Blog
Big Data Expo 2018: Deep Learning, der Motor der KI-Revolution

Vor zwei Wochen hatte ich die Gelegenheit, auf der Big Data Expo 2018 einen Vortrag über Deep Learning zu halten. Es war ein nicht-technischer Vortrag, der versuchte, Deep Learning zu entmystifizieren und zu erklären, warum Deep Learning die KI-Tech-Revolution vorantreibt. 1
Der Titel meines Vortrags lautete Deep Learning, der Motor der KI-Revolution. Und wenn ich Revolution sage, meine ich nicht nur einen technologischen Fortschritt, sondern eine Technologie, die die Gesellschaft verändert.
Dieser Blogbeitrag ist ein Versuch, meinen Vortrag zusammenzufassen. Er ist ein wenig abgehackt, weil der Vortrag viel Storytelling enthielt, um Konzepte miteinander zu verbinden, aber ich hoffe, dass dieser Beitrag auch für diejenigen von Nutzen ist, die beim Vortrag nicht dabei waren. 2
Technische Revolutionen
Ende der 90er/Anfang der 00er Jahre erlebten wir die Internet-Revolution, in der Unternehmen wie Google, Facebook, Youtube, Netflix und Airbnb entstanden. Auch einige Unternehmen passten sich dem Internet-Zeitalter an und brachten neue Produkte auf den Markt, wie MSN Messenger, Hotmail und den iTunes Store.
Dann, nach der Veröffentlichung des iPhone im Jahr 2007, begann die mobile Revolution. Großer Reichtum wurde geschaffen, da sich die Nutzer über mobile Anwendungen viel stärker mit Produkten auseinandersetzten. Unternehmen wie Uber, Tinder, Snapchat und Instagram wurden gegründet. Clevere Unternehmen aus der Internet-Ära setzten sich durch und brachten mobile Anwendungen wie Facebook, YouTube, LinkedIn und Spotify auf den Markt.
Die nächste Welle wird die Revolution der künstlichen Intelligenz sein. Die KI ist bereit, verschiedene Sektoren und Märkte zu verändern. In einigen Fällen hat sie bereits neue Produkte hervorgebracht, wie Google Translate oder
Jeder kennt die großen Unternehmen wie Google(Waymo) und Tesla, die mit Hilfe von KI das perfekte selbstfahrende Auto entwickeln wollen, und intelligente Assistenten wie Alexa, aber KI, die auf Deep Learning basiert, ist auch in vielen anderen Bereichen durch kleinere Unternehmen vertreten. Nehmen Sie zum Beispiel Lyrebird, ein Unternehmen mit Sitz in Kanada, das Ihre Stimme synthetisieren kann, oder

Wie passt Deep Learning in das Ökosystem der künstlichen Intelligenz?
Lassen Sie uns zunächst die Konzepte der künstlichen Intelligenz, des maschinellen Lernens und des Deep Learning betrachten.
Künstliche Intelligenz ist nach der Definition von John McCarthy, der den Begriff 1956 prägte, "die Wissenschaft und Technik der Herstellung intelligenter Maschinen". Beachten Sie, dass es keine Angaben darüber gibt, wie Maschinen Intelligenz nachahmen; dies kann durch Geschäftsregeln, Brute-Force-Algorithmen, Symbolmanipulation oder statistisches Lernen geschehen.
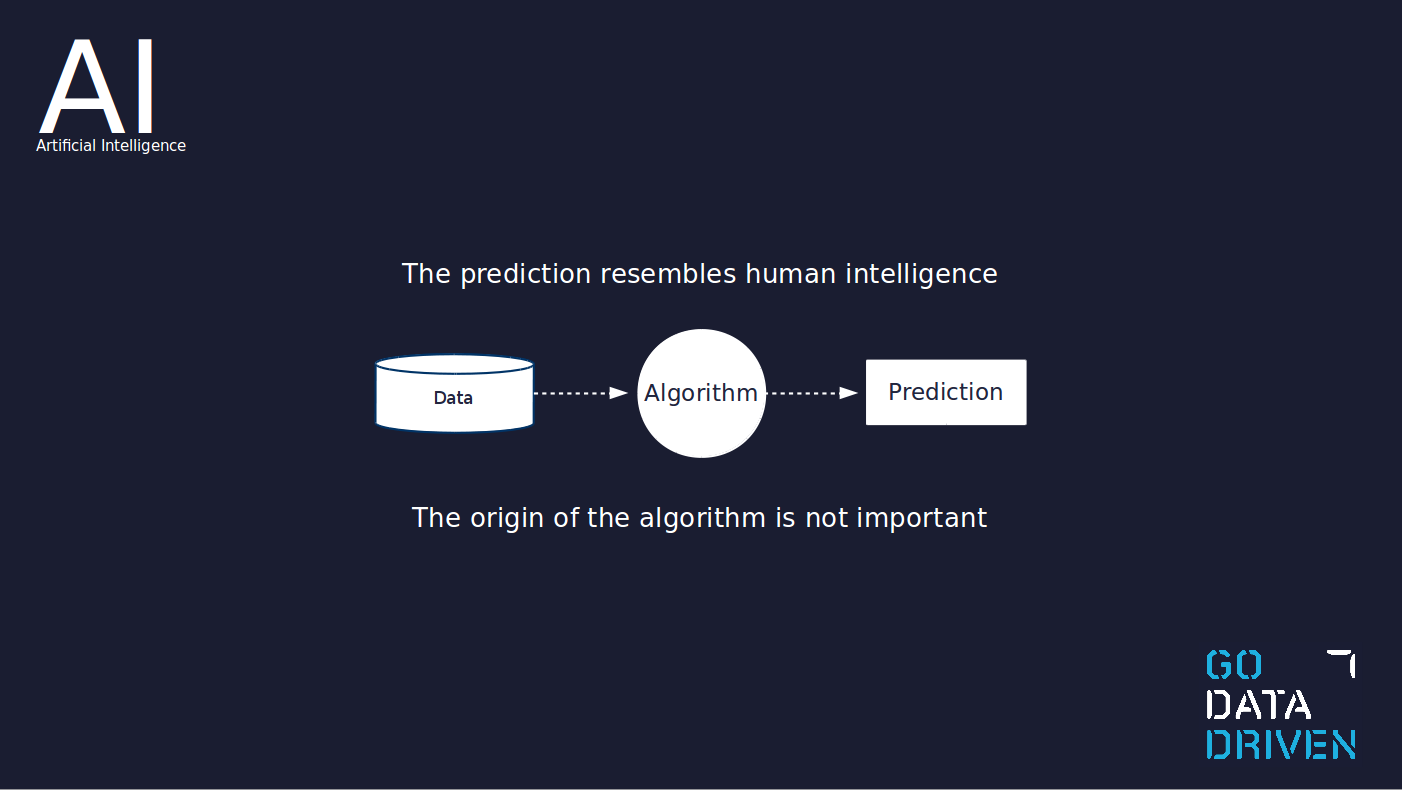
Maschinelles Lernen ist ein Konzept innerhalb der künstlichen Intelligenz. Arthur Samuel definierte den Begriff maschinelles Lernen 1959 als "die Fähigkeit zu lernen, ohne explizit programmiert zu werden". Die Grundidee ist, dass Daten in einen Lernalgorithmus einfließen und daraus ein Modell entsteht, das in der Lage ist, Vorhersagen für neue, noch nicht gesehene Daten zu treffen.
