
Hinweis: Lesen Sie den zweiten Teil dieses Beitrags hier.
Einführung
Viele Unternehmen stehen heute vor der Frage: "Wie kann ich einfacher und schneller einen Mehrwert aus meinen Daten ziehen?". Unabhängig davon, ob Sie bereits eines dieser Unternehmen sind oder eines werden wollen, wird dieser Artikel einen Weg aufzeigen, wie Sie die Datenverarbeitung rationalisieren und die Datenanalyse verbessern können. Eine wichtige Entwicklung in diesem Bereich ist das Produkt "dbt" (data build tool), das einen einheitlichen und konsistenten Rahmen für die Pflege und Erstellung von Geschäftslogik auf Ihrer Datenbank bietet.
Eine seiner Funktionen ist der dbt Semantic Layer, mit dem eine Grundlage für bessere Business Intelligence-Prozesse geschaffen werden kann. Im ersten Teil dieses Artikels werden wir erklären, was ein Semantic Layer ist. Im zweiten Teil dieses Artikels werden wir 2 Anwendungsfälle beschreiben, um zu zeigen, wie Sie dbt SL in die aktuelle Business Intelligence-Landschaft integrieren können:
- Google Sheets (für Business-Analysten),
- Python (für Dateningenieure und Datenwissenschaftler).
Was ist dbt?
Neben anderen modernen Datenmodellierungstools gibt es auch dbt. In den ETL / ELT-Prozessen steht dbt für das T - transform. Mit dieser Plattform können Sie Transformationen mit SQL erstellen, Tests hinzufügen und eine benutzerfreundliche Dokumentation erstellen. Es ist zwar nicht dazu gedacht, bestehende Datenplattformen oder Modellierungssprachen zu ersetzen, kann aber als logische Schicht in verschiedene Datenverarbeitungstools integriert werden, um die Geschäftslogik zu erhalten. Ähnlich wie bei anderen fortgeschrittenen Tools können Sie mit dbt transformierte Tabellen in Ihrer Zieldatenbank speichern und die Bedingungen festlegen, unter denen die Ergebnisse aktualisiert werden sollen.
Was ist die semantische Schicht?
Der dbt Semantic Layer (SL) ist eine Erweiterung der Hauptfunktionalität von dbt. Er wurde entwickelt, um eine zentralisierte und konsistente Möglichkeit zur Definition von Geschäftsmetriken, Dimensionen und Beziehungen zu bieten. Er dient als einzige Quelle der Wahrheit für die Geschäftslogik und stellt sicher, dass jeder im Unternehmen dieselben Definitionen für die wichtigsten Metriken verwendet. Wichtig ist, dass dbt SL ein lebendiges Produkt ist, mit dem Sie über eine API kommunizieren können, um die Ergebnisse bestimmter Geschäftsberechnungen zu erhalten.
Diese Schicht befindet sich zwischen den Rohdaten und den Business Intelligence (BI)-Tools und ermöglicht eine genaue und konsistente Berichterstattung. Die dbt SL ist eine logische Schicht, die über Ihrem Datenmodell erstellt wird. Hier können Sie Berechnungen für Metriken und auch Dimensionen definieren, nach denen Sie diese Daten analysieren möchten.
Wichtige Funktionen der dbt Semantischen Schicht
- Metrikdefinitionen: Die SL ermöglicht die Definition von Metriken an einem Ort und gewährleistet so die Konsistenz der Berechnungen in allen Berichten und Dashboards.
- Verwaltung von Dimensionen: Es bietet Funktionen zur Definition von Dimensionen, nach denen Sie Daten analysieren möchten, was eine bessere Qualität der Aufteilung ermöglicht.
- Datenherkunft: Die Benutzer können die Herkunft der Datenpunkte bis zu ihrer Quelle zurückverfolgen, was die Transparenz und das Vertrauen in die Daten fördert. Dies ist dank der automatisch generierten Online-Projektdokumentation möglich.
- Kompatibilität mit BI-Tools: SL lässt sich in Google Sheets, MS Excel und beliebte BI-Tools wie Tableau, Looker und Power BI integrieren und erweitert so deren Möglichkeiten.
