Blog
10 Tipps für die Migration von SAS Viya zu Snowflake + dbt

Foto von Stephen Phillips - Hostreviews.co.uk auf Unsplash
TLDR
- In diesem Blog teilen wir die wichtigsten Erkenntnisse aus unserem jüngsten Projekt zur Migration eines Kunden aus dem Sportsektor von SAS Viya auf Snowflake und dbt und geben praktische Tipps für eine reibungslosere Migration.
- Snowflake und dbt bieten dank ihrer Unterstützung für Versionskontrolle für SQL-Code, automatisierte Tests und Dokumentation eine leistungsstarke Kombination aus modernen Analysen.
- Wir besprechen praktische Tipps wie die Verwendung des Pakets dbt-audit-helper zum Vergleich migrierter Tabellen, die Herausforderungen von Lift-and-Shift gegenüber Remodeling und die Feinheiten inkrementeller Flows.
Ein wenig Hintergrund
Einer unserer Kunden aus der Sportbranche hatte sich bereits seit mehreren Jahren auf SAS Viya als primäre Analyseplattform verlassen. Die Plattform beherbergte mehr als 50 analytische Flows, die über mehrere Jahre hinweg aufgebaut worden waren und eine bedeutende Geschäftslogik und institutionelles Wissen darstellten. Diese Abläufe waren wichtig für die Entscheidungsprozesse des Unternehmens und die nachgelagerte Berichterstattung.
Herausforderungen mit SAS Viya
Als das Geschäft des Kunden wuchs, konnte die SAS Viya Plattform nicht mehr mit den sich entwickelnden Anforderungen Schritt halten. Die wichtigsten Einschränkungen wurden immer deutlicher:
- Fehlen einer robusten Versionskontrolle für den Analysecode
- Keine abgestufte Bereitstellung über mehrere Umgebungen hinweg
- Begrenzte Möglichkeiten für automatisierte Tests
- Schwierigkeiten bei der Skalierung zur Anpassung an wachsende Datenmengen
Diese Einschränkungen sind für viele Unternehmen bei der Skalierung ein großes Problem. Obwohl SAS Viya eine Plattform ist, die eine Reihe von Funktionen für die Visualisierung, die Datenabfolge und die Unterstützung mehrerer Programmiersprachen bietet, können die Datenteams von heute anspruchsvollere Entwicklungspraktiken erwarten, um ihre Analytics-Workloads skalieren und pflegen zu können.
dbt und Snowflake für moderne Datenteams
Welche Alternativen gibt es also für Datenteams, die mehr Entwicklungskontrolle wünschen? Nun, wenn Sie bereits mit Xebia Data vertraut sind, könnten Sie sagen, dass wir dbt wirklich mögen. Für diejenigen unter Ihnen, die das Tool (oder besser gesagt die Plattform, wenn wir über das verwaltete Angebot sprechen) nicht kennen: dbt ist ein Produkt von dbt Labs, das als Open-Source-Python-Paket begann. Es handelt sich im Wesentlichen um ein Framework, mit dem Sie SQL auf eine vernünftige und modulare Art und Weise schreiben können, was für Analysten sehr nützlich war, die sich durch ein Durcheinander von einzelnen SQL-Dateien kämpfen mussten. Im Laufe der Jahre hat es sich zu einer vollwertigen Plattform entwickelt. Aber heute konzentrieren wir uns auf das Open-Source-Paket dbt-core, das heute von vielen Datenteams verwendet wird.
Was uns an dbt gefällt, ist die Tatsache, dass es einen SQL-basierten Ansatz für den Aufbau von Datenanalyse-Pipelines bietet, mit Versionskontrolle, Tests und Dokumentation von Anfang an. Uns gefällt, dass dbt sowohl als produktionsreifes Open-Source-Paket verfügbar ist, mit dem Ihr Team sofort beginnen kann, als auch als verwaltete Cloud-Plattform für Teams, die einen Teil der Komplexität der modernen Softwareentwicklung auslagern möchten. Wir positionieren es als unser zentrales Datenumwandlungstool, wenn wir unser maßgeschneidertes Xebia Data-Plattformangebot bei Kunden einsetzen. Wir bieten auch interne Schulungen und Support für die Kunden von dbt Labs an. Letztes Jahr wurden wir sogar zum EMEA Services Partner des Jahres ernannt. Auch wenn wir vielleicht ein wenig voreingenommen sind, denken wir, dass wir das aus gutem Grund sind ;)
dbt lässt sich mit einer Vielzahl von Datenplattformen verbinden, ist also nicht an eine bestimmte Datenplattform gebunden. In diesem Fall hatte sich der Kunde bereits für Snowflake als Datenplattform entschieden. Eine beliebte Wahl, da es sich um ein vollständig verwaltetes Data Warehouse handelt, das hoch skalierbar ist und neben einer robusten Zugriffskontrolle auch erstklassige Datenanalysefunktionen bietet. Wir sind nicht voreingenommen (na ja, vielleicht sind es einige von uns), aber wir mögen Snowflake aus diesen Gründen. Also keine schlechte Wahl. In Kombination mit den zuvor genannten Funktionen von dbt war dies eine solide Wahl für unseren Kunden.
Vergleich der Fähigkeiten zur Datenentwicklung
| Aufgabe | SAS Viya | dbt + Schneeflocke |
|---|---|---|
| Versionskontrolle | ❌ Begrenzte, oft manuelle Prozesse | ✅ Native Git-Integration mit Branch-Management und CI/CD-Funktionen |
| Testen | ❌ Manuelle Validierung, benutzerdefinierte Skripte erforderlich | ✅ Integrierte Datenqualitätstests (Eindeutigkeit, nicht-null, Beziehungen, benutzerdefiniertes SQL) |
| Dokumentation | ❌ Oft getrennt vom Code, manuelle Pflege | ✅ Selbstdokumentierende Modelle mit integrierter Dokumentation, die mit dem Code aktualisiert wird |
| Visualisierungen | ✅ Robuste integrierte Dashboarding- und Visualisierungsfunktionen | ❌️ Begrenzte native Visualisierungsoptionen; erfordert in der Regel separate BI-Tools |
Die Migration
Die Lösung bestand darin, die grundlegenden Workloads auf Snowflake zu migrieren, gepaart mit dbt (Data Build Tool) für Transformationen. Diese Kombination würde die erforderliche Skalierbarkeit und moderne Entwicklungsfunktionen bieten, während der Kunde SAS Viya für nachgelagerte Analysen und Berichte beibehalten konnte, wo sich das Team wohl fühlte.
Unser Team, bestehend aus zwei Analytikern und einem unterstützenden Dateningenieur, machte sich auf eine sechsmonatige Migrationsreise, nach der wir die restliche Arbeit an das interne Team des Kunden übergeben würden. Die erheblichen Unterschiede zwischen dem Ansatz von SAS Viya und SQL-basierten Plattformen wie Snowflake erforderten eine sorgfältige Planung und Ausführung.