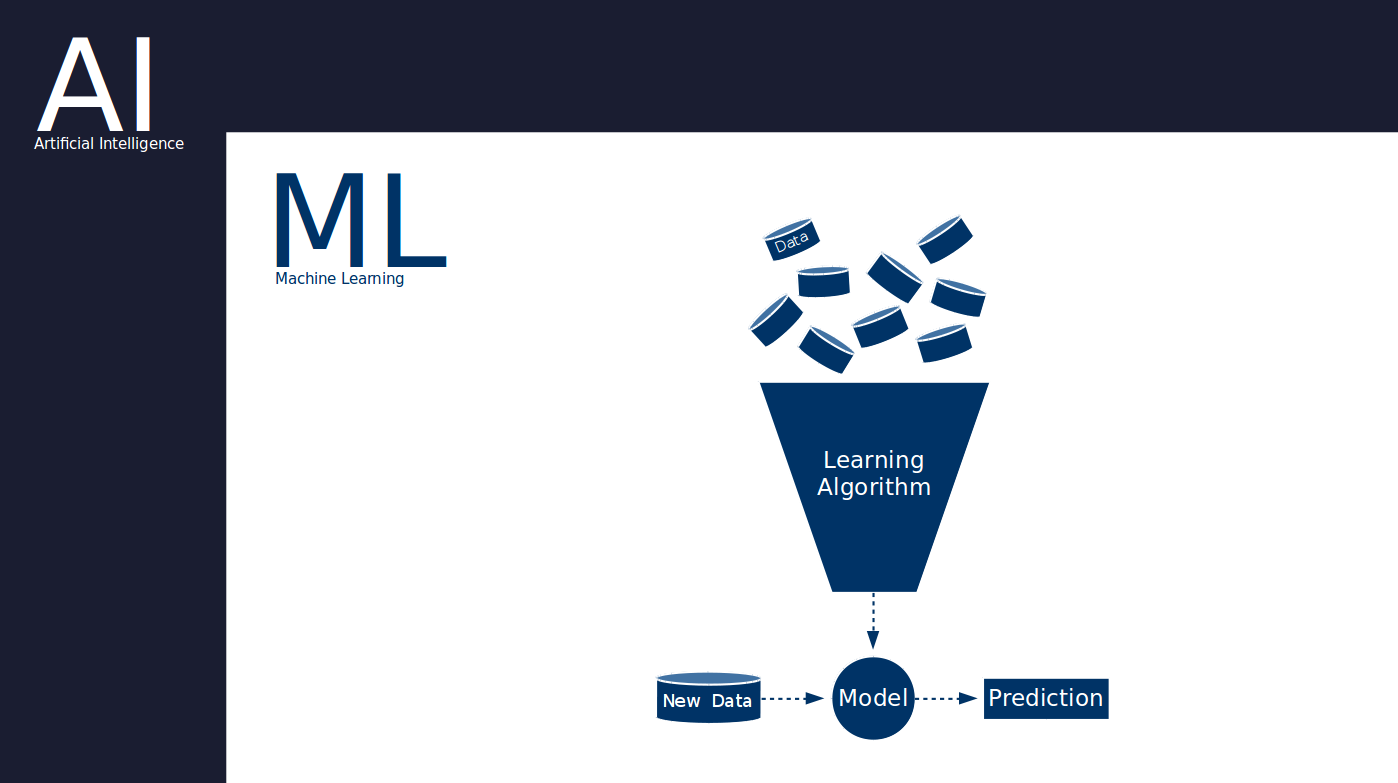
Deep Learning ist ein Konzept innerhalb des maschinellen Lernens und der künstlichen Intelligenz. Es verwendet Algorithmen für maschinelles Lernen, die vom menschlichen Gehirn inspiriert sind und die Konzepte von Neuronen oder Synapsen enthalten.

Ein Beispiel für künstliche Intelligenz, aber nicht für maschinelles Lernen, ist zum Beispiel ein Steuerrechner, der eine Aufgabe auf der Grundlage von Geschäftsregeln ausführt. Ein anderes Beispiel ist das berühmte Deep Blue, das 1996 den Schachchampion Garry Kasparov mit einem Brute-Force-Algorithmus besiegte.

Der alte Ansatz zur Erkennung von Spam-E-Mails, der auf der Naive Bayes-Technik basierte, ist ein Beispiel für maschinelles Lernen und nicht für Deep Learning; ich nenne ihn traditionelles maschinelles Lernen. Zusammenfassend lässt sich sagen, dass bei diesem Ansatz gezählt wird, wie oft ein Wort in einem Korpus bekannter Spam-E-Mails vorkommt, und dass eine neue E-Mail, die dieses Wort enthält, mit einer bestimmten Wahrscheinlichkeit als Spam eingestuft wird. Ein weiteres Beispiel für traditionelles maschinelles Lernen ist die Anwendung eines Modells (z.B. Random Forest) auf eine Reihe von technischen Merkmalen, um Vorhersagen zu treffen (z.B. die Vorhersage von Hauspreisen auf der Grundlage von Grundfläche, Anzahl der Zimmer, Lage usw.)

Ein Beispiel für Deep Learning ist Smart Reply, das 2017 in Google Mail eingeführt wurde. Smart Reply ist in der Lage zu verstehen, was in der E-Mail gesagt wird, und eine menschenähnliche Antwort vorzuschlagen, die dem Kontext der Konversation entspricht. Ein weiteres Beispiel für Deep Learning ist die Identifizierung des Subjekts in einer Beschreibung oder Rezension oder das jüngste Aushängeschild des Deep Learning, AlphaGo.
