Blog
Aufbau eines stabilen öffentlichen Netzwerks auf AWS: Teil 3

Region Evakuierung DNS-Ansatz
Willkommen zur Fortsetzung unserer umfassenden Blogserie "Building Resilient Public Networking on AWS", in der wir fortschrittliche Netzwerkstrategien für regionale Evakuierung, Failover und robuste Disaster Recovery vorstellen. Hier finden Sie eine Zusammenfassung dieser spannenden Reise:
- Wiederholung der Netzwerkkonzepte aus der Sicht des Kunden: Wenn Sie unsere Erkundung grundlegender Netzwerkkonzepte in der ersten Folge verpasst haben, können Sie dies hier nachholen hier nach. Wir haben den Grundstein für das Verständnis der Grundlagen gelegt, die den folgenden Diskussionen zugrunde liegen.
- Sichere öffentliche Web-Endpunkte bereitstellen: Wenn Sie diesen Blogbeitrag verpasst haben, finden Sie ihn hier . Wir haben wir uns mit den Feinheiten der Bereitstellung eines Webservers und der Befestigung seines öffentlichen Endpunkts auf AWS befasst. Außerdem haben wir die Verwaltung einer DNS-gehosteten Zone mit Route 53 entmystifiziert, einschließlich der nahtlosen Integration mit DNS-Hosting-Anbietern von Drittanbietern.
- Evakuierung der Region mit DNS-Ansatz: In diesem Blog-Beitrag werden wir die bisherige Webserver-Infrastruktur in mehreren Regionen (us-east-1 und us-west-2) bereitstellen und dann den DNS-basierten Ansatz für die regionale Evakuierung prüfen, der die Leistungsfähigkeit von AWS Route 53 nutzt. Wir werden die Vorteile und Einschränkungen dieser Technik untersuchen.
- Regionale Evakuierung mit statischem Anycast-IP-Ansatz: Im folgenden Blog-Beitrag werden wir die Webserver-Infrastruktur in mehreren Regionen einrichten und dann das Konzept der Evakuierung von Regionen mithilfe des robusten Global Accelerator mit einem statischen Anycast-IP-Ansatz erkunden. Gewinnen Sie einen Einblick in die Vorteile und Überlegungen zur Implementierung.
- Persistente TCP-Verbindungen des Clients und warum dies ein Problem sein könnte: Zum Abschluss unserer Serie beleuchten wir die entscheidende Rolle, die der Umgang mit einem der häufigsten HTTP-Client-Verhaltensweisen spielt - den persistenten TCP-Verbindungen. Finden Sie heraus, warum die Vernachlässigung dieses Aspekts zum potenziellen Scheitern der zuvor besprochenen Ansätze führen kann.
Außerdem haben wir für Sie ein GitHub-Repository zur Ergänzung dieser Blogserie . Es bietet Infrastructure as Code (IaC) mit AWS Cloud Development Kit (CDK) und CloudFormation, so dass Sie die erforderliche Infrastruktur mühelos bereitstellen und verwalten können.
Einführung
In diesem dritten Blog-Beitrag möchten wir unsere Leser mit einem mittleren Verständnis des Themas auf die nächste Stufe bringen.
Heute machen wir uns auf den Weg, um die Webserver-Infrastruktur einzurichten, die wir in unserem zweiten unserem zweiten Beitrag, aber mit einer Besonderheit - wir werden es in mehreren Regionen einsetzen (us-east-1 und us-west-2). Unser Hauptaugenmerk wird auf dem DNS-basierten Ansatz zur regionalen Evakuierung liegen.
Ein wichtiger Teil dieses Prozesses ist die Einrichtung der erforderlichen Infrastruktur in der Cloud. Um dies effizient zu bewerkstelligen, nutzen wir Infrastructure as Code (IaC) mit Hilfe des AWS Cloud Development Kit (CDK), das mit TypeScript implementiert wurde. Den entsprechenden Code für diesen Blogbeitrag finden Sie in der bereitgestellten Link .
Für diejenigen, die neu bei AWS CDK sind oder eine Auffrischung benötigen, empfehlen wir, mit unserem Leitfaden zu beginnen: " Erste Schritte mit dem AWS CDK ." Diese Ressource vermittelt Ihnen ein solides Verständnis der AWS CDK-Grundlagen, die Sie benötigen, um mühelos mitzuarbeiten.
In den folgenden Abschnitten werden wir Sie Schritt für Schritt durch eine Anleitung führen, in der wir das Wesen der Evakuierung einer Region mit Hilfe eines DNS-basierten Ansatzes erkunden und die Vorteile und Grenzen dieser Technik diskutieren. Also, fangen wir an!
Überblick über die Architektur
Das nebenstehende Diagramm stellt die Architektur unserer Infrastruktur visuell dar und hebt die Beziehungen zwischen den wichtigsten Komponenten hervor. Während die CDK-Stacks die Infrastruktur innerhalb der AWS Cloud bereitstellen, erfordern externe Komponenten wie der DNS-Anbieter (ClouDNS) manuelle Schritte. Diese Schritte sind in dem folgenden Diagramm deutlich markiert.