Wichtige Erkenntnisse und Tipps
Hier sind also die wichtigsten Erkenntnisse und Tipps, die wir nach 6 Monaten der Migration gesammelt haben:
Tipp 1: Heben und Verschieben vs. Umgestalten
Die Migration von Daten-Workloads bringt eine wichtige Entscheidung mit sich: Sollen Sie bestehende Modelle und Logik unverändert übernehmen und verschieben oder die Gelegenheit nutzen, das Datenmodell von Grund auf neu zu gestalten?
Lift-and-Shift ist der Begriff für die Übertragung eines Systems auf eine neue Plattform ohne Änderung des zugrunde liegenden Codes. Bei einer Datenmigration bedeutet dies, dass man versucht, das ursprüngliche Datenmodell und die Geschäftslogik so weit wie möglich beizubehalten. Wir stellen jedoch häufig fest, dass Datenmodelle im Laufe der Zeit immer chaotischer und komplexer werden, so dass sie schwer zu pflegen und zu debuggen sind. Oft ist nicht eine einzelne Person daran schuld, denn die Datenmodelle sind in der Regel das Ergebnis der kollektiven Arbeit eines Teams im Laufe der Zeit und des Aufbaus von Komplexität. Bei Datenmigrationen kann eine Lift-and-Shift-Methode ein schneller Erfolg sein, aber sie kann auch eine Quelle versteckter Probleme sein, die schwer zu beheben sind.
Ein "umgestaltender" Ansatz bietet die Möglichkeit, wartungsfreundlichere Designs wie das von Ralph Kimball populär gemachte Dimensional Model zu implementieren. Aufgrund seiner (relativen) Einfachheit ist es bei Analysten und Geschäftsanwendern gleichermaßen beliebt. Mehr über das Dimensional Model erfahren Sie in Tais Blog oder in der dbt-Implementierung. Es ist eine solide Strategie, die wir unzählige Male für unsere Kunden umgesetzt haben und auch in absehbarer Zukunft umsetzen werden.
Der Umbau bringt jedoch seine eigenen Herausforderungen mit sich:
Herausforderung 1: Anforderungen an das Fachwissen Eine effektive Umgestaltung erfordert ein tiefes Verständnis des Geschäftsbereichs. Migrationsentwicklern kann dieses Wissen fehlen, was den Fortschritt verlangsamt. Die Modellierung ist nicht einfach, da sie Erfahrung, Domänenwissen und Bauchgefühl kombiniert. In unserem Fall ging es um die Modellierung von Sportdaten im Data Warehouse. Einige der Fragen, die wir diskutierten, waren: "Sollten die Spielerstatistiken auf Spielebene modelliert oder saisonal aggregiert werden? Oder vielleicht beides? Und wie sieht es mit der Mannschaftszugehörigkeit eines Spielers aus? Sollten sie als sich langsam verändernde Dimensionen behandelt werden, um zu verfolgen, wann Spieler gehandelt werden? Oder wie wäre es mit der