Blog
MapType bündeln, Ausbeute beibehalten. Wie Variant die 10-fache Geschwindigkeit für Halbleitertestprotokolle in Datenfabriken lieferte

"Die hohe Kunst der Datentechnik besteht darin, das Gleichgewicht zwischen Datenverfügbarkeit und Systemleistung zu wahren."
Ted Malaska
Bei Melexis, einem weltweit führenden Anbieter fortschrittlicher Halbleiterlösungen, sorgt die Verschmelzung von künstlicher Intelligenz (KI) und maschinellem Lernen (ML) für eine Revolution in der Fertigung. Durch den Einsatz von prädiktiver Analytik und intelligenter Automatisierung optimiert das Unternehmen die Produktionsausbeute, beugt Anlagenausfällen vor und gewährleistet die Präzision, die von Automobil- und Industrieanwendungen gefordert wird. Im Mittelpunkt dieser Transformation steht der Testlogs-Datensatz - ein geschäftskritischer Datensatz, der während der Funktionsprüfung von Halbleiterwafern und -chips erzeugt wird.
Die Daten-Herausforderung
Jeden Monat generiert Melexis Terabytes an Testlogdaten. Diese Menge unterstreicht sowohl die Komplexität der modernen Halbleiterfertigung als auch die Notwendigkeit schneller, zuverlässiger Analysen. Diese Datensätze bilden das Rückgrat der Entscheidungen in der Qualitätssicherung (QA). Daher sind zeitnahe Erkenntnisse von entscheidender Bedeutung.
Die Datenplattform: Databricks
Melexis verwaltet seine Testlogs auf Databricks, einer cloudbasierten Datenplattform, mit der Sie Datenpipelines und maschinelle Lernmodelle in großem Umfang ausführen können. Die Plattform basiert auf Apache Spark, einer verteilten Computing-Engine für die Verarbeitung großer Datenmengen. Databricks verspricht schnelle und zuverlässige Analysen großer Datensätze.
Das Leistungsparadoxon
Trotz der Versprechungen von Databricks dauerten die Abfragen von 1 TB Testdaten über 4 Stunden - weitmehr als die 1-Stunden-SLA, die für zeitnahe Produktionsentscheidungen erforderlich ist. Noch verblüffender: DuckDB, eine leichtgewichtige Single-Node-Engine, übertraf Databricks bei kleineren Teilmengen. Die Skalierung der Rechenressourcen verschaffte vorübergehend Abhilfe, allerdings zu untragbaren Kosten, da die Benchmarks ein lineares Skalierungsproblem aufzeigten:
4 Arbeiter × 4 Stunden = 16 Arbeiter × 1 Stunde = 1TB verarbeitetDie Ursache dafür? Eine täuschend einfache Designentscheidung: die MapType-Spalte, in der Testmessungen gespeichert werden.
Die versteckten Kosten der Flexibilität
Die Spalte measurements - eine flexible Key-Value-Map, die Hunderte von dynamischen Testparametern erfasst - erwies sich als Alptraum bei der Abfrageausführung. Durch ihre Flexibilität konnte zwar die Verwaltung von Hunderten von spärlichen, dynamischen Spalten in einem breiten Tabellenformat vermieden werden, doch verdeckte sie einen kritischen Engpass: lineare Schlüsselsuchen im großen Maßstab.
Lassen Sie uns das Problem analysieren, indem wir mit der ursprünglichen Tabelle testlogs beginnen.
Die Original-Testlogs-Tabelle
Tabellenschema
Die Tabelle testlogs hat das folgende vereinfachte Schema:
| Spalte | Daten Typ | Beschreibung |
|---|---|---|
| lot_id | string | Kennung für das Produktionslos. |
| test_outcome | string | Ergebnis des Tests (z.B. PASSED, FAILED). |
| Messungen | map<string, string> | Schlüssel-Werte-Paare von Testparametern (z.B. Spannung, Temperatur, Fehlercodes). |
Beispiel Daten:
| lot_id | test_outcome | Messungen |
|---|---|---|
| lot_001 | PASSED | {param1 -> "1.0", param2 -> "HT2"} |
| lot_002 | FAILED | {param1 -> "1.5", param3 -> "true"} |
| Grundstück_003 | PASSED | {param2 -> "FX8", param4 -> "40-23"} |
Warum MapType?
Die Kolumne measurements hat aus zwei wichtigen Gründen die MapType von Spark verwendet:
- Schema-Flexibilität: Hunderte von dynamischen Testparametern (z.B.
param1,param2) können hinzugefügt werden, ohne das Tabellenschema zu ändern. - Semi-Strukturierte Speicherung: Messwerte haben unterschiedliche Typen (z.B. Doubles, Booleans, Strings). Indem wir diese Werte in Strings umwandeln, schaffen wir im Wesentlichen einen Schema-auf-Lese-Ansatz.
