Blog
Datenqualitätsregeln: Durchsetzung der Zuverlässigkeit von Datensätzen. Sicherstellung der Datenqualität mit AWS Glue DataBrew

In der heutigen datengesteuerten Welt ist die Erhaltung der Qualität und Integrität Ihrer Daten von größter Bedeutung. Die Sicherstellung, dass die Datensätze eines Unternehmens genau, konsistent und vollständig sind, ist entscheidend für eine effektive Entscheidungsfindung und betriebliche Effizienz. Unser demnächst erscheinendes eBook "Data Quality No-Code Automation with AWS Glue DataBrew: A Proof of Concept" bietet praktische Strategien und Tools, mit denen Sie eine erstklassige Datenqualität erreichen können.
In diesem Blog-Beitrag stellen wir Ihnen eine Vorschau auf unser Ebook vor, das Sie durch die Erstellung von Datenqualitätsregeln in AWS Glue DataBrew am Beispiel von HR-Datensätzen zur Verbesserung ihrer Zuverlässigkeit führt. Die Befolgung dieser Schritte stellt sicher, dass Ihre Daten sauber, konsistent und bereit für die Analyse sind.
This blog is a part of the ebook: Data Quality No-Code Automation with AWS Glue DataBrew: A Proof of Concept, you can download it here.
Regeln für die Datenqualität
In der modernen Datenarchitektur gilt das Sprichwort "Garbage in, garbage out", was die entscheidende Bedeutung der Datenqualität für die Zuverlässigkeit und Effektivität von Analyse- und Machine-Learning-Prozessen unterstreicht. Die Integration von Daten aus verschiedenen Quellen stellt eine Herausforderung dar, die sich aus dem Umfang, der Geschwindigkeit und der Wahrhaftigkeit der Daten ergibt. Während Unit-Tests von Anwendungen gang und gäbe sind, ist die Sicherstellung der Wahrhaftigkeit der eingehenden Daten ebenso wichtig, da sie die Leistung und die Ergebnisse von Anwendungen erheblich beeinflussen können.
Die Einführung von Datenqualitätsregeln in AWS Glue DataBrew geht diese Herausforderungen direkt an. DataBrew, ein visuelles Datenaufbereitungstool, das auf Analysen und maschinelles Lernen zugeschnitten ist, bietet einen robusten Rahmen für die Profilierung und Verfeinerung der Datenqualität. Im Mittelpunkt dieses Rahmens steht das Konzept eines "Regelsatzes", einer Sammlung von Regeln, die verschiedene Datenmetriken mit vordefinierten Benchmarks vergleichen.
Nutzen Sie AWS Glue DataBrew, um einen umfassenden Satz von Datenqualitätsregeln zu erstellen, die auf die spezifischen Anforderungen des Unternehmens zugeschnitten sind. Diese Regeln umfassen verschiedene Aspekte wie fehlende oder falsche Werte, Änderungen in der Datenverteilung, die sich auf ML-Modelle auswirken, fehlerhafte Aggregationen, die sich auf Geschäftsentscheidungen auswirken, und falsche Datentypen mit erheblichen Auswirkungen, insbesondere in finanziellen oder wissenschaftlichen Kontexten.
Nutzen Sie die intuitive Oberfläche von DataBrew, um Regelsätze zu erstellen und bereitzustellen, die die definierten Datenqualitätsregeln in umsetzbare Einheiten konsolidieren. Diese Regelsätze dienen als Grundlage für die Automatisierung von Datenqualitätsprüfungen und die Gewährleistung der Einhaltung vordefinierter Standards in verschiedenen Datensätzen. Wir gehen auf all diese Schritte ein und erläutern sie Schritt für Schritt in diesem ebook.
Nach der Definition der Datenqualitätsregelsätze geht es im nächsten Schritt um die Erstellung spezifischer Datenqualitätsregeln und -prüfungen, um die Integrität und Genauigkeit eines Datensatzes zu gewährleisten - worauf wir uns in diesem Blogpost konzentrieren. AWS Glue DataBrew ermöglicht die Erstellung mehrerer Regeln innerhalb eines Regelsatzes, und jede Regel kann verschiedene Prüfungen enthalten, die auf bestimmte Datenqualitätsprobleme zugeschnitten sind. Diese flexible Struktur ermöglicht es dem Benutzer, einen umfassenden Ansatz zur Validierung und Bereinigung von Daten zu verfolgen.