Entwicklungsumgebungen
Es gibt zwei verfügbare Versionen des dbt-Tools - dbt Cloud und dbt Core. Im Prinzip bieten beide dieselbe grundlegende dbt-Plattform, aber sie unterscheiden sich in ihrer Arbeitsweise und den verfügbaren Funktionen. dbt Core ist die quelloffene, selbstgehostete Version, die eine vollständige Einrichtung der Entwicklungsumgebung erfordert. Um diese Version zu verwenden, müssen Sie ein Hosting für die Plattform einrichten, den Scheduler und den Orchestrator für die Jobs konfigurieren und auch die Protokollierungs- und Überwachungsmechanismen hinzufügen. Im Vergleich dazu ist dbt Cloud eine betriebsbereite Plattform, die von dbt verwaltet wird. Es handelt sich um einen gehosteten Dienst, der eine Weboberfläche bietet, die eine einfache Entwicklung aller Transformationen, Zusammenarbeit und Orchestrierung ermöglicht.
Darüber hinaus sind Kosten und Funktionen die wichtigsten Unterscheidungsmerkmale zwischen diesen beiden Produkten. dbt Core ist kostenlos und quelloffen, während dbt Cloud eine kostenlose Stufe mit eingeschränkten Optionen und kostenpflichtige Stufen mit allen Funktionen anbietet, wobei die Kosten von der Teamgröße abhängen. dbt Core ist nur auf grundlegende Funktionen beschränkt, während dbt Cloud eine vollständige Plattform für die Zusammenarbeit im Team, rollenbasierte Zugriffskontrolle, Entwicklungsumgebung und Versionierung bietet.
Da wir uns hier auf den Semantic Layer von dbt konzentrieren, ist es wichtig zu erwähnen, dass der Benutzer in dbt Core nur SL-Definitionen erstellen und lokal validieren kann - unter Verwendung spezieller Python-Bibliotheken. In der dbt Cloud hingegen erhalten wir, sofern wir eine Team- oder Enterprise-Lizenz erwerben, die Möglichkeit, eine Online-API für unseren dbt SL zu konfigurieren. Dank dieser API können wir über externe Tools wie Google Sheets oder Python-Anwendungen mit unserem Modell kommunizieren.
Verwendung
Sie können auf verschiedene Arten mit SL interagieren, die im Allgemeinen in zwei Gruppen eingeteilt werden: vordefinierte und benutzerdefinierte. Vordefinierte Integrationen funktionieren als Plug-ins für ausgewählte Tools wie Google Sheets, Microsoft Exceloder Tableau (siehe die vollständige Liste hier). In diesen Programmen können Sie das Plug-in aktivieren, die Verbindung mit SL herstellen und Abfragen über eine Drag-and-Drop-Oberfläche konfigurieren. Im folgenden Anwendungsfall sehen Sie, wie Sie dbt SL mit Google Sheets verbinden können.
Andererseits können Softwareentwickler mit Hilfe von kundenspezifischen Integrationen maßgeschneiderte Lösungen erstellen, die den dbt Semantic Layer in die bestehende IT-Architektur integrieren.. Zum Zeitpunkt der Erstellung dieses Artikels können Ingenieure die JDBC-API verwenden, GraphQL API, oder Python SDK für diese benutzerdefinierten Integrationen (weitere Einzelheiten finden Sie hier). Sehen Sie sich den Anwendungsfall unten an, um zu erfahren, wie Sie mit dbt SL über GraphQL API kommunizieren können.
In Anbetracht der Möglichkeiten des dbt Semantic Layer gibt es zwei Schlüsselbereiche in Ihrem Unternehmen, die erheblich davon profitieren könnten:
Business-Analytik
- Keine Kodierung - Geschäftsanalysten, die nicht wissen, wie man programmiert oder mit Datenbanken kommuniziert, können ganz einfach frische und umgewandelte Daten von dbt SL erhalten.
- Logik - die Geschäftslogik von Maßnahmen und Berechnungen ist auf der SL-Ebene definiert, so dass es keine Verwirrung darüber gibt. BAs können aufbereitete Daten abrufen und für die Analyse verwenden, ohne sich in die Details vertiefen zu müssen.
