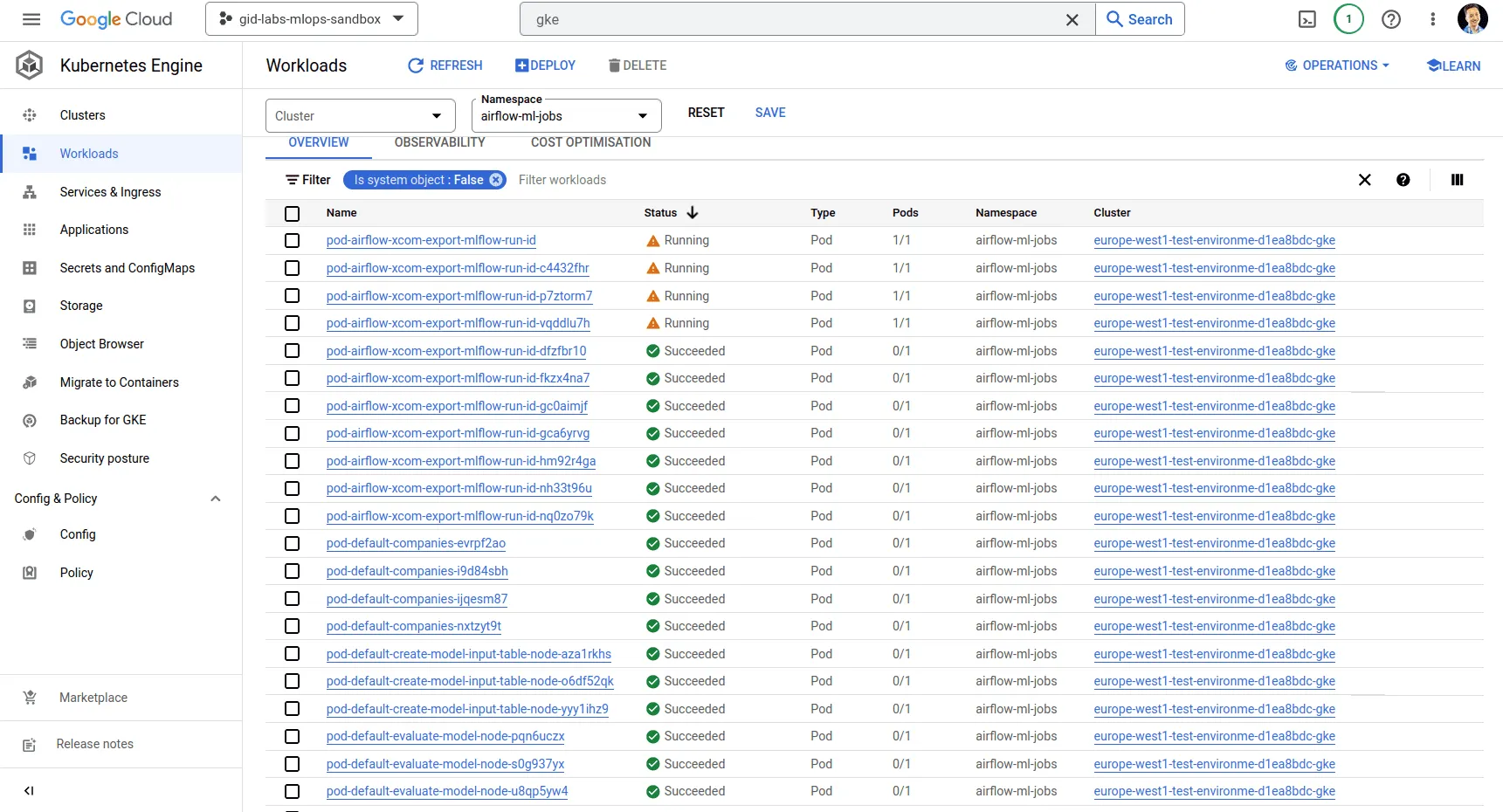
Wir sehen, dass der xcom-Knoten von airflow manchmal lange Zeit zurückbleibt - das liegt daran, wie langsam der xcom-Mechanismus in KubernetesPodOperator sein kann. Der Container auf der Seite des Exporteurs wartet im Wesentlichen darauf, dass ein Signal nach dem Lesen der Daten beendet wird, aber er kann auch länger hängen bleiben. Dieser Mechanismus ist auch der Grund, warum in diesem kleinen Beispiel der Knoten zum Erstellen einer Sitzung in MLflow am längsten braucht (etwa 5 Minuten). In vielen Szenarien ist dies kein Problem. Im Nachhinein betrachtet könnte dies verbessert werden. Die MLflow-Sitzungserstellung kann entweder direkt in Airflow mit PythonOperator erfolgen (und das Hinzufügen der MLflow-Bibliothek als externe Abhängigkeit in Airflow akzeptieren) oder der Kommunikationsmechanismus kann durch den Bucket als Medium anstelle von xcom ersetzt werden.
Fazit
Das Kedro-Airflow-Plugin kann Ihnen mit etwas Aufwand die Arbeit abnehmen und dafür sorgen, dass Ihre Ingenieure die DAG-Übersetzungsaufgaben vergessen und sich auf kreativere Aufgaben konzentrieren können! Der einzige Schritt, der noch aussteht, ist die Einbindung der DAG-Erstellung und das Hochladen des Prozesses in Ihre CI-Tools.
Wir hoffen, dass Ihnen dieser Artikel gefallen hat und Sie ihn nützlich fanden. Wenn Sie Fragen oder Anregungen haben, kontaktieren Sie uns bitte über das untenstehende Formular.
Verfasst von
Artur Dobrogowski
Unsere Ideen
Weitere Blogs




Contact