Blog
Tiefer Umschwung: Flugverzögerungen mit Tensorflow und Kubernetes reduzieren

Der Amsterdamer Flughafen Schiphol ist einer der verkehrsreichsten Flughäfen der Welt. Er fertigt über 70 Millionen Passagiere pro Jahr und über 500.000 Flugbewegungen pro Jahr ab. Derzeit stößt Schiphol an die Grenzen seiner Betriebskapazität.
Um seinen Reisenden weiterhin einen hochwertigen Service zu bieten, sucht Schiphol nach allen möglichen Möglichkeiten, das Erlebnis zu verbessern. Eine der ärgerlichsten und frustrierendsten Erfahrungen für alle Beteiligten (Passagiere, Fluggesellschaften, aber auch der Flughafen selbst) sind Verspätungen.
Um Flugverspätungen zu bekämpfen, wurde ein datengesteuerter Ansatz gewählt, um Einblicke in die Prozesse zu gewinnen, die die Verspätungen verursachen können, von der Ankunft bis zum Abflug und jedem Schritt dazwischen. Der 'Turnaround'-Prozess ist dabei ein wichtiger Bestandteil.
In diesem Blog erörtern wir, wie wir (unter anderem) Tensorflow und Kubernetes eingesetzt haben, um wertvolle Einblicke in den Turnaround-Prozess zu gewinnen.
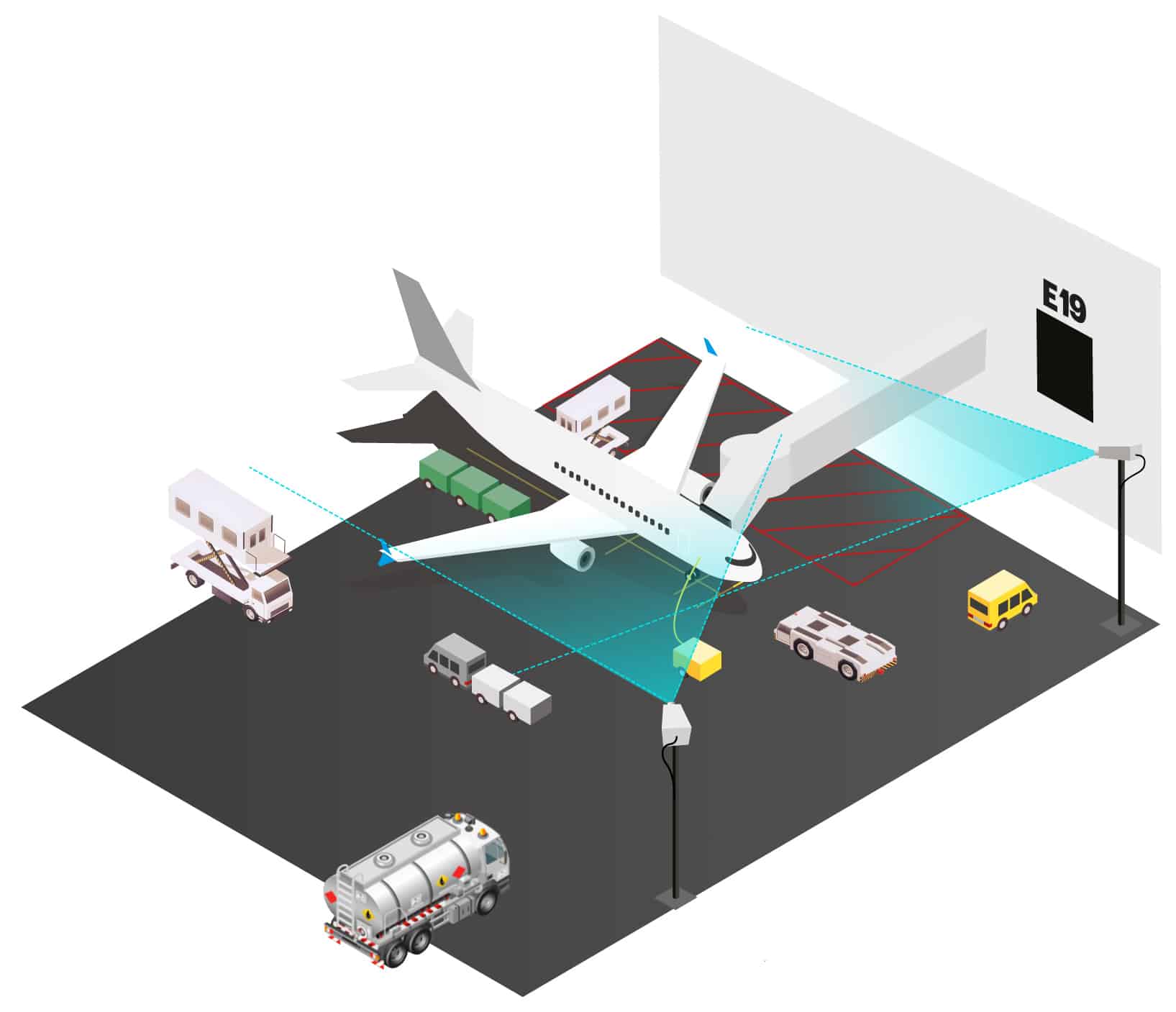
Also... Was ist ein Turnaround?