- Flexibilität - mithilfe der vordefinierten Integrationen mit z.B. Google Sheets oder Microsoft Excel können Analysten benutzerdefinierte Berichte erstellen, die Daten aus selbst definierten Abfragen verwenden.
Datentechnik & Datenwissenschaft
- Erweiterung - Spezialisten in den Bereichen DE & DS können ihre Datenpipelines mit der dbt SL API weiterentwickeln und maßgeschneiderte Lösungen für ihre Bedürfnisse erstellen.
- Klare Geschäftslogik - dank der definierten Logik in dbt SL brauchen Sie die Details der Berechnungen nicht weiter zu untersuchen. Das spart Zeit bei der Recherche und ermöglicht es Spezialisten, schneller Ergebnisse zu liefern.
- Frische - durch die Verwendung der dbt-Abfragen können sie mit den aktuellsten Daten arbeiten, wodurch das Risiko von Datenfehlern verringert wird.
- Automatisierung - Sie können viele Aufgaben im Zusammenhang mit der Dateneingabe automatisieren und sich so auf wertschöpfende Aufgaben konzentrieren. Dies führt zu einer Verkürzung der Zeit zwischen Datenerstellung und -analyse.
Anwendungsfall: dbt SL mit Google Sheets
Was ist der geschäftliche Kontext? Sie sind ein Business Analyst, der sich stark auf Datentools wie Microsoft Excel oder Google Sheets verlässt. In Ihrer täglichen Arbeit erhalten Sie viele Anfragen zur Überprüfung von Daten, zur Berechnung einiger grundlegender KPIs und zur schnellen Beantwortung von Geschäftsfragen. Sie sind kein Entwickler, wissen also nicht, wie man in SQL oder Python kodiert, und sind auf der Suche nach sofort einsetzbaren Datenansichten. Kürzlich haben Sie erfahren, dass Ihr Unternehmen ein dbt-Tool implementiert hat und Sie den dbt Semantic Layer mit vordefinierten KPI-Berechnungen nutzen können. Sie möchten Ihr Toolset mit diesem neuen Spielzeug erweitern und beginnen mit der Einrichtung eines neuen Datenflusses.
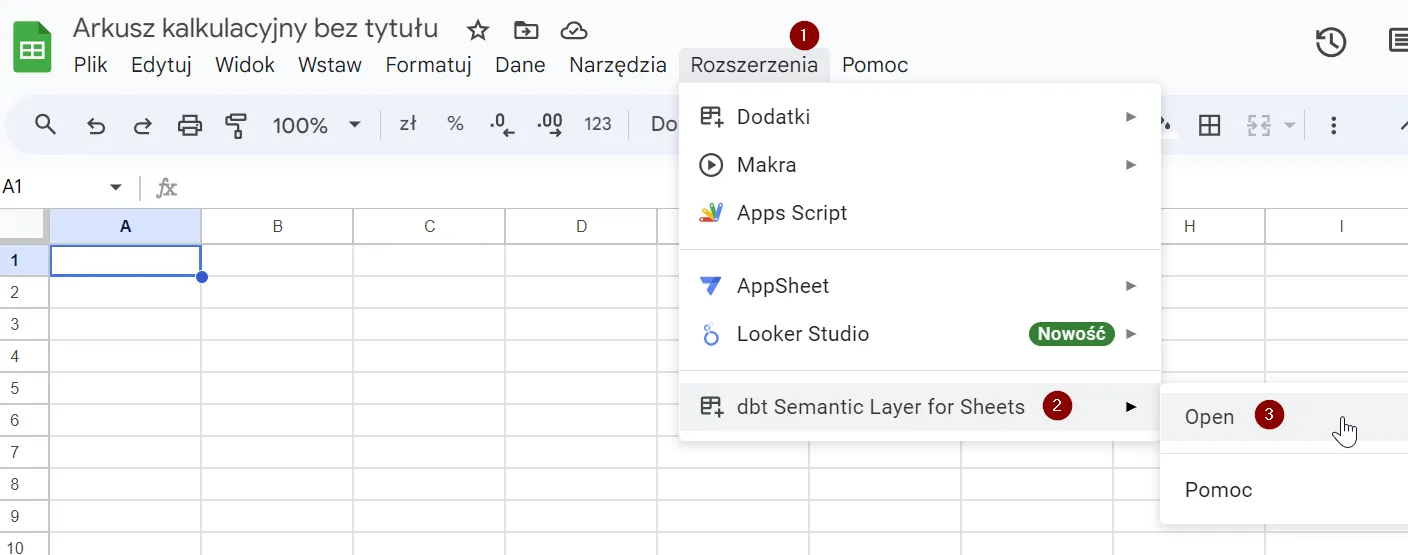
Um dbt SL in Google Sheets verwenden zu können, müssen Sie zunächst eine neue Erweiterung namens "dbt Semantic Layer for Sheets" aus dem Google Workspace Marketplace hinzufügen. Wenn Sie sie nicht selbst hinzufügen können, müssen Sie Ihren Google Tenant Admin bitten, sie in Ihrer Organisation zu installieren. Wenn dies geschehen ist, öffnen Sie die Google Sheets-App und gehen Sie zu Erweiterungen → dbt Semantic Layer for Sheets → Öffnen. 