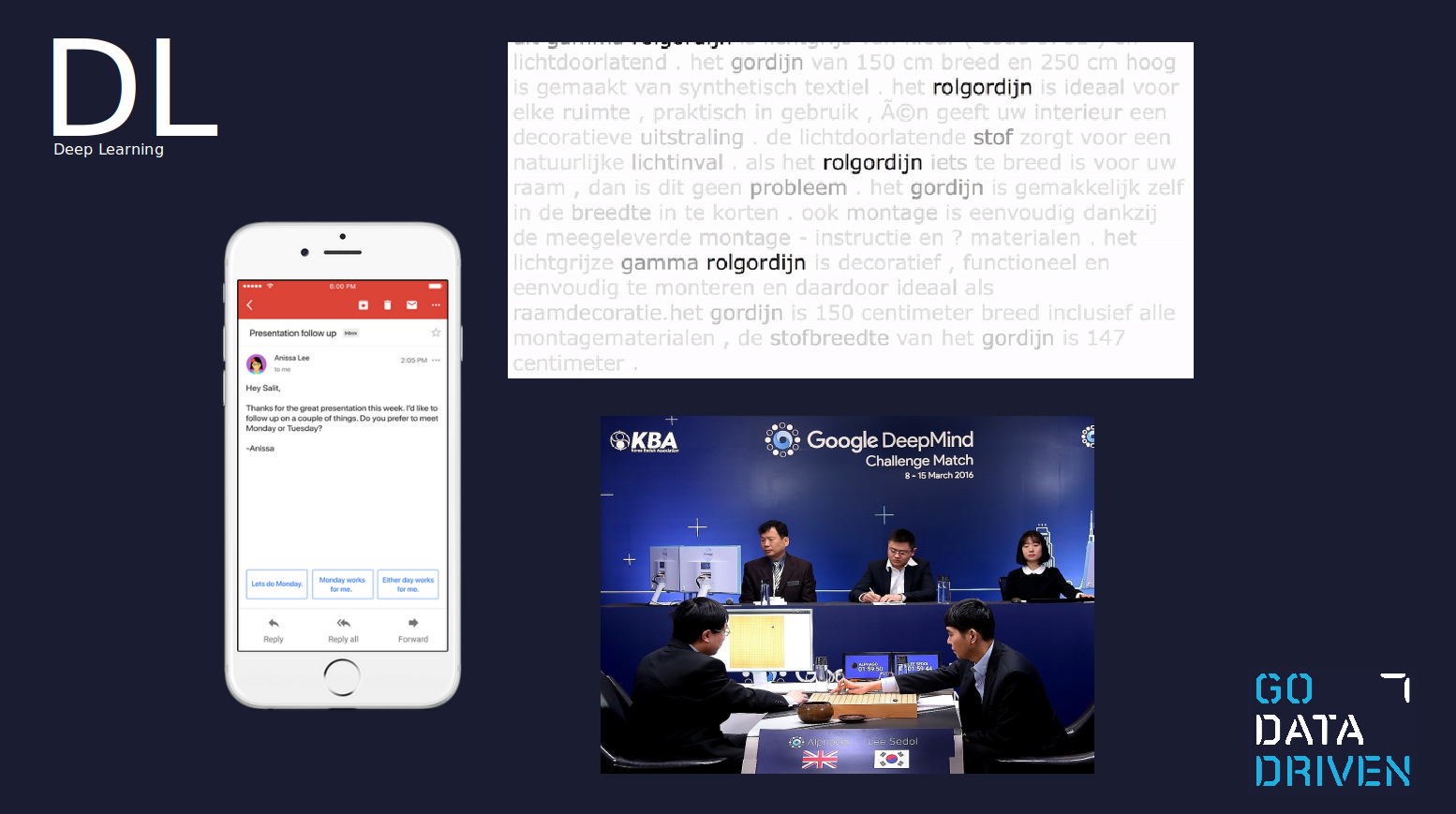
Traditionelles ML vs. Deep Learning
Traditionelles maschinelles Lernen erfordert die Erstellung von Merkmalen. Dies wird in der Regel von einem Datenwissenschaftler in Zusammenarbeit mit einem Fachexperten durchgeführt. Diese Merkmale müssen von einem Menschen ausgewählt oder fest kodiert werden.
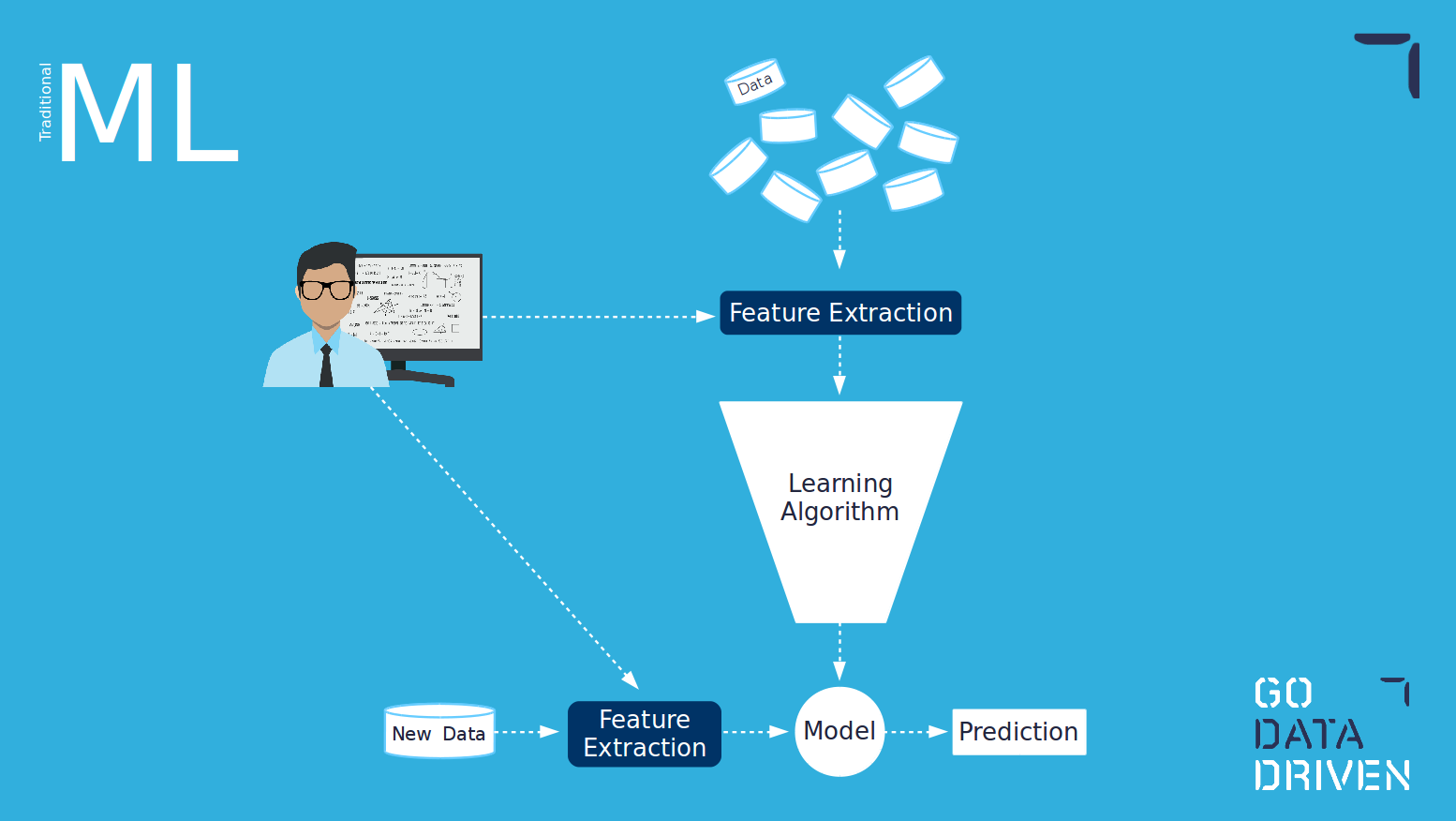
Andererseits müssen beim Deep Learning keine von Menschenhand geschaffenen Merkmale erstellt werden. Die Erstellung von Merkmalen erfolgt durch den Lernalgorithmus selbst. Einer der Vorteile von Deep Learning ist, dass der Algorithmus für Anwendungsfälle, in denen es nicht einfach ist, die zu verwendenden Merkmale zu erstellen oder zu identifizieren, diese für Sie herausfindet. Einer der Nachteile ist jedoch, dass diese Merkmale nicht unbedingt von Menschen interpretiert werden können, so dass es schwierig ist, zu erklären, wie das Modell arbeitet und warum es bestimmte Entscheidungen trifft. 3
