Blog
Aufbau eines stabilen öffentlichen Netzwerks auf AWS: Teil 1

Überarbeitung von Netzwerkkonzepten aus der Sicht des Kunden
Willkommen zu unserer umfassenden Blog-Serie über fortschrittliche Netzwerkstrategien, die auf regionale Evakuierung, Failover und robuste Disaster Recovery zugeschnitten sind. Gemeinsam werden wir uns mit einer Reihe wichtiger Themen befassen, die für das Verständnis und die Implementierung anspruchsvoller Netzwerklösungen von zentraler Bedeutung sind. Hier ist, was Sie auf dieser spannenden Reise erwarten können:
- Überdenken Sie Netzwerkkonzepte aus der Sicht des Kunden: Bevor wir etwas auf der Serverseite einrichten auf der Serverseite einrichten, besprechen wir zunächst die grundlegenden Netzwerkkonzepte aus der Sicht des Clients, um sicherzustellen, dass Sie das Wesentliche verstehen, auf dem die folgenden Diskussionen basieren.
- Bereitstellung von Secure Public Web-Endpunkte: Lernen Sie die Feinheiten der Bereitstellung eines Webservers und der Befestigung seines öffentlichen Endpunkts auf AWS kennen. Außerdem werden wir die Verwaltung einer DNS-gehosteten Zone mit AWS Route 53 entmystifizieren, einschließlich der nahtlosen Integration mit DNS-Hosting-Anbietern von Drittanbietern.
- Evakuierung der Region mit DNS-Ansatz: An dieser Stelle werden wir die bisherige Webserver-Infrastruktur in mehreren Regionen bereitstellen und dann den DNS-basierten Ansatz zur regionalen Evakuierung prüfen, der die Leistungsfähigkeit von AWS Route 53 nutzt. Wir werden die Vorteile und Einschränkungen dieser Technik untersuchen.
- Regionale Evakuierung mit statischem Anycast-IP-Ansatz: Auch hier werden wir die Webserver-Infrastruktur in mehreren Regionen einrichten und dann das Konzept der Evakuierung von Regionen unter Verwendung des robusten Global Accelerator mit einem statischen Anycast-IP-Ansatz erkunden. Gewinnen Sie Einblicke in die Vorteile und Überlegungen zur Implementierung.
- Persistente TCP-Verbindungen des Clients und warum dies ein Problem sein könnte: Zum Abschluss unserer Serie beleuchten wir die entscheidende Rolle der Behebung eines der häufigsten Verhaltensweisen von HTTP-Clients - persistente TCP-Verbindungen. Finden Sie heraus, warum die Vernachlässigung dieses Aspekts zum potenziellen Scheitern der zuvor besprochenen Ansätze führen kann.
Außerdem werden wir zusammen mit dieser Serie von Blogbeiträgen ein GitHub-Repository um die erforderliche Infrastruktur mit AWS CDK (Cloud Development Kit) einfach und schnell bereitzustellen, ohne dass Sie manuelle Aufgaben mit der AWS Console durchführen müssen. Für diesen ersten Beitrag der Serie werden wir sie jedoch nicht benötigen.
Einführung
In diesem ersten Blog-Beitrag, der sich an Anfänger richtet, werden wir uns mit den Grundlagen des Netzwerks aus der Sicht des Clients befassen. Wir werfen einen genaueren Blick auf die zugrunde liegenden Mechanismen, die die Interaktion zwischen Ihrem Gerät und den öffentlichen Endpunkten im Internet ermöglichen. Vom Verständnis der Rolle von DNS-Resolvern bis hin zur Enträtselung der häufigsten Verhaltensweisen von HTTP-Clients werden wir die grundlegenden Netzwerkkonzepte durchgehen und sicherstellen, dass Sie mit dem nötigen Wissen ausgestattet sind, um sich in den kommenden Diskussionen sicher zu bewegen.
Schnallen Sie sich also an und kommen Sie mit uns auf diese aufregende Reise, um die Geheimnisse belastbarer Netzwerke auf AWS zu lüften.
Das öffentliche Internet aus der Sicht des Kunden
Lassen Sie uns tiefer eintauchen und verstehen, wie das öffentliche Internet aus der Perspektive eines Clients funktioniert. Im weiteren Verlauf dieses Blogbeitrags werden wir das komplizierte Zusammenspiel zwischen HTTP-Clients und DNS-Auflösern unter die Lupe nehmen und die Mechanismen verstehen, die eine sichere und nahtlose Verbindung zu Ihrem öffentlichen Endpunkt ermöglichen. Diese Untersuchung ist nicht nur entscheidend für das Verständnis Ihrer serverseitigen Anforderungen, sondern bildet auch die Grundlage für den Aufbau einer robusten und zuverlässigen Netzwerkinfrastruktur.
Stellen Sie sich einen HTTP-Client vor, der ein Webbrowser, eine Anwendung oder ein beliebiges Programm sein könnte, das HTTP-Anfragen unterstützt. Wenn dieser Client eine neue TCP-Verbindung aufbauen muss, leitet er einen DNS-Auflösungsprozess ein. Dieser Prozess umfasst die Übermittlung einer DNS-Anfrage an einen DNS-Resolver, der normalerweise vom Betriebssystem des Benutzers bereitgestellt wird. Der DNS-Resolver übernimmt dann die Aufgabe, den Domänennamen in eine IP-Adresse zu übersetzen, indem er autoritative DNS-Server konsultiert und das Ergebnis zusammen mit dem Time-to-Live (TTL)-Wert für diesen speziellen DNS-Eintrag zur späteren Verwendung speichert.