Um eine Verbindung zu einem bestimmten dbt SL herzustellen, geben Sie bitte den Hostnamen, die Umgebungs-ID und das Service-Token an. Alle diese Angaben finden Sie unter Einstellungen → Projekt → Semantische Schicht (siehe Beispiel auf dem Screenshot unten). 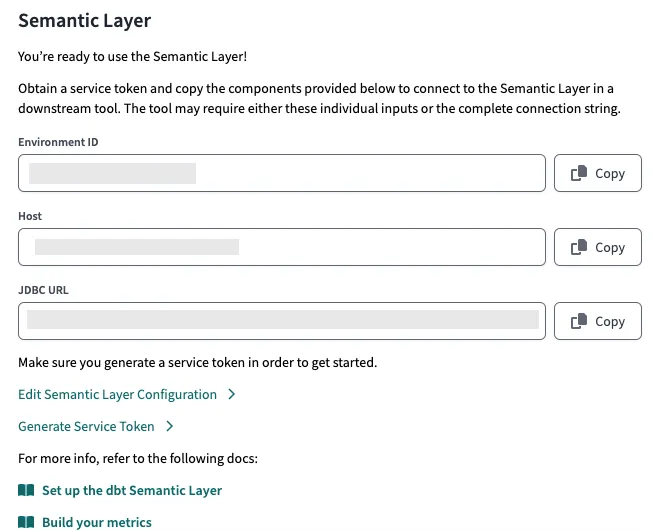
Nach der Verbindung mit SL sehen Sie den Query Builder, in dem Sie die Daten auswählen können, die Sie sehen möchten, z.B. Metrik, Gruppierung nach, Filterung usw. Wenn Sie fertig sind, klicken Sie auf die Schaltfläche Abfrage ausführen und Google Sheets wird die Daten von dbt abfragen und die Ausgabe in der Tabelle darstellen. 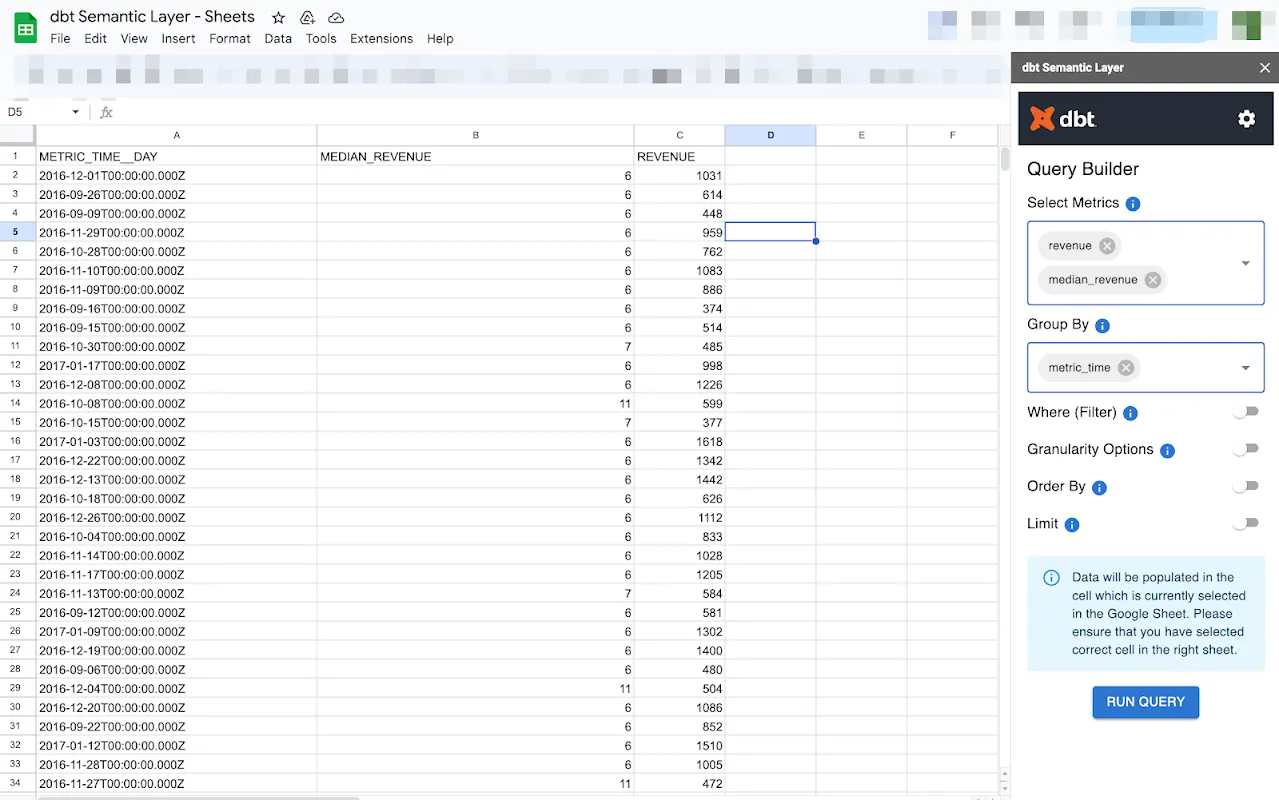
Diese Abfrage wird jedes Mal aktualisiert, wenn Sie Google Sheets öffnen oder wenn Sie erneut auf die Schaltfläche Abfrage ausführen klicken. Sie können diese Daten für Ihre weiteren Analysen oder die Erstellung von Dashboards verwenden.
