
In einem früheren Beitrag über die Gestaltung von Daten- und KI-Organisationen habe ich die Gestaltungsprinzipien aus dem Buch Team Topologies vorgestellt und diese Prinzipien im Hinblick auf einige wichtige Aspekte einer Daten- und KI-Organisation diskutiert:
- Lebenszyklus von KI-Lösungen und Komplexität der Anwendungsfälle
- Daten-as-a-Service
- Daten & KI Reifegrad
- Begrenzte Anzahl von Datenexperten
In diesem Blog werde ich einen Blick auf drei Unternehmen werfen, die sich in Größe und KI-Reifegrad unterscheiden, und untersuchen, wie das organisatorische Design aussehen könnte. Für das erste Unternehmen werden wir 3 verschiedene Szenarien betrachten, das zweite Unternehmen nur eines und das dritte Unternehmen wird Ihnen sehr vertraut sein. Wir bewerten die Entwürfe anhand der Designprinzipien, die wir im vorherigen Blog besprochen haben.
Die Schlussfolgerung des vorangegangenen Blogs war, dass die vier grundlegenden Teamtopologien, die drei Arten der Teaminteraktion und die Designprinzipien aus dem Buch uns sowohl die verbale als auch die visuelle Sprache (siehe Abbildung 1) geben, um Organisationsdesign effektiver und spezifischer zu diskutieren. Es gibt nicht nur ein einziges festes Organisationsdesign, das auf jede Organisation passt, und es gibt auch nicht nur ein einziges festes Organisationsdesign, das auf eine einzige Organisation im Laufe der Zeit passt.
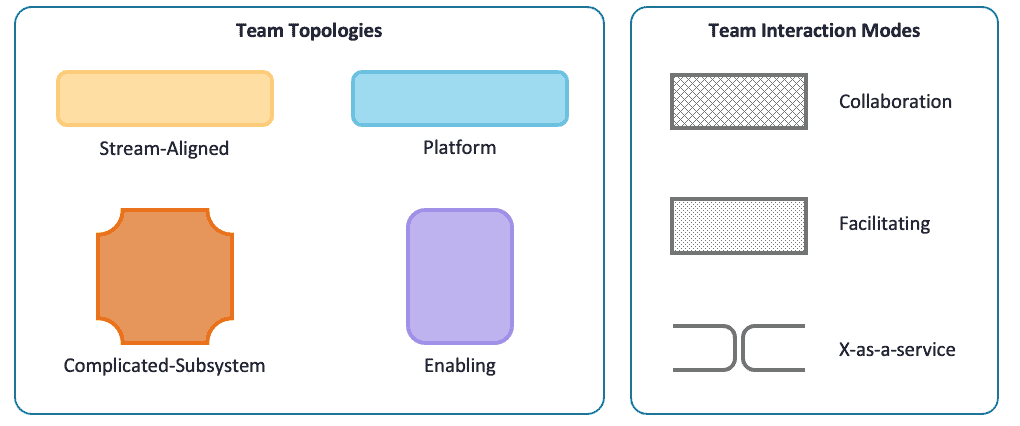 Abbildung 1: Legende der Team-Topologien
Abbildung 1: Legende der Team-Topologien
Fall 1: Mittelständisches Unternehmen, grundlegende KI-Erfahrung
Dieses Unternehmen arbeitet schon seit einigen Jahren an KI-Anwendungsfällen. Es begann mit Marketinganalysten, die an einem innovativen Projekt über die nächstbesten Aktionsmodelle im Verkaufstrichter arbeiteten, unterstützt von externen Datenwissenschaftlern. Datenanalysten aus dem BI-Team der IT-Abteilung halfen bei der Beschaffung der erforderlichen Daten. Die Ergebnisse waren vielversprechend und mit Unterstützung der IT-Abteilung wurde eine vorübergehende Lösung gefunden, um das Modell in der Produktion einzusetzen. Die Marketingabteilung experimentiert weiter und hat einen Junior-Datenwissenschaftler eingestellt. Die Abteilung Supply Chain Operations hat ebenfalls einen Junior Data Scientist eingestellt, um anhand historischer Verkaufs- und Betriebsdaten die Prognosen für das Transportvolumen der nächsten Woche zu verbessern. Seitdem haben die Möglichkeiten der KI im gesamten Unternehmen viel Aufmerksamkeit erregt und es gibt viele Ideen für potenzielle KI-Anwendungsfälle. Einige dieser Anwendungsfälle können mit Hilfe von externen Daten und KI-Experten in Gang gesetzt werden. Die Geschäftsleitung ist sich jedoch bewusst, dass KI nicht mehr wegzudenken ist und dass eine eigene KI-Fähigkeit auf lange Sicht die optimalere Lösung ist, sowohl aus Sicht der Kosten als auch der internen Wissensentwicklung. Deshalb hat die Geschäftsleitung beschlossen, Daten und KI als eine Schlüsselkompetenz in ihre Strategie für die nächsten Jahre aufzunehmen.