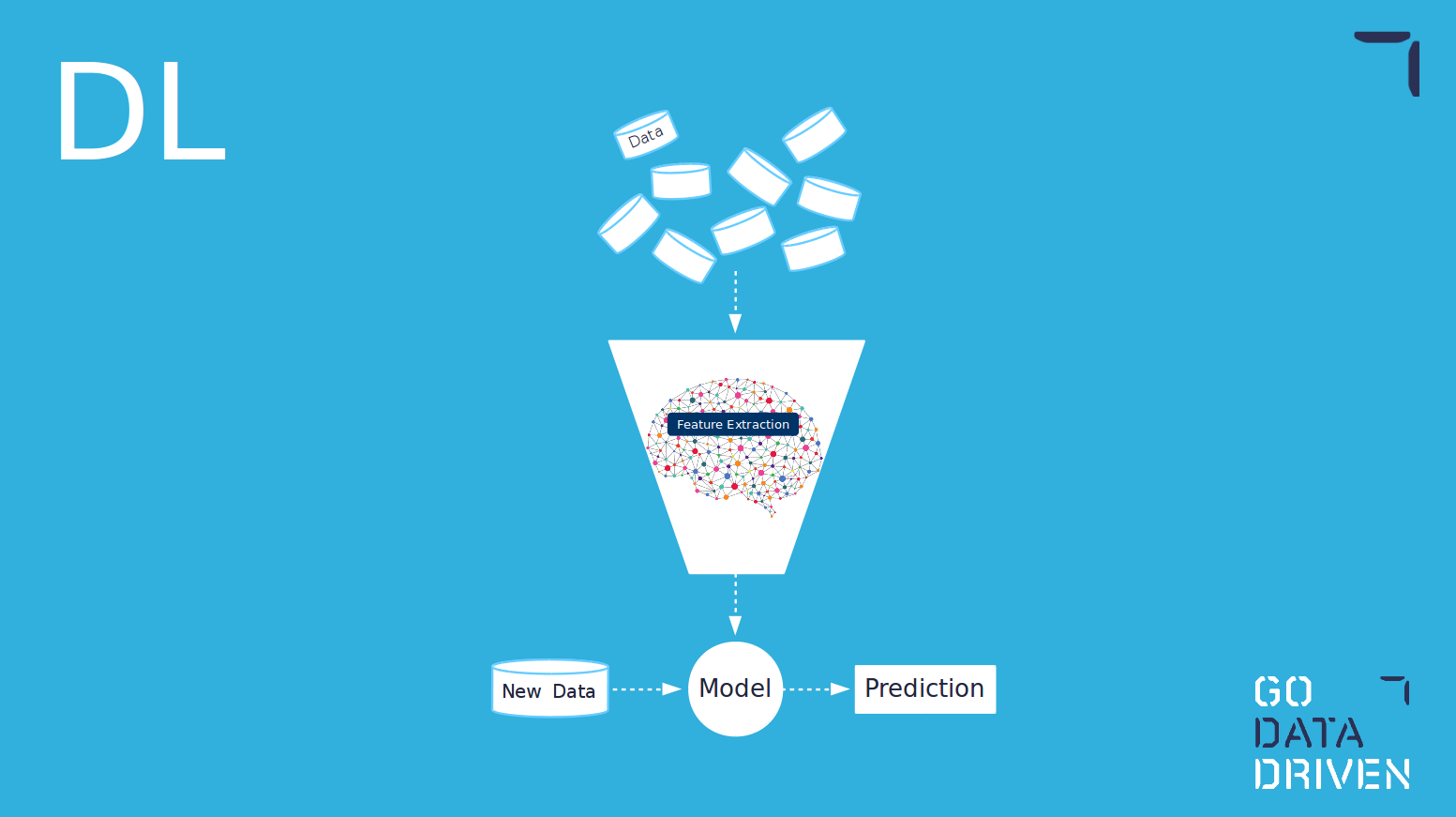
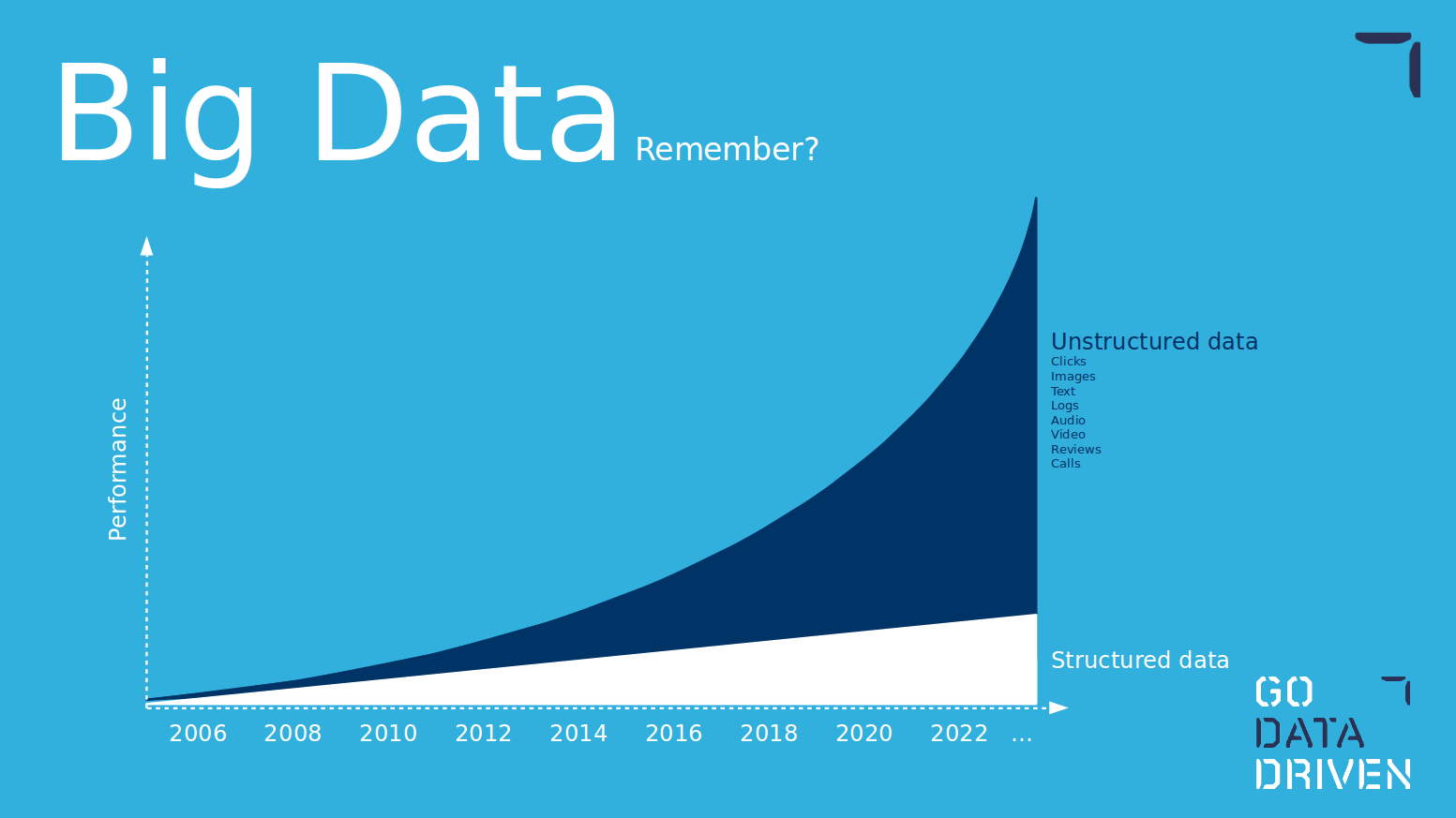
Erinnern Sie sich an die Grafik unten? Angesichts des Versprechens der Macht unstrukturierter Daten haben Unternehmen viel Aufwand und Ressourcen in die Einrichtung hochmoderner Umgebungen und Datenpipelines gesteckt. Deep Learning ist das richtige Werkzeug, um die Möglichkeiten unstrukturierter Daten voll auszuschöpfen. Wenn Sie herkömmliches maschinelles Lernen verwenden und Funktionen auf unstrukturierten Daten erstellen, verwandeln Sie diese im Grunde in strukturierte Daten und schöpfen den potenziellen Wert der Pipelines für unstrukturierte Daten nicht aus. Da unstrukturierte Daten immer dominanter werden, ist Deep Learning ein Muss in der Toolbox.