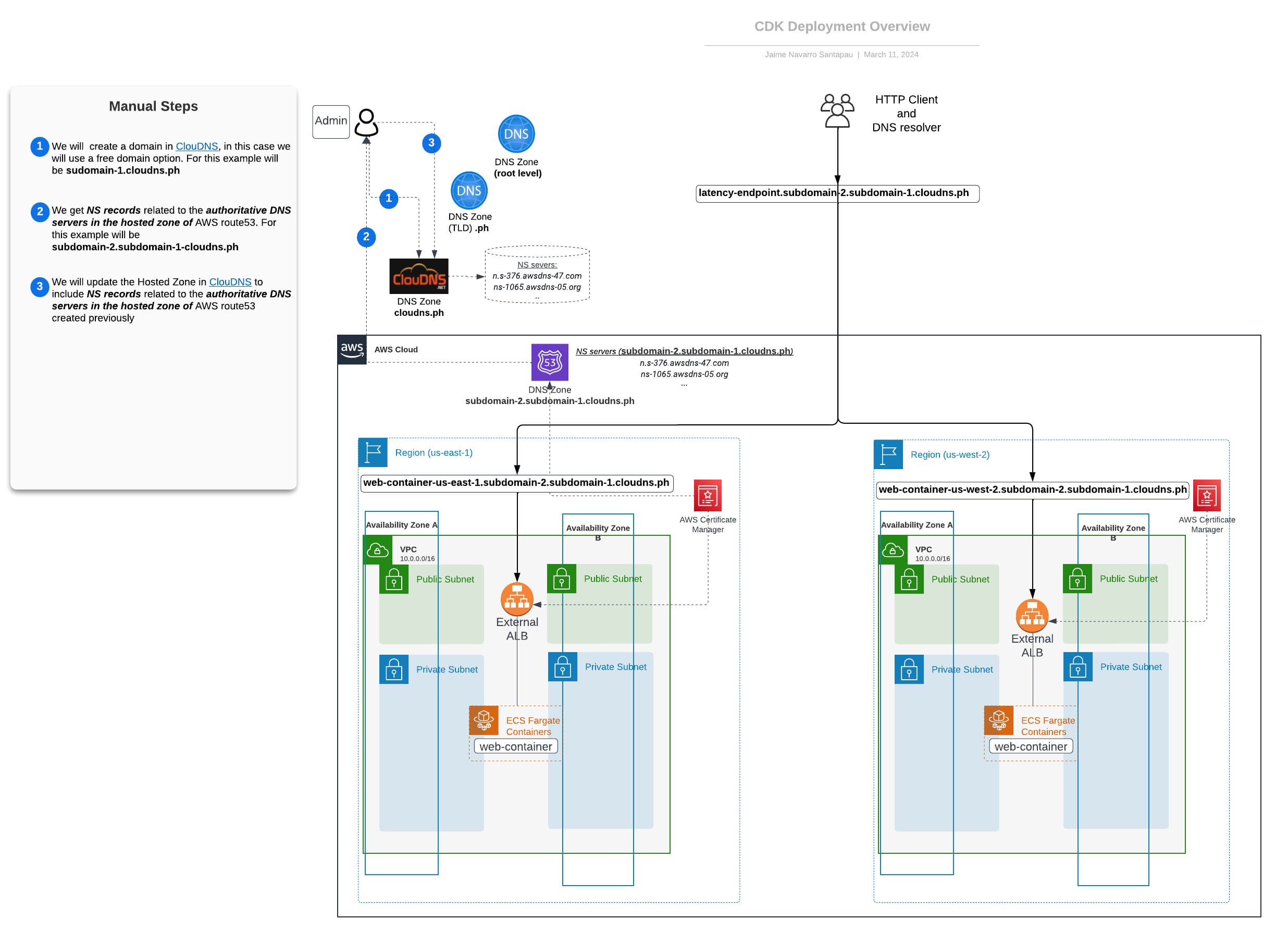 Netzwerkübersicht - DNS-Latenzansatz mit Route 53
Netzwerkübersicht - DNS-Latenzansatz mit Route 53
In diesem Abschnitt werden wir die Netzwerkaspekte prüfen, um zu verstehen, wie AWS Route 53 DNS-Datensätze basierend auf der Latenz bereitstellen kann. Dies ist besonders nützlich, wenn Sie über Ressourcen verfügen, die über mehrere AWS-Regionen verteilt sind, und Sie den Datenverkehr an die Region weiterleiten möchten, die die beste Latenz für den Client bietet.