Szenario 1.1: Dezentrale Datenexperten
Die Geschäftsbereiche beginnen damit, Datenexperten einzustellen, in Übereinstimmung mit den strategischen Schlüsselkompetenzen, die vor kurzem für Daten und KI definiert wurden. Für einige Geschäftsbereiche ist die Analytik noch sehr neu, sie haben andere, dringendere Datenprobleme, so dass sie beschließen, Datenanalysten einzustellen, um den Rest der Abteilung mit den benötigten Erkenntnissen zu unterstützen. Die Marketingabteilung stellt einen Datenanalysten für das Next Best Action Team ein. Nach einiger Zeit sind alle Geschäftsbereiche froh über die neuen Datenexperten in ihren Teams. Die Analysten sind sehr damit beschäftigt, den Kollegen bei allen Arten von Datenanfragen zu helfen, und manchmal können sie sogar neue Wege der Datennutzung vorstellen und innovative Erkenntnisse generieren. Die Ingenieure haben einige Fortschritte gemacht, aber aufgrund vieler dringender Anfragen von Analysten und Wissenschaftlern werden viele Workarounds implementiert. Anfangs haben die Datenwissenschaftler an spannenden Experimenten gearbeitet, aber den Mitgliedern des Produktteams fehlen die Zeit und das Wissen, um das Potenzial der KI wirklich zu erschließen, und außerdem haben sie andere Prioritäten bei der Weiterentwicklung der Online-Dienste. Die Datenwissenschaftler wenden ihre Zeit und Aufmerksamkeit darauf, Kollegen außerhalb des Produktteams bei allen möglichen datenbezogenen Fragen zu helfen.
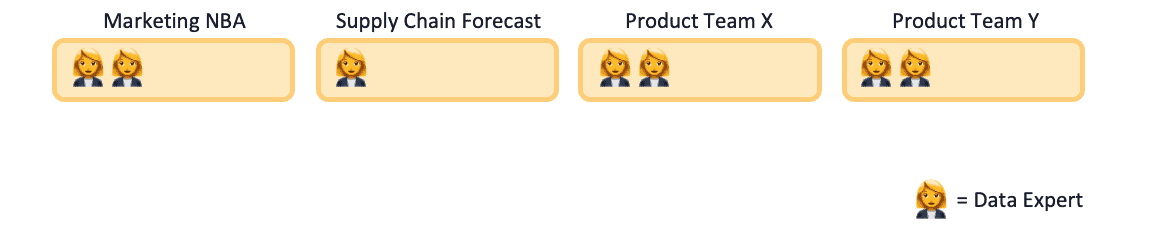 Abbildung 2: Szenario 1.1
Abbildung 2: Szenario 1.1
Dies ist definitiv Conways Gesetz in Aktion: unkoordinierte Bemühungen mit verstreuten und recht jungen Datenexperten, die an ihren eigenen Projekten arbeiten, führen zu punktuellen Lösungen und einem Flickenteppich aus pragmatischen Implementierungsansätzen. Es gibt kein Plattformteam, das die Implementierung von Daten- und maschinellen Lernpipelines gemäß den besten technischen Verfahren anleitet und erleichtert. In der Datenwelt tauchen ständig neue Tools und Technologien auf, und ohne eine angemessene Anleitung durch die Führungsebene könnten die Datenexperten versucht sein, diese neuen Tools regelmäßig einzuführen, was den technischen Flickenteppich weiter vergrößert.
Ein weiterer Effekt der verstreuten Datenexperten ist das Fehlen einer gemeinsamen Wissensentwicklung. Es gibt keine Gemeinschaft oder kein Team, das dies erleichtert, wie es ein Enabling Team tun würde.
Da das Unternehmen relativ klein ist, werden die wenigen Produktteams ein recht breites Spektrum an Komponenten und Diensten haben, für die sie verantwortlich sind. Der Daten- und/oder KI-Teil innerhalb dieses Bereichs ist möglicherweise klein. Dies führt zu einer Menge Overhead und Kommunikation innerhalb des Teams, die nichts mit der Arbeit des Datenwissenschaftlers zu tun hat.