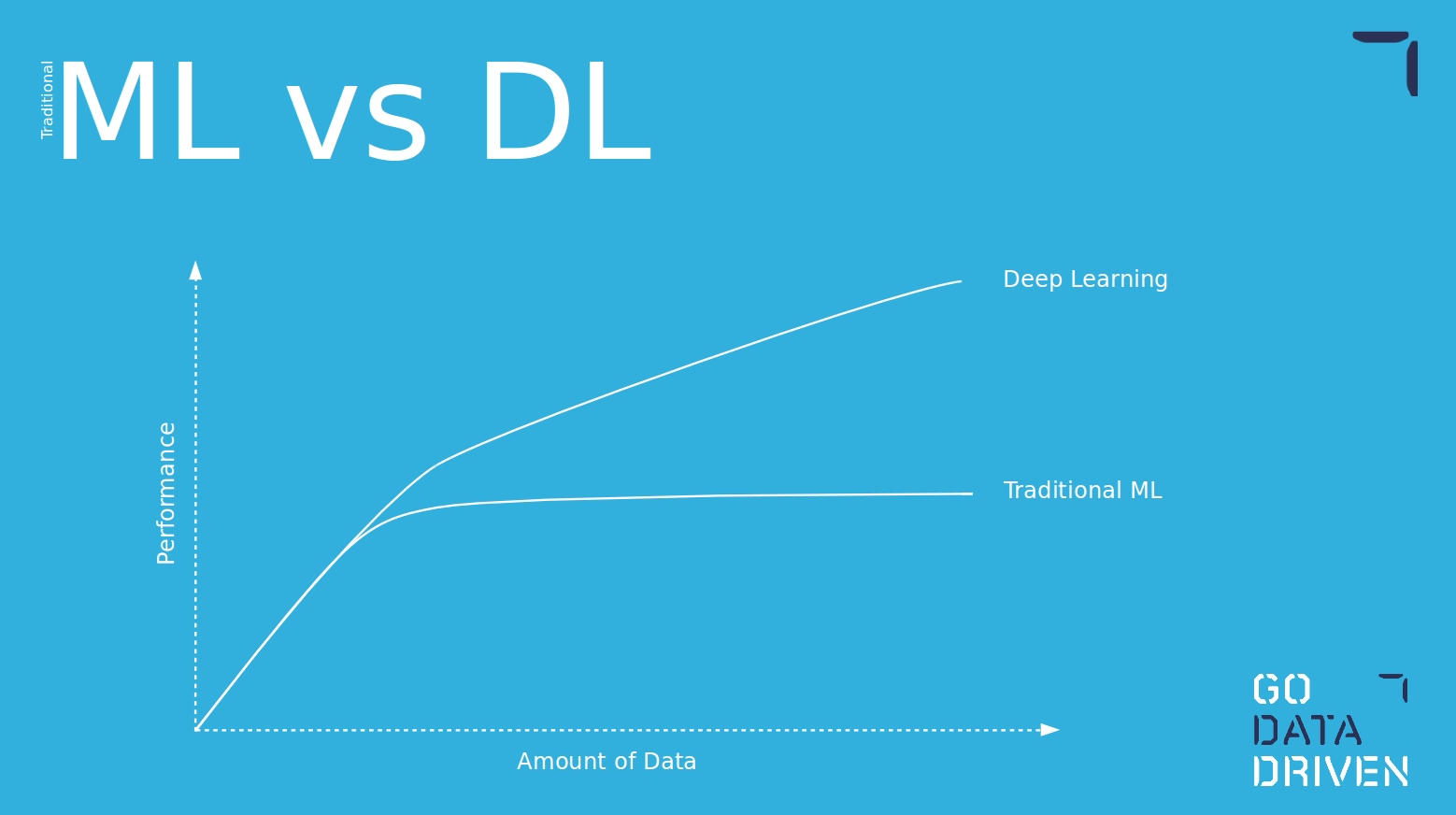
Ein weiterer Vorteil der Verwendung von Deep Learning-Modellen ist, dass die Modelle mit wachsender Datenmenge immer weiter lernen und komplexere Beziehungen innerhalb der Daten erfassen können.
DL-Ökosystem
Überwachtes Lernen ist wahrscheinlich das bekannteste Thema im Bereich des maschinellen Lernens und bezieht sich auf einen beschrifteten Datensatz zum Trainieren. Semi-überwachtes Lernen bezieht sich, wie der Name schon sagt, auf die Situation, in der nur ein Teil unseres Datensatzes beschriftet ist. Unüberwachtes Lernen liegt dann vor, wenn der gesamte Datensatz nicht beschriftet ist. Meistens besteht die Aufgabe nicht so sehr darin, etwas vorherzusagen, sondern Beziehungen in unseren Daten zu finden, indem wir die Wahrscheinlichkeitsverteilung der Daten modellieren.