Anwendungsfall: dbt SL mit GraphQL API in Postman
Die Präsentation der Lösung wird in zwei Teilen erfolgen. Zunächst zeigen wir, wie Sie die Anfrage mit Postman erstellen und testen, und dann, wie Sie den Code in Python schreiben.
Zunächst müssen Sie die URL ermitteln, unter der Ihr Projekt verfügbar ist. Gehen Sie zu Einstellungen → Konten → Zugriffs-URLs und kopieren Sie den dort aufgeführten Wert (der mit ...dbt.com/ endet). 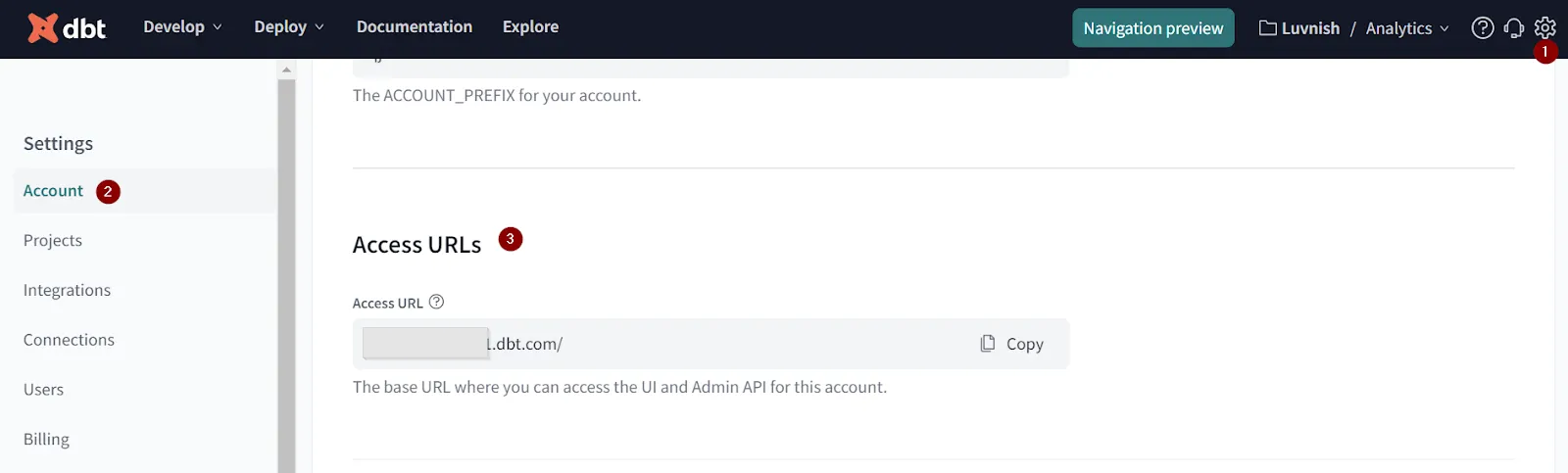
Rufen Sie die Details Ihrer SL auf, indem Sie zu Einstellungen (Symbol oben rechts) navigieren, Projekte wählen und dann den Namen des Projekts, an dem Sie arbeiten. Scrollen Sie nach unten zu den Details der semantischen Ebene. Bitte notieren Sie sich die Details zu Ihrem Semantischen Layer. 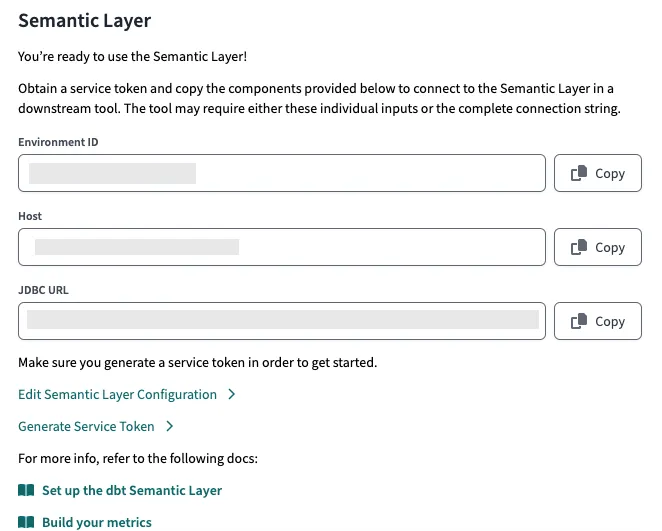