Starke Kommunikationslinien, die für die Wertschöpfung erforderlich sind, sollten sich in der Teamstruktur widerspiegeln und auf die Autonomie des Teams abzielen. Man könnte argumentieren, dass dieses Prinzip des Kommunikationsdesigns für dieses Produktteam in umgekehrter Weise gilt. Der Datenwissenschaftler wird in viele Kommunikationsvorgänge (z.B. Verfeinerungsbesprechungen) einbezogen, wobei er nur einen begrenzten Beitrag zur Arbeit des Datenwissenschaftlers leistet bzw. mit ihm in Verbindung steht. Die Zeit, die für die Wertschöpfung zur Verfügung steht, wird dadurch reduziert. Dies führt zu der Idee, dass dieses Team möglicherweise nicht der optimale Ort für den Datenwissenschaftler ist. Je weiter der KI-Anwendungsfall in den Lebenszyklus der KI-Lösung vordringt und je geringer der Kommunikationsbedarf mit dem Rest des Teams ist, desto mehr wird dieses Argument an Bedeutung gewinnen.
Szenario 1.2: Produktteam Daten & KI
Neben der Identifizierung von Daten & KI als strategische Kompetenz argumentiert der CIO in diesem Szenario, dass diese Kompetenz zentral entwickelt werden sollte. Auf diese Weise kann bei der Einstellung ein Gleichgewicht zwischen Dienstalter und Fachwissen im Team der Datenexperten hergestellt werden. Es gibt ein Budget für eine Cloud-Plattform und für die Einstellung von 8 zusätzlichen Mitarbeitern für Daten und KI. Der CIO beschließt, ein Data & Analytics-Produktteam innerhalb der IT-Abteilung zu bilden, und die bestehenden Datenwissenschaftler aus dem Marketing und der Lieferkette werden dem neuen Team beitreten. Die Einstellung und die Eingewöhnung in das neue Team nehmen einige Zeit in Anspruch, aber mit Hilfe einiger externer Berater kommt das Team innerhalb eines halben Jahres in Schwung. Die Dateningenieure arbeiten eng mit dem IT-BI-Team zusammen, um neue Datenquellen für BI und KI vorzubereiten. Mit dem IT-Cloud-Team bauen sie eine Cloud-Daten/BI/AI-Plattform auf. Analysten und Datenwissenschaftler arbeiten gemeinsam mit verschiedenen Geschäftsbereichen und Produktteams an verschiedenen Experimenten, Projekten und Ad-hoc-Anfragen. Alle 2 Wochen findet ein Sprint-Planungs- und Verfeinerungsmeeting für das gesamte Data & Analytics Produktteam statt, das fast einen ganzen Tag dauert. Die Anzahl der gleichzeitigen Aktivitäten ist beeindruckend und wird, wenn man sich das Backlog des Teams ansieht, noch weiter steigen. Der PO des Teams hat einen Vollzeitjob, um alle Interessengruppen im gesamten Unternehmen zu managen. Der PO hat ständig damit zu kämpfen, die Erwartungen in Bezug auf Machbarkeit und Kapazität herunterzuschrauben und Prioritäten zu setzen. Erschwerend kommt hinzu, dass Datenanalysten und Datenwissenschaftler im gesamten Unternehmen für ihre umfassenden Datenkenntnisse bekannt sind und Kollegen Wege finden, die Zeit der Datenexperten zu nutzen, um einige Ad-hoc-Aufgaben zu erledigen und dabei den PO zu umgehen.
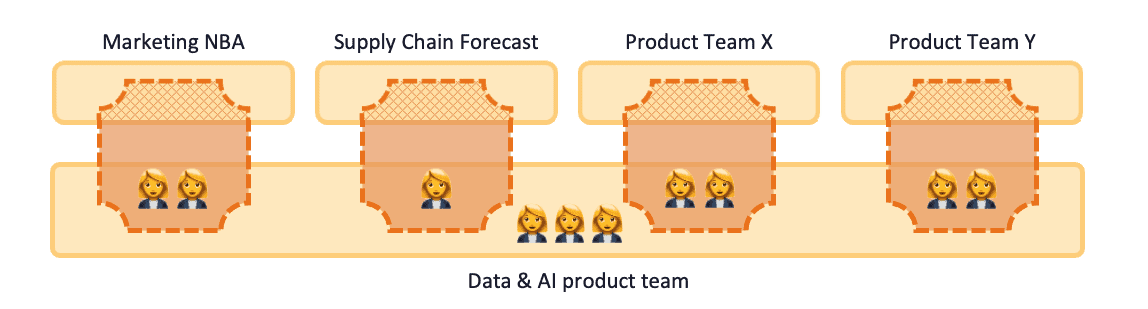 Abbildung 3: Szenario 1.2
Abbildung 3: Szenario 1.2
Datenanalysten/Wissenschaftler profitieren von der Zusammenarbeit mit der Datentechnik beim Aufbau einer gemeinsamen Plattform. Nach der anfänglichen Lernkurve werden sie in der Lage sein, mit Hilfe von Best Practices und den verfügbaren Vorlagen für Daten- und maschinelle Lernpipelines viel schneller zu experimentieren und zu entwickeln. Dies führt zu einer harmonisierten Nutzung einer einzigen Datenplattform. Es liegt auf der Hand, dass die Architektur des Datensystems davon profitiert, dass die Datenexperten in einem Team arbeiten, wie es das Conway'sche Gesetz vorhersagt.