Transferlernen ist meiner Meinung nach eine der nützlichsten Arten von Techniken für ein gemeinsames Projekt oder Unternehmen. Transferlernen besteht darin, ein Problem zu lösen und das gewonnene Wissen zur Lösung eines anderen Problems zu verwenden. Diese Probleme können sich je nach Datensatz unterscheiden, z.B. das Trainieren eines Modells zur Lösung eines Problems mit einem umfangreichen öffentlichen Datensatz und das anschließende Lösen desselben Problems mit einem kleineren Datensatz, der zu Ihrem Anwendungsfall gehört. Es kann sich auch um denselben Datensatz, aber zwei verschiedene Aufgaben handeln. Anstatt die Aufgaben getrennt zu lösen, verwendet der Algorithmus das Wissen aus der Lösung der einen Aufgabe für die andere. Transfer-Lernen verschafft im Wesentlichen einen Vorsprung bei der Lösung eines Problems.
Deep Reinforcement Learning ist eine ganz besondere Art von Technik. Sie besteht darin, eine Aufgabe zu lernen, indem man sie viele Male ausprobiert und aus fehlgeschlagenen und erfolgreichen Versuchen lernt. Der Ansatz ist vergleichbar damit, wie ein Kind das Fahrradfahren lernt. Die genauen Anweisungen sind so komplex, dass die einzige Möglichkeit zu lernen darin besteht, es auszuprobieren. Die Anwendungsfälle für Deep Reinforcement Learning erfordern in den meisten Fällen Simulatoren, da es kostspielig ist, viele Fehlversuche durchzuführen.4 Ich persönlich kenne nur wenige tatsächliche Geschäftsfälle für Deep Reinforcement Learning, aber es ist derzeit ein sehr heißes Thema und sicherlich auf dem neuesten Stand der Technik.
Meta-Lernen, auch bekannt als "Lernen zu lernen", untersucht die Fähigkeit des Menschen, neue Aufgaben zu lernen. Dieses Konzept ist eng mit dem heiligen Gral der KI verbunden: der künstlichen allgemeinen Intelligenz (AGI). Beim Meta-Lernen wird versucht, Modelle zu entwickeln, die in vielen verschiedenen Problemdomänen Intelligenz erreichen.
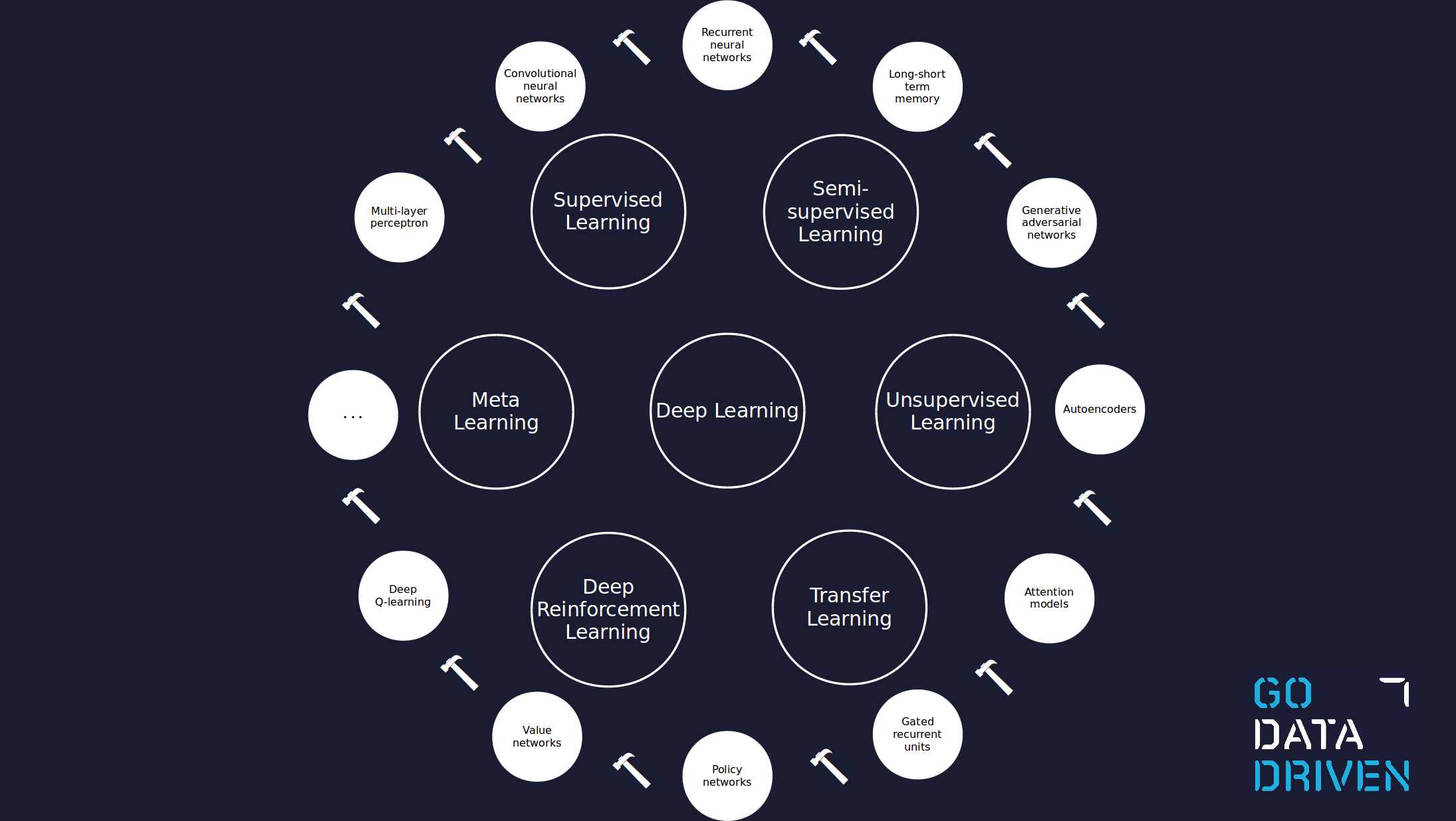
Im Bereich Deep Learning gibt es bereits viele Tools, von denen einige für eine bestimmte Art von Daten oder einen bestimmten Anwendungsfall entwickelt wurden. Die Abbildung unten zeigt einige davon, aber es gibt noch viel mehr und ihre Zahl wächst. Es besteht ein Bedarf an Deep Learning-Experten, die wissen, welche Tools für Ihren Anwendungsfall geeignet sind und wie man sie so abstimmt, dass sie ihre maximale Leistung erreichen.