Speicherung von Schiedsrichterentscheidungen als Teil eines Spiels, oder sollte man sie lieber als separate Fakten verfolgen? Die Entscheidungen, die wir trafen, beruhten in hohem Maße auf Gesprächen mit den Analysten, die die Daten verwendeten, wobei wir versuchten, ein Gleichgewicht zwischen der Einfachheit des Datenmodells und der Abdeckung von Randfällen herzustellen. Das ist nie eine leichte Aufgabe.
Herausforderung 2: Probleme mit der Datenqualität Bei der Umstrukturierung treten oft Probleme mit der Datenqualität zutage, deren Lösung Fachwissen erfordern kann. Bei einem "Lift-and-Shift"-Verfahren können wir davon ausgehen, dass die Daten, unabhängig von ihrer Qualität, einfach von der alten in die neue Datenbank verschoben werden sollten. Aber beim "Remodel"-Ansatz bauen wir aktiv ein neues, manche würden sogar sagen "besseres" Modell auf. Was aber, wenn die Grundlagen Probleme mit der Datenqualität haben? Um diese Probleme zu lösen, sind oft Fachkenntnisse erforderlich, über die die migrierenden Entwickler nicht verfügen und die von den internen Experten des Kunden eingebracht werden müssen.
Herausforderung 3: Ausweitung des Umfangs Sobald die Umgestaltung beginnt, können die Beteiligten zusätzliche Funktionen verlangen: "Da Sie Tabelle X ändern, könnten Sie Funktion Y hinzufügen?" Dies ist eine häufige Anfrage, aber es ist nicht immer möglich, neue Funktionen zu einem bestehenden Modell hinzuzufügen. Sie müssen entscheiden, ob Sie die neue Funktion in das bestehende Modell einbauen oder ein separates Modell erstellen.
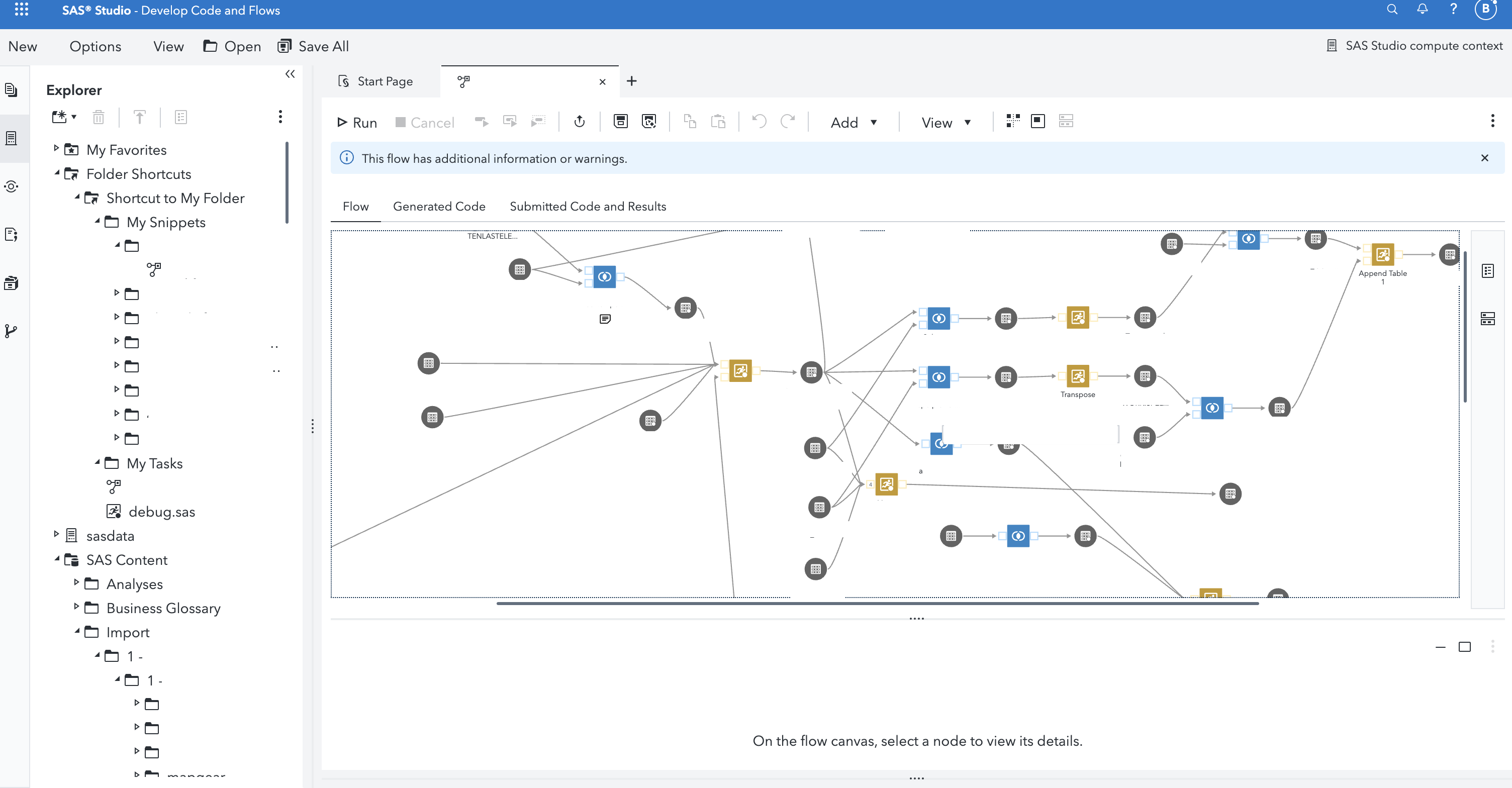
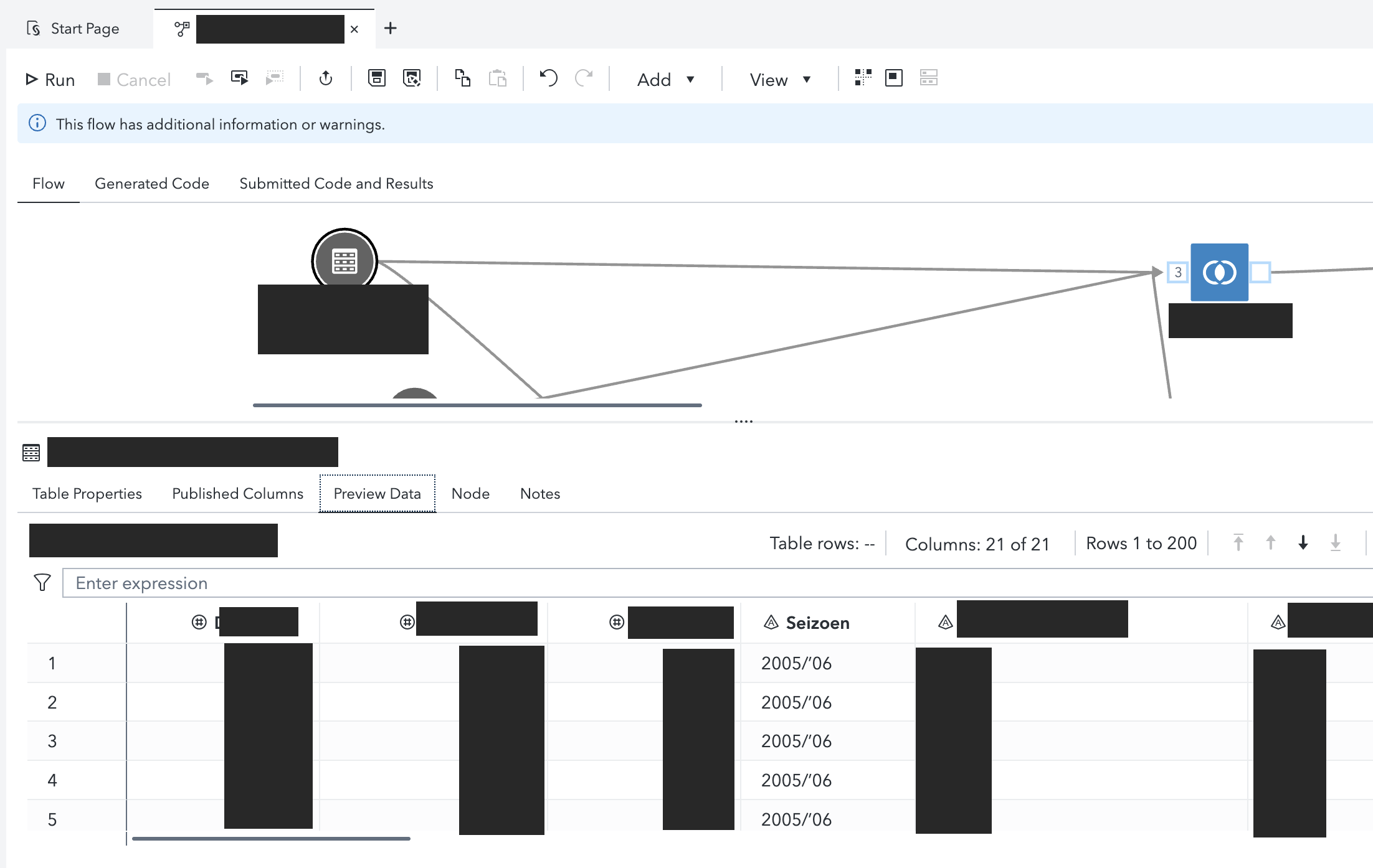
Die obige Abbildung zeigt, wie komplex SAS-Flows im Laufe der Zeit werden können, so dass sie ohne sorgfältige Planung nur schwer zu pflegen und zu migrieren sind.
Tipp 2: Implementieren Sie Tools zum Tabellenvergleich
Bei der Migration der Geschäftslogik von SAS zu Snowflake ist die Validierung von entscheidender Bedeutung. Der manuelle Vergleich von Tabellen mit Millionen von Zeilen ist unpraktisch und fehleranfällig. Bei Tabellen mit Millionen von Zeilen und mehreren Spalten reicht ein "Nur-Augen-Prinzip" einfach nicht aus.
Das Paket dbt-audit-helper war für diese Aufgabe von unschätzbarem Wert. Sein Makro compare_all_columns hilft dabei, Unterschiede zwischen den ursprünglichen SAS-Tabellen und unseren neu erstellten dbt-Modellen zu erkennen. Wir fanden dieses Makro besonders hilfreich - damit können Sie das Makro auf zwei Tabellen (oder dbt-Modelle) richten und sehen, wo sie sich unterscheiden.
