Blog
Working with multiple partition formats within a Hive table with Spark

Problem statement and why is this interesting
Incoming data is usually in a format different than we would like for long-term storage. The first step that we usually do is transform the data into a format such as Parquet that can easily be queried by Hive/Impala.
The use case we imagined is when we are ingesting data in Avro format. The users want easy access to the data with Hive or Spark. To have performant queries we need the historical data to be in Parquet format. We don't want to have two different tables: one for the historical data in Parquet format and one for the incoming data in Avro format. Our preference goes out to having one table which can handle all data, no matter the format. This way we can run our conversion process (from Avro to Parquet) let's say every night, but the users would still get access to all data all the time.
In Hive you can achieve this with a partitioned table, where you can set the format of each partition. Spark unfortunately doesn't implement this. Since our users also use Spark, this was something we had to fix. This was also a nice challenge for a couple of Xebia Friday's where we could then learn more about the internals of Apache Spark.
Learn Spark or Python in just one day
Develop Your Data Science Capabilities. **Online**, instructor-led on 23 or 26 March 2020, 09:00 - 17:00 CET.
Setting up a test environment
First we had to identify what we need to be able to reproduce the problem. We needed the following components:- Hive with persistent Hive metastore
- Hadoop to be able to store and access the files
- Spark
$ brew install hadoop $ brew install hive $ brew install apache-spark $ mkdir ${HOME}/localhdfs
$ docker pull krisgeus/docker-hive-metastore-postgresql:upgrade-2.3.0 $ docker run -p 5432:5432 krisgeus/docker-hive-metastore-postgresql:upgrade-2.3.0
- Download postgresql-42.2.4.jar from this link
- Add this jar to Hive lib directory (in our case the Hive version was 2.3.1)
$ cp postgresql-42.2.4.jar /usr/local/Cellar/hive//libexec/lib.
- Create a working directory
$ mkdir ${HOME}/spark-hive-schema $ cd ${HOME}/spark-hive-schema
- Create a configuration directory and copy hadoop and hive base configurations
$ mkdir hadoop_conf $ cp -R /usr/local/Cellar/hadoop/3.0.0/libexec/etc/hadoop/* ${HOME}/spark-hive-schema/hadoop_conf $ cp -R /usr/local/Cellar/hive/2.3.1/libexec/conf/* ${HOME}/spark-hive-schema/hadoop_conf $ cp conf/hive-default.xml.template ${HOME}/spark-hive-schema/hadoop_conf/hive-site.xml
- Change configurations in hive-site.xml so we actually use the Hive Metastore we just started
system:java.io.tmpdir /tmp/hive/java system:user.name ${user.name} hive.metastore.warehouse.dir ${user.home}/localhdfs/user/hive/warehouse location of default database for the warehouse javax.jdo.option.ConnectionUserName hive Username to use against metastore database javax.jdo.option.ConnectionURL jdbc:postgresql://localhost:5432/metastore JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. datanucleus.connectionPoolingType NONE Expects one of [bonecp, dbcp, hikaricp, none]. Specify connection pool library for datanucleus javax.jdo.option.ConnectionDriverName org.postgresql.Driver Driver class name for a JDBC metastore javax.jdo.option.ConnectionUserName hive Username to use against metastore database
- Make /tmp/hive writable:
$ chmod 777 /tmp/hive
- In a terminal set paths so we can start HiveServer2, where hadoop_version=3.0.0, hive_version=2.3.1