Dieses Design vermied den Alptraum der Verwaltung von über 1.000 Spalten für jeden möglichen Testparameter. Es hatte jedoch einen versteckten Preis: die Abfrageleistung.
Die Entscheidung zwischen Flexibilität und Leistung ist ein klassisches Dilemma der Datentechnik.
Die Abfrage: Normalisierung der Karte
Analysten mussten bestimmte Parameter zwischen verschiedenen Tests vergleichen. Um zum Beispiel param1 (ein numerischer Wert) und param2 (ein kategorischer Code) für mehrere Testergebnisse zu analysieren, ist die folgende Abfrage erforderlich:
SELECT
lot_id,
test_outcome,
CAST(measurements["param1"] AS DOUBLE) AS param1, -- Extract as double
measurements["param2"] AS param2 -- Leave as string
FROM testlogs
Ausgabe:
| lot_id | test_outcome | param1 | param2 |
|---|---|---|---|
| lot_001 | PASSIERT | 1.0 | HT2 |
| lot_002 | FAILED | 1.5 | NULL |
| Grundstück_003 | PASSED | NULL | FX8 |
In der Praxis würde diese Abfrage normalerweise Hunderte von Parametern und Millionen von Datensätzen umfassen. Das Grundprinzip bleibt jedoch dasselbe: Extrahieren Sie bestimmte Schlüssel aus der Map und wandeln Sie sie in ihre korrekten Datentypen um.
Problemanalyse: Warum MapType zum Nadelöhr wurde
Auf den ersten Blick sieht die MapType wie ein effizientes Datenformat aus. Spark's MapType ist speichereffizient im Binärformat gespeichert. Darüber hinaus sind die Schlüssel und Werte in zwei Arrays aufgeteilt, so dass nicht benötigte Werte übersprungen werden können. Allerdings werden die Schlüssel und Werte in der Reihenfolge des Einfügens gespeichert und sind daher unsortiert. Das bedeutet, dass die Suche nach einem Schlüssel sehr ineffizient ist: Spark muss das Schlüssel-Array so lange durchlaufen, bis eine Übereinstimmung gefunden wird.