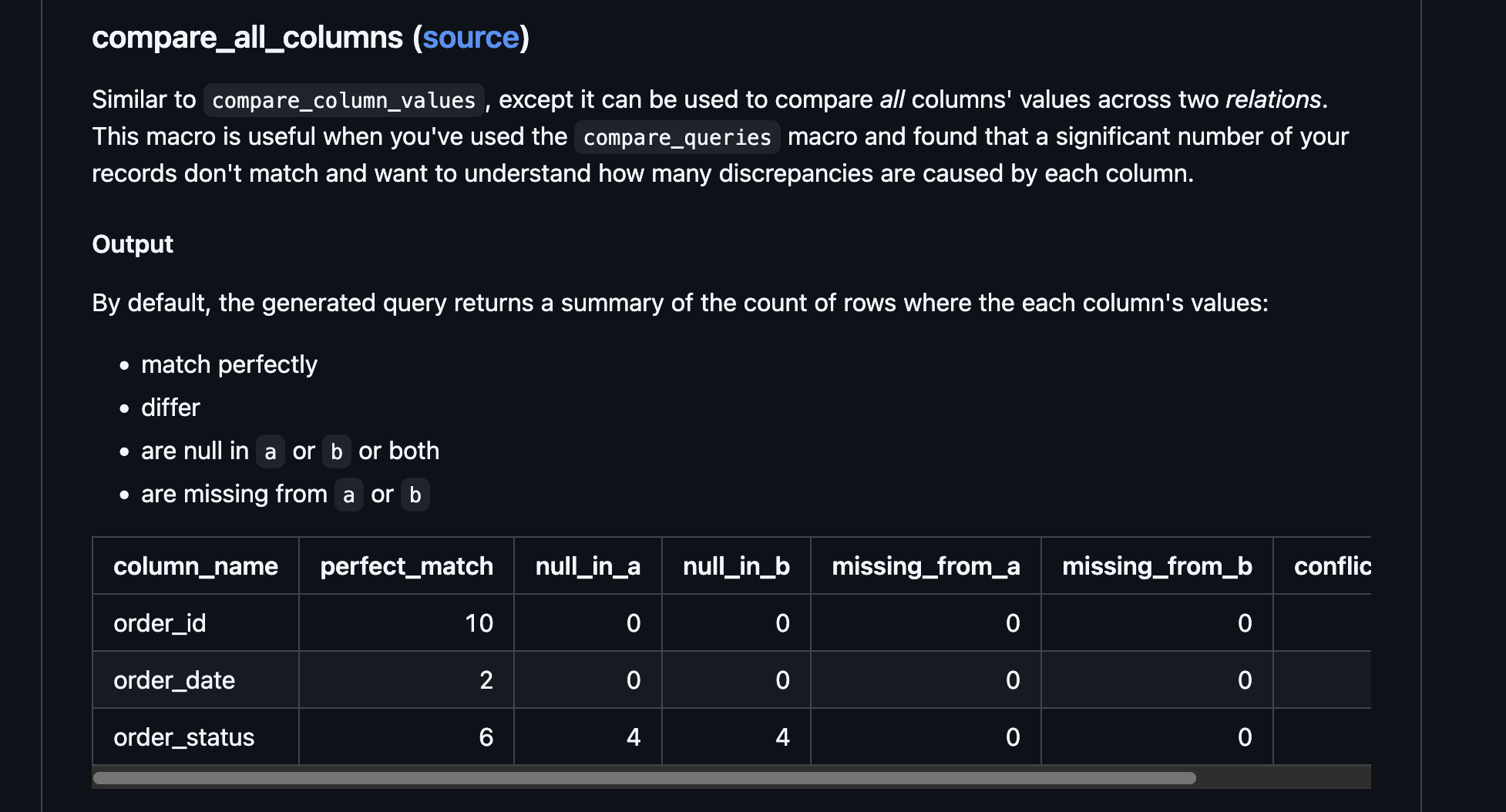
Unser Ansatz war:
- Kopieren Sie die ursprüngliche SAS-Tabelle nach Snowflake
- Erstellen Sie das entsprechende dbt-Modell in Snowflake
- Verwenden Sie das Vergleichstool, um Diskrepanzen zu erkennen und zu beheben.
Wir haben sogar das Makro compare_all_columns angepasst, um es etwas verständlicher zu machen, obwohl das Makro inzwischen auch im Paket aktualisiert wurde und recht intuitiv erscheint.
Eine weitere Option, die Sie sich ansehen sollten, ist dbt-data-diff, das speziell für Snowflake- und dbt-Benutzer entwickelt wurde und von einem Datenberatungsunternehmen namens infinitelambda stammt. Für uns war dbt-audit-helper jedoch mehr als ausreichend.
Ohne ein Vergleichstool müssen Sie die Tabellen manuell überprüfen und die Ergebnisse vergleichen. Dies ist ein zeitaufwändiger Prozess und kann fehleranfällig sein. Ein Vergleichstool kann Ihnen bei dieser Aufgabe helfen und Ihnen viel Zeit ersparen.
Tipp 3: Komplexe SAS-Flows mit Variablen debuggen
Ein häufiges Problem in SAS-Flows ist das Überschreiben von Variablen. In vielen Abläufen sind wir auf Codemuster gestoßen, bei denen dieselbe Variable mehrfach neu zugewiesen wurde:
/* Example of problematic SAS code with variable overwriting */
DATA results;
/* First calculation */
SET input_table;
revenue = sales * price;
RUN;
DATA results;
/* Second calculation overwrites previous results */
SET results;
profit = revenue - cost;
RUN;
DATA results;
/* Third calculation overwrites again */
SET results;
margin = profit / revenue;
RUN;
Dieser Codierungsstil ist zwar funktional, kann aber die Fehlersuche erschweren, da Zwischenergebnisse überschrieben werden. Für SAS-Abläufe gibt es kein Debugging über Haltepunkte, so dass Zwischenergebnisse verloren gehen und nur das Endergebnis verfügbar ist. Zur Fehlersuche bei diesen Abläufen müssen Sie den gesamten Prozess ausführen und die Ausgabe der Ausführung untersuchen.
Unsere Lösung bestand darin, eine Kopie des Ablaufs in einem Entwicklungsordner zu erstellen und den Code zu ändern, um Zwischentabellen zu erhalten:
/* Improved SAS code with unique variable names */
DATA results_step1;
/* First calculation preserved */
SET input_table;
revenue = sales * price;
RUN;
DATA results_step2;
/* Second calculation builds on previous without overwriting */
SET results_step1;
profit = revenue - cost;
RUN;
DATA results_final;
/* Final calculation with all intermediates preserved */
SET results_step2;
margin = profit / revenue;
RUN;
Tipp 4: Mischen von SQL und SAS-Logik in den SAS-Flows
Eine der größten Herausforderungen bei der Migration war der Umgang mit Flows, die SQL mit SAS-spezifischer Logik kombinierten. Anstatt nur SQL-Logik zu verwenden, die einfacher auf Snowflake und dbt zu portieren ist, kann die SAS-Sprache auch für Dinge verwendet werden, die in SQL nicht möglich oder sehr schwierig sind, wie z.B.:
- Schleifen über Datensätze mit
DOSchleifen - Ausführen von Fensterfunktionen mit
LAGin der SAS-Sprache - Benutzerdefinierte Codeknoten mit SAS-spezifischer Syntax
Dies erhöht die Komplexität der SAS-Flows und der Migration, da diese Logik in einfaches SQL umgewandelt oder mit der Jinja-Logik von dbt erweitert werden muss.