Es ist viel Kommunikation zwischen den Datenexperten und den Geschäfts-/Produktteams erforderlich. Der Interaktionsmodus zwischen dem Daten- und KI-Produktteam und dem Rest der Organisation kann als umfassend und viel zu viel bezeichnet werden, was zu einer sehr begrenzten Autonomie des Daten- und KI-Produktteams führt. Ein völlig autonomes Daten- und KI-Produktteam wäre in dieser Konstellation wirklich seltsam, denn man kann nicht erwarten, dass dieses Team geschäftsrelevante Lösungen entwickelt, ohne überhaupt mit dem Unternehmen zu kommunizieren.
In der Praxis erweist es sich als sehr schwierig, die Akzeptanz dieser Lösungen durch die Unternehmensteams zu gewährleisten, da während des Entwicklungsprozesses eine große Distanz zwischen den Datenwissenschaftlern und den Interessengruppen des Unternehmens besteht. Und die Zeit, die die ohnehin knappen Ressourcen für KI-Lösungen aufwenden, die nicht genutzt werden, weil sie den tatsächlichen geschäftlichen Anforderungen nicht gerecht werden, ist nicht sehr gut angelegt.
Zusätzlich zu der "zwischen den Teams"-Kommunikation hat das Team regelmäßige Besprechungen, wie jedes Produktteam. Während das Team an vielen verschiedenen Projekten und Aufgaben arbeitet, arbeitet jeder Datenexperte nur an einer Handvoll davon. Während der Planungs- und Verfeinerungssitzungen wird die meiste Zeit auf die Projekte und Aufgaben der anderen Teammitglieder verwendet. Dies ermöglicht es, das Wissen und die Erfahrung aller in die Arbeit des Teams einfließen zu lassen, aber es gibt effektivere Wege, um diese Art der Kommunikation zu erleichtern. Die Zusammensetzung des Data & AI Produktteams, das an vielen Aufgaben, Projekten und Geschäftsbereichen arbeitet, führt wiederum zu einer hohen Kommunikationslast für jeden Datenexperten. Und dieses Mal hat es nichts mit der Arbeit der Experten selbst zu tun. Wie in Szenario 1.1 gilt auch hier das umgekehrte Prinzip des Kommunikationsdesigns, was darauf hindeutet, dass das aktuelle Teamdesign aus Sicht der "teaminternen" Kommunikation suboptimal ist.
Die hohe interne und externe Kommunikationsbelastung, unter der sowohl der PO als Einzelner als auch das Team als Ganzes zu leiden haben, macht dieses Teamdesign zu einer Herausforderung für das Erreichen einer hohen Teamproduktivität. Auch wenn diese Produktivität durch die gemeinsame Arbeit auf einer Plattform verbessert wird.
Szenario 1.3: Daten- und KI-Expertenpool
Dieses Szenario beginnt ähnlich wie das vorherige, nur dass das Team von Daten- und KI-Experten nicht als autonomes Produktteam mit eigenen Sprint-Planungstreffen usw. arbeiten soll. Stattdessen wird ein "Home Base"-Team gebildet, von dem aus Datenexperten für einen bestimmten Zeitraum bestimmten Projekten oder Produktteams zugewiesen werden. Diese Zuteilung erfolgt in Teilzeit, da ein bestimmter Prozentsatz der Zeit (10 % bis 20 %) der Datenanalysten und -wissenschaftler für die gemeinsame Entwicklung von Wissen, Fähigkeiten und Infrastruktur, an der das Team arbeiten wird, reserviert wird. Die Dateningenieure verbringen bis zu 50 % ihrer Zeit im eigenen Team, um Best Practices, Vorlagen usw. für Daten- und maschinelle Lernpipelines einzuführen und mit dem BI-Team zusammenzuarbeiten, um das On-Premise-Data-Warehouse in die Cloud zu migrieren und die Daten sowohl für BI- als auch für KI-Anwendungen verfügbar zu machen. Anstatt das gesamte Budget für Dateningenieure, Analysten und Wissenschaftler auszugeben, werden zwei Analytik-Übersetzer (AT) eingestellt. Die ATs stehen in Kontakt mit den Geschäftsteams, sammeln alle Ideen und Anfragen rund um Daten und KI, besprechen die Prioritäten mit dem Management und planen die Zuweisung von Datenexpertise an Projekte und Produktteams.