$ export HADOOP_HOME=/usr/local/Cellar/hadoop//libexec $ export HIVE_HOME=/usr/local/Cellar/hive/ /libexec $ export HADOOP_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ export HIVE_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ hiveserver2
- In another terminal set the same paths and start beeline, where hadoop_version=3.0.0, hive_version=2.3.1
$ export HADOOP_HOME=/usr/local/Cellar/hadoop//libexec $ export HIVE_HOME=/usr/local/Cellar/hive/ /libexec $ export HADOOP_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ export HIVE_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ beeline -u jdbc:hive2://localhost:10000/default -n hive -p hive
Creating a working example in Hive
- In beeline create a database and a table
CREATE DATABASE test; USE test; CREATE EXTERNAL TABLE IF NOT EXISTS events(eventType STRING, city STRING) PARTITIONED BY(dt STRING) STORED AS PARQUET;
- Add two parquet partitions
ALTER TABLE events ADD PARTITION (dt='2018-01-25') PARTITION (dt='2018-01-26'); ALTER TABLE events PARTITION (dt='2018-01-25') SET FILEFORMAT PARQUET; ALTER TABLE events PARTITION (dt='2018-01-26') SET FILEFORMAT PARQUET;
- Add a partition where we'll add Avro data
ALTER TABLE events ADD PARTITION (dt='2018-01-27'); ALTER TABLE events PARTITION (dt='2018-01-27') SET FILEFORMAT AVRO;
- Check the table
SELECT * FROM events;
| events.eventtype | events.city | events.dt |
|---|---|---|
DESCRIBE FORMATTED events PARTITION (dt="2018-01-26");
| Column name | Data type |
|---|---|
| # Storage Information | |
| SerDe Library: | org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe |
| InputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat |
| OutputFormat: | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat |
DESCRIBE FORMATTED events PARTITION (dt="2018-01-27");
| Column name | Data type |
|---|---|
| # Storage Information | |
| SerDe Library: | org.apache.hadoop.hive.serde2.avro.AvroSerDe |
| InputFormat: | org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat |
| OutputFormat: | org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat |
- Create test data directory
mkdir ${HOME}/spark-hive-schema/testdata
- Generate Avro data and add to table
$ cat ${HOME}/spark-hive-schema/testdata/data.json { "eventtype": "avro", "city": "Breukelen" } { "eventtype": "avro", "city": "Wilnis" } { "eventtype": "avro", "city": "Abcoude" } { "eventtype": "avro", "city": "Vinkeveen" } $ cat ${HOME}/spark-hive-schema/testdata/data.avsc { "type" : "record", "name" : "events", "namespace" : "com.xebia.events", "fields" : [ { "name" : "eventtype", "type" : "string" }, { "name" : "city", "type" : "string" }] $ brew install avro-tools $ cd ${HOME}/spark-hive-schema/testdata $ avro-tools fromjson --schema-file data.avsc data.json > ${HOME}/localhdfs/user/hive/warehouse/test.db/events/dt=2018-01-27/data.avro
- Generate parquet data and add to table
$ cd ${HOME}/spark-hive-schema/testdata $ spark-shell > import org.apache.spark.sql.functions.lit > spark.read.json("data.json").select(lit("parquet").alias("eventtype"), col("city")).write.parquet("data.pq") > :quit $ cp ./data.pq/part*.parquet ${HOME}/localhdfs/user/hive/warehouse/test.db/events/dt=2018-01-26/
- Insert data into last existing partition using beeline
INSERT INTO TABLE events PARTITION (dt="2018-01-25") SELECT 'overwrite', 'Amsterdam';
- Check that we have data in beeline
SELECT * FROM events;
| events.eventtype | events.city | events.dt |
|---|---|---|
| overwrite | Amsterdam | 2018-01-25 |
| parquet | Breukelen | 2018-01-26 |
| parquet | Wilnis | 2018-01-26 |
| parquet | Abcoude | 2018-01-26 |
| parquet | Vinkeveen | 2018-01-26 |
| avro | Breukelen | 2018-01-27 |
| avro | Wilnis | 2018-01-27 |
| avro | Abcoude | 2018-01-27 |