Öffnen Sie Postman und erstellen Sie eine neue POST-Anfrage. Fügen Sie die Zugriffs-URL in den Abschnitt URL ein und fügen Sie am Ende '/api/graphql' hinzu. Als nächstes wählen Sie als Autorisierung 'Bearer Token' und fügen das in der dbt Cloud generierte Service Token ein. Falls Sie noch kein Token haben, gehen Sie bitte zu Einstellungen, wählen Sie "Service Token" auf der linken Seite und erzeugen Sie dort eines. 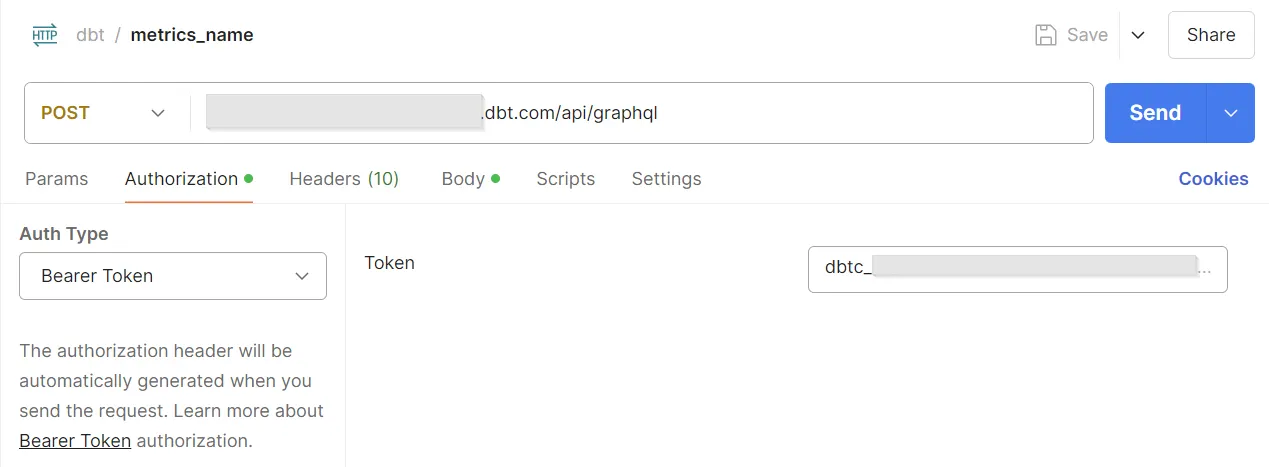
Legen Sie im Abschnitt Body den Typ 'GraphQL' fest und fügen Sie die Abfrage, die Sie ausführen möchten, im Abschnitt Query ein. Bitte sehen Sie sich die Dokumentation zur Verwendung der GraphQL API hier.
Als Beispiel fordere ich von der API die Liste aller verfügbaren Metriken an, einschließlich der Dimensionen, die mit jeder von ihnen verbunden sind. Eine Dokumentation aller möglichen Anfragen finden Sie hier. 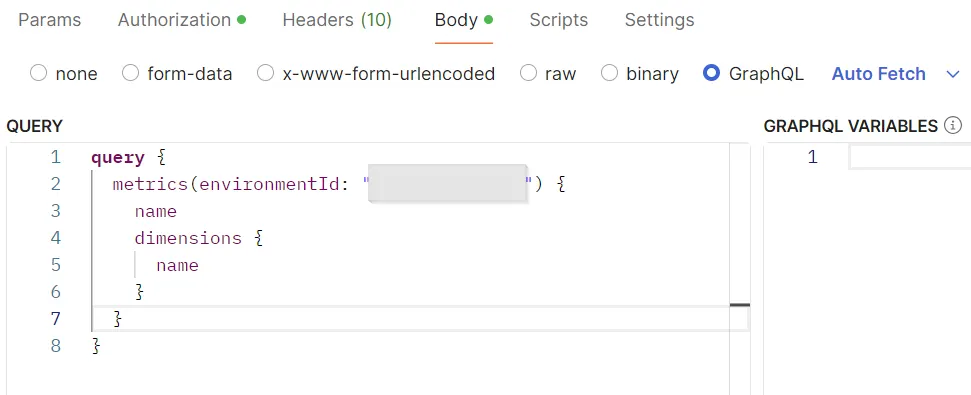
Senden Sie die Anfrage und Sie können die Ergebnisse in Postman sehen.
{
"data": {
"metrics": [
{
"name": "revenue",
"dimensions": [
{
"name": "metric_time"
},
{
"name": "order_id__order_placed_at"
},
{
"name": "order_id__order_status"
}
]
},
{
"name": "orders",
"dimensions": [
{
"name": "metric_time"
},
{
"name": "order_id__order_placed_at"
},
{
"name": "order_id__order_status"
}
]
}
]
}
}Wenn Sie eine Abfrage erstellt haben, die erfolgreich läuft, können Sie zu Python übergehen. Öffnen Sie den Abschnitt 'Code' und kopieren Sie die Abfrage, die später verwendet werden soll. 
Die allgemeine Logik bei der Kommunikation mit der GraphQL-API besteht darin, dass Sie zunächst eine Abfrage erstellen und diese an die API senden. Als Antwort erhalten Sie die QueryID und im zweiten Schritt senden Sie eine Anfrage an die API, um die Ergebnisse Ihrer QueryID abzufragen. Wir haben ein Skelett der Abfrage vorbereitet, das Sie in Python verwenden können - siehe unten.
