
Winning Recipe for Finetuning LLMs
At NeurIPS 2023 we participated in the LLM Efficiency Challenge. During the conference, I met up with the winners of the competition and joined the workshop where they shared their approach. In this blog, we share the key takeaways on the winning approaches.
The Challenge
The goal of the competition is to finetune a Large Language Model (LLM) to perform well on a broad range of tasks. The rules were simple:
- Use an open-source base model.
- Finetune it with open-source human-generated data.
- On a single GPU within 24 hours.
There were two tracks in the competition depending on the GPU type:
- 4090 Track (24GB VRAM)
- A100 Track (40GB VRAM)
The Recipe
What did both winners do? In general, the winning approach was quite similar across both tracks.
- Start with a good base model that performs well on relevant benchmarks and is efficient during inference.
- Rigorously filter for high-quality data by curating it and balancing it between tasks.
- Parameter efficient finetuning can be done with LoRA or QLoRA and if higher efficiency is needed also Flash Attention.
Make it your own
Where the approaches differed was whether they used quantization and Flash attention.
Resource optimized
If your application is more constrained by memory, time, and/or costs, you might want to consider using QLoRA and Flash Attention. Be wary of the quantization loss, measure it during your experiments. Flash Attention at the time of the competition was bleeding edge, now it is more integrated across deep learning packages.
Less constrained
If you have a bit more memory to spare, you can consider using LoRA. In both cases experiment with the rank. As you have read in this blog, the range you can experiment with is quite large. The rank of the winning approaches ranges from 8 to 256.
Let's dive into the specifics of the two different winning strategies.
4090 Track - Detailed Winning Approach
The winner of the 4090 track was Team Upaya. Their approach was unique in several ways. They focussed on the generalization of the model and used semi-automated data curation.
Data Selection and Preparation
Team Upaya started with the Super Natural Instructions dataset. They manually selected relevant tasks and went down from 1600+ to ~450 tasks. The tasks were then categorized into 2 categories, Exact Match and Generation tasks. The base model was used to see where it is already doing well and not doing well. Between tasks, they sampled more from Generation tasks with low Rouge score or Exact Match tasks with low Accuracy. They balanced their samples to ~50k from each category. Resulting in the first 100k samples of their dataset.
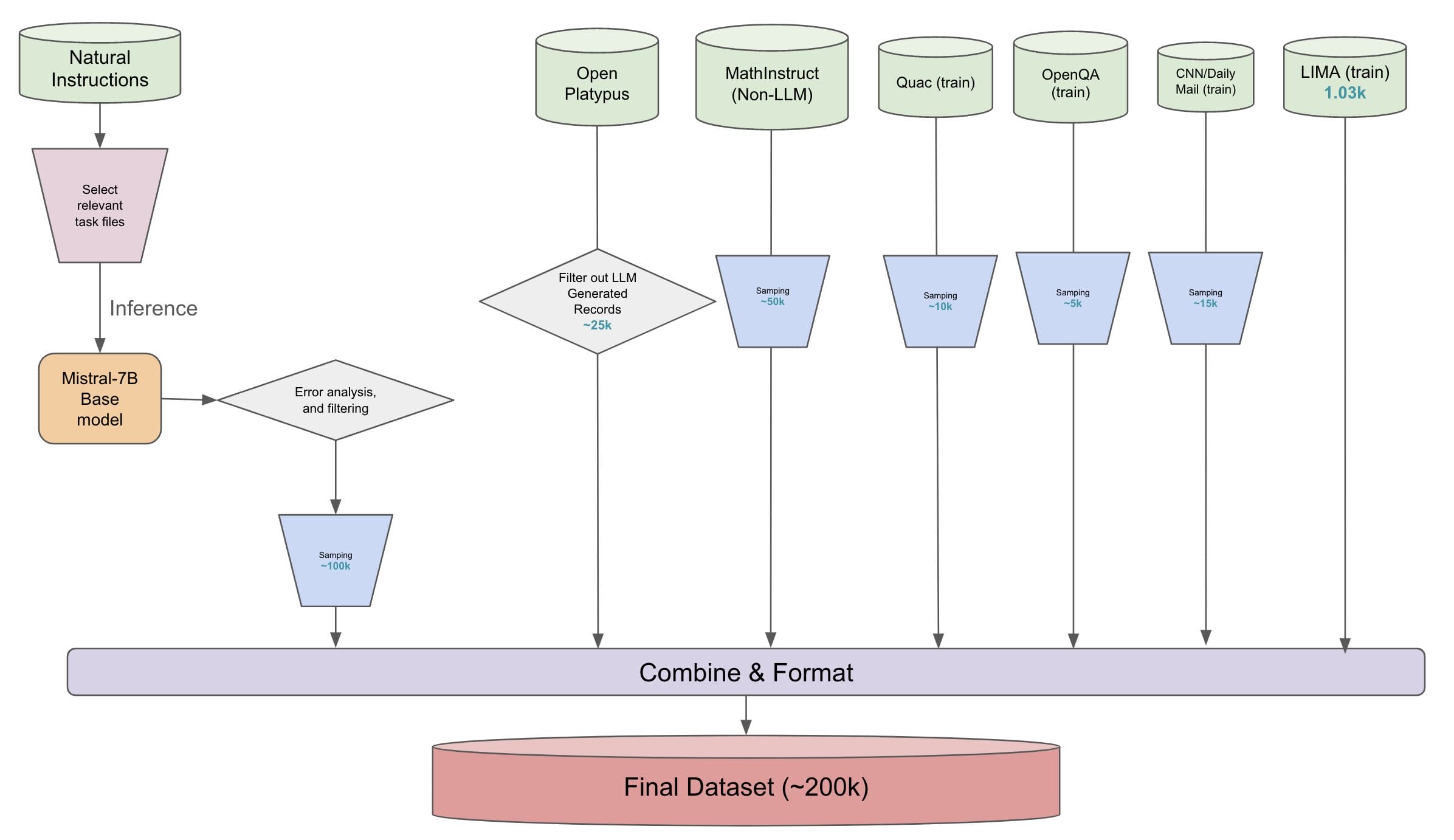
Other datasets that were added are:
- Open Platypus (Non-LLM generated): 25k samples
- MathInstruct (Non-LLM generated): 50k samples
- Quac (train): 10k samples
- OpenQA (train): 5k samples
- CNN/DailyMail (train): 15k samples
- LIMA (train): 1k samples
These samples are combined and formatted. MathInstruct needs a bit of special preparation. The final dataset is 200k samples. The script combine_datasets.py combines all datasets as shown in the above diagram and prepares final train/validation splits. The validation set is 10% and the test contains 2000 samples. The final dataset is available on HuggingFace.