In dieser Phase unseres PoC konzentrieren wir uns auf die Implementierung einer Reihe präziser Regeln für die Datenqualität und die entsprechenden Überprüfungen, die den üblichen Datenproblemen entsprechen, die häufig in Personaldatensätzen auftreten. Diese Regeln sind nicht nur dazu gedacht, Fehler zu erkennen, sondern auch die Konsistenz und Zuverlässigkeit eines Datensatzes zu gewährleisten.
Überprüfung der Zeilenzahl
Regel: Stellen Sie sicher, dass die Gesamtzahl der Zeilen mit den erwarteten Zahlen übereinstimmt, um sicherzustellen, dass keine Daten fehlen oder übermäßig dupliziert sind.
Die genaue Überprüfung der Zeilenzahl in unserem Datensatz ist wichtig, um die Vollständigkeit und Zuverlässigkeit der Daten zu gewährleisten. Wenn Sie in AWS Glue DataBrew eine Regel zur Bestätigung der korrekten Gesamtzahl der Zeilen einrichten, stellen Sie sicher, dass bei der Datenverarbeitung keine Datensätze fehlen oder versehentlich dupliziert werden. Diese Überprüfung ist entscheidend für die Integrität aller nachfolgenden Analysen oder Operationen.
Um diese Prüfung einzurichten, müssen Sie die folgenden Schritte in der DataBrew-Konsole unter dem von Ihnen festgelegten Regelsatz für die Datenqualität ausführen:
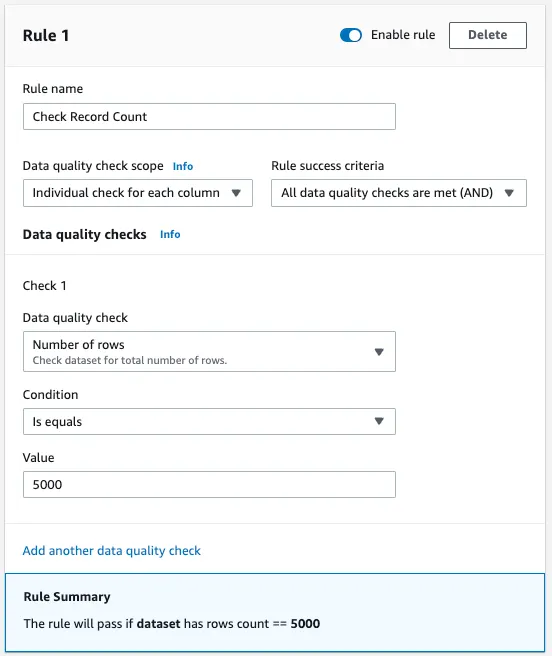
- Navigieren Sie zunächst zu dem Bereich der DataBrew-Konsole, in dem Sie Ihre Datenqualitätsregeln verwalten können. Klicken Sie auf 'Neue Regel hinzufügen', um eine Regel für die Zeilenzahl zu erstellen.
- Weisen Sie dieser Regel einen beschreibenden Namen zu, der ihren Zweck angibt, z.B. 'Check Record Count'. Diese Benennung hilft, die Funktion der Regel bei der Sicherstellung der Datengenauigkeit leicht zu erkennen.
- Setzen Sie den Bereich 'Datenqualitätsprüfung' auf 'Einzelprüfung für jede Spalte'. Die Überprüfung der Zeilenzahl scheint zwar eine Prüfung des gesamten Datensatzes zu sein, aber diese Einstellung stellt sicher, dass die Regel mit dem richtigen Umfang ausgewertet wird und korrekt ausgelöst wird.
- Wählen Sie unter 'Erfolgskriterien der Regel' die Option 'Alle Datenqualitätsprüfungen sind erfüllt (AND)'. Diese Auswahl legt fest, dass die Zeilenzahl ohne Abweichung genau mit der erwarteten Zahl übereinstimmen muss, damit die Regel erfolgreich ist.