In einem Satz ausgedrückt, ist ein Turnaround der Prozess des "Umdrehens" eines Flugzeugs von einem ankommenden zu einem abfliegenden Flug. Formal wird dieser Prozess als die Zeit definiert, die zwischen "on-block" und "off-block" vergeht, oder, um es mit den Worten des Laien zu sagen, zwischen "Ankunft am Gate" und "Verlassen des Gates". Während eines Turnarounds finden Aktivitäten wie das Aussteigen und Einsteigen von Passagieren, das Ent- und Beladen von Gepäck und Fracht, Catering, Betankung und Enteisung statt. Die meisten Flughäfen haben keinen automatisierten Einblick in diese Aktivitäten, da sie von den Fluggesellschaften organisiert werden. Darüber hinaus kann jede Fluggesellschaft Vereinbarungen mit einem oder mehreren Abfertigern haben, die die verschiedenen erforderlichen Tätigkeiten ausführen. Dies alles schafft eine komplexe Landschaft mit vielen Parteien, die verschiedene Aufgaben in unterschiedlicher Reihenfolge und auf unterschiedliche Weise ausführen. Man könnte den Turnaround fast als "Blackbox" bezeichnen, was den Zeitpunkt, die Dauer oder die Reihenfolge der Aktivitäten betrifft.
Es gibt mehrere Möglichkeiten, wie ein Einblick in diesen Prozess sehr wertvoll und nützlich sein könnte, um Flugverspätungen zu reduzieren. Ein oft genanntes Beispiel, das leicht zu verstehen ist: Wenn ein Flugzeug 10 Minuten vor dem geplanten Abflug nicht aufgetankt wurde, ist es sehr unwahrscheinlich, dass es das Gate pünktlich verlassen kann. Diese Informationen können genutzt werden, um den Betrieb des Flughafens so zu optimieren, dass die Auswirkungen einer solchen Verspätung minimiert werden und sich nicht auf andere Flüge auswirken. Sie könnten auch genutzt werden, um vielleicht sofort einzugreifen und den Tankwagen auf den Weg zum Flugsteig zu bringen. Es gibt eine Menge potenzieller Anwendungsfälle.
In diesem Blog werden wir nicht weiter auf diese eingehen. Stattdessen werden wir uns darauf konzentrieren, wie wir diese Informationen generieren, da sie eindeutig von großem Wert sind.
Die Idee
Bevor wir ins Detail gehen, wie wir dieses Problem mit Data Science & Engineering lösen können, lassen Sie uns kurz zusammenfassen, wie der Ansatz aussehen wird. Aufgrund der Komplexität der Landschaft (z.B. der Anzahl der beteiligten Parteien) ist es nicht trivial, Einblicke in die Vorgänge während eines Turnarounds zu gewinnen.
Ein Ansatz ist die Verwendung von Kameras, die einen Video-Feed liefern. Anstelle der Installation, Konfiguration und Wartung von möglicherweise Hunderten von Sensoren, die für jedes Tor mit Dutzenden von Parteien koordiniert werden müssten, hat der Einsatz von Kameras den großen Vorteil, dass viel weniger Infrastruktur benötigt wird. An manchen Orten sind die Kameras sogar schon vorhanden. Jede Kamera sendet in regelmäßigen Abständen Schnappschüsse ihres Videobildes in unsere Pipeline. Unsere Pipeline nimmt diese Bilder auf, führt ein wenig schwarze Magie aus (auch bekannt als Data Science) und gibt Ereignisse aus. Beispiele für diese Ereignisse könnten AircraftStopsAtGate, CateringTruckArrivesAtGate oder RefuelingEnds sein. Diese Ereignisse können dann verwendet werden, um Einblicke in die Vorgänge während eines Turnarounds zu erhalten und, was noch wichtiger ist, wann genau.