Wenn ein DNS-Auflöser einen DNS-Eintrag auf der Grundlage der Latenz abfragt, gibt er die dynamischen IPs des Application Load Balancer (ALB) zurück, der Ihrem Standort am nächsten liegt. Daraufhin stellt der HTTP-Client eine TCP-Verbindung her, um HTTP-Anfragen an den nächstgelegenen ALB zu senden. Das folgende Diagramm veranschaulicht die Vernetzung für diesen Ansatz:
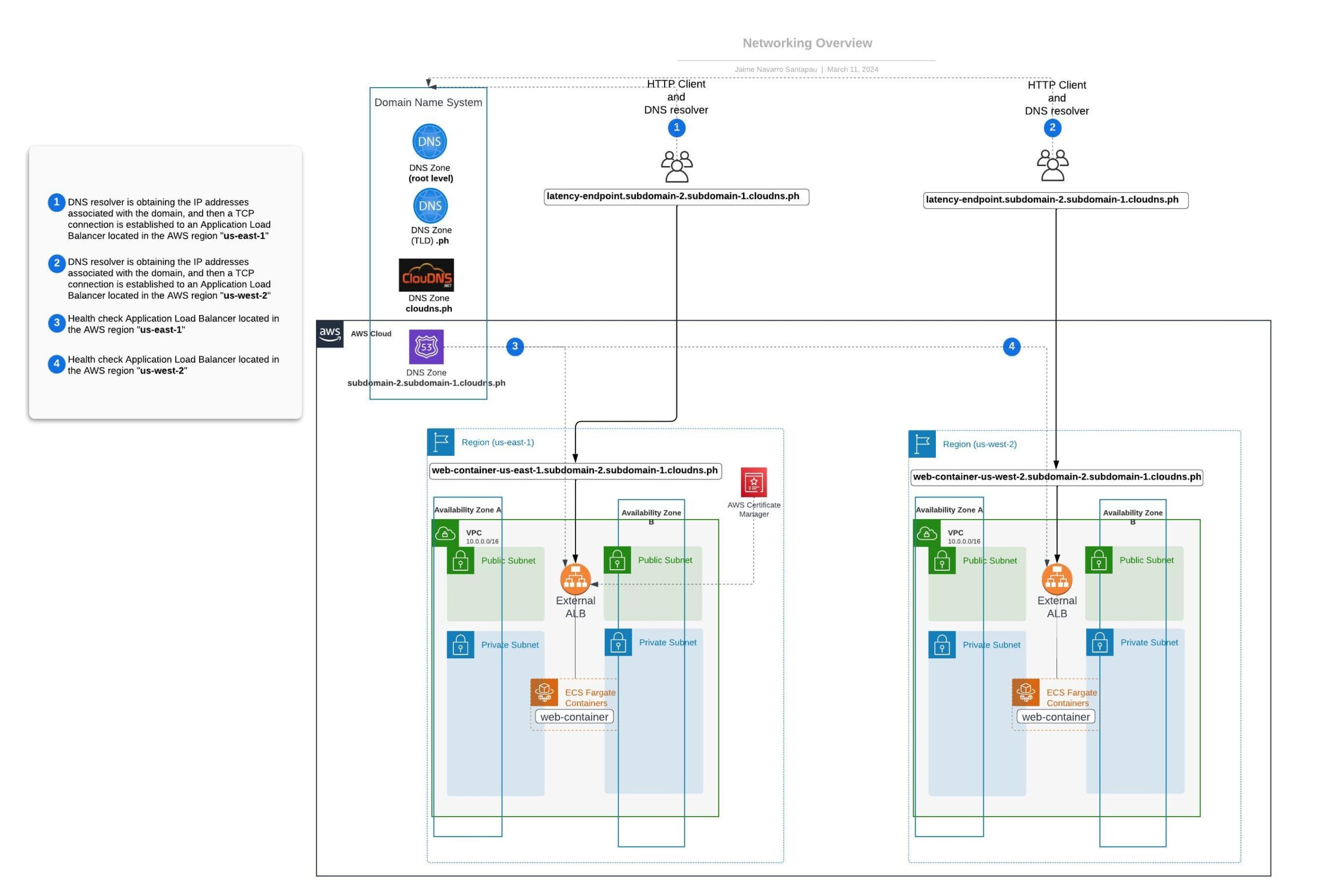
Implementierungsschritte und Validierungen
Im weiteren Verlauf dieser Blogserie werden wir auf dem Wissen und den Erkenntnissen aus unseren früheren Blogbeiträgen aufbauen. Daher haben wir in diesem Blogbeitrag die schrittweise Anleitung zur Bereitstellung und Validierung dieser Infrastruktur weggelassen. Sie können jedoch auf diese Anleitung zugreifen, indem Sie dem Link Leitfaden für Implementierungsschritte und Validierungen Link in unserem GitHub-Repository.
Dieser Leitfaden bietet einen detaillierten Überblick über den Bereitstellungsprozess, einschließlich der Einrichtung von Schlüsselkomponenten, Konfigurationseinstellungen und Validierungsprüfungen. Die Anleitung ist leicht verständlich und enthält klare Anweisungen und hilfreiche Tipps, die Sie durch jeden Schritt führen.
Evakuierung der Region mit DNS-Ansatz über Route 53
Nachdem wir die notwendige Infrastruktur mit Hilfe der zuvor beschriebenen Richtlinien eingerichtet haben, können wir nun anhand eines praktischen Beispiels zeigen, wie eine Region (in diesem Fall us-east-1) effektiv evakuiert werden kann, wenn die bestehende Infrastruktur Probleme aufweist. Dieses Beispiel soll ein grundlegendes Verständnis für den Prozess vermitteln.
- Schritt 1: Um einen Ausfall in der Region zu simulieren, ändern wir unseren Webdienst in us-east-1 so, dass er einen HTTP 500-Fehlercode zurückgibt. Dieser Fehlercode steht für einen Serverfehler und weist auf einen hypothetischen Ausfall in der Region hin.
- Schritt 2: Der HTTP 500-Fehlercode löst fehlgeschlagene Gesundheitsprüfungen für unsere latenzbasierten DNS-Einträge in us-east-1 aus. Diese Gesundheitsprüfungen dienen als Frühwarnsystem, das Route 53 auf mögliche Probleme aufmerksam macht und es dazu veranlasst, den Datenverkehr umzuleiten.
- Schritt 3: Als Reaktion auf die anhaltenden Fehler bei der Zustandsprüfung stellt Route 53 die Weitergabe der zugehörigen IPs für den ALB us-east-1 ein. Daher werden die DNS-Einträge der Clients bei der nächsten geplanten Aktualisierung aktualisiert, um die IPs des ALB us-west-2 zu verwenden, wodurch die regionale Evakuierung effektiv umgesetzt wird.
Dieser dreistufige Prozess bietet Einblicke in die schnelle Bewältigung von Serviceunterbrechungen und stellt sicher, dass die Auswirkungen auf die Endbenutzer während regionaler Ausfälle minimal sind.