| avro | Vinkeveen | 2018-01-27 |
- Double check that the formats are correct
$ tree ${HOME}/localhdfs/user/hive/warehouse/test.db/events .../localhdfs/user/hive/warehouse/test.db/events ├── dt=2018-01-25 │ └── 000000_0 ├── dt=2018-01-26 │ └── part-00000-1846ef38-ec33-47ae-aa80-3f72ddb50c7d-c000.snappy.parquet └── dt=2018-01-27 └── data.avro
Creating a failing test in Spark
Connect to spark and make sure we access the Hive Metastore we set up:$ export HADOOP_HOME=/usr/local/Cellar/hadoop//libexec $ export HIVE_HOME=/usr/local/Cellar/hive/ /libexec $ export HADOOP_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ export HIVE_CONF_DIR=${HOME}/spark-hive-schema/hadoop_conf $ spark-shell --driver-class-path /usr/local/Cellar/hive/2.3.1/libexec/lib/postgresql-42.2.4.jar --jars /usr/local/Cellar/hive/2.3.1/libexec/lib/postgresql-42.2.4.jar --conf spark.executor.extraClassPath=/usr/local/Cellar/hive/2.3.1/libexec/lib/postgresql-42.2.4.jar --conf spark.hadoop.javax.jdo.option.ConnectionURL=jdbc:postgresql://localhost:5432/metastore --conf spark.hadoop.javax.jdo.option.ConnectionUserName=hive --conf spark.hadoop.javax.jdo.option.ConnectionPassword=hive --conf spark.hadoop.javax.jdo.option.ConnectionDriverName=org.postgresql.Driver --conf spark.hadoop.hive.metastore.schema.verification=true --conf spark.hadoop.hive.metastore.schema.verification.record.version=true --conf spark.sql.hive.metastore.version=2.1.0 --conf spark.sql.hive.metastore.jars=maven > spark.sql("select * from test.events").show() ... java.lang.RuntimeException: file:...localhdfs/user/hive/warehouse/test.db/events/dt=2018-01-27/data.avro is not a Parquet file. expected magic number at tail [80, 65, 82, 49] but found [-126, 61, 76, 121] ...
$ git clone https://github.com/krisgeus/spark.git $ cd spark $ ./build/sbt "hive/testOnly *HiveSQLViewSuite"
- create a table with partitions
- create a table based on Avro data which is actually located at a partition of the previously created table. Insert some data in this table.
- create a table based on Parquet data which is actually located at another partition of the previously created table. Insert some data in this table.
- try to read the data from the original table with partitions
$ ./build/sbt "hive/testOnly *MultiFormatTableSuite ... - create hive table with multi format partitions *** FAILED *** (4 seconds, 265 milliseconds) [info] org.apache.spark.sql.catalyst.parser.ParseException: Operation not allowed: ALTER TABLE SET FILEFORMAT(line 2, pos 0) [info] [info] == SQL == [info] [info] ALTER TABLE ext_multiformat_partition_table [info] ^^^ [info] PARTITION (dt='2018-01-26') SET FILEFORMAT PARQUET ...
Understanding execution plans
The best explanation that we found was on the Databricks site, the article about Deep Dive into Spark SQL’s Catalyst Optimizer Here is an excerpt in case you don't want to read the whole article:At the core of Spark SQL is the Catalyst optimizer, which leverages advanced programming language features (e.g. Scala’s pattern matching and quasiquotes) in a novel way to build an extensible query optimizer. We use Catalyst’s general tree transformation framework in four phases, as shown below: (1) analyzing a logical plan to resolve references, (2) logical plan optimization, (3) physical planning, and (4) code generation to compile parts of the query to Java bytecode. In the physical planning phase, Catalyst may generate multiple plans and compare them based on cost. All other phases are purely rule-based. Each phase uses different types of tree nodes; Catalyst includes libraries of nodes for expressions, data types, and logical and physical operators.