Im folgenden Diagramm versuchen wir, die in diesem Abschnitt erläuterten Konzepte kurz zusammenzufassen und die einzelnen Schritte beim Senden einer HTTP-Anfrage zu skizzieren. Darüber hinaus stellen wir die grundlegende Infrastruktur vor, die in den nächsten Teilen dieser Blogserie weiter erforscht wird.
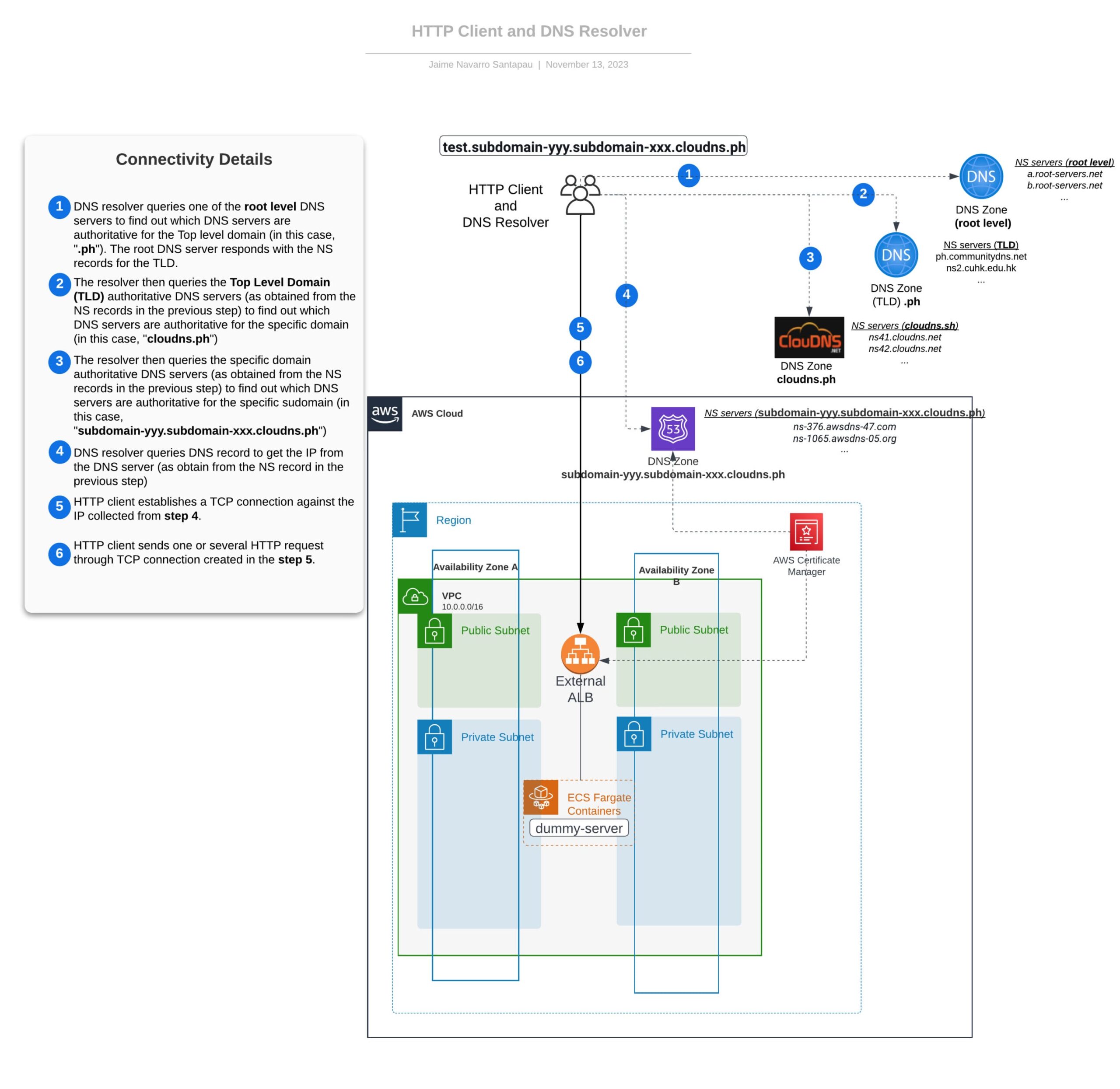
Übersicht über die Konnektivität auf der Client-Seite
DNS-Auflöser
In diesem Abschnitt werden wir uns auf den Teil des DNS-Auflösers konzentrieren und die Funktionsweise dieser Komponente auf der Client-Seite beleuchten, was uns auch ein grundlegendes Verständnis dafür vermittelt, wie das Domain Name System (DNS) im Internet funktioniert.