Schritt 1 - Der Webdienst gibt den HTTP-Code 500 in us-east-1 zurück
In diesem ersten Schritt ändern wir unseren Web-Service-Container in us-east-1 so, dass er sich wie ein Fehler verhält, indem er einen HTTP 500-Code zurückgibt, der normalerweise auf Serverprobleme hinweist.
Um diese Änderung vorzunehmen, verwenden wir einen curl-Befehl, um eine HTTP-Anfrage an unseren Webdienst in us-east-1 zu stellen. Stellen Sie sicher, dass Sie "subdomain-2.subdomain-1.cloudns.ph" durch Ihre eigene Domain ersetzen:
locken https://web-container-us-east-1.subdomain-2.subdomain-1.cloudns.ph/config/http/500
Die Antwort sollte lauten 'HTTP-Code Antwort: 500', was bestätigt, dass unser Webdienst in der Region us-east-1 nun einen HTTP-Fehlercode 500 zurückgibt. Damit ist der Weg frei für die Evakuierung der Region.
Schritt 2 - AWS Route 53 Health Checks schlagen in us-east-1 fehl
Durch die Rückgabe des HTTP 500-Fehlercodes erkennt der Gesundheitscheck unseres Webdienstes in us-east-1 ein Problem. Nach ein paar Minuten löst dies einen Fehlschlag der Zustandsprüfung aus und zeigt an, dass unser Service in dieser Region "ungesund" ist. Sie können dies überwachen, indem Sie den folgenden Link in Ihrer AWS-Konsole öffnen:
AWS amazon.com/route53/gesundheitschecks/home?region=us-east-1#/
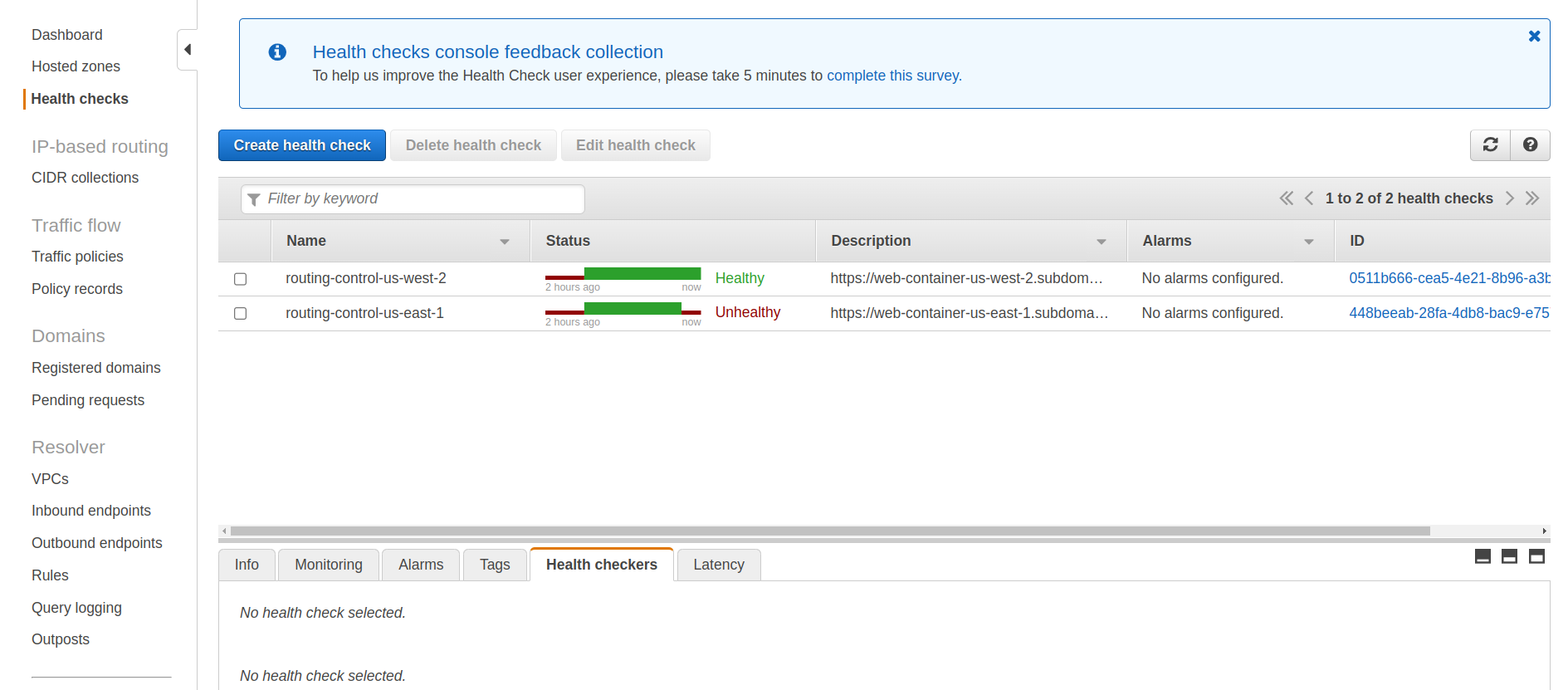
Denken Sie daran, dass eine fehlgeschlagene Gesundheitsprüfung für die Evakuierung unserer Region von entscheidender Bedeutung ist, da sie die Umleitung des Verkehrs in gesündere Regionen einleitet.
Schritt 3 - AWS Route 53 stellt die Weiterleitung der ALB-IPs von us-east-1 ein
Nach dem Ausfall des Gesundheitschecks in us-east-1 sendet AWS Route 53 die dynamischen ALB-IPs der Region nicht mehr an das Internet. Das bedeutet, dass nach ein paar Minuten die Abfrage des DNS-Eintrags für diese Domäne ( Latenz-Endpunkt. subdomain-xx.subdomain-xx.cloudns.ph ) gibt nur die IPs für die ALB in us-west-2 zurück.