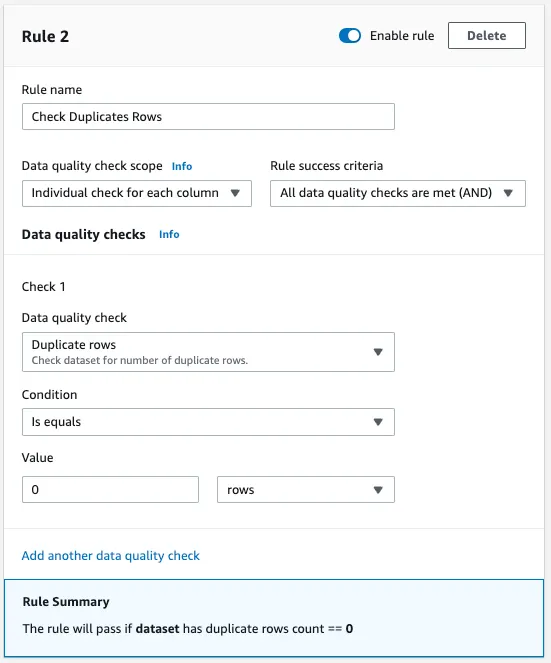
- Navigieren Sie zu der Oberfläche, auf der die vorhandenen Regeln angezeigt werden, und wählen Sie "Weitere Regel hinzufügen", um eine neue Bedingung zu definieren, die sich auf Duplikate konzentriert.
- Geben Sie der Regel einen beschreibenden Namen, der ihren Zweck widerspiegelt. Ein vorgeschlagener Name könnte 'Doppelte Zeilen prüfen' sein, der die Funktion der Regel deutlich macht.
- Setzen Sie die Option 'Umfang der Datenqualitätsprüfung' auf 'Einzelprüfung für jede Spalte'. Diese Einstellung ermöglicht es der Regel, jede Spalte unabhängig voneinander zu prüfen, um eine umfassende Abdeckung aller Datenpunkte zu gewährleisten.
- Definieren Sie die 'Erfolgskriterien der Regel', indem Sie 'Alle Datenqualitätsprüfungen sind erfüllt (UND)' auswählen. Dieses Kriterium stellt sicher, dass die Regel nur dann erfolgreich ist, wenn alle Prüfungen das Nichtvorhandensein von Duplikaten bestätigen, was die Datenintegrität stärkt.
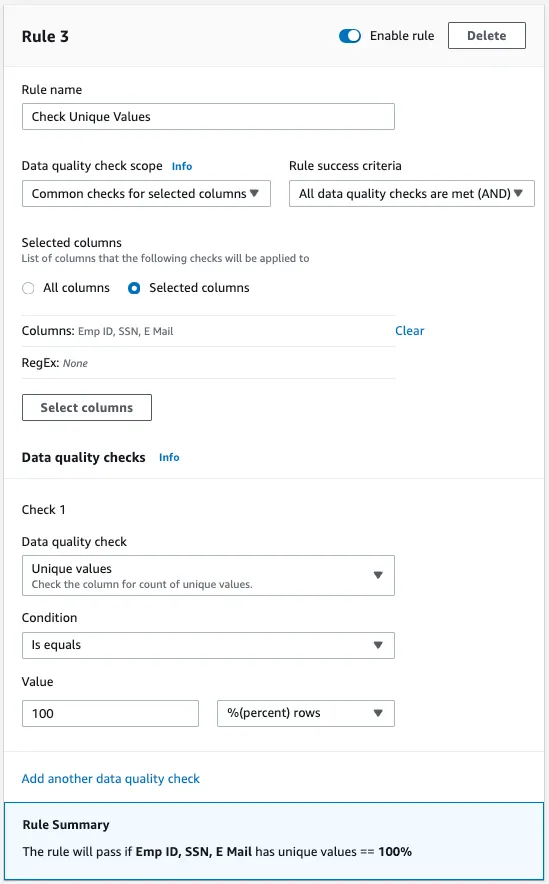
- Rufen Sie die DataBrew-Konsole auf und suchen Sie Ihr aktives Datenqualitätsregelwerk. Wählen Sie hier "Weitere Regel hinzufügen", um mit der Definition einer neuen Regel zu beginnen, die die Eindeutigkeit bestimmter Spalten überprüfen soll.
