
Am 5. Januar hat AWS eine neue CloudTrail-Komponente angekündigt, AWS CloudTrail Lake. Dabei handelt es sich um eine verwaltete Funktion, die aus verschiedenen AWS-Services besteht und eine benutzerfreundlichere Nutzung von CloudTrail ermöglicht. Vor CloudTrail Lake war das Einrichten von abfragbaren CloudTrail-Protokollen über Organisationskonten hinweg zwar nicht mühsam, aber doch etwas anstrengend und für mich nicht sehr sinnvoll.
Was ist AWS CloudTrail Lake?
Ich nehme an, Sie ahnen bereits, was CloudTrail Lake ist. Es abstrahiert CloudTrail Trails, S3 und Athena, indem es Ihnen eine Plattform bietet, auf der Sie Ihre CloudTrail-Daten speichern, abfragen und verwalten können. Was mir an CloudTrail Lake wirklich gefällt, ist die Tatsache, dass AWS die Möglichkeit geschaffen hat, dass Unternehmen ihre Protokolle über ihre AWS-Konten und mehrere Regionen hinweg an einem einzigen Ort zusammenfassen können. Das macht CloudTrail Lake zu einem Muss für Unternehmen, die zentralisierte Protokollierungskonten verwenden.
Den See einrichten
Es ist ziemlich einfach, einen CloudTrail Lake zu erstellen, da alles hinter einem so genannten Ereignisdatenspeicher abstrahiert wird. Sie können sich diesen Ereignisdatenspeicher als einen unveränderlichen Speichercontainer vorstellen, der einen CloudTrail-Trail umgibt.
aws create-event-data-store
--name my-cloudtrail-lake-data-store
--multi-region-enabled
--retention-period 365
--termination-protection-enabled
Sie können optional das Flag
--organization-enabledangeben, wenn Sie möchten, dass der Ereignisdatenspeicher Ereignisse sammelt, die für eine Organisation in Organizations protokolliert wurden.Die CLI sollte Ihnen folgendes zurückgeben:
{
"EventDataStoreArn": "arn:aws:cloudtrail:us-east-1:123456789012:eventdatastore/EXAMPLE-ee54-4813-92d5-999aeEXAMPLE",
"Name": "my-cloudtrail-lake-data-store",
"Status": "CREATED",
"AdvancedEventSelectors": []
"MultiRegionEnabled": true,
"OrganizationEnabled": false,
"RetentionPeriod": 365,
"TerminationProtectionEnabled": true,
"CreatedTimestamp": "2022-01-09T14:19:39.417000-05:00",
"UpdatedTimestamp": "2022-01-09T14:19:39.603000-05:00"
}
Das Kennzeichen --retention-period steht für die Aufbewahrung der Ereignisse im Ereignisdatenspeicher in Tagen. In Verbindung mit einem standardmäßigen Aufbewahrungsfenster von sieben Jahren hilft dies den Kunden, ihre Compliance-Anforderungen zu erfüllen.
Beachten Sie auch, dass die Antwort ein Array AdvancedEventSelectors enthält. Sie können optional die Unterstützung von Datenereignissen im Ereignisdatenspeicher konfigurieren. Datenereignisse bieten einen Einblick in die Ressourcenoperationen, die auf oder innerhalb einer Ressource durchgeführt werden, diese werden auch als Data Plane Operations bezeichnet. Denken Sie bei der Verfolgung von Datenereignissen in DynamoDB zum Beispiel an die API-Vorgänge
Zeit, die Badehose anzuziehen
Das war nur ein abgedroschener Wortwitz, Sie hätten Ihre SQL-Klamotten anziehen sollen. Ähnlich wie bei der Abfrage von CloudTrail-Protokollen über Athena verwenden Sie jetzt die CloudTrail Lake UI. Jeder Ereignisdatenspeicher ist mit einer ID verknüpft, die für die Abfrage erforderlich ist. Wenn Sie kein SQL-Guru sind wie ich, können Sie die Beispielabfragen nutzen, die Benutzern den Einstieg in das Schreiben von Abfragen für gängige Szenarien erleichtern sollen. (Ich mag SQL in vielerlei Hinsicht nicht, was die Orthogonalität betrifft, aber das ist ein Thema für einen anderen Artikel).