In der Tat sollten die DNS-Einträge für diese Domänen ähnlich aussehen:
- https://dnschecker.org/#A/latency-endpoint.subdomain-2.subdomain-1.cloudns.ph
- https://dnschecker.org/#A/web-container-us-west-2.subdomain-2.subdomain-1.cloudns.ph
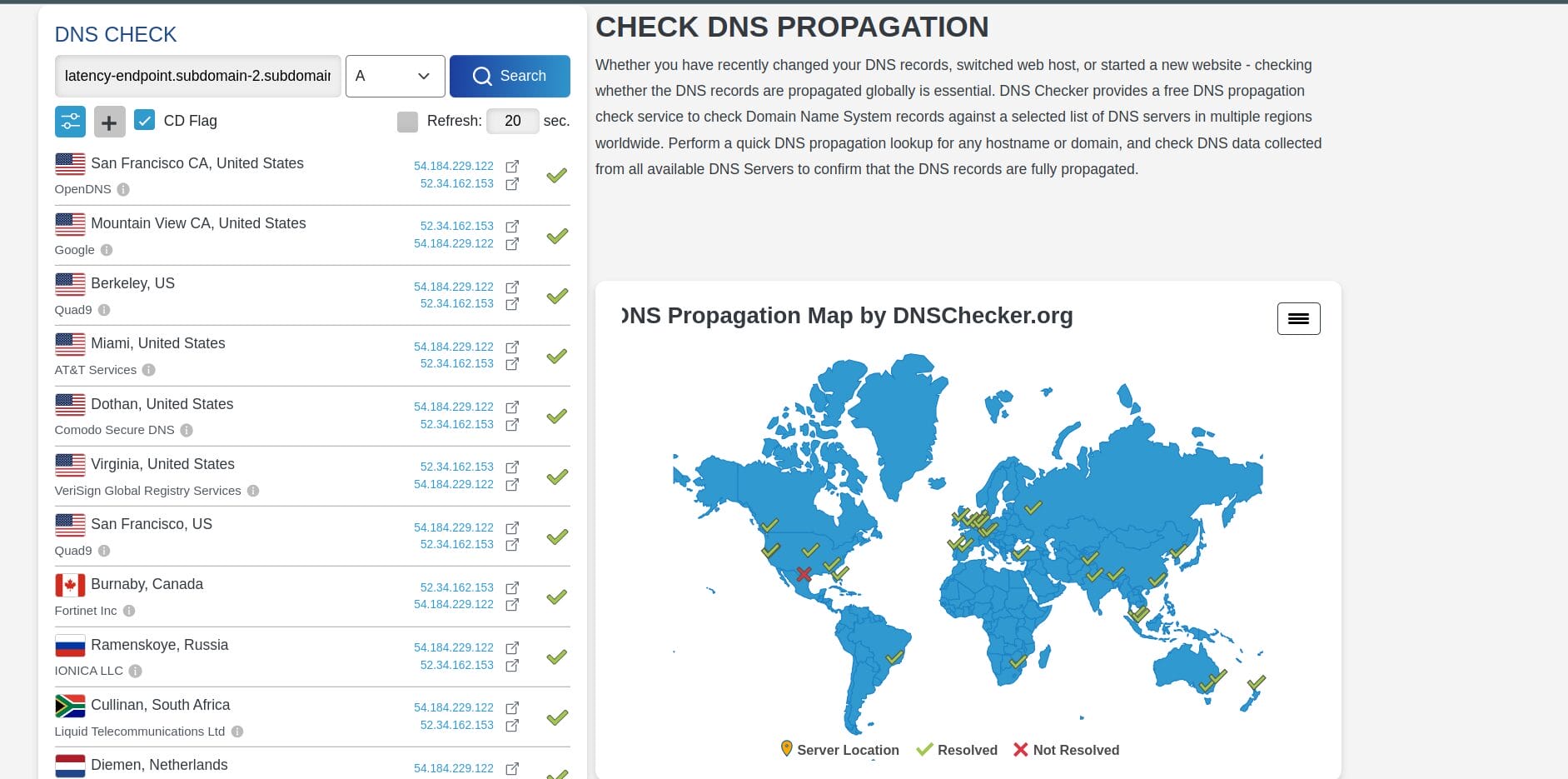
Dies bestätigt, dass der DNS-basierte regionale Evakuierungsprozess korrekt funktioniert hat.
Als Nächstes zeigen wir ein Diagramm, das den endgültigen Zustand unseres Netzwerks nach der erfolgreichen Evakuierung der Region us-east-1 veranschaulicht.