- Geben Sie dieser neuen Regel einen aussagekräftigen Namen, z.B. 'Eindeutige Werte prüfen'. Dieser Name hilft bei der Identifizierung des Zwecks der Regel innerhalb des breiteren Rahmens des Datenqualitätsmanagements.
- Wählen Sie für den Bereich "Datenqualitätsprüfung" die Option "Gemeinsame Prüfungen für ausgewählte Spalten". Mit dieser Einstellung kann sich die Regel auf die Eindeutigkeitsprüfung für mehrere bestimmte Spalten konzentrieren, anstatt auf den gesamten Datensatz oder einzelne Spalten isoliert.
- Wählen Sie 'Alle Datenqualitätsprüfungen sind erfüllt (AND)' für die 'Erfolgskriterien der Regel'. Diese Konfiguration stellt sicher, dass alle angegebenen Spalten ausnahmslos das Kriterium der Eindeutigkeit erfüllen müssen, damit die Regel erfolgreich ist.
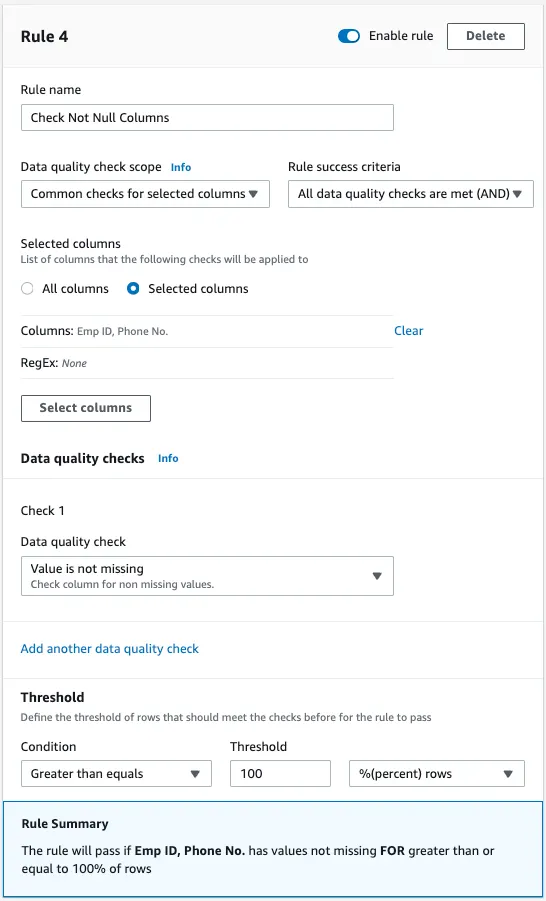
- Navigieren Sie in der DataBrew-Konsole im Kontext Ihres Projekts zu dem Bereich, in dem die Datenqualitätsregeln verwaltet werden, und klicken Sie auf "Weitere Regel hinzufügen". Damit starten Sie den Prozess zur Definition einer neuen Validierungsregel.
- Geben Sie der Regel einen aussagekräftigen Namen, der ihren Zweck widerspiegelt, z.B. 'Check Not Null Columns'. Auf diese Weise lässt sich die Funktion der Regel in späteren Verwaltungs- und Prüfungsprozessen leicht erkennen.
- Setzen Sie den Bereich 'Datenqualitätsprüfung' auf 'Gemeinsame Prüfungen für ausgewählte Spalten'. Diese Einstellung ermöglicht es der Regel, mehrere angegebene Spalten gleichzeitig unter einem einheitlichen Kriterium zu prüfen.
- Wählen Sie für die Erfolgskriterien der Regel die Option 'Alle Datenqualitätsprüfungen sind erfüllt (UND)'. Dadurch wird sichergestellt, dass die Regel nur dann erfolgreich ist, wenn alle Bedingungen für die ausgewählten Spalten erfüllt sind und keine Nullwerte vorhanden sind.