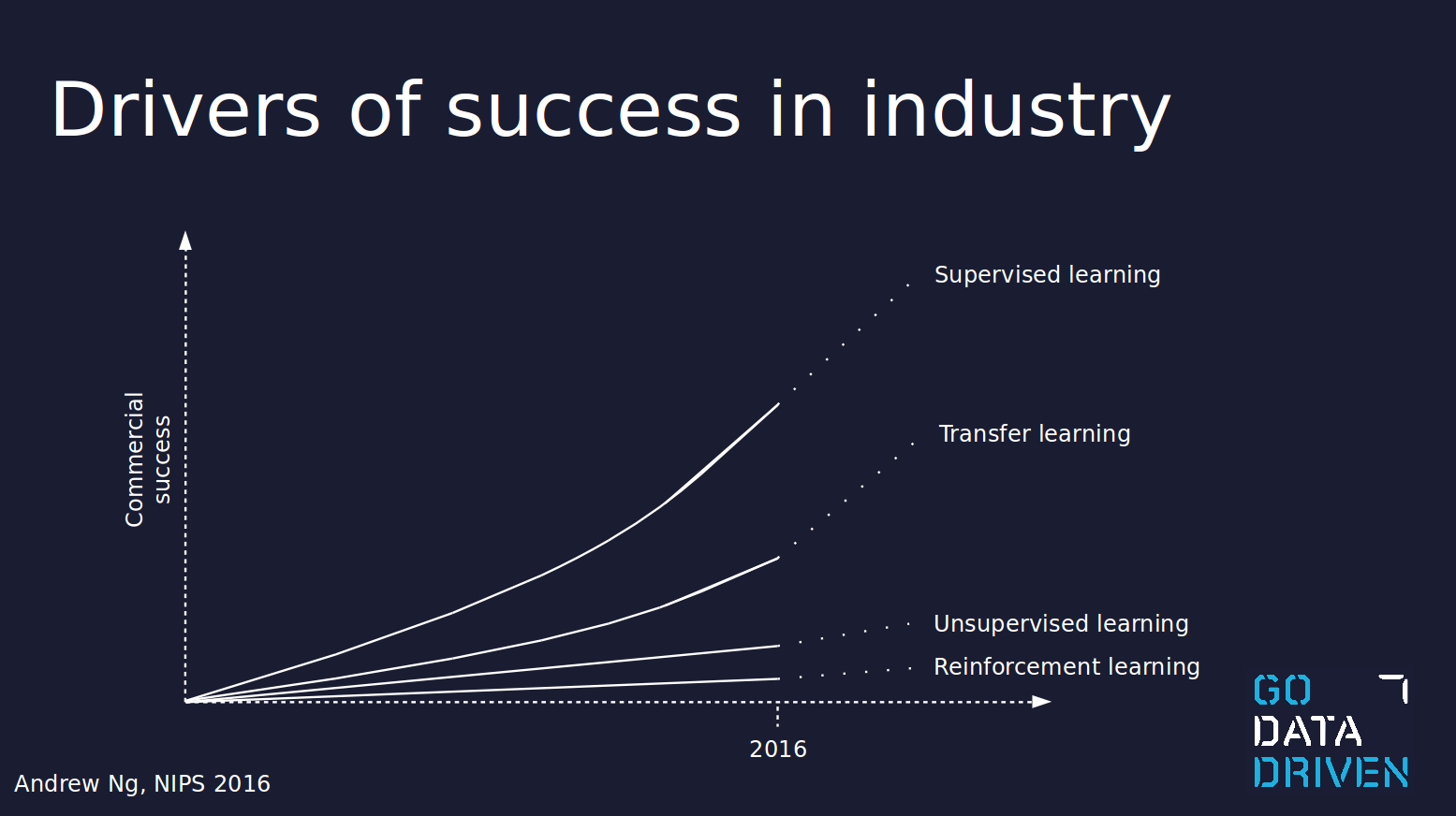
Die Business Cases werden derzeit hauptsächlich durch überwachtes Lernen vorangetrieben, wobei Transfer Learning für Unternehmen ohne die Ressourcen und das technische Know-how der Tech-Giganten sehr wichtig wird. Auch wenn die folgende Abbildung von Andrew Ng im Jahr 2016 präsentiert wurde, vermittelt sie doch ein klares Bild davon, wo die künstliche Intelligenz in der Industrie derzeit steht.
Einfach anfangen
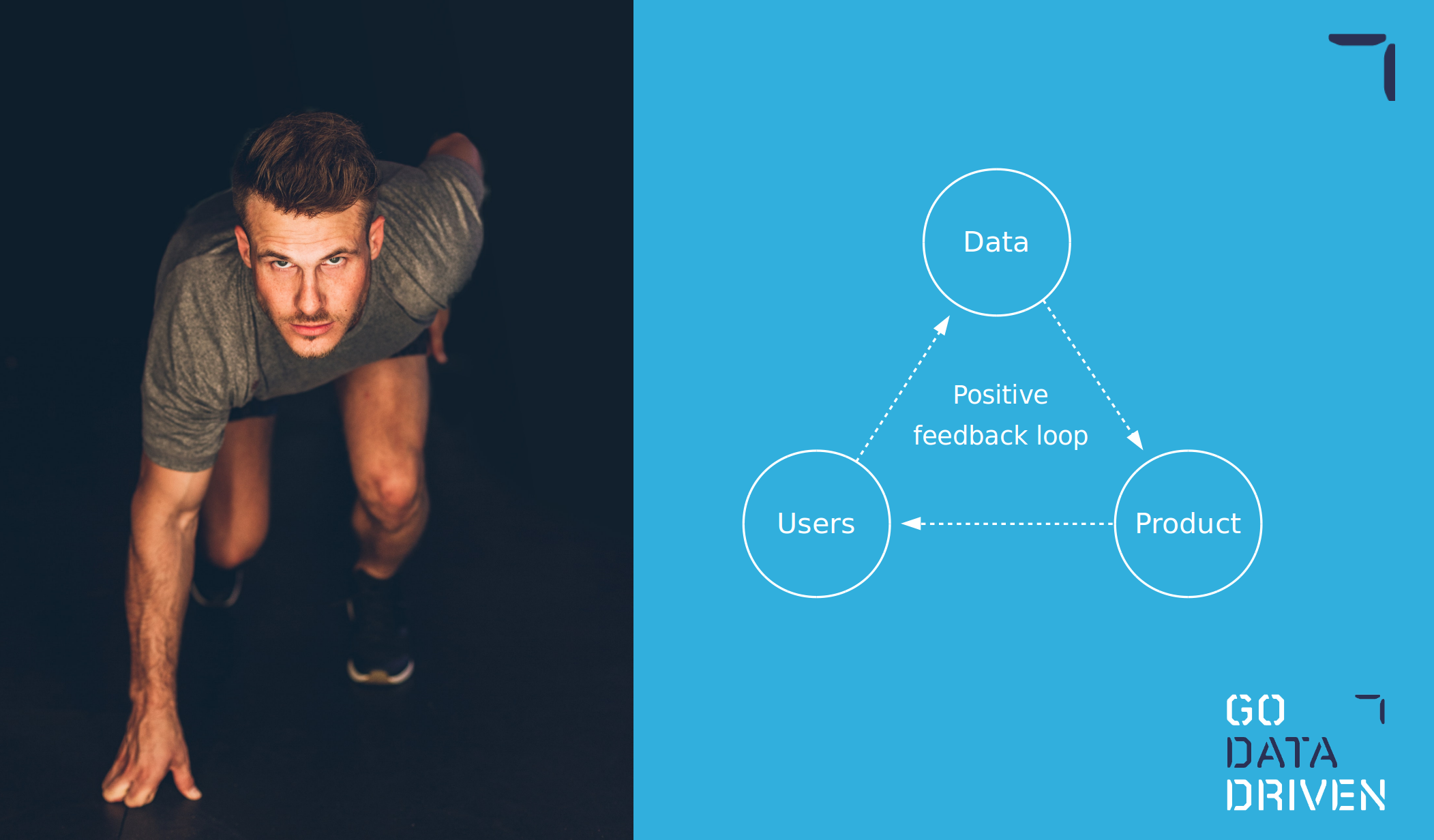
Man sagt, dass man für den Start eines Deep Learning-Projekts eine riesige Menge an Daten benötigt... das ist nicht unbedingt wahr! Wenn Sie eine Idee für ein KI-Unternehmen oder -Projekt haben, denken Sie daran, dass Sie nicht gleich zu Beginn einen Homerun erzielen müssen. Die Entwicklung eines KI-Projekts ist mit einer positiven Rückkopplungsschleife verbunden. So können Sie beispielsweise mit Hilfe von Transfer Learning bereits mit einer kleinen Datenmenge ein Minimum Viable Product entwickeln. Und wenn Ihre Idee angenommen wird und Nutzerdaten einfließen, können Sie ein immer besseres Modell entwickeln.