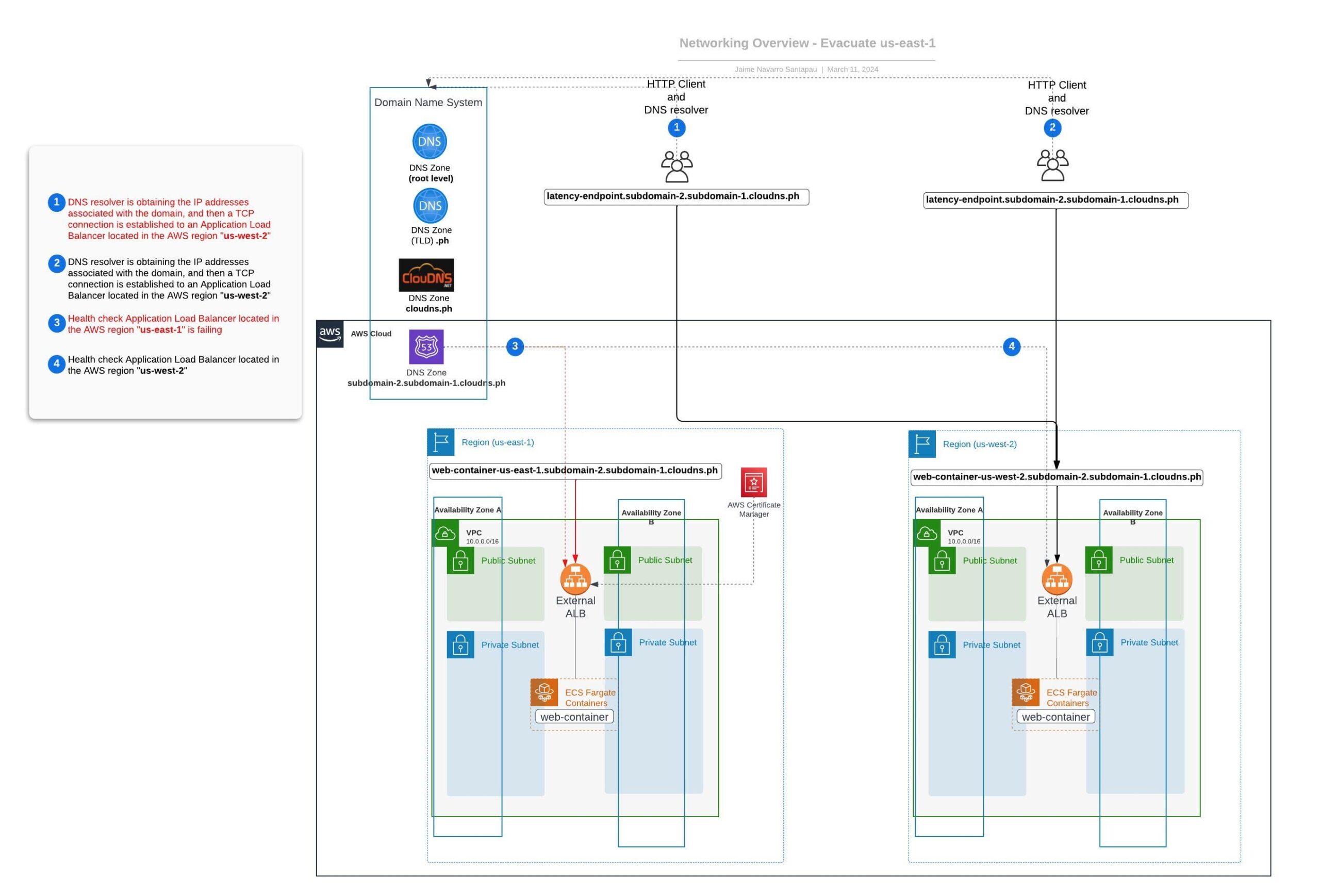 Diese Übung bietet eine grundlegende Basis für das Verständnis, wie die Evakuierung einer Region unter Verwendung des DNS-Ansatzes mit Route 53 funktioniert. Es ist jedoch erwähnenswert, dass dieses Beispiel zu Anschauungszwecken vereinfacht ist. In der Praxis würden Sie eine Region nicht automatisch evakuieren wollen, wenn ein einzelner Endpunkt ausfällt.
Diese Übung bietet eine grundlegende Basis für das Verständnis, wie die Evakuierung einer Region unter Verwendung des DNS-Ansatzes mit Route 53 funktioniert. Es ist jedoch erwähnenswert, dass dieses Beispiel zu Anschauungszwecken vereinfacht ist. In der Praxis würden Sie eine Region nicht automatisch evakuieren wollen, wenn ein einzelner Endpunkt ausfällt.
Deshalb ist es wichtig, sich mit fortschrittlicheren Strategien und Lösungen zu befassen. Unser ' Erweiterungen ' Der Abschnitt ''Erweiterungen'' befasst sich mit diesem Thema und untersucht andere Optionen, die AWS Route 53 und AWS CloudWatch nutzen, um unseren ursprünglichen Ansatz zu verbessern.
Vorteile - Evakuierung der Region mit DNS-Ansatz
Dies sind nur einige der Vorteile, die wir aus dieser Lösung ziehen können:
- Vereinfachtes Verkehrsmanagement: Die geografisch basierte Routing-Funktion in AWS Route 53 ermöglicht eine vereinfachte Verwaltung der Verkehrsverteilung über verschiedene geografische Gebiete.
- Kostengünstig: Im Vergleich zu anderen Cloud-basierten DNS-Services bietet AWS Route 53 eine kosteneffiziente Lösung für die DNS-Verwaltung, da Benutzern nur die tatsächlich genutzten Ressourcen berechnet werden.
- Hohe Verfügbarkeit: AWS Route 53 ist ein hochverfügbarer und zuverlässiger Service. So bietet er minimale Ausfallzeiten und maximale Datenintegrität während der Evakuierung der Region.
- Skalierbarkeit: Die Skalierbarkeit von AWS Route 53 ermöglicht es dem DNS-Setup, die Evakuierung einer Region effektiv zu bewältigen, unabhängig von der Größe des Unternehmens oder der Menge des Datenverkehrs, den es erhält.
- Gesundheitsprüfungen: Das System zur Gesundheitsprüfung von AWS Route 53 hilft bei der Automatisierung des Evakuierungsprozesses von Regionen, da der Service den Datenverkehr umleitet, wenn die Gesundheitsprüfung für eine bestimmte Region fehlschlägt.