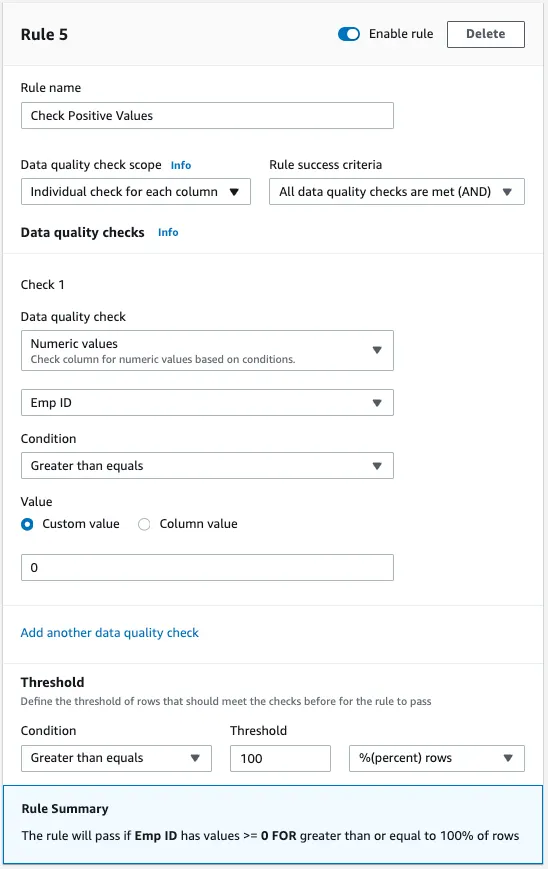
- Navigieren Sie zum Abschnitt "Regeln" in der DataBrew-Projektumgebung und wählen Sie "Weitere Regel hinzufügen", um die Erstellung einer neuen Datenqualitätsregel zu starten.
- Geben Sie dieser Regel einen eindeutigen und beschreibenden Namen, z.B. 'Positive Werte prüfen'. Diese Benennung hilft dabei, den Zweck der Regel schnell zu erkennen und sorgt für Klarheit in Datenqualitätsberichten.
- Setzen Sie den Bereich 'Datenqualitätsprüfung' auf 'Individuelle Prüfung für jede Spalte'. Dadurch kann die Regel spezifische Prüfungen auf jede Spalte unabhängig anwenden und sicherstellen, dass jedes Feld die festgelegten Kriterien erfüllt, ohne von anderen Datenspalten beeinflusst zu werden.
- Wählen Sie 'Alle Datenqualitätsprüfungen sind erfüllt (UND)' für die 'Erfolgskriterien der Regel'. Diese Einstellung bestätigt, dass jede unter dieser Regel angegebene Bedingung erfüllt sein muss, damit die Regel erfolgreich ist, so dass eine umfassende Überprüfung gewährleistet ist.
- Wählen Sie unter "Prüfung 1" die Option "Numerische Werte" aus der Liste der verfügbaren Datenqualitätsprüfungen. Diese Auswahl legt fest, dass sich die Regel auf die Überprüfung numerischer Daten in den ausgewählten Spalten konzentrieren soll.
- Für die zu überprüfenden Spalten wählen Sie zunächst 'Emp ID' aus dem Dropdown-Menü. Dieser Schritt ist entscheidend, da er die Regel anweist, die folgenden Bedingungen speziell auf das Feld Mitarbeiter-ID anzuwenden.
- Setzen Sie die Bedingung auf 'Größer als gleich'. Diese Bedingung stellt sicher, dass die Regel prüft, ob die Werte größer oder gleich dem Schwellenwert sind, den Sie als Nächstes definieren werden, oder nicht.
- Wählen Sie für den Wert 'Benutzerdefinierter Wert' und geben Sie '0' ein. Diese Konfiguration schreibt vor, dass die Mitarbeiter-IDs Null oder positiv sein müssen, wodurch negative Zahlen, die für dieses Feld nicht gültig sind, ausgeschlossen werden.
- Wählen Sie für 'Prüfung 1' die Option 'Wert fehlt nicht' aus den Optionen in den Datenqualitätsprüfungen. Mit dieser Prüfung wird sichergestellt, dass jeder Eintrag in den angegebenen Spalten Daten enthält.
- Setzen Sie die Bedingung auf 'Größer als gleich' und geben Sie als Schwellenwert '100' an. Wählen Sie '% (Prozent) Zeilen' aus dem Dropdown-Menü. Diese Konfiguration verlangt, dass 100 % der Zeilen für jede ausgewählte Spalte die Bedingung erfüllen, keine Nullwerte zu enthalten.