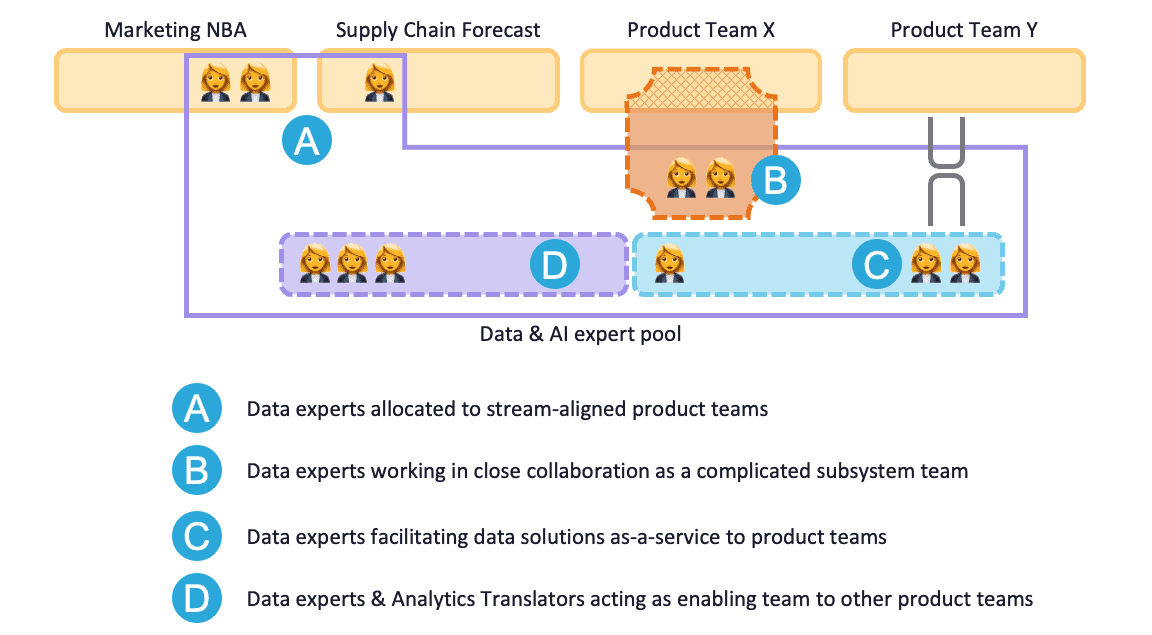 Abbildung 4: Szenario 1.3
Abbildung 4: Szenario 1.3
Dieses Szenario sieht eine Reihe von Verbesserungen gegenüber dem vorherigen vor, die alle mit der Kommunikation sowohl innerhalb des Teams als auch mit anderen Teams zu tun haben. Bei der Kommunikation mit anderen Teams geht es um die Arbeit an spezifischen Anwendungsfällen, bei der Kommunikation innerhalb des Teams geht es um die Entwicklung der Plattform und des Wissens, um die Entwicklung von Daten- und KI-Lösungen zu erleichtern. In ihrer vorübergehenden Zeit im Geschäfts- oder Produktteam sind die Datenexperten Teil eines auf den Stream ausgerichteten Teams, während ihrer Zeit im eigenen Data & AI-Team sind sie Teil eines Plattform-/Enabling-Teams.
Sie arbeiten in dem auf den Stream ausgerichteten Team, solange es relevant ist, und ziehen vorzugsweise für mehrere Tage pro Woche in die Nähe dieses Teams, um die Kommunikation zu erleichtern (A in Abbildung 4). Die Planung und Verfeinerung der Arbeit erfolgt innerhalb des Geschäfts- oder Produktteams und nicht innerhalb des allgemeineren, unterstützenden Daten- und KI-Teams. Wenn die Arbeit im Lebenszyklus der KI-Lösung fortschreitet und der Kommunikationsbedarf abnimmt, kann der Interaktionsmodus auf Zusammenarbeit umgestellt werden. Die Datenexperten, die an der KI-Lösung arbeiten, können ein kompliziertes Subsystemteam für das auf den Strom ausgerichtete Geschäftsproduktteam bilden (B in Abbildung 4). Später, wenn die Lösung produktionsreif ist, kann dies in die Topologie des Plattformteams und den As-a-Service-Interaktionsmodus (C in Abbildung 4) übergehen.