Physische Infrastruktur
Obwohl unsere Lösung softwarebasiert ist, benötigen wir dennoch etwas Hardware
Bevor wir uns mit der Software-Einrichtung befassen, sollten wir uns ein wenig mit der physischen Infrastruktur befassen. In unserem Fall haben wir einige Experimente mit 2 verschiedenen Kamerakonfigurationen durchgeführt:
- Eine einzelne Kamera, die an der Nase des Flugzeugs positioniert ist.
- Ein Paar Kameras, eine diagonal von der linken Seite des Flugzeugs positioniert, eine auf der diagonalen Seite von links.
Was die physische Infrastruktur betrifft, wäre Option 1 natürlich vorzuziehen. Leider neigen Flugzeugflügel und -triebwerke dazu, die Sicht stark zu beeinträchtigen, was dazu führt, dass viele Objekte von dieser einen Kamera aus nicht (vollständig) sichtbar sind. Option 2 hat den Vorteil, dass sie schräg und leicht erhöht angebracht ist, so dass wir über die Tragflächen hinwegsehen können. Außerdem können wir mit zwei Kameras die Bilder der beiden Kameras korrelieren, um fehlerhafte Erkennungen zu vermeiden.
Eine oft gestellte Frage ist, ob Edge-Computing hier eine Option wäre. Kurz gesagt: Ja, das wäre es. Im Allgemeinen besteht der größte Vorteil des Edge-Computing jedoch in der Reduzierung des Netzwerkverkehrs. Im Fall von Schiphol (und Flughäfen im Allgemeinen) ist die geografische Ausdehnung recht begrenzt. Außerdem war bereits eine dedizierte Netzwerkverbindung zur Cloud vorhanden. Edge Computing würde auch erheblich mehr Wartung vor Ort für jedes Gerät erfordern als nur eine Kamera. Angesichts dieser Überlegungen haben wir uns für eine softwarebasierte Lösung entschieden.

Die Pipeline
Sehen wir uns die "schwarze Magie", von der wir sprachen, einmal genauer an. Wie sieht die Pipeline, die von den Rohbildern zu den Ereignissen führt, eigentlich aus?
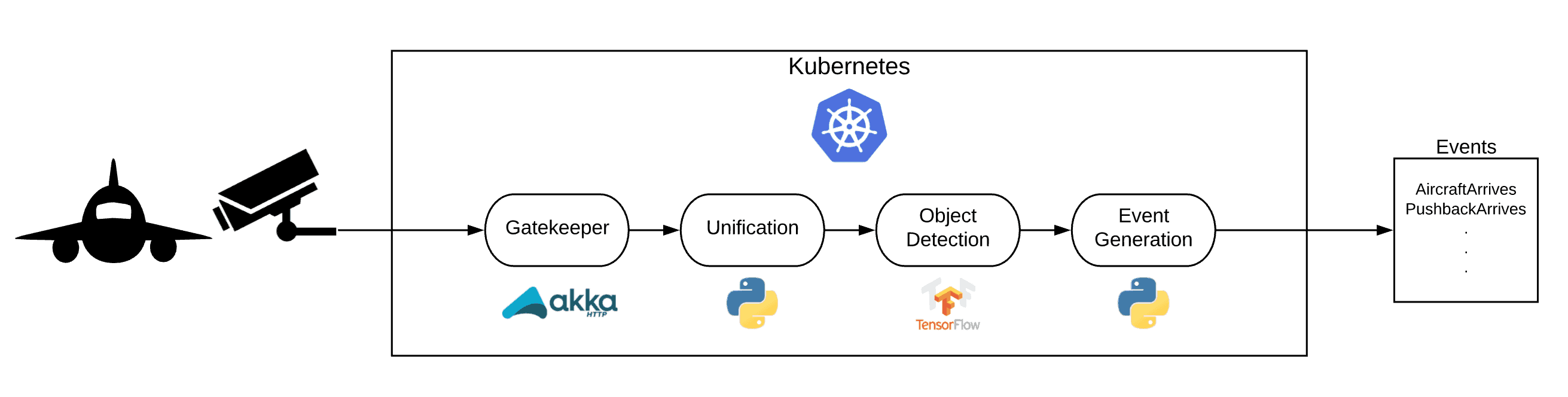
Auf einer hohen Ebene kann der Ablauf wie folgt beschrieben werden:
- Die Bilder werden von der Kamera-Infrastruktur über REST oder gRPC an unseren Gatekeeper gesendet.