Hier sehen Sie eine vereinfachte Darstellung des MapType Binärformats: 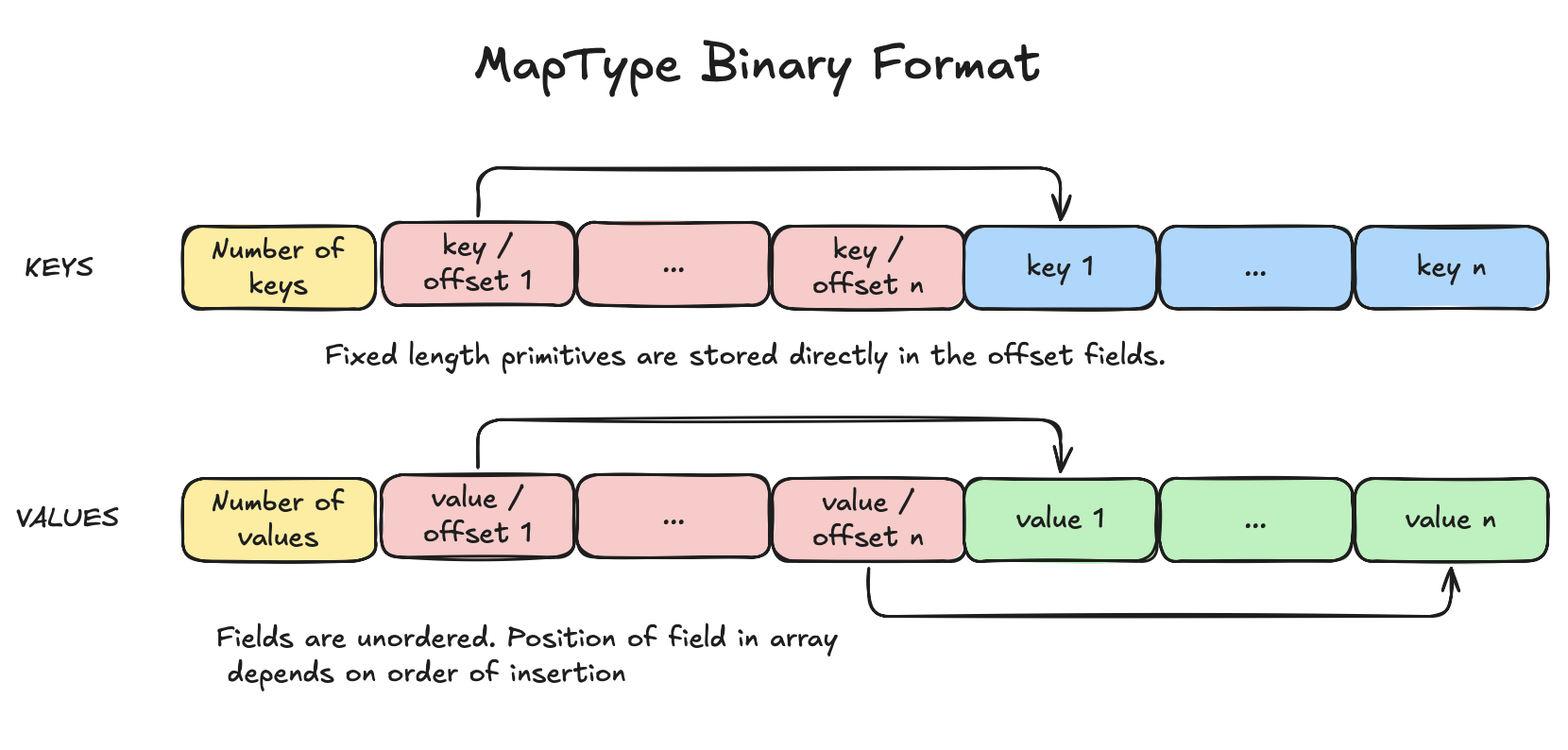
Das Schlüssel-Array besteht aus einer Kopfzeile und einem Feld "Anzahl der Schlüssel", das die Anzahl der Schlüssel innerhalb des Arrays angibt. Außerdem enthält es "Schlüssel- oder Offset"-Felder, die auf den Beginn des Schlüssels im Feld Schlüssel-Offset verweisen. Handelt es sich bei dem Schlüssel um einen primitiven Typ mit fester Länge, wie z.B. Integer, Float oder Boolean, dann wird der Schlüssel direkt im Feld key gespeichert. Das Werte-Array ist ähnlich aufgebaut wie das Schlüssel-Array. Wenn ein Schlüssel gefunden wird, kann sein Wert gefunden werden, indem zum gleichen Index des Feldes value offset innerhalb des Arrays values gesprungen wird. Anhand dieses Offsets kann der Wert gelesen werden.
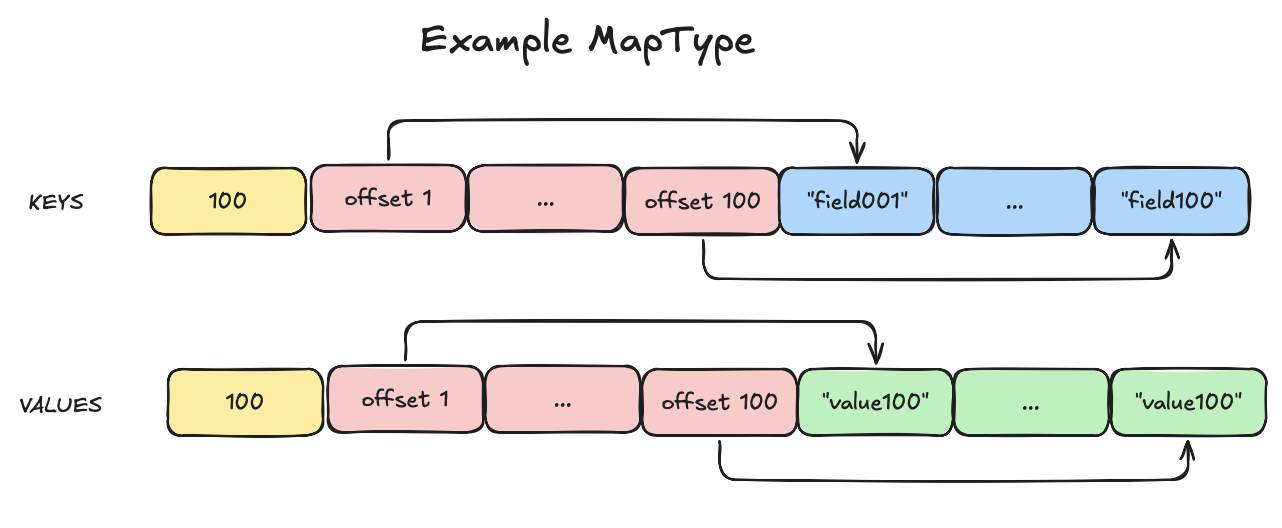
Das Problem der linearen Schlüsselsuche
Das Iterieren durch das Schlüssel-Array, bis eine Übereinstimmung gefunden wird, ist eine O(n) -Operation pro Zeile. Für jede Zeile ist es so, als würde man ein Wörterbuch von vorne bis hinten lesen, um ein Wort zu finden. Das funktioniert bei kleinen Wörterbüchern, aber bei großen Wörterbüchern ist es ineffizient. Im schlimmsten Fall entspricht die Anzahl der Überprüfungen der Anzahl der Schlüssel in der Map. Dies geschieht auch, wenn der Schlüssel nicht in der Map vorhanden ist, was in den Testlogs häufig vorkommt.