Prompt-format
For the prompt format, they used the following format:
- special_tokens:
- bos_token: "<s>"
- eos_token: "</s>"
- unk_token: "<unk>"
Base Model
Mistral-7B is the base model that was used by Upaya. They also experimented with other models, like QWEN-14B, but Mistral-7B performed best also taking inference time and VRAM into consideration.
Finetuning Methods
Their main methods for efficient finetuning were QLoRA, Flash Attention, and the paged_adamw_32bit optimizer. While they trained for 3 epochs with a batch size of 2 and an accumulation of 4. Retrospectively they found the model after 2 epochs performed best on their validation set. Upaya's final model can be found on Huggingface.
QLoRA
The hyperparameter settings for QLoRA were quite standard:
- Rank of 128
- Alpha of twice the rank 256
- Quantization of the pretrained weights to NF4
- Precision of trainable weights in BF16
It was interesting to see that they applied LoRA to all attention layers:
- lora_target_modules:
- q_proj
- v_proj
- k_proj
- o_proj
- gate_proj
- down_proj
- up_proj
As opposed to the A100 track where only two attention layers were used.
Flash Attention
Flash attention sped up the training and inference. Which combined with the NF4 quantization allowed them to fit the model on a 4090 GPU.
Paged AdamW 32bit
The paged AdamW optimizer was used to reduce the memory footprint of the optimizer.
All hyperparameters can be found in their repository.
For more details, you can check out their repo or paper, which is accepted at the Data-centric Machine Learning Research (DMLR) workshop at ICLR 2024.
A100 Track - Detailed Winning Approach
The winners of the A100 track are Team Percent-BFD.
Data Selection and Preparation
Their dataset is based on the following datasets:
| Dataset | Subset | Sampling |
| MMLU | all high school subjects & philosophy, moral disputes & moreal scenarios | 10% random |
| BIG-bench | analytic_entailment, causal_judgement, empirical_judgements, known_unkowns, logical_deduction, emoji_movie, strange_stories, snarks, dark_humor_detection | |
| CNN_dailymail | 10% random | |
| TruthfulQA | ||
| GSM8K | ||
| LIMA | 10 copies | |
| Databricks-dolly-15k | ||
| Oasst1-en | ||
| summarize_from_feedback_tldr_3_filtered |
After filtering and subsampling their final dataset still contained 247.000 rows in total.
Prompt-format
The prompts were formatted using the SFT format:
Human: {query}
Assistant: {answer}
Base Model
After rigorous experimentation and re-evaluation when new models were released, the team settled on QWEN-14B.
Finetuning Methods
The only efficient finetuning method used was LoRA. It was interesting to see that no quantization was used. The frozen en trainable parameters were both in BF16 precision.
They were able to still fit the model in 40GB VRAM by using a very low rank of 8, and only applying LoRA on two of the attention layers:
c_attnc_proj
On top of that the batch size was only 2 with an accumulation of 4. But this was more common across other teams. To stay within the 24-hour limit, they only trained for 1 epoch.
Conclusion
Let's briefly recap the winning recipe for finetuning LLMs. What was interesting to see is that both teams had a similar theme. Now you can apply these methods in your finetuning pipeline:
- Start with a good base model. The experimentation starts with the selection of the base model.
- Rigorously filter for high-quality data. Don't compromise on the quality of the data.
- Choose the finetuning method based on your situation, whether you want to efficiently finetune or your situation is less constrained.
Acknowledgments
Congratulations to the winners of the competition and thanks to both teams for sharing their approach. A special thanks to Ashvini Jindal (the team lead of Upaya), whom I had the pleasure of meeting at NeurIPS, and for his feedback on this blog. Finally, thanks to the organizers for hosting the competition and workshop. Hopefully, I see you all at the next edition.
References
Written by

Jetze Schuurmans
Machine Learning Engineer
Jetze is a well-rounded Machine Learning Engineer, who is as comfortable solving Data Science use cases as he is productionizing them in the cloud. His expertise includes: AI4Science, MLOps, and GenAI. As a researcher, he has published papers on: Computer Vision and Natural Language Processing and Machine Learning in general.
Our Ideas
Explore More Blogs




Contact