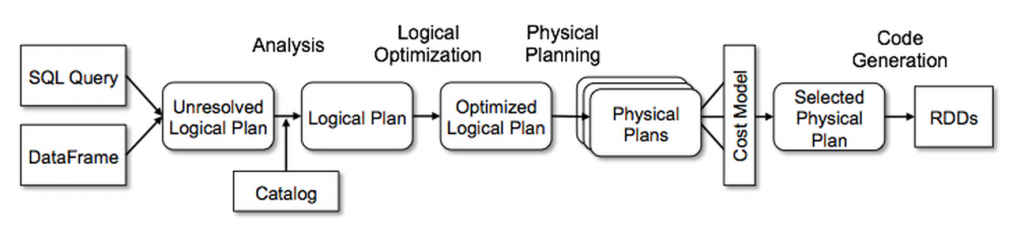
Spark SQL begins with a relation to be computed, either from an abstract syntax tree (AST) returned by a SQL parser, or from a DataFrame object constructed using the API. Spark SQL uses Catalyst rules and a Catalog object that tracks the tables in all data sources to resolve these attributes. It starts by building an “unresolved logical plan” tree with unbound attributes and data types, then applies rules that do the following: Looking up relations by name from the catalog. Mapping named attributes, such as col, to the input provided given operator’s children. Determining which attributes refer to the same value to give them a unique ID (which later allows optimization of expressions such as col = col). Propagating and coercing types through expressions: for example, we cannot know the return type of 1 + col until we have resolved col and possibly casted its subexpressions to a compatible types. The logical optimization phase applies standard rule-based optimizations to the logical plan. These include constant folding, predicate pushdown, projection pruning, null propagation, Boolean expression simplification, and other rules. In the physical planning phase, Spark SQL takes a logical plan and generates one or more physical plans, using physical operators that match the Spark execution engine. It then selects a plan using a cost model. At the moment, cost-based optimization is only used to select join algorithms: for relations that are known to be small, Spark SQL uses a broadcast join, using a peer-to-peer broadcast facility available in Spark. The framework supports broader use of cost-based optimization, however, as costs can be estimated recursively for a whole tree using a rule. We thus intend to implement richer cost-based optimization in the future. The physical planner also performs rule-based physical optimizations, such as pipelining projections or filters into one Spark map operation. In addition, it can push operations from the logical plan into data sources that support predicate or projection pushdown. We will describe the API for these data sources in a later section. The final phase of query optimization involves generating Java bytecode to run on each machine.
Support setting the format for a partition in a Hive table with Spark
First we had to discover that Spark uses ANTLR to generate its SQL parser. ANTLR ANother Tool for Language Recognition can generate a grammar that can be built and walked. The grammar for Spark is specified in SqlBase.g4. So we need to support FILEFORMAT in case a partition is set, thus we had to add the following line to SqlBase.g4.| ALTER TABLE tableIdentifier (partitionSpec)? SET FILEFORMAT fileFormat
/** * Create an [[AlterTableFormatPropertiesCommand]] command. * * For example: * {{{ * ALTER TABLE table [PARTITION spec] SET FILEFORMAT format; * }}} */ override def visitSetTableFormat(ctx: SetTableFormatContext): LogicalPlan = withOrigin(ctx) { val format = (ctx.fileFormat) match { // Expected format: INPUTFORMAT input_format OUTPUTFORMAT output_format case (c: TableFileFormatContext) => visitTableFileFormat(c) // Expected format: SEQUENCEFILE | TEXTFILE | RCFILE | ORC | PARQUET | AVRO case (c: GenericFileFormatContext) => visitGenericFileFormat(c) case _ => throw new ParseException("Expected STORED AS ", ctx) } AlterTableFormatCommand( visitTableIdentifier(ctx.tableIdentifier), format, // TODO a partition spec is allowed to have optional values. This is currently violated. Option(ctx.partitionSpec).map(visitNonOptionalPartitionSpec)) }
/** * A command that sets the format of a table/view/partition . * * The syntax of this command is: * {{{ * ALTER TABLE table [PARTITION spec] SET FILEFORMAT format; * }}} */ case class AlterTableFormatCommand( tableName: TableIdentifier, format: CatalogStorageFormat, partSpec: Option[TablePartitionSpec]) extends RunnableCommand { override def run(sparkSession: SparkSession): Seq[Row] = { val catalog = sparkSession.sessionState.catalog val table = catalog.getTableMetadata(tableName) DDLUtils.verifyAlterTableType(catalog, table, isView = false) // For datasource tables, disallow setting serde or specifying partition if (partSpec.isDefined && DDLUtils.isDatasourceTable(table)) { throw new AnalysisException("Operation not allowed: ALTER TABLE SET FILEFORMAT " + "for a specific partition is not supported " + "for tables created with the datasource API") } if (partSpec.isEmpty) { val newTable = table.withNewStorage( serde = format.serde.orElse(table.storage.serde), inputFormat = format.inputFormat.orElse(table.storage.inputFormat), outputFormat = format.outputFormat.orElse(table.storage.outputFormat), properties = table.storage.properties ++ format.properties) catalog.alterTable(newTable) } else { val spec = partSpec.get val part = catalog.getPartition(table.identifier, spec) val newPart = part.copy(storage = part.storage.copy( serde = format.serde.orElse(part.storage.serde), inputFormat = format.inputFormat.orElse(table.storage.inputFormat), outputFormat = format.outputFormat.orElse(table.storage.outputFormat), properties = part.storage.properties ++ format.properties)) catalog.alterPartitions(table.identifier, Seq(newPart)) } Seq.empty[Row] } }
Surprise: execution plan differences...