DNS-Auflöser - Theorie
Ein DNS-Resolver (Domain Name System Resolver) ist eine wichtige Komponente der Internet-Infrastruktur, die eine entscheidende Rolle bei der Übersetzung von menschenfreundlichen Domainnamen (wie www.example.com ) in numerische IP-Adressen (Internet Protocol) um, die Computer und Netzwerkgeräte verwenden, um sich gegenseitig im Internet zu finden. Er fungiert als Vermittler zwischen den Geräten der Benutzer und den maßgeblichen DNS-Servern, die die IP-Adressinformationen für Domainnamen speichern.
Die meisten gängigen Betriebssysteme wie Windows, macOS und Linux enthalten DNS-Auflöser als Teil ihrer Netzwerkkomponenten. Diese integrierten Resolver sind in der Regel so konfiguriert, dass sie die vom Netzwerk bereitgestellten oder die vom Benutzer angegebenen DNS-Server verwenden.
Das folgende Diagramm erklärt, wie ein DNS-Resolver funktioniert:
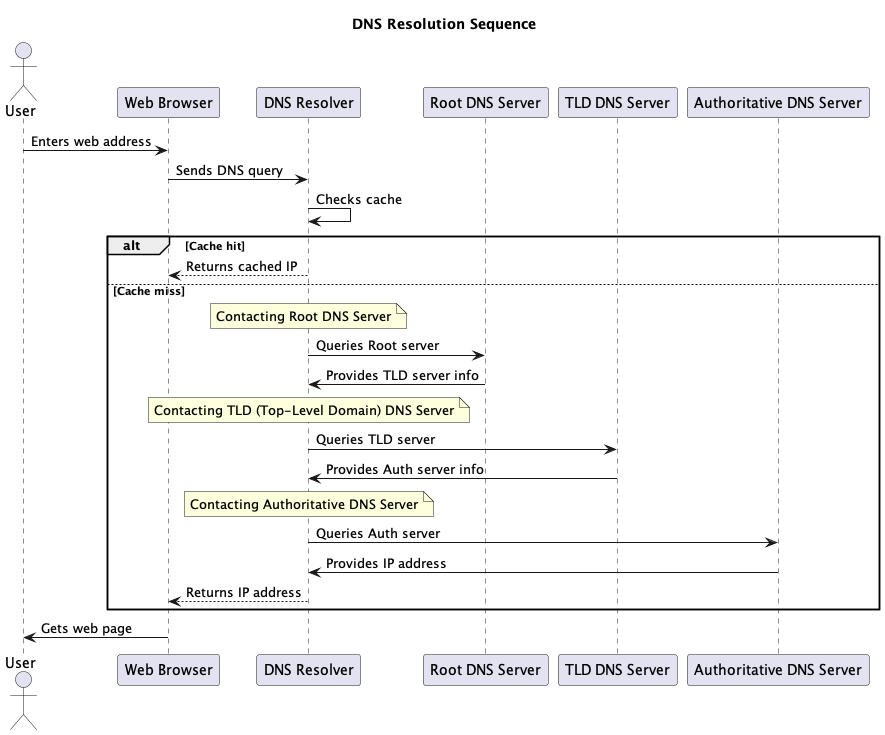
DNS-Resolver sind für das effiziente Funktionieren des Internets von entscheidender Bedeutung, da sie die Belastung der autoritativen DNS-Server verringern, indem sie Informationen zwischenspeichern und den Prozess der Übersetzung von Domainnamen in IP-Adressen beschleunigen. Darüber hinaus können sie Sicherheitsfunktionen wie DNS-Filterung und DNSSEC-Validierung (DNS Security Extensions) bieten, um Benutzer vor bösartigen Websites und DNS-bezogenen Angriffen zu schützen.
Es ist wichtig zu wissen, dass NS (Name Server) Einträge (oder autoritative DNS-Server ) sind wie Wegweiser, die DNS-Auflöser zu den richtigen DNS-Servern leiten, die für eine bestimmte Domain zuständig sind. Sie spielen eine wichtige Rolle für den effizienten und dezentralen Betrieb des DNS-Systems. Sie stellen sicher, dass DNS-Anfragen an die entsprechenden autoritativen Server für die endgültige IP-Auflösung geleitet werden.
DNS Resolver - Reales Beispiel
In diesem Abschnitt werden wir den Befehl dig +trace Befehl um dem Leser ein Werkzeug an die Hand zu geben, mit dem er die zuvor erläuterten Ergebnisse überprüfen kann.
Mit dem Befehl dig +trace können Sie den Delegationspfad einer DNS-Abfrage nachverfolgen und Schritt für Schritt anzeigen, wie die DNS-Auflösung durchgeführt wird. Wenn Sie diesen Befehl mit einem Domänennamen wie test.subdomain-yyy.subdomain-xxx.cloudns.ph eingeben, erhalten Sie eine detaillierte Ausgabe mit den autorisierenden DNS-Servern, die für jede Ebene der Domäne zuständig sind, und dem Auflösungsprozess.