Der Umfang der benötigten Kommunikation dient als Indikator für die "Verkleinerung der Topologie" vom Stream-ausgerichteten Team auf ein kompliziertes Subsystemteam und ein Plattformteam zu einem späteren Zeitpunkt, um z.B. unnötige Overhead-Kommunikation im Stream-ausgerichteten Produktteam zu vermeiden, das eine KI-Lösung benötigt.
Wie bereits erwähnt, beziehen sich die Aktivitäten des Teams Daten & KI auf die Entwicklung von Plattformen und Wissen. Wissensentwicklung für die Datenexperten selbst, aber auch für den Rest der Organisation, um die Daten- und KI-Kenntnisse und das Bewusstsein aller zu verbessern.
Es gibt nicht nur eine einzige Team-Topologie, in der die Datenexperten arbeiten. Vielmehr wechselt der einzelne Datenexperte im Laufe der Zeit die Topologie und den Interaktionsmodus, um sich an die für die jeweilige Aufgabe erforderliche Kommunikation anzupassen. Anstatt dies als verwirrend zu empfinden, macht die spezifische Kennzeichnung der optimalen Teamtopologie und des Interaktionsmodus pro Aufgabe die erforderliche Kommunikation, Dynamik und Herausforderungen transparent. Nur so kann die kognitive Belastung des Teams und seiner Mitglieder richtig gesteuert werden.
Der Analytik-Übersetzer (AT) ist für den Großteil der Kommunikation verantwortlich und überbrückt die Kluft in Bezug auf Wissen, Fähigkeiten und Prioritäten zwischen den Teams für komplizierte KI-Subsysteme und den auf den Strom ausgerichteten Geschäfts-/Produktteams. Darüber hinaus arbeitet der AT daran, die Datenkompetenz im Unternehmen zu erhöhen, indem er die Geschäftsteams in grundlegende Analysen und Datenoperationen einführt und so die Ad-hoc-Arbeitslast der Datenexperten reduziert. Auf diese Weise fungiert das AT als Befähigungsteam (D in Abbildung 4) für einfachere datenbezogene Aufgaben in Richtung Unternehmen (zusammen mit anderen, derzeit nicht zugewiesenen Datenexperten), als PO für Aufgaben mit mittlerem Schwierigkeitsgrad, die in den Teams für komplizierte Subsysteme erledigt werden, und als (Vermittler zum) Ressourcenmanager für die größeren Projekte, bei denen die Datenexperten den auf den Strom ausgerichteten Teams zugewiesen werden.
Fall 2: Großes Unternehmen, fortgeschrittene KI-Erfahrung
Dieses Unternehmen ist im Vergleich zu dem aus Fall 1 viel größer. Allerdings war die Struktur früher wie in Szenario 1.3, was gut zum Umfang der damaligen Daten- und KI-Aktivitäten passte. Mit der wachsenden Zahl von kundenorientierten KI-Anwendungen und Datenexperten entstanden in mehreren Geschäftsteams dedizierte KI-Ressourcen. Das zentrale Daten- und KI-Team existiert immer noch und bietet KI-Dienste wie früher an, aber heutzutage hauptsächlich für Abteilungen und Teams ohne dedizierte Datenexperten oder z.B. zur vorübergehenden Unterstützung anderer Datenwissenschaftler bei großen Projekten. Die Dateningenieure sind in ein Data-Engineering-Team umgezogen, das sich sowohl auf Daten als auch auf Cloud-Engineering für BI- und KI-Zwecke konzentriert. Das Team stellt fortgeschrittenen Analysten und Data Scientists Vorlagen für Datenvorbereitungspipelines und fortgeschrittene Cloud-Workspaces als Service zur Verfügung. Mehrere KI-Anwendungen haben den gesamten Lebenszyklus bis zur Produktion durchlaufen, und es wurde ein ML-Engineering-Team gebildet, das neue Tools und Technologien zu diesem Thema erforscht, Best Practices für die Ausführung und Überwachung von Modellen in der Produktion einführt und die Produktteams mit Schulungen und z.B. Code-Reviews unterstützt. Die Datenanalysten und Datenwissenschaftler haben eine Analytics Community ins Leben gerufen, in der sie sich treffen, um ihre neuesten Erfolge zu teilen und an der Entwicklung von Wissen zu arbeiten. Obwohl das aktuelle Design sowohl aus organisatorischer Sicht als auch aus Sicht der IT-Architektur solide ist und recht gut funktioniert, sind weitere Verbesserungen geplant. Die Data Governance der gesamten IT-Betriebslandschaft ist ausgereift und die Produktteams werden bald in der Lage sein, die Datenaufbereitung, -dokumentation und -überwachung für BI- und KI-Zwecke zu übernehmen.