- Gehen Sie zu Ihrem Ereignisdatenspeicher (den Sie unter CloudTrail -> Lake in der AWS-Konsole finden).
- Weiter zum Editor.
- Kopieren Sie die folgende SQL-Abfrage, ändern Sie die
FROM, ersetzen Sie den Zeitbereich und führen Sie sie aus.
SELECT userIdentity, eventTime, eventName, awsRegion, sourceIPAddress FROM fc19d5bd-9dd5-4cbf-9071-4a7546954a7a
where eventTime > '2022-01-09 00:00:00.000' and eventTime < '2022-01-09 23:59:59.999'
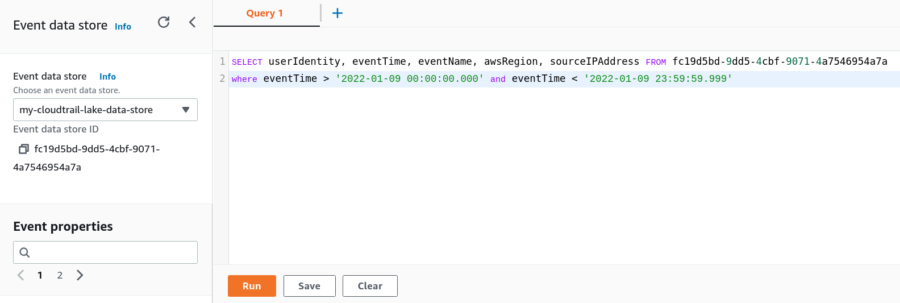
Oben links unter 'Ereignisdatenspeicher' finden Sie die ID des Ereignisdatenspeichers.
Nach dem Ausführen der Abfrage werden die Ergebnisse unten im Editor ausgegeben. Optional können Sie auf
Preferences(Zahnrad) klicken, um Spalten aus dem Ergebnis zu entfernen. Alle Abfragen, die Sie ausführen, werden in einer Historie gespeichert (für die letzten sieben Tage). Außerdem können Sie häufig verwendete Abfragen speichern, um sich etwas Zeit zu sparen.
Vorteile gegenüber 'Ereignisverlauf'
CloudTrail Lake-Abfragen bieten eine tiefere und besser anpassbare Sicht auf Ereignisse als der Ereignisverlauf oder die Ausführung von LookupEvents. Eine Suche im Ereignisverlauf ist auf ein einzelnes AWS-Konto beschränkt, liefert nur Ereignisse aus einer einzigen Region und kann nicht mehrere Attribute abfragen. CloudTrail Lake-Benutzer können Abfragen über mehrere Felder ausführen und CloudTrail Lake kann Ereignisse aus Ihrem Unternehmen in einem einzigen Ereignisdatenspeicher zusammenfassen und in allen Regionen gleichzeitig suchen.
Preisgestaltung
Bei CloudTrail Lake zahlen Sie für das Datenvolumen, das Sie aufnehmen, für das Datenvolumen, das Sie für die Analyse scannen, und für die Datenspeicherung, wenn Sie die Daten länger als 7 Jahre aufbewahren möchten. Neukunden können CloudTrail Lake 30 Tage lang ohne zusätzliche Kosten* testen. Während dieser Zeit haben Sie Zugriff auf den vollen Funktionsumfang.
-
Begrenzt auf 5 GB Ingestion und 5 GB gescannte Daten. Die Datenspeicherung ist kostenlos. Die Preise für das Einlesen und Speichern hängen vom Volumen ab:
-
Erste 5TB: $2,5 pro GB
- Nächste 20TB: $1 pro GB
- Über 25TB: $0,5 pro GB Bitte beachten Sie, dass die Abfragen von CloudTrail Lake pro GB gescannter Daten berechnet werden.
Verfasst von

Bruno Schaatsbergen
Bruno is an open-source and serverless enthusiast. He tends to enjoy looking for new challenges and building large scale solutions in the cloud. If he's not busy with cloud-native architecture/development, he's high-likely working on a new article or podcast covering similar topics. In his spare time he fusses around on Github or is busy drinking coffee and exploring the field of cosmology.
Unsere Ideen
Weitere Blogs




Contact