Die Lösung: Gehen Sie einen Schritt zurück und untersuchen Sie die Absicht der SAS-Logik. Ist es möglich, dasselbe Ergebnis auch mit SQL zu erreichen? Anstatt die Logik einfach zu portieren, könnten wir das gleiche Ergebnis auch mit einem anderen Ansatz erreichen.
Tipp 5: SAS Flow-Abhängigkeiten entwirren
In SAS können die Bewegungen voneinander abhängen. So kann beispielsweise Ablauf A eine Ausgabetabelle erstellen, die Ablauf B als Eingabe liest. Tatsächlich kann die von Ablauf A erstellte Ausgabetabelle eine beliebige Anzahl von nachgelagerten Abhängigkeiten haben, einschließlich Dashboards.
Dies muss sorgfältig bedacht werden. Wenn Sie einen SAS-Flow durch ein dbt-Modell ersetzen, aber die Ausgabetabellen nicht dieselben sind, könnte dies die nachgelagerten Flows oder Dashboards zerstören. Glücklicherweise bietet SAS Viya ein Tool, um diese Abhängigkeiten zu verfolgen.
Die Lösung: Verwenden Sie die leistungsstarke Lineage-Funktion von SAS, um die Abhängigkeiten zwischen Datenströmen zu verstehen. In der Lineage-Übersicht können Sie nach verschiedenen Datensätzen und Datenströmen suchen und die vorgelagerten (vorher) und nachgelagerten (nachher) Abhängigkeiten sehen.
Bei der Migration der Abläufe werden wir neue Tabellen in Snowflake erstellen und wir möchten wissen, welche Abläufe/Dashboards von diesen Tabellen abhängen. Eine nette Funktion im Lineage-Tool ist die Filterung nach "Datensätzen". In der Suche nach Objekten können Sie nach Tabellen suchen und dann die Asset-Typen "In-Memory", "CAS-Tabelle" und "SAS-Tabelle" auswählen. Einmal ausgewählt, können Sie die entsprechenden Objekte anzeigen:
Die Lösung: Nutzen Sie die leistungsstarke Lineage-Funktion von SAS, um die Abhängigkeiten zwischen Datenströmen zu verstehen. In der Lineage-Übersicht können Sie nach verschiedenen Datensätzen und Datenströmen suchen und die vorgelagerten (vorher) und nachgelagerten (nachher) Abhängigkeiten sehen.
Tipp 6: Machen Sie sich mit der SAS Vorschau-Filterung vertraut
Beim Debuggen von Unterschieden zwischen dem dbt-Modell und dem ursprünglichen SAS-Flow werden Sie oft den Flow öffnen und Teile davon ausführen wollen, um herauszufinden, warum die Datensätze unterschiedlich sind. Dazu können Sie die Vorschaufunktion in SAS verwenden. Hier können Sie die Datensätze filtern (ähnlich wie bei der WHERE Klausel in SQL), z.B. season = '2025'. Beachten Sie jedoch, dass es einige Probleme mit den Typen gibt, da das Filtern eines Datumsstrings in SAS durch Hinzufügen von 'd' zum String gecastet werden muss: season = '2025'd.
Tipp 7: Achten Sie auf die dbt-Datentests
In den SAS-Flows gab es keine Eindeutigkeits- oder Nulltests. Wenn Sie damit nicht vertraut sind, sehen Sie sich die dbt-Dokumentation zu Datentests an. Diese "Datentests" validieren die Daten in Ihren Tabellen. Eine Tabelle sollte IMMER einen Primärschlüssel haben (der aus mehreren Spalten bestehen kann), und dieser Schlüssel sollte NIEMALS ungültig sein. Dies ist im Wesentlichen das erste Gebot der Datenanalyse. Die Befolgung dieses Prinzips gewährleistet die Einzigartigkeit von Datensätzen und verhindert doppelte Datensätze (die in der Regel die Erznervensäge eines Analyseingenieurs sind).
JEDOCH kann die Aufdeckung bereits bestehender Datenqualitätsprobleme extrem zeitaufwändig sein. Das Hinzufügen von unique und not_null Tests ist zwar eine bewährte Praxis im dbt (und in der Analysetechnik allgemein), kann aber eine Lift-and-Shift-Migration erheblich verlangsamen. Wir haben viel Zeit damit verbracht, Probleme mit der Datenqualität in den Datensätzen zu entdecken. Das ist normal, und das Testen verbessert letztendlich Ihre Datenqualität. Entscheiden Sie jedoch im Voraus, ob die Behebung dieser Probleme in den Rahmen Ihrer Migration fällt.
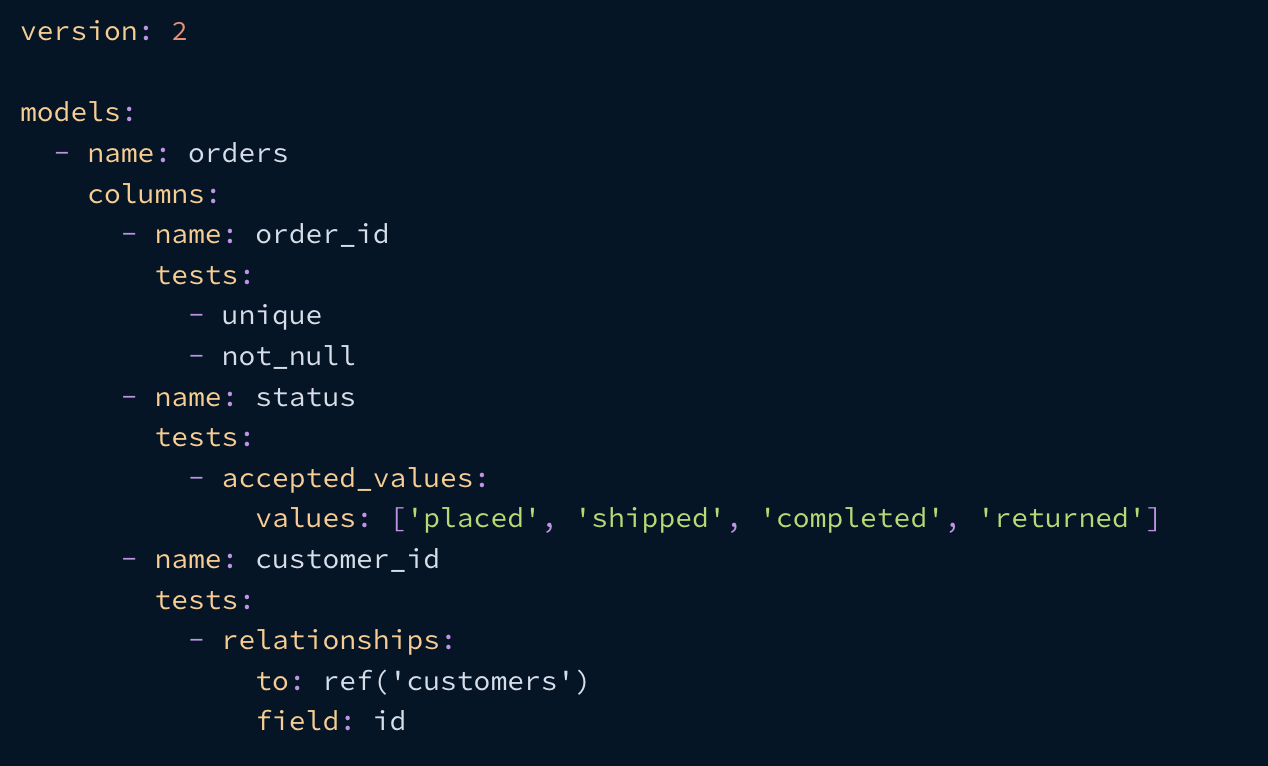
Wenn Sie eine "Lift-and-Shift"-Datenmigration durchführen, sollten Sie sich darüber im Klaren sein, dass die Implementierung von dbt's data_tests (im Gegensatz zu unit_tests, die eine ganz andere Herausforderung darstellt) Ihren Fortschritt wahrscheinlich verlangsamen wird, da fehlgeschlagene Tests angesprochen oder absichtlich ignoriert werden müssen. Bevor Sie beginnen, sollten Sie Ihre Verantwortlichkeiten für die Migration klären: Wird von Ihnen erwartet, dass Sie Probleme mit der Datenqualität beheben, oder sollten Sie sich ausschließlich darauf konzentrieren, die Zahlen aus dem ursprünglichen System abzugleichen, selbst wenn diese Inkonsistenzen enthalten? Es gibt zwar keine pauschale Antwort, aber wir bei Xebia Data sind der festen Überzeugung, dass Probleme mit der Datenqualität die Hauptursache für Probleme bei der Berichterstattung sind und wann immer möglich erkannt, angegangen und verhindert werden sollten.