So könnte die Ausgabe des Befehls dig +trace für die angegebene Domain aussehen:
- Root Server: The command will start by querying one of the root DNS servers to find the authoritative DNS servers for the .ph (top-level domain). The root DNS servers have NS records like this one:
- Datensatztyp: NS
- TTL: 23247 Sekunden
- Wert: i.root-servers.net
- TLD Server: After obtaining the information about the .ph authoritative name servers from the root server, the command will query one of the .ph authoritative name servers to find out which name servers are responsible for the cloudns.ph domain. The .ph authoritative name servers have NS records like this one:
- Datensatztyp: NS
- TTL: 172800 Sekunden
- Wert: ph.communitydns.net
- Second-Level Domain Server: The command will then query one of the authoritative name servers for cloudns.ph to determine which name servers are authoritative for the subdomain-xxx.cloudns.ph domain. The authoritative name servers for cloudns.ph have NS records like this one:
- Datensatztyp: NS
- TTL: 86400 Sekunden
- Wert: ns43.cloudns.net
- Subdomain Server: Finally, it will query the authoritative name server for subdomain-yyy.subdomain-xxx.cloudns.ph to retrieve the specific DNS records (such as A, AAAA, MX, etc.) associated with that subdomain. The authoritative name server for subdomain-yyy.subdomain-xxx.cloudns.ph have NS records like this one:
- Datensatztyp: NS
- TTL: 172800 Sekunden
- Wert: ns-1055.awsdns-03.org
- Die letzten Zeilen zeigen die IP-Adresse an, die mit dem DNS-Eintrag 'test.subdomain-yyy.subdomain-xxx.cloudns.ph.' verbunden ist:
- Datensatztyp: A
- TTL: 300 Sekunden
- Wert: 192.168.0.1
Außerdem zeigt die Ausgabe DNS-Einträge wie den NS (Name Server) Record, DS (Delegation Signer) Record, RRSIG (Resource Record Signature) Record und NSEC3 (Next Secure Version 3) Record für jede Ebene der Hierarchie. Der Einfachheit halber haben wir jedoch nur die NS-Einträge in die Ausgabe aufgenommen und die anderen DNS-Einträge, die mit DNSSEC verbunden sind, weggelassen.
dig test.subdomain-yyy.subdomain-xxx.cloudns.ph +trace | grep -v RRSIG | grep -v RRSIG | grep -v DS ; <<>> DiG 9.10.6 <<>> test.subdomain-yyy.subdomain-xxx.cloudns.ph +trace ;; globale Optionen: +cmd . 23247 IN NS i.root-servers.net. . 23247 IN NS k.root-servers.net. . 23247 IN NS m.root-servers.net. . 23247 IN NS b.root-servers.net. . 23247 IN NS h.root-servers.net. . 23247 IN NS g.root-servers.net. . 23247 IN NS a.root-servers.net. . 23247 IN NS d.root-servers.net. . 23247 IN NS e.root-servers.net. . 23247 IN NS f.root-servers.net. . 23247 IN NS j.root-servers.net. . 23247 IN NS c.root-servers.net. . 23247 IN NS l.root-servers.net. ;; Empfangen von 1109 Bytes von 100.90.1.1#53(100.90.1.1) in 11 ms ph. 172800 IN NS ph.communitydns.net. ph. 172800 IN NS ns2.cuhk.edu.hk. ph. 172800 IN NS ns4.apnic.net. ;; Empfangene 625 Bytes von 192.58.128.30#53(j.root-servers.net) in 145 ms cloudns.ph. 86400 IN NS ns43.cloudns.net. cloudns.ph. 86400 IN NS ns44.cloudns.net. cloudns.ph. 86400 IN NS ns41.cloudns.net. cloudns.ph. 86400 IN NS ns42.cloudns.net. ;; Empfangene 540 Bytes von 202.12.31.53#53(ns4.apnic.net) in 292 ms subdomain-yyy.subdomain-xxx.cloudns.ph. 3600 IN NS ns-231.awsdns-28.com. subdomain-yyy.subdomain-xxx.cloudns.ph. 3600 IN NS ns-1965.awsdns-53.co.uk. subdomain-yyy.subdomain-xxx.cloudns.ph. 3600 IN NS ns-724.awsdns-26.net. subdomain-yyy.subdomain-xxx.cloudns.ph. 3600 IN NS ns-1055.awsdns-03.org. ;; Empfangene 212 Bytes von 108.62.121.219#53(ns42.cloudns.net) in 123 ms test.subdomain-yyy.subdomain-xxx.cloudns.ph. 300 IN EINER 192.168.0.1 ... ;; Empfangene 228 Bytes von 205.251.199.173#53(ns-1965.awsdns-53.co.uk) in 37 ms
Bitte beachten Sie, dass die dargestellte Ausgabe zwar als Richtlinie dient, die tatsächliche Ausgabe jedoch je nach DNS-Infrastruktur und der spezifischen Konfiguration der betreffenden Domäne variieren kann. Nichtsdestotrotz erweist sich die Verwendung dieses Befehls als wertvolle Methode, um den DNS-Auflösungsprozess nachzuvollziehen und Einblicke in die Feinheiten der DNS-Delegation für jede beliebige Domäne zu erhalten.
Einen umfassenden Einblick in die Fähigkeiten und Funktionen des dig-Befehls erhalten Sie in diesem Lernprogramm.