- Da die Kameras unabhängig voneinander Bilder produzieren, müssen wir die Bilder pro Tor vereinheitlichen, um sicherzustellen, dass wir einen einzigen Datenpunkt pro Zeitstempel für jedes Tor haben.
- Sobald wir diesen einzelnen Datenpunkt haben, führen wir eine Objekterkennung durch, die eine Liste der Erkennungen für ein Tor zu einem bestimmten Zeitpunkt erstellt.
- Die Ausgabe der Objekterkennung ist etwas umständlich zu verarbeiten (wenn Sie z.B. 2 Stunden lang alle paar Sekunden hören, dass ein Flugzeug am Gate steht, ist das etwas nervig). Um die unbearbeiteten Erkennungen zu aggregieren, führen wir eine Ereignisgenerierung durch.
- Schließlich geben wir die generierten Ereignisse an unsere nachgelagerten Verbraucher aus, die diese Daten zur Verbesserung ihrer jeweiligen Prozesse nutzen können.
Wie Sie auf dem Bild sehen können, kommen bei diesem Prozess mehrere Technologien zum Einsatz. Auch wenn es für jede von ihnen gültige Alternativen gibt, werden wir in diesem Beitrag den folgenden Stapel verwenden:
- Kubernetes ist die Plattform, auf der alle Komponenten ausgeführt werden.
- Kafka ist der verwendete Nachrichtenbus.
- Das Objekterkennungsmodell ist ein trainiertes Tensorflow-Modell.
- Event Generation ist ein Python-Modul.
- Der Gatekeeper ist eine Scala-Anwendung, die mit Akka HTTP erstellt wurde.
Der Torwächter
Um die Streaming-Plattform von der Software auf den Kameras zu entkoppeln, haben wir einen Dienst entwickelt, der als REST-Endpunkt für die Kameras fungiert. Dieser Gatekeeper nimmt POST-Anfragen mit Bildern entgegen und leitet die Bilder als Nachrichten an den Nachrichtenbus weiter. So können wir unser komplettes Backend, den Message Bus oder etwas anderes ändern, während die Schnittstelle zwischen den Kameras und der Pipeline unverändert bleibt.
Vereinheitlichung
Die Kameras arbeiten völlig unabhängig voneinander. Ein Nachteil dabei ist, dass die Bilder, die in der Pipeline ankommen, nicht synchronisiert sind und keine Nachrichten-ID haben. Für unsere Pipeline benötigen wir jedoch zwei Bilder, die Daten für einen einzigen Zeitpunkt darstellen. Um dies zu erreichen, haben wir einen "Vereinheitlichungs"-Algorithmus entwickelt, der auf den Zeitstempeln der ankommenden Bilder basiert. Der Algorithmus puffert die Bilder für eine bestimmte Zeitspanne und versucht, Bildpaare zu bilden, wobei ein Bild von jeder Kamera stammt.
<<>>
<<>>
Objekt-Erkennung
Idealerweise muss jedes Objekt, das für eine der Umkehraktivitäten verantwortlich ist, auf den Bildern erkannt werden. Dazu gehören Objekte wie z.B.:
- Kraftstoffpumpe LKW
- Catering-LKW
- Bandlader (für Gepäck)
- Gepäckwagen
Wie bereits erwähnt, haben unsere Data Scientists ein Objekterkennungsmodell mit Tensorflow erstellt. Glücklicherweise haben sie hervorragende Arbeit geleistet und unglaubliche Genauigkeits- und Präzisionswerte erzielt, was die korrekte Erkennung aller verschiedenen Objekte und Fahrzeuge angeht, die an einer Wende beteiligt sind. Wir werden ihnen nicht den Wind aus den Segeln nehmen und in diesem Blogbeitrag enthüllen, wie sie das erreicht haben ;-).