Tipp 8: Umgang mit echten Löschungen in Quellsystemen
Die Quelldaten, mit denen wir arbeiteten, wurden in wöchentlichen inkrementellen Stapeln geliefert, d.h. wir erhielten nur die neuesten Daten aus dem Quellsystem. Irgendwann während der Migration stellten wir jedoch fest, dass ein bestimmter Datensatz nicht viel Sinn machte, da einige Datensätze doppelt vorhanden waren, wo sie nicht sein sollten, wodurch unsere Primärschlüsseltests in dbt fehlschlugen.
Dies führte uns zu der Erkenntnis, dass die Benutzer des Quellsystems tatsächlich einige Datensätze gelöscht hatten (auch als "echte Löschungen" bezeichnet). Dabei handelte es sich nicht um einen Fehler, sondern um eine Funktion des Quellsystems. Da diese Löschungen jedoch nicht mit uns synchronisiert wurden, da wir nur jede Woche neue Datensätze erhielten. Dies führte zu einer Diskrepanz in den Daten, sowohl in SAS als auch in dbt. Solange unsere Daten von diesen Löschungen "nichts wussten", konnten wir dieses Problem nicht beheben und konnten diese Datensätze nur filtern, da wir wussten, dass sie nicht korrekt waren.
Hier ist ein vereinfachtes Beispiel, um das Problem anhand von Sportdaten zu veranschaulichen:
Woche 1: Erste Spielerdaten im Quellsystem
| player_id | player_name | team_name | season |
|-----------|-------------------|-----------|--------|
| 1001 | Dumky De Wilde | Xebia FC | 2025 |
| 1002 | Lasse Benninga | Xebia FC | 2025 |
| 1003 | Jovan Gligorevic | Xebia FC | 2025 |
Woche 1: Unser Data Warehouse nach dem ersten Laden
| player_id | player_name | team_name | season |
|-----------|-------------------|-----------|--------|
| 1001 | Dumky De Wilde | Xebia FC | 2025 |
| 1002 | Lasse Benninga | Xebia FC | 2025 |
| 1003 | Jovan Gligorevic | Xebia FC | 2025 |
In Woche 2 wechselte Lasse Benninga zu einem anderen Team und wurde aus dem Xebia FC-Kader im Quellsystem entfernt. Unser inkrementeller Ladeprozess erhält jedoch nur neue oder geänderte Datensätze, keine Informationen über Löschungen.
Woche 2: Aktuelle Daten im Quellsystem
| player_id | player_name | team_name | season |
|-----------|-------------------|-----------|--------|
| 1001 | Dumky De Wilde | Xebia FC | 2025 |
| 1003 | Jovan Gligorevic | Xebia FC | 2025 |
| 1004 | Ricardo Granados | Xebia FC | 2025 | <- New player added
Woche 2: Inkrementeller Export, den wir erhalten
| player_id | player_name | team_name | season |
|-----------|-------------------|-----------|--------|
| 1004 | Ricardo Granados | Xebia FC | 2025 | <- Only new records
Woche 2: Unser Data Warehouse nach dem inkrementellen Laden
| player_id | player_name | team_name | season |
|-----------|-------------------|-----------|--------|
| 1001 | Dumky De Wilde | Xebia FC | 2025 |
| 1002 | Lasse Benninga | Xebia FC | 2025 | <- Problem! Player was removed in source
| 1003 | Jovan Gligorevic | Xebia FC | 2025 |
| 1004 | Ricardo Granados | Xebia FC | 2025 |
Wie Sie sehen können, zeigt unser Data Warehouse immer noch Lasse Benninga in der Mannschaft an, obwohl dieser Spieler aus dem Quellsystem entfernt wurde. Dies führt zu Problemen bei der Verknüpfung mit anderen Tabellen (z.B. Spielstatistiken) oder bei der Durchführung von Primärschlüsseltests in dbt.
Lösung: Regelmäßige vollständige Synchronisierung aller Daten
Wenn wir stattdessen eine vollständige Synchronisierung durchführen, würde unser Data Warehouse den aktuellen Stand der Mannschaftsaufstellung korrekt wiedergeben:
| player_id | player_name | team_name | season |
|-----------|-------------------|-----------|--------|
| 1001 | Dumky De Wilde | Xebia FC | 2025 |
| 1003 | Jovan Gligorevic | Xebia FC | 2025 |
| 1004 | Ricardo Granados | Xebia FC | 2025 |
In dbt können Sie dies umsetzen, indem Sie regelmäßig (z.B. wöchentlich oder monatlich) eine vollständige Aktualisierung Ihrer inkrementellen Modelle einplanen, um sicherzustellen, dass Ihre Daten mit dem Quellsystem synchronisiert bleiben.