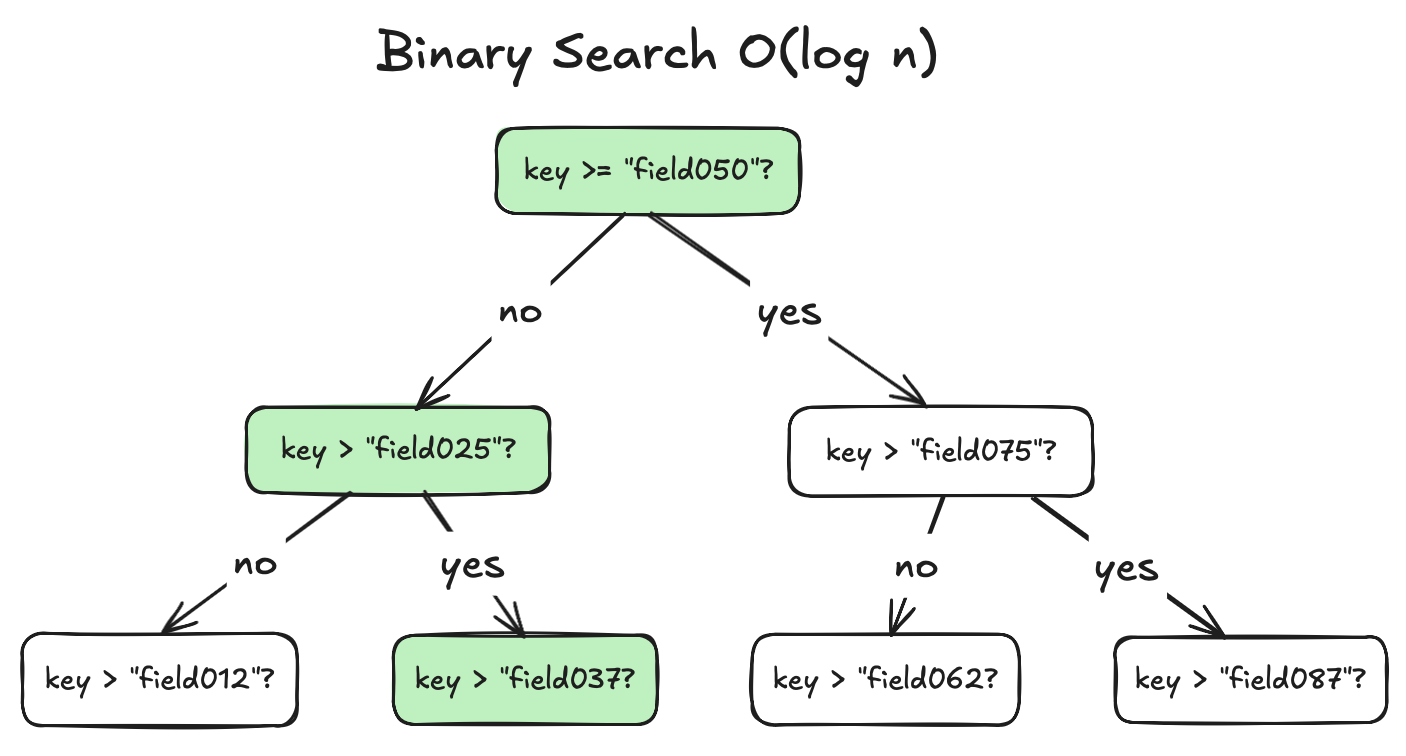
Im folgenden Beispiel sind 82 Überprüfungen erforderlich, um Feld Nummer 42 in einer Karte mit 100 Feldern zu finden. 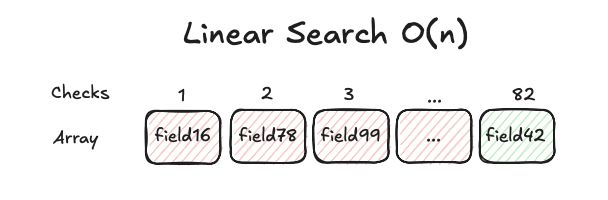
Die Skalierbarkeitsfalle
- Datenvolumen: 1 TB an Testprotokollen = ~1 Milliarde Zeilen.