Ein gutes Beispiel dafür ist Blue River, das damit begann, Models anhand von Bildern zu trainieren, die sie mit ihren Smartphones aufgenommen hatten. Blue River wurde kürzlich für 300 Millionen an John Deer verkauft.
Der Wettbewerb um die Vorherrschaft der KI
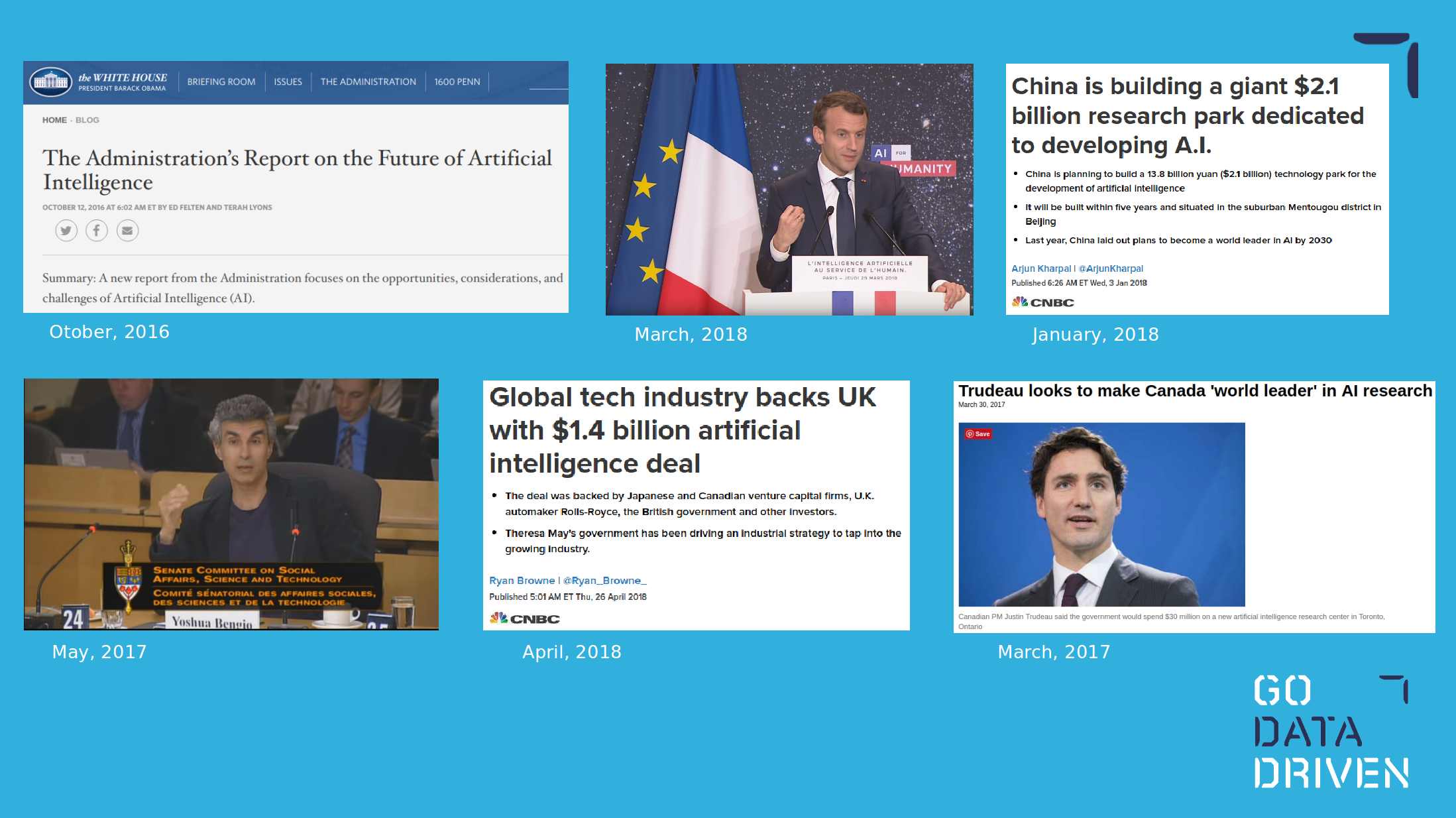
Abschließend möchte ich darauf hinweisen, dass es da draußen einen Krieg gibt. Viele der führenden Länder investieren massiv in KI-Forschungszentren oder KI-Unternehmertum, um die KI-Industrie in ihren Ländern anzukurbeln, aber auch, um KI- und Deep Learning-Talente zu halten. Ich persönlich lebe in den Niederlanden und bin manchmal enttäuscht über den Mangel an Visionen für eine KI-basierte Zukunft in diesem Land. Ich spreche hier mit KI-Startups mit großartigen Ideen, die mit so wenig Mitteln so viel erreichen, und wenn ich nach San Francisco fahre und den enormen Unterschied bei den Investitionen sehe, ist mir klar, wer am Ende an der Spitze stehen wird. Ich ermutige Regierungen, Risikokapitalgeber, Unternehmen und Investoren aus den Niederlanden, die KI-Situation rund um den Globus ernst zu nehmen.
Die vollständigen Folien finden Sie hier.
- Die Big Data Expo ist eine zweitägige Konferenz in den Niederlanden, die seit mehreren Jahren stattfindet und an der rund 5000 Besucher teilnehmen - und das Beste daran ist, dass sie kostenlos ist! Ich würde sagen, dass die Konferenz geschäftsorientiert ist und sich auf Anwendungsfälle, inspirierende Vorträge und die Zukunft von Big Data und KI in Unternehmen konzentriert.
- Hier finden Sie die Folien
- Es werden derzeit große Anstrengungen unternommen, um dieses Problem zu lösen. Wenn Sie interessiert sind, suchen Sie nach dem Thema "Destillation von Deep Learning"-Modellen.
- Denken Sie an selbstfahrende Autos: Sie wollen doch nicht bei jedem fehlgeschlagenen Versuch einen Unfall bauen!
Unsere Ideen
Weitere Blogs




Contact