In Schritt 1 senden Sie die erste Anfrage, um die QueryID zu erhalten, dann müssen Sie einige Zeit warten, bevor Sie die zweite Anfrage senden, und schließlich senden Sie eine weitere Anfrage, um das Ergebnis unter Verwendung der erhaltenen QueryID zu erhalten.
Öffnen Sie den Code-Editor Ihrer Wahl und kopieren Sie das Code-Skelett. Passen Sie die initial_query so an, dass sie die Abfrage Ihrer Wahl enthält, ersetzen Sie YOUR_ACCESS_TOKEN durch Ihren Service Token und passen Sie den Parameter time.sleep an die Komplexität Ihrer Anfrage an. Jetzt ist Ihr Code fertig und Sie können ihn ausführen und das Ergebnis sehen.
Beispiel-Code
import requests
import time
# Define the GraphQL API endpoint
url = "https://your-graphql-api.com/graphql"
# Step 1: Send the initial request to get the QueryID
initial_query = """
query {
initiateQuery {
queryId
}
}
"""
# Set up the request headers (if needed)
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_ACCESS_TOKEN" # Optional, if your API requires authentication
}
# Make the initial request to get the QueryID
response = requests.post(url, json={'query': initial_query}, headers=headers)
# Check if the response is successful and extract the QueryID
if response.status_code == 200:
response_json = response.json()
if "errors" in response_json:
print("Errors returned from the API during the first query:")
print(response_json["errors"])
else:
query_id = response_json["data"]["initiateQuery"]["queryId"]
print(f"QueryID obtained: {query_id}")
else:
print(f"Initial query failed with status code {response.status_code}")
print(response.text)
exit()
# Step 2: Wait for some time before sending the second request
time.sleep(10) # Adjust the delay as necessary
# Step 3: Send another request to get the result using the obtained QueryID
result_query = """
query getResult($queryId: ID!) {
queryResult(queryId: $queryId) {
status
resultData {
field1
field2
# Add more fields as per the schema
}
}
}
"""
# Define the variables for the second query
variables = {
"queryId": query_id
}
# Make the request to get the result
result_response = requests.post(url, json={'query': result_query, 'variables': variables}, headers=headers)
# Handle the response from the second query
if result_response.status_code == 200:
result_response_json = result_response.json()
if "errors" in result_response_json:
print("Errors returned from the API during the second query:")
print(result_response_json["errors"])
else:
result_data = result_response_json["data"]["queryResult"]
print("Result Status:", result_data["status"])
if result_data["status"] == "COMPLETED":
print("Query Result Data:", result_data["resultData"])
else:
print("Query is still processing or failed.")
else:
print(f"Result query failed with status code {result_response.status_code}")
print(result_response.text)Zusammenfassung
Der dbt Semantic Layer kann, wenn er richtig definiert ist, die Datenanalyse eines Unternehmens erheblich voranbringen. Er bietet einen einheitlichen und konsistenten Rahmen für die Definition von Geschäftsmetriken und -dimensionen, was für viele Unternehmen von entscheidender Bedeutung ist. Wie im Abschnitt 'Verwendung' gezeigt, kann die Einführung des dbt SL die Arbeit von Business Analysten um neue Datenquellen erweitern und die Arbeit von Data Science auf die nächste Stufe heben, was zu erheblichen Verbesserungen der Datenkonsistenz und der Gesamteffizienz führt.
Für Unternehmen, die ihre Datenanalysefähigkeiten verbessern wollen, ist die Investition in einen dbt Semantic Layer ein strategischer Schritt, der langfristig erhebliche Vorteile verspricht. Da sich die Datenlandschaft ständig weiterentwickelt, werden Tools wie dbt eine immer wichtigere Rolle bei der Gestaltung der Zukunft von Business Intelligence und Analysen spielen.
Wenn Sie mehr über die Möglichkeiten von dbt erfahren möchten oder vor anderen Herausforderungen im Zusammenhang mit Data Na AI stehen, zögern Sie nicht, uns zu kontaktieren.
Verfasst von
Przemyslaw Baran
Unsere Ideen
Weitere Blogs




Contact