HTTP-Client und allgemeine Verhaltensweisen
Nach der Auflösung der DNS-Anfrage und dem Abruf der IP-Adresse durch den DNS-Resolver ist der nächste kritische Schritt im Kommunikationsprozess der HTTP-Client. Als Schlüsselelement bei der Datenübertragung sorgt der HTTP-Client für den nahtlosen Austausch von Informationen zwischen dem Client und dem Server und spielt eine entscheidende Rolle beim Aufbau effektiver Kommunikationskanäle.
Innerhalb dieses komplizierten Prozesses wirken sich mehrere entscheidende Verhaltensweisen und Protokolle erheblich auf die Leistung und Effizienz der Datenübertragung aus. Dazu gehört die Verwaltung von Dauerhafte TCP-Verbindungen erweist sich als ein entscheidender Schwerpunkt. Wenn Sie die Übertragung mehrerer Anfragen und Antworten über eine einzige dauerhafte Verbindung ermöglichen, verringert sich der mit dem Aufbau mehrerer Verbindungen verbundene Overhead. Es ist jedoch wichtig zu wissen, dass die Aufrechterhaltung dieser Verbindungen möglicherweise zu einer Erschöpfung der Ressourcen und zu Latenzproblemen führen kann, insbesondere in Umgebungen mit hohem Datenverkehr.
Neben der Behandlung von persistenten TCP-Verbindungen ist das Verständnis anderer gängiger HTTP-Client-Verhaltensweisen wie Caching-Mechanismen, Cookie-Verwaltung und effektiver Umgang mit Weiterleitungen ebenso wichtig, um eine effiziente und sichere Datenübertragung zu gewährleisten. Unser Hauptaugenmerk in dieser Blogserie liegt jedoch auf dem Verständnis der Feinheiten von dauerhaften TCP-Verbindungen und deren Auswirkungen auf die Serverseite.
Persistente TCP-Verbindungen für verschiedene Tools
In diesem Abschnitt befassen wir uns mit der praktischen Implementierung von persistenten TCP-Verbindungen in verschiedenen Tools, die in diesem Bereich häufig verwendet werden. Indem wir die Funktionalitäten beliebter Tools wie Curl und Postman untersuchen, möchten wir Ihnen ein umfassendes Verständnis dafür vermitteln, wie diese Tools persistente TCP-Verbindungen verwalten. Durch diese Untersuchung erhalten Sie wertvolle Einblicke in die verschiedenen Ansätze, die diese Tools für den Umgang mit persistenten Verbindungen verwenden, so dass Sie verstehen können, welches Tool am besten geeignet ist, um verschiedene Szenarien zu testen.
Persistente TCP-Verbindungen für Curl
Curl, ein leistungsfähiger HTTP-Client für die Befehlszeile, wird für schnelle Netzwerküberprüfungen bevorzugt. Seine Verwendung beim Testen von persistenten TCP-Verbindungen kann jedoch Einschränkungen haben, da das Betriebssystem die zugehörigen Ressourcen, einschließlich Sockets, am Ende des Befehls freigibt.
Trotz dieser Einschränkung bietet Curl die Möglichkeit, TCP-Verbindungen herzustellen und mehrere HTTP-Anfragen über diese Verbindung zu senden. Hier ist ein Beispiel, das zeigt, wie Sie Curl für diesen Zweck verwenden können:
curl https://www.google.com -o /dev/null -w "nDNS Zeit: %{time_namelookup}nVerbindungszeit: %{time_connect}nAppCon Zeit: %.{time_appconnect}nPreXf Zeit: %.{time_pretransfer}nStartXf Zeit: %.{time_starttransfer}nGesamtzeit: %{time_total}n"
--next https://www.google.com -o /dev/null -w "nDNS-Zeit: %{time_namelookup}nVerbindungszeit: %{time_connect}nAppCon Zeit: %.{time_appconnect}nPreXf Zeit: %.{time_pretransfer}nStartXf Zeit: %.{time_starttransfer}nGesamtzeit: %{time_total}n"
...
...
DNS-Zeit: 0.010317
Verbindungszeit: 0.110349
AppCon Zeit: 0.219555
PreXf Zeit: 0.220107
StartXf Zeit: 0.387455
Gesamtzeit: 0.411979
...
...
DNS-Zeit: 0.000050
Verbindungszeit: 0.000000
AppCon Zeit: 0.000000
PreXf Zeit: 0.001372
StartXf Zeit: 0.257576
Gesamtzeit: 0.288846
Die Ausgabe zeigt deutlich die Zeitunterschiede zwischen der ersten und der folgenden HTTP-Anfrage. Bei der ersten Anfrage entsteht zusätzlicher Zeitaufwand durch den Aufbau der sicheren SSL-TCP-Verbindung mit dem kostspieligen TCP-Handshake und dem SSL-Handshake. Nachfolgende Anfragen profitieren von der Wiederverwendung dieser sicheren TCP-Verbindung, wodurch die für die Übertragung der Daten benötigte Zeit reduziert wird.
Obwohl es den Rahmen dieses Blogbeitrags sprengt, möchten wir darauf hinweisen, dass der Curl-Befehl Anfragen über das Protokoll HTTP/1.1 oder HTTP/2 senden kann; jedes dieser Protokolle behandelt persistente TCP-Verbindungen unterschiedlich. Wenn Sie also wissen möchten, welches Protokoll Sie verwenden, können Sie die Option -v (verbose) in den vorherigen Befehl einfügen, und Sie können sehen, welches Protokoll verwendet wird, neben anderen nützlichen Informationen. Umfassende Einblicke in die Fähigkeiten und Funktionen von Curl erhalten Sie in der offizielle Dokumentationsseite .