- Schlüssel pro Map: ~1000 Parameter pro Zeile.
- Schlüsselvergleiche insgesamt: 1 Milliarde Zeilen × 1000 Schlüssel = 1 Billion Vergleiche.
Selbst mit den Optimierungen von Spark ertränkt dies den Cluster in unnötiger Arbeit. Wir haben zum Beispiel festgestellt, dass die CPUs bei Abfragen völlig ausgelastet sind. Das macht die Sache noch schlimmer, denn bei hoher Auslastung verbringen die Aufgaben die meiste Zeit damit, in der Schlange zu warten, anstatt ausgeführt zu werden.
Der Engpass war klar: die lineare Schlüsselsuche in großem Maßstab.
Die Lösung: VariantType
Vor kurzem hat Databricks einen neuen Datentyp eingeführt: VariantType. Diese Datenstruktur, die in Databricks ab Runtime 15.3 und in der Spark 4-Vorschau verfügbar ist, verspricht, bis zu 8x schneller zu sein als die Extraktion von Daten aus einem JSON-String. Die Frage ist jedoch, ob VariantType auch schneller ist als MapType. Dies wird nirgends erwähnt. Oberflächlich betrachtet schien es gut zu passen, da es wie MapType eine Schema-Flexibilität ermöglicht. Im Gegensatz zu MapType verwendet es einen Schema-on-read-Ansatz. In unserem Fall passte das gut, denn für die Testlogs mussten wir die Werte ohnehin in ihre richtigen Typen umwandeln. Dies würde uns also den Aufwand ersparen, von String auf den richtigen Datentyp zu casten. Auf der Suche nach einer Alternative zu dem langsamen MapType haben wir beschlossen, VariantType zu testen.
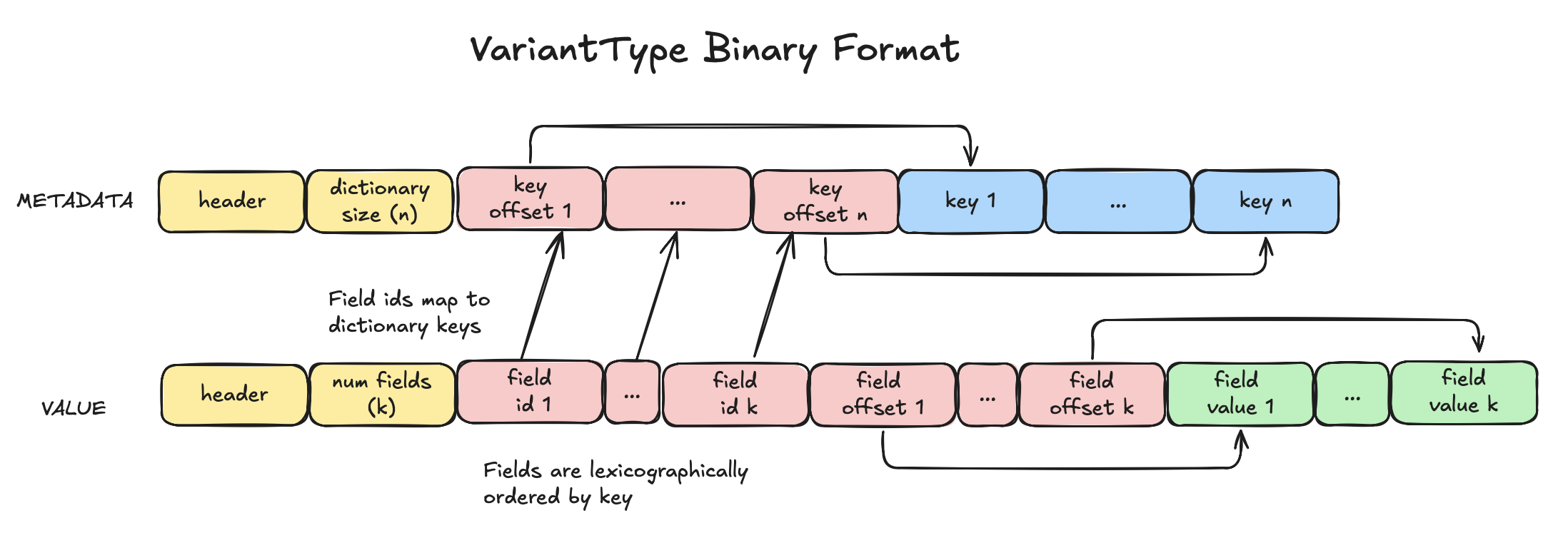