Nachteile - Evakuierung der Region mit DNS-Ansatz
Die DNS-basierte Evakuierung von Regionen ist zwar effektiv, hat aber auch einige Nachteile:
- Client-seitige Abhängigkeit: Wir müssen uns darauf verlassen, dass die HTTP-Clients die neuen IPs für die Domäne verwenden, um die Evakuierung der Region effektiv umzusetzen. Wenn es auf der Client-Seite ein Problem bei der Aktualisierung der DNS-Einträge gibt, könnte der gesamte Prozess fehlschlagen.
- Failover-Mechanismus-Abhängigkeit: Die DNS-Propagationszeit kann variieren, und wenn sie lang ist, kann dies dazu führen, dass der Datenverkehr in der Zwischenzeit weiterhin an die ungesunde Region weitergeleitet wird.
- DNS-Cache-Verzögerungen: Obwohl selten, kann die DNS-Verbreitung bis zu 48 Stunden dauern. Denken Sie auch daran, dass der Zeitpunkt, ab dem die Geräte neue IPs verwenden, von den Aktualisierungsintervallen ihres jeweiligen DNS-Caches abhängt.
- Fehlende feinkörnige Kontrolle: Mit diesem Ansatz können Sie den Verkehr nicht präzise aufteilen. Sie können zum Beispiel nicht einen bestimmten Prozentsatz des Verkehrs in eine bestimmte Region leiten; das ist keine Option.
- Keine Unterstützung der Client-Affinität: Der latenzbasierte DNS-Eintrag kann demselben Client im Laufe der Zeit verschiedene IPs zuweisen, was bedeutet, dass ein Client im Laufe der Zeit an verschiedene Regionen weitergeleitet werden kann.
Diese Einschränkungen können für bestimmte Projekte oder Cloud-basierte Softwarelösungen ein Hindernis darstellen. Daher werden wir in unserem nächsten Blogbeitrag einen anderen Netzwerkansatz untersuchen. Wir werden statische Anycast-IPs verwenden, die vom AWS Global Accelerator unterstützt werden, wodurch die meisten dieser Nachteile möglicherweise überwunden werden können.
Erweiterungen und Automatisierung
In diesem Abschnitt werden wir uns auf die Verbesserung unserer Lösung zur automatischen Evakuierung einer Region konzentrieren. Wir werden weiterhin den bereits erläuterten DNS-Ansatz mit AWS Route 53 und den damit verbundenen Gesundheitsprüfungen für unsere DNS-Datensätze auf der Grundlage der Latenz verwenden.
CloudWatch Alarm mit Route 53 Zustandsprüfungen
Die Integration von CloudWatch Alarms mit Route 53 Health Checks ist ein bemerkenswerter Fortschritt für unsere Einrichtung - sie ermöglicht es uns, eine breite Palette von Problemen zu erkennen.
In unserem Beispiel werden unsere CloudWatch Alarme von Metriken gespeist, die von unserer ALB generiert werden, aber wir könnten auch jede andere Metrik verwenden, die wir für relevanter halten. Das Schöne an dieser Lösung ist ihre Flexibilität - unser CloudWatch-Alarm könnte jede relevante Metrik verwenden, um zu entscheiden, ob eine Evakuierung der Region notwendig ist, was uns eine bessere Kontrolle darüber gibt, wann und warum die Evakuierung eingeleitet wird.
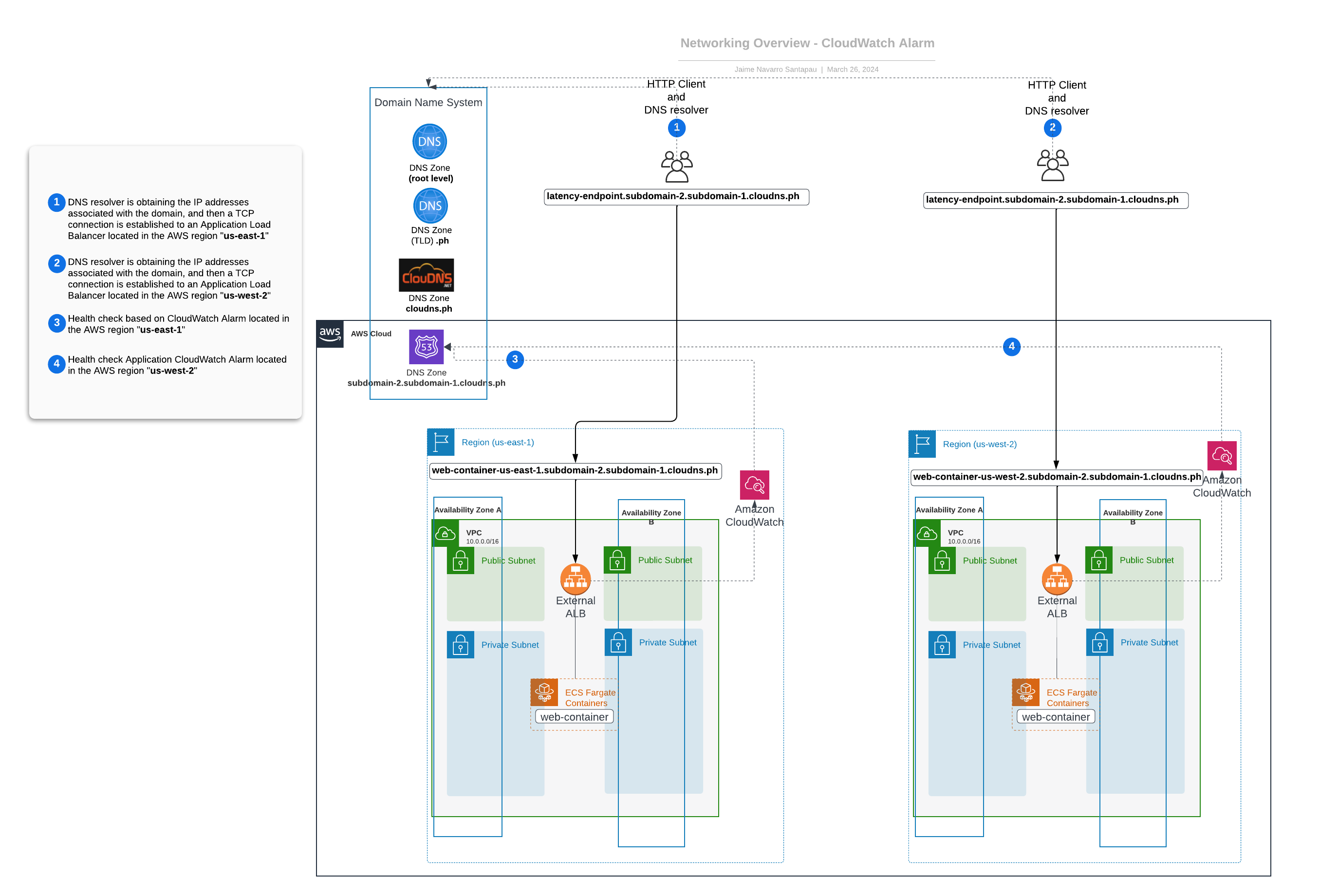 Wie in der Abbildung dargestellt:
Wie in der Abbildung dargestellt:
- Route 53 verwaltet unsere latenzbasierten DNS-Datensätze und überwacht ständig die mit diesen Datensätzen verbundenen CloudWatch Alarme als Gesundheitschecks.