Dauerhafte TCP-Verbindungen für Postman
Postman, ein benutzerfreundliches Tool zum Testen von APIs, erleichtert mit seiner intuitiven Oberfläche die Entwicklung, das Testen und die Dokumentation von APIs. Im Gegensatz zum Befehlszeilenprogramm curl bleibt der Prozess von Postman nach dem Senden einer HTTP-Anfrage aktiv und ermöglicht so die Verwaltung von persistenten TCP-Verbindungen über mehrere Server hinweg.
Um dieses Verhalten von persistenten TCP-Verbindungen innerhalb von Postman zu demonstrieren, betrachten Sie das folgende Beispiel:
- Starten Sie Postman und initiieren Sie eine neue Anfrage ( https://www.google.com/not-found )
- Senden Sie mehrere HTTP-Anfragen an den gewünschten Endpunkt und überwachen Sie dabei die Antwortzeiten und die Stabilität der Verbindung im Konsolenbereich.
Die folgenden Bilder zeigen ein Beispiel für die vorherigen Schritte:
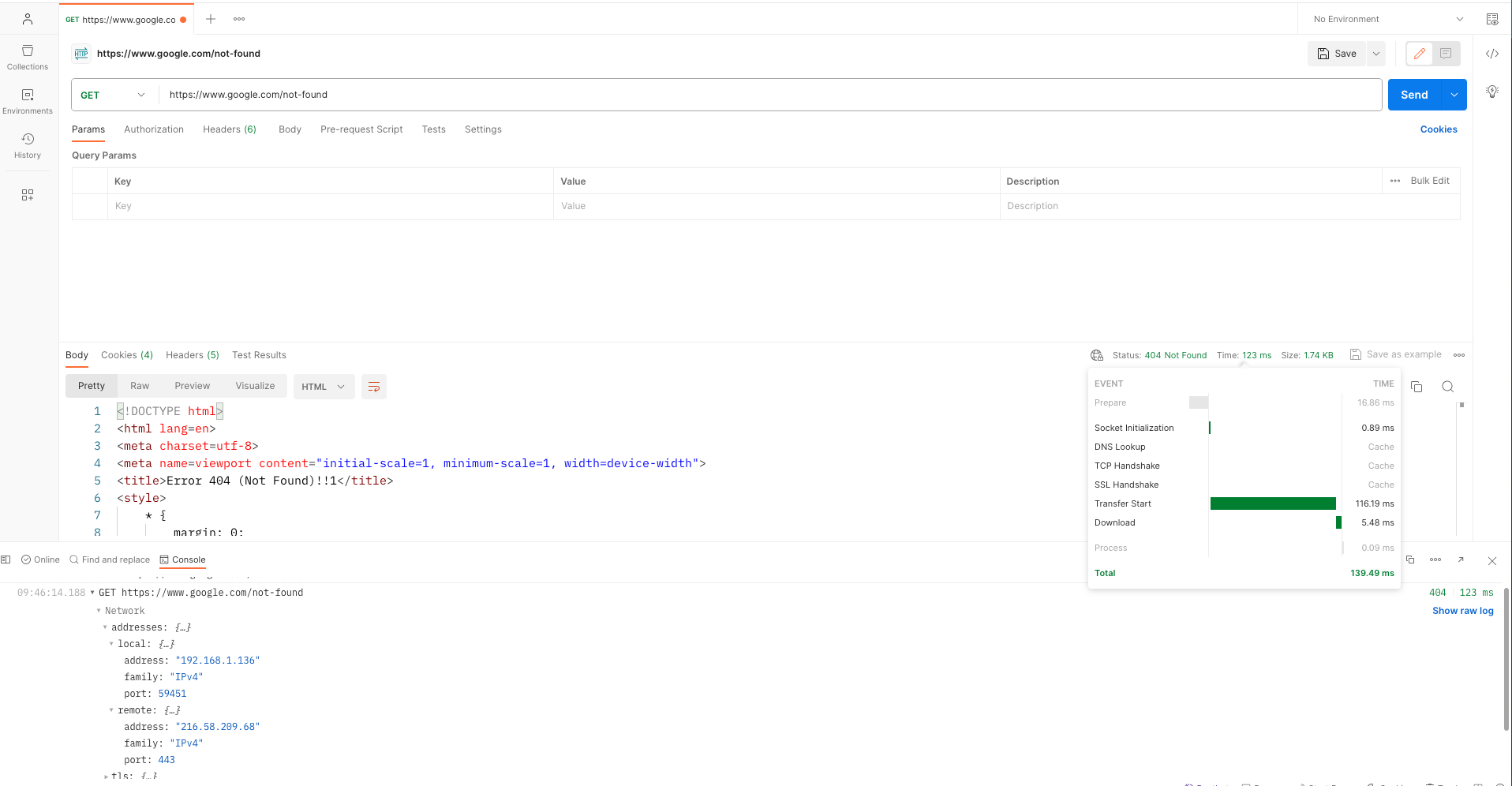
Erste HTTP-Anfrage
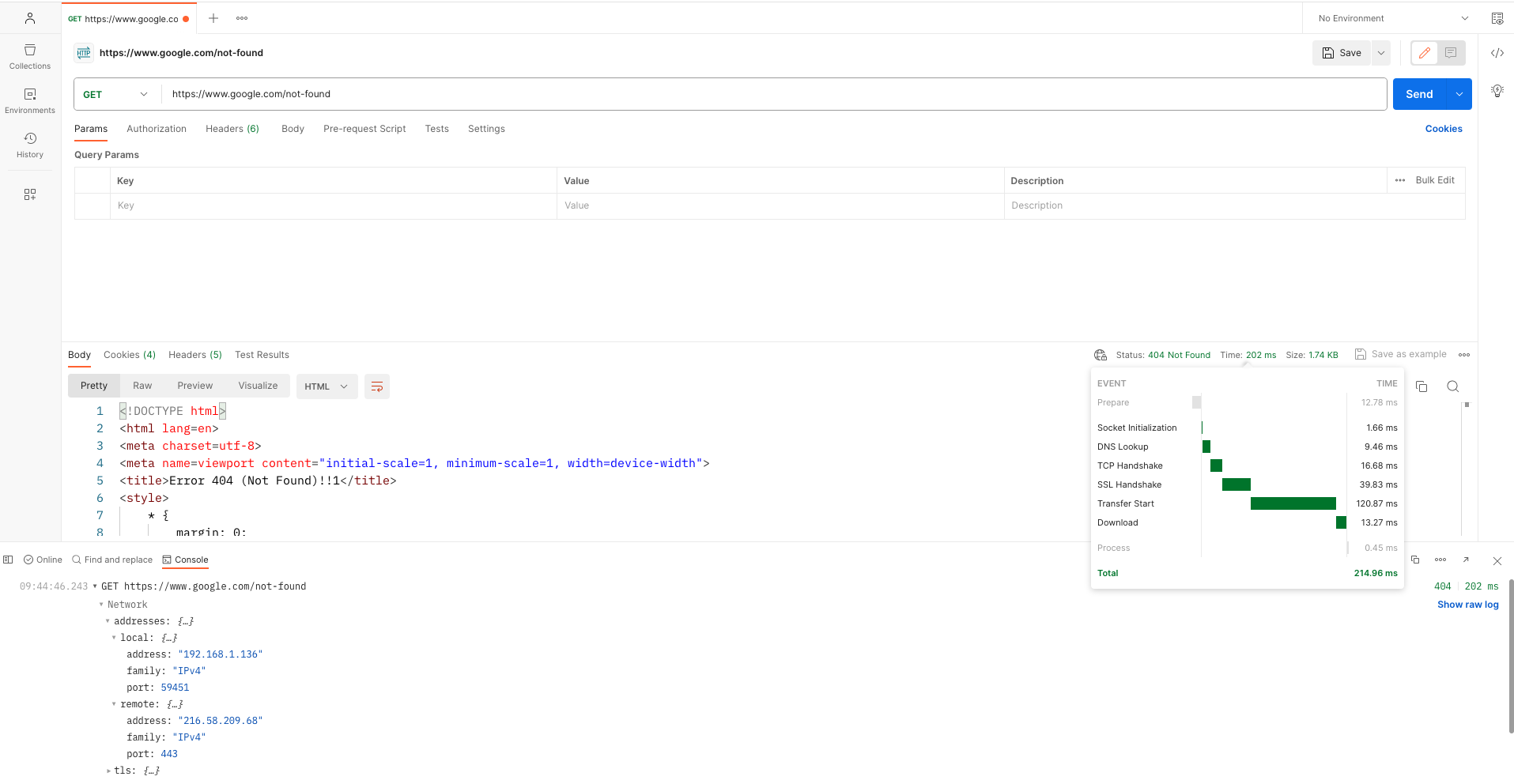
Zweite HTTP-Anfrage