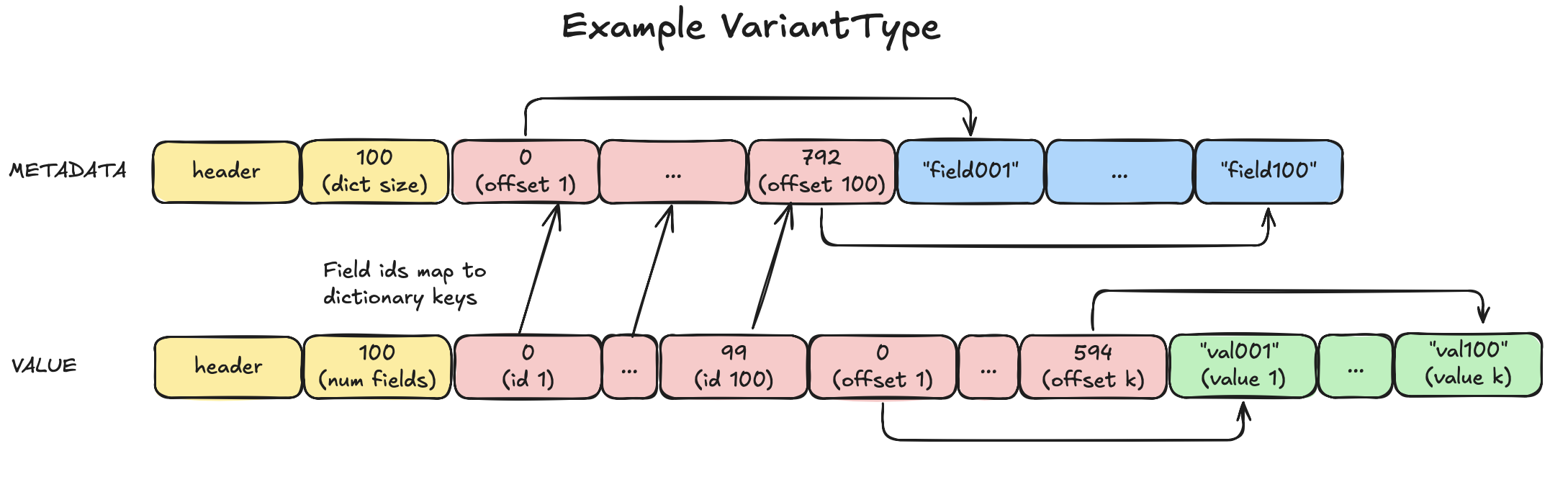
Wie Sie sehen können, ist die Kodierung von VariantType der Kodierung von MapType sehr ähnlich. Allerdings werden die Schlüssel und Werte in lexikografisch sortierter Reihenfolge gespeichert. Dies ermöglicht eine binäre Suche, die eine Zeitkomplexität von O(log n) anstelle von O(n) hat. Bei einer Karte mit 100 Elementen reduziert sich dadurch die maximale Anzahl der Vergleiche auf 7 (log₂(100) ≈ 6,64) gegenüber 100 bei der linearen Suche.
Binäre Suche
Bei der binären Suche wird ein Schlüssel gesucht, indem er mit dem mittleren Element des Arrays verglichen wird. Wenn der Schlüssel kleiner ist, wird die Suche in der linken Hälfte fortgesetzt, wenn er größer ist, wird sie in der rechten Hälfte fortgesetzt. Dies wird so lange wiederholt, bis der Schlüssel gefunden ist. Sobald der Schlüssel gefunden ist, kann der entsprechende Wert über denselben Index im Array für den Werteversatz abgerufen werden.
Die Benchmark-Ergebnisse sind atemberaubend
Der schnellere binäre Suchalgorithmus von VariantType bedeutet, dass er die lineare Suche von MapType bei größeren Karten wahrscheinlich übertreffen wird. Um dies zu überprüfen, wurde ein synthetischer Datensatz erstellt und die Zeit für den Zugriff auf alle Schlüssel bei einem Datensatz mit 1.000 Datensätzen gemessen. Um die Auswirkungen der Anzahl der Schlüssel zu messen, wurde die Anzahl der Schlüssel von 1 bis 10.000 variiert.