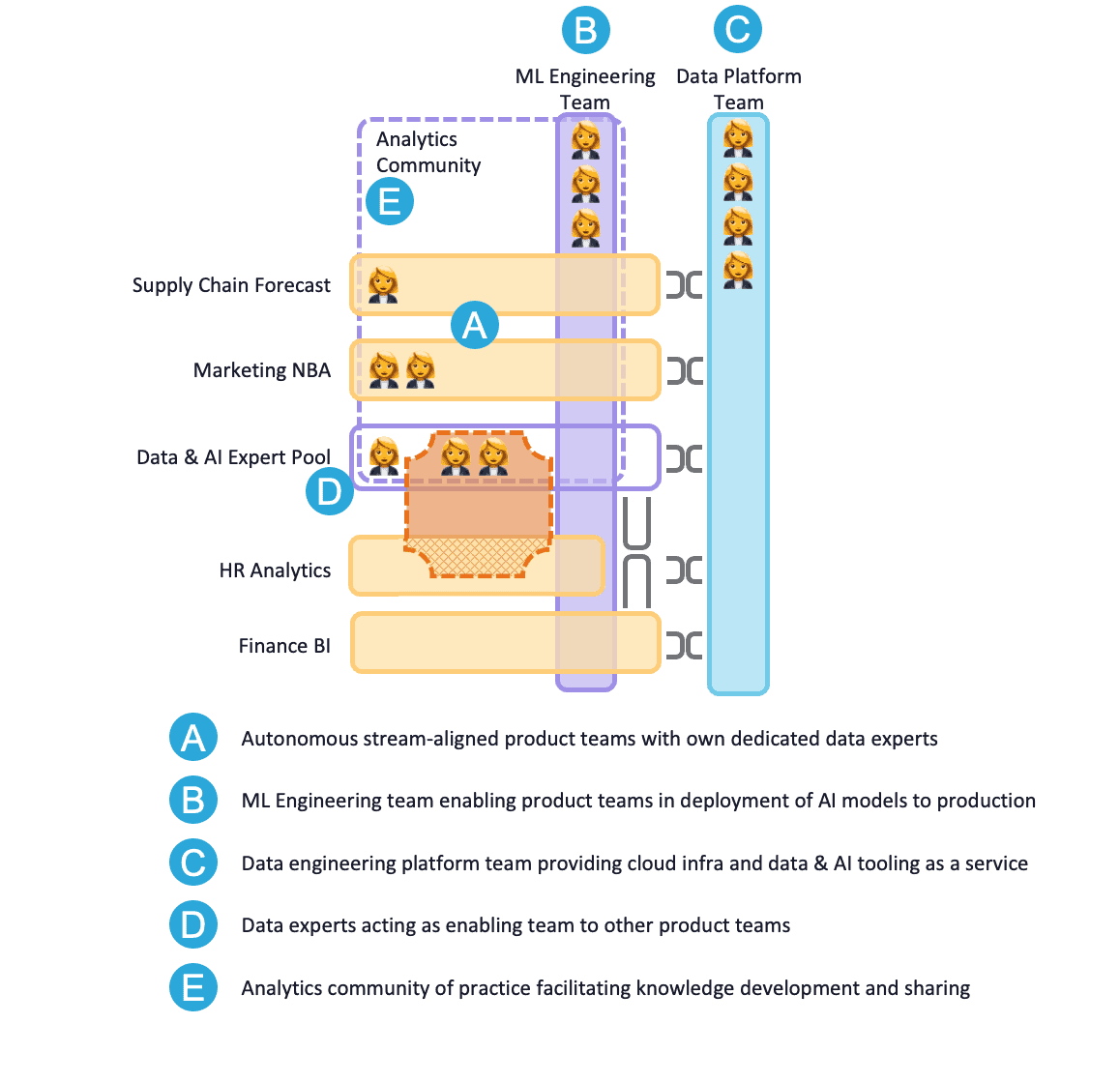 Abbildung 5: Szenario 2
Abbildung 5: Szenario 2
Nun, der Hauptzweck dieses Szenarios ist natürlich, zu skizzieren, wie eine große KI-Organisation aussehen könnte. Der Hauptunterschied zu früheren Szenarien besteht darin, dass die Produktverantwortlichen aufgrund der gestiegenen Nachfrage und des höheren Budgets für KI-Lösungen rechtfertigen können, das ganze Jahr über Datenexperten in ihren Teams zu beschäftigen.