Die Ausgabe zeigt deutliche Zeitunterschiede zwischen der ersten und der folgenden HTTP-Anfrage. Die erste Anfrage erfordert zusätzliche Zeit aufgrund des Aufbaus der sicheren SSL-TCP-Verbindung mit dem ressourcenintensiven TCP-Handshake und SSL-Handshake. Nachfolgende Anfragen nutzen die Wiederverwendung dieser aufgebauten sicheren TCP-Verbindung, was zu einer Verkürzung der Datenübertragungszeiten führt.
Wenn Sie außerdem den folgenden Befehl auf Ihrem Rechner ausführen, erhalten Sie Einblicke in die Dauer, für die die dauerhafte TCP-Verbindung zum Server bestehen bleibt.
for i in $(nslookup www.google.com | grep "Adresse: " | awk '{ print $2 }'); do echo $i; netstat -na | grep $i ; done
216.58.209.68
tcp4 0 0 192.168.1.136.59451 216.58.209.68.443 ESTABLISHED
Die Ergebnisse zeigen drei verschiedene Szenarien:
- Die Verbindung wird auf der Client-Seite geschlossen: Wenn der Postman-Prozess beendet wird, gibt das Betriebssystem umgehend die zugehörigen Ressourcen und Sockets frei, ähnlich wie beim Befehl curl.