Ein Nachteil ist, dass sie das Modell in einem kompletten Batch-Szenario erstellt haben, was vor allem daran lag, dass zu Beginn des Modells kein Datenstrom zur Verfügung stand. Für unsere Benutzer könnten Einblicke (fast) in Echtzeit natürlich sehr wertvoll sein, da sie so schneller auf mögliche Abweichungen reagieren oder vielleicht ihre Planung umstellen könnten, wenn sie feststellen, dass ein Flugzeug nicht rechtzeitig abfliegen kann. Aus diesem Grund mussten wir das Objekterkennungsmodell im Streaming-Verfahren zum Laufen bringen.
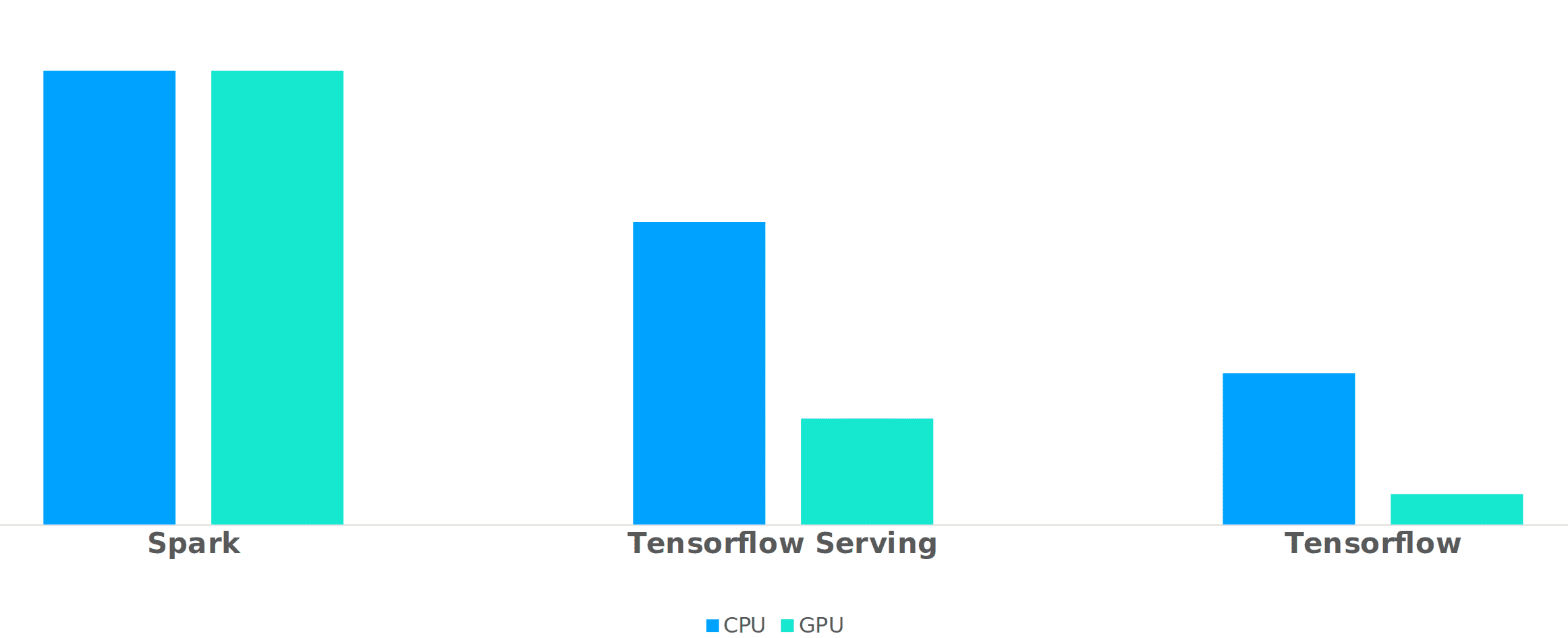
Es wäre unaufrichtig von uns, zu behaupten, dass wir unsere endgültige Lösung sofort gefunden haben. Wir haben eine ganze Menge ausprobiert. Zunächst versuchten wir, die Inferenz auf Spark laufen zu lassen (da Schiphol die Infrastruktur dafür zur Verfügung hatte). Eine Zeit lang haben wir auch Tensorflow Serving verwendet. Tensorflow Serving funktioniert gut, brachte aber zusätzliche Komplexität mit sich, da wir eine REST/gRPC-Schnittstelle benötigten und somit auch einen Dienst, der mit dieser Schnittstelle interagieren konnte. Es hat von Anfang an sehr gut funktioniert und wir empfehlen es jedem, der schnell ein Tensorflow-basiertes Modell zur Verfügung stellen möchte.