Der größte Teil der Daten- und KI-Arbeit wird autonom in den Produktteams des Unternehmens (A in Abbildung 5) erledigt, mit Unterstützung des ML-Engineering-Enabling-Teams (B in Abbildung 5) und des Data-Engineering-Plattformteams (C in Abbildung 5). Ein Schlüsselfaktor für den Erfolg von Produktteams bei der Entwicklung von KI-Lösungen innerhalb des Teams ist ein PO, der die Besonderheiten des Lebenszyklus von KI-Lösungen versteht, von der Idee bis zur Produktion. Das Analytics Translator Training ist für POs zu diesem Zweck gut geeignet.
Die kognitive Belastung der auf Streams ausgerichteten Teams mit Datenexperten und dem zentralen Data & AI-Expertenpool (D in Abbildung 5) wird durch das Data-Engineering-Plattformteam und das ML-Engineering-Enabling-Team reduziert. Auf diese Weise stehen die Tools und Technologien während der Entwicklung und Produktion als Service des Plattformteams zur Verfügung, und das Wissen rund um die Modellbereitstellung für die Produktion kann vom Enabling-Team bezogen werden. So können sich die Datenanalysten und Wissenschaftler auf ihre Anwendungsfälle und ihr spezifisches Fachwissen konzentrieren, anstatt sich mit Technologie und Engineering auseinandersetzen zu müssen.
Im Vergleich zu Szenario 1.3 gibt es kein physisches Team mehr, das die Wissensentwicklung erleichtert. Die Datenexperten haben zu diesem Zweck eine Community of Practice gegründet (E in Abbildung 5). Eine andere Möglichkeit wäre die Einführung eines Analytik-Kapitels mit einem engagierten Leiter, der die Analytik-Community noch mehr stärkt. Der Leiter des Kapitels kümmert sich um die Einstellung, das Onboarding und das Coaching von Datenexperten und sorgt so für mehr Kontinuität bei der Verwaltung von Datentalenten und für eine ausgewogene Daten- und KI-Belegschaft in allen Produktteams in Bezug auf Dienstalter und Fachwissen.
Die operative Belastung durch die Verwaltung vieler Datenpipelines in der Produktion durch das Plattformteam, das unter anderem Daten-as-a-Service bereitstellt, wird zu groß und zu komplex. Beim Betrieb der Pipelines können viele Abhängigkeiten entstehen. Auch hier gilt wieder das Conway'sche Gesetz: Ein Team, das Data-as-a-Service für viele Datenquellen bereitstellt, führt zu einem Systemdesign mit einer großen komplexen Komponente, die die Daten liefert. Durch die Verlagerung der Zuständigkeiten für die Datenaufbereitung, -dokumentation und -überwachung hin zu den datenerzeugenden Produktteams wird das Data-Engineering-Plattformteam von sehr detaillierten Aufgaben in Bezug auf bestimmte Datenquellen entlastet, so dass es sich auf seine unterstützenden Aufgaben konzentrieren kann. Darüber hinaus wird das Datensystem als Ganzes gemäß dem Conway'schen Gesetz ein wenig entwirrt, wodurch die Verwaltung der Datenpipelines übersichtlicher wird.
Fall 3: Ihr KI-Unternehmen!
Vielleicht erkennen Sie einige Merkmale und Organisationsformen der Unternehmen aus den beiden oben genannten Fällen wieder, aber jedes Unternehmen hat seine eigene Geschichte, seine eigenen Details und seine eigene Vision, die zu der aktuellen Organisationsstruktur für Daten und KI geführt haben.
Bitte beachten Sie, dass keines der Beispiele in diesem Blog als die beste Einzellösung angesehen werden sollte, die eine Organisation anstreben sollte. Das Ziel dieses Blogs war es zu zeigen, wie man die Vor- und Nachteile bestimmter Organisationsformen anhand der Theorie aus dem Buch Team Topologies bewerten kann. Ihre Organisation sollte sich zum Ziel setzen, eine solche Bewertung durchzuführen und daraus ihr eigenes bestes Data &AI-Organisationsdesign abzuleiten.
Möchten Sie das organisatorische Design für Daten- und KI-Teams speziell für Ihr Unternehmen besprechen und verschiedene Szenarien für mögliche Verbesserungen bewerten? Bitte kontaktieren Sie uns!
Unser KI-Reifegrad-Scan kann verwendet werden, um bestimmte Aspekte Ihres Unternehmens zu bewerten. Sie erhalten Empfehlungen, um Ihr Unternehmen auf die nächste Stufe der KI-Reife zu bringen und können diese als Input für die KI-Strategie und das KI-Organisationsdesign Ihres Unternehmens nutzen.
Verfasst von
Arjan van den Heuvel
Unsere Ideen
Weitere Blogs




Contact