- Wenn diese CloudWatch Alarme ausgelöst werden, wird ein Ausfall der zugehörigen Zustandsprüfung registriert, was auf ein Problem in dieser Region hinweist.
Diese verbesserte Integration von CloudWatch Alarms mit Route 53 Health Checks stärkt die Evakuierungsstrategie unserer Region erheblich und verspricht eine präzisere Erkennung und bessere Kontrolle bei der Entscheidungsfindung.
Schlussfolgerung und nächste Schritte
Herzlichen Glückwunsch! Sie haben die Komplexität der regionalen Evakuierung mithilfe des DNS-Ansatzes mit Route 53 erfolgreich gemeistert. Wir haben uns mit der Einrichtung der erforderlichen Infrastruktur befasst, den DNS-Latenzansatz näher beleuchtet und ein praktisches Beispiel für eine regionale Evakuierung demonstriert.
Aber unsere Reise ist noch nicht zu Ende. Hier finden Sie eine kurze Zusammenfassung unserer kommenden Beiträge:
- Wir werden die Evakuierung von Regionen mit dem Anycast IP-Ansatz mit Global Accelerator untersuchen. Wir werden die Vor- und Nachteile der oben genannten Ansätze abwägen und Ihnen eine ausgewogene Perspektive bieten, damit Sie die beste Strategie für Ihre Bedürfnisse wählen können.
- Zum Abschluss unserer Blogpost-Reihe besprechen wir eines der häufigsten Verhaltensweisen von HTTP-Clients (persistente TCP-Verbindungen) und erklären, warum das Ignorieren dieses Verhaltens zum völligen Scheitern der bisherigen Ansätze führen kann.
Bleiben Sie also dran, wenn wir unsere Reise zum Aufbau von stabilen und hochverfügbaren Anwendungen in der Cloud fortsetzen. Wir freuen uns darauf, Ihnen weitere Einblicke und praktische Beispiele zu geben, damit Sie diese fortschrittlichen Netzwerkstrategien meistern können. Bis dahin, viel Spaß beim Experimentieren!
Zusätzliche Ressourcen
- AWS CDK Erste Schritte : Dieser Leitfaden führt Sie in die wesentlichen Konzepte von AWS CDK ein und beschreibt den Installations- und Konfigurationsprozess.
- AWS ACM-Dokumentation (ACM) Dokumentation: Greifen Sie auf die offizielle AWS-Dokumentation für AWS Certificate Manager zu, um Funktionen, Anwendungsfälle und bewährte Verfahren zu erkunden.
- AWS Route 53 Dokumentation : Vertiefen Sie sich in die Feinheiten von AWS Route 53 mit der offiziellen Dokumentation, die DNS-Verwaltung und Domainregistrierung abdeckt.
- ClouDNS Dokumentation : In der offiziellen ClouDNS-Dokumentation finden Sie detaillierte Informationen zu den DNS-Hosting-Diensten und -Konfigurationen von ClouDNS.
- GitHub Repository für praktische Beispiele: Erkunden Sie das GitHub-Repository, das in dieser Blogpost-Reihe verwendet wird, um auf praktische Beispiele und Infrastruktur-als-Code-Konfigurationen (IaC) zuzugreifen.
Verfasst von
Jaime Navarro Santapau
I'm a Senior DevOps Engineer with over 18 years of experience starting as a Software Engineer followed by Backend Software Development Lead. Currently, I manage complex infrastructure and deliver scalable solutions. Proficient in cloud platforms like AWS and Azure, containerization technologies (Docker, Kubernetes), and automation tools. Proven track record in driving successful DevOps implementations, streamlining workflows, and improving team collaboration. Strong expertise in CI/CD pipelines, monitoring, and scripting languages.




Contact