We were playing around and we accidentally changed the format of the partitioned table to Avro, so we had an Avro table with a Parquet partition in it...and IT WORKED!! We could read all the data...but wait, what?!!? So Avro table with Parquet partition works, but Parquet table with Avro partition doesn't? What's the difference? Let's see the execution plans:- execution plan for the Parquet table with Avro partitions
[ { "class" : "org.apache.spark.sql.execution.ProjectExec", "num-children" : 1, "projectList" : [ [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... "qualifier" : "ext_parquet_partition_table" } ], [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... "qualifier" : "ext_parquet_partition_table" } ] ], "child" : 0 }, { "class" : "org.apache.spark.sql.execution.FileSourceScanExec", "num-children" : 0, "relation" : null, "output" : [ [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... } ], [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... } ], [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... } ] ], "requiredSchema" : { "type" : "struct", "fields" : [ { "name" : "key", "type" : "integer", "nullable" : true, "metadata" : { } }, { "name" : "value", "type" : "string", "nullable" : true, "metadata" : { } } ] }, "partitionFilters" : [ ], "dataFilters" : [ ], "tableIdentifier" : { "product-class" : "org.apache.spark.sql.catalyst.TableIdentifier", "table" : "ext_parquet_partition_table", "database" : "default" } } ]
- execution plan for the Avro table with Parquet partitions
[ { "class" : "org.apache.spark.sql.hive.execution.HiveTableScanExec", "num-children" : 0, "requestedAttributes" : [ [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... "qualifier" : "ext_avro_partition_table" } ], [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", ... "qualifier" : "ext_avro_partition_table" } ] ], "relation" : [ { "class" : "org.apache.spark.sql.catalyst.catalog.HiveTableRelation", ... "tableMeta" : { "product-class" : "org.apache.spark.sql.catalyst.catalog.CatalogTable", "identifier" : { "product-class" : "org.apache.spark.sql.catalyst.TableIdentifier", "table" : "ext_avro_partition_table", "database" : "default" }, "tableType" : { "product-class" : "org.apache.spark.sql.catalyst.catalog.CatalogTableType", "name" : "EXTERNAL" }, "storage" : { "product-class" : "org.apache.spark.sql.catalyst.catalog.CatalogStorageFormat", "locationUri" : null, "inputFormat" : "org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat", "outputFormat" : "org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat", "serde" : "org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe", "compressed" : false, "properties" : null }, "schema" : { "type" : "struct", "fields" : [ { "name" : "key", "type" : "integer", "nullable" : true, "metadata" : { } }, { "name" : "value", "type" : "string", "nullable" : true, "metadata" : { } }, { "name" : "dt", "type" : "string", "nullable" : true, "metadata" : { } } ] }, "provider" : "hive", "partitionColumnNames" : "[dt]", "owner" : "secret", "createTime" : 1532699365000, "lastAccessTime" : 0, "createVersion" : "2.4.0-SNAPSHOT", "properties" : null, "stats" : null, "unsupportedFeatures" : [ ], "tracksPartitionsInCatalog" : true, "schemaPreservesCase" : true, "ignoredProperties" : null, "hasMultiFormatPartitions" : false }, "dataCols" : [ [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", "num-children" : 0, "name" : "key", "dataType" : "integer", "nullable" : true, "metadata" : { }, "exprId" : { "product-class" : "org.apache.spark.sql.catalyst.expressions.ExprId", "id" : 