Die Ergebnisse waren eindeutig: VariantType übertraf MapType bei einem Datensatz mit 10k Schlüsseln um das 5-fache.
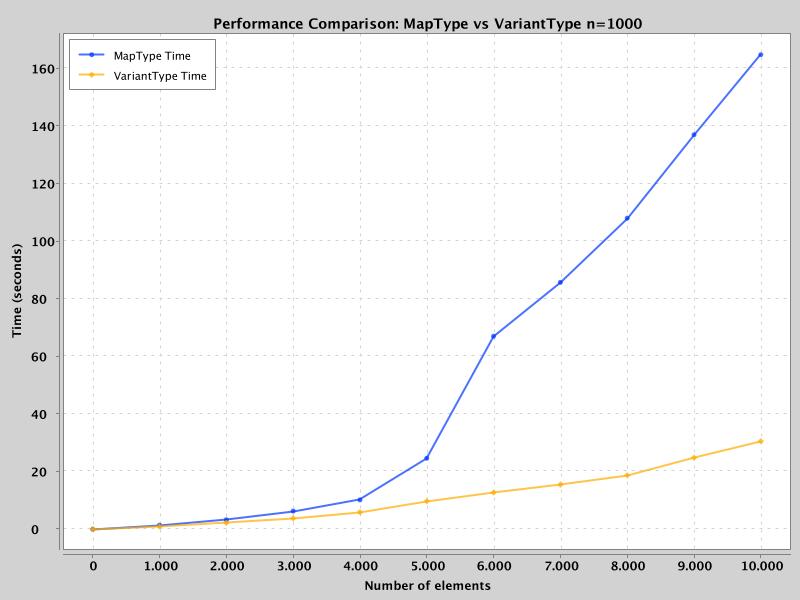
Lief im lokalen Modus auf einem Apple M4 mit 10 Kernen und 30 GB RAM.
VariantType übertrifft die Leistung von MapType deutlich, wenn die Anzahl der Schlüssel steigt. Bei etwa 6.000 Schlüsseln nimmt die Leistung von MapTypeaufgrund von CPU-Sättigung und Aufgaben-Warteschlangen schnell ab - ein Verhalten, das auch in Produktionsumgebungen beobachtet wurde, in denen die CPUs durchgehend zu 100 % ausgelastet waren. Der Grund dafür? Die lineare Suche ist CPU-intensiver und erfordert viel mehr Vergleiche.
Die Schattenseiten von VariantType
VariantType hat einige Nachteile im Vergleich zu einem MapType mit Schlüsseln nur auf der Stammebene:
-
Höherer Speicherplatz- und Speicher-Overhead: Beispielsweise belegen 1.000 Zeilen mit 10.000 Elementen ~1,25x mehr Speicherplatz (590MB vs. 471MB). Beachten Sie, dass die Speicherung von VariantType bei tief verschachtelten Strukturen effizienter wird, da das binäre Format die Schlüssel nur einmal speichert (im Gegensatz zu JSON-Strings, die die Schlüssel wiederholen).
-
Langsamere Schreibvorgänge: Die Kodierung von VariantType dauerte in den Benchmarks aufgrund der Komplexität des Binärformats ~20% länger.
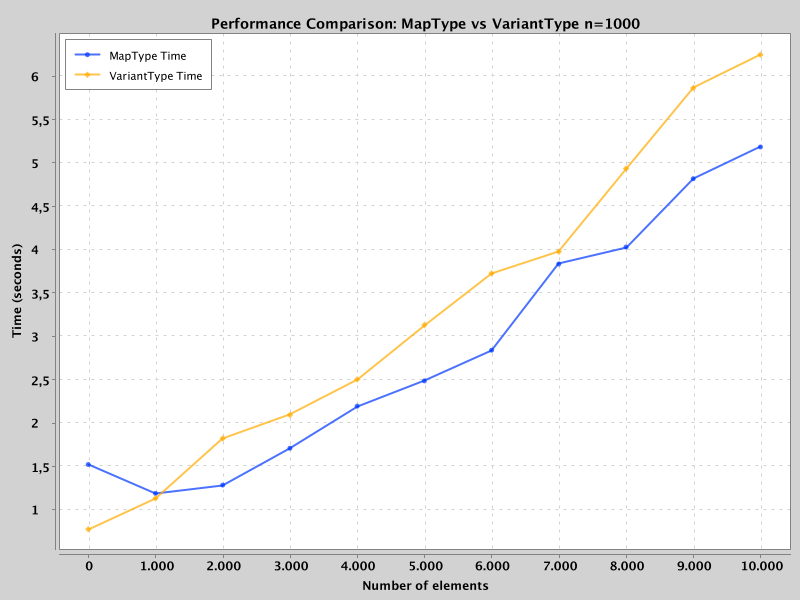
Die geringere Schreibleistung ist sinnvoll, da Spark die Schlüssel sortieren muss und außerdem etwas komplexer ist als die MapType-Kodierung.