- Wählen Sie unter "Prüfung 1" die Option "Eindeutige Werte" aus der Liste der verfügbaren Datenqualitätsprüfungen. Mit dieser Option wird geprüft, ob jeder Eintrag in den angegebenen Spalten eindeutig ist.
- Setzen Sie die Bedingung auf 'Ist gleich' und geben Sie den Wert '100' ein. Wählen Sie dann '% (Prozent) Zeilen' aus dem Dropdown-Menü. Diese Einstellung legt fest, dass 100 % der Zeilen für jede ausgewählte Spalte eindeutige Werte enthalten, wodurch die absolute Eindeutigkeit, die für diese Bezeichner erforderlich ist, bestätigt wird.
- Unter der ersten Prüfung mit der Bezeichnung "Prüfung 1" wählen Sie "Doppelte Zeilen" aus der Liste der verfügbaren Datenqualitätsprüfungen. Diese Auswahl zielt speziell auf doppelte Datensätze innerhalb des Datensatzes ab.
- Für die Bedingung zur Bewertung der Prüfung verwenden Sie 'Ist gleich'. Diese Bedingung wird verwendet, um das Ergebnis der Dublettenprüfung mit einem vordefinierten Wert zu vergleichen.
- Geben Sie den Wert '0' an und wählen Sie 'Zeilen' aus dem Dropdown-Menü. Diese Einstellung bedeutet, dass die Regel nur dann erfolgreich ist, wenn keine doppelten Zeilen gefunden werden, was mit unseren Kriterien für die Datenqualität übereinstimmt.
- Wählen Sie innerhalb der Regel die Option "Anzahl der Zeilen" aus den Optionen unter "Datenqualitätsprüfungen". Diese spezielle Prüfung konzentriert sich direkt auf die Quantifizierung der Zeilen des Datensatzes.
- Wählen Sie für die Bedingung 'Ist gleich', um die genaue Erwartung für die Zeilenzahl festzulegen.
- Geben Sie den Wert '5000' als die genaue Anzahl der erwarteten Zeilen im Datensatz ein. Diese Zahl sollte die erwartete Zeilenzahl widerspiegeln, die sich aus den Parametern für die Datenerfassung oder der anfänglichen Schätzung der Datensatzgröße ergibt.
Durch die Implementierung dieser Regel schaffen Sie einen robusten Überprüfungsprozess für die Zeilenzählung, die eine entscheidende Rolle bei der Wahrung der Integrität der Daten spielt. Sie stellt sicher, dass der in AWS Glue DataBrew geladene Datensatz vollständig ist und dass keine Datenverluste oder Duplizierungsprobleme die Qualität Ihrer Informationen beeinträchtigen. Diese Regel ist ein wesentlicher Bestandteil unseres Datenqualitätsrahmens, der eine zuverlässige datengestützte Entscheidungsfindung unterstützt.
Prüfung auf doppelte Zeilen
Regel: Identifizieren und entfernen Sie alle doppelten Datensätze, um die Einzigartigkeit des Datensatzes zu erhalten.
Die Sicherstellung der Einzigartigkeit der Daten in unserem Datensatz ist entscheidend für die Genauigkeit und Zuverlässigkeit der daraus abgeleiteten Analysen. Um doppelte Zeilen in unserem Datensatz effektiv zu identifizieren und zu eliminieren, verwenden wir einen strukturierten Ansatz in AWS Glue DataBrew. Dieser Prozess beinhaltet die Einrichtung einer speziellen Regel zur Erkennung von Duplikaten. Greifen Sie zunächst in der DataBrew-Konsole auf Ihr zuvor definiertes Datenqualitätsregelwerk zu. Von hier aus fügen Sie eine neue Regel hinzu, die auf doppelte Einträge zugeschnitten ist.
Durch die sorgfältige Konfiguration dieser Regel stellen wir sicher, dass unser Datensatz gründlich nach doppelten Einträgen durchsucht wird. Alle gefundenen Einträge werden zur Überprüfung oder zur automatischen Bearbeitung markiert, je nach den allgemeineren Data Governance-Strategien, die wir anwenden. Die Umsetzung dieser Regel ist ein wichtiger Schritt, um sicherzustellen, dass unsere Daten unberührt bleiben und dass alle durchgeführten Analysen auf genauen und zuverlässigen Informationen beruhen.