Letztendlich gelang es uns, dies recht elegant zu bewerkstelligen, indem wir den Kafka-Konsumenten direkt in den Tensorflow-Code einfügten, den wir für die Batch-Inferenz verwendet hatten. Unsere größte Frage war jedoch, ob wir GPUs für die Inferenz verwenden sollten oder nicht. Unsere Data Scientists waren der festen Überzeugung, dass dies für das Training und die Batch-Inferenz in großem Maßstab notwendig sei. Mit einigen Optimierungen gelang es uns jedoch, die Inferenzzeit pro Bildpaar auf etwa 1 Sekunde pro Bild zu senken. Die größte Schwierigkeit für uns (die wir neu in Tensorflow sind) bestand darin, die Tensorflow-Sitzung wiederzuverwenden, anstatt für jede Nachricht eine neue zu starten. Am Ende sah unsere Inferenzschleife ungefähr so aus:
with detection_graph.as_default():
with tf.Session() as sess:
tensor_dict = get_tensors()
for message in kafka_consumer:
data = parse_message(message.value)
results = run_inference_for_dual_images(data, sess, tensor_dict)
send_message(results, producer, topic)Als neugierige Ingenieure haben wir natürlich ein grobes Benchmarking der Lösungen durchgeführt, das Sie unten sehen können. Bitte beachten Sie, dass wir die Y-Achse absichtlich weggelassen haben, da wir keine wissenschaftliche Relevanz für bestimmte Zahlen beanspruchen wollen :-).
Erzeugung von Ereignissen
Nachdem wir die Bilder der Kameras einer Objekterkennung unterzogen haben, verfügen wir nun über Informationen darüber, welche Objekte zu einem bestimmten Zeitpunkt vorhanden waren, und zwar (fast) in Echtzeit. Die Arbeit mit diesen Daten ist zwar interessant, aber sie wäre schwierig und würde relativ fortschrittliche Tools erfordern, zu denen unsere Geschäftsanwender keinen einfachen Zugang haben.

Die Ereignisgenerierungskomponente unserer Pipeline nimmt die Erkennungen und fasst sie zu menschenfreundlicheren Ereignissen zusammen, wie z.B.:
- AircraftStopsAtGate und AircraftLeavesGate
- FuelingStart und FuelEnd
Wir müssen aus mehreren Gründen ein wenig fenstern:
- Es kann sein, dass eine (oder beide) der Kameras ausfällt oder keine Bilder sendet. In einem solchen Fall bedeutet die Tatsache, dass wir ein Flugzeug für 1 oder 2 Zeitstempel nicht "sehen", nicht, dass das Flugzeug verschwunden ist. Wir möchten die Benutzer zuverlässig darüber informieren können, ob und wann ein Ereignis tatsächlich eingetreten ist.
- Die Kameras könnten Fahrzeuge sehen, die im Hintergrund vorbeifahren, auf dem Weg zu einem anderen Tor. In solchen Fällen ist die Erkennung nicht wirklich falsch, aber wir möchten nicht, dass sie ein Ereignis auslöst.
- Die Kameras selbst können durch das Wetter beeinträchtigt werden. Sie können sich vorstellen, dass Regentropfen die Sicht verdecken oder dass starker Wind die Kamera leicht bewegen kann. In solchen Fällen kann das Objekterkennungsmodell (vorübergehend) eine nicht korrekte Ausgabe liefern.
Aus all den oben genannten Gründen legen wir ein einfaches gleitendes Fenster über die Erkennungen, während sie in den Ereignisgenerator fließen. Sobald das Fenster aktualisiert wurde, wird eine Reihe von Geschäftsregeln ausgeführt, um zu bestimmen, ob ein Ereignis erzeugt werden soll oder nicht. Um Ihnen einen Einblick zu geben, wie eine solche Geschäftsregel aussieht, haben wir hier etwas Pseudocode bereitgestellt:
if fuel_truck is present or aircraft is not present:
return
num_present = 0
for observation in window:
if fuel_truck_detected:
num_present += 1
num_present_ratio = num_present / window_size
if num_present_ratio > presence_threshold_ratio:
trigger_event(fuel_truck_arrives)Jedes Ereignis wird etwas anders definiert, um den spezifischen Merkmalen dieses Ereignisses Rechnung zu tragen. Sie können sich zum Beispiel vorstellen, dass die Anwesenheit eines bestimmten Lastwagens nicht von Interesse ist, wenn zu diesem Zeitpunkt kein Flugzeug zu sehen ist (vielleicht hält der Fahrer für eine Tasse Kaffee an ;-) ).