Für unseren Anwendungsfall überwiegen die Leistungsgewinne diese Nachteile bei weitem. Daher sind wir für unsere Testlogs-Tabelle auf VariantType umgestiegen.
Die Ergebnisse
- 10x schnellere Abfragezeiten: Abfragen auf 1 TB Daten fielen von 4+ Stunden auf 20 Minuten.
- Zufriedene Analysten: Schnellere Einblicke und interaktive Erkundung. Ein Analyst bemerkte: "Es ist so cool, dass ich jetzt
Abfragen durchführen kann und in wenigen Minuten Ergebnisse erhalte." - Höherer Geschäftswert: Analysten können jetzt während technischer Besprechungen Fragen zu Testprotokollen beantworten - was früher
aufgrund langsamer Abfragen unmöglich war. - Kosteneinsparungen: Geringere Rechenkosten durch Vermeidung von linearen Skalierbarkeitsfallen. Kleinere Cluster (z.B. Single Worker
Nodes) bewältigen jetzt Arbeitslasten, für die früher 4+ Nodes erforderlich waren.
Betrachtete Alternativen
Es wurden mehrere andere Ansätze getestet und in Betracht gezogen. Ich werde sie hier kurz besprechen.
Getestete Ansätze
- Liquid Clustering: Keine messbaren Leistungssteigerungen für unseren Key-Lookup-Engpass.
- Partitionsspalten hinzugefügt: Die Filtergeschwindigkeit wurde geringfügig verbessert, aber das Filtern war nicht unser kritischer Pfad.
Geprüfte Alternativen
- StructType: Zu starr für dynamische Schlüssel. Selbst bei der dynamischen Erstellung von Strukturen zur Laufzeit müssen die Parameter irgendwo nachgeschlagen werden, was die Vorteile zunichte macht.
- JSON-Strings: Langsamer als MapType. Eine Menge Parsing-Overhead.
- Breite Schema-Tabellen: Unpraktisch für 1.000+ dynamische Parameter. Die Schemaverwaltung würde zu einem Alptraum werden.
- Geteilte Tabellen: 1.000+ Tabellen für Parameter verwalten? Nein, danke.
- Langes (schmales) Format: Erfordert Schwenken/Verbinden für die horizontale Analyse. Unsere Tests haben gezeigt, dass dies 30-100x langsamer ist als Map/VariantType-Scans.
- Andere Binärformate wie Protobuf: Ich habe es nicht getestet, aber es scheint, dass Variant Type besser geeignet ist, da es für Spark entwickelt wurde und ein Schema zum Einlesen bietet.
- Verwendung einer anderen Abfrage-Engine: DuckDB wurde für eine kleine Teilmenge ausprobiert, aber es handelt sich um einen einzelnen Knoten und ist nicht für diese Datengrößen optimiert. Vielleicht kann SmallPond für unseren Anwendungsfall interessant sein, aber es ist noch nicht in Databricks verfügbar.
Learnings
- Die Datenkodierung ist wichtig: Der richtige Datentyp kann sich drastisch auf die Leistung auswirken.
- Schema-Flexibilität vs. Leistung: VariantType schafft ein Gleichgewicht, indem es sowohl Flexibilität als auch Geschwindigkeit für halbstrukturierte Daten bietet.
- Benchmarking früh, Benchmarking oft: Proaktives Benchmarking verhindert Engpässe in der Produktion.
Die Zukunft von VariantType
Databricks optimiert VariantType weiter, einschließlich der Unterstützung für das Shredden - das Extrahieren vonFeldern aus dem Binärformat in separate Spalten.
Zu den Vorteilen gehören:
- Kompaktere Kodierung.
- Min/Max-Statistiken für das Überspringen von Daten.
- Reduzierte E/A- und CPU-Auslastung durch Beschneidung ungenutzter Felder.
Ich hoffe, Sie hatten Spaß beim Lesen dieses Beitrags. Wenn Sie Fragen haben, können Sie sich gerne an mich wenden. Benchmark-Code:
Link zu GitHub Repo.
Verfasst von
Daniël Tom
Daniël is a data engineer at Xebia Data. He gets energy from problem solving and building data applications. In addition, he likes to tinker with the latest data tools.
Unsere Ideen
Weitere Blogs




Contact