Einzigartigkeit von Schlüsselidentifikatoren
Regel: Stellen Sie sicher, dass jede Mitarbeiter-ID, E-Mail-Adresse und SSN in allen Datensätzen eindeutig ist, um Überschneidungen zu vermeiden.
Die Sicherstellung der Einzigartigkeit der Daten in unserem Datensatz ist entscheidend für die Genauigkeit und Zuverlässigkeit der daraus abgeleiteten Analysen. Um doppelte Zeilen in unserem Datensatz effektiv zu identifizieren und zu eliminieren, verwenden wir einen strukturierten Ansatz in AWS Glue DataBrew. Dieser Prozess beinhaltet die Einrichtung einer speziellen Regel zur Erkennung von Duplikaten. Greifen Sie zunächst in der DataBrew-Konsole auf Ihr zuvor definiertes Datenqualitätsregelwerk zu. Von hier aus fügen Sie eine neue Regel hinzu, die auf doppelte Einträge zugeschnitten ist.
Durch die sorgfältige Konfiguration dieser Regel stellen Sie sicher, dass wichtige persönliche und berufliche Identifikatoren wie Mitarbeiter-ID, E-Mail und SSN eindeutig einzelnen Datensätzen zugeordnet werden, wodurch die Zuverlässigkeit und Genauigkeit Ihres Datensatzes erhöht wird. Dieser Schritt ist entscheidend für die Qualität Ihrer Daten und stellt sicher, dass alle Analysen, die aus diesem Datensatz abgeleitet werden, auf korrekten und nicht-duplizierenden Informationen basieren.
Nicht-null-kritische Felder
Regel: Mitarbeiter-ID und Telefonnummern dürfen keine Nullwerte enthalten, um vollständige Daten für wichtige Kontaktinformationen zu gewährleisten.
Um die Integrität und Vollständigkeit unseres Personaldatensatzes zu gewährleisten, müssen wir sicherstellen, dass bestimmte kritische Felder, insbesondere Mitarbeiter-IDs und Telefonnummern, immer ausgefüllt sind. Ein ungültiger Wert in diesen Feldern könnte auf eine unvollständige Datenerfassung oder auf Verarbeitungsfehler hinweisen, was zu Ungenauigkeiten in der Mitarbeiterverwaltung und -kommunikation führen könnte.
Durch die Konfiguration dieser Regel stellen Sie sicher, dass keine Datensätze im Datensatz in den Feldern Mitarbeiter-ID und Telefonnummer ungültige Werte aufweisen, was die Vollständigkeit und Nutzbarkeit Ihrer HR-Daten erhöht. Dieser Schritt ist von entscheidender Bedeutung, um qualitativ hochwertige, verwertbare Daten zu erhalten, die eine effektive Personalverwaltung und operative Prozesse unterstützen.
Validierung der numerischen Daten
Regel: Mitarbeiter-IDs sollten ganze Zahlen sein und das Feld Alter sollte keine negativen Werte enthalten, um die logische Datenintegrität zu wahren.
Durch die Implementierung dieser Regel stellen Sie sicher, dass kritische numerische Felder wie die Mitarbeiter-ID und das Alter keine negativen Werte enthalten, wodurch die logische Konsistenz und Zuverlässigkeit Ihres Datensatzes gewahrt bleibt. Dieser proaktive Ansatz bei der Datenvalidierung ist ein wesentlicher Bestandteil der Aufrechterhaltung hoher Datenqualitätsstandards, die für genaue und zuverlässige HR-Analysen und Operationen erforderlich sind.
There are even more data quality rules to set, but we extend this topic further in the ebook: “Data Quality No-Code Automation with AWS Glue DataBrew: A Proof of Concept,” where we present the entire data quality process. We demonstrate profile job certification, data quality validation and how to conduct cleaning the dataset.
This ebook is available now, offering you the insights and tools necessary to maximize the potential of your datasets and more. Ensure your data is accurate, reliable and ready for impactful analysis. Download the data quality ebook here.
Verfasst von
Sylwia Kołpuć
Data & AI Marketing Manager
Unsere Ideen
Weitere Blogs




Contact