Das Ergebnis
Die Ereignisse, die durch den Schritt der Ereignisgenerierung erzeugt werden, ermöglichen es uns, in Echtzeit Einblicke in die Vorgänge bei der Abfertigung eines Flugzeugs zu erhalten. Die Darstellung dieser mit Zeitstempeln versehenen Ereignisse in einem Gantt ist ebenfalls sehr nützlich, da Sie so einen guten Überblick darüber erhalten, welche Prozesse zu welchem Zeitpunkt abliefen:
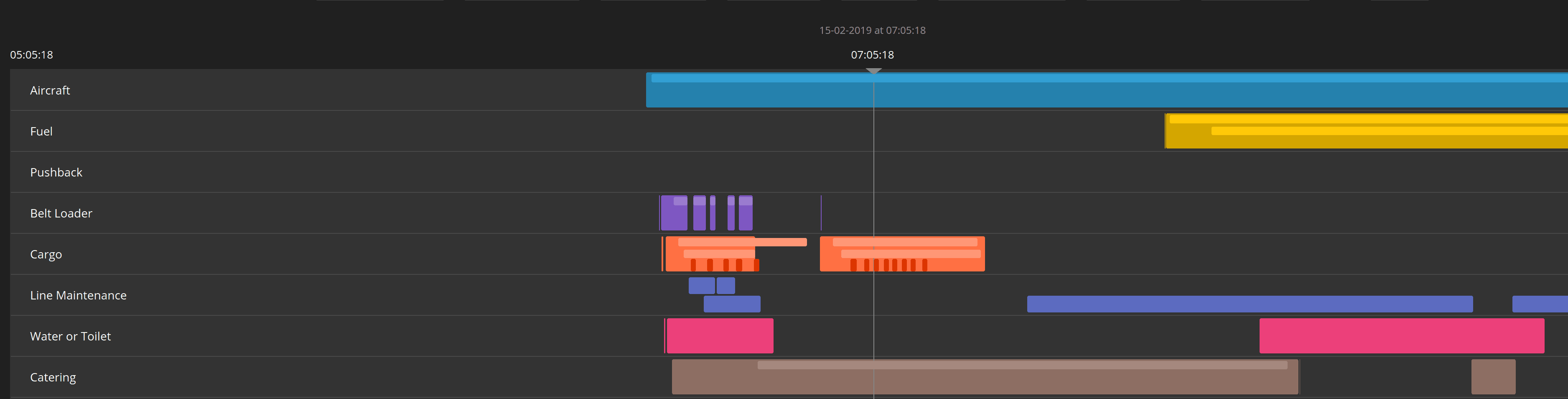
Auf diese Weise kann der Betrieb besser verstehen, was vor sich geht, und möglicherweise eingreifen, wenn dies notwendig und angemessen ist.
Einpacken
Zusammenfassend lässt sich sagen, dass wir eine End-to-End-Streaming-Pipeline aufgebaut haben, die Bilder aufnimmt und Betriebsereignisse ausgibt, die zur Optimierung des Abfertigungsprozesses von Flugzeugen am Flughafen Amsterdam Schiphol verwendet werden können. Dieses System wird derzeit noch weiter verfeinert, aber wir wollten diese erste Version bereits mit Ihnen teilen. Wenn Sie Tipps, Tricks, Kommentare oder Fragen zu diesem Thema haben, zögern Sie nicht, uns zu kontaktieren! Wir würden uns freuen, Ihre Meinung zu hören!
Wenn Sie mehr darüber erfahren möchten, wie dieses Projekt weiterentwickelt wurde, werden wir am 1. April auf der Kubecon 2020 in Amsterdam einen Vortrag halten. Details finden Sie hier
Unsere Ideen
Weitere Blogs




Contact