Lösung: Fordern Sie regelmäßige vollständige Synchronisierungen der Quelldaten an, um sicherzustellen, dass Sie mit dem Quellsystem auf dem Laufenden bleiben. Die Lektion lautet: Wenn Sie inkrementelle Exporte aus einem Quellsystem erhalten, das Löschungen zulässt, müssen Sie regelmäßig vollständige Synchronisierungen durchführen, um echte Löschungen korrekt zu verarbeiten.
Tipp 9: Berücksichtigen Sie inkrementelle SAS-Flows sorgfältig
Neben den inkrementellen Datenladungen enthielten die SAS-Flows selbst auch "inkrementelle Logik". Einfach ausgedrückt bedeutet dies, dass bei der Ausführung eines Flusses nicht ALLE Daten in der Quelltabelle gelesen und verarbeitet werden, sondern nur eine Teilmenge - zum Beispiel where season = '2025', um nur die letzte Saison zu lesen, oder insert_date >= last_run_date, um nur die seit dem letzten Lauf eingefügten Datensätze zu verarbeiten. Dieser Ansatz ist besonders wertvoll für große Datensätze, deren Verarbeitung viel Zeit in Anspruch nimmt, da Sie nicht die gesamte Tabelle lesen müssen, wenn Sie sich nur für die neuesten Daten interessieren.
Ähnlich wie bei der inkrementellen Last sollten Sie jedoch regelmäßig vollständige Synchronisationen in Betracht ziehen, um der "Abwanderung der Geschäftslogik" entgegenzuwirken. Dies ist ein komplexeres Thema, daher soll ein Beispiel helfen.
Nehmen wir an, Sie haben eine Sportmannschaft namens Xebia, die drei Saisons hintereinander gespielt hat. Nun wird in der neuen Saison eine Regel eingeführt, die besagt, dass ein Team immer den Ländercode an den Namen anhängen muss (dummes Beispiel, ich weiß, aber bleiben Sie bei mir). Gut, denken wir. Wir fügen es dem Ablauf hinzu, so dass der Ländercode dem Namen vorangestellt wird. Nachdem wir also den verbesserten Fluss ausgeführt haben, heißt unser Team in der Saison 2025 'Xebia NL' statt 'Xebia'. Und da wir den Fluss nur inkrementell ausführen, d.h. wenn wir den Fluss ausführen, würden wir nur die Daten der aktuellen Saison laden und diese Saison in der Ausgabetabelle überschreiben, lautet der Teamname der vorherigen Saison immer noch 'Xebia'.
Betrachten Sie nun die Migration dieses Flusses nach Snowflake und dbt: Da wir die aktuelle, aktuelle Geschäftslogik in den SAS-Fluss migrieren werden, wird sie das Voranstellen des Ländercodes beinhalten. Wenn wir dann die Daten der aktuellen Saison mit denen der migrierten Snowflake-Tabelle vergleichen, werden sie übereinstimmen. Wenn wir die Daten der vorherigen Saisons vergleichen, wird dies jedoch nicht der Fall sein, da in unserer neuen Snowflake-Tabelle für jede Saison 'Xebia NL' anstelle von 'Xebia' wie in der ursprünglichen SAS-Tabelle steht. Das ist ein Problem, denn wenn wir die Tabellen vergleichen wollen, können wir das nicht tun, da die Daten nicht übereinstimmen werden.
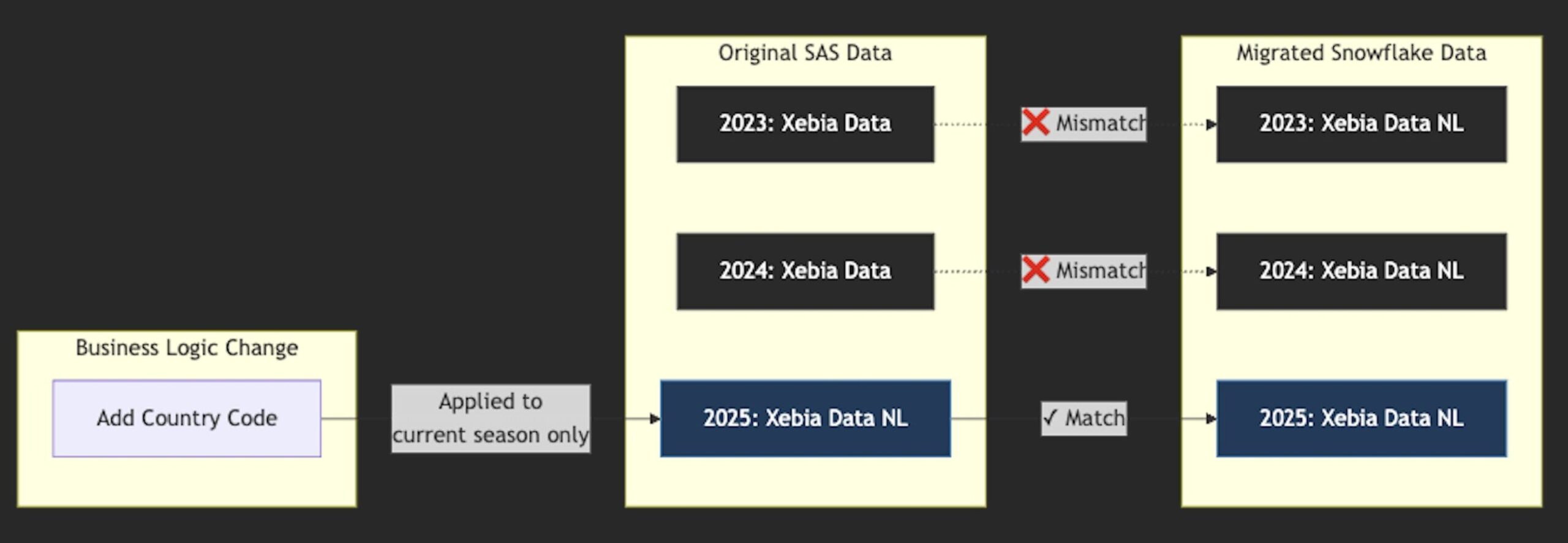
Diese Frage ist schwierig, da es mehrere Optionen gibt und eine Entscheidung auf der SAS-Seite getroffen werden muss:
-
Option 1: Führen Sie eine vollständige Synchronisierung auf der SAS-Seite durch. Dadurch wird der gesamte Verlauf mit der AKTUELLEN Geschäftslogik überschrieben. Abhängig von der Art der Logik ist dies möglicherweise nicht das, was Sie wollen, da Sie die Historie effektiv löschen. Wenn Sie dies tun, sollten Sie vorsichtshalber eine Kopie der älteren Partitionen (Jahreszeiten) aufbewahren, die Sie überschreiben werden. Der Vorteil ist, dass Sie die Snowflake-Tabelle mit den SAS-Tabellen abgleichen können, da sie nun dieselben Daten ergeben sollten, da die Geschäftslogik aktualisiert wurde.