25, "jvmId" : "5988f5b1-0966-49ca-a6de-2485d5582464" } } ], [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", "num-children" : 0, "name" : "value", "dataType" : "string", "nullable" : true, "metadata" : { }, "exprId" : { "product-class" : "org.apache.spark.sql.catalyst.expressions.ExprId", "id" : 26, "jvmId" : "5988f5b1-0966-49ca-a6de-2485d5582464" } } ] ], "partitionCols" : [ [ { "class" : "org.apache.spark.sql.catalyst.expressions.AttributeReference", "num-children" : 0, "name" : "dt", "dataType" : "string", "nullable" : true, "metadata" : { }, "exprId" : { "product-class" : "org.apache.spark.sql.catalyst.expressions.ExprId", "id" : 27, "jvmId" : "5988f5b1-0966-49ca-a6de-2485d5582464" } } ] ] } ], "partitionPruningPred" : [ ], "sparkSession" : null } ]
Finding the magic setting
We went digging in the code again and we discovered the following method in HiveStrategies.scala/** * Relation conversion from metastore relations to data source relations for better performance * * - When writing to non-partitioned Hive-serde Parquet/Orc tables * - When scanning Hive-serde Parquet/ORC tables * * This rule must be run before all other DDL post-hoc resolution rules, i.e. *PreprocessTableCreation,PreprocessTableInsertion,DataSourceAnalysisandHiveAnalysis. */ case class RelationConversions( conf: SQLConf, sessionCatalog: HiveSessionCatalog) extends Rule[LogicalPlan] { private def isConvertible(relation: HiveTableRelation): Boolean = { val serde = relation.tableMeta.storage.serde.getOrElse("").toLowerCase(Locale.ROOT) serde.contains("parquet") && conf.getConf(HiveUtils.CONVERT_METASTORE_PARQUET) || serde.contains("orc") && conf.getConf(HiveUtils.CONVERT_METASTORE_ORC) } ...
false, meaning that we won't optimize to data source relations in case we altered the partition file format.
We simulated this by adding the following line to our unit test:
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false")
Implement multi format partitions support without disabling optimizations manually
We decided to add a property,hasMultiFormatPartitions to the CatalogTable which reflects if we have a table with multiple different formats in it's partitions. This had to be done in HiveClientImpl.scala
The following line did the trick:
hasMultiFormatPartitions = shim.getAllPartitions(client, h).map(_.getInputFormatClass).distinct.size > 1
/** * Relation conversion from metastore relations to data source relations for better performance * * - When writing to non-partitioned Hive-serde Parquet/Orc tables * - When scanning Hive-serde Parquet/ORC tables * * This rule must be run before all other DDL post-hoc resolution rules, i.e. *PreprocessTableCreation,PreprocessTableInsertion,DataSourceAnalysisandHiveAnalysis. */ case class RelationConversions( conf: SQLConf, sessionCatalog: HiveSessionCatalog) extends Rule[LogicalPlan] { private def isConvertible(relation: HiveTableRelation): Boolean = { val serde = relation.tableMeta.storage.serde.getOrElse("").toLowerCase(Locale.ROOT) val hasMultiFormatPartitions = relation.tableMeta.hasMultiFormatPartitions serde.contains("parquet") && conf.getConf(HiveUtils.CONVERT_METASTORE_PARQUET) && (!hasMultiFormatPartitions) || serde.contains("orc") && conf.getConf(HiveUtils.CONVERT_METASTORE_ORC) } ...
Further enhance your Apache Spark knowledge!
We offer an in-depth Data Science with Spark course that will make data science at scale a piece of cake for any data scientist, engineer, or analyst!Written by
Kris Geusebroek




Contact