- Die Verbindung wird auf der Serverseite geschlossen: Wenn umgekehrt der Postman-Prozess aktiv bleibt und keine weiteren HTTP-Anfragen über die TCP-Verbindung gesendet werden, schließt die Serverseite die Verbindung schließlich auf der Grundlage der Konfiguration des Leerlauf-Timeouts.
- Die Verbindung könnte für einen unbestimmten Zeitraum bestehen: Solange der Postman-Prozess fortbesteht und weiterhin HTTP-Anfragen über die TCP-Verbindung sendet, könnte die Verbindung auf unbestimmte Zeit bestehen bleiben, da es im TCP-Protokoll keine festgelegten Grenzen gibt.
Dieser Blogbeitrag konzentriert sich zwar in erster Linie auf das Verständnis von persistenten TCP-Verbindungen, aber es ist erwähnenswert, dass Postman in der aktuellen Version ausschließlich das Senden von HTTP-Anfragen über das Protokoll HTTP/1.1 unterstützt. Weitere Informationen zur Nutzung von Postmans Fähigkeiten zur Verwaltung von TCP-Verbindungen und zur Durchführung von API-Tests finden Sie in der offiziellen Postman Dokumentation .
Schlussfolgerung und nächste Schritte
Herzlichen Glückwunsch! Sie haben die Grundlagen darüber gelernt, wie HTTP-Clients auf öffentliche Endpunkte zugreifen können. Die Erkenntnisse aus dieser Diskussion werden in unseren kommenden Blogbeiträgen eine wichtige Rolle spielen.
In unserer nächsten Folge werden wir uns mit der Erstellung eines sicheren öffentlichen Endpunkts auf AWS befassen und dabei ACM (AWS Certificate Manager) und AWS Route53 nutzen. Außerdem werden wir uns mit der Verwaltung einer DNS-gehosteten Zone mit AWS Route 53 und der nahtlosen Integration mit einem DNS-Hosting-Anbieter wie ClouDNS. Mit einem umfassenden Verständnis der Funktionsweise des DNS-Resolvers sind wir nun gut gerüstet, um die Feinheiten der Verwaltung von DNS-Servern auf der Serverseite zu meistern.
Dies ist jedoch nur der Auftakt zu unserer umfassenden DevOps-Blogserie. In den kommenden Artikeln werden wir unseren Webserver über mehrere AWS-Regionen hinweg bereitstellen und wichtige Themen wie regionale Evakuierung, Failover und Notfallwiederherstellung unter Verwendung verschiedener AWS-Produkte und -Ansätze behandeln. Hier ein kleiner Vorgeschmack auf das, was kommen wird:
- Überprüfung der Evakuierung von Regionen mithilfe eines DNS-Ansatzes mit AWS Route53.
- Bewertung der Evakuierung von Regionen unter Verwendung des statischen Anycast-IP-Ansatzes mit Global Accelerator.
Wir werden die Stärken und Schwächen eines jeden Ansatzes gründlich untersuchen. Zum Abschluss der Serie werden wir beleuchten, warum diese Ansätze möglicherweise scheitern könnten, ohne eines der häufigsten Verhaltensweisen von HTTP-Clients zu berücksichtigen - nämlich persistente TCP-Verbindungen - und die Szenarien, in denen diese Verbindungen auf unbestimmte Zeit bestehen bleiben könnten.
Bleiben Sie dran für einen tieferen Einblick in den Aufbau von stabilen und hochverfügbaren Anwendungen in der Cloud.
Zusätzliche Ressourcen
Für Leser, die weitere Einblicke in einige der in diesem Artikel erwähnten Themen suchen, empfehlen wir die folgenden Ressourcen zu erkunden:
- Neues Zine: Wie DNS funktioniert! (jvns.ca) - Dieses Zine erklärt klar und schnell mit einer Reihe von Diagrammen, wie DNS funktioniert.
- TCP - Drei-Wege-Han dshake im Details - Ein Video von Sunny Classroom, das hilft zu verstehen, wie der TCP 3-Wege-Handshake beim Aufbau einer Verbindung abläuft.
- SSL/TLS-Handshake-Protokoll - Ein Video von Sunny Classroom, das erklärt, welches Protokoll zwischen einem Webserver und seinen Clients verwendet wird, um Vertrauen aufzubauen.
- HTTP 1 vs. HTTP 1.1 vs. HTTP 2: Eine detaillierte Analyse - DZone : Dieser Artikel enthält eine detaillierte Analyse der Unterschiede zwischen HTTP 1, HTTP 1.1 und HTTP 2.
Verfasst von
Jaime Navarro Santapau
I'm a Senior DevOps Engineer with over 18 years of experience starting as a Software Engineer followed by Backend Software Development Lead. Currently, I manage complex infrastructure and deliver scalable solutions. Proficient in cloud platforms like AWS and Azure, containerization technologies (Docker, Kubernetes), and automation tools. Proven track record in driving successful DevOps implementations, streamlining workflows, and improving team collaboration. Strong expertise in CI/CD pipelines, monitoring, and scripting languages.
Unsere Ideen
Weitere Blogs




Contact