-
Option 2: Um die Historie zu bewahren, sollten Sie sie nicht überschreiben, indem Sie eine vollständige Synchronisierung im SAS-Flow durchführen. Dies bedeutet jedoch, dass wir die historischen Werte nicht replizieren können, da die Geschäftslogik verloren gegangen ist (und selbst wenn wir in den SAS-Änderungsprotokollen zurückgehen könnten, könnte dies je nach Anzahl der bisherigen Änderungen eine gewaltige Aufgabe sein). Ein pragmatischer Ansatz besteht darin, die älteren Partitionen (Saisons) in ein separates Snowflake-Modell zu migrieren und dieses mit dem neuesten dbt-Modell (der aktuellen Saison) zu UNIONieren. Dokumentieren Sie auch die Unterschiede zwischen den beiden Modellen, damit das Team in Zukunft darauf achten kann. Ziehen Sie in Erwägung, von nun an regelmäßige vollständige Synchronisierungen für das neue inkrementelle dbt-Modell durchzuführen (natürlich ohne die separaten historischen Daten zu überschreiben).
Tipp 10: Historie für überschriebene Daten aufbewahren
Dies führte zu einem Problem, wenn eine Sportmannschaft in eine andere Abteilung wechselte und die vorherige Abteilungszugehörigkeit während des wöchentlichen SAS-Flowlaufs überschrieben wurde.
Ohne dbt-Snapshots (normale Tabelle - nur aktueller Stand):
-- Regular table only shows the current state
SELECT * FROM teams WHERE team_id = '1234';
| team_id | team_name | division_id | division_name | updated_at |
|---------|-----------|-------------|---------------|----------------------|
| 1234 | Xebia Data | DIV_C | Division C | 2025-03-15 09:45:00 |
Mit dbt-Schnappschüssen (Erhaltung der Historie als SCD Typ 2):
-- dbt snapshot table preserves the complete history
SELECT
team_id,
team_name,
division_id,
division_name,
updated_at,
dbt_valid_from,
dbt_valid_to
FROM team_division_snapshot
WHERE team_id = '1234'
ORDER BY dbt_valid_from;
| team_id | team_name | division_id | division_name | updated_at | dbt_valid_from | dbt_valid_to |
|---------|-----------|-------------|---------------|----------------------|----------------------|----------------------|
| 1234 | Xebia Data | DIV_A | Division A | 2025-01-10 14:30:00 | 2025-01-10 14:30:00 | 2025-02-05 10:15:00 |
| 1234 | Xebia Data | DIV_B | Division B | 2025-02-05 10:15:00 | 2025-02-05 10:15:00 | 2025-03-15 09:45:00 |
| 1234 | Xebia Data | DIV_C | Division C | 2025-03-15 09:45:00 | 2025-03-15 09:45:00 | null |
Lösung: Verwenden Sie dbt-Snapshots, um die Historie zu erhalten. Wir können die Daten in diesen Snapshots speichern, so dass wir, wenn die Originaltabelle überschrieben wird, den Verlauf behalten. Lesen Sie hier mehr über Schnappschüsse
Tipp 11: Umgang mit SAS-spezifischen Funktionen in Snowflake
Ein weiterer kostenloser Tipp, da Sie es bis hierher geschafft haben!
Während der Migration werden Sie wahrscheinlich auf SAS-spezifische Funktionen stoßen, die keine direkten Entsprechungen in Snowflake haben. Wir haben zum Beispiel festgestellt, dass sich die Altersberechnungen aufgrund der Präzisionsunterschiede zwischen der yrdif-Funktion von SAS und der DATEDIFF-Funktion von Snowflake leicht unterscheiden. Dies ist darauf zurückzuführen, dass yrdif Schaltjahre komplexer behandelt. Snowflake bietet zwar Äquivalente für die meisten SAS-Funktionen, aber in einigen Fällen müssen Sie entweder eigene Funktionen schreiben oder geringfügige Berechnungsunterschiede akzeptieren.
Lösung: Dokumentieren Sie die Unterschiede zwischen SAS- und Snowflake-Funktionen und entscheiden Sie gemeinsam mit den Beteiligten, welche Genauigkeitsabweichung akzeptabel ist. In unserem Fall haben wir kleine Unterschiede bei den Altersberechnungen akzeptiert, nachdem wir uns vergewissert hatten, dass sie keine Auswirkungen auf die Geschäftsentscheidungen haben würden.
Fazit
Die Migration von SAS Viya zu Snowflake und dbt ist kein Selbstläufer - es ist eine bedeutende Umstellung, die ihre eigenen Herausforderungen mit sich bringt. Diese modernen Tools bieten zwar Vorteile wie Skalierbarkeit und Versionskontrolle, aber sie sind letztlich auch nur das: Tools.
Die eigentliche Grundlage für eine erfolgreiche Transformation der Analytik ist nicht der Technologie-Stack, sondern die Datenteams, die täglich zusammenarbeiten. Es sind die Analysten und Techniker, die sich für die Verbesserung der Datenqualität durch automatisierte Tests einsetzen, die komplexe Abfragen vereinfachen, anstatt sie fortzuführen, und die sich die Zeit nehmen, die nicht-intuitiven Aspekte Ihrer Datenmodelle zu dokumentieren.
Ja, dbt und Snowflake können die Umsetzung dieser Praktiken erleichtern, aber sie werden die zugrunde liegenden Probleme in Ihrem Datenökosystem nicht auf magische Weise lösen. Sie werden weiterhin Probleme aufdecken und diskutieren müssen, Tag für Tag. Die Arbeit mit dbt macht diese Probleme nur sichtbarer und einfacher zu lösen.
Unsere Migrationsreise hat uns gelehrt, dass der Erfolg ebenso sehr von Menschen und Prozessen abhängt wie von Plattformen. Die Teams, die nach der Migration erfolgreich sind, sind diejenigen, die Zusammenarbeit, kontinuierliche Verbesserung und ein Engagement für Qualität schätzen - unabhängig von der verwendeten Technologie.
Sind Sie daran interessiert, mehr über diese Migration zu erfahren oder haben Sie Fragen zu den gegebenen Tipps? Nehmen Sie Kontakt mit uns auf!
Möchten Sie mehr erfahren?
Sehen Sie sich unsere verwandten Schulungen an:
- Data Warehousing und Datenmodellierung
Benötigen Sie mehr Ausrüstung auf Ihrem Weg zum Analytics Engineer?
Sie möchten Ihre Kenntnisse im Bereich Analytics Engineering vertiefen? Dann suchen Sie nicht weiter! Unser Expertenteam hat den maßgeblichen Leitfaden verfasst: The Fundamentals of Analytics Engineering. Dieses umfassende Werk, das von mir und sechs talentierten Co-Autoren verfasst wurde, enthält alles, was Sie wissen müssen, um als Analytics Engineer erfolgreich zu sein.
 Die Grundlagen der Analysetechnik
Die Grundlagen der Analysetechnik
Verfasst von
Lasse Benninga
Unsere Ideen
